结合深度强化学习的区块链分片系统性能优化
2022-10-18温建伟姚冰冰万剑雄李雷孝
温建伟,姚冰冰,万剑雄,李雷孝
1.内蒙古自治区气象信息中心,呼和浩特 010051
2.内蒙古自治区基于大数据的软件服务工程技术研究中心,呼和浩特 010080
近年来,随着人工智能、互联网、物联网的快速发展,数据呈现爆炸式增长,为了保证数据的安全性,区块链技术广泛应用于医疗、金融等各种领域。然而,当前区块链有着低的吞吐量和可扩展性的限制,大大限制了区块链的应用。区块链具有去中心化、安全、可扩展性三种特性,根据区块链的三难困境[1],任何区块链只能满足三个特性中的两个。所以,在提高区块链吞吐量和可扩展性的同时需要保证区块链的安全性。以上问题是当今社会的难题,是区块链领域的挑战。
目前,对于提高区块链吞吐量较为有效的方式是将分片技术应用到区块链中,并对区块链体系结构进行重新设计。因此,近年来学术界不断探索在改进的体系结构中利用分片技术的优化控制方法提高区块链吞吐量。目前对于提高区块链吞吐量的主要方法分为静态优化方法与动态优化方法。静态优化方法是指区块链采用分片技术时,使用的分片策略一直固定不变。采用静态优化方法的研究有文献[2-5]。以上研究对于区块链的分片选择均是静态策略,这不符合动态的区块链环境。因此,有研究提出动态优化方法,将分片技术与深度强化学习(deep reinforcement learning,DRL)[6]结合。根据动态的区块链系统环境采用动态的分片策略。将分片技术与深度强化学习结合的研究有文献[7-8]。
以上利用深度强化学习进行动态优化方法研究,大多数采用deepQnetwork(DQN)[9]算法,解决了静态的区块链分片策略的缺点。但是当行为维度扩大后,行为组合将会引起行为空间爆炸,采用基本强化学习DQN算法,神经网络难以训练,将会影响区块链的性能。为解决上述问题,本文提出了一种结合深度强化学习的区块链分片策略优化的方法解决动态区块链分片处理数据的问题。本文的主要贡献为提出了深度强化学习branching duelingQ-network(BDQ)[10]算法与区块链分片技术结合的方法,解决了区块链吞吐量低的问题,并且对行为空间进行扩大,实现了区块链分片系统的细粒度控制。本文将区块链分片问题建立为马尔科夫决策过程,提出了branching duelingQ-network shard-based blockchain(BDQSB)算法,解决了传统动态优化行为空间爆炸的问题。研究构建了区块链分片仿真系统,相比于使用DQN 算法,仿真结果表明,本文提出的BDQSB算法将区块链吞吐量提高了25%。
1 研究现状
分片技术可以有效的提高区块链吞吐量。分片技术可以分为静态分片与动态分片两类。典型的静态分片技术如Elastico、OmniLedger。Luu等人[2]提出了Elastico,是最早面向公有链的分片技术。Elastico 将PoW(proof of work)[11]协议与PBFT(practical byzantine fault tolerance)[12]协议相结合,节点首先通过PoW建立身份证明,然后节点被随机分到各个委员会中,由于每个委员会中的节点数量足够小,所以委员会每步可以完全运行片PBFT 协议。