一种边云结合的漂浮物检测识别方法
2022-10-19杨克义陈亮雄杨静学贾会梅
杨克义,陈亮雄,杨静学,贾会梅,梁 涛
(1.河南中光学集团有限公司,河南 南阳 473003;2.广东省水利水电科学研究院,广东 广州 510640)
0 引 言
2019年全国水利工作会议和全国水文工作会议均提出当前水文工作要聚焦支撑解决“四大水问题”,紧密围绕水利中心工作,以提高水文监测预报预警业务能力和服务水平为重点,强化水旱灾害防御支撑,拓展水利监管服务,拓宽社会服务领域,以及时、准确、全面的水文监测预报预警信息为水利工作和经济社会发展提供可靠支撑和保障。结合国家、水利部以及省委省政府的政策要求,广东省水利厅提出了开展广东智慧水利融合工程。其中,漂浮物的监督治理作为水利日常管理工作的重要一环,急需通过智能化建设来解决。
在传统图像处理领域,主要通过漂浮物的边缘、轮廓、颜色等特征并结合分类器进行漂浮物的分类识别工作。例如,左建军等采用背景减除法分割出图像中的漂浮物区域,再利用BP算法进行漂浮物特征训练,并构建漂浮物分类器对分割区域进行漂浮物识别。朱贺等结合灰度阈值分割和河道轮廓识别方法实现对河道区域的准确提取。这些方法检测效率高,执行速度快,但同时存在对光照以及图像噪声极为敏感、鲁棒性较差等缺点。随着深度学习技术在目标检测领域的广泛使用,越来越多的学者使用深度学习技术进行河道、湖泊的漂浮物检测识别,并提出了多种网络模型的改进和应用案例。例如鲍佳松等采用的基于深度卷积神经网络的水面漂浮物分类识别术。李宁等采用的基于AlexNet的小样本水面漂浮物识别。陈运军等提出的基于VGGNet的湖面塑料制品漂浮物识别。李国进等采用的基于改进FasterR-CNN的水面漂浮物识别与定位。杨伟煌等采用的一种水面漂浮垃圾的智能收集系统。由于在实际河道中漂浮物种类繁多、环境复杂,上述方法使用单一神经网络模型进行检测识别难度大、错误率高,很难应用在实际场景中。