生命意义感结构及其自适应测量:基于Bifactor模型
2022-10-18林靖凯涂冬波
林靖凯,涂冬波
(1.北京师范大学教育学部,北京 100875,2.江西师范大学心理学院,江西 南昌 330022)
0 引言
近年来,由于积极心理学兴起,所以对于“生命意义感”的研究热度逐步增加,而且社会竞争越来越激烈,这使得不少人感到压力剧增,在这快节奏的竞争中逐渐迷失自我,导致生命意义感缺失,这一现象也使得越来越多研究人员投入生命意义感的研究中.关于生命意义感,V.E. Frankl[1]认为“对意义的寻求是人类在生活中的首要动机”,人类有在生命中寻找意义和价值的内在需求,意义和目的感的缺乏会使人深陷痛苦[1-2];后来也有许多学者从不同角度对生命意义感进行论述,但一直以来没有得到一个统一的界定.直到2016年对生命意义感进行了总结,学术界才基本认可了生命意义感包含理解、目的和价值[3].
从积极心理学的意义出发,李金珍等[4]认为心理学有必要去关注在人性中的积极面,致力于帮助普通人生活得更健康、更美好,促进个人、团体和社会的繁荣.尽管人们的生存环境和内外在条件存在种种困难,但绝大多数普通人能过上一种相对满意的、有尊严的生活,而正是这些普通人构成了社会的基础.生命意义感是积极心理学的一个重要研究内容,对生命意义感测量方式的研究也符合积极心理学研究的价值导向;大量研究证实,生命意义感的缺乏会对个体或他人造成危及生命等严重后果.因此,为了减轻缺乏生命意义感的个体给自己或他人带来的伤害,生命意义感的测量、识别及诊断就显得十分必要.为此,国内外大量学者开发了相关的测评工具,这些量表所包含的维度、测量角度并不完全一致,相互之间存在些许差异,但目的都是生命意义感(或被称为生活意义感)这一特质.有些项目直接测量了生命意义感,有些项目并非直接测量生命意义感.如有些项目会对生命意义感的来源或对影响生命意义感的因素进行测量,并取得了较好的效果,从这方面可以看出生命意义感的测量是多元的.V.E. Frankl[1]表示生命可以从3个方面来获得意义:(i)从人们所给予生活的东西中获得,即从人们的创造物中获得;(ii)从人们对世界所求取的东西中获得,即从人们认为有价值的事情中获得;(iii)从人们对命运所采纳的立场中获得,这一立场是人们深信而不可改变的.盛正群[5]认为:从生存的悲剧性经验中、从痛苦、死亡和愧疚中也可以找到生命的意义.如从“相信生活有终极目的和意义”以及“致力于创造性工作”是从生命意义的来源等角度进行测量.又如“我有自己人生意义的理论体系,这使我真正懂得活着的意义”“我有清晰的人生目标和目的”“我认为自己的人生很重要”这3个项目就分别从生命意义感的理解、目的和价值[3]3个成分对生命意义感进行直接测量.另外,影响生命意义感的因素众多,如R.F. Baumeister[6]指出:生命的意义对个体的自我感和同一性起着重要的作用.缺乏意义和价值就会导致自我的分裂,这种情况通常会在边缘性人格障碍的患者身上发现,在生命意义感量表[7]中的“从兼职或学生工作等日常生活中,我更了解自己和肯定自己”“我在付出中获得了对于自我的肯定与喜悦”便是从该角度对生命意义感进行的测量.在以往对生命意义感的研究中,有研究人员认为其是一个1维结构,也有研究人员则认为其是多维结构.因此,生命意义感的测量结构有待进一步验证,而且结合以往量表测量角度的多元性和测量结果的相关性来看,有理由相信,生命意义感可能不是简单的1维或多维结构,而是含有一般因子和特殊因子的Bifactor结构,在这种结构中每一个项目都对应1个特殊因子和1个一般因子.本文利用计算机自适应测验题库体量大、内容覆盖面广的优势,试图从更全面的多元角度,探索一个更加有效合理的测量结构.