各个委员会中的节点并行处理事务,所以Elastico几乎实现了对吞吐量的线性扩展。OmniLedger[3]的整体架构是由一条身份链以及多条子链构成的。OmniLedger使用RandHound[13]协议,将所有节点分成不同的组,并随机将这些组分配到不同的分片子链。每个分片内共识采用PBFT协议。过移除块的全序要求,将块组织成有向无环图(directed acyclic graph,DAG)结构,增加了系统的吞吐量、降低了交易确认延迟。此外,OmniLedger 使用原子提交协议来处理跨分片交易,并使用账本剪辑技术,引入检查点,将检查点之前的历史数据进行裁剪,降低节点的存储压力。OmniLedger 实现了区块链吞吐量随着分片的数量线性增加。
在Elastico、OmniLedger 基础上对区块链系统架构进行改进并采用分片技术的研究成果,如Zillqa、Rapid-Chain。Zillqa[4]团队在Elastico 的基础上进行了架构和性能优化。在设计架构上,提出双链架构,另一条是交易链,一条是目录服务链。交易链上保存交易数据,目录服务链存放矿工元数据信息。在性能优化上,共识阶段Zillqa 借鉴了CoSi[14]多重签名技术,并用数字签名代替MAC,极大提升了PBFT 的扩展性,使得PBFT 可以适用于几百个节点,通过在PBFT中使用数字签名来提高效率。RapidChain[5]在OmniLedger 的基础上,加入了基于纠删码的信息分发技术来加快区块的传播速度,实现了覆盖通信、计算与存储的全分片技术,为了降低状态代价,RapidChain采用了Cuckoo协议,每次分片切换只需替换部分节点。Rapidchain 系统中主要包含三个重要阶段,分别是bootstrapping phase(引导启动阶段)、consensus phase(共识阶段)和reconfiguration phase(重构阶段)。Bootstrapping 阶段只会在在Rapidchain 系统开始时运行一次,这个阶段是为了创建一个初始随机源,并随机选出一个特殊的委员会,叫作参考委员会(reference committee),再由这个参考委员会的成员对节点进行随机分配,构成一个个分片委员会。
近年来,出现了一些优化区块链吞吐量的动态分片技术。动态分片技术解决了静态分片技术一直使用固定分片策略的问题。动态分片技术可以为动态的区块链环境提供动态的分片策略,使区块链吞吐量得到提升。DRL是一种典型的动态优化方法,可以为复杂的区块链系统决策问题提供行为策略。Yun等人[7]提出了一个基于分片的可扩展区块链系统,在保持高安全级别的同时优化吞吐量,将分片技术与深度强化学习算法相结合,将区块链分片选择过程抽象为马尔科夫决策过程(Markov decision process,MDP)[15],提出了基于分片的深度Q网络区块链所使用的分片协议(deepQnetwork shard-based blockchain,DQNSB)模型。分片技术不断将挖掘任务委托给其他节点。通过调整分片数量,可以主动改变安全级别。采用深度强化学习的方法来优化区块链的性能,以满足大规模和动态的物联网操作。特别是,在DRL框架的基础上,将信任的概念融入到共识过程中,通过监控每个epoch的共识结果来估计网络的恶意概率。