考虑语义距离的领域科学知识主题关联与演化研究*
2022-10-19何禄鑫杨艳妮
张 瑞 何禄鑫 杨艳妮
(1.湖北工业大学 经济与管理学院 武汉 430064;2.三峡大学 文学与传媒学院 宜昌 443002)
科学创新是引起世界发展变迁和人类生活进步的根本动力。科学每一次创新既是对原有科学理论和知识的继承,也意味着科学史上的进步与突破。人们基于已有的知识去创造新的知识,新旧知识的关联往往很密切。综合分析知识结构及不同知识间存在的关联,对揭示科学系统中的研究热点和学科领域发展趋势具有重要意义。在过去十年里,主题检测与挖掘的研究一直是一个活跃的研究领域,成为科学文献文本分析中的一项关键技术。不少学者运用各种主题建模处理不同领域的科学文献数据,将研究主题作为科学文献基本知识单元,如焦红等利用主题模型提取图书情报领域粗糙集主题,并绘制知识演化路径[1];李海峰利用结构话题模型获得中美两国数字孪生研究主题[2];GoEunHeo通过ACT(Auther-Conference-Topic)模型研究生物信息学的跨学科性质[3];等等。对科学知识进行主题层次的分析,往往与科学研究动态、影响评估以及知识扩散等研究密切相关[4]。
随着主题模型的广泛运用,另外一些研究对主题模型进行改进,以经典的LDA主题模型为例,Hassan拓展了LDA主题模型,提出带有距离矩阵主题模型来识别研究主题[5];伊惠芳等提出语境增强Context-LDA模型以增强模型的泛化能力[6]。无疑,主题模型在理解文本内容具有突出优势,是在文本挖掘和知识发现中起核心作用的学习任务之一。虽然过去的主题模型能反映主题、文档与单词之间的层级关系,不同的主题改进模型提高了聚类效率,但单词表达形式多样,建模过程中容易忽略了单词之间同属领域的语义信息,导致出现主题内容重复、边界模糊、不易解释的情况。为了克服主题建模过程中的局限性,提高主题表示能力,本文提出基于语义距离的主题相似度计算方式和规则,从知识体系上承载概念与概念间的关系,在此基础上结合实际科学文献数据操作,探究主题关联及演进路径。
1 相关研究工作
1.1 主题建模相关研究
主题建模在过去得到长足发展,主要包括基于规则和基于统计两种方式。基于规则的主题建模,是指根据人工制定相应的文本映射规则,这种方式虽然准确性高,但是对不同文本内容,存在规则可移植性差、鲁棒性不好等缺点[7]。比如,石倩雯等指出为更好检索文物信息,博物馆研究人员在文献标引工作中需十分重视主题标引语言和规则[8]。而基于统计的主题建模成为一种主流方法,研究人员所青睐的是该方式主要依赖于词频等统计信息建立主题模型,适用于大规模文档,简单实用且精度很高,但缺点是计算中假定每个单词只有一种含义,容易忽视文本内在逻辑结构[9]。黄晓斌等指出在主题模型中确认核心词是较大的难点,意义不强的词会影响分类效果[10]。Daud等也指出主题模型中文档之间呈现的单词忽略了语义内在结构,并将会议挖掘和专家发现作为优化机制,提出群组主题建模[11]。
如果一个主题的词汇间没有任何联系,则表现出随机性太强,凸显不出每个主题的区别和意义,在单一领域分析中的应用容易受到限制。因此,本文考虑既遵循一定的文本映射规则,又服从统计计算规律:在构建主题模型时,由具有知识规则的领域本体指导,以提高主题连贯性和一致性,使主题在语义上紧密地结合在一起。
1.2 主题关联与演化研究