现有的量表是采用传统纸笔测验的施测手段,而且几乎都是基于经典测量理论(classical test theory,CTT)开发出来的.然而,传统纸笔测验存在一些先天性的局限,如为了使分数具有可比性,所有的人都必须回答相同的项目,这意味着被试常常需要回答与他们心理特质水平不匹配的项目,从而降低了测试的动机、兴趣及测量的精度.对于大学生生命意义感的监测(尤其是对生命意义感缺失个体的监测),需做到定期测量和长期追踪观察,很明显,传统纸笔测验很难做到这一点.因为每一次对传统纸笔测验进行测量,被试都要做相同的题目,在多次重复测量之后被试可能形成作答定势,所以很难排除过往测量的干扰;而且,传统纸笔测验题量较大,测量耗费大量的时间,对大学生群体进行普测也会耗费大量的人力和物力.
然而,计算机自适应测试(computerized adaptive testing,CAT)技术的产生能够很好地解决上述问题.CAT可以根据每位被试的反应情况和心理特质水平,智能地从题库中挑选出与被试特质水平相匹配的题目,从而做到对被试的自适应测量,即“千人千卷”的个性化测试.CAT在每次测量中只有少数题目曝光,大大延长了测验的使用寿命;同时CAT还能减少题长,减轻被试负担,提高了测试的动机和水平,并在一定程度上降低被试的厌烦情绪.总的来说,CAT是一种同时兼顾了测量效率和测量精度的新型测量技术,目前已被广泛应用于心理测评领域,如艾森克个性问卷(成人版)计算机自适应测验[8]、特质焦虑计算机化自适应测验[9]等.
因此,为了进一步克服目前国内外关于生命意义感纸笔测量的不足,本文拟在项目反应理论(IRT)框架下,采用CAT技术探讨生命意义感的计算机化自适应测验(CAT-MLM),以此来克服传统纸笔测验的一些缺陷;同时,本文还进一步验证了CAT-MLM的科学性及有效性,并且探讨了CAT-MLM对传统纸笔测验在测量信度及测量精度上的提升效果,这将为生命意义感的测量提供一种新视角和新技术.
1 方法
1.1 使用的量表
计算机化自适应测验的开发离不开大型的题库支持,本文CAT-MLM初始题库的项目主要来自通用的4个知名生命意义感量表[10-11],包含生活信念、生活热情、生活成就、生活目的和生活价值等5个子维度;生命意义感量表[7,12]包含意志自由、追求意义的意志和生命的意义等3个子维度;生活目的测试[13-14]包含生活感受、生活目标、生命态度和自主感等4个子维度;生命意义问卷[5,15]包含成就、人际关系、公平、追求、信仰、家庭、亲密关系、自我超越、自我接受和快乐等10个子维度.CAT-MLM初始题库共计109题,保留每个项目原始计分方式,同时本研究使用以上量表的中文版量表.
另外,还有一份效标量表,即人生意义问卷(meaning in life questionnaire,MLQ),它是由王鑫强汉化修订[16]的,该量表共10题,采用Likert7点计分,该问卷在美国和日本大学生样本中表现出良好的信效度[17].
1.2 被试
将在初始题库中所有项目组成的测验,通过网络问卷和纸笔测试的形式进行发放和回收,并根据该数据构建生命意义感题库.
被试来自中国30个省级行政区(澳门、天津、西藏和新疆除外)的大学生,共调查1 101人,删除10个项目以上未作答的被试82人.根据测谎题的作答与最佳答案的差值,3道测谎题差值总和最大的前5%删除,上述2种策略共删137人,剩余有效被试964人.被试年龄最小值为17,年龄最大值为29,年龄平均数为19.98(SD=1.51);男生人数为349,女生人数为615;大一学生人数为230,大二学生人数为294,大三学生人数为333,大四学生人数为107;文科学生人数为417,理工科学生人数为474,艺术与体育学生人数为46,医学学生人数为27;城镇学生人数为524,农村学生人数为440.
1.3 研究方法
1.3.1 实验1:CAT-MLM题库开发及CAT-MLM算法有效性验证 (i)基于Bifactor模型的因素分析.将964份有效数据随机分成数量相等的2份,分别作为探索样本和验证样本.利用探索样本进行探索性因素分析,以各项目的因素负荷作为指标,对题库的项目进行筛选.根据CFI、NNFI等拟合指标,选取拟合最好的模型,对验证样本进行验证性因素分析,并将该模型用于后续CAT的开发.
