基于Linux平台语音识别技术的实现
2022-10-19程海波欧阳宏基
程海波,欧阳宏基
(咸阳师范学院 计算机学院,陕西 咸阳 712000)
0 引 言
随着经济和科技的飞速发展,各项新型技术取得了或多或少的进步。其中,在《互联网技术司法应用白皮书》中提到的语音识别技术近些年备受人们关注。从国外的Audry系统,到大众所熟知的Siri、小度、高德地图语音导航,以及科大讯飞的方言识别等均发展迅速。除此之外,语音识别技术还在日常的生活,如医疗、通信、工业等领域取得了不错的成就。就目前发展的形势来看,语音识别仍然具有较高的开发价值。本文主要以多媒体技术及网络技术为基础,结合Linux平台,通过ALSA和科大讯飞的SDK进行音频录制、播放等功能,进而实现语音识别。
1 语音识别技术
1.1 语音识别的概念
语音识别技术也称自动语音识别(Automatic Speech Recognition, ASR),这是让语音识别设备通过识别、学习和理解,将目标声音的内容转换为计算机可读的数据输入(如:文字或命令)的一项高级技术。同时,它也属于一门复杂的交叉学科,涉及的学科包括:声学、心理学、语言学、概率论、人工智能、信号处理、信息理论、模式识别等。
1.2 语音识别原理
语音识别的原理是将语音转换成用户能读懂的文字。其采用模式识别作为基本框架,分为数据预处理、特征提取、模型训练、测试应用四部分,其功能模块和原理如图1所示。
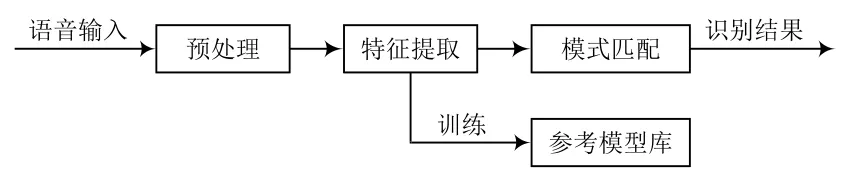
图1 语音识别原理模块
语音识别一般可分为两个模块,训练模块和识别模块。训练模块主要通过对声音的学习,将学习结果构成语音库并存储,在识别过程中将当前听到的声音在语音库中查找相应语义或词义。识别模块依据当前主流的语音识别算法,解析接收的声音信号特征参数(即特征提取),按照既定的判断条件和准则与语音库的数据进行比较,最终通过对比得出语音识别结果。
2 关键技术
2.1 ALSA
高级 Linux 声音架构(Advanced Linux Sound Architecture,ALSA)是一个完全开放的音频驱动程序集,它主要支持Linux操作系统中的乐器数字化接口(MIDI)及声频。在Linux 2.6内核版本之后,ALSA被默认为声音子系统,而之前2.4版本所使用的开放声音系统(OSS)则被舍弃。
ALSA具有以下特点:
(1)支持各种型号的声效卡和声频接口;
(2)支持旧的开放声音系统(OSS)API,具有OSS程序二进制兼容性;
(3)模块化设计;
(4)支持线程安全和SMP;
(5)提供用户空间库(lib)以简化应用程序的编程并提供更高级别的功能。
急性冠脉综合征是临床上较为常见的心血管疾病之一,同时也是冠张动脉粥样硬化性心脏病之一,通常见于老年人群[3];曾有学者研究表明:急性冠脉综合征诱发因素与吸烟、高血压、糖尿病、高脂血症及冠心病家族史等具有密切相关联系,患者可伴有发作性胸痛、胸闷等一系列临床表现,若不实施有效方法进行治疗,能够诱发心律失常、心衰、猝死等并发症,继而危及患者的生命安全,且进一步降低生存质量[4]。
由于ALSA很好地兼容了OSS,且其内含有更加友好的编程接口,因此ALSA对于开发人员而言无疑是更好的选择。ALSA系统主要包含了驱动包(Driver)、开发包(libs)、开发包插件(libplugins)、设置管理工具包(utils)、其他声音相关处理小程序包(tools)、特别声频固件包(firmware)、OSS接口兼容模拟层工具(OSS)等共7个子包。其中,Driver包是开发人员进行开发所必备的。
Driver包中含有一些内核驱动程序,其高达数十万行的内容主要包括一些公共代码及硬件关联代码;libs包括一些函数库,主要用来支持应用程序,使用最多的是asoundlib.h(头文件)以及libasound.so(共享库);而utils主要以ALSA为基础,用来控制声效卡的应用程序,如alsactl(声效卡的高级设置)、record(音频录制)、aplay(音频播放)等。
目前,ALSA主要给用户空间提供了以下几个接口:信息接口(Information Interface,/proc/asound)、控制接口(Control Interface,/dev/snd/controlCX)、混音器接口(Mixer Interface,/dev/snd/mixerCXDX)、PCM接口(PCM Interface,/dev/snd/pcmCXDX)、Raw 迷笛接口(Raw MIDI Interface,/dev/snd/midiCXDX)、音序器接口(Sequencer Interface,/dev/snd/seq)、定时器接口(Timer Interface,/dev/snd/timer)。
2.2 科大讯飞SDK
SDK(软件开发工具包)是为创建应用软件而集成的软件工具包,一般包含有专属的软件包、框架、操作系统以及硬件平台等。科大讯飞SDK是科大讯飞基于多种功能集合而来的工具包。
当开发人员要实现相应语音识别的功能时,就需要调用相应的SDK,以科大讯飞离线语音合成功能为例。
首先,下载需要使用的科大讯飞SDK包,用户进入讯飞开放平台页面(https://www.xfyun.cn)注册账号成为开发者,注册成功后,创建一个专属于自己的控制台。创建完成后,进入SDK下载中心,选择“应用”这一栏并选择自己的控制台,平台选择Linux,之后选择需要的服务,此外选择离线语音合成。完成以上步骤后,点击SDK下载,便可以将SDK文件下载到用户的电脑上,在Linux环境下实现语音合成。
(1)将讯飞包放入Linux系统的家目录中;
(2)创建一个工作目录,将讯飞包放入解压:
mkdir /home/llx/xunfei;
mv Linux_aisound_exp1227_35146063.zip home/gec/xunfei;
cd /home/llx/xunfei;
unzip Linux_aisound_exp1227_35146063.zip;
(3)配置科大讯飞库文件:
sudo cp /home/llx/xunfei/libs/x64/* /lib;
完成库文件的搭建后,可以看到讯飞包中有关各文件的说明,见表1所列。