科学知识主题关联是实现科学知识局部动态分析和演化发展的前提。王曰芬等利用主题在学科领域中的贡献关系构建主题-主题关联网络,并分析学科知识结构演化[12];赵蓉英等从共词网络的视角探究数据科学研究的主题关联结构与发展演化态势[13]。在不同的应用场景中,学者们提出一系列改进措施,Yang等认为很难捕捉到连贯性和具体性的主题表达,提出了基于关联的主题选择(ATS)模型[14]。张金柱等提出采用节点中心度和重要程度来改进主题关联算法[15]。常见的主题关联方法可归纳为四种[16]:直接关联法、相似度阈值法、距离阈值法以及最大相似度法。主题相似度较大表明主题研究有延续的可能,Gaul 等基于文本材料内容相似性处理主题之间关系网络,进而探究主题随时间的演变[17];Sun等通过LDA生成主题模型结果,使用余弦相似度计算主题间相似程度,超过预定义阈值视为相似并连接[18]。
关于主题相似度度量方式有许多,如交叉熵、余弦相似度、JS(Jensen-Shanon)散度、KL(Kullback-Leibler)散度等,这类方法的共性在于基于句法层面的词汇分布比较主题间的差异程度,因此较大程度取决于词汇频率。单从词汇频率来判别主题相关性,那很多含义类似词汇出现频率较低或者没有共现关系,容易忽略它们之间潜在关联性。本文将本体中概念节点之间的关系延伸到主题之间的关系,提出新的相似度规则以探寻主题间关联关系强弱,认为若一个主题与另一个主题相似度较大,则这两个主题是相关的,并对时间相邻窗口主题进行关联,进而探究主题的演化情况。
2 研究设计
2.1 科学知识主题获取与分析框架
科学知识主题获取和分析目的是通过从源文档集合中学习语义主题并揭示主题的关系。重点包括两项工作:通过主题强度来描述科学知识内容形态,其时间分布反映了不同类型的领域科学知识在不同时间下的活跃程度和受关注程度,体现领域知识结构体系的纵向变化;基于主题之间相似度建立时序上主题内容的关联,刻画主题自身属性随时间的演化过程,揭示科学知识发展情况。分析框架如图1所示。
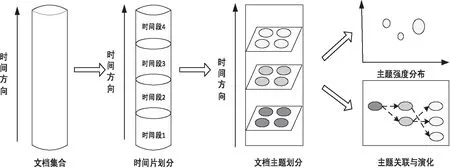
图1 分析框架
主题分布与主题演化体现了科学知识的稳定性和发展性,具体步骤如下:
(1)首先为明确领域知识结构,选取一个时间段的学科领域文档,并按不同时期划分文档,根据LDA主题模型横向划分每个时期下的主题,按照聚类结果标注主题标签。
(2)分析不同时期的主题强度分布。不同于文档数目可以直接统计,主题强度是一种抽象的变量,主题强度分布取决于文档属于该主题的概率、以及文档的数量,相同主题标签的主题强度有可能持平、上升或下降。
(3)分析不同时段下主题之间的对应关系。主题关联对象为时间呈前后关系的主题,考虑词汇之间的语义距离构建主题关联规则,分析不同时段下主题之间是否存在知识属性相同或类似,以确定主题延续情况。
(4)推演出领域主题的演化路径,根据路径结果判断领域主题发展状况。
2.2 考虑语义距离的主题关联规则
2.2.1规则构建方法
建立不同时间下的主题关联对明确领域知识变化意义重大。根据主题模型运算原理,在主题内部所呈现的主题词具有较强的语义关联,本文重点是解决不同主题之间的语义关联。主题模型计算结果是处理文档中文本噪音,将文档表示为主题的集合,每个主题由许多主题词组成,主题词之间并没有逻辑结构关系。主题间关联受到“词汇”与“词汇”之间关系影响,这种关系可以归纳为等同、属分、相关关系[19]。