只在边端进行漂浮物检测对硬件设备要求高,建设成本大;只在云端进行漂浮物检测,需要大量视频回传,网络建设成本高。根据边端、云端设备的不同特点,本文设计了一种边云结合的漂浮物检测识别方法,该方法在边端部署小型神经网络对视频进行初筛,剔除大量无目标数据以降低网络传输量;在云端部署大型神经网络对疑似目标进行精细识别分类。
1 算法设计
1.1 边云结合流程设计
本文设计了一种边云结合的漂浮物检测识别方法:
(1)在河岸架设多路摄像头,对获取的视频帧进行初筛,剔除大量无目标的视频信息;
(2)将疑似目标的视频信息传输到云端服务器进行精细识别分类,并转换为报警信息进行存储和上报。
系统物理架构如图1所示,算法流程如图2所示。
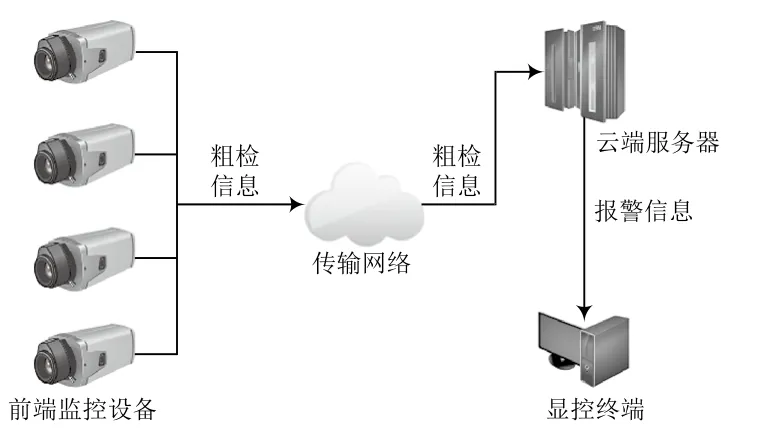
图1 物理架构

图2 算法流程
1.2 边端算法设计
在边端实现疑似目标的定位,但因设备算力有限,因此需要一个快速高效且算力要求不高的目标检测模型。二阶目标检测模型检测精度高但检测速率低,无法满足河道监测的要求;一阶目标检测模型中的YOLO系列是当前工业界的最佳视觉识别算法之一,在精度和速率方面能够达到较好均衡。相较于之前YOLOv1~v4采用的Darknet框架,YOLOv5使用PyTorch框架,对用户非常友好,不仅容易配置环境,而且模型训练速度快,所以在边端选用YOLOv5网络进行目标检测。YOLOv5结构如图3所示。
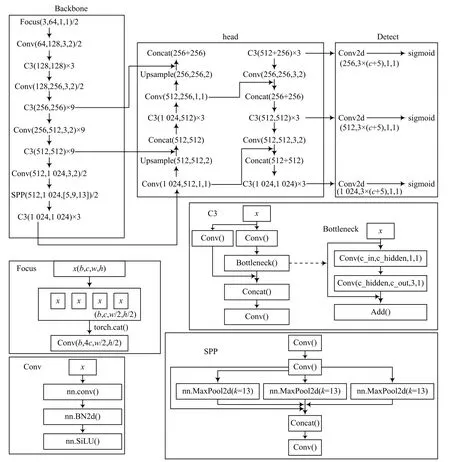
图3 YOLOv5结构
1.3 云端算法设计
在云端部署的模型主要进行目标的识别,要求具有最优的准确率,目前各分类模型具体性能见表1所列。
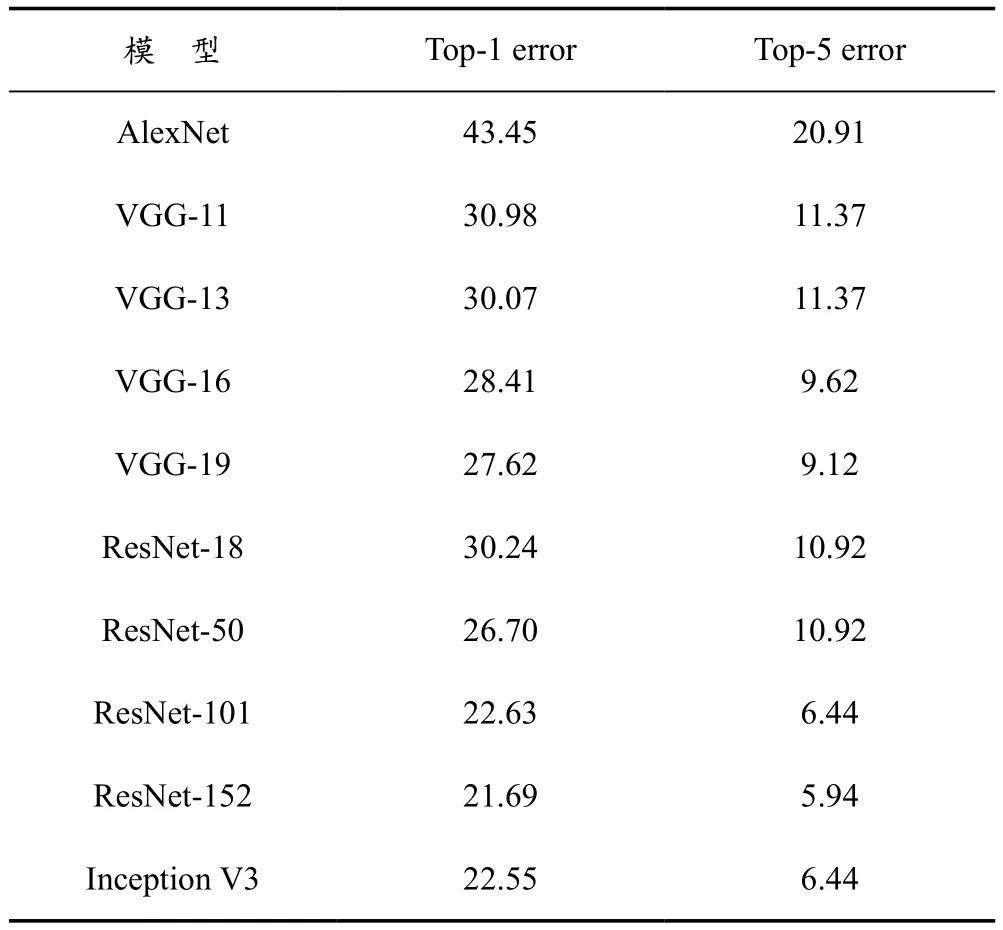
表1 各分类模型性能表