表1 讯飞包各文件说明
了解清楚各文件后,用户便可以使用科大讯飞库的代码:

经过如上步骤便可基本实现调用SDK。但此步骤仅仅只能演示科大讯飞的示例代码,如果需要修改科大讯飞的源码文件进行自定义合成语音,则需以下步骤:

3 语音识别技术实现
(1)集成讯飞SDK。用户选择需要的功能,将下载的SDK包进行整合并压缩,压缩包名为XF_SDK.tar.bz。接着,压缩包放入Linux系统的目录中解压(需要使用tar命令),解压完成后进入XF_SDK文件夹中的源码目录对源码进行编译。
(2)创建管道文件。创建2个管道文件分别用于控制讯飞服务器的识别开始和数据返回:


(3)执行讯飞识别语音应用。进入XF_SDK下的bin目录执行./asr_offline_sample(asr_offline_sample是语音识别程序)程序。
(4)开启识别服务器后,需要控制pipe与pipeg管道文件。打开新终端并输入 :echo "star" > pipeg。
(5)应用实例。使用者发出声音如:“你好”。数据接收端便会出现图2所示的结果。
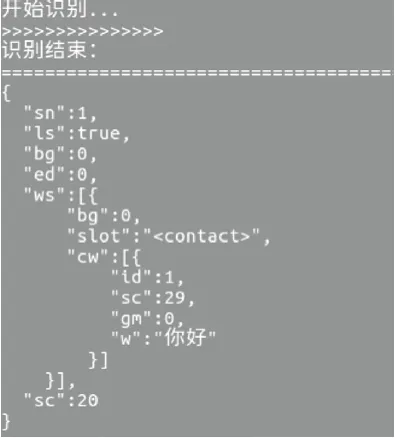
图2 语音识别结果
若要修改语音识别命令,则需要修改bin目录下的call.bnf文件。
4 结 语
语音识别技术复杂且使用面广,随着语音识别技术的发展,越来越多的问题都将被提出和解决。本文主要结合Linux平台,使用ALSA和讯飞SDK,初步实现了Linux环境下语音识别的部分基础功能。下一步的研究方向是以此次经验为基础,结合实际情况,实现Linux环境下语音识别技术的更多功能并将其与嵌入式平台结合。