词汇具有语义、语法、语用等基本属性[20],而词汇之间的关系主要取决于其语义属性。语义是一种主观性较强的概念,通常需要建立在人们对词汇理解的基础上。语义相似度(semantic similarity)的计算就是以词汇的这种主观概念属性为基础,将词汇之间的关系量化,并表现为具体数值。考虑语义距离的主题关联的基本思想是将主题层的相似度计算映射到词汇层中,将不同词汇在本体结构中路径距离解释和表示为语义距离(semantic distance),进行词汇与词汇之间的相似度计算,进而推导主题层的相似度关系。
现有两个主题,TopicA包含词汇知识为(Word1,Word2,Word3),TopicB包含词汇知识为(Word1',Word2',Word3'),如果领域本体中存在Word1隶属于Word1',则在主题层中TopicA和TopicB的关联关系需考虑词汇层中Word1和Word1'在知识本质属性中的承接关系(见图2)。
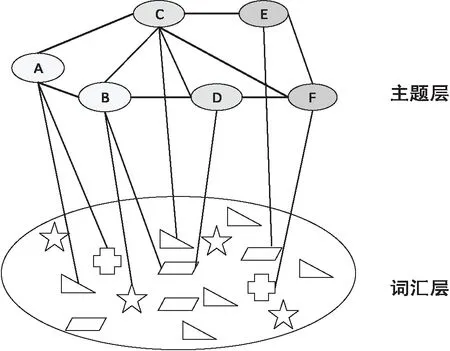
图2 主题层到词汇层映射关系
在语义距离的基础上计算相似度,对于两个主题词Word1,Word2,它们的相似度计算公式为[21]:
(1)
其中,Dis(Word1,Word2)表示词汇Word1,Word2在层级结构中的语义距离,语义距离越大,则词汇的相似度越小。
为了准确表达概念之间的语义相似度,需要领域本体中的“结构特征”描述词汇的语义。结合词汇的语义关系路径计算主题的相似度,构建计算规则。规则中,在词汇与词汇匹配、词汇与主题词匹配均使用了“最小原则”,目的是使不同词汇与同一目标匹配的异质化程度最大,进而提高计算结果显著性。
规则一:主题与主题之间的相似度由词汇与词汇之间的相似度决定。由于一个主题词有多个概念,每一个概念在本体的结构位置不一样,在这里取“最小原则”,两个主题词之间的距离取它们中概念距离最短的进行计算。
规则二:假设TopicA主题-词汇矩阵中,权重排名前n的词汇为(Word1,Word2,…,Wordn),TopicB主题-词汇矩阵中,权重排名前n的词汇为(Word1',Word2',…,Wordn'),则TopicA-TopicB之间的相似度表示为:
(2)
其中,Wordj'表示TopicA中的词Wordi。遍历TopicB中的词,遵循“最小原则”,寻找在TopicB中与Wordi距离最小的词为Wordi与TopicB的相似度,如此循环。所有TopicA中的词与TopicB相似度之和的平均数,得到TopicA-TopicB的相似度。
规则三:假设TopicA中的词Wordi在TopicB中的距离最短词汇为Wordj',但是Wordj'在TopicA中的距离最短词汇不一定是Wordi,则由此计算出的TopicB-TopicA相似度与TopicA-TopicB相似度值不一样,取平均处理,即TopicA与TopicB之间的相似度为:
SIM=
(3)
2.2.2简单示例
MeSH作为生命科学领域最常用的知识库,也是一个规模大、概念完备的领域本体库,建立了详细的概念属性及概念与概念之间的关系。以MeSH词表中的树状图来表征领域概念结构位置为例,基于MeSH词表计算语义距离:主题词之间连通路径的边权重相加。将边的权值简化处理,取值为1;主题词之间的路径长度越大,语义距离就越大。
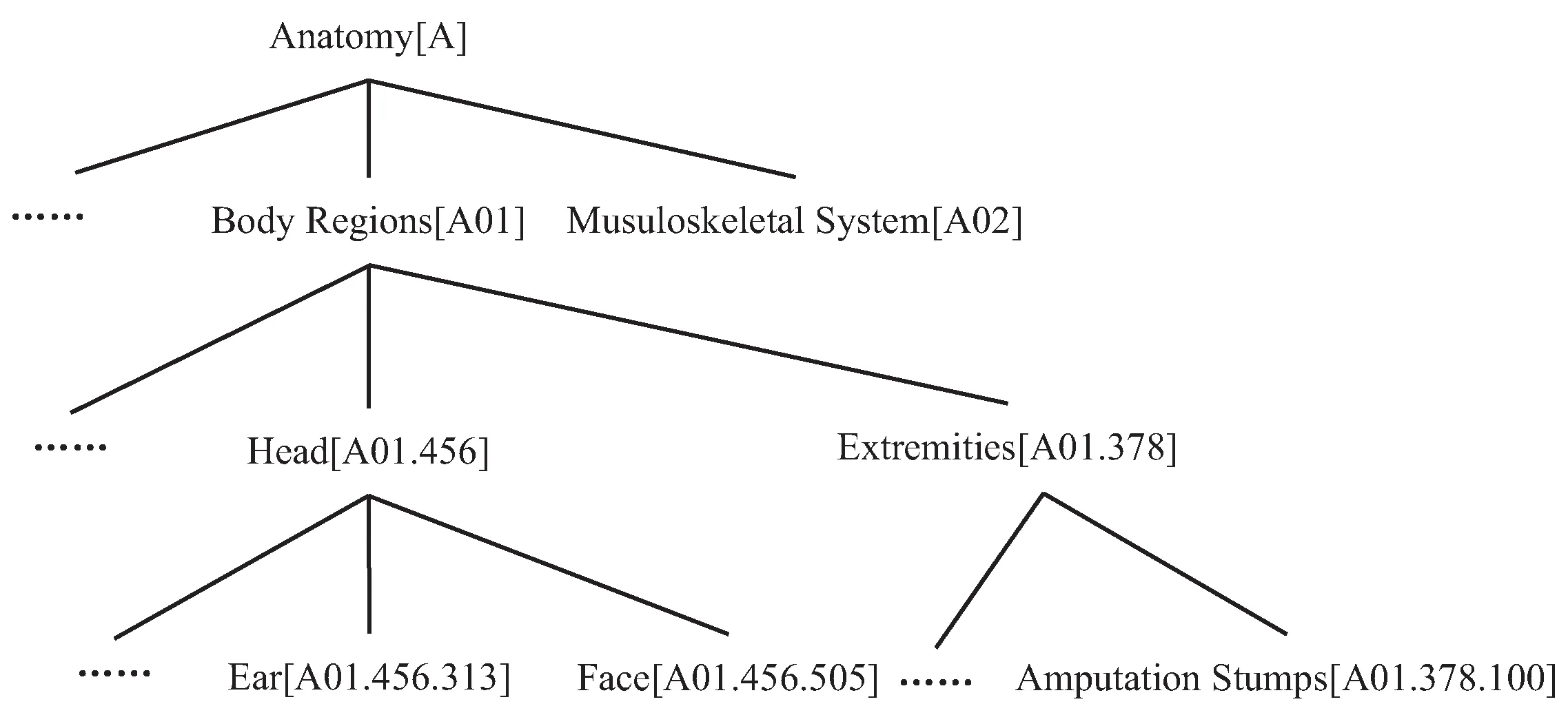