基于网络信任,计算安全分片的数量,并采用自适应控制保持最优吞吐量条件。Zhang等人[8]提出了一种区块链与强化学习结合的天空链。一种新型的基于动态分片的区块链框架,在不影响动态环境下的可扩展性的前提下,实现了性能和安全性的良好平衡。首先,提出了一种自适应分类账协议,以保证基于动态分片策略的分类账能够有效的合并或分割。然后,为了优化高维系统状态的动态环境下的分片策略,提出了一种基于深度强化学习的分片方法。构建了一个从性能和安全性方面评估区块链分片系统的框架,通过调整分片间隔、分片数和块大小,使系统的性能和安全达到长期的平衡。深度强化学习可以从以往的经验中学习区块链分片系统的特点,并根据当前的网络状态采取合适的分片策略,获得长期的回报。
以上基于DRL 的动态分片技术,普遍采用基本的深度强化学习算法DQN,采用DQN算法解决了状态空间爆炸问题。但是,当行为维度增大导致行为空间爆炸时,使用DQN算法会使神经网络无法训练。
2 问题描述
在区块链网络中,网络中的客户端将事务请求发送给区块链网络中的所有节点,区块链网络中的节点进行分片来对事务进行并行的处理。首先,根据区块链中节点解决一个工作量难题(PoW)的速度快慢,在区块链网络节点中选择出解决PoW快的一定数量的节点组成目录委员会,目录委员会中的节点是对最后所有片内产生的区块进行最终的打包处理。选择完目录委员会中的节点后,区块链中其余节点进行分片,根据节点的ID将区块链中的节点分成K片,对事务进行并行处理,片内节点将事务打包成区块,验证完成后,发送给目录委员会,目录委员会进行最终打包,打包成最终块,验证通过后上传到区块链上,同时将打包的最终块信息返回给所有片内节点,片内节点进行信息更新。
区块链网络中的节点进行分片时,静态的分片策略不能有效的处理动态的区块链环境。针对当前的问题,可以通过将深度强化学习算法加入到区块链系统中,将区块链中分片问题建立成马尔科夫决策过程,为区块链系统每次进行分片提供合适的分片策略,达到处理事务的最大吞吐量。
3 区块链分片问题的马尔科夫决策过程
区块链网络中节点分片的选择是序贯决策过程,本文将分片的选择问题建模成马尔科夫决策过程。其中包括状态空间、行为空间和奖励函数。


行为空间:通过对区块大小、出块时间和区块链分片数量的选择来实现对区块链网络中节点进行分片,并行处理事务。本文将区块大小、出块时间和区块链分片数量定义为离散的行为空间,在t时刻区块链网络中的区块大小为B、出块时间为TI、区块链分片数量为K,行为空间定义为A={B,TI,K}。
奖励函数:奖励表示在当前状态下采取行为所获得的收益。本文的优化目标是提高区块链每秒处理事务的数量。因此定义奖励函数为:

其中,α表示学习率,为常数。Q-learning 方法将所有状态和其对应行为存储在Q表中。当状态空间和行为空间维数很大的时候,此方法对于处理高维度问题难以实现,主要原因是计算机内存无法存储Q表,而且每次在Q表中搜索十分消耗时间。
4 基于深度强化学习的区块链分片算法
4.1 算法设计
基于深度强化学习算法的区块链分片选择逻辑如图1 所示。强化学习智能体通过神经网络输出对应行为的Q值来选择相应的区块链分片行为at;将分片行为执行到区块链系统环境中,环境产生下一个状态st+1,获得产生的奖励R。将智能体与区块链系统环境交互产生的经验(st,at,st+1,Rt+1)存储到经验池D中,对神经网络进行训练。

