基于多源信息融合的碳价格预测模型
2022-10-19郑一鸣,连子炎,兰子梦
0 引言
当今社会科技发达,信息流通,大数据作为这个高科技时代的产物已经渗透入各行各业,成为重要的生产因素。如任守航基于瓦斯浓度数据,提出了适用于煤矿企业的瓦斯浓度预测预警方法,为煤矿企业在实际生产中防控瓦斯灾害事故提供了良好的技术手段。张昊然汇总了医疗行业的海量数据,通过对各项医疗指标的监控与分析,对医疗机构进行多维度画像,从而为管理者制订提升医疗服务水平的具体策略提供参考。众多案例均表明人们利用大数据可以很好地将多源信息进行融合,从而对某些领域展开预测。而能够间接反映多源信息的一个重要指标便是搜索指数。搜索指数是以用户的搜索量为数据基础、以关键词优化为统计对象,科学分析并计算出各个关键词在网页中搜索频次的加权和。随着互联网普及率的显著提高,互联网技术日趋成熟,搜索引擎服务也逐渐完善,人们愈发倾向于借助互联网来获取自己所需的信息。鉴于此,近年来学者们常基于在我国有较高影响力的百度搜索平台,利用其百度指数对某些行业的发展趋势进行研究。邓于佳针对股票价格复杂无规律的涨跌预测问题,将有效关键词的百度指数作为股票投资者关注度的衡量标准,在不考虑宏观因素的情况下,结合神经网络模型,较为准确地预测出了股票的价格趋势,能够为投资者提供一定的决策依据。黄锦波从互联网的角度出发,考虑消费者的网络互动行为,选择BP神经网络作为模型,同百度指数结合对人身险保费进行预测,证明了引入百度指数的模型有助于提高人身险保费收入的预测精准度。马隆对用户的搜索行为与P2P行业成交量之间的关系进行分析,并通过用户的搜索行为对P2P行业成交量的发展趋势进行预测。同时还将传统预测模型的预测结果与加入搜索指数的预测模型的预测结果进行对比,发现后者的预测精度明显高于前者。周恬恬提出了基于百度指数和随机森林模型的上证综指走势预测方法,建立了上证综指收盘值的回归预测模型和上证综指收盘值涨跌分类预测模型,并且通过与无百度指数的随机森林回归预测模型实验对比,发现该模型具有更高的精确度和更好的拟合效果,证明了百度指数对于该模型预测的高度有效性。综上,本文将对碳价格进行预测:首先选取多个与碳价格相关关键词,爬取其百度指数,并利用MDS算法降维;然后基于历史数据与百度指数建立LSTM预测模型,对碳价格进行预测;最终对不同输入层的预测结果进行有效性检验及对比分析。
1 基于多源信息融合的碳价格预测模型
1.1 模型构建的基本思路
本文首先查阅大量文献,选择了9个能够反映民众对碳交易关注热度的关键词,再利用MDS算法将其缩减至3维矩阵,然后将3维碳热度矩阵和历史碳价格作为LSTM模型和LSSVM模型的输入层,进而得到预测结果,最后,利用RMSE对预测结果进行误差分析和有效性评价,具体思路如图1。
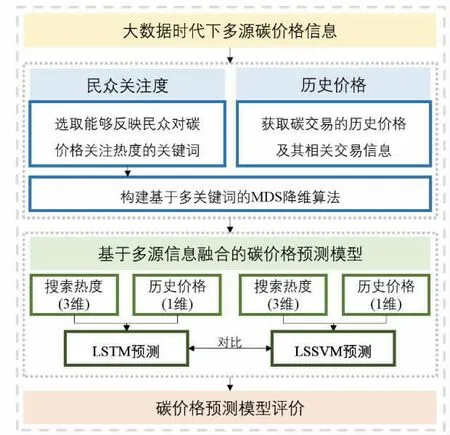
图1 基于多源信息融合的碳价格预测模型的基本思路
1.2 基于多源信息融合碳价格预测模型构建的基本过程
1.2.1 基于多关键词的MDS降维模型 选取并收集与碳价格相关的关键词百度指数,鉴于关键词较多,且各关键词之间有较高的相似性,故建立MDS模型对所得数据进行降维处理,并且在尽可能保持各关键词相似性的前提下,将其在低维空间中进行表示。首先将选取的9个关键词实例及其百度指数进行向量化表示,可以得到9维空间中的距离矩阵D,D是一个(9×9)的矩阵,其中第i行j列的元素表示第i个关键词实例和第j个关键词实例之间的距离,现将其降维值3维空间Z中,Z表 示第i个关键词实例。因任意两个关键词实例在Z中的距离与原始空间的距离相同,故有
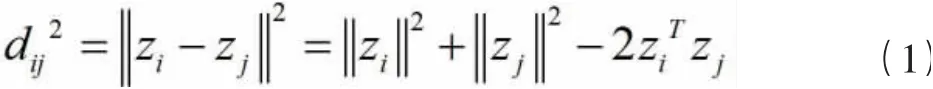
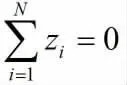
对(1)左右两边求和:

再对(3)两边求和:
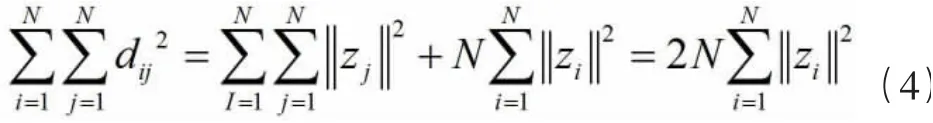
定义内积矩阵Z=ZZ,将(2)(3)(4)代入(1)中,得

由于B是对称矩阵,因此对B特征分解可得

Λ为特征值矩阵,V为特征向量矩阵,欲将数据降维至3维空间,故选择前3个最大得特征值以及特征向量,降维之后得数据点表示为

1.2.2 基于历史信息的LSTM预测模型 碳价格的波动不仅会受到近期的影响,而且过去任意时期都有可能对未来的变化造成冲击,只是随着时间推移,过去的时间节点对现在的影响可能呈现递减趋势。因此本文选择借助LSTM神经网络的门控机制,过滤冗余信息并筛选出有效历史信息对碳价格进行预测。每一个LSTM的神经单元是由细胞状态以及输入门、遗忘门和输出门三个门组成。首先由遗忘门根据下式来决定当前状态需要丢弃哪些历史信息:

此时引发细胞状态的第一次改变,即

然后向输入门中输入前一期的细胞状态C,前一期的输出值S,以及该期的数据X,由输入门对所有输入信息进行处理,并根据:

引发细胞状态的第二次改变:

最终由输出门得到输出结果O(t)与输出值S:

1.2.3 基于历史信息的LSTM预测模型LSSVM在SVM的基础上进行改进,采用最小二乘线性方程作为损失函数,将SVM的不等式约束转化为了等式约束,从而将复杂的二次规划问题转化为相对较简单的求解线性方程组问题,有助于基于历史信息对具有非线性特性的碳价格进行有效拟合。设给定一组训练样本集:

其中x为第i个输入向量,y为第i个输出向量,n为输入向量的维数,N为训练样本的大小。LSSVM的核心是将训练样本非线性映射到高维特征空间,在高维空间中进行线性回归。回归函数为
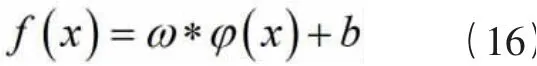
其中ω为权重向量,φ(x)为LSSVM的核函数,反映低维特征空间到高维特征空间的映射关系,b为偏差。依据结构风险最小化原则,LSSVM优化问题可转化为:

其中e为拟合误差,y为惩罚因子,用于控制误差的惩罚程度。引入拉格朗日乘子λ求解该优化问题:

然后根据KKT条件对上式求解推导:
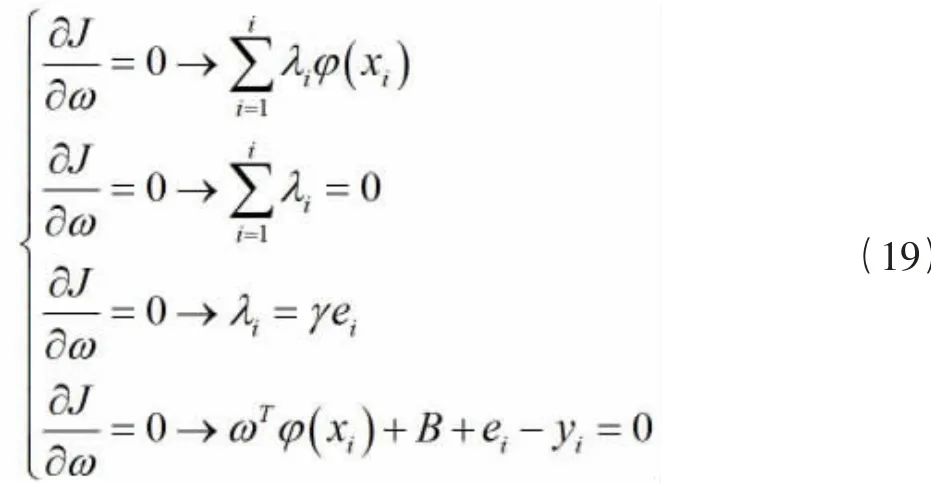
求解消除方程中的棕和e,得到最终预测模型函数:

其中K(x,x)为核函数,反映输入空间到高维特征空间的非线性映射。本文采用具有径向对称且泛化能力强的径向基核函数作为该预测模型的核函数
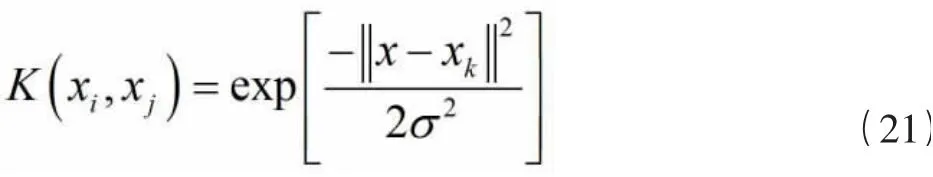
其中滓为核函数的宽度因子。
2 实例仿真与结果分析
2.1 数据来源与处理
本文选取从2019/10/29至2022/03/07共314个数据,其中前284天为训练集,后30天为测试集。查阅文献后,本文选取了低碳经济、碳交易、碳达峰、碳中和、碳足迹、碳排放、碳关税、减排、碳税九个关键词,以这些关键词的百度指数作为人们对碳价格的关注热度。利用MDS算法降维后的结果如图2。

