基于手工特征的视频哈希研究综述
2022-10-19于梦竹唐振军
于梦竹, 唐振军
(广西多源信息挖掘与安全重点实验室(广西师范大学), 广西 桂林 541004)
视觉信息是人类获取外界信息的一个最重要途径,其中视频是主要的视觉信息来源之一。互联网时代,人们越来越喜欢用视频记录生活,并利用社交平台发布和分享视频。在抖音、快手、YouTube、爱奇艺、腾讯视频、优酷等视频服务平台,每天都有大量用户上传数以万计的视频数据,这给海量视频数据的存储和管理带来巨大挑战,迫切需要研究快速视频处理技术,如视频索引和视频检索等。另一方面,VideoStudio和iMovie等功能强大且界面友好的视频编辑软件出现,使得视频的编辑操作变得日益简便,但也为视频内容的篡改和伪造等侵权行为提供了方便。因此,视频的版权保护和完整性认证成为另一个挑战性问题。例如,视频服务网站迫切需要高效的视频拷贝检测技术,以确保用户上传的视频不侵犯版权。
视频哈希是从视频中提取到的基于视觉内容的短小数字序列。在实际应用中,用视频哈希来表示视频,能降低视频的存储代价和视频相似计算的复杂度。目前,视频哈希已被广泛应用于拷贝检测、篡改取证、视频索引、视频检索等方面。通常,视频哈希仅与视频视觉内容有关,与视频的具体存储比特无关,这是视频哈希算法与传统密码学哈希算法的一个重要区别。对于MD5和SHA-1等密码学哈希算法,它们也可以将任意输入数据映射成一个短小数字序列,但它们对输入数据变化敏感,即使是1 bit不同都会完全改变输出的哈希值,因此不适用于视频数据的识别和内容认证。在实际应用中,由于视频会经历格式转换和压缩等内容保留处理,这些处理只改变视频的具体存储比特,但不改变其视觉内容,因此视频哈希算法需要满足的第1个性能是鲁棒性,即视频哈希算法必须对压缩、噪声干扰、亮度调整、格式转换等内容保留操作具有稳健性。换言之,对于内容相似的视频,即使它们的具体存储比特不同,视频哈希算法应输出完全相同或十分相似的哈希值。视频哈希算法的第2个基本性能是唯一性,即对于不同内容的视频,视频哈希算法输出相同或相似哈希值的概率很低。通常,鲁棒性和唯一性存在相互制约关系,一方面性能的提高往往会导致另一方面性能的下降。发展兼顾两者性能的高效视频哈希算法是当前研究的一个重要任务。此外,面向一些具体应用场景的视频哈希算法还有额外的性能要求。例如,用于内容取证时,视频哈希算法应具有安全性,即哈希值必须用密钥加密,以提高哈希系统的安全性能。常见的安全性策略有2种:一种策略是在特征提取阶段,用随机分块等技术来选择图像帧内容,通过随机提取特征来确保哈希值的安全性,由于随机选取特征会出现图像帧重要内容被忽略的情况,因此算法唯一性往往会略为下降;另一种策略是在哈希生成阶段,用密码学技术对特征进行置乱或异或等加密处理,通常,该策略不会影响唯一性,但安全性略低于第一种策略。
视频哈希算法和图像哈希算法同属于视觉哈希算法研究范畴,两者的起源[1]可追溯到20世纪90年代中后期,但视频哈希算法[2]的研究进展略慢于图像哈希算法[3-4]。当前,视频哈希算法被广泛应用于视频识别、拷贝检测、防伪取证等方面[5-6],吸引了多媒体和机器学习等领域的大量研究人员。通常,视频哈希算法包含特征提取和特征压缩编码2个主要步骤。在过去10多年,针对视频数据特点,研究人员设计和开发了许多手工特征提取技术,并建立一系列有效的视频哈希算法。近年,受到深度学习的启发,一些研究人员开始探索利用深度神经网络来实现视频特征的自动提取,以建立新的视频哈希技术。图1是代表性视频哈希算法的时间线,本文主要介绍和分析其中基于手工特征的视频哈希算法研究成果。从技术角度而言,手工特征既可单独从空域提取,也可以单独从时域提取,还可以联合时空域提取。当前,基于手工特征的视频哈希算法研究主要集中在空域特征提取和时空域特征提取,单独用时域特征构造哈希算法的研究相对较少。因此,本文将基于手工特征的视频哈希算法分为基于空域计算的哈希算法和基于时空域计算的哈希算法2个大类,其中基于空域计算的哈希算法又可分为逐帧计算和关键帧计算2类,基于时空域计算的哈希算法可划分为正交变换、统计特征、视觉特征点、数据降维和其他技术等5类。
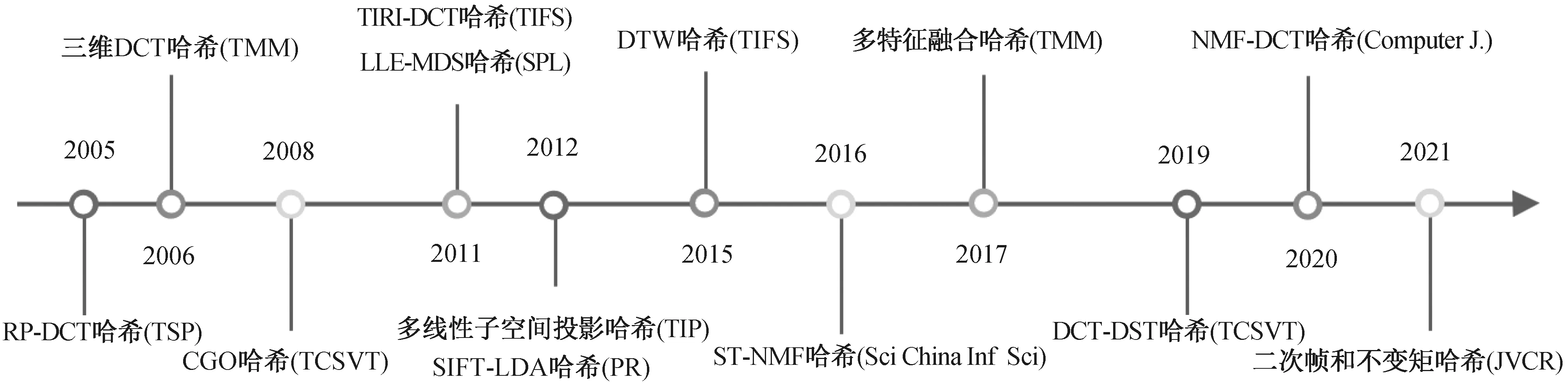
图1 代表性视频哈希算法的时间线Fig.1 Timeline of some representative video hashing algorithms
本文后续内容安排如下:第1章介绍和分析基于空域计算的视频哈希算法研究进展并总结其性能;第2章介绍和分析基于时空域计算的视频哈希算法研究进展并总结其性能;第3章介绍常见的视频哈希度量方法;第4章介绍视频哈希性能评价指标;第5章总结视频哈希研究的常用数据集;第6章展望未来研究工作。
1 基于空域计算的视频哈希算法
基于空域计算的视频哈希算法主要利用视频的每一帧或关键帧的像素特征来构造哈希。通常,该类算法将视频看作一组图像帧,使用图像哈希技术从图像帧中提取哈希值。该类算法能有效提取视频的帧内信息,但忽略了帧间信息,因此唯一性往往受到限制。根据图像帧的处理方式不同,该类算法可分为基于逐帧计算的哈希算法和基于关键帧计算的哈希算法2类。下面将对这2类算法进行介绍。
