联合注意力机制与MatchPyramid的文本相似度分析算法
2022-10-18孙海春朱容辰孙天杨
代 翔,孙海春,朱容辰,孙天杨
中国人民公安大学 信息网络安全学院,北京 100038
文本相似度计算是自然语言处理领域的核心技术之一,在自动问答系统、信息检索、自动文本摘要、文本分类等自然语言处理的任务中都有着广泛的应用[1]。随着深度学习的迅速发展,文本相似度计算方法层出不穷,孪生网络结构是文本相似度计算常采取的一种网络结构,将两个文本分别输入到两个子网络中,子网络常采用卷积神经网络或者长短期记忆网络,通过这两个独立的子网络分别对两个文本进行特征提取,然后将子网络输出的特征向量采用曼哈顿距离等距离度量方法进行计算即得到两个文本的相似度得分。这种以孪生网络为主体的文本相似度计算方法,善于捕获单文本内部的特征,但文本之间没有产生交互,因而完全忽略了文本之间的关联信息。之后,注意力机制被引入到文本相似度计算当中用来建模文本之间的交互信息,例如给定以下两个文本:
A:He said the foodservice pie business doesn’t fit the company’s long-term growth strategy.
B:The foodservice pie business does not fit our long-term growth strategy.
当对A 句中“foodservice”进行编码时,注意力机制可以使我们看到B句中各个单词对“foodservice”的影响力,影响力越高,对A句中“foodservice”进行编码的过程中贡献度就越大。通过这种方式,使两个文本在编码过程中融入彼此的信息从而产生交互。MatchPyramid 模型提出一种新颖的交互方式,其在编码过程中使两个文本词向量矩阵进行点积,将两个文本融合为图的模式。接着使用卷积神经网络对该二维图进行特征提取,在卷积的过程中两个文本在不同层级的特征上产生信息交互。本文针对传统的MatchPyramid 模型进行改进,在输入编码层加入多头自注意力机制和互注意力机制增强对文本内部特征和文本间关联特征的表达。其次使用了密集连接的卷积神经网络,弥补了模型对长距离依赖特征提取的不足,结果表明本文模型在文本相似度计算任务上表现更好。
1 Related works
早期,人们判断两段文本是否相似主要依赖于关键字匹配,这种匹配方式完全忽略了语义的影响,对于语义相似而字面差距大的文本识别效果不好。之后,人们逐渐考虑到了语义理解在文本相似度计算中的重要性,使用一系列的机器学习算法如LSA、PLSA、LDA将文本从稀疏的高维空间映射到低维语义空间,在低维语义空间计算相似度。在这一时期初步考虑到了语义,但一词多义等问题仍是难点。Mikolov等人[2]创造出的word2vec模型,该模型使用大量的语料库训练,不仅使单词从过去稀疏的独热编码转换到了稠密的分布式词向量表示方法,极大降低了单词表示维度,也考虑到了单词的语义。Pennington等人[3]在word2vec的基础上提出了glove向量,相比word2vec 单单考虑到了单词局部的上下文信息,glove 通过共现矩阵考虑到了整个语料库的全局信息,对单词的语义表达更充分。刘继明等人[4]提出PO-SIF算法,将word2vec词向量使用SIF算法转化为句向量,然后计算句向量之间的相似度。Huang 等人[5]提出了DSSM模型,首次将神经网络模型运用到文本相似度计算当中,DSSM 模型使用的是词袋模型,但其提出了词哈希技术,将单词切割为三字母表示,极大地降低了单词向量的维度,接着将降维后的单词向量投入到全连接神经网络中抽取相应的语义特征。随后,Shen 等人[6]提出了CLSM模型,该文认为,DSSM模型采用词袋模型忽略了文本中的词序,文中利用滑动窗口顺序取词,然后利用词哈希技术降维,在一定程度上考虑到了文本的位置信息。同时,在特征提取层,用卷积神经网络替代全连接神经网络,通过卷积层操作融入局部上下文信息,但忽略了全局信息。后续又出现了LSTMDSSM[7]等模型提升对文本长距离依赖特征的提取表现。Hu等人[8]提出了ARC-I和ARC-II模型,ARC-I单纯使用CNN 分别对文本提取特征,两个文本之间并没有交互。而ARC-II 模型属于交互学习的模型,模型从两个文本分别抽取词向量组合起来进行全卷积,以此加强对关联特征的提取。Yin等人[9]提出了ABCNN模型,将注意力机制与CNN 相结合进行特征表示。Wan 等人[10]提出了MV-LSTM 模型,使用双向LSTM 对语句重编码,然后将编码后的句向量以多种方式进行交互操作,最后使用k-Max 池在每个交互矩阵上提取最大信号。2016年,Liang等人[11]提出了MatchPyramid模型,该模型将两个文本的词向量矩阵通过点积转化为二维图的形式,然后使用CNN 对二维图进行卷积操作。Mueller 等人[12]提出了孪生LSTM 模型评估句子之间的语义相似性,将词嵌入作为LSTMs的输入,把句子编码为固定大小的向量来表达句子潜在意义,然后对两个向量计算曼哈顿距离。