面向网络基础设备的流量识别与威胁检测技术*
2022-10-16邓金祥温嵩杰侯俊龙田晓东周恩亚
邓金祥,温嵩杰,侯俊龙,田晓东,周恩亚,谷 峰
(成都深思科技有限公司,四川 成都 610095)
0 引言
随着互联网的蓬勃发展、联网设备的日益增加,网络连接设备,如路由器、交换机、防火墙等,在互联网中的存量也达到了一定量级。近年来,多家路由器厂商的安全漏洞在黑客间广为流传,以路由器为主的网络设备相关安全事件被频繁曝出。网络设备面临的威胁风险正在成为仅次于英特尔中央处理器(Central Processing Unit,CPU)漏洞的新增长领域[1]。网络连接设备(以下简称网络设备)在互联网中占据着支撑地位,一旦被恶意攻击,攻击者可以对下游服务器和个人PC 实施精准打击,进一步发起域名系统(Domain Name System,DNS)劫持、窃取信息、网络钓鱼等攻击,直接威胁用户数据存储安全,使得相关网络设备变成随时可被引爆的“地雷”,造成严重后果。
1 安全现状
1.1 国内外安全形势
在2013 年,斯诺登披露的“棱镜计划”就已经表明:路由器等网络设备是实施网络监听的重要攻击目标。2015 年9 月,国外安全公司FireEye发现针对路由器的植入式后门,涉及多种型号的Cisco 路由器。2018 年3 月,卡巴斯基揭露了一起潜伏6 年的,被称作“弹弓”的网络间谍行动,攻击者通过入侵非洲和中东多国的路由器,感染了数千台设备。2018 年5 月,Cisco 公司称俄罗斯黑客组织利用恶意软件感染了全球至少50 万台路由器,主要影响对象为小型和家庭常用的Linksys、MikroTik、Netgear、TP-Link、华硕、华为、中兴和D-Link 等路由器。2020 年3 月,360 披露了两个神秘黑客组织通过入侵居易科技的网络设备,窃取邮件及文件并添加后门的行为。
由上述安全事件中可以看出,网络设备安全事件正愈演愈烈,然而,公众所知的网络设备安全事件只是冰山一角。国家信息安全漏洞共享平台在分析验证多家厂商的路由器产品后,发现它们都存在后门,黑客可由此直接控制路由器。在长期对各类高级可持续威胁攻击(Advanced Persistent Threat attack,APT)案件的跟踪中,笔者发现,以位于发达国家的APT 组织为主的黑客组织,其实很早就开始大量利用网络设备漏洞开展窃密活动了,但由于缺乏有效的网络设备流量检测产品,很多安全事件没有被及时发现。此外,在之前中美贸易摩擦以及“五眼”联盟对中国华为、中兴等网络设备厂商的限制事件中,也可以看出,网络设备安全对国家网络安全至关重要,因此受到了国内外政府的高度重视。基于此,习近平总书记在2018 年4 月的讲话中特别提到:要积极发展网络安全产业,做到关口前移,防患于未然。
1.2 当前检测能力的脆弱性
传统的网络设备识别检测方案主要是基于一些已知的漏洞或常规攻击手段提取一些流量上的检测规则,再进行全流量匹配实现检测。侧重于直接发现攻击或者入侵的过程。这种方式在实战过程中虽然也具备一定的效果,但做法比较简单、粗暴,没有形成体系,检测规则基本上反映了系统的检测能力,局限性非常明显,具体体现在以下几个方面:
(1)检测规则难以做到全面覆盖,检测存在明显的滞后性。网络设备本身类型很多,各类设备的硬件形式、固件类型、操作系统都存在很大的差异,要想实现对漏洞等相关威胁的有效覆盖本身就比较困难,加之目前网络安全行业中针对网络设备安全的关注不够,进一步导致了检测规则的搜集和更新比较滞后,因此很多威胁无法及时被发现和检测。
(2)对未知威胁的检测能力薄弱。由于检测方式过分依赖规则,导致检测系统的检测能力都是针对相关规则的已知威胁的,对于新形式的未知威胁无能为力。
(3)网络设备通信常被配置为白名单。在企业级网络环境中,一般都会配备防火墙、入侵防御系统(Intrusion Prevention Systems,IPS)、入侵检测系统(Intrusion detection system,IDS)等防护设备,但在实际使用中,为保证网络通畅和维护方便,常将网络设备IP 及常用端口设置为白名单,这就给攻击者可乘之机,形成安全防护漏洞。