图1 算法的逻辑结构Fig.1 Logical structure of algorithm
本文将深度强化学习branching duelingQ-network(BDQ)算法运用到区块链分片系统,提出了基于分片的分支决斗Q网络(BDQSB)算法。BDQSB 算法相较于DQN算法的优势是解决了行为空间爆炸以及行为空间爆炸导致神经网络难以训练的问题。本文提出的BDQSB算法在每一个决策时刻t将系统的状态st=(R,C,H,P)作为输入,输出行为at=(B,TI,K)。
求解问题公式(1)使用深度强化学习算法的步骤如下。

算法1的第1步为初始化经验回放池D,用于存放agent 与区块链环境进行交互产生的经验样本,用来训练神经网络。算法的第2 步初始化两个结构相同的神经网络以及两个网络的权重参数,将当前区块链系统环境的状态输入到神经网络中可以得到预测的区块链分片行为。算法的第4~7步中第4步是得到当前时刻区块链系统环境的状态st=(R,C,H,P),用于输入到神经网络中得到分片行为。第5步神经网络输出3个子行为的优势函数和状态值函数,将子行为的优势函数与状态值函数相加得到行为分支的Q值。
在权衡开发与探索二者之间,根据ε-greedy 策略(ε-greedy 策略是一种常用的策略。其表示在智能体做决策时,有一很小的正数ε(<1)的概率随机选择未知的一个动作,剩下1-ε的概率选择已有的动作中动作价值最大的动作),选择每个行为分支中对应Q值最大的子行为组成最终环境所执行的分片行为at=(B,TI,K)。根据概率ε在行为空间中随机产生行为。在算法进行探索行为初始阶段ε的值较大。随着算法的不断迭代,ε逐渐递减,算法倾向于选择神经网络生成的行为。第6 步将得到的行为at=(B,TI,K)输入到区块链系统环境中,根据第三个子行为K,区块链节点进行分片,根据第一个子行为B和第二个子行为TI,节点并行处理事务,产生区块。目录委员会将最终块上传带区块链中,区块链系统环境进行状态转化,得到下一个状态st+1=(R,C,H,P)。第7 步环境执行行为前的状态转变成执行行为后的状态,得到环境的下一个状态和环境对于执行行为的奖励r,即处理事务的吞吐量。第8步将agent与区块链系统环境进行交互产生的样本存储到经验池中,用于对神经网络的更新。
在时间复杂性方面,BDQSB 算法在选择神经网络输出的行为时(算法第9 行)只需要对Q网络进行前向传播,其复杂度为O(1)。在训练Q网络时,时间复杂度与梯度下降的次数相关。在神经网络结构的复杂度方面,神经网络输出层共有 |B|+|TI|+|K|个输出。在5.3节中,将进一步从实验角度比较不同方法的时间成本。
4.2 Q 函数近似
