基于视觉注意力模型的电表铭牌识别研究*
2022-10-20张忠宝张威鲁观娜彭鑫霞
刘 影,张忠宝,张威,鲁观娜,彭鑫霞
(国网冀北电力有限公司,北京 102208)
当前对电表等电力设备的管理已经越来越多地引入了各类智能化手段,以促进电网管理的数字化水平。其中,实现电表铭牌的自动化识别是极为关键的一项技术,对提升电表设备在归档,维修以及更换等管理各环节的效率有重要意义[1-3]。
针对这一问题,本文提出一种使用深度学习技术的电表铭牌识别方法。该方法采用了自然语言处理问题中常用的编码器-解码器结构,便于引入注意力机制。相比基于传统图像处理的识别技术,本文方法避免了复杂的图像特征工程(feature engineering)过程,引入了卷积神经网络(convolutional neural networks,CNN)用于自动提取图像特征;同时,相比一般的纯视觉方法,本文将自然语言处理领域常用的注意力模型引入铭牌识别任务,这一机制可以引导模型关注图像中涉及文字的重点区域,进一步结合语言模型,提升识别效果。本文通过在真实数据上的实验验证了该方法的优势。
1 相关研究
铭牌或标牌识别是一类典型的场景文字识别(scene text recognition)任务[4]。所谓场景文字,指的是直接包含在自然场景图像中的文本,区别于以规则样式印刷的文本。相比印刷文本,场景文本在样式(颜色,字体等)、清晰度(分辨率)甚至内容方面都具有更高的不确定性,因此复杂程度往往也高于一般意义上的光学字符识别(optical character recognition,OCR)问题。
端到端的场景文字识别任务通常分为两个主要步骤:文字检测,在图像上分割出包含文字的区域;内容识别,输出该区域内的具体文本内容[5]。前者是一种目标检测问题,对于铭牌识别这类特定的场景文字识别任务,由于具备了铭牌特征的先验知识,可以通过常用的目标检测器如单发检测器(singleshot detection,SSD)或区域卷积神经网络(region-CNN,RCNN)来完成[6-7]。本文重点关注第二个步骤的问题。
现有的内容识别技术通常基于预先定义的词典,即通过限制内容的范围来实现更高精度的识别。对于样式变化较少、内容标准化程度较高的一类场景文字,如车牌号、身份证等,这一方法能达到极佳的效果[8-9]。显然,这主要是因为此类场景文本内容多样化程度低,预设词典提供了可靠的先验知识。而电表铭牌的内容与样式丰富度无疑要高得多,很难单纯通过词典来限制,因此铭牌识别更偏向于无约束或半约束的文本内容识别,这也是本文主要研究内容。
2 模型结构