(ii)IRT模型选择.在IRT中,选择合适的IRT模型进行数据分析是保证数据分析结果准确的前提.本文采用常用的偏差(-2LL、AIC、BIC统计量)等[18-19]相对拟合指标进行模型拟合比较,以选择相对更拟合数据的模型.-2LL、AIC、BIC统计量的值越小表示模型拟合越好.本文考察的IRT模型主要有使用较广泛的等级反应模型(GRM)[20]和拓广分部评分模型(GPCM)[21],并从这2个模型中选择一个与实测数据拟合更佳的模型作为随后数据分析的IRT模型.
(iii)项目分析.对题库进行项目质量分析,以确保最终留在题库中的项目具有较高的质量.项目质量分析主要包括项目区分度、项目拟合度(item-fit)检验以及项目功能差异(DIF)检验.
项目区分度表示具有相似分数的人在潜在特质上的差异程度,为了保证题库的高质量,本文删除区分度过低的项目[22].
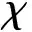
采用Logistic回归方法进行DIF检验,并使用McFadden′s pseudoR2的变化量进行评价,当R2的改变量大于0.02时,项目存在DIF[24].
(iv)CAT-MLM算法与效果验证.在建立完成CAT-MLM题库的基础上,对CAT-MLM的相关算法进行设置并检验其效果.CAT算法主要涉及初始题选取、选题策略、能力估计方法及终止规则等方面.本文CAT-MLM的初始题采用随机法选取,选题策略采用最大信息量法(maximum information,MI),能力参数估计方法采用期望后验方法(EAP),终止规则采用定长终止规则(即被试的用题量达到了事先设定的要求则终止测试).
实验1以CAT-MLM真实的题库参数以及真实被试在所有项目上纸笔测验的真实作答为基础,模拟真实被试在CAT-MLM上的自适应过程,从而检验 CAT-MLM的测量效果.真实被试共计964人,这些真实被试完成了题库中所有项目的纸笔作答,模拟被试在CAT-MLM上的自适应作答.目前在国际上有2种运用较广的双因子CAT 测验设计[25],本文采用Bifactor CAT[26]设计,具体过程如下:从第1位真实被试开始,进行其在一般因子上的CAT程序,第1题从题库中随机选取,并将该被试在纸笔测验中对该题的作答作为其在G因子CAT上的作答,根据该作答估计该被试特质水平,并根据估计的特质水平(θ)采用最大信息量的方法选取下一试题给被试作答,同样将该被试在纸笔测验中对该题的作答作为其在G因子CAT上的作答,…,依此进行直至达到了事先设定的终止规则,结束G因子的测试;在G因子CAT中已经被执行的项目同时测量了1个一般因子和1个特殊因子,根据被试已作答的项目估计被试在特殊因子F1上的水平值,并作为F1因子CAT的水平初始值,根据该水平初始值选择被试在F1因子上的所要作答的项目,然后采用与G因子CAT相同的方法进行F1因子的CAT选题与测试,直至达到F1因子的终止规则,结束F1因子的测试;以同样的方法,测试下一个因子;接下来其余被试依次按此方法模拟,直至完成所有被试在所有因子(包含1个一般因子和3个特殊因子)上的CAT-MLM测试.最后,将964位被试在CAT-MLM一般因子测试中估计的特质水平(θ1)与使用在题库中所有题目的纸笔测验所估计的特质水平(θ2)求相关系数,再计算964位被试在CAT-MLM各因子测试上的误差均值和边际信度,以考察CAT-MLM的测量效果.
同时,为了考察CAT-MLM的测量效度,964位被试还完成了在效标量表上的作答,将这964位被试在CAT-MLM一般因子上的测量结果与在效标量表MLQ上的测量结果进行比较分析,并求取其校标关联效度.
1.3.2 实验2:CAT-MLM对传统纸笔测验测量精度的提升 在CAT-MLM(一般因子)的测验长度与传统纸笔测验(即传统生命意义感量表)相同的情况下,实验2探讨CAT-MLM是否能提供比传统量表更高的测量精度以及更高的测量信度,即在相同测验长度下,CAT-MLM是否能显著提升测量的精度及信度,从而探讨CAT-MLM的性能及其优势.实验2选用了用于构建CAT-MLM的4个量表,即PIL、SLMS、MLM和PMP,它们的题数分别为20题、20题、23题、46题.因此在实验2中CAT-MLM的一般因子测验的终止规则分别设置为20题、20题、23题和46题.