由表1可以看出,ResNet152是当前图片分类任务中表现最好的神经网络,所以本文选择ResNet152模型在云端进行目标识别分类。所选模型在top5上的错误率为5.94%,效果突出,ResNet的结构可以很好地加速神经网络的训练,模型准确率有较大提升,避免了层数加深准确率下降的问题。同时,系统可以满足云端的漂浮物分类需求,ResNet152模型的结构见表2所列。

表2 ResNet152各层结构表
2 实 验
2.1 数据集准备
网络模型构建完成后,进入数据集准备阶段。数据集的质量优劣直接影响网络模型的性能。考虑到数据集的来源应与使用环境相近,本文在大中小型河道的岸边进行数据采集。考虑到季节、天气、光照等环境因素对网络模型的影响,本文在不同环境条件下对各种河道及漂浮物进行拍摄录像,然后通过抽帧获取目标图片。此外,还借助一些数据增强手段来丰富数据集,例如通过对图像进行几何变换,包括翻转、旋转、裁剪、变形、缩放等增加数据,以及通过对图像的像素重分布,包括噪声、模糊、颜色变换、擦除、填充等增加数据。
2.2 实验结果与分析
边端模型训练设备的硬件配置为:处理器 IntelCorei7-4460、内存32G、显卡GTX1080、16G;软件环境为:操作系统 Ubuntu18.04、框架PyTorch、网络 YOLOv5。共训练2次。第一次训练,保证数据集样本及类别不变,并以此训练结果为基准判断本文方法的有效性。训练时主要观察模型的精确率,精确率越高说明误检率越低,第一次训练效果如图4所示。

图4 YOLOv5第一次训练效果
第二次训练,考虑到边端设备算力有限,将数据集样本类别信息去除,由此,YOLOv5只做目标定位而不做目标识别,以降低其计算复杂度。第二次训练效果如图5所示。
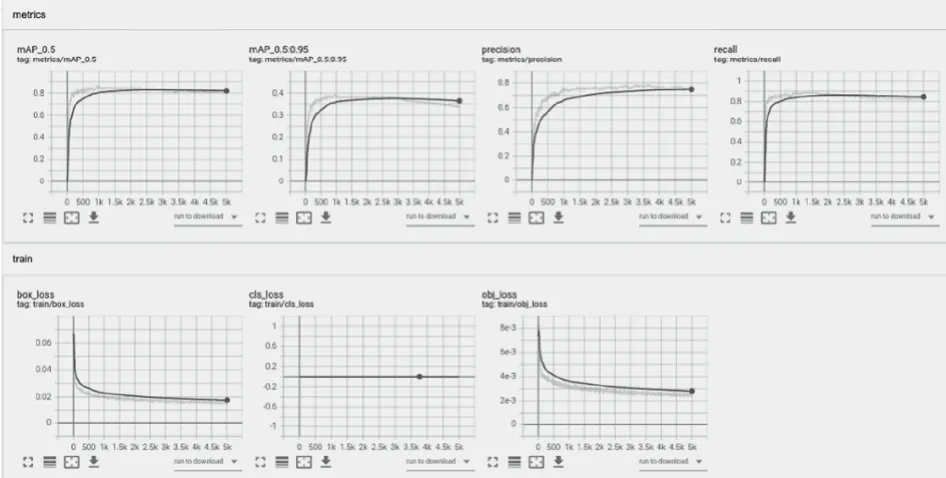
图5 YOLOv5第二次训练效果
云端模型训练设备的硬件配置为:处理器IntelXeon(R) CPU E5-2678 v3 @ 2.50 GHz × 48、内 存 32G、显 卡GTX3090、32G。软件环境为:操作系统Ubuntu18.04、框架PyTorch、网络ResNet152。在训练前,需将数据集进行裁剪,将目标从背景分离得到目标数据集,模型训练效果如图6所示。