图3 MeSH树形图部分示例
图3为截取MeSH词表中以解剖学Anatomy[A]为首的部分树形图。每一个节点表示为一个主题词[Treenum],其中,Ear[A01.456.313]和Face[A01.456.505]之间的最短路径:Ear—Head—Face;语义路径距离取值为2。而Ear和Amputation Stumps之间的最短路径:Ear—Head—Body Regions—Extremitie—Amputation Stumps;语义路径距离取值为4。因此,Face比Amputation Stumps在语义上更接近于Ear。根据MeSH树形图定义的层级关系结构,可以得到不同词汇之间的语义距离。
根据规则一,不同的概念有多个Treenum,取“最小原则”,例如,Ear词汇既包括隶属于Head[A01,456]下面的Ear[A01.456.313],还包括隶属于Sense Organs[A09]下面的Ear[A09.246],Face[A01.456.505]的Treenum唯一,则计算Ea[A01.456.313]与Face[A01.456.505]最短路径为2,计算Ear[A09.246]与Face[A01.456.505]最短路径为5;根据最小原则,取主题词Ear与Face之间的最短路径为2。
3 实证研究与结果分析
本文选取Scopus数据库作为科学知识数据来源。Scopus数据库目前是全世界最大的引文数据库,涵盖了摘要、参考文献及索引,其现有索引的题录数据甚至超越了Web of Science的提供量[22]。Scopus中包含四大门类学科:生命科学、社会科学、理工和医学。根据研究目标,以Scopus生命科学领域2013-2018年3 575 103篇文献文献题录数据作为研究样本。用Scopus检索工具,以生命科学为学科领域范围,文献类型限定为“Article”“Review”“Note”“Editorial”“Letter”,共有3 639 038篇文献。获取的文献数据占搜集文献的比例为98.24%。
3.1 主题强度分布
在主题量化过程中,一般基于这样的前提事实:主题存在于文档中,不同文档由不同主题形成的混合体。因此,LDA主题模型的计算结果为主题强度的表达及不同主题特性的对比提供了强有力的依据。采用先离散方式,在时间维度上对文档集合进行切分,从数据分布情况来看,领域内文献按年份划分数量变化不大,选取时间间隔长度为1年较为合适。结合MeSH知识库和AC自动机将生命科学领域文本数据转化为主题词词袋,然后将文献按年份划分进行LDA主题建模,2013-2018年每年文献划分为50个主题。
主题强度可以通过LDA结果中文档-主题概率θ得出。统计不同时间区间内某一主题占据的比例,计算公式(4)表示:时间窗口t上主题z的强度为文档中所有主题z所占比例之和除以文档数量。
(4)
结合各时间窗下不同主题强度分布散点图,获得不同主题发展变化及趋势信息(见图4)。统计2013-2018年主题强度的标准偏差,结果分别为0.00076、0.00098、0.00084、0.00078、0.0010、0.0010。不同年份的主题强度离散程度虽有差异,但无明显上升或下降趋势,呈周期波动性,表明整体主题分布的变化情况较稳定。

图4 各时间窗主题强度分布