实验2在CAT算法的选择上与实验1一致,实验2将在4种终止规则下CAT-MLM的结果与具有同等题长的传统量表的结果进行比较,重点比较它们的测量误差、测验信度和信息量,根据被试特质水平和测验对于被试的测量误差的关系做散点图,然后依据相同方法做特质水平-信度散点图和特质水平-信息量散点图,以此比较在相同题长下这2种测量形式对于不同特质水平被试的测量误差、测验信度和信息量差异.
1.4 分析软件
探索性因素分析(EFA)和验证性因素分析(CFA)均采用软件Mplus7,其余分析利用R语言的各种软件包进行,如模型选择和项目拟合检验等采用mirt包、DIF检验采用lordif包、CAT算法采用catR包.
2 结果
2.1 实验1:CAT-MLM题库开发及CAT-MLM算法有效性验证
2.1.1 因素分析 采用双因子模型(Bifactor model)对探索样本进行探索性因素分析,并在多个竞争模型(分别为2个、3个、4个和5个特殊因子模型)中选择出拟合指标最好的模型(3个特殊因子的Bifactor model),其比较拟合指数(CFI)为0.91、近似误差均方根(RMSEA)为0.034、标准化残差均方根(SRMR)为0.045,在删除因素负荷过低或为负的项目后,剩余92题;然后利用验证样本对该模型进行验证性因素分析,其CFI为0.90、RMSEA为0.035、SRMR为0.050,模型如图1所示(该示意图已将项目按照维度顺序重新编号).这一结构说明:目前国内外关于生命意义量表测量了1个共同因素(即整体生命意义感),同时包含了3个相对独立的特殊因素(即生活感受、生命意志以及生活价值).
2.1.2 题库建设 在尝试GRM和GPCM模型之后,GRM模型的-2LL统计量值为21 9687.6、AIC统计量值为221 095.5、BIC统计量值为224 524.8(这里-2LL是在logistic回归中的最大似然估计,AIC是赤池信息准则,BIC是贝叶斯信息准则),GPCM模型在经过500次迭代后,仍然无法收敛,这说明GPCM模型不适用于本研究.因此,选择GRM模型有助于后续的研究.

图1 CAT-MLM模型示意图
运用GRM模型进行参数估计,在92题中有5题区分度过低,为了提高题库的质量,将这5题删除,剩下87题.对剩余87个项目进行项目拟合检验,发现所有项目的显著性p值均小于临界值0.01.将男性作为参照组,女性作为目标组,考察项目是否存性别DIF.所有项目的McFadden′sR2变化量均高于临界值0.02,即项目在性别水平上均不存在DIF.最终的CAT-MLM题库构建完成,共包含87个项目.整个题库的平均区分度参数为1.46(SD=0.82),这说明整个题库具有较高的质量;同时项目的位置参数(难度参数)的取值范围为[-6.24,6.80],覆盖范围远大于能力值标准正态分布的“3σ原则”的区间(-3,3),适合测量不同特质水平的被试.结果如表1所示.

表1 在题库中各项目的来源
表1呈现了在最终题库中87个项目所测量的子维度,从表1可知4个原量表的所有子维度均有项目被纳入题库,即在题库中的87个项目测量了4个原量表的所有子维度.
2.1.3 CAT-MLM算法与效果验证 表2和表3分别为G因子和特殊因子(包括F1因子、F2因子、F3因子)基于真实被试模拟的CAT在定长终止规则下各项指标的结果,其中G因子的定长终止规则为做完20个项目即停止测试,F1、F2、F3因子的定长终止规则为做完属于本因子题库60%的项目即停止测试,表2和表3所呈现的指标结果可以反映CAT-MLM题库质量及其CAT算法的效果.表2包括了一般因子在定长终止规则下的平均测量误差、测量的边际信度,以及使用题库所有题目所估计的特质值与使用定长终止策略估计的特质值的相关系数和一般因子在定长终止规则下与效标量表MLQ的效标关联效度;表3包含3个特殊因子在定长终止规则下的误差均值和边际信度.