Parikh 等人[13]提出了可分解注意力模型,该模型将两个句子分解成每个词的软对齐机制,来计算当前文本中每个词与另一段文本的注意力得分从而得到每个词的加权向量,该模型强调单词之间的对应关系。Wang等人[14]提出了适用于句子匹配任务的比较聚合框架,研究了在对两个句子向量进行匹配过程中使用不同比较函数的效果。在2017 年,Nie 等人[15]提出了SSE 模型,在编码层使用堆叠的双向LSTM,同时每层Bilstm的输入都是前面所有层输出的连接,最后一层的输出接最大池化形成固定向量后输入到分类器中。Chen 等人[16]提出了ESIM 模型,该模型在编码层使用Bilstm 对输入词向量在当前语境下重编码,接着对输出的两个文本向量使用注意力加权,加权后的向量与原始向量采取多种方式组合。最后将生成的向量连接起来再输入到Bilstm中进行特征提取。Wang等人[17]提出了BIMPM模型,该模型对于孪生Bilstm 的每一步进行交互匹配,且提出了多种匹配方式,实现更细粒度的交互机制。Yi等人[18]提出了MCAN模型,注意力机制通常用来关注重点信息,本文中将注意力机制视为特征提取器,将多种注意力机制视为从不同的视角提取文本特征,增强了文本特征表示。Chen 等人[19]提出将对抗网络应用到文本相似度建模任务上,认为这种方式能更好的建模了两个文本之间的共同特征。Kim等人[20]提出DRCN模型,结合密集连接和注意力机制的递归模型进行文本相似度计算,文中使用5 层Bilstm 模型,每层的输入都采用密集连接包含了之前所有层的输出,同时为了避免密集连接机制所造成的的维度增大,引入自编码器压缩高维向量到固定长度,这种密集连接机制避免了底层特征的丢失。赵琪等人[21]提出胶囊网络和BIGRU 的联合模型,认为胶囊网络可以提取文本的局部特征,BIGRU 可以提取文本的全局特征,该模型在Quora数据集上准确率达到86.16%。
交互式模型能很好地建模文本之间的关联特征,传统的MatchPyramid 模型的特点决定了它在句内特征与长距离依赖特征方面的提取还有改善的空间。基于此,本文提出融合注意力机制的增强MatchPyramid 模型,多头自注意力机制弥补了模型在单文本内部特征提取的不足,互注意力机制则增强了对文本间交互特征的表示,同时,采用密集连接的卷积神经网络提升模型在长距离依赖特征提取上的表现。结果表明,本文模型在文本相似度计算任务上有更优良的表现。
2 模型架构
本文的模型分为输入编码层、特征提取层、特征分析判断层。如图1 所示为本文模型架构图。在输入编码层,首先使用自编码器(autoencoder,AE)对初始词向量降维,降维后的词向量作为多头自注意力和互注意力机制的输入,通过多头自注意力机制,可以提取到单文本的内部语义特征,捕获文本内部的词依赖关系;互注意力机制更善于提取句间特征,对两个句子中更相似的部分给予更高的关注。本文将两种注意力的输出以不同形式相组合,然后将形成的多种特征与初始词向量相连接形成新的词向量矩阵。传统的MatchPyramid 模型将两个文本通过点积形成单通道图的形式,本文首先将新形成两个文本向量通过转换矩阵映射到多个特征子空间,然后使特征子空间的文本向量对应点积形成多通道图作为特征提取层的输入,相比于单通道图输入到卷积神经网络进行特征提取,映射到多个特征子空间再进行特征提取更能突出某些特征。在特征提取层相比于传统的MatchPyramid 模型,本文使用了密集连接的卷积神经网络,使底层特征能够传递到最高层,避免了特征信息的丢失。本文的密集连接卷积神经网络分为3个DenseBlock,其中前2 个DenseBlock 包含4 个卷积模块,第3 个DenseBlock 包含2 个卷积模块。每个卷积模块都包括Batch Normalization 层、卷积层、ReLU 层,其中最后一个卷积模块增加池化层进行特征降维。本文池化层联合平均池和最大池进行组合池化。在特征分析判断层,本文的分类器是一个多层感知机(multilayer perceptron,MLP),由两个全连接神经网络组成,网络间加入ReLU 激活函数和batch normalization 层,最后使用Sigmoid函数进行二分类。
2.1 输入编码层
2.1.1 自编码器
在输入编码层,不像之前的模型直接使用注意力加权后的词向量矩阵代替初始的glove词向量矩阵作为后续网络的输入。本文将多头自注意力机制与互注意力机制的输出以多种形式组合并与原始300 维预训练的glove向量相连接作为后续网络的输入。假如直接将多个词向量矩阵按照图1模式相连接,那么词向量的维度将达到1 500 维,极大地增加模型运行时间。因此为防止词向量长度过大造成计算量的急剧上升,本文增加了自编码器用于降低维度。本文的自编码器只包含编码层,去除了解码层,使用自编码器将300维glove向量压缩到64 维,然后将降维后的词向量作为多头自注意力机制和互注意力机制的输入,这极大地降低了注意力层的计算量。
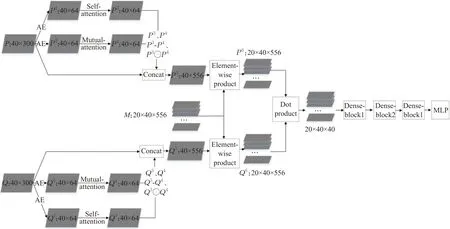
图1 总体模型架构Fig.1 Overall model architecture
2.1.2 多头自注意力机制