本文提出的电表铭牌识别方法主要基于具有编码器-解码器(encoder-decoder)框架的视觉注意力模型,具体结构如图1 所示。这一框架常用于自然语言处理与时序预测等序列到序列学习任务,本文将其引入铭牌识别这一计算机视觉问题中[10-12]。编码器将文字检测步骤中分割出的含有文本的局部图像作为输入,并通过卷积神经网络将该图像编码为卷积特征序列。视觉注意力模型则基于多层感知器(multi-layer perceptron,MLP)结构,被嵌入编码器与解码器之间。在解码器依次识别出图像中的文本内容时,注意力模型通过调整注意力权值,在每一步使解码器重点处理文字序列的特定部分。随后,基于长短时记忆网络(long short-term memory,LSTM)的解码器逐步输出一系列文字,拼接为最终的识别结果。
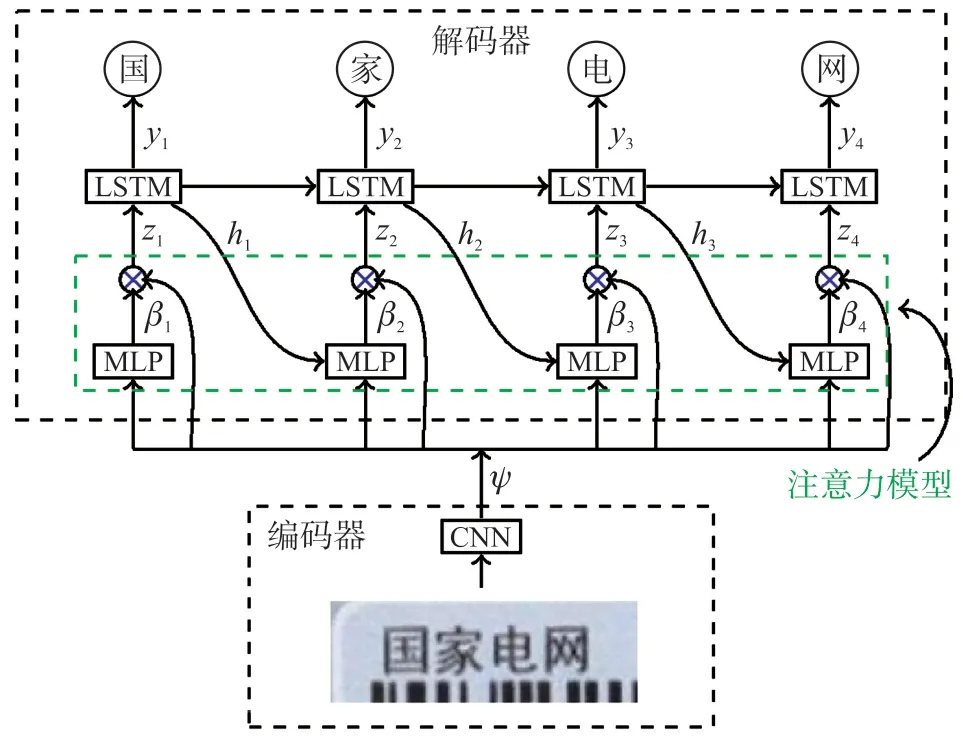
图1 视觉注意力模型的编码器-解码器结构
2.1 编码器
编码器部分使用卷积神经网络结构从图像中自动提取特征。但不同于一般的CNN 分类模型。在卷积层后使用全连接层生成固定长度的特征向量,这里结合了注意力机制的思想,直接使用网络中最后一个卷积层产生的特征,通过这种处理,可以生成一组卷积特征向量,其中每个特征向量都对应一个特定的视觉感受域(receptive field),进一步则对应图像空间中的特定区域。因此,通过注意力模型,后续的解码器部分可以基于此空间信息关注图像的最相关部分,这一过程也模拟了人眼对于图像的观察行为[13-14]。
如图1,给定含有文字的输入图像,编码器将生成一组特征向量:
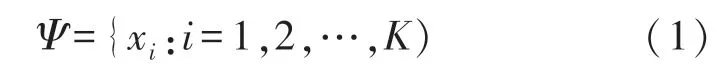
式中:xi代表对应图像第i个区域的特征向量,本质上,每个xi都是由一部分图像空间信息经过卷积层特征映射生成。
2.2 视觉注意力模型
自然语言处理中的注意力机制可分为软注意力(soft attention)与硬注意力(hard attention)两类。类比到铭牌识别领域,硬注意力机制会使解码器根据注意力值大小只关注具有最大值的部分,软注意力机制则会取若干个区域加权平均后由解码器处理[15-16]。考虑到含文字图像的特性,在区域划分细粒度程度高的情况下,字符跨越多个空间单元是普遍现象,因此基于软注意力机制的处理更为合理,即通过注意力权值组合对应不同空间区域的多个特征向量。
如图1,视觉注意力模型在每个时间步上都生成向量zt,该值将作为LSTM 解码器的输入特征。zt可以表示为式(1)中向量组Ψ的加权组合,即
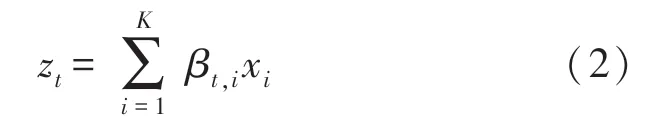
式中:βt,i为权值,且在每个时间步t,有

