基于N-gram 和Transformer 的DGA 恶意域名检测
2022-10-18芦天亮闫尚义张建岭
杨 成, 芦天亮, 闫尚义, 张建岭
(中国人民公安大学信息网络安全学院, 北京 100038)
0 引言
如今,人们的生活越来越离不开互联网,截至2021 年6 月,我国网民规模达10.11 亿,较2020 年底新增网民2 175 万,互联网普及率达71.6%[1]。但是互联网的应用在丰富人们生活的同时,也带来了很多安全隐患。 在访问网站时,输入的域名会通过DNS 服务解析为IP 地址,进而定位到目标服务器浏览相应的Web 服务。 因为域名系统本身没有安全检测机制,所以恶意软件、病毒常使用DNS 服务与外部服务器通信[2]。
恶意域名作为恶意软件、病毒与恶意服务器的通信载体,被黑客APT 组织广泛运用。 为满足攻击者的攻击需求,以及防止恶意域名被安全厂商发现,无法继续展开攻击行为,攻击者常使用域名生成算法(Domain Generation Algorithm, DGA)生成大量的恶意域名,还可以实现隐藏真正恶意服务器的目的。
现有恶意域名检测算法检测效果不够好,并且无法挖掘域名深层次特征。 鉴于此,本文提出了一种新的恶意域名检测方法,主要工作和贡献如下:
(1) 在数据处理阶段,使用N-gram 算法处理数据集,并使用word-hashing 技术增添域名中字符的首尾位置信息,该模型能够深入地学习恶意域名的字符位置特征,增强模型的鲁棒性;
(2) 在模型训练阶段,运用Transformer 模型识别恶意域名,进一步加深了模型对恶意域名中字符位置信息、字符特征等深层特征的学习,提升了识别的准确率;
(3) 对Alexa 和360 安全实验室提供的数据集进行实验,与Nalve Bayesia 算法、XGBoost 算法、RNN 模型、LSTM 模型等进行对比。 实验表明,本文提出的算法的准确率达96.04%, 召回率达95.99%,优于大多数主流恶意域名检测算法。
1 相关工作
1.1 恶意域名生成算法
攻击者为了应对封堵IP 和域名等措施,使用DGA 算法生成大量候选域名列表,域名列表会随DGA 选择参数的不同而不断变化,有效地掩护了真实的恶意服务器,为传输病毒、木马、恶意程序提供了便捷。 域名生成算法使用时间、特定字符串等参数通过异或、哈希等操作生成一系列伪随机字符串[3]。 随着学者对DGA 算法研究的深入,针对恶意域名检测的方法也在不断地完善与发展,但在检测已有恶意域名的同时,新的DGA 家族变体也随之出现,360 安全实验室公开的恶意域名家族多达54 个。