DQN 方法解决了状态空间爆炸的问题,但是当行为空间爆炸时,DQN方法存在神经网络输出复杂、难以训练的缺点,因此文献[4]对DQN 进行改进,提出了branching duelingQ-network(BDQ)。如图2为BDQ的神经网络结构。相较于传统的DQN 算法,BDQ 算法提出了一种新的神经网络结构,行为空间有几个子行为就对应几个网络分支,并且具有一个共享的决策模块。BDQ算法为每个单独的动作维度提供一定程度的独立性,可扩展性较好。BDQ算法将区块链状态st=(R,C,H,P)输入到神经网络中,状态经过共享模块(即神经网络的隐藏层)进行抽象,输出分为两个分支,分别为状态分支和行为分支。行为分支输出每个子行为的优势函数A1(st,a1),A2(st,a2),A3(st,a3),状态分支输出状态值函数V(st),将子行为的优势函数与状态值函数合并得到子行为的Q函数,区块链分片系统决策时,根据输出的每个子行为Q值来选择相应的行为。
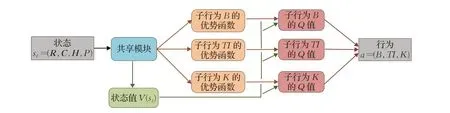
图2 BDQ的神经网络结构Fig.2 Neural network structure of BDQ
将BDQ 算法引入4.1 节算法1 中,其中第9 步的更新过程是在经验池中随机抽取minibatch 大小的经验,使用梯度下降的方式更新神经网络参数。BDQ对lossfunction的更新公式为:

BDQ算法中有两个结构相同的神经网络,其中online network 网络实时更新,targetnetwork 每隔C步更新一次,将online network参数值赋给targetnetwork。
5 仿真实验
5.1 仿真系统
本文所构建的区块链仿真系统中包括200 个区块链的节点。
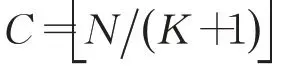

图3 区块链分片仿真系统结构Fig.3 Simulation system structure of blockchain sharding
5.2 实验参数
算法中的神经网络设计为四层全连接网络,其中3个隐藏层神经元个数分别为256、128、64。激活层函数使用的是ReLU。优化器使用RMSprop,学习率为0.05。在实验中,将前1 000步设置成算法的探索步数,1 000步以后,探索率ε以每步0.01的方式增加,一直增加到0.9。
其他参数应用自文献[13]的实验,实验参数如表1所示。

表1 算法的主要参数Table 1 Main parameters of algorithm
5.3 算法性能评价
如图4对比9组策略的平均奖励,9组策略分为6类。
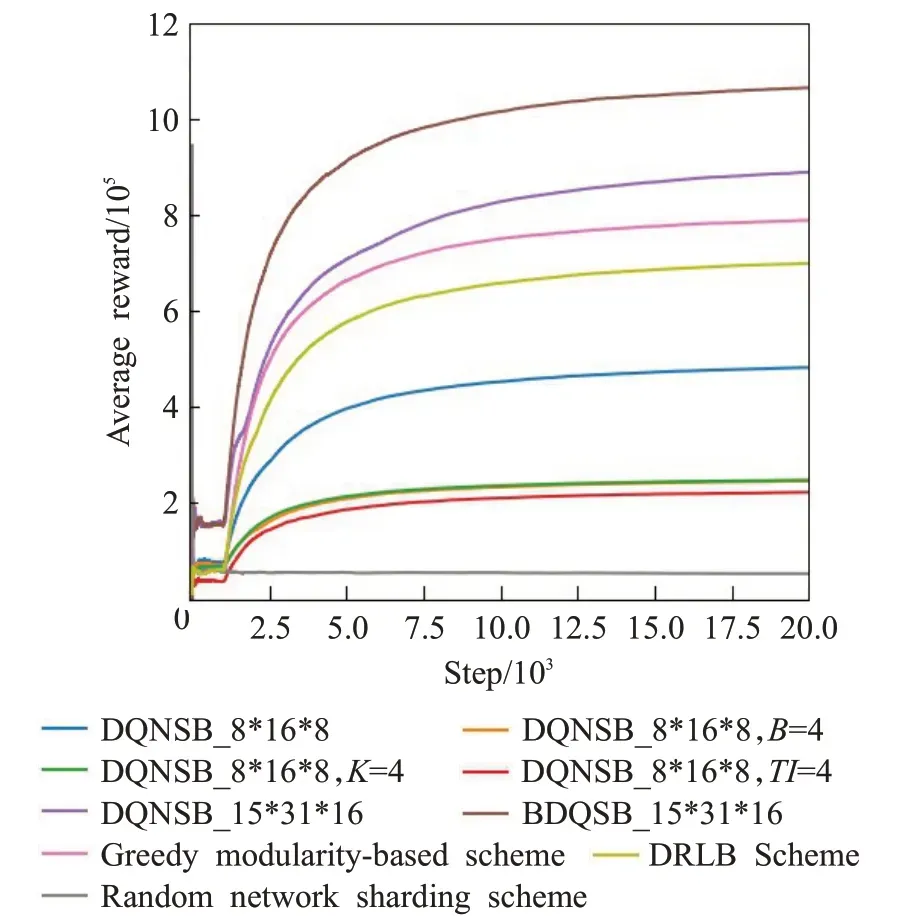
图4 平均奖励Fig.4 Average reward
(1)动态DQNSB 策略,包括DQNSB_8*16*8 和DQNSB_15*31*16。DQNSB_8*16*8策略中3个子行为B、TI、K的可选范围分别为[1,8]、[1,16]、[1,8]中的整数离散值,3个子行为的取值间隔都为1,行为空间大小为1 024。DQNSB_15*31*16是扩大行为空间后的策略,3个子行为B、TI、K的可选范围分别为[1,8]、[1,16]、[1,16],子行为B,TI的取值间隔为0.5,子行为K的取值间隔为1,行为空间大小为7 440。
(2)半动态DQNSB 策略,分别为DQNSB_8*16*8,B=4、DQNSB_8*16*8,TI=4 和DQNSB_8*16*8,K=4,是将动态策略DQNSB_8*16*8 的3 个子行为的值分别固定。