从表2可知:使用题库中所有项目对一般因子进行估计,其误差均值和边际信度分别为0.10和0.99,效标关联效度高达0.753,这也能够说明本文所开发的CAT题库有较高的质量.若使用20题定长终止为一般因子CAT的终止规则,则测验整体的误差均值和边际信度与使用整个题库基本相当,分别为0.15和0.98,在此终止规则下,估计出的特质值与使用整个题库估计出的特质值相关系数高达0.978,且效标关联效度为0.749,这说明使用此终止规则能够使测量结果稳定、精确、有效.
表3为该CAT的各特殊因子分测验的精度指标,F1、F2、F3因子的误差均值分别为0.34、0.37、0.45,均不大于0.45;3个因子的边际信度分别为0.89、0.86、0.80,均不小于0.80.
总之,实验1的结果说明CAT-MLM有较好的测量信度和效度,同时也说明CAT-MLM所采用的算法可行、科学,效果好.

表2 在定长20题终止规则下一般因子CAT的各项效果指标

表3 定长CAT的各特殊因子的测量误差和信度
2.2 实验2:CAT-MLM与传统纸笔测验的比较
实验2的结果如图2~图4所示.图2呈现了在相同测验长度下CAT-MLM(一般因子)和传统量表的测量误差散点图.图2结果显示:在题数相同的情况下,绝大多数被试在CAT上的测量误差比在传统量表上的测量误差更低,即CAT-MLM有效降低了测验误差.其中,与SLMS、PIL、MLM、PMP相比,CAT-MLM的平均测量误差分别降低了41.13%、39.30%、27.50%、29.20%.

图2 在各定长下CAT-MLM与其相同题数的传统纸笔测验的测量误差散点图
图3呈现了在相同测验长度下CAT-MLM(一般因子)和传统量表的测量信度散点图.图3结果显示:在测量题数相同的情况下,绝大多数被试在CAT上的测量信度比在传统量表上的测量信度更高,即CAT-MLM有效提升了测量信度.其中,与SLMS、PIL、MLM、PMP相比,CAT-MLM的边际信度分别提升了5.10%、4.41%、2.09%、1.43%.

图3 在各定长下CAT-MLM与其相同题数的传统纸笔测验的测量信度散点图

图4 在各定长下CAT-MLM与其相同题数的传统纸笔测验的信息量散点图
图4为CAT-MLM使用定长终止规则在各种题长下对于所有真实被试的信息量与其题长相等的传统纸笔测验量表对于所有真实被试的信息量的散点图.由图4可以看出:无论是传统纸笔测验量表还是计算机化自适应测验,对于生命意义感水平在[-2,2]上的被试都有较高的信息量.除了题数较多的PMP外,其余独立量表对于生命意义感很低的极端被试的信息量都较低(信息量低于25意味着测验标准误差大于0.2),而与其题长相同的CAT-MLM能够在生命意义感水平较低的被试群体中有较好的表现.相比传统纸笔测验量表,CAT-MLM对于生命意义感低的极端被试在测量信息量上有相当大的提升.从图4不难看出:在相同题长的情况下,对于在[-4,4]上的所有被试,CAT-MLM的信息量几乎大于任何一个传统纸笔测验量表的信息量.由此可见,CAT-MLM对于所有生命意义感水平的被试信息量都有所提升,尤其是对于生命意义感水平低于-2的极端被试,CAT-MLM更是有飞跃性的提升.