1.1 基于逐帧计算的哈希算法
该类算法将视频的每一帧看作一幅图像,然后将图像哈希技术直接应用于每一帧,最后联合每帧的特征生成哈希值。该类算法较好地保留了所有图像帧的像素信息,但逐帧计算带来较高的时间复杂度,并且哈希序列往往较长。下面介绍该类算法的一些代表性成果。
在早期的研究中,Mucedero等[7]提出利用亮度方差及坐标来设计视频哈希算法。该算法先对视频进行预处理,提取每一帧的亮度分量并通过重采样和低通滤波得到标准帧,然后逐帧计算基于分块的像素方差矩阵,并找到每块的最小值,最后通过记录最小值及其位置来构造哈希序列。该算法可有效识别经过MPEG-2或MPEG-4压缩的视频。Lee等[8]提出一种基于梯度方向质心(centroid of gradient orientations,CGO)的视频哈希算法。考虑到CGO特征能够抵抗亮度、颜色和对比度的变化,该算法对预处理后的标准帧进行非重叠分块,然后计算每块的CGO特征,用于生成每帧的特征向量,最后串联所有帧的特征向量来构成哈希序列。该算法对压缩和帧率变化等操作具有鲁棒性,但对剪切和旋转操作存在局限性。
Yang等[9]提出一种基于SURF(speeded up robust feature)和Hilbert曲线的视频哈希算法,并应用于视频拷贝检测。该算法先逐帧应用SURF提取局部特征点,提取过程如下:设p(x,y)是视频帧的一个点,那么它在尺度σ下的Hessian矩阵定义为
(1)
式中Lxx(p,σ)、Lxy(p,σ)和Lyy(p,σ)是视频帧与相应高斯二阶导数在p处的卷积。设卷积的近似值表示为Dxx、Dxy和Dyy,得到H矩阵的判别式为
(2)
通过Det(H)计算出Hessian矩阵的行列式最大值,并与所有相邻点进行比较,用来遴选稳定SURF特征点。然后,将每一帧划分成大小相同的非重叠块并统计出每块的稳定SURF特征点个数。接着,按照Hilbert曲线的顺序遍历每块,并根据曲线上SURF特征点的数量来生成哈希序列。该算法可抵抗图像帧的水平翻转等多种攻击,但唯一性有待提高。
Peng等[10]设计了一种多模型哈希算法。在预处理阶段,先以固定采样率对每帧进行重采样,再转换成灰度帧并调整为固定大小,然后逐帧提取视频序列的全局特征和局部特征,其中全局特征利用金字塔梯度方向直方图(pyramid histogram of oriented gradients,PHOG)提取,局部特征通过SIFT(scale invariant features transform)特征点构造,最后利用哈希函数将全局特征和局部特征映射到二进制哈希序列。该算法具有较好的鲁棒性,可有效应用于视频拷贝检测。
Himeur等[11]提出一种联合纹理描述符和颜色描述符的视频哈希算法。首先,去除所有帧的边框,只保留视频的重要内容,然后利用二值化图像统计特征(binarized statistical image features,BSIF),将每帧转换到BSIF域。受到Tang等[12]启发,为了抵抗旋转和翻转攻击,将BSIF图像分割成不同的圆环,利用圆环构造BSIF直方图,接着将不同环的BSIF直方图进行拼接,得到表示帧内容的特征向量,之后串联每帧的特征向量得到纹理描述符。对于颜色描述符,将BSIF图像进行非重叠分块,计算每块的色度直方图。最后,联合纹理描述符和颜色描述符构成哈希序列。在另一项工作中,Himeur等[13]设计了一种新的哈希算法,该算法采用相同的基于环分解的BSIF技术并联合不变颜色特征(invariant color descriptor,ICD),进一步提高了对旋转和翻转等几何攻击的鲁棒性,但唯一性并没有提升。
Sun等[14]提出一种基于Contourlet域的隐马尔可夫树(hidden Markov tree,HMT)模型和奇异值分解(singular value decomposition,SVD)的视频哈希算法。在预处理阶段,该算法通过平滑和重采样将输入视频转换为标准视频,接着逐帧应用Contourlet HMT模型,捕捉所有Contourlet系数在尺度、方向和位置上的相关性,实现对压缩、加性噪声、滤波等常见操作的鲁棒性,最后运用SVD对系数矩阵进行压缩,生成紧凑的哈希序列。该算法的鲁棒性能优于基于CGO的视频哈希算法[8]。
Chen等[15]提出基于低秩稀疏分解(low-rank and spare decomposition,LRSD)和离散小波变换(discrete wavelet transformation,DWT)的视频哈希算法。该算法先对输入视频进行预处理,使用时空域双重下采样操作确保输出哈希的长度相同,再利用Logistic 映射置乱视频序列来提高安全性,接着对每个视频帧应用LRSD。对于一个视频帧X,LRSD可得到一个低秩分量L和一个稀疏分量K,公式为
(3)
式中‖·‖0表示L0范数,λ是平衡系数。由于低秩分量包含视频帧的基本内容,因此该算法选择视频帧的低秩分量作为特征矩阵。最后,对每个特征矩阵应用二维DWT,计算低频子带系数的平均值并将其量化,生成二值哈希序列。该算法可抵抗MPEG-4压缩、高斯低通滤波和小角度的帧旋转。
