基于组合模型的网络热点话题动态预测算法的研究
2022-10-15杨茜王克勤
杨茜,王克勤
(1.西安医学院,公共卫生学院, 陕西,西安 710021;2.成都理工大学,信息科学与技术学院, 四川,成都 610059)
0 引言
智能互联自媒体时代造就了网络成为多元化的信息传播平台,网络热点事件受众更为广泛[1]。网络热点话题信息主要来自微博、网评和新闻事件,热点事件的态势走向是舆情管理的重要内容。正面、积极向上的信息同样会产生良性的导引和走向,负面的言论以及恶意导向将会对公众、甚至是整个社会产生消极影响,成为危险因子。因此,对于热点事件的信息监管和预测是目前舆论监督管理的重要课题[2-3]。Logistics回归模型是最早应用于网络热点分析的算法,其对于线性变化的分析效果较好,但是处理非线性变化的网络热评的特征分析存在明显不足[4]。虽然后来融入了聚类算法与新闻事件分类及关联规则识别分析,但聚类算法没有预测分析的能力[5]。近年来,随着舆论监管的重视度日益加强,神经网络算法、极限向量机等算法在网络热点预测方面应用日益成熟,前者的预测准确度依赖于分析样本的数据量,数据量小预测的准确性不稳定;后者在处理大量样本时,误差明显增加[6-7]。
基于此,本文结合支持向量机处理海量数据的能力以及目前对于非线性变化的网络热点事件的分析预测方面存在的不足,提出了基于组合模型的网络热点话题演化动态预测模型。首先使用改进的k-means聚类分析缩小样本空间范围,然后应用改进果蝇算法筛选支持向量机模型的最优参数,进一步提升预测模型的精度。实验结果表明:本文提出的组合模型预测精度达到了99%,误差率更低,同时,性能方面也有较大的提升,具有较高的理论价值和实际推广应用前景。
1 改进k-means聚类
首先使用改进后的k-means聚类算法结合优秀的历史热点分类进行聚类,生成最佳样本训练集合,降低数据规模。通过动态生成k值,应用密度扩张的原理挖掘到数据集中的密集点集作为初始聚类集,并摘到密度最大的点作为聚类点,从而解决了k-means算法中聚类结合量以及初始点位难以确定的问题。
获取核心聚类点示意图如图1所示。其中,o即为核心点,由图1可以发现该距离与空间密度负相关。扩展到密集空间中,选择空间内的极小值定义为k-means算法中k值,其与聚类结果密切相关。本文在计算k值得过程中使用密度特征树法。密度特征数设置了儿子——兄弟子树的存储方式,举例如ε领域内节点p的儿子所对应存储的密度小于p所对应的数据点q1。q1的兄弟节点存储的密度也小于p的相邻按聚类升序排列的数据点q2,q3,…,qi,…,qm,构件过程如图2所示。首先找到ε领域内的q1数据点,根据该点生产最小儿子节点、兄弟节点,依次迭代直到找到ε领域内的最小值数据点q11,在此基础上按照核心距离的大小插入对应的兄弟子树和分支。

图1 核心点与其周围数据点关系图

图2 动态特征树的构建
获得最小k值的k-means聚类算法首先根据与K个初始聚类中心的聚类划分到最相近的聚类簇中,然后处理未聚队列weiList中的孤立点,具体算法如下。
Step 1 通过动态特征树建立聚类队列CList以及聚类详细说明队列NList,从中获得每个类别对应的代表。
Step 2 处理待处理网络新闻或者热评,将其定位到起始的聚类密度中心点位。
Step 3 通过式(1)逐一计算每一个类族的网络热评对象的均值,同时更新对应类别的平均值。Ci内各聚类对象的平均值mi的计算公式为
(1)
其中,|Ci|表示集合C中元素的个数。
Step 4 结合Step 3中计算出来的聚类对象的均值,处理未聚类对象,将其划分到分值接近的聚类族中。
Step 5 通过式(2)计算聚类的平均误差值E,根据既定的阈值α识别Step 4中的聚类结果,如果满足误差值小于既定阈值,说明聚类已经稳定,聚类完成。否则回到Step 3重复执行。
(2)
式中,E代表全部聚类对象的误差均值的合计值,p代表待聚类的样本对象,oi代表了聚类类族中与式(1)计算的平均值最为接近的网络热评对象。
Step 6 获得最终的聚类,完成聚类。
至此,即可将需要分析预测的网络热点样本分类到对应的类别中,并将该类别下的文档作为预测的训练样本集合。
2 改进支持向量机模型
2.1 支持向量机
支持向量机模型作为统计学为基础的算法,通过在高维空间中获得准确的分类超平面,区别各种类型样本点,获得最大超平面[8-9]。其计算过程如下。
对于给定的数据集合{(x1,y1),…,(xi,yi)},(i=1,2,…,m),x∈Rd,y∈R,使用非线性映射完成低纬度数据与高纬度数空间变化,进行线性回归,回归方程如式(3):
f(x)=w·φ(xi)+b
(3)
式中,w为权向量,b是实数。对式(3)变换后,得到支持向量机的约束算法如式(4):
(4)
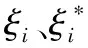
(5)