3 结论与讨论
本研究的目的是:探索出一个更有利于生命意义感测量,且拟合度更佳的测量模型,并依据此模型,建立一个基于IRT的生命意义感的计算机自适应测验(CAT-MLM),再验证CAT-MLM对传统纸笔测验在测验精度及测量信度上的提升.实验1基于964位真实被试的作答数据,运用Bifactor模型对所有项目进行探索性因素分析和验证性因素分析,最终选取在所有竞争模型中拟合最佳的模型,用于后续CAT的开发,最终选取的模型包含1个一般因子和3个特殊因子.在IRT框架下,通过项目拟合检验、项目功能差异分析等方法,最终选取了包括符合测量学要求且项目质量较高的87题来构建CAT-MLM题库.研究发现:在本实验开发的题库中拥有87个项目的CAT-MLM效果良好;使用定长终止规则和最大信息量选题法对真实被试进行模拟测量,一般因子的平均测量误差为0.15、边际信度高达0.98,一般因子的平均误差均不大于0.45、边际信度均不小于0.80,并且该CAT有良好的效标关联效度,能高效地对生命意义感进行测量.以上多方面结果说明本研究开发的CAT-MLM算法可行、科学、效果好.另外,从表1可以看出:所有原量表的子维度均有题目被保留下来,并纳入最终题库,各子维度的测量角度存在些许差异,但都测量了生命意义感这一共同因子.本文利用了CAT题库题量大、覆盖面广的优点,对生命意义感的测量结构进行了重新探索,本文构建的Bifactor模型在一定程度上说明生命意义感的测量是多角度、多元的,但最终都能有效测量生命意义感这个一般因子.从理论上分析,由于每个个体所处的外部环境和自己心理的内部环境都十分复杂,导致生命意义感的影响因素众多,所以生命意义感的测量内容十分多元.由于以往生命意义感量表的开发者有些从生命意义感本身进行直接测量,有些从生命意义感的来源或影响因素进行间接测量,所以以往量表的开发者开发出了测量角度差异较大,但测量目标高度重合,结果高度相关;从统计分析的角度看,对被试在原量表各子维度的得分进行相关性分析,结果发现这些子维度两两之间都具有显著的中度或高度相关.从理论和统计测量的角度都能有力地支持本研究所开发的Bifactor测量模型,也能解释Bifactor模型对生命意义感的测量为何有更好的拟合度.由于传统纸笔量表需要被试完成所有的项目,要考虑到被试的答题负担,所以要控制量表的题量,便难以同时涵盖如此多的测量角度,而将CAT运用于类似于生命意义感这种测量角度多元的特质的测量,就能显示出CAT题库内容覆盖面广的优点,由于生命意义涵盖广泛的内容与诸多因素相关,所以更广的覆盖面无疑能使生命意义感的测量有更好的效果,要有如此多元的测量角度和内容覆盖面,这是传统量表难以做到的.因此,尽管CAT-MLM从不同的测量视度出发,但是它们均是从直接测量和间接测量2个角度来测量人的生命意义感这一相同特质.综合这些结果也可以看出生命意义感不是简单的多维结构,而是一种被较少用于生命意义感研究的双因子结构,同时,也能够较好地解释长期以来生命意义感的结构和成分为何一直难以统一.实验2在与传统量表相同题长的情况下考察CAT-MLM是否能有效提高测量的精度及测量的信度.实验结果显示:与传统纸笔测验的量表相比,无论是测量误差、边际信度还是信息量CAT-MLM都有明显差异,CAT-MLM对传统纸笔测验量表的测量误差降低幅度最多达到41.13%,对传统纸笔测验量表的边际信度提升幅度最高达到5.10%.比较不同测量方式对于所有被试的信息量后发现:相比传统纸笔测量,CAT-MLM对绝大多数被试具有较高的测量精度,尤其是对生命意义感水平低于-2的极端被试的信息量有极大提升.
本文开发的CAT-MLM对于传统纸笔测量的测量精度有极大提升.CAT-MLM作为生命意义感的一种新的测量工具,利用其高精度、高效率和对生命意义感极低的被试十分敏感的特点,可以被用来较好地解决前文提到的对在大学生群体中缺失生命意义的个体的筛查问题,以识别出生命意义感水平过低的人,及早预防和干预,并对所有在校大学生进行定期普查.利用CAT-MLM进行普查的优势是速度快、效率高,同时CAT可以减少题目的曝光率,增长题库使用寿命,防止被试前后多次重复回答同样的题目,形成回答定势,导致测验准确度降低.而且,CAT-MLM能较好地弥补传统纸笔测量对于极端被试测量精度极低的缺陷,对于在普查中期望发现严重缺乏生命意义感的个体具有较高的敏感度,一旦发现生命意义感过低的学生,尽早采取必要措施,减少自残、自杀等悲剧事件的发生.