(4)全流量环境检测网络设备风险的效率低下。在绝大部分网络环境下,网络中的流量都是非网络设备产生的,检测系统无法对流量进行区分,只能统一进行检测。这样的做法,导致大部分检测都是无效的,浪费了很多硬件资源,资源利用率低。此外,由于全流量检测导致单台检测设备的流量接入能力有限,可以部署的网络流量规模也就有限,从而进一步降低了网络设备风险的检出率。
2 网络设备风险分析
目前,网络设备越来越受到APT 组织的关注,其原因与设备本身的以下特点密切相关。
(1)长期在线且暴露面广。网络设备作为网络基础设施,不可避免地需要放置在网络边界,暴露在互联网中。特别是为了方便被其他接入设备发现和管理,网络设备往往比普通终端设备更直接地暴露在网络中并提供服务。此外,为了保障网络持续、稳定、高效地运转,设备需要保持长期在线工作。
(2)固件更新慢且升级复杂。网络设备因为其功能比较简单,出现功能性问题的概率较低,因此更新通常比较慢。最为严重的是,大部分网络设备无法自动更新固件,一旦出现漏洞则需要用户主动升级固件,或者由厂商提供固件升级服务。
(3)关注度低,风险不易发现。网络设备一旦部署,只要网络处于正常运行状态,用户就很少再关注网络设备的安全性,因此,即使网络设备被曝出漏洞,也会因为遗忘、不关心、不了解等因素,不能及时得到修复。
(4)防护措施少,不易检测。网络设备因为其自身性能、软件库等因素,一般不会配备安装防病毒、防渗透等专业防护软件,因此受到威胁后很难被发现和清除。
(5)受信任度高,易于穿透。网络设备是设计用于连接设备与设备、网络与网络的关键节点设备,是网络数据传输的枢纽,要实现正常通信,网络设备需要完全被信任,因此所有的通信数据都会被放行通过这些设备。
基于以上特点,网络设备一旦被控,将成为攻击者可长期操控的稳定攻击源,且不易被发现和检测。同时,攻击者可以较为容易地通过被控设备对目标网络进行内网渗透、流量劫持等扩散性攻击,大范围影响网络安全,造成严重后果。
2.1 固件漏洞分析
2021 年,Cisco 公布了一个新的路由器命令注入漏洞,漏洞编号CVE-2021-1414。该漏洞允许未经身份验证的远程攻击者在受影响的设备上执行任意代码,继而通过路由器进行一系列的内网渗透、信息窃取、网络破坏等高危攻击和窃密行为。
受漏洞影响的设备为Cisco 的RV340 系列路由器,该系列路由器可为小型企业提供防火墙和高速上网服务。在人力与经费有限的情况下,小型企业很难防范来自网络设备的漏洞攻击。因此,APT 组织将目标放在这些与大型企业合作的中小企业上,以中小企业为跳板,只要攻陷任何一家,就有机会渗透与其合作的大型企业,如图1 所示。

图1 网络设备攻击
RV340 路由器使用的固件为.img 格式,由此可知,此系列的路由器是基于openwrt 开发的。OpenWRTF 是一个高度模块化、高度自动化的嵌入式Linux 系统,拥有强大的网络组件和扩展能力,多被用于工控设备、电话、小型机器人、智能家居、路由器以及基于IP 的语音传输(Voice over Internet Protocol,VOIP)设备中。
本文先使用binwalk 对固件文件进行分析,得到文件系统中的全部内容,定位到目标平台为ARM 32 小端。然后,结合已知的公开漏洞信息对固件的文件系统进行定位分析,并使用交互式反汇编器专业版(Interactive Disassembler Professional,IDA)进行逆向工程分析,最终定位至漏洞函数setpre_snmp,如图2 所示。此函数在调用popen 执行命令前未对usmUserPrivKey 中的值进行过滤,从而导致了命令注入。目前Cisco 官方针对此漏洞已经出具了修复方式,即需要将固件版本升级到一定版本以上。

图2 固件代码漏洞
根据对上述漏洞的分析可以看出,网络设备漏洞是非常容易被利用并作为攻击手段的。此外,由于大多数路由器不支持自动升级,都需要人为进行版本检测再进行在线升级,甚至有些情况下只能离线升级。