(3)本文提出的动态策略BDQSB_15*31*16。BDQSB_15*31*16策略空间大小、行为的取值范围和取值间隔与DQNSB_15*31*16策略相同。

(5)Random network sharding strategy[17]是完全随机选取行为的策略。
(6)DRLB[18]策略,是一个基于DRL(深度强化学习)的算法,动态选择区块链中区块生产者、共识算法、区块大小和出块时间来提高区块链系统的性能。
从图4 可以看出,使用半动态策略进行的3 个实验所得到的平均奖励曲线明显低于相同行为空间使用动态策略DQNSB_8*16*8 得到的平均奖励曲线。说明使用深度强化学习算法对区块链节点进行分片,可以对吞吐量进行一定的提升。图4 中DQNSB_15*31*16 曲线与DQNSB_8*16*8 曲线比较显示将行为空间扩大约7倍后,采用DQNSB算法得到的平均奖励曲线,比没有扩大行为空间前的奖励大约提升了2 倍。说明细分行为后扩大行为空间能够提升区块链处理事务的吞吐量。从图4 中DQNSB_8*16*8 曲线、DQNSB_15*31*16 曲线和BDQSB_15*31*16 曲线可以看出,使用BDQSB 算法得到的平均奖励比行为空间为1 024 的DQNSB 算法提升了大约2.5 倍,比扩大后行为空间为7 440 的DQNSB算法提高了约1.25 倍,说明BDQSB 算法能使神经网络得到更好的训练,区块链系统能够得到更好的行为。其余3 组 实 验greedy modularity-based stratgy、random network sharding strategy 和DRLB 策略,仿真结果表明,与以上3组实验相比,使用BDQSB算法将区块链吞吐量分别提升了大约1.6 倍、24 倍和1.7 倍。说明本文提出的BDQSB 对于区块链分片吞吐量提升是更好的策略。
本文比较了BDQSB算法与DQNSB算法[13],DQNSB算法解决了状态空间爆炸的问题,算法中利用神经网络对Q函数进行近似。若行为每个维度可选离散值较少,则可缩小Q网络的输出数量,但是可能会导致算法的性能不佳,反之亦然。
表2 中有3 组行为策略,其中DQNSB_8*16*8 策略和DQNSB_15*31*16 策略采用的都是DQN 算法,其区别是第二个策略比第一个策略在行为空间上对行为粒度划分的更细。使用DQNSB_8*16*8策略时,神经网络输出数量为|B|×|TI|×|K|=1 024。与第一个策略相比,第二个策略对子行为B,TI的取值划分更加细粒化。子行为K的取值范围相较于第一个策略扩大了1 倍。行为空间扩大后,使用DQNSB_15*31*16 策略时,神经网络输出数量为 |B|×|TI|×|K|=7 440。BDQSB_15*31*16 策略行为空间划分与DQNSB_15*31*16 策略相同。因为BDQSB_15*31*16 策略使用的是BDQ 算法,神经网络输出的数量为 |B|+|TI|+|K|=62。

表2 不同算法采用的行为空间Table 2 Behavior spaces used by different algorithms