表1列出基于逐帧计算的代表性哈希算法的发表年份和主要技术。表2总结了这些代表性算法的鲁棒性和安全性。由于该类哈希算法忽略了帧间信息,因此它们对帧间操作并不稳健,很少讨论帧平移和帧丢弃等性能。此外,该类算法普遍能够抵抗压缩和旋转等操作,但很少考虑安全性。

表1 基于逐帧计算的代表性哈希算法

表2 基于逐帧计算的代表性哈希算法的鲁棒性和安全性
1.2 基于关键帧计算的哈希算法
该类算法将视频分割成多个镜头,每个镜头由多个时间连续且内容相似的视频帧组成,然后从每个镜头提取代表性的帧作为关键帧,接着运用图像哈希技术提取每个镜头关键帧的哈希值,最后串联每个关键帧的哈希值构成整个视频的哈希序列。与基于逐帧计算的哈希算法相比,该类算法在降低计算复杂度的同时能较好地兼顾鲁棒性和唯一性。下面介绍该类算法的一些代表性成果。
一项早期的经典工作是Roover等[16]提出的基于径向投影(radial projections,RP)和离散余弦变换(discrete cosine transform,DCT)的视频哈希算法。该算法先使用RP和DWT技术构造图像哈希算法,简称为RASH,然后将RASH应用于每个关键帧,从而得到视频哈希。具体而言,RASH先计算图像像素的径向投影,再提取每个投影的方差,构造出一个RP方差向量,然后对方差向量应用DCT,对40个低频DCT系数进行量化得到图像哈希序列。在关键帧选取方面,先利用镜头边界检测方法分割视频,对于每组连续帧,选择局部差异最小的帧作为关键帧,这种关键帧提取方法可以抵抗轻微的几何变换。由于RP的计算成本较高且每个关键帧的哈希序列需要单独计算,因此该算法的时间复杂度很高。
Nie等[17]提出基于局部线性嵌入(locally linear embedding,LLE)的视频哈希算法。LLE是一种非线性降维方法,利用LLE进行数据降维分构造权重矩阵和计算低维嵌入向量2个步骤。权重矩阵W可通过xi的最邻近点线性重构实现,重构误差可由函数ε计算得到,公式为
(4)
式中Wij是xi和xj的权重。得到权重矩阵后,将每个高维向量xi映射成一个低维向量yi,可通过最小化代价函数Ω来实现,公式为
(5)
在关键帧选择阶段,该算法采用视频层析成像方法对输入视频进行镜头分割,利用均匀随机向量选取每组镜头的关键帧。在特征提取阶段,对每个关键帧进行8×8大小的非重叠分块,提取每个DCT块的亮度直流系数,串联所有DCT直流系数得到表示关键帧的高维特征向量,将所有关键帧的特征向量进行排列,得到一个高维特征矩阵。最后,将LLE应用于特征矩阵,实现把高维空间的特征向量映射到三维空间,对三维的特征向量进行量化得到二进制哈希序列。在另一项工作中,Nie等[18]提出基于等距特征映射(isometric mapping,Isomap)的视频哈希算法。该算法将输入视频进行预处理,通过重采样和缩放得到标准视频。为了降低计算复杂度,采用视频层析成像方法进行视频镜头分割,并在每组镜头中均匀选取20%的帧作为关键帧。最后,将关键帧的亮度分量看作高维数据并运用Isomap将其映射成三维空间的点,通过计算点与点的距离来生成哈希序列。该算法可以有效抵抗高斯白噪声和帧率变化,但对帧旋转的稳健性有待提高。
Kim等[19]设计基于区域二值模式(region binary patterns,RBP)的视频哈希算法。该算法先利用镜头边缘检测方法分割视频,提取每个镜头的中心帧作为关键帧并将其调整为固定大小;然后利用环分割将关键帧分成若干个环,对于每个环,再分割成6个子区域,通过比较相邻子区域之间的平均亮度,分别从单个圆环和相邻环之间提取2个互补的RBP特征;接着,把可以通过翻转和旋转重合的RBP分为一组并建立索引;最后串联所有索引生成哈希序列。该算法对视频旋转和翻转等攻击具有良好的鲁棒性,可应用于视频拷贝检测。Neelima等[20]提出基于SIFT和SVD的视频哈希算法。在预处理阶段,该算法利用双线性插值将每帧调整为标准大小,同时检测图像帧是否经历旋转攻击,对于经历旋转攻击的帧,运用几何变换和裁剪对其进行复原,之后再进行高斯低通滤波。接着,对预处理后的视频进行镜头分割,选取每个镜头的中间帧作为关键帧。由于SIFT特征点对缩放、旋转和平移具有不变性,因此提取关键帧的SIFT特征点并将它们聚合到32个类。然后,根据聚类中心选取图像块并对每个块应用SVD,选取最大奇异值作为块特征,串联所有图像块的最大奇异值即可得到关键帧的特征序列。最后,用均值量化方法对特征序列进行处理,得到二进制序列。该算法对旋转和缩放等几何攻击具有鲁棒性,但唯一性有待提高。表3列出基于关键帧计算的代表性哈希算法的发表年份和主要技术。表4总结了这些代表性算法的鲁棒性和安全性。由表4可见,它们普遍对大角度旋转和帧丢弃操作鲁棒,但并未考虑安全性。

表3 基于关键帧计算的代表性哈希算法

表4 基于关键帧计算的代表性哈希算法的鲁棒性和安全性
2 基于时空域计算的视频哈希算法