DGA 选择的生成参数,主要分为2 类。
(1) 静态DGA。 生成的域名不依赖种子的域名生成算法,这类域名生成算法有一定几率在生成时产生相同的域名。
(2) 基于种子的DGA。 根据种子所选的不同分为2 类:
①一类使用硬编码的种子生成域名,如使用推特热门话题作为种子;以欧洲中央银行每天发布的外汇参考汇率作为种子;以日期作为随机种子。
②一类基于字典生成的域名,该域名多为单词组合生成,从结构上看与合法域名较为相似。
每类DGA 代表的恶意域名家族见表1。
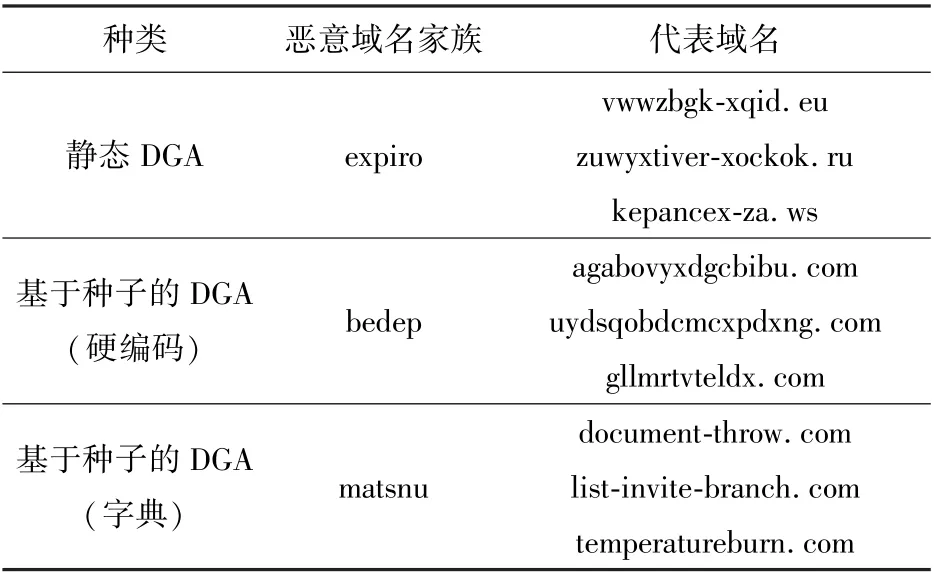
表1 域名生成算法分类
1.2 恶意域名检测技术
恶意域名检测研究主要分为2 类:基于流量分析和基于域名字符特征的恶意域名检测[4]。
(1)基于流量分析的恶意域名检测
基于流量分析的恶意域名检测方法[5]主要从域名使用者运用的Fast-Flux 和Domain-Flux 技术研究。 Fast-Flux 技术[6]用于应对防御者进行IP 限制策略,攻击者在拥有大量主机的基础上,为每个主机的IP 配置较小的TTL 值,实现恶意域名通过DNS解析IP 地址的快速转变,使防御者的IP 限制策略失效。 Domain-Flux 技术[7]使用DGA 生成大量的备用域名,只从中选取一个域名作为命令与控制服务器(Command and Control,C&C)的域名,该技术使得域名禁用的策略失效。
(2)基于域名字符特征的恶意域名检测
由于IP 地址不便于记忆,为了满足人们记忆和访问的需求,所以发明了域名,其本身包含丰富的特征信息。 合法域名使用的域名长度往往小于恶意域名的长度;参考英文单词的结构[8],合法域名的平均记忆字元数常小于恶意域名的对应值,并且合法域名中不常见到超过连续3 个的重复字母,而DGA生成的域名可能包括更多的连续字符。
使用机器学习方法的恶意域名检测常使用上述字符特征进行研究。 根据合法域名与恶意域名字符分布上的差异,Yadav 等[9]通过查看同一组IP 地址中域名的unigram 和bigram 特征分布检测恶意域名;Agyepong 等[10]根据字符分布的频率分析和域名加权分数的方法检测DGA;王红凯等[11]利用域名长度等特征提出了一种基于随机森林识别恶意域名的方法;Shi 等[12]结合字符特征、DNS 特征和网站的whois 信息使用极限学习机(Extreme Machine Learning,ELM)模型识别恶意域名。
