基于注意力机制的机器阅读理解模型研究
2022-10-18郭泽晨吕文蓉
武 迪 ,马 宁 , 郭泽晨 ,吕文蓉
(1.西北民族大学 中国民族语言文字信息技术教育部重点实验室,甘肃 兰州 730030;2.西北民族大学 甘肃省民族语言智能处理重点实验室,甘肃 兰州 730030)
0 引言
机器阅读理解(Machine Reading Comprehension;MRC)是作为问答技术研究的重要分支,一般形式为给定一篇文章,答题者阅读并理解文章的内在含义,并对文章的题目给出自己的理解和回答[1].机器阅读理解在自然语言处理中极具挑战性,对于实现真正意义上的人工智能具有重要的推动作用.随着深度学习技术的发展,机器阅读理解任务抛开了传统的基于人工规则或者构造关系数据库来解决问题.近年来,大规模阅读理解数据集的出现,使得机器阅读理解模型得到了强有力的数据支撑,为机器阅读理解模型优化提供了条件.注意力机制的思想来源于人类获取信息的方式,人眼往往聚焦于更需关注的目标区域,注意力机制是模仿此机制,给重要信息分配较高权重来降低不重要信息的权重,实现重要信息提取.CNN和RNN模型在机器阅读理解中得到了较为广泛的应用,但它们对序列中不同位置之间依赖关系的建模并不直接,而注意力机制可以将每个词之间的距离简化为一,较好地提高了模型的并行程度.注意力机制是深度学习快速发展后广泛应用于自然语言处理、统计学习、图像检测、语音识别等领域的核心技术[2].鉴于机器阅读理解任务的形式,注意力机制的不断发展非常有利于机器阅读理解任务的实现,通过它来计算文章和问题之间不同注意力权重值,有效融合文章和问题的语义信息.对语义信息进行解码来准确定位问题答案,成为机器阅读理解任务中不可或缺的关键技术.
1 注意力机制原理
注意力机制最早应用于图像处理领域,其作用是将传统的视觉搜索方法进行优化,可选择地调整视觉对网络的处理,减少需要处理样本数据并增加样本间的特征匹配[3].注意力机制在自然语言处理领域的应用相对较晚,最早应用于机器翻译工作中.Bahdanau等[4]提出,使用类似注意力机制在机器翻译任务上将翻译和对齐同时进行,他们首先将attention机制应用到NLP领域中.2017年,Ashish Vaswani等[5]提出Transformer模型,使用attention机制代替LSTM,自注意力机制进入大众视线.自注意力机制可以充分考虑一个句子中不同词语之间语义与语法联系,用在普通注意力或双向注意力之后,句间信息能够更好地融合,从而在机器阅读理解任务中得到了广泛应用.
注意力机制的核心是针对不同目标输出生成不同的上下文向量,并将其看做对输入词向量的加权处理,因此,可以被定义为不同时间步编码器输出的加权求和,得到更多目标输出有用的信息.在注意力机制计算过程中包含三个参数,分别为Query、Key、Value.这里用Q,K,V表示,Q是一个随意线索,在机器阅读理解任务中为问题的序列表示,而Key和Value为不随意线索,在这里为文章序列表示.
首先,通过注意力分数函数来计算问题中逐个词对文本中所有词的注意力分数,表示目标语言各位置与源语言各位置之间相关性大小.注意力分数函数f(q,k)计算方法有以下几种:
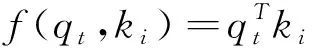
(1)
(2)
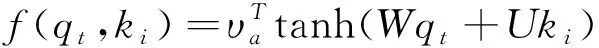
(3)
(4)
其次,利用softmax函数对注意力分数进行指数归一化处理,得到相应的注意力权重.将源语言与目标语言之间注意力权重看成一个矩阵,长为文章长度,宽为问题长度,文章中第i个词和问题中词的权重公式如式(5).
(5)
最后,根据权重对相应的v进行加权求和,得到上下文向量.attention value的计算公式如式(6).
(6)
2 基于注意力机制的机器阅读理解模型
目前,许多注意力机制都基于编码器—解码器模型.在自然语言处理领域,可以把编码器—解码器模型看作模型对一个句子或一段话进行加工处理后生成另一个句子和一段话的通用处理模型.在机器阅读理解任务中,模型的输入为文本和问题:首先需要利用编码器将其编码为机器能识别的形式,即将其编码为对应的词向量,然后在交互层利用注意力机制对文本和问题的语义信息进行融合,为序列中每个词生成权重信息,而解码器则是将经过中间交互层产生的向量解码为输出答案.