视频是一个时间序列上的图像集合,时空信息在视频内容描述中起重要作用。基于时空域计算的视频哈希算法不仅考虑视频的空域信息,而且考虑时域特性。由于该类算法充分利用视频的帧内和帧间信息来构造哈希,因此其分类性能普遍优于基于空域计算的视频哈希算法,已成为当前视频哈希算法研究的一个主流方向。根据特征提取技术不同,该类算法又可分为基于正交变换的哈希算法、基于统计特征的哈希算法、基于视觉特征点的哈希算法、基于数据降维的哈希算法和其他技术5类。下面对这5类算法进行介绍。
2.1 基于正交变换的哈希算法
该类算法利用正交变换提取视频在时域和频域的系数,通过分析不同系数的频率分布和统计特征构造哈希。常见的正交变换包括三维DCT、极性余弦变换(polar cosine transform, PCT)和离散正弦变换(discrete sine transform,DST)等。下面介绍该类算法的一些代表性成果。
一项早期的经典工作是Coskun等[21]提出的基于三维 DCT的视频哈希算法。该算法先将视频转换为规格化视频,然后在亮度分量上应用三维DCT提取低频系数。由于低频系数主要反映视频的近似信息,因此其对滤波和压缩等攻击具有鲁棒性。最后,对低频系数排序并通过中位数进行量化,生成二进制哈希序列。此外,为了增加安全性,他们还给出另外一种哈希算法,通过将三维DCT替换为三维随机基数变换(random bases transform,RBT)来实现安全哈希提取。对于一个维度为L1×L2×L3的视频,它的三维RBT基函数公式为
(6)
式中:l1=1,…,L1,l2=1,…,L2,l3=1,…,L3;β是归一化项;θ是伪随机产生的频率。上述2种哈希算法均可抵抗时域变化,例如帧率改变和丢帧,同时也可抵抗MPEG-4压缩和对比度变化等空域操作,但是对小角度旋转敏感。在另一项工作中,Li[22]利用三维 DCT系数之间的能量关系来设计哈希算法。首先将视频帧序列进行分组,然后利用密钥从每个分组随机选择不同位置和宽度的正方形来构造若干个立方体,接着对这些立方体应用三维 DCT,最后利用立方体的中低频系数的能量大小关系构造二进制哈希序列。该算法对旋转、压缩和丢帧操作具有良好的鲁棒性,但对几何攻击不够稳定。

(7)
式中ω表示指数加权函数。显然,利用TIRI方法提取的代表帧包含时域信息和空域信息。在特征提取阶段,对每个代表帧进行重叠分块,每块应用二维 DCT,然后选择与直流系数相邻的第一个水平系数和第一个垂直系数作为特征。在哈希生成阶段,串联所有DCT系数构成特征向量并用中值对其量化,生成二进制哈希序列。TIRI-DCT哈希算法对噪声和丢帧等操作具有鲁棒性,与三维DCT哈希算法[21]进行比较,实现了更好的分类性能。在另一项工作中,Setyawan等[24]利用边缘方向直方图(edge orientation histogram,EOH)和DCT设计视频哈希算法。首先计算输入视频每一帧的EOH,然后对EOH的每个bin沿时间方向应用一维DCT提取时间信息,最后利用DCT系数构造哈希。该算法对亮度调整、MPEG压缩和丢帧等内容保留操作具有鲁棒性,并且对内容改变操作具有敏感性。
Tang等[25]提出基于时空极性余弦变换(spatial-temporal PCT,ST-PCT)的视频哈希算法。受到Coskun等[21]的三维DCT启发,他们将应用于图像的二维PCT扩展到视频数据,设计了ST-PCT哈希算法,进一步提高对几何变换的鲁棒性。对于一个维度为N1×N2×N3的视频M(ui,vj,wk),ST-PCT的定义为
(8)
式中[·]*表示共轭复数,Ψ(ui,vj)和L(wk,μ)分别是空域和时域的核函数。在预处理阶段,ST-PCT哈希算法将输入视频缩放到固定大小并提取亮度分量。在特征提取阶段, 利用ST-PCT从亮度分量提取几何时空特征,计算过程如下:在时域上对视频进行一维 DCT,得到低频系数组成的三维特征矩阵,然后在空域上对特征矩阵进行二维PCT,提取时空特征,最后将时空特征量化为一个二进制哈希序列。该算法对大角度旋转鲁棒,可以应用于视频检索。
Khelifi等[26]联合DCT和DST设计了一种视频哈希算法。设x(n)为一个信号(n=0,1,…,Z-1),那么信号x(n)的DCT定义为
(9)
x(n)的DST定义为
(10)
该算法首先提取输入视频的亮度分量并进行重采样;其次在水平、垂直和时间3个方向上分别应用三维差分亮度块均值(differential luminance block means,DLBM)得到3个三维数组,接着通过信号校准技术获得每个方向上的单个信号;然后利用DCT和DST计算所有DLBM三维数组中每个信号的归一化位移,生成3个二维归一化位移数组;最后串联归一化移位数组形成哈希序列。该算法使用基于分段的度量方法进行相似性测量,可以应用于视频认证和视频识别。