传统机器学习的方法提取域名字符特征分析恶意域名工作量大,耗费的时间过长,并且该方法提取的特征可能会被DGA 使用者回避,如基于字典的域名生成算法产生的恶意域名不易被传统方法检测。深度学习方法较传统机器学习方法的模型更复杂,它可以挖掘数据集深层次的特征,能够从训练集中的有限特征集合中推导出新的特征。
赵科君等[13]利用word-hashing 技术[14]将所有域名转换为二元语法字符串,使用词袋模型将域名映射到了高维的向量空间,之后搭建5 层深度神经网络对转换为高维向量的域名进行训练分类检测。传统RNN 算法难以解决恶意域名实验中梯度扩散的情况,Xu 等[15]使用双向递归神经网络算法提取有效的语义特征,使用递归网络有效地解决了梯度扩散和梯度爆炸的问题。
恶意域名检测问题中,许多学者使用LSTM 模型,试图寻找域名中更多的特征。 Ghosh 等[16]使用改进的LSTM 模型,在传统LSTM 模型上加入ALOHA(Auxiliary Loss Optimization for Hypothesis Augmentation)[17],增加了对基于词汇生成的恶意域名的检测准确率。 徐国天等[18]为了解决独热编码中稀疏矩阵和维度灾难等问题,采用词向量嵌入对域名中的字符编码,并且融合卷积神经网络和长短期记忆网络训练恶意域名检测模型,提高了算法的效率。 张斌等[19]使用CNN 网络提取域名中字符组合的特征避免N-gram 的特征稀疏分布的问题,之后使用LSTM 挖掘域名字符串中的上下文信息。 王甜甜等[20]构建双向长短时记忆神经网络和卷积神经网络的混合模型BiLSTM-CNN,在其构建的待检测域名集合中实现了域名分类。 张鑫等[21]为了解决缩略域名上存在的误报率高的问题,采用LSTM 改进了Transformer 模型的编码方式,以更好地捕获字符位置信息,该模型能有效区分DGA 和缩略域名。
从上面的研究可以看出,学者们在DGA 的检测中,在对网络流量、DNS 解析信息、域名字符等信息统计的基础上,利用机器学习或深度学习算法进行恶意域名分类或恶意域名家族的聚类。 但对于某些恶意域名家族可能并不适用,并且攻击者会回避随机生成域名的特征,如suppobox 家族的域名。 面对这类域名,需要挖掘更好的统计特征,本文使用Ngram 模型,并运用包含注意力机制的Transformer 模型,该算法能较好地处理文本数据,可以有效地对恶意域名进行分类。
2 恶意域名检测模型
为了进一步提升识别恶意域名的准确率,本文基于Transformer 网络架构,提出了基于N-gram、word-hashing、特征增益的恶意域名检测方法,模型分为数据处理、模型训练、域名类别预测3 个阶段,从位置信息、字符特征等方面更深入地挖掘了恶意域名的特点,检测过程如图1 所示。