一般的编码器—解码器模型只将输入的文本x转化为其语义表示c,对于所有的输入向量,在生成其语义表示时权重都是相等的,但加入注意力机制模型,对于不同的向量生成的语义信息表示c不同,可以更加准确地表示句间词的关联程度.在进行解码时根据融合的各个语义向量c,按照开始和结束位置的最大概率输出更加准确的结果.加入注意力机制的编码器—解码器模型如图1所示.
注意力机制不仅可以单独进行任务处理,还可以与其他模型相结合完成更加复杂的任务.其思想应用在阅读理解任务中,可以把文章部分看作是编码器部分,问题部分看作解码器部分,如果自身既是编码器部分又是解码器部分,这就是自注意力机制[6].大多机器阅读理解任务都基于编码器—解码器模型,随着句子长度的增加会面临无法保留输入序列信息等问题,如果将其与注意力机制相结合可以有效解决这些问题.
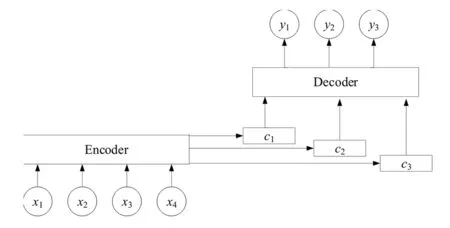
图1 基于注意力机制的编码器—解码器模型
2.1 普通注意力机制机器阅读理解模型
自斯坦福机器阅读理解数据集SQuAD问世以来,经过谷歌、微软、百度、科大讯飞、腾讯、斯坦福大学等在内的众多研究机构的不懈努力,形成了“词向量化—语义编码—语义交互—答案预测”这样一套四层机器阅读理解模型体系[7].注意力机制为语义交互答案预测中的关键一环.基于神经网络的注意力机制阅读理解模型的主要思想是模仿人类阅读理解过程进行建模.阅读理解问答任务可拆分为三部分:阅读,理解和答案搜索[8].根据其原理,注意力权重矩阵计算可分为三个阶段:
1)通过注意力分数函数F(q,k)计算Query和每个Key之间的注意力分数a1,a2,a3,a4.
2)将注意力分数经过softmax()函数进行归一化得到权重信息w1,w2,w3,w4.