Tang等[27]运用非负矩阵分解(non-negative matrix factorization,NMF)和DCT技术设计了一种新的视频哈希算法。首先对输入视频进行预处理,通过时空域双重下采样生成规格化视频;然后将视频帧进行分组并利用随机分块策略提取帧数据;接着对帧数据应用二维DCT,选取DCT结果的第1行和第1列的系数来构造帧分组的特征矩阵;最后采用NMF对特征矩阵进行降维,从NMF系数矩阵中学习短小的特征码,通过串联所有分组的特征码生成哈希序列。该算法可有效抵抗MPEG-2压缩、随机丢帧和小角度旋转等操作。表5列出基于正交变换的代表性哈希算法的发表年份和主要技术。表6总结了这些代表性算法的鲁棒性和安全性。由表6可见,这些算法大多对压缩、模糊、亮度调整和帧丢弃等操作鲁棒,并且具有较好的安全性。

表5 基于正交变换的代表性哈希算法
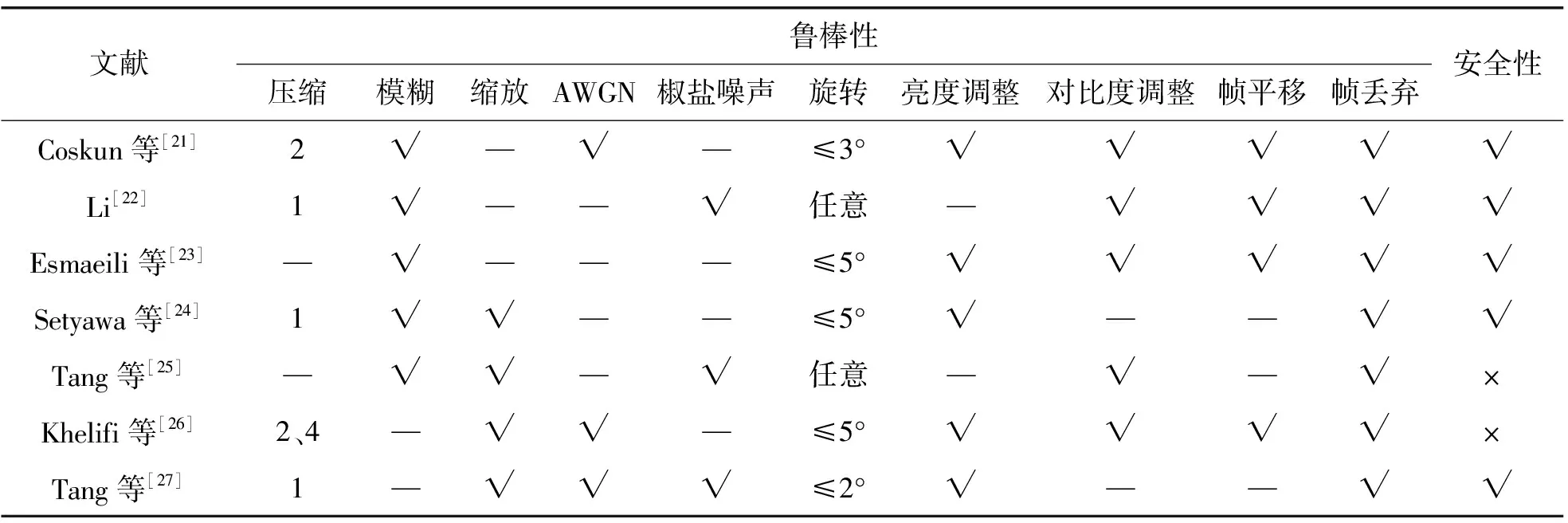
表6 基于正交变换的代表性哈希算法的鲁棒性和安全性
2.2 基于统计特征的哈希算法
该类算法通过计算时空域的统计信息来构造哈希,常见的统计特征包括均值、方差、高阶累积量、直方图和矩等。这些统计特征对常见内容保留操作攻击具有稳健性,因此基于统计特征的哈希算法通常对噪声和压缩等操作表现出良好的鲁棒性。下面介绍该类算法的一些代表性成果。
在早期研究中,Oostveen等[2]提出基于均值计算的视频哈希算法。该算法先对视频的每一帧进行非重叠分块,提取亮度分量并计算每块的平均亮度;其次将2×2的时空Haar滤波器应用于分块均值,计算块间和连续帧间的差值,有效地保留了时空信息;最后对滤波结果进行量化,得到二进制哈希序列。由于分块均值易受压缩、几何变换等操作的影响,因此该算法的鲁棒性并不理想。针对文献[2]的不足,Zhou等[28]在提取特征过程中引入一种新的相似性计算方法,利用帧的相似性来提取时空特征,从而提高算法的鲁棒性。
聂秀山等[29]提出基于拉普拉斯特征映射(Laplacian eigenmaps,LE)的视频哈希算法。LE是一种经典的流行学习方法,能够将高维空间的数据投影到低维空间,并且确保在低维空间尽可能保留局部样本点之间的结构不变。设图像I的样本点在低维空间的映射数据集为Y,在计算样本点的低维嵌入坐标时,LE算法通过目标函数
(11)
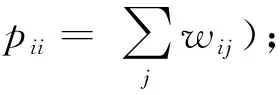
朱映映等[31]设计一种融合结构信息和时域信息的视频哈希算法。该算法先将输入视频转化为灰度视频,并对视频帧进行随机重叠分块,然后通过计算帧内块的亮度均值差得到结构特征,同时通过计算帧间块的亮度均值差得到时域特征,接着将这些特征量化为比特序列,最后联合结构特征序列和时域特征序列构成最终的哈希序列。在另一项工作中,文振焜等[32]同样利用分块亮度均值来构造时域特征和空域特征。上述2种基于分块亮度均值的哈希算法具有较好的鲁棒性,但是由于交换块内像素不会改变块均值,因此它们难以检测局部小范围的内容篡改,安全性有待提高。
Tang等[33]提出基于二次帧和不变矩的视频哈希算法,包括预处理、二次帧构造和不变矩提取3个阶段。在预处理阶段,对输入视频进行时空域双重下采样和颜色空间转换。在二次帧构造阶段,对预处理后的视频进行分组,将三维DWT应用于每组,利用LLL子带的DWT系数构造二次帧。由于LLL子带的DWT系数受噪声和压缩等操作的影响较小,因此二次帧构造不仅实现初步的数据压缩,而且提高了哈希的鲁棒性。在不变矩提取阶段,提取二次帧的Hu矩作为视频帧特征。Hu矩是一种经典的图像不变矩,对平移、旋转和缩放等几何变换具有不变性。通常,Hu矩由7个不变矩组成,定义如下:
v1=η20+η02;
(12)
(13)
v3=(η30-3η12)2+(3η21-η03)2;
(14)
v4=(η30+η12)2+(η21+η03)2;
(15)
v5=(η30-3η12)(η30+η12)[(η30+η12)2-3(η21+η03)2]+
(3η21-η03)(η21+η03)[3(η30+η12)2-(η21+η03)2];
(16)
v6=(η20-η02)[(η30+η12)2-(η21+η03)2]+4η11(η30+η12)(η21+η03);
(17)
v7=(3η21-η03)(η30+η12)[(η30+η12)2-3(η21+η03)2]-
(η30-3η12)(η21+η03)[3(η30+η12)2-(η21+η03)2]。
(18)
式中ηzq(z,q=0,1,2, …)是归一化中心矩。最后,串联所有二次帧的不变矩,并对它们进行量化得到十进制哈希序列。该哈希算法的分类性能优于文献[15]和文献[24]的哈希算法。表7列出基于统计特征的代表性哈希算法的发表年份和主要技术。表8总结了这些代表性算法的鲁棒性和安全性。由表8可见,这些算法普遍可以抵抗压缩、缩放、帧平移和帧丢弃等操作,但很少考虑安全性。

表7 基于统计特征的代表性哈希算法

表8 基于统计特征的代表性哈希算法的鲁棒性和安全性
2.3 基于视觉特征点的哈希算法
该类算法主要通过提取视频在空域和时域的视觉特征点来构造视频哈希。由于视觉特征点在视频经历内容保留操作之后仍然保持不变,因此用稳健视觉特征点构造的哈希算法具有较强的鲁棒性。视频哈希算法研究常用的视觉特征点提取技术包括Harris角点检测器和SIFT 特征点等。