图5~7 显示在数量为7 440 的行为空间中,使用DQNSB 算法和BDQSB 算法训练20 000 步后,3 个子行为在不同算法中的平均值。从图5 子行为B的平均值可以看出,BDQSB 算法在算法运行期间子行为B的平均值比DQNSB 算法行为B的平均值大约高8%,子行为B表示区块的大小,说明使用BDQSB算法处理的事务更多。从图6 子行为TI的平均值可以看出,BDQSB算法的子行为TI比DQNSB 算法所获得的子行为TI少7%,子行为TI为区块产生时间,说明使用BDQSB算法处理数据所用时间更短,处理数据更快。从图7子行为K的平均值可以看出,BDQSB算法行为中的K也高于DQNSB 中的行为K值,说明使用BDQSB 算法区块链网络分片更多,处理事务更多。综上所述,BDQSB算法比DQNSB 算法能使区块链的吞吐量得到更大的提升。

图5 子行为B的平均值Fig.5 Average value of sub-beha vior B
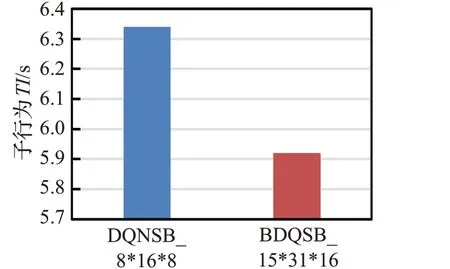
图6 子行为TI的平均值Fig.6 Average value of sub-behavior TI

图7 子行为K的平均值Fig.7 Average value of sub-behavior K
表3 是不同算法的神经网络训练的时间成本。从表3 可以看出,random network sharding strategy 是完全随机选取行为的策略,不需要训练神经网络,因此没有训练神经网络的时间成本。greedy modularity-based stratgy是只关注当前奖励不考虑未来的策略,该策略时间成本比使用BDQSB_15*31*16策略的时间成本短,但是提高区块链性能的效果不如BDQSB_15*31*16 策略好。虽然在行为空间较小时使用半动态策略DQNSB_8*16*8,B=4、DQNSB_8*16*8,K=4、DQNSB_8*16*8,TI=4 和动态策略DQNSB_8*16*8 的时间成本比使用BDQSB_15*31*16策略的时间成本短,但是与BDQSB_15*31*16 策略相比没有更好地提高区块链的性能。在使用DQNSB_15*31*16 策略和DRLB 策略时的时间成本比使用BDQSB_15*31*16策略的时间成本多,而且在提高区块链性能方面也不如BDQSB_15*31*16 策略。在BDQSB 与所有策略相比后,说明BDQSB 策略不仅能使神经网络训练的时间成本减少,同时还提高了区块链的性能。
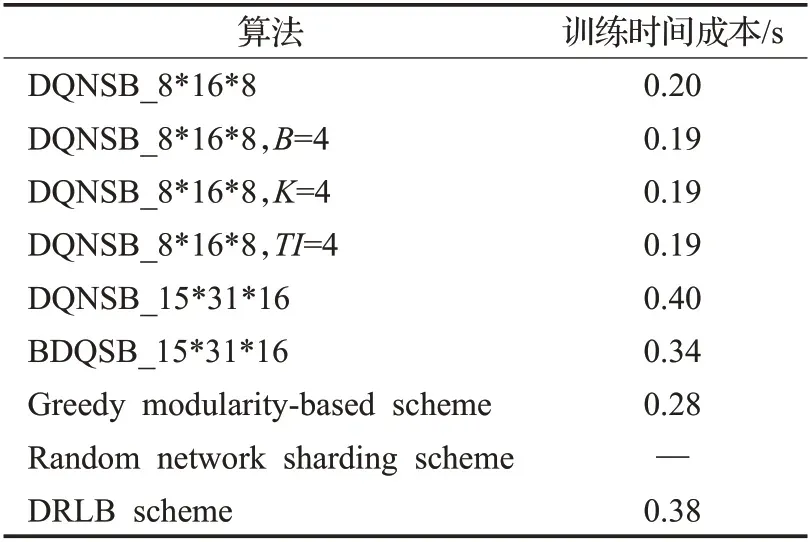
表3 不同策略的时间成本Table 3 Time cost of different strategies
6 结束语
本文研究了区块链通过进行分片并行处理事务来提高区块链吞吐量的问题,将区块链分片问题抽象为马尔科夫过程决策过程,并设计了一种基于BDQSB 的区块链分片选择算法。通过实验将BDQSB 算法与DQNSB 算法在不同的行为空间上进行了对比,结果表明基于BDQSB算法的区块链处理事务的性能明显优于使用DQNSB 算法。实验结果显示,使用BDQSB 算法区块链能够处理更多事务的同时提高处理事务的速度。本文研究的内容为区块链提升吞吐量性能提供了参考,提出的方法对将区块链应用到更多的领域,具有重要的实际意义。