3)将文本中的每个value与权重信息进行加权求和得到问题中的一个词对文本中所有词的Attention values,上述过程如图2所示.
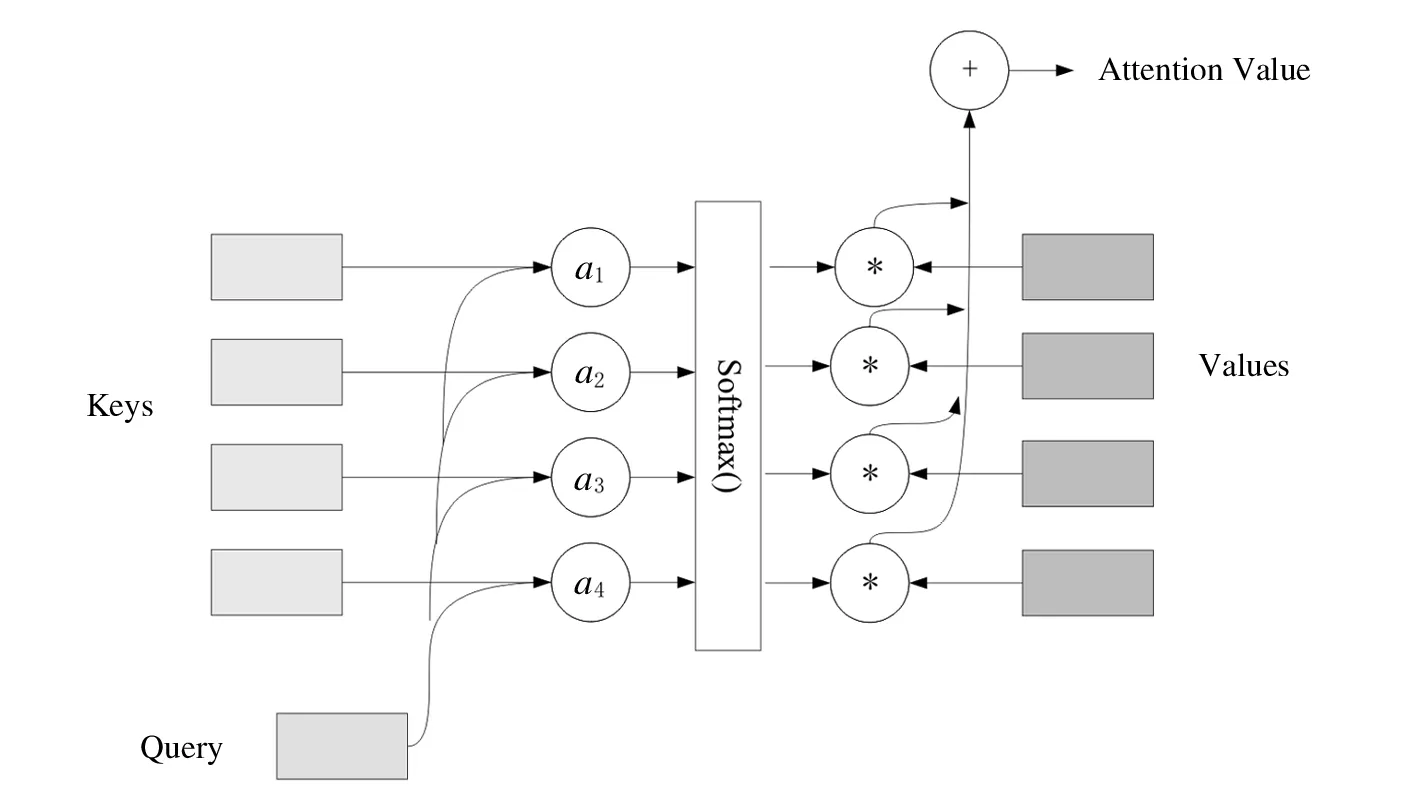
图2 注意力值计算过程
2.2 双向注意力机制机器阅读理解模型
早期的机器阅读理解模型大多用单向的注意力机制,其缺点是不能很好地获得文档和问题之间的联系,在文档和问题的编码过程中会丢失有效信息[9].双向注意力机制可以在普通注意力机制基础上进一步融合句子的语义信息,以注意力流的形式出现在BiDAF模型中.BiDAF模型由Minjoon Seo等[10]提出.模型中的交互层使用了文章和问题两个角度的注意力机制.
BiDAF模型通过多级分层的结构对不同粒度级别的上下文表征进行建模,模型包括character-level,word-level和聚合上下文信息的embeddings,接着采用双向注意力流来获得query-aware上下文表征[11].BiDAF模型结构如图3所示.
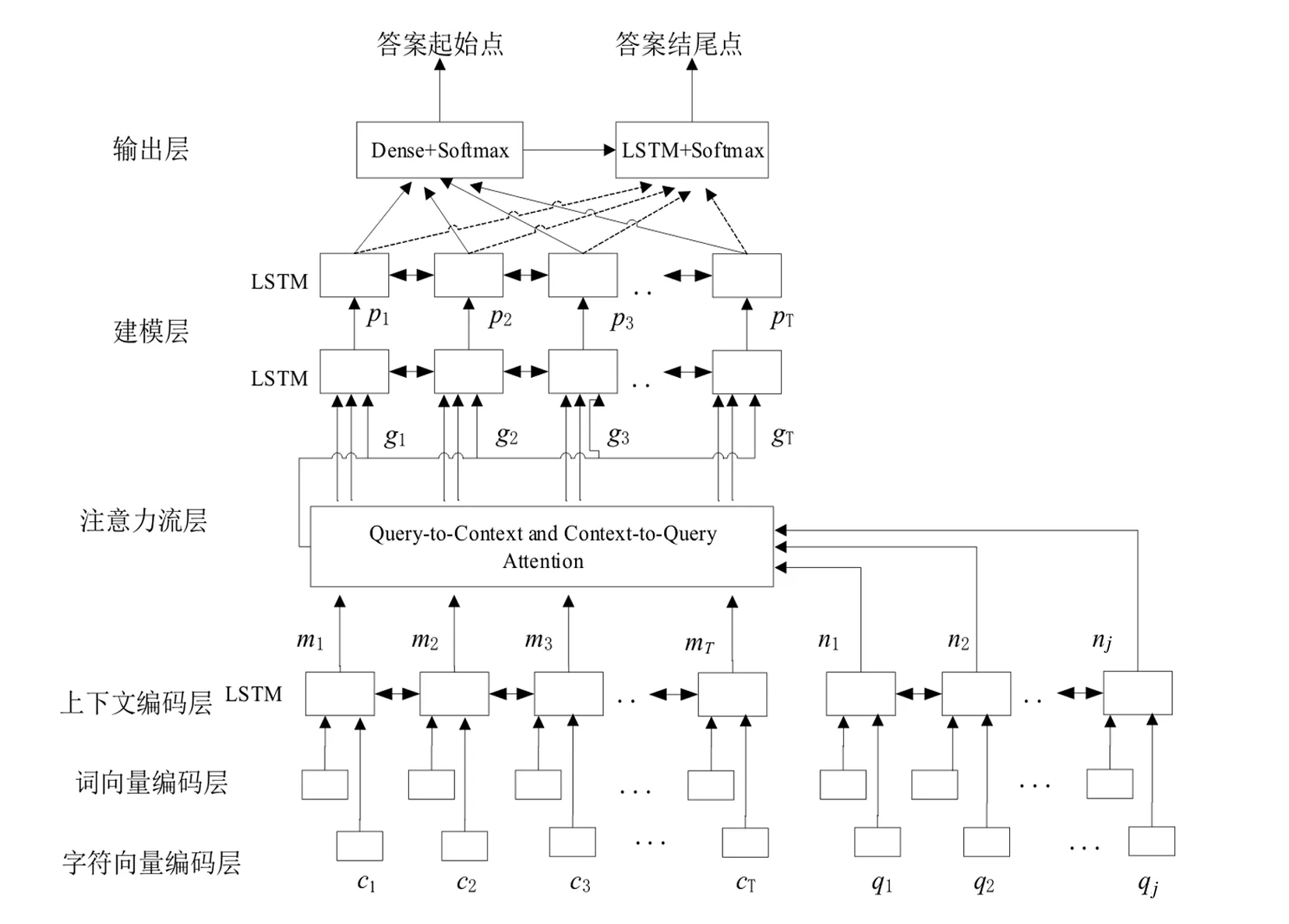
图3 BiDAF模型结构
双向注意力流层主要包含两块:由文本到问题的注意力和由问题到文本的注意力.
由文本到问题的注意力表示问题中的哪些词与文本中的词相关程度最高.在本模型中,上下文编码层的输出为文本表征矩阵M和问题表征矩阵N,首先引入一个标量函数α,这个可训练函数用来计算两个词向量之间的相似度,经过函数的计算生成一个向量相似度矩阵S.矩阵S中Stj表示文本中的第t个词和问题中的第j个词的相似度.计算公式为Stj=α(M:tN:j),其中M:t为M中的第t列,N:j为N中的第j列.