Zhao等[34]提出基于时空兴趣点的视频哈希算法。该算法先使用Harris角点检测器提取每帧的特征点,然后建立帧间的特征点轨迹,接着选择其中的时空持久点(persistent points),把每个持久点周围区域的差分作为视频的局部特征,最后使用Hilbert曲线来降低特征维度生成哈希序列。由于该算法建立在时域轨迹基础上,因此对插入帧或丢帧等时域操作具有稳健性,并取得较好的视频拷贝检测性能。在另一项工作中,Li等[35]提出基于时空显著点的视频哈希算法。该算法先用预处理将输入视频转换为规格化视频,然后利用镜头边界检测方法分割视频并生成3个代表帧,接着利用Harris角点检测器提取空间候选点。设I(x,y)为视频帧的一个像素点,Harris算子的表达式为
(19)
其泰勒展开式为
E(x,y)≈[x,y]M[x,y]T。
(20)
式中M为近似形式的矩阵,
(21)
式中:G(Δx,Δy)为高斯滤波器;Ix和Iy分别为图像x和y方向的梯度值。设ρ1和ρ2是矩阵M的2个特征值,特征点的响应函数定义为
(22)
式中:det(M)=ρ1ρ2;trace(M)=ρ1+ρ2;ξ是经验常数。利用Harris算子提取出空间候选点后,对它们进行排序生成每个关键帧的候选点,最后利用运动估计法在候选点中筛选出对时间变化稳定的点,并用它们构成哈希序列。该算法利用时空兴趣点实现对几何攻击的鲁棒性,但计算复杂度较高。
Vretos等[36]提出基于SIFT和隐含狄利克雷分布(latent Dirichlet allocation,LDA)的视频哈希算法。该算法针对视频中出现的面部表情,提取潜在的视频主题,用于构造视频哈希。具体而言,先通过人脸检测器提取视频中的面部图像;然后利用SIFT特征点进行人脸聚类,提取面部图像的兴趣点和相应特征;接着在图像对之间寻找匹配的SIFT点对,并计算匹配特征向量的欧氏距离;其次利用距离和兴趣点的总数判断人脸是否属于同一个人,形成视频的潜在语义直方图;最后将整个视频数据库的人脸直方图作为LDA的输入,生成哈希序列。该算法需要事先对视频数据库进行训练,计算代价较大。
魏晖等[37]联合SIFT特征点、边缘检测和方向直方图构造视频哈希算法,包括3个取证组件:第1个组件是利用SIFT提取视频帧的特征点,用于估计几何变换;第2个组件是对视频逐帧应用Prewitt算子,提取每帧运动对象的能量边缘,用于检测运动对象的增加和删除;第3个组件利用边缘方向直方图计算图像分块的4个方向直方图,用于篡改定位检测。该算法以模块化方式实现视频取证,但仅适用于背景静止的视频,应用范围相对较窄。表9列出基于视觉特征点的代表性哈希算法的发表年份和主要技术。表10总结了这些代表性算法的鲁棒性和安全性。由表10可见,这些算法大部分能够抵抗压缩、模糊、缩放、对比度调整和帧丢弃等操作,但是很少考虑安全性。

表9 基于视觉特征点的代表性哈希算法
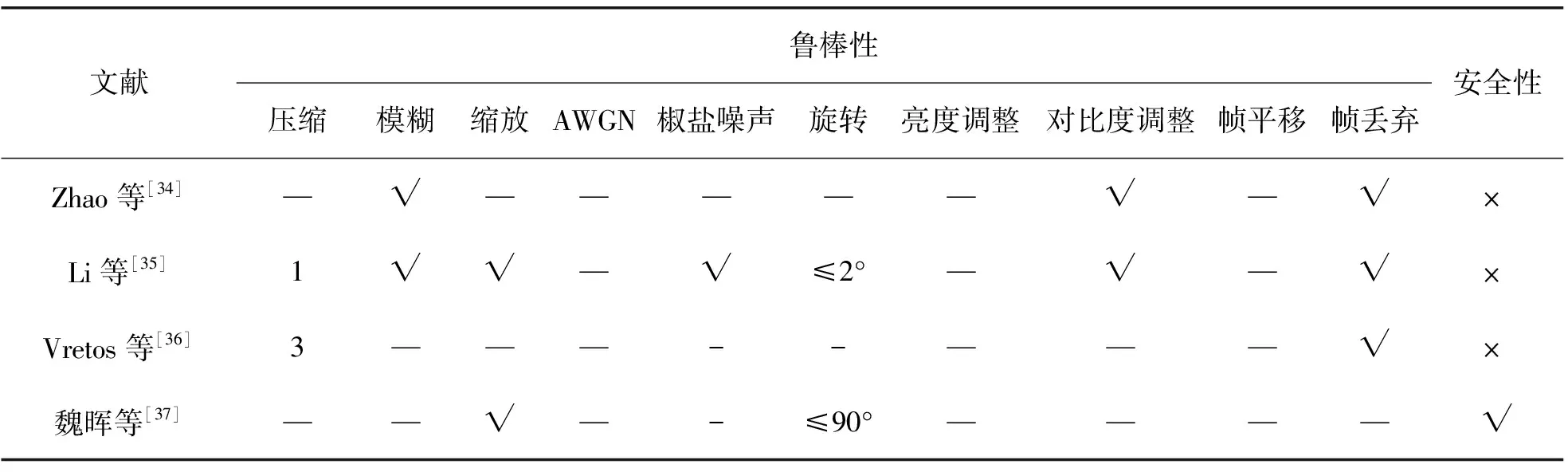
表10 基于视觉特征点的代表性哈希算法的鲁棒性和安全性
2.4 基于数据降维的哈希算法
该类算法将视频数据看作高维数据,通过数据降维技术将高维数据映射到低维空间,利用低维特征数据来构造哈希。视频哈希算法研究常用的数据降维技术包括LLE、多维尺度分析(multidimensional scaling,MDS)、张量分解、独立成分分析(independent component analysis,ICA)、NMF和SVD等。下面介绍该类算法的一些代表性成果。
Nie等[38]提出基于双层嵌入的视频哈希算法。该算法利用LLE和MDS将高维视频数据映射到低维空间,有效地保留视频的局部信息和全局信息。具体而言,首先,对输入视频进行重采样并映射成一个加权无向图,再通过图模型选取分散帧;其次,利用分散帧和k近邻方法对视频进行聚类,在类内应用LLE实现降维生成局部特征,在类间应用MDS实现第二级嵌入生成全局特征;最后,串联局部特征和全局特征构成哈希序列。该算法能够抵抗几何攻击,但唯一性有待提高。在另一项工作中,Tang等[39]联合使用MDS、DWT和序数测度(ordinal measures,OM)来设计一种新的视频哈希算法。该算法先通过时空域双重下采样操作生成固定大小视频,再将标准视频的颜色空间转换到HSI颜色空间,然后对视频进行分组,选取每组帧的平均值作为代表帧,接着对每个代表帧应用二维DWT,并在DWT低频子带上计算梯度特征来构造高维矩阵,最后利用MDS从高维矩阵中学习低维特征,运用OM对特征值进行量化生成哈希序列。该算法生成的哈希序列较短并且分类性能优于文献[15]和文献[24]的哈希算法。
Li等[40]提出基于多线性子空间投影的视频哈希算法。该算法先将输入视频进行预处理得到规格化视频,然后随机选择一系列重叠的子立方体,并确保这些立方体覆盖整个视频,其次对每个立方体应用平行因子分析(parallel factor analysis,PFA)进行张量分解得到3个特征矩阵,最后将特征矩阵串联成特征向量并量化为哈希序列。该算法不仅对模糊、压缩和小角度旋转等空域操作具有鲁棒性,而且对帧率变化和随机丢帧等时域攻击也表现出较好的稳健性。在另一项工作中,Nie等[41]也运用张量分解技术设计出一种基于多特征融合的视频哈希算法。该算法利用张量模型挖掘视频的综合特征,探索特征内部和特征之间的关系。具体而言,先将视频构造为高阶张量并使用Tucker分解视频张量。设X是一个三阶视频张量,Tucker分解的公式为