由式(5)可知,支持向量机的最终回归预测的结果受惩罚系数以及核函数对应的参数影响较大,基于此,本文选用自适应步长的果蝇优化算法得到上述两个参数的全局最优解,从而提升支持向量机模型的预测精度。
2.2 优化果蝇算法
为了解决传统的果蝇算法由于其步长固定存在收敛不到最优解以及产生局部最优的问题,本文提出了动态调整步长的模式,迭代的前半段搜索半径比较大,通过增加步长,提升其全局范围内的寻优能力。在迭代的后半段, 果蝇的搜索半径将会变得非常小,整体的寻优能力可以减低,同步提升局部的寻优能力,进一步平衡局部以及整体的关系。具体做法如式(6):
(6)
式中,L′代表动态变化的步长,L代表原始步长,gen是指目前的代数,max gen代表最大代数。
在当前这一代果蝇完成搜索之前,使用式(7)获得果蝇的变异的几率mu,当该值达到了变异条件时,复制当前最佳的M个果蝇,通过式(8)对果蝇的位置进行变异更新。迭代的前一段受果蝇间的个体差异比较大的影响,最差果蝇与最佳果蝇之间存在的较大的差别,此时算出来的变异率比较低。迭代的后半段,个体间差异逐步降低,此时增加变异几率,减少群体陷入局部最优的情况。
(7)
(8)
式中,S代表了味道的浓度值,min(S)、max(S)分别代表果蝇搜索过程的当前最小浓度与历史最大浓度。S值最终转化为支持向量机的最优参数。式中,Xmu、Ymu分别代表果蝇更新后的位置坐标,(Xaxis,Yaxis)代表果蝇当前位置坐标,normrnd为随机搜索函数,生成每一个果蝇的随机搜索距离。
基于组合模型的网络热点事件预测算法的执行流程如图3所示。

图3 基于组合模型的网络热点事件预测模型的执行流程
3 实证结果与分析
3.1 实验数据集
实验阶段,本文选择了目前较为突出的网络热点话题印度疫情作为研究对象,并在全网搜索微博、百度、知乎等文档数据作为训练集,并与经典的神经网络模型算法进行对比实验,验证预测模型的准确性。
3.2 结果与分析
使用本文的组合模型针对上述热点事件的预测结果如图4所示。

图4 本文模型的话题预测结果
从图4可以分析出,本文提出的组合模型算法对热门事件的走势预测准确率较高,基本与实际走势保持一致。本文对样本的误差进行了统计,具体如图5所示。

图5 样本预测误差值
由误差测试图可知,误差整体保持在-0.1到0.1之间,而最大的绝对误差值为0.051。对比其他模型的预测精度,如表1所示。

表1 不同算法识别准确率
对比SVM、BP神经网络算法以及本文提出的算法,如表1所示。本文提出的算法精确度最高达到99.03%,对比其他模型算法提升了4%左右,算法的执行时间也更加少。说明引入了聚类分析和果蝇算法剔除了无效数据,提升了算法的精度,同时改善了整体的执行效率。
4 总结
本文提出基于组合模型的网络热点话题演化动态预测模型。首先使用改进的k-means聚类分析缩小样本空间范围,然后应用改进果蝇算法筛选支持向量机模型的最优参数,进一步提升预测模型的精度。实验结果表明本文提出的组合模型预测精度达到了99%,同时,性能方面也有较大的提升,具有较高的理论价值和实际推广应用前景。