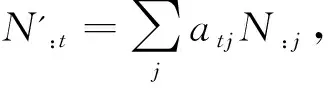
2.3 自注意力机制机器阅读理解模型
自注意力是注意力机制在Q=K时的一种改进(即查询源文本序列自身),是建模源文本序列内部元素间的依赖关系,以加强对源文本语义的理解[12].不同于普通注意力机制,自注意力机制是为了考虑句内词语的语义及语法之间的联系,将词向量经过自注意力机制神经网络处理后的词语融合整个句子的语义信息,不只包含该词的信息,可以通过设置多个自注意力层使语义信息得到更加充分的融合.在机器阅读理解任务中,自注意力机制往往会设置多层,或者将其设置在双向注意力机制之后,对语义信息做进一步融合.
对于单词序列{θ1,θ2,θ3,…,θm},用RNN模型来处理时,在处理第m个单词时需要处理第m-1个单词时的信息.以此类推,若要得到第m个单词和第一个单词之间的关联信息就需要进行m-1次的信息传递.在信息传递过程中,若单词之间距离过长,则会导致信息在传递过程中丢失,同时序列处理的速度也十分缓慢.利用自注意力机制处理单词序列时,可将每个单词之间的信息传递距离简化为1,摆脱了这种顺序传递方式.如果直接计算两个单词之间的关联程度,能够很好地解决长距离依赖问题,同时由于单词之间的联系都是相互独立的,因此能提高模型并行度.
设θ1,θ2,θ3,θ4为文本输入序列的向量,λ1,λ2,λ3,λ4为文本输出序列的向量,与普通注意力机制一样,自注意力机制也需要先计算向量之间的注意力分数,计算句内两词向量的关联程度.这里以计算其他词向量与词向量θ1的关联程度为例,设输入序列中θ2,θ3,θ4与θ1的关联程度用向量z1,2,z1,3,z1,4来表示.z的计算和普通注意力机制方法相同,其中所用最多的方法是点积,自注意力机制计算过程如图4所示.