因此,向量zt实际上编码了图像各区域的相对重要性信息,该信息反映了某个区域对于文字识别结果的贡献程度。βt,i可以简单地通过一个全连接神经网络(其输入-输出映射记为f)连接softmax 分类器获得。具体地,首先将编码器的特征向量xi与前一个时间步LSTM 解码器的隐状态向量ht-1输入全连接网络得到

再经过softmax 函数得到
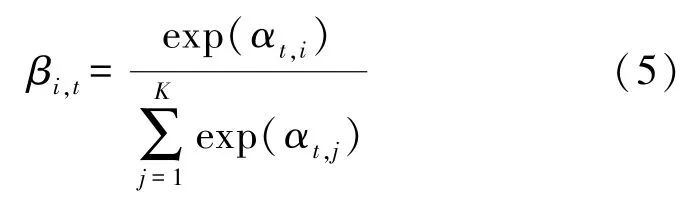
容易验证式(5)得到的注意力权值满足式(3)规定的归一化条件。
2.3 解码器
解码器部分基于长短时记忆网络,在每个时间步输出给定字符集L中的一个字符。实际上,解码器的输出格式是一个|L|维的向量,每个维度上的值代表实际字符是该字符的概率。输出向量依赖于注意力向量zt,前一时间步解码器的隐状态ht-1与输出向量yt-1,其依赖关系用矩阵形式可以表示为

式中:T和E都是一个由网络训练得到的权值矩阵/向量,it,ft,ot与gt则是LSTM 神经元中输入门(input),遗忘门(forget),输出门(output)与记忆门(memory) 部分的参数[17]。σ与tanh 分别代表sigmoid 与双曲正切激活函数。最终的输出概率为
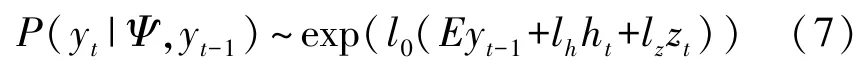
这里的l0,lh以及lz都是预先设置的重要性参数,也可通过网络训练得到。
3 模型推断
本文使用集束搜索(beam search)技术[18-19]从LSTM 解码器输出上推断识别结果,并结合语言模型进行优化。
3.1 集束搜索
模型训练完成后,集束搜索在每个可能的词汇w=[c1,…,cn]上最大化如下的目标函数

式中:ci表示组成词的各个字符,特别地,使用cn代表终止符(不代表任何具体字符),当推断过程执行到该字符时立即结束。
式(8)的形式与语言模型中由词汇前向生成文本的形式是相似的,这说明可以引入语言模型的思想对集束搜索过程进行一定改进。
3.2 语言模型的引入
文本通过语法和语义形成上下文关系,这意味着对于铭牌识别这类任务,文本本身的这一特征对模型输出构成一定的约束条件,利用这些条件对于改进识别效果是有益的。尽管LSTM 模型自身可以隐式学习连续字符之间的某些潜在上下文结构,但依然可以基于先验知识,显式添加较长的依赖关系。
本文使用最基本的n-gram 语言模型来反映这类关系。n-gram 中假设了任意字符的概率依赖于之前的n个字符,即

式中:#(c1c2…cn-1)表示序列c1c2…cn-1出现的频数[20]。将这一假设引入集束搜索,式(8)变为
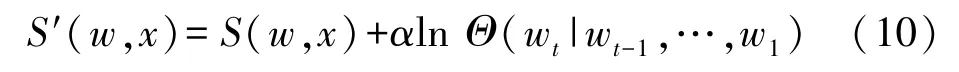
这里α是一个控制权重的参数。显然,与式(8)相比,式(10)添加了一个用n-gram 模型反映当前词上下文依赖的约束项。
4 实验与讨论
4.1 实验环境设置
实验中使用的数据集是包含14 万张图片的真实电表铭牌数据集,部分样本如图2。图片在光照、清晰度、倾斜程度等各方面都具有较高的多样性,便于评价识别模型的鲁棒性。实验中使用SSD 目标检测模型先分割出铭牌图像中含文字的大致区域,再基于本文模型进行具体的文字内容提取。