图6 ResNet152训练效果
数据搜集完毕后,通过筛选和标注形成最终的数据集。数据集共有图片17 985张,样本53 959个,漂浮物类别10种。样本类别分布均衡,达到训练要求。
通过图4、图5可以看出,YOLOv5两次训练的损失函数曲线图大致相同,目标框的损失曲线大致相同,训练的2个模型的目标定位检测损失一致,可以说明模型在检测定位方面一致,其中检测分类YOLOv5模型的精确率为75.81%。图6(a)是ResNet152模型的训练损失图,训练1 000次后损失约0.001,图6(b)是模型在验证集的准确率,训练1 000次后准确率约为98.2%。
将图5的模型在相同验证集进行定位检测,将检测到的目标信息传给ResNet152模型进行分类,得到结果后计算出相应的精确率,最终结果对比见表3所列。
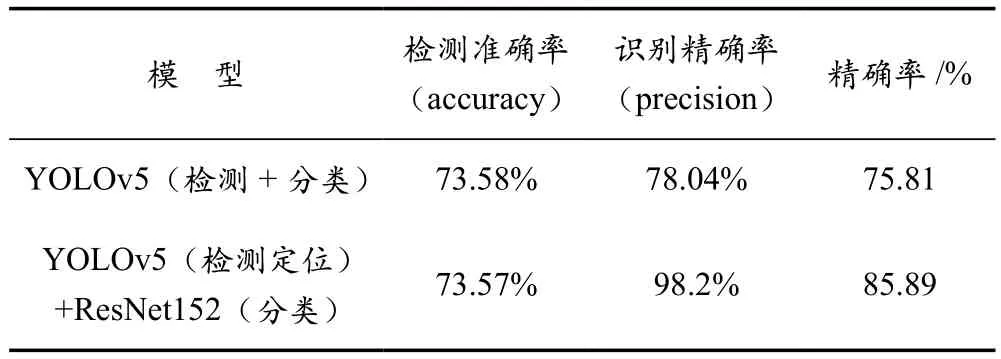
表3 结果对比表
由表3可知,图4的检测准确率与本文的边端检测准确率基本相同,从图4、图5中box_loss函数趋于相同也可以得到佐证,图4的精确率为75.81%。采用本文方法在边端进行检测的准确率为73.57%,在云端的识别精确率为98.2%,本文的精确率为85.89%。与图4的精准度对比,本文的精确度提高了10.08%。由此可见,本文提出的边云结合的漂浮物检测识别方法切实可行,满足了河道漂浮物的预警需求。
3 结 语
通过对神经网络的研究分析,结合边端和云端设备的不同特点,本文设计了一种边云结合的漂浮物检测识别方法,该方法目前通过实验测试提高了模型检测识别的精确度,减少了模型预测的耗时。但实验中还存在一些不足,比如检测定位模型选用的是YOLOv5模型,没有对其进行剪枝压缩,缩小模型规模以进一步降低模型对边端设备算力的要求,下一步尝试在保证其检测精度的前提下对模型进行压缩剪枝。