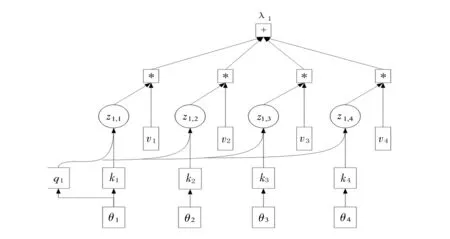
图4 自注意力机制计算过程
其中wq,wk,wv为未知参数,需要通过模型训练得到.令q1=wqθ1,k2=wkθ2,k3=wkθ3,k4=wkθ4分别为句子中所有词向量,则z1,2=q1k2,z1,3=q1k3,z1,4=q1k4.另外,θ1也需计算与自己的关联性,b1为所有词与第一个词的关联程度信息.在这里v1=wvθ1,v2=wvθ2,v3=wvθ3,v4=wvθ4,最后得出λ1的计算公式(7).
(7)
2.4 注意力机制机器阅读理解模型对比分析
普通注意力机制可以使得模型在解码时将注意力集中于权重较高的部分,编码器不再将所有的语义信息集中于最后一个隐层输出单元,这样就能改进传统的循环网络推断速度慢等问题.在此基础上,更多形式的注意力机制也被大规模应用于阅读理解模型中.
在处理阅读理解任务时,输入往往为两个源片段,双向注意力则是对普通注意力的改进,使得模型可以交互两个源片段的语义信息.双向注意力在阅读理解、NLI(Natural Language Inference)等任务中广泛应用.该机制可以更好地理解两个序列间的关系.通常的做法是将 K2Q与Q2K的注意力输出进行拼接或聚合得到最终的输出,模型据此进行推理[12].大量的实验数据证明,双向注意力机制可以通过交替或并行方式更好地交互文本与问题的内容,提升模型准确率.Seo等[10]实验证明,在双向注意力的交互过程中,相较与Q2K,K2Q 的比重对结果的影响更大.
无论是普通注意力还是双向注意力,在进行交互时都忽略了文本自身的语义联系.受Cheng等[13]内部注意力的启发,自注意力机制被提出,自注意力可以加强模型对文本自身的理解,在阅读理解中相当于脱离问题去阅读文本.这种做法可以避免带着问题去阅读时可能陷入的局部最优[14].相较于前两者,自注意力机制目前应用更为广泛.Vaswani等[5]基于此构建了自注意力网络,将位置编码加入到词向量输入中,并在自注意力层后加入全连接前馈网络,来作为Transformer和Bert模型的一部分,取代了传统的LSTM或RNN,大幅度提高了模型性能.
3 结语
注意力机制在机器阅读领域具有重要理论意义和应用价值.随着深度学习不断发展,注意力机制在各个领域的任务中应用更加广泛.注意力机制可以提高编码器—解码器模型框架的可解释性,能更好地融合语义信息.本文主要对普通注意力、双向注意力以及自注意力中语句的处理过程进行详细阐述,并在此基础上对模型进行对比分析:无论是双向注意力机制,还是自注意力机制,都致力于更好地融合语义信息,使模型能更加准确地预测问题答案.
机器阅读理解任务主要解决长篇章的推理回答,注意力机制可以提供灵活并有效的信息交互与利用方式,无论是BiDAF模型还是Transformer都不同程度地利用了注意力机制.与注意力机制相结合的各模型在处理自然语言的各项任务中起到重要作用,在机器翻译、问答系统中都得到了广泛应用,能提高神经网络模型的可解释性,同时在传递过程中可避免信息丢失.因此,对基于注意力机制的机器阅读理解技术进行研究,具有重要的理论价值和广阔的应用前景[15].在图像处理方面利用注意力机制可以选择图像的聚焦位置,产生更具分辨性的特征表示.Mnih等[16]在RNN上加入了注意力机制来实现图像分类,降低了处理高分辨率图片的复杂性.Zhang等[17]提出了自注意力生成对抗网络,允许对图像生成任务进行注意力驱动的远程依赖建模.另外,注意力机制在语音识别领域也有广泛应用.Liu和Lane[18]提出了一种基于注意力的用于联合意图检测和槽填充的神经网络模型,其F1值得到显著提升.