为了分析2013-2018年生命科学领域中的热点研究主题,对每年排名前三的主题添加主题标签,见表1。整体来说,“基因”“细胞”和“病理与生理”是生命科学领域三个热门研究领域。

表1 2013-2018年生命科学领域热点主题(Top3)
3.2 主题关联
根据2013-2018年生命科学领域文献划分的主题,按照相邻时间窗口,在计算中取每个主题权重排名前10的词汇,对相邻时间段的主题,根据2.2.1中的规则,结合MeSH领域本体库,进行主题对相似度计算,每两个时间段的相似度计算次数为50*50次。
根据主题间相似度计算结果,按照文献[23]设定的关联和过滤条件,若相邻时间窗下的两个主题满足前向关联、后向关联的条件之一,则二者之间建立主题关联,否则,主题关联不成立;同时为了提高主题之间演化关系的准确度,依据主题相似度阈值和主题间的相似度排序,过滤掉无效的主题关联。
其中,2013年Topic3与2014年的各项主题进行相似度配对计算,其排序结果见表2。计算结果表明不同主题对的相似度值之间具有明显的差异性。
2013年Topic3的概率权重排名前三的主题词集

表2 2013年Topic3与2014年各主题相似度排序
合为(Genes,Genome,Gene Expression);在2014年中,比2013年Topic3相似度高0.3,且排名前二的两个主题分别为:Topic39(Genes,Mutation,Gene Expression)、Topic17(DNA,Genome,Polymerase Chain Reaction);Topic3相似度分别为0.389和0.339,远高于2014年的其他主题。然后通过人工检验、对比和观察,发现由此相似度规则计算得出的高相似度主题对与人工判断具有明显的一致性,结果显示计算性能良好、准确度较高。
根据主题之间的关联和过滤,不同年份主题与主题间具有明确关系,利用桑基图进行可视化,图中同一纵列代表同一时间段主题,每一条连线代表相邻年份主题间关联关系,连线粗细代表主题对之间相似度大小,得到生命科学领域2013-2018年主题关联时序图,见图5。

图5 生命科学领域主题关联时序
3.3 主题演化路径
主题演化过程是指主题在时序上的发展变化过程。根据知识生命周期理论,知识个体发展过程都将经历初生、成长、成熟和衰退四个时期。因此,不少研究者将主题演化过程分为五种形式:新增、合并、继承、分化、和消亡[24-25]。从整体上看,在2013-2018年期间,主题间的交叉融合不断涌现,关联的主题数表现出先增加后减少的态势,2013-2016年主要的演化状态为主题分化,2017年主要的演化状态为主题合并,说明生命科学领域主题知识发展呈先扩张后收缩的整体趋势。
图6说明了两条完整的演化路径,第一条演化路径为2013年Topic17分化为2018年的Topic7和Topic18,2015年的Topic36继承了2014的Topic18,2015年的Topic36和新增Topic8合并为2016年的Topic2,最后消亡;第二条演化路径为2013年的Topic2和Topic42合并为2014年的Topic16,2015年的Topic30进行一次继承,2016年发生一次合并,2017年进行一次继承,2018年再次进行合并,该主题路线是一条合并和继承交互进行的发展路线。

图6 主题演化路径
由演化路径图可知,大多数的主题合并往往伴随主题的新增,而主题的继承和分化极大可能随后产生主题的消亡。因此本文基于主题的“合并”和“分化”演化关系,总结出2013-2018年生命科学领域呈现的主题发展趋势特征如下:
(1)主题知识发展的开始与扩张趋势。主题不断合并展现了主题知识体系逐步成长的局面。主题合并的过程也是科学研究聚焦的过程,体现出知识融合的特征,往往在主题知识结构尚未牢固,正在快速建立的阶段,由其他主题的知识组合、演变而来,主题的影响力不大。将路径图中主题合并演化关系进行归纳,见表3。重点归纳出前一时期的后向主题,并总结其主题标签。

表3 2013-2018年生命科学领域合并演化关系
从生命科学领域的主题关联与演化中,总结如下规律:
a.骨髓与造血干细胞研究知识的凝聚和成长。从2014年的Topic16、2015年的Topic14到2018年的Topic41是一条完整的演化路径中的三次主题合并,体现出清晰的知识发展脉络:从第一次合并主题“骨髓干细胞”,再到第二次合并主题“干细胞”,再到第三次次合并主题“骨髓干细胞”,说明围绕“骨髓干细胞”和“干细胞”不断在交叉融合。
b.物理治疗学、病理生理学等研究知识的不断积累。2016年的Topic22和2017年的Topic41是连续年份发生合并的两个主题,且2016年的Topic22“物理治疗”和Topic41主题“运动”合并主题来源重合,说明这两类主题知识密切相关。观察三个主题知识的特点,发现其共性是兼具重要性和综合性,与其他研究主题的交叉性特别强,在发展进程中在不断地吸收和融合其他主题。
c.细胞学相关分支主题研究知识的分散和独立。2014年的Topic34、2015年的Topic25和Topic20,以及2016年的Topic2,这些主题是不同年份比较分散的合并后的主题,主题标签共三类:“转移酶”“生物膜”和“培养技术”。这些主题的共性是将细胞作为一个独立的分析单元。这类主题研究特点是需要其他方法和技术的配合,因此能广泛利用其它主题研究,逐渐成长为独立于细胞学的分支主题。
(2)主题知识发展的稳定与成熟趋势。演化路径中具有分化状态的主题,通常是现阶段受人们重视的主题,属于大多数发文量多、热度较大的主题研究,随着时间推移分化出不同的子分支,表现得相对成熟,在学科领域中具有主导地位。相比于其他年份间知识关联,2017年和2018年间没有主题分化,多为主题继承,表明主题发展趋向稳定。将路径图中主题合并演化关系进行归纳,见表4。重点归纳出后一时期的前向主题,并总结其主题标签。
a.基因学、细胞学等研究知识的分离和细化。在6年内,11个分化的主题中,有5个属于每年主题热度最靠前的主题,分别为:“基因”“细胞”“环境”和“植物”。2014年的Topic27、2015年的Topic31是在连续的年份中发生分化的同一类主题“细胞”。“细胞”作为一个研究大类,综合性较强,能够分化出不同的主题研究。观察这类主题的知识特点,可以看出这些主题具有长期的知识积累、以及完备的知识体系。
b.生物化学等相关研究知识对其他研究的辐射作用。2015年的Topic40、2016年的Topic49是发生在连续年份中分化的两类主题,定义这两个主题的标签分别是“催化/氧化”和“新陈代谢”。这两个主题主要探究物质的组合、转化和交换程序,也是生物化学中的重要原理,因此是适用性、应用性较强的主题内容。

表4 2013-2018年生命科学领域分化演化关系