综上,在网络设备保有量不断增加,但受关注度低的背景下,其面临的风险正日益增加,尤其是旧版本的网络设备,都存在已知的公开的漏洞。
2.2 应用服务漏洞分析
在现有的网络设备中,防火墙设备本身就是网络安全的屏障,可以大幅度提高网络的安全性,处理过滤大部分未知流量,将风险因素降至最低,强化网络安全防护能力。但是就是这样一个专门用于网络安全防护的设备,在面对现有的网络空间环境时,也会出现力有不逮的情况。在网络安全领域,防火墙漏洞也是屡见不鲜,矛与盾的冲突始终在不停地上演。
Fortigate 防火墙的cookie 栈溢出漏洞就是这一冲突之下的一角缩影。该漏洞编号为CVE-2016-6909,最早由Equation Group 组织使用来攻击各大厂商的防火墙。该漏洞在特定版本的Fortigate 防火墙中存在。这些版本的防火墙中的Cookie 解析器存在缓冲区溢出问题,远程攻击者可以使用特意拼接的HTTP 请求执行任意代码,以跳过防火墙的防护,入侵内部网络,完成内网横向渗透、信息窃取、网络破坏等攻击动作。
本文根据厂商提供的虚拟机镜像版本FGT_VM-v400-build0482,对该漏洞进行了深入的分析定位及复现,以提取其中的特征信息。通常情况下,防火墙设备不会提供shell,而是仅提供一个简易的命令行界面(Command Line Interface,CLI),在上面只能使用其内置的功能,这些功能并没有组成一个可用的操作系统,也无法通过CLI 直接拿到shell。基于此类设备特点,对虚拟机镜像进行挂载,找到内核镜像文件flatkc.smp 与flatkc.nosmp,配置文件extlinux.conf,从而定位到文件系统rootfs.gz,将其解压,分析其init 进程,便于后续漏洞定位。解压的文件系统如图3 所示。

图3 文件系统
分析init 进程的结果如下:
检查/bin.tar.xz 是否存在,若是则创建子进程执行/sbin/xz -check=sha256 -d/bin.tar.xz;父进程等待子进程结束后删除/bin.tar.xz;之后检查/bin.tar是否存在,若是则创建子进程执行/sbin/ftar -xf/bin.tar;父进程等待子进程结束后删除/bin.tar。
上一步成功后检查/migadmin.tar.xz 是否存在,若是则创建子进程执行/sbin/xz -check=sha256 -d/migadmin.tar.xz;父进程等待子进程结束后删除/migadmin.tar.xz;之后检查/migadmin.tar 是否存在,若是则创建子进程执行/sbin/ftar -xf/migadmin.tar;父进程等待子进程结束后删除/migadmin.tar。
删除/sbin/xz。
删除/sbin/ftar。
执行/bin/init。
再对bin.tar.xz 进行分析后,如图4 所示,可以看出其中httpsd 等网络服务都是/bin/init 的软链接。/bin/init 应当为防火墙提供了基本的网络服务,而chmod 等常用命令等都是/bin/sysctl 的软链接,应当类似busybox 的工具库。

图4 bin.tar.xz 分析
根据CVE 通告描述的Cookie,解析过程中发生缓冲区溢出的描述,构造HTTP 请求来进行漏洞复现;然后将Cookie 中的字段进行拆分组合,最终确定AuthHash 字段是栈溢出漏洞,当其字符数量达到0x60 时会触发防火墙栈溢出,httpsd 服务崩溃。根据报错信息进行回溯后,最终定位到sub_820CB5E()函数,如图5 所示,它对Cookie 内容的解析使用了不安全的%s 来读取AuthHash 到栈上,从而导致栈溢出漏洞。

图5 溢出点
在后续研究中,尝试使用了gadget 来拼写攻击载荷,组成HTTP 请求,执行了一段关机代码:

最终也成功终止了防火墙服务,关闭了防火墙设备,其他shellcode 则不再赘述。