在公式(4)中,将h次注意力机制的结果按照维度dv进行拼接后,通过W0进行线性变换得到的结果即为最终的多头注意力。
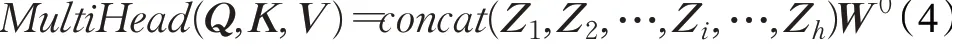
本文多头自注意力机制的输入为经自编码器压缩过的词向量矩阵,因此输入输出的词向量长度均为64维。
2.1.3 互注意力机制
文本相似度建模是基于双文本,因此既要考虑单文本内部的依赖特征,也要关注文本之间的关联特征。将预训练的300 维Glove 向量输入到自编码器,向量长度被压缩到64 维,然后将压缩后的向量输入互注意力机制中,公式(5)和(6)表示输入的两个压缩后的词向量矩阵P2和Q2,对P2中的任何一个单词,要衡量其与Q2中每个单词间的相关程度。这在现实中具有很好的解释性,在判断两个语句之间的相似性时,两个语句的单词之间相关程度并不是一致的,更要关注重点信息。为了计算pi对Q2的注意力,首先根据公式(7)计算出pi与Q2中每个单词之间的相关程度,然后将所有得到的值使用公式(8)归一化即得到pi与Q2之间每个单词的注意力权重,最后根据公式(9)使用注意力权重对Q2的每个词向量加权求和即得到最终的pi对Q2的注意力值。
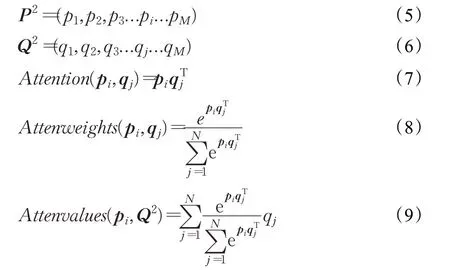
在得到多头自注意力与互注意力的输出后,不像以往的模型直接使用注意力的输出作为后续网络的输入,本文将注意力的输出以多种方式组合并与底层的词向量相连接。以文本P(文本Q类似)为例,本文计算互注意力和多头自注意力之间的差值以及二者之间的元素点积,如公式(10)将注意力机制的输出、差值、元素点积的结果与原始的300 维Glove 向量相连接,得到的词向量为556维,认为这样能够更好地对文本进行表示。
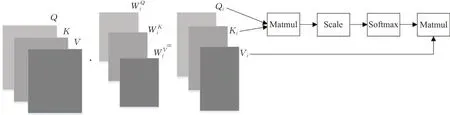
图2 单头注意力计算过程Fig.2 Calculation process of single head attention