图2 实验数据集中的部分样本图片
实验中的卷积网络与LSTM 网络给基于开源深度学习库PyTorch[21]搭建,运行在一台搭载了两块NVIDIA GTX 2080Ti 图形处理器的计算机上。图1中编码器部分的CNN 模型由四层卷积层与一个全连接层组成,最后一个卷积层的输出作为编码器输出特征。CNN 的特征图(feature map)大小为4×13,LSTM 解码器的输入为52×512。式(10)中控制上下文依赖的参数α 设置为0.3。实验中采用的评价指标为精确度,即正确识别出的字符数与总字符数之比。
4.2 实验结果
本文实验首先验证了注意力模型、语言模型与预设字典对识别效果的提升,结果见表1。其中Att表示视觉注意力模型,LM 表示语言模型,n-gram 中的n值取3。

表1 模型优化过程
显然,视觉注意力模型、语言模型与预设词典的引入对于模型在铭牌识别任务上的提升都具有一定的意义。本质上,这些步骤都代表先验知识的增加。其中,视觉注意力模型对于模型性能提升的效果最为显著,而预设词典的增益效果则最不明显,这也说明本文方法在实际应用中无需预先建立大规模词典。
表2 将本文方法与其他主流模型进行了比较,结论是一致的:视觉注意力模型与语言模型的引入对于铭牌识别模型提升效果十分可观。表中HMM指隐马尔可夫模型(Hidden Markov Model,HMM)。
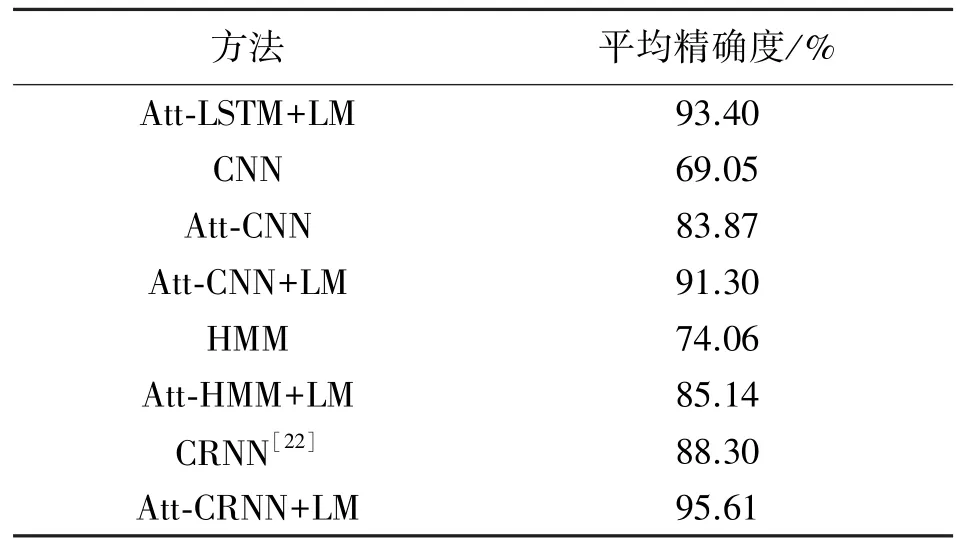
表2 模型性能比较
5 结束语
针对电表等电力设备的铭牌文本内容识别问题,本文提出了一组基于视觉注意力模型的识别技术。在这一问题上,本文方法的主要创新点包括:
(1)相比一般的基于卷积神经网络的方法,本文将自然语言处理领域中常用的注意力机制引入铭牌识别这一视觉问题,通过注意力权值使模型中的解码器重点处理与识别结果关系更紧密的图像区域,提升识别准确度,同时理论上也能提升模型处理的效率;
(2)将语言模型引入了铭牌识别任务中:通过n-gram 语言模型显式地将文本上下文依赖关系作为铭牌识别的约束条件,实验结果证明,这一处理进一步提升了模型识别效果;
(3)通过实验验证了本文方法对于预设词典的依赖性较低,这克服了许多传统方法的一大局限性,同时也说明本文方法具有更高的鲁棒性与更广泛的适用场景。
本文的后期研究包括引入更高阶的语言模型,如目前流行的各类预训练模型和图网络,将更复杂的上下文结构引入铭牌识别任务中。