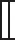
(23)
文振焜等[42]设计基于Gabor小波分解和ICA的视频哈希算法。ICA可从混合数据中提取出原始的独立信号,能有效实现噪声抑制。该算法通过宏块预测和补偿信息技术选取关键帧,对关键帧进行预处理得到标准关键帧;然后将每个标准关键帧进行非重叠分块,每块应用二维Gabor小波分解,用分解得到的低频系数构成关键帧的特征矩阵;接着将ICA应用于特征矩阵生成中间特征矩阵,对中间矩阵按行排序形成新的转置矩阵;最后对转置矩阵的列进行中位值量化生成哈希序列。该算法对噪声和亮度变化具有鲁棒性,但对旋转和拉普拉斯锐化等操作敏感。
受到Tang等[12]的环分割技术启发,Nie等[43]提出基于球形环(spherical torus,ST)和NMF的视频哈希算法。该算法先对视频进行规格化,然后将视频分割成一系列重叠的立方体,对于每个立方体,用球形环对立方体进行分割,通过球形环来捕获时空信息;接着用球形环像素来构造一幅时空图像,并采用NMF对时空图像进行降维,将NMF系数矩阵的列串联起来形成立方体哈希;最后连接所有立方体哈希得到最终哈希序列。ST-NMF哈希算法对模糊和噪声攻击具有鲁棒性,可用于近似重复视频的检测,但唯一性并不理想。
最近,Chen等[44]提出基于低秩帧的视频哈希算法。该算法由预处理、低秩帧计算和低秩帧压缩等3个阶段组成。在预处理阶段,先将彩色视频转换到YCbCr颜色空间,选取亮度分量表示视频,同时通过时空域双重采样操作将视频转为固定大小视频。在低秩帧计算阶段,对视频进行分组,从每个分组中提取出一个低秩帧来表示该分组。具体而言,将每一个帧逐行连接形成一个向量,于是每个分组对应一个高维矩阵,然后对高维矩阵应用SVD。设Q为一个高维矩阵,Q的SVD计算公式为
Q=USVT,
(24)
式中:S是由奇异值组成的实对角矩阵;U和V分别是Q的左奇异向量和右奇异向量。接着用较大的奇异值对高维矩阵进行低秩重建,最后根据重建结果来构造出低秩帧。由于较大的奇异值对内容保留操作具有稳健性,因此使用低秩帧进行哈希提取能提高鲁棒性。在低秩帧压缩阶段,将二维DWT应用于每个低秩帧,选取LL子带的系数均值作为特征并进行取整量化,最后串联所有低秩帧的量化特征生成哈希序列。该算法对MPEG压缩、随机丢帧和随机插入帧等操作有较好稳健性,分类性能优于ST-NMF哈希算法。表11列出基于数据降维的代表性哈希算法的发表年份和主要技术。表12总结了这些代表性算法的鲁棒性和安全性。由表12可见,这些算法普遍具有良好的鲁棒性,特别是能够抵抗旋转,但安全性有待提高。

表11 基于数据降维的代表性哈希算法

表12 基于数据降维的代表性哈希算法的鲁棒性和安全性
2.5 其他技术
除了上述4种类型的技术之外,其他一些技术也被用于视频哈希研究。例如,欧阳杰等[45]将Cortex变换引入视频哈希研究,设计出可反映人眼视觉系统特性的哈希算法。该算法先对视频进行预处理和随机重叠分块,然后将Cortex变换应用于每个分块,将其分解成直流分量和子带系数,最后结合子带系数构成时空域对比度敏感函数、子带内和子带间的对比度掩蔽函数,用于提取视觉感知特征。该算法利用Cortex变换和人眼视觉系统特性提高了感知鲁棒性。考虑到代表帧提取是视频哈希算法的一个重要步骤,Liu等[46]设计了一种加权计算技术,通过联合使用动态视觉注意模型和静态视觉注意模型来计算时域代表帧。用该技术构造的哈希算法对插入帧或丢帧等操作具有鲁棒性。在另一项工作中,Sun等[47]提出基于外观特征和注意力特征融合的视频哈希算法。该算法采用视觉注意力模型提取注意力特征,通过深度信念网络将注意力特征与视觉外观特征相结合生成哈希序列。该算法可有效抵抗高斯噪声、高斯模糊和中值过滤等攻击。考虑到检测时域攻击视频存在的时间同步困难问题,Li等[48]设计了一种基于2阶段计算的视频哈希算法。该算法用动态时间规整(dynamic time warping,DTW)方法实现视频同步,通过计算相邻代表帧来提取光流信息,然后运用光流方向直方图来构造哈希,最后利用距离增强策略从DTW信息和光流信息中获取互补信息,以提高对时域攻击的稳健性。由于光流计算的复杂度较高,因此该算法的运行时间较慢。
3 哈希度量方法
视频哈希的度量方法是通过计算2个视频哈希序列的差异来判断2个视频内容的相似程度。如果哈希序列的差异小,那么对应视频的相似程度就高;如果哈希序列的差异大,那么对应视频的相似程度就低。由于不同视频哈希算法提取出的哈希序列表示形式不同,因此不同哈希算法往往选择不同的度量方法。常用的视频哈希度量方法包括汉明距离、误码率和欧氏距离。设h1=[h1(1),h1(2),…,h1(γ)]和h2=[h2(1),h2(2),…,h2(γ)] 表示2个长度为γ的哈希序列,d(h1,h2)表示哈希序列h1和h2的度量方法。下面介绍这3种度量方式(相关文献见表13)。