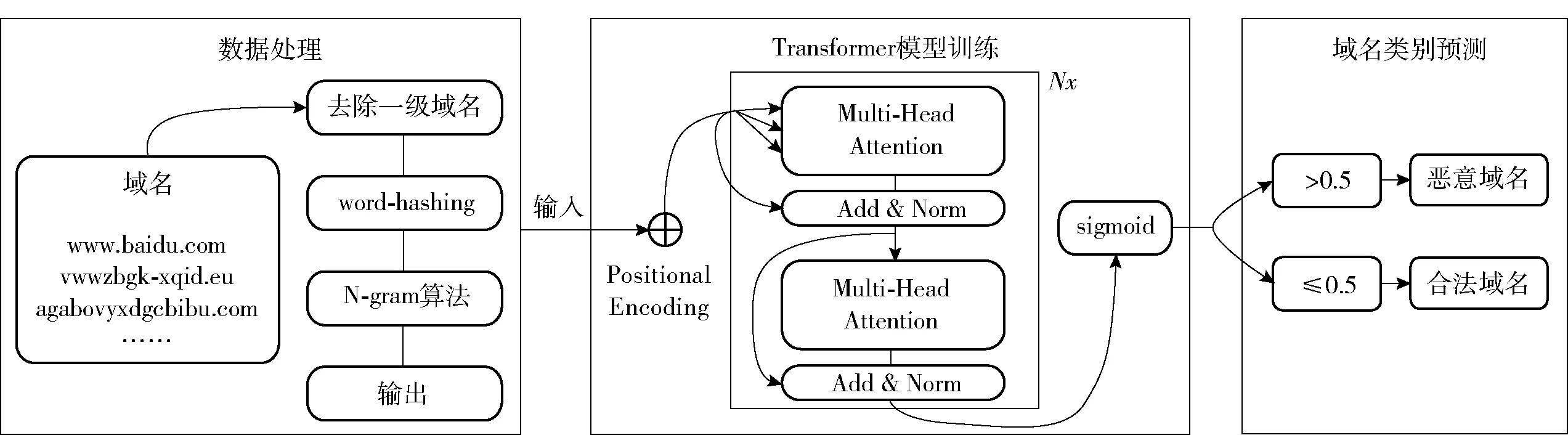
图1 模型检测流程
2.1 word-hashing
自然语言处理问题中,常使用one-hot encoding的方法将文本信息转换为深度学习可以直接使用的向量形式,但是其生成的向量非常稀疏,面对onehot encoding 产生的稀疏矩阵,常使用word2vec 技术将高维向量空间映射到低维向量空间。 因为恶意域名的样本单元以字符串为单位,没有上下文环境,会破坏域名的特征信息,所以word2vec 技术无法对恶意域名样本转换成向量后的空间降维。
本文采用word-hashing 技术的目的是降低词袋向量中的维数,word-hashing 技术基于N-gram 方法,对每一个字符串的首部和尾部添加一个符号标志位(如“#”),之后使用N-gram 方法处理,以域名“www.baidu.com”为例,处理过程如图2 所示。
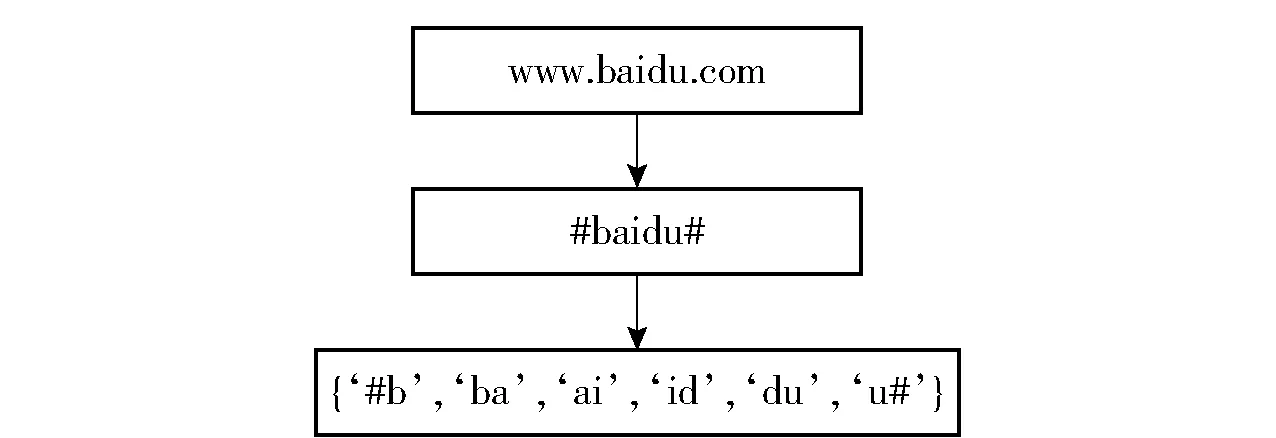
图2 word-hashing 算法处理“www.baidu.com”
因为英文字母是有限的,所以选择bigram 或trigram 算法产生的子字符串结果是有限的,其维度不会过大,相较于使用one-hot Encoding 方法会产生巨大的稀疏矩阵,选择N-gram 算法可以提高资源利用率。 针对恶意域名检测问题,基于N-gram 的word-hashing 方法将域名样本转化为向量,一定程度上节约了深度学习搭建时的内存损耗,并且特征模型不用随样本增加而修改。
2.2 N-gram
N-gram 是一种基于统计的语言模型算法,在自然语言处理的过程中实现了“联想”行为。 对于一个确定的字符串,N-gram 算法处理过的结果是该字符串所有长为N 的子字符串,对于域名“www.linkedin.com”,当N=2 时,处理过程如图3 所示。

图3 N-gram(N=2)算法处理“linkedin.com”
N-gram 算法认为一个单词的出现依赖其他的若干词语,因此可以用来判断一个句子的构成是否合理,并且,当获得足够多的信息时,所预测的信息越准确。
恶意域名检测中运用N-gram 算法以字母为最小单元,并且为了避免N-gram 结果冗余,仅使用二级域名作为模型的输入部分,将顶级域忽略。 假设我们现在有n个字母组成的域名s= (w1,w2,…,wn),每一个字母wi都与第一个字母w1到其前一个字母wn-1有关,如式(1)所示。
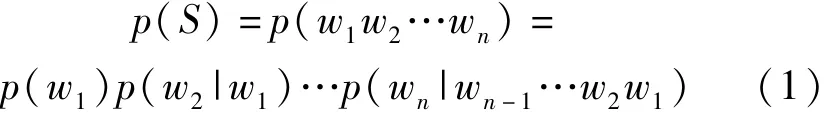