图2 搜索热度降维结果
将降维后的搜索热度和历史碳交易价格分别作为LSTM模型和LSSVM模型的输入层,建立LSTM碳价格预测模型和LSSVM碳价格预测模型,具体输入如表1。
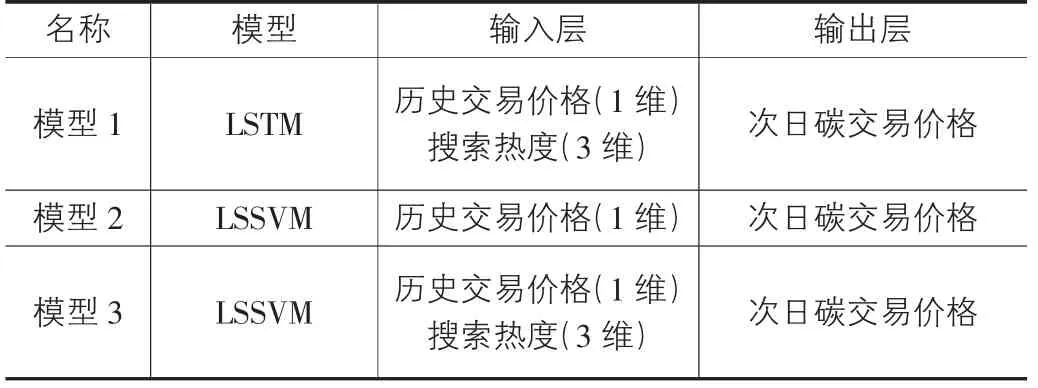
表1 三种模型的输入输出参数
此时,我们可以得到基于多源信息融合的碳价格预测模型的结果,如图3。
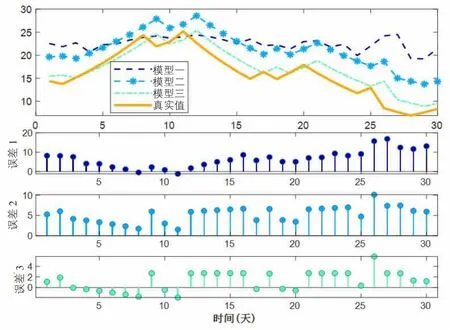
图3 碳价格预测结果
2.2 预测的评价指标
本文选取误差平方和(SSE)、平均绝对百分比误差(MAPE)、均方根差(RMSE)和平均绝对误差(MAE),用于评估以上三种碳价格预测模型的优劣。计算公式如下:
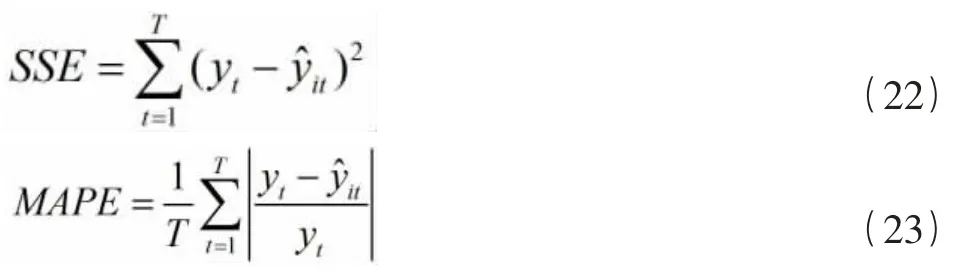

根据公式(22)-(25)计算各碳价格预测模型的评价结果如表2。

表2 各模型预测效果对比
通过表2可以看出,无论是SSE、MAPE、RMSE、MAE,模型3的预测效果都显著优于模型1,这表明LSSVM模型比LSTM更适合预测碳价格的波动。考虑民众关注热度的模型3预测效果明显优于模型2,表明民众关注对碳价格的波动有一定影响。实践证明,引入多源信息的预测模型能显著提高预测精度,考虑多方面影响因素在实际预测中是有必要的。
3 结论
针对本文所研究的问题,通过对比同等条件下LSTM和LSSVM的预测性能,最终基于LSSVM构造两类预测模型,一类仅考虑历史价格对碳价格的影响,另一类则同时考虑历史价格和关键词百度指数,研究其对碳价格的共同影响。实验结果显示,加入关键词百度指数后的模型,其预测性能有了显著提升。由此可见网络搜索指数对于某些问题的预测研究有着较为重要的正面影响,因此在未来的研究中会继续将搜索指数置于较为重要的位置,以提高模型的精确性与合理性。