c.组织器官等相关研究知识的衍生发展。2013年的Topic17、2017年的Topic22,以及2016年的Topic32,主题标签为“肝脏”、“肺脏”和“创伤”,是与组织器官相关的重要研究内容。组织器官与生命体的正常形态有关,科学体系中将不同的组织器官分为不同的学科,因此每一个分支研究具有独立性和关联性。
4 方法对比与结果分析
4.1 主题关联方法对比分析
基于主题-词概率分布的主题关联方法是较为常见的计算方式,该算法考虑了词汇对于主题的重要程度。根据该方法,本文运用余弦相似度计算2013年与2014年主题之间的相似度,并与本文提出的考虑语义距离的主题相似度计算方法进行对比(见表5)。
计算结果表明,2014年Topic39与Topic17排名前二,相似度分别为0.978338和0.585775,与上文方法计算结果基本一致。其后,两种方法在相似度计算结果排序上有较大差异。分析2014年的Topic7(role,toy,social control)和Topic27(cells,apoptosis,cell line),从反映出来的主题意义来看,Topic27主题可明确为细胞,更接近2013年的Topic3主题基因。此外,Topic7相似度为0.500747,其后主题均稍高于0.5,界线不明显。

表5 主题关联方法对比
两种方式基本能够识别强关联的主题,但是主题-词概率分布的主题关联方法容易受到重合度较高、一般化词汇的影响,对于弱关联的主题识别差异不明晰。考虑语义距离的主题关联方法的计算,引入了词汇的位置和距离,利用词汇之间的客观关系判断主题之间的相关程度,重视词汇间的隐形关系,能够克服文本中常用词汇的干扰。相比较而言,该方法在揭示主题之间的关系上更加准确,与人工判断符合度更高,在进行计算时可以不受语料库大小的限制,丰富了现有的主题相似度计算方法。
4.2 结果分析与发现
本文首先分析生命科学领域2013-2018年在主题强度分布,了解领域中表现突出的研究主题,分析领域研究热点,并解释其深层次原因。在主题相似度计算中,结合领域本体计算主题与主题之间相似度的规则和算法,最后实证结果表明该算法能够有效衡量主题之间的语义关联,完成主题的时序演化路径的构建。
在对生命科学领域的演化结果的分析中,本研究得到:主题合并大多伴随主题的新增,意味着主题发展的开始与扩展趋势,从主题合并中往往会发现兴起与正在积累知识的主题,其中包括骨髓与造血干细胞等主题,物理治疗学、病理生理学等主题,以及细胞学相关分支主题;主题的继承和分化说明主题发展趋于稳定,在演化中发现大多数热门主题都属于分化中的主题,如基因学、细胞学等热门主题,这类主题往往具有长期的知识积累,能够作为其他相关研究的基础。另外,适用性较强或知识特征丰富的主题,如生物化学、组织器官等主题,从局部演化形成其他研究主题的趋势更明显。
5 结 语
本研究提出了考虑语义距离的主题关联规则和方法,在文档层级上利用领域语料库从文本中识别主题,根据主题词的相关程度进行主题关联,以解决主题内容重复、边界模糊的问题。并通过生命科学领域实际数据操作验证,借助MeSH本体计算主题层的相似度关系,构建主题关联与演化路径,以追溯生命科学领域知识结构的发展态势与变化情况。结果表明,不仅能够验证所采用方法的有效性,还能够检测和跟踪主题,清晰地反映主题演化的趋势。但本文仍有一些局限,所提方法借助领域本体库在主题之间建立联系,提升了主题之间的语义联系,但在本体不规范、不完善的领域,其应用效果可能不明显,方法的适用范围和泛化性能有进一步提升的空间。