式(1)在运算过程中会带来过多的变量,同时对于N-gram 模型,在N取的较大时,得到的结果会十分稀疏。 为了解决这个问题,利用马尔可夫链的假设,第i个字母wi出现的概率仅与当前字母前N个字母有关,通过马尔可夫链的假设大幅缩减了式(1)的计算量,此时的情况如式(2)所示。

2.3 Transformer
Transformer 网络[22]是融入注意力机制的Encoder-Decoder 模型。 常见的Encoder-Decoder 框架使用RNN 网络实现,但因其依赖序列顺序特征,使训练不能并行进展,所以效率较慢。 在Transformer网络中,因为大量使用自注意力机制,该网络可以并行处理数据,并且自注意力机制在处理过程中,输入和输出都来源同一序列,能够很好地捕获全局信息。在恶意域名检测的应用中,并没有生成文本,所以主要用到了Transformer 结构中的Encoder 部分,本文使用的Transformer 结构如图4 所示。
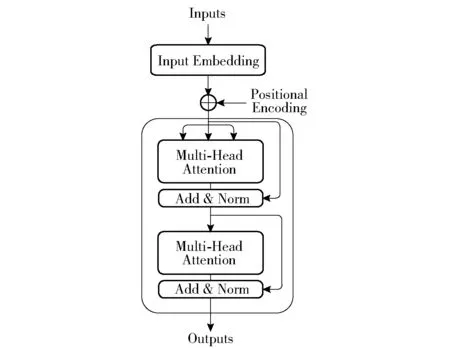
图4 Transformer(Encoder 部分)结构
在Transformer 网络中没有像RNN 中的顺序结构,所以需要元素的位置信息,位置信息的计算如式(4)所示。

其中,pos为字母在域名字符串中的位置,i是字母向量的位置,dmodel是字母向量的维度,在i为奇数时,使用cos 函数处理,i为偶数时,使用sin 函数处理。
Transformer 的核心是多头注意力机制,多头注意力机制由多个自注意力机制构成。 自注意力机制是将Q(Query)、K(Key)进行相似度计算,与V(Value)相乘后得到权重求和的过程,如式(5)所示。

其中,n表示多头注意力机制中的头数,Wo是线性变化的参数矩阵。
3 实验
3.1 数据集和测试环境
本文使用的数据集包括合法域名和恶意域名,合法域名来自Alexa 网站收集的排名前100 万的域名集合,恶意域名来自360 网络安全实验室公开收集的不同DGA 家族的恶意域名,例如nymaim、necurs等知名恶意域名家族的恶意域名共计100万条。
本文的实验基于keras 的深度学习框架,后端使用Tensorflow 模块。 具体的实验环境如表2所示。
表2 实验环境配置
3.2 数据处理
随机抽取合法域名和恶意域名各1 万条数据作为实验的数据集,对于每一个域名,因为合法域名和恶意域名一级域名的特征不明显,所以舍弃一级域名,构成数据集D1。