综上,防火墙设备是为了确保安全而引入的,但安全产品又会有新的安全问题产生,成了一个无解的循环。尤其在当前愈加严峻的网络空间安全形势下,针对网络设备所可能受到的安全风险,需要研究提出高效、准确的检测技术及思路。
3 网络设备检测思路
从网络设备安全这个角度,可以把网络中的流量分为两类:一类是网络设备的自身流量,即网络设备自己和外部建立通信时产生的流量,比如访问路由器web 管理界面的流量;另一类是网络设备转发的流量,就是网络中的非网络设备,比如手机、PC、服务器等这些设备产生的流量,这些流量只是会通过网络设备进行转发,所以称之为转发流量,与网络设备自身产生的流量是不同的。本文的检测重点为网络设备的自身流量,如图6 所示。
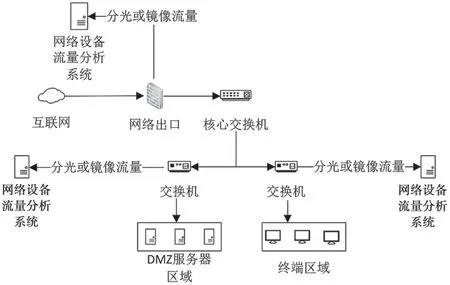
图6 网络设备流量
3.1 流量采集与处理
流量采集是高对抗网络基础设备威胁检测的基础。只有捕获到正确的数据包,后续的流量分离和威胁检测溯源才有价值。下文将对网络基础设备威胁检测使用的流量采集技术,以及主流的流量处理开发平台进行研究分析。
3.1.1 高速流量采集技术
原始数据包在线采集主要是通过物理层和数据链路层的信号解析和解帧,实现对原始数据包报文的获取。传统的网络设备驱动需要产生中断才能将数据包提交到用户层进行处理,并且还会对数据包进行多次拷贝,因此性能低下。具体地,网络数据包到来后,网卡设备先根据配置进行直接存储器访问(Direct Memory Access,DMA)操作;随后网卡发送硬中断,唤醒处理器;处理器被唤醒后,则将数据包填充到读写缓冲区数据结构;内核处理完数据包后,则通知用户层获取数据包,用户层收到消息以后,再将数据包拷贝到用户层。在整个过程中,首先硬中断和内存拷贝非常消耗性能,每次硬中断大约会消耗100 μs,加上终止上下文带来的缺页中断,性能开销更大;其次,Linux 在内核态和用户态之间的来回切换也会消耗大量性能,导致性能进一步降低。
通过研究,本文重新设计的高速流量采集技术能够克服之前架构的性能限制,具体方式如下:
(1)预分配和重用内存资源:在开始分组接收之前,预先分配好将要到达的数据包所需的内存空间,用来存储数据和元数据。
(2)并行直接通道传递数据包:为了解决序列化的访问流量,建立从网卡多队列(Receive Side Scaling,RSS)到应用之间的直接并行数据通道,通过特定的RSS 队列、特定的CPU 核和应用三者的绑定来实现性能的提升。
(3)内存映射:将应用程序的内存区域映射到内核态的内存区域,应用能够在没有中间副本的情况下读写这片内存区域。这种方式可以使应用直接访问网卡的DMA 内存区域,即零拷贝技术。
(4)数据包的批处理:为了避免对每个数据包重复操作的开销,对数据包进行批量处理,即将数据包划分为组,按组分配缓冲区一起复制到内核/用户内存。
为了满足高性能数据接入要求,本文重写了网络驱动设备进行数据采集,其处理流程如图7 所示。

图7 网络设备驱动处理流程
由图7 可知,当数据包到来时,该网络设备驱动不会产生中断,而是直接将数据包保存在缓存区中。当一块缓存区写满以后,则将缓存提交到应用层,再重新申请一块新的缓存区用于存取数据,用户层接收到缓存的数据后,就立即处理缓存的数据。
通过高速流量采集技术,能够快速完整地实现大流量场景下的转发流量和网络设备流量采集,为后续的网络基础设备流量识别、分离、分析与检测做好数据准备。
3.1.2 流量处理开发平台
目前流行的流量处理开发主要使用Gopacket 和数据平面开发工具集(Inter Data Plane Development Kit,DPDK),网络基础设备威胁检测技术使用的则是DPDK 平台。
DPDK 是英特尔公司设计开发的数据平面开发工具集,广泛应用于传统电信领域3 层以下的应用。在此开发平台中,通过使用无锁队列、RingBuffer、AC_BM、Hyperscan 等众多高性能匹配算法,实现了超大流量数据处理能力。