1)汉明距离。它是通过计算2个哈希序列在相同位置上的不同比特数来判断序列差异。通常,较大的汉明距离表明2个视频的内容差异较大。反之,如果汉明距离越小,那么哈希序列对应的视频内容差异就越小。汉明距离的计算公式为
(25)
2)误码率。它可看作是归一化的汉明距离,主要通过计算2个哈希序列在相同位置上的不匹配比特的百分比来判断差异。通常,误码率越高说明2个视频的内容差异越大。反之,误码率越小说明2个视频的内容越相似。误码率的计算公式为
(26)
式中τ为2个哈希序列的不匹配比特的总数,且τ∈{0,1,2,…,γ}。
3)欧氏距离。它是通过计算2个哈希序列在相同位置上的十进制数差异来判断相似性。通常,较大的欧氏距离说明2个视频的内容差异较大。反之,欧氏距离越小说明2个视频的内容越相似。欧氏距离的计算公式为

(27)
4 性能评价指标
视频哈希算法的常用性能评价指标包括ROC(receiver operating characteristics)曲线和P-R(precision-recall)曲线等。下面介绍这2种常用评价指标的计算公式。
1)ROC曲线。该曲线主要用于分析视频哈希算法在鲁棒性和唯一性之间的分类性能。在 ROC 图中,x轴通常定义为错误接受率(false positive rate,FPR),y轴定义为正确接受率(true positive rate,TPR),具体定义如下:
(28)
(29)
由于 ROC 曲线是由许多坐标点(FPR,TPR)绘制而成,因此曲线越接近ROC 图的左上角说明对应哈希算法的分类性能越好。此外,为了进行定量分析,通常还使用AUC(ROC曲线面积)进一步评估分类性能。AUC的最小值为0,最大值为1。一般而言,AUC越大,哈希算法的分类性能越好。
2)P-R曲线。该曲线主要用于评估视频哈希算法的检索性能。在 P-R图中,x轴通常定义为召回率(Recall),y轴定义为精确率(Precision),具体定义如下:
(30)
(31)
由于 P-R曲线是由许多坐标点(Recall,Precision)绘制而成,因此曲线越接近P-R图的右上角说明对应视频哈希算法的检索性能越好。此外,还可以使用精确率和召回率的调和平均值,即F分数,来综合评估检索性能。F分数的最小值为0,最大值为1。一般而言,F分数越大,哈希算法的检索性能越好。
5 常用数据集
视频哈希算法研究常用的数据集包括TRECVID、ReefVid、CC_WEB_VIDEO和UCF101等,这些数据集包含不同类型的视频,可用于测试视频哈希算法的性能。TRECVID数据集最早于2003年发布,当前累积了大量视频,这些视频的类型众多,包括新闻杂志、科学新闻、新闻报道、纪录片、教育节目、档案视频、电视剧集和电影等。ReefVid数据集由1 000多个与珊瑚礁有关的视频组成。CC_WEB_VIDEO数据集由从YouTube、Google Video和Yahoo下载的12 790个视频组成,分为24个主题,主要用于视频拷贝检测评估。UCF101数据集由从YouTube下载的13 320个视频组成,分为101个人类行为类别,如运动、乐器和人物交互等,这些视频在摄像机运动、物体外观、视角、背景、照明条件等方面存在较大差异。表14总结了上述常用数据集的特点。
值得注意的是,为了验证哈希算法的鲁棒性,研究人员通常利用内容保留操作对数据集中的视频进行鲁棒攻击,以构造出相似视频库。常用的空域内容保留操作包括亮度调整、对比度调整、MPEG-2压缩、MPEG-4压缩、帧旋转、帧放缩、加性高斯白噪声、椒盐噪声、乘性噪声和高斯低通滤波等。常用的时域内容保留操作包括帧交换、帧插入、帧丢弃和帧率改变等。

表14 常用数据集的特点
6 展望
近年,视频哈希研究受到研究人员的广泛关注,一些重要研究成果陆续刊登在国内外重要学术期刊上,有效促进视频哈希研究的发展。当前,视频哈希研究仍然面临许多问题和挑战,下一步研究工作可重点关注如下几个方面:
1)面向篡改取证的视频哈希算法。随着DeepFace等换脸软件的出现,人脸视频的篡改操作日益便捷,社交网络上出现越来越多的伪造视频。针对人脸篡改等应用场景,设计具有篡改取证能力的哈希算法将是未来视频哈希研究的一个重点任务。
2)基于深度学习的高效视频哈希算法。近年,深度学习在图像分类和识别等方面取得巨大成功,一些研究人员尝试将卷积神经网络等深度学习技术引入视频哈希研究。然而,大部分深度神经网络存在模型参数众多、训练时间长等问题,因此需要针对视频数据特点,设计新型深度神经网络,以构造出高效哈希算法。此外,由于Transformer网络在多种视觉任务上表现出优异的性能并超越传统卷积神经网络,因此利用Transformer网络设计视频哈希算法将是未来研究的一个热点。
3)面向移动应用的轻量级视频哈希算法。移动计算设备的普及催生了大量的移动应用,由于这些设备的计算和存储能力有限,因此针对PC应用场景设计的视频哈希算法难以应用到移动终端。为此,迫切需要针对移动应用场景,设计轻量级的视频哈希算法。