对于数据集D1,经过bigram 处理后共有1 417个词组元素,trigram 处理后共有31 220 个词组元素,4-gram 处理后共有127 469 个词组元素,5-gram处理后共有138 636 个词组元素。 对D1中的合法域名和恶意域名分别使用N-gram 算法,得到域名的词组元素分布如图5(a)和(b)所示。
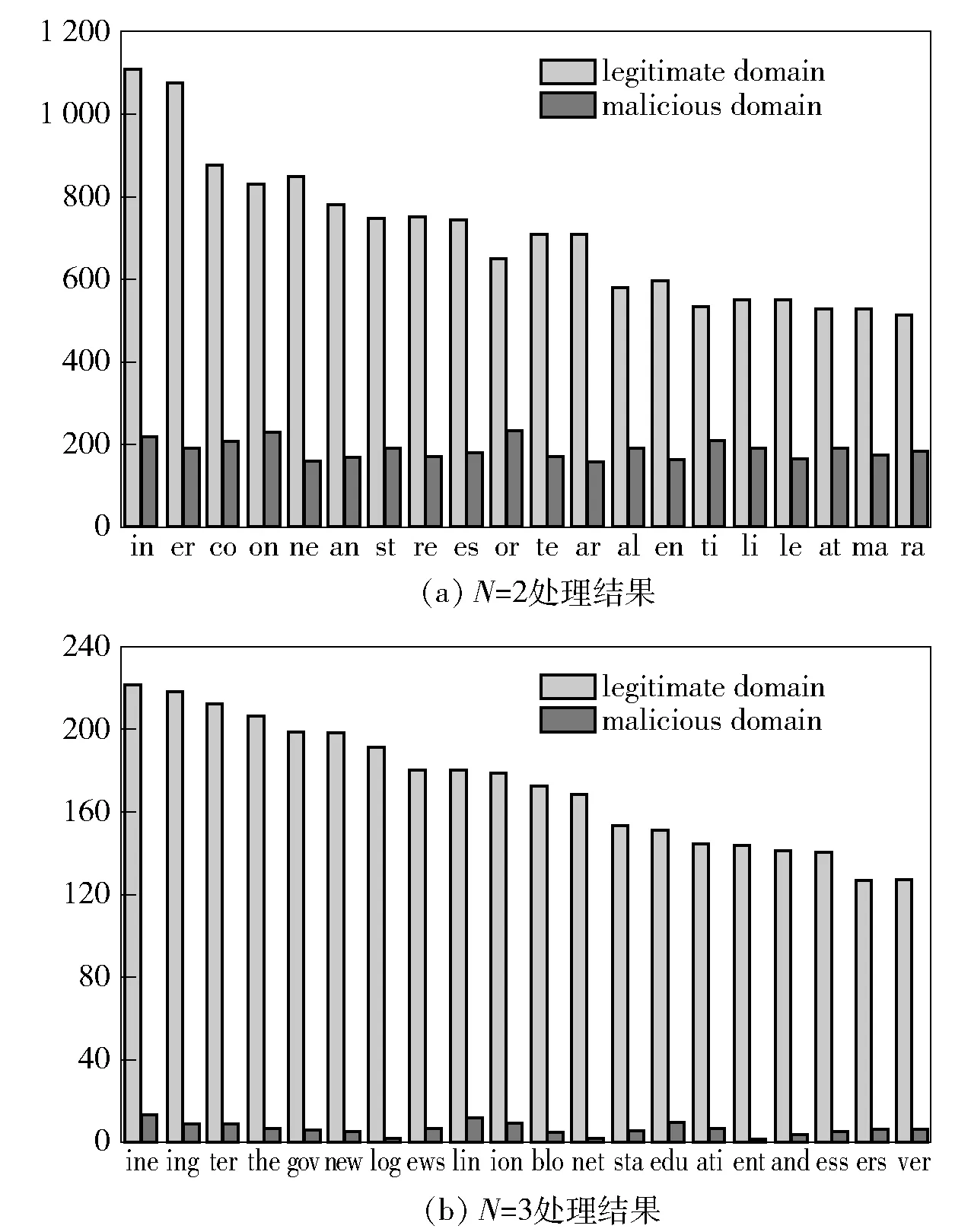
图5 合法域名和恶意域名词组元素频率的分布(部分)
由合法域名和恶意域名的N-gram(N=2,3)结果分布,可以看出DGA 生成的恶意域名的词组元素与合法域名分割的词组元素频率有很大的差异,同时恶意域名的词组元素分布较为均匀,而合法域名的词语元组分布差异很大,所以bigram 分割后产生的词组元素具有较好的域名分类特征。
N=4,5 时,由于词组元素位数增多,合法域名字符串已经可以看出明显的单词特征,而D1数据集中的恶意域名经过N-gram 算法处理后,不存在这些类词组元素的字符串,通过分析N-gram 算法处理后,词组元素的数字特征如表3 所示。
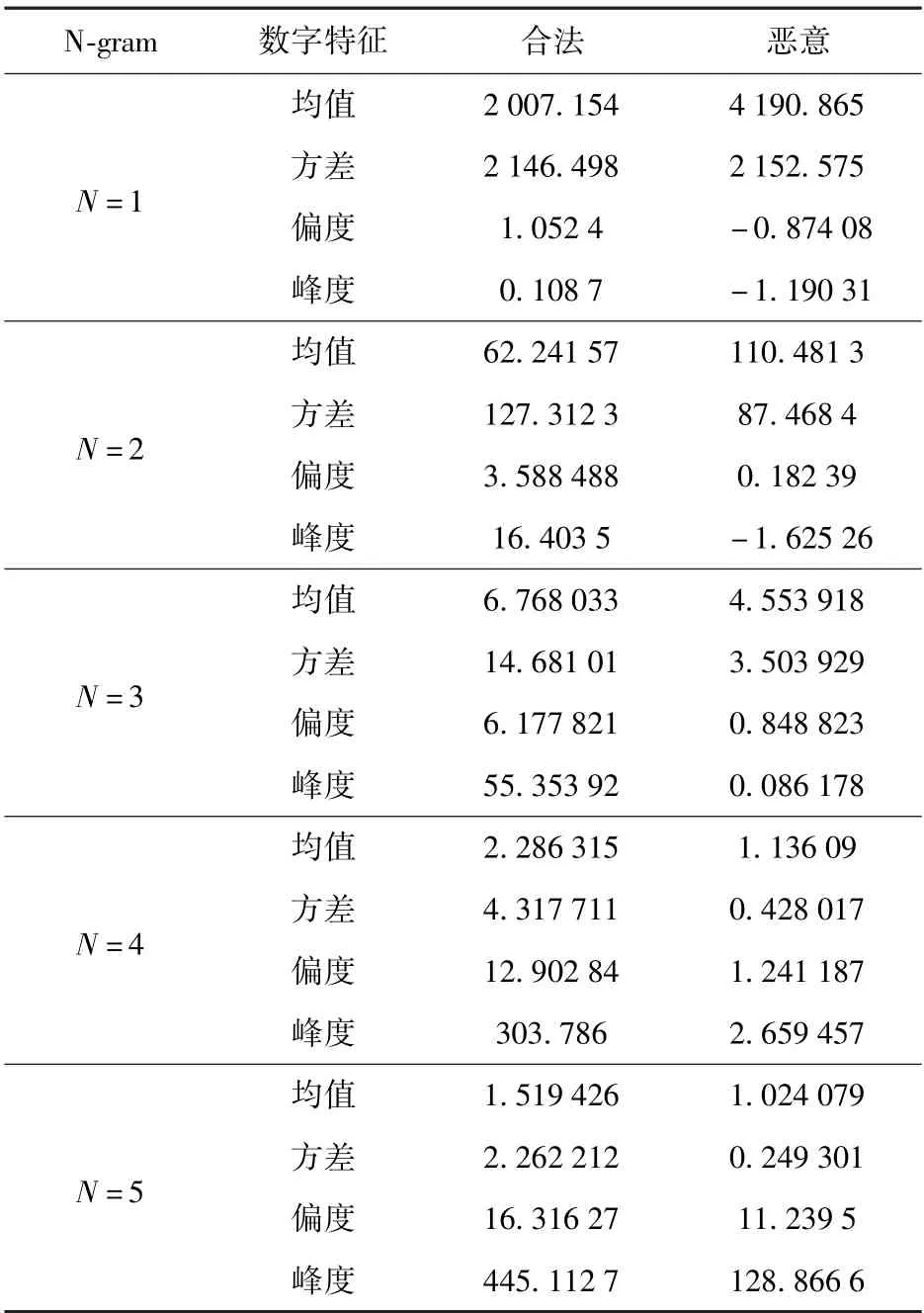
表3 N-gram 算法结果分析
分析中使用均值、方差、偏度和峰度作为数字特征的指标分析两类域名N-gram 处理后的结果。 均值是表示词组元素分布集中趋势的指标;方差能看出词组元素的数量变化趋势;偏度能够看出域名的词组元素分布是否对称;峰度能够得到域名词组元素数据分布相较正态分布的不同。
从表3 可以看出,除N=1 外,N-gram 处理后合法域名和恶意域名的词组元素具有相同的特征。 在N=2,3,4,5 时,恶意域名词组元素的方差均小于合法域名的词组元素,方差小说明域名词组元素分布的均匀,为随机生成的域名;方差大,则词组元素分布集中,是人为干预产生的域名。 恶意域名词组元素的偏度小于合法域名词组元素,在数据分布上,恶意域名较合法域名有更好的对称性。 从峰度来看,恶意域名的数据分布比合法域名的数据分布更贴合正态分布。
以bigram 处理后的数据为例,实验中使用word-hashing 技术,在每个二级域名的首部和尾部添加上标识符“#”,数据元素由1 417 个增加到了1 486 个,首尾标志的增加标注了域名的部分位置信息,在没有大幅造成冗余的同时,丰富了识别过程中的特征。 所以使用N-gram 算法和word-hashing 组合的数据预处理方法能够有效提取域名的字符频率和字符位置信息特征。
3.3 实验结果及分析
3.3.1 评价指标