基于DPDK 的流量处理平台为了满足大流量环境,将网络数据直接从网络适配器传输到用户程序,降低系统调用和数据复制的次数,减少CPU 在数据拷贝时候的负载,实现CPU 的零参与。此外,利用DPDK 的大页内存方式还可以提高内存访问效率,降低页表缓存(Translation Lookaside Buffer,TLB)冲突概率。为实现物理地址到虚拟地址的转换,Linux 一般通过查找TLB 来进行快速映射,如果在查找TLB 时没有命中,就会触发一次缺页中断,将访问内存来重新刷新TLB 页表。Linux 中,默认页大小为4 KB,当用户程序占用4 MB 的内存时,就需要1 KB 的页表项,如果使用2 MB 的页面,那么只需要2 条页表项,这样有以下两个好处:
(1)使用大页内存的内存所需的页表项比较少,对于需要大量内存的进程来说节省了很多开销,像Oracle 之类的大型数据库优化都使用了大页面配置;
(2)TLB 是CPU 中单独的一块高速Cache,一般只能容纳100 条页表项,采用大页内存可以大大降低TLB Miss 的开销,从而降低TLB 冲突概率。
DPDK 针对英特尔网卡实现了基于轮询方式的轮询模式(Poll Mode Drivers,PMD)驱动,该驱动由应用程序接口(Application Program Interface,API)和用户空间运行的驱动程序构成。该驱动使用无中断方式直接操作网卡的接收和发送队列,除了链路状态通知仍必须采用中断方式以外。目前PMD 驱动支持英特尔大部分1 GB、10 GB 和40 GB 的网卡。
因此,可以利用DPDK 流量处理平台,实现在大流量环境下的流量采集工作,采集网络设备转发流量及网络设备自身流量。本文基于DPDK 技术所奠定的流量数据基础,进一步深入研究网络设备流量针对性识别与分离技术。
3.2 流量识别与分离
在现有的网络流量环境中,流量中的绝大部分都是转发流量,而不是网络设备的自身流量。两种流量在统一的检测分析中,不仅效率不高,还存在较大的互相干扰。因此,要采用一定的技术手段进行网络设备流量的分离[2],包括网络设备的正常业务流量(比如网络设备web 的流量、路由协议的流量),网络设备直接参与通信的流量(比如网络设备被控后的回传流量)。
两种流量是无法简单地基于协议特征实现区分的,且网络设备承担着路由转发的功能,会将其转发的流量数据帧改变为自己的IP 或MAC 地址,因此,从IP 和MAC 地址上也无法实现流量的区分。同时,从网络安全分析角度来看,流量中小部分的未知的流量,反而是更需要关注的流量,高级威胁往往隐藏于未知流量中。
网络设备流量在网络中的流量占比很小,如果流量分离技术准确率不高,则必然会出现大量非网络设备流量被误识别,从而出现准确识别的网络设备流量被湮没的情况,最终可能导致分离结果不可靠,甚至不可用。由此,必须要保证以极高的准确率实现不局限于协议特征的流量分离能力。
针对上述问题,下文将对网络基础设备威胁检测中使用的流量分离技术进行研究。
3.2.1 通信指纹预测技术
经过长期的研究发现,网络设备流量虽然在流量层面没有直接有效的识别特征,但针对网络设备的特殊应用场景而言,仍然可以通过挖掘流量协议各层隐藏的信息并分析它们之间的联系,来识别网络设备流量,而其核心技术之一就是栈指纹辨识技术[3]。
任何一段信息,包括文字、语音、视频、图片等,如果对其进行无损压缩编码,理论上编码后的最短长度就是它的指纹(信息熵),在编码算法正确的情况下,任意两段信息的指纹都很难重复,如同人类的指纹一样。基于不同设备厂家对互联网通信协议(Request For Comments,RFC)相关文档的不同理解,不同的网络设备厂商在具体实现TCP/IP协议栈的时候就可能存在极其微小的差异[4]。此外,还由于以下外部因素增大了彼此的差异:
(1)RFC 规范中存在着一些可选的特性,不同厂家可选项不一致;
(2)某些私自对TCP/IP 协议栈实现的改进;
(3)少数不遵从RFC 规范的行为。
通过探测并仔细分析这些网络设备的协议栈指纹差异,对不同厂商的网络设备信息进行积累,提取其网络设备的协议栈指纹。目前,已经完成34类主流路由/交换机品牌,以及30 类主流防火墙设备的协议栈指纹积累。将积累的栈指纹数据作为训练集,结合机器学习朴素贝叶斯算法来初步完成对网络流量中的网络设备流量分离及识别。