2.1.4 多通道映射
传统的MatchPyramid 模型将两个文本的词向量矩阵通过点积形成单通道二维图的形式,图中的每个像素点即为两个单词的词向量点积后得到的实数值。本文提出将两个文本的词向量矩阵映射到多个表示子空间中,由公式(11)生成初始化三维张量M,其中mi的维度与输入的词向量矩阵的维度一致,均为seq_len×embed_size,l代表要映射的通道数,具体来说对于输入的词向量矩阵P5和Q5而言,根据公式(12)将词向量矩阵P5与M进行元素点积,最终将词向量矩阵映射到20个特征子空间中,对Q5进行同样的操作。

经多通道映射后得到的P6和Q6的形状为l×seq_len×embed_size,将二者做点积,形成多通道二维图的形式,形状为l×seq_len×seq_len,其中某单通道二维图的像素点即代表在该表示子空间下两个单词的词向量点积后得到的实数值。该多通道二维图即为后续特征提取层的输入。
2.2 特征提取层
传统的MatchPyramid 模型在特征提取层将两个文本词向量矩阵经点积后形成的单通道二维图直接输入到多层CNN中进行特征提取,依靠CNN层的堆叠虽然能在一定程度上加强对文本长距离特征的提取,但是也在一定程度上造成了底层特征的损失。本文在特征提取层使用密集连接的CNN,通过密集连接的方式将底层的特征传递到顶层的卷积层。这种将不同卷积层的特征图相连接的方式,可以实现特征重用,既使模型能够提取文本长距离依赖特征,又减少了底层特征的损失。如图3 所示,特征提取层主要由3 个DenseBlock 组成,其中前2个DenseBlock均包含4个卷积模块,最后1个DenseBlock 由2 个卷积模块组成。其中每个卷积模块都包含batch normalization层、卷积层、ReLU层,最后一个卷积模块添加池化层用于对特征图降维。
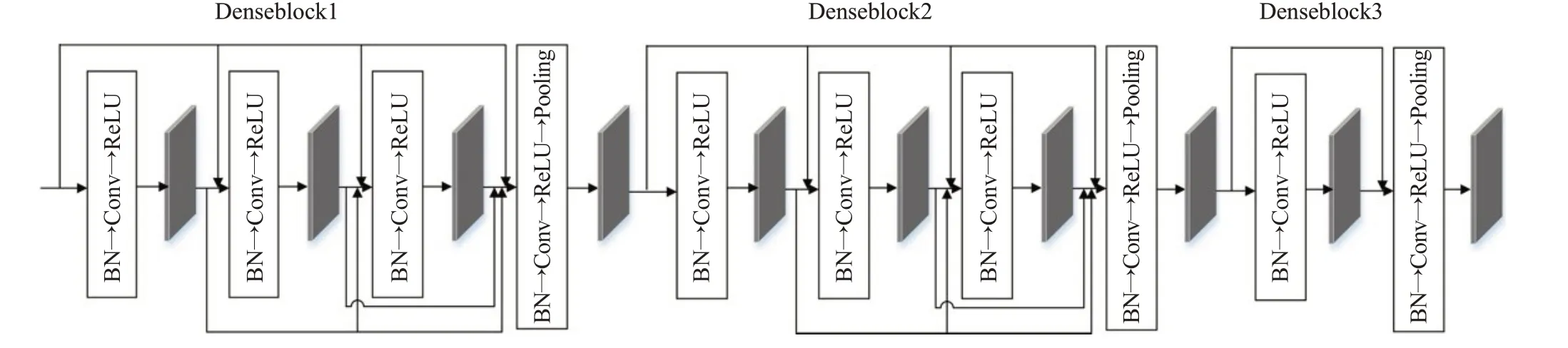
图3 特征提取层流程图Fig.3 Flow chart of feature extraction layer
Batch normalization层在本文的网络中发挥很大的作用,深度神经网络的训练十分复杂,每层网络的一个很细微的变化通过层层传递,就会逐渐被放大,当我们对初始层的输入进行归一化的处理后,数据经过神经网络的隐藏层的变换会导致深度模型中间层网络的输入数据的分布不断变化,然后网络去不断地调整以适应这种新的数据分布,从而影响到训练速度。中间层网络输入数据分布的变化引起后续网络数据分布的改变,这种神经网络训练过程中中间层数据分布的变化也被称为内部协方差偏移。batch normalization 是归一化网络层,在卷积层前添加batch normalization 层可以使每层卷积网络的输入数据分布保持稳定,从而使网络快速收敛,并且有利于提高网络的泛化能力。
对于batch normalization层的具体计算是针对每一批数据进行的,首先根据公式(13)计算出每批数据的均值,m代表batch_size:

但是如果单纯的将每层网络的输入数据做归一化处理,那么上层网络所学习到的特征分布就会被破坏。因此,为了保留上层网络学习到的特征分布,batch normalization 算法在对批数据归一化处理后加入了变换重构,如公式(16),其中γ和β是可学习参数,从该公式中可以看出,当γ与β的值接近于批标准差和均值时,特征分布就会被还原,从而起到恢复特征分布的作用。

本文特征提取层的输入数据的形状为batch_size×l×seq_len×seq_len,l代表输入通道数。在本文的Denseblock模块中,每一个卷积模块的输入都会采取密集连接的机制,根据公式(17)将前面所有卷积模块的输出都连接起来作为本层卷积模块的输入,其中函数Hl是卷积模块中batch normalization 层、卷积层、ReLU 层、池化层一系列操作的组合,xl代表每一个卷积模块的输出。

2.3 特征分析判断层
在特征分析判断层将特征提取层最终输出的特征图展平然后输入到分类器中。该层主要包含一个多层感知器,由两层全连接神经网络组成,在每层全连接神经网络前添加batch normalization层对输入数据做归一化处理,最后使用Sigmoid 函数进行二分类从而判断出两个文本是否相似。损失函数本文使用的是二分类交叉熵损失函数。
3 实验结果与分析
3.1 数据集
本文使用的数据集为Quora Question Pairs[17],该数据集包含多个字段,囊括了问题对的序号以及标识问题对是否具有相同的含义的序号,1代表问题对具有相同释义,0 代表该问题对之间无关联。数据集一共包含404 000 个问题对,将其划分为训练集、验证集和测试集,其中训练集包括384 000条数据,验证集和测试集各10 000 条数据。本文在数据处理方面,去除了停用词,句子最大长度设置为40 个字符,长度不足40 个字符的则补齐,超过40个字符的句子则截取前40个字符。
3.2 实验设置
本文使用预训练的300维Glove向量做初始化词嵌入,对于未登录词随机初始化。优化器选择Adam,超参数设置方面,学习率设置为0.001,batch_size 设置为64,epoch 设置为20。本文的实验环境为:pytorch1.6.0,python3.6.9。
3.3 评价指标
文本相似度计算属于二分类任务,两个文本若被判断为相似则分类为1,不相似便被分类为0。对此,本文使用准确率、精确率、召回率、F1值和Auc值来评价模型的好坏。
准确率,即预测结果中正确预测的样本占所有预测结果的比重:


3.4 实验结果及分析
针对本文提出的模型,实施了4 个实验进行验证:(1)将本文的模型其他的一些基准模型进行对比;(2)进行消融实验,探索模型各部分是否发挥积极作用;(3)对密集连接的卷积神经网络的层数进行了探索;(4)探讨了BN层的位置对本文模型的影响。
如表1所示,在Quora Question Pairs数据集上将本文模型与其他文章中所提出的模型进行对比,相比于文献[11]提出的MatchPyramid 模型,文献[22]提出的联合孪生LSTM网络在准确率和F1值上均有所提升。传统的MatchPyramid 模型,将两段文本的词向量矩阵通过点乘形成二维图,在此过程中,两段文本已经进行了初次交互,而后续利用多层卷积神经网络对该二维图进行特征提取,能够获得文本短语特征、语法和语义等高阶特征。文献[22]提出的模型,在MatchPyramid模型的基础上,通过利用LSTM 的长期记忆性,从而保留了一些文本内长距离依赖特征,因此效果要好于传统的Match-Pyramid 模型。而相比于以上所提出的模型,本文的模型在输入编码层融合了多头自注意力机制和互注意力机制,自注意力机制相比于LSTM 网络,不仅能够提取出文本全局特征,而且更能锐化关键特征,充分表示出单文本内部的特征依赖,而互注意力机制通过对两段文本进行交互加权,进一步加强了文本间交互特征的表示,最后将点积形成的单通道图映射到多个表示子空间,以丰富特征表达。在特征提取层本文采取了密集连接的卷积神经网络,将底层边缘特征与高阶特征相结合,避免了特征损失,最终本文的模型准确率达到86.62%,F1值达到86.93%,相比前文所提到的模型有所提升。

表1 基准模型对比Table 1 Comparison of benchmark models单位:%
如表2所示,本文对模型各部分发挥的作用做出了定量的分析,将注意力机制的结果与原始词向量相连接,会使词向量表示能力更加健壮,从而对模型的性能产生影响。特征映射将形成的单通道图映射到多个表示子空间,丰富了底层的特征表示,同时在密集连接的卷积神经网络中,特征映射的通道数会对后续多层卷积神经网络的参数造成较大影响。

表2 消融实验对比Table 2 Comparison of ablation experiments单位:%
BN层在每个卷积层和最终的全连接层都发挥着作用,一方面,提高网络的收敛速度,另一方面,在一定程度上抑制模型的过拟合,提高模型的泛化能力,因此当去除了所有的BN层后,模型的过拟合现象比较严重,使得模型的效果更差。最后,可以看出dense 网络对模型的提升效果并不太好,原因在于实验中为了提高模型的运行速度,本文模型在加深模型深度的同时,降低了卷积层的通道数,从而减少了模型的参数量,不可避免地削弱了特征提取层的表征能力,使得dense 网络对模型的提升效果不明显。
在特征提取层,本文采取了密集连接的卷积神经网络,网络层数的增加能使模型提取更高层次的特征,但盲目的增加网络层数,一方面过深的网络也会导致模型过拟合,另一方面过深的网络会引起参数量的急剧增长,从而加剧了模型时间复杂度。因此,选取适当的网络层数也是本文需要探索的目标。如表3 所示给出了不同深度的卷积层下模型的效果,可以看出当层数为10时最合适。

表3 不同卷积层数实验对比Table 3 Experimental comparison of different convolution layers 单位:%
将BN层置于卷积层之后,激活层之前,可以使卷积层的输出落在激活函数的非饱和区从而缓解梯度爆炸或梯度消失的问题。本文测试了将BN层分别置于卷积层前后的效果,如表4所示BN层位于卷积层之前效果更好,原因在于本文的密集连接在每个卷积层的输入都会接受到其他层的输出,因此若将BN层置于卷积模块中卷积层之后激活层之前,那么归一化的效果只会作用于当前层的输出,然而下一层网络的输入是之前所有层的输出相连接,因此BN层归一化的效果被极大的削弱了,所以对于本文而言,将BN层置于卷积层之前效果更好。

表4 BN层位置对比Table 4 Comparison of ablation experiments单位:%
4 结束语
本文对传统的MatchPyramid 模型进行了改进,通过多头自注意力机制和互注意力机制,弥补了传统的MatchPyramid 模型对单文本内特征和双文本间依赖特征提取的不足,采取多通道映射将单通道图映射到多个表示子空间丰富了特征表达,也能对关键特征起到锐化作用。接着使用密集连接的卷积神经网络使得底层特征能够参与到最终的分类决策当中,避免了特征损失。实验结果表明,本文提出的模型在文本相似度计算任务上效果很好。