实验中使用准确率(Acc)评价算法对域名的分类精度,使用召回率(recall)评价模型对恶意域名的分类情况,准确率的计算公式如式(8)所示。
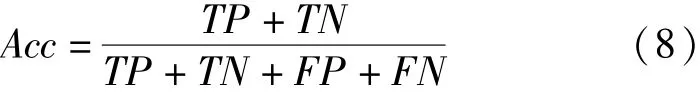
其中,TP表示恶意域名且被预测为恶意域名的数量,FN表示恶意域名但被预测为合法域名的数量,TN表示合法域名且被预测为合法域名的数量,FP表示合法域名但被预测为恶意域名的数量。
召回率的计算公式如式(9)所示。

由式(9)可以看出TP+FN为数据集中恶意域名的总数,所以召回率可以计算出模型对恶意域名的检测效果。
为了验证本文提出的基于bigram 和Transformer的框架检测恶意域名的结果,本文设计了4 组实验,以下实验均在keras 深度学习框架下,Tensorflow 后端和sklearn 模块中实现。
3.3.2 N-gram 算法对比实验
为了选择出效果更好的语言模型,对N-gram 技术中N的取值进行分析。 对于N≥3 时,虽然可以捕获更多的特征,对字符预测的能力也显著提升,但是在模型中产生大量的稀疏矩阵,容易导致算出的概率失真,并且参数空间很大会造成维数灾难,模型在训练时对时间和内存会产生巨大的损耗,导致实验不能顺利进行。 在原有N-gram 和Transformer 检测模型的基础上,使用基于L1 正则化的特征选择算法对特征进行优化,经过特征增益处理,除了实现筛选特征的目的,还对高维的矩阵进行了降维,大大降低了实验时间和内存损耗,使实验可行。
对N的取值进行测试,探究最合适的N的取值,结果如表4 所示。
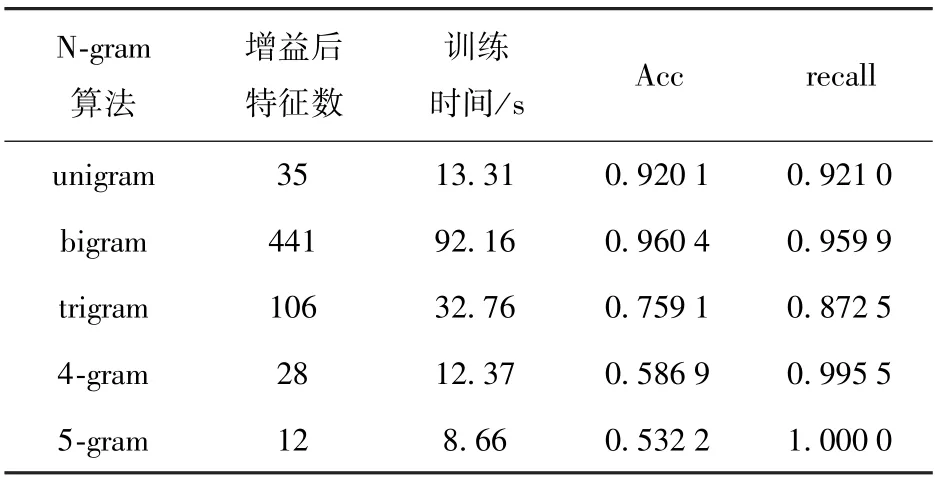
表4 N-gram 算法对比
实验结果表明,模型中使用brigram 处理数据得到的效果最好。 随着N值的变化,虽然得到的词组元素种类不断增加,但因为词组元素的基本单位在扩充,域名中符合同一种类的词组元素的数目必然减少,所以训练得到的有效特征减少。 以“linkedin”为例,其“li”词组元素在数据集D1中共有749 个,经过trigram 处理后,“lin”词组元素在D1中共有192 个,少于二元词组元素处理的结果。 同时,训练得到的模型识别的准确率不断降低,且召回率不断升高,说明发生了过拟合现象。
3.3.3 网络模型对比实验
数据集均用bigram 处理,将输出后的结果用经典的机器学习和深度学习算法进行比较,实验选取Nalve Bayesia 算法、XGBoost 算法、RNN 模型、LSTM模型与Transformer 模型进行对比,实验结果如图6所示。
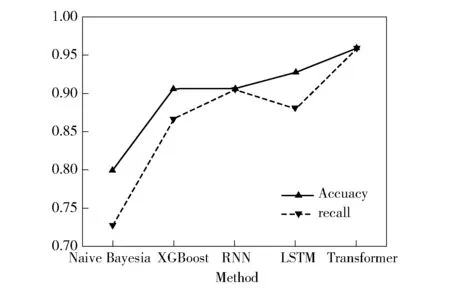