朴素贝叶斯是基于贝叶斯定理的算法,即在两个条件关系之间,测量每个类的概率,则每个类的条件概率给出x的值。以样本可能属于某类的概率来作为分类依据。在确定了网络设备的栈指纹后,计算某网络流量来源于网络设备A 的概率是X,来源于网络设备B 的概率是Y,如果X>Y,则判定该网络流量来源于网络设备A。
通信指纹预测技术采用两种策略分离网络基础设备流量,一是正向捕获,二是方向过滤。正向捕获即以上述的栈指纹识别技术为核心,通过机器学习算法不断加深栈指纹特征匹配的准确度,从而完成网络基础设备流量分离。反向过滤是一种过滤流量中协议栈指纹与网络设备协议栈指纹不相同的方法。根据非网络设备与网络设备指纹的差异,收集非网络设备的指纹形成指纹特征库,从而可以过滤流量中非网络设备的流量。针对可能出现的指纹相同的情况,可进一步采用协议特征过滤的方式降低捕获流量的误报率。该技术包含指纹特征过滤与协议特征过滤两大要点,具体如下文所述。
(1)指纹特征过滤。基于研究分析发现,大部分网络设备指纹与PC 或服务器等非网络设备存在一定的差异,基于这些差异可提取非网络设备的指纹形成非网络设备指纹特征库,用于过滤非网络设备流量。
(2)协议特征过滤。考虑到存在非网络设备指纹特征与网络设备相同的情况,在指纹特征过滤后,可根据需要基于协议(HTTP 等)特征进一步过滤非网络设备流量。
网络设备流量反向过滤主要流程如图8 所示。反向流程先提取流量中的设备指纹,与非网络设备指纹特征相匹配,如果匹配成功则过滤流量;匹配不成功,则进一步提取协议特征,与非网络设备协议特征库相匹配,匹配成功则提取设备指纹加入非网络设备指纹库并过滤流量,否则保存流量。

图8 网络设备流量反向过滤
正向捕获能够保证捕获特定网络设备的流量,反向过滤能够保证未知网络设备流量不丢失。结合上述两种策略,通信指纹预测技术既可以分离特定网络设备的流量,又可以分离未知网络设备的流量,从而能大幅度提高网络设备流量分离的精确度。
3.2.2 设备时钟分析技术
设备时钟分析技术是基于采集流量信息中的时间戳信息[5]进行分析,并计算对应设备的时钟频率、相位差[6]等信息,从而实现硬件来源判断的技术。该技术的原理为在RFC1323 协议中新增了两个TCP选项,即窗口扩大选项和时间戳(Timestamp)选项。其中,时间戳选项可以使TCP 对报文段进行更加精确的往返时延(Round-Trip Time,RTT)测量[7],即发送方在每个报文中放置一个时间戳数值,接收方在确认中返回这个数值,从而允许发送方为每一个收到的ACK 计算RTT。时间戳是一个单调递增的值,RFC1323推荐在1 ms~1 s之间将时间戳值加1。
一个特定的网络设备可能具备多个独立的时钟脉冲,包括设备的系统时间和设备自身的TCP 堆栈时钟脉冲(时间戳选项时钟脉冲)。虽然专业管理下的设备系统时钟脉冲可以通过网络时间协议(Network Time Protocol,NTP)与真实时间同步,但是对于大多数网络设备而言,NTP 协议的安装并不能使主机的系统时钟脉冲与真实时间保持同步,或者只是偶尔能保持同步。这样,对于一个非专业管理设备,如果能够通过分析流量信息中的时间戳信息来及时掌握设备系统时钟脉冲值,那么就能推断出系统时钟脉冲相位差的信息。在实践中,任何网络基础设备的系统时钟脉冲都不是绝对稳定的,实际的时钟脉冲频率总是存在或大或小的相位偏差。基于上述硬件基础,可以利用时间戳原理测量实际存在的网络基础设备相位差,从而实现硬件来源判断。
综上,通信指纹预测技术和设备时钟分析技术结合,再通过分析各层协议中可能存在的网络设备隐藏信息,对流量进行佐证判断,最终实现网络设备流量的分离准确率达到99%以上。
3.3 威胁分析与检测
通过控制网络基础设备进行扩散攻击是顶级APT 组织的常用攻击手法。因此,在分离出网络基础设备流量后,如何对其流量进行全方位的安全检查与分析[8],找出潜藏其中的风险也是一项富有挑战性的工作。
一般的入侵行为被归类为冒充攻击、穿透安全控制、泄露、拒绝服务和恶意使用等。网络基础设备作为备受青睐的攻击跳板或攻击隐藏手段,基于网络设备的隐藏的攻击方式仍然可以归类到上述攻击手法中。
入侵检测技术[9]的主要目的是尽快、尽可能可靠地检测出网络基础设备中的攻击行为。它的核心是分析网络基础设备的行为以检测异常流量。入侵检测主要通过统计方法和预测模式生成来进行检测。统计方法先通过文件访问、CPU、I/O 利用率、出错率、企图登录失败的次数等构成一个用户原始轮廓;然后利用入侵检测技术将当前活动产生的轮廓与原始轮廓进行比较,如发现明显偏离,即可认为是一次入侵事件。预测模式生成则是试图应用一系列规则和算法得出的概率,并根据过去的行为序列来预测某个主体将来的行为,大方向偏离所预测的结果也被标志为入侵行为。
3.3.1 k-means 恶意行为特征提取技术
由于机器学习具有较好的拟合性和泛化性,能够保证在对已知恶意行为进行精确识别的前提下,对未知恶意行为保持较好的识别能力,所以利用机器学习技术对恶意行为进行智能判定。
利用入侵检测技术,在网络基础设备行为流量中提取到恶意行为的基因(高维向量)后,对恶意行为代码样本库中的恶意代码根据其基因利用k-means 算法[10]进行聚类,其中,k值需要手工指定并且每一个类别的标签需要人工标注。
聚类算法试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集被称为一个“簇”(cluster)。通过这样的划分,每个簇可能对应一些潜在的概念或类别。
k-Means 算法思想:对给定的样本集,事先确定聚类簇数k,让簇内的样本尽可能紧密分布在一起,使簇间的距离尽可能大。该算法试图将集群数据分为n组独立数据样本,并使n组集群间的方差相等,数学描述为最小化惯性或集群内的平方和。k-Means 作为无监督的聚类算法,实现较简单,聚类效果好。算法流程如图9 所示,具体的算法流程描述如下:


图9 k-means 算法流程
3.3.2 层次聚类恶意行为同源判定技术
利用k-Means 恶意行为特征提取技术在网络基础设备行为流量中提取到恶意行为的特征基因(高维向量)后,对不处于恶意行为代码样本库中的恶意代码,基于其基因利用层次聚类算法进行聚类,主要用于非标注恶意代码家族的变种识别和相似性判定。在数量超过一定阈值后,也可以通过人工标注的方式加入恶意行为代码基因库中。
层次聚类算法[11]分为凝聚和分裂两种。凝聚使用自底向上的策略,即最开始每个对象是独立的类(N类),经过不断合并成更大的类,直到所有对象都合并到同一个类中,或者算法达到某个终止条件即停止。合并过程是将两个相近的类合并成一个类,所以整个算法过程最多进行N次迭代,即可将所有对象合并到同一个类下。分裂采用自顶向下的策略,即最开始每个对象都在同一个类中(1 类),经过不断拆分成更小的类,直到最小的类都相对独立或只有一个对象。
在网络设备攻击行为相似性判定过程中,采用层次聚类算法的凝聚策略,将每个独立的攻击行为作为底层最原始的合并对象,并将基于k-means 算法提取的攻击特征,如源IP、端口、证书、脚本、指纹、回连地址、时间等要素,作为合并条件;然后合并同源或相似攻击;最终,结合威胁情报等信息进行同源性判定。
入侵检测技术结合两种恶意行为特征提取和同源判定技术[12],能够完成自动提取攻击载荷、域名、IP、指纹等关键基因信息,以及API 调用流程、攻击者画像、恶意代码积累、攻击手法归类、APT 组织溯源等行为特征,助力威胁情报生产,完成针对网络设备的恶意攻击行为的检测工作。
4 结语
本文梳理了国内外网络安全形势现状及网络基础设备威胁检测技术的现状,并聚焦主流技术观察与核心技术突破,总结了网络基础设备威胁检测技术。网络基础设备作为网络世界在现实世界的重要支撑,其面临的安全风险不容忽视,而每一位关注网络安全的研究者都应是其守护者。面对日益增长的网络基础设备安全风险,应持续推动相关安全技术的发展,守护网络空间安全,守护国家安全。