图6 模型训练算法对比
可以看出,由于Transformer 模型能够提取更多的字母的位置关系,同时使用多头注意力机制,算法能够捕捉更多的字词组合间的特征,所以在恶意域名分类问题上取得了较好的效果。
3.3.4 多头注意力head 对比实验
对于Transformer 模型中,head 的数量也会对实验产生影响,通过改变head 的值进行实验,实验结果如图7 所示。
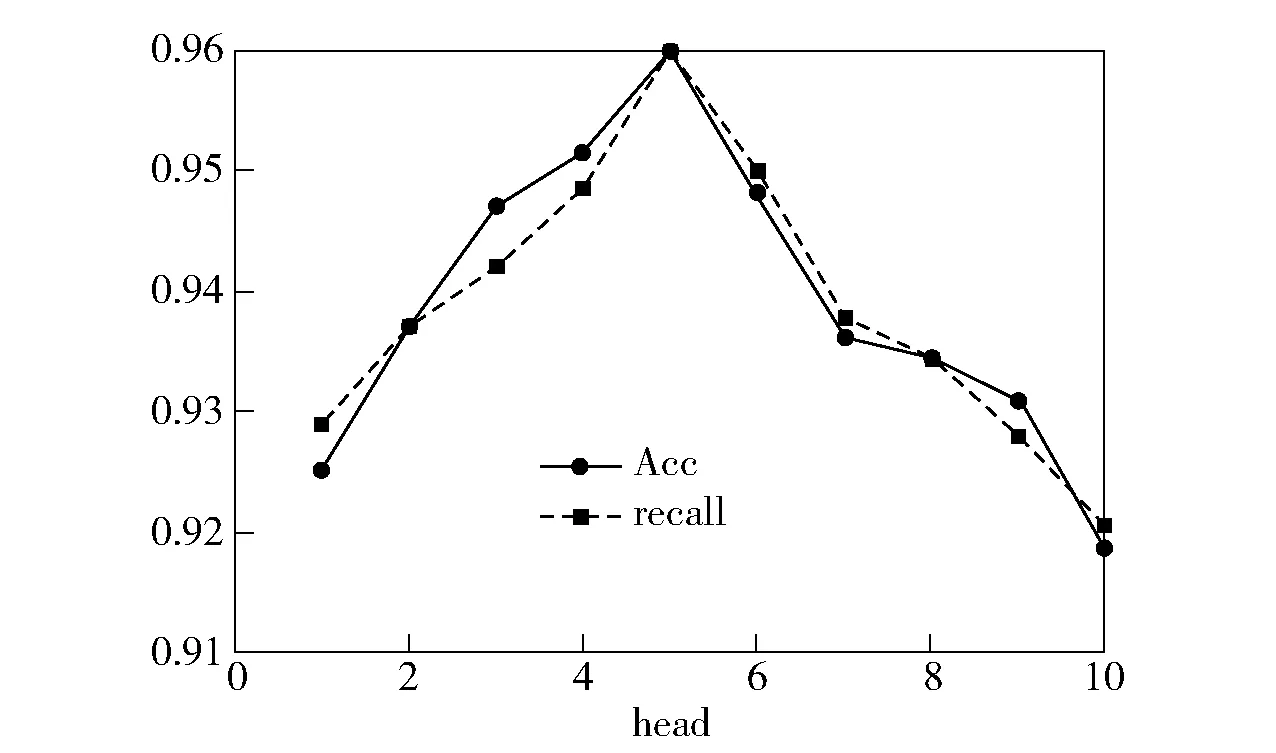
图7 准确率和召回率变化趋势
从图7 可以看到,当head 数量为5 时,模型的Acc和recall均达到最好效果,此时改变head 数量并不能对模型的检测效果有所提高,即增加对特征矩阵的线性映射的次数,无法在增加的线性空间内提取出有效的特征。 根据该实验结果,检测模型中head的值取5 时会使恶意域名检测效果达到最优。
3.3.5 消融实验对比
为了进一步验证检测模型中各部分对实验的影响,对本文提出的N-gram 和Transformer 恶意域名检测模型进行消融实验。 首先使用bigram 和Transformer 实验,为了验证word-hashing 的有效性,使用word-hashing 处理后的数据集进行恶意域名检测;之后通过增加L1 正则化,对特征增益前后的模型进行对比,验证特征增益对模型的影响,实验结果如表5所示。
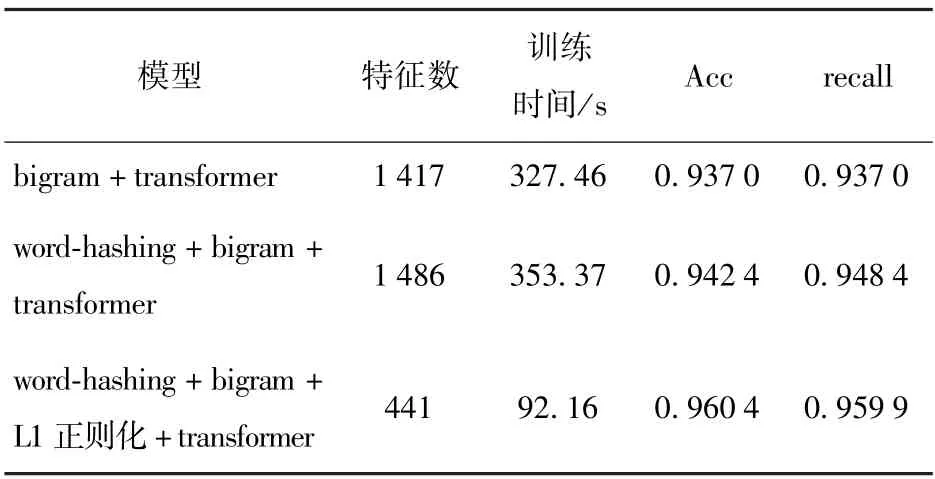
表5 消融实验分析
从表5 可以看出,使用word-hashing 可以增加域名字符串中的首尾位置信息,使模型检测的准确率和召回率小幅提升。 添加L1 正则化后,模型训练的时间大幅减小,同时,模型的准确率增加了1.80%,召回率增加了1.15%,结果表明,L1 正则化后增益的特征能够更准确地检测出恶意域名。
综上所述,本文提出的N-gram 和Transformer 框架可以有效、准确地检测恶意域名。
4 结语
针对现有恶意域名检测算法提取深层特征较少的现状,提出了N-gram 和Transformer 的深度学习框架,提高了域名内字母位置信息、字母间组合关系特征的提取效果。 针对恶意域名检测问题,本框架还有需要改进的方面,域名预处理尝试使用组合Ngram 的结果;对网络模型优化,使得更贴合恶意域名的应用场景,提高识别的准确率。
接下来将会挖掘字母间其他深层的特征,如,相邻的辅音分布、辅音元音组合的统计。 此外,针对对抗生成网络、文本生成算法[23]进一步研究,网络结构是否能抵御恶意样本的攻击也是今后研究的主要内容。
