基于TinyYOLOv2的轻量化人流监控装置的设计与实现
2022-10-15逯雨辰梅健强
逯雨辰,梅健强
(天津职业技术师范大学 电子工程学院,天津 300222)
0 引 言
公共场所人流密度监控是对指定空间和时间范围内的人员数量信息进行统计量化的方法,是实现人员身份识别的重要基础,对降低疫情常态化下交叉感染风险具有重要意义。当前公共场所人流密度监控大多通过人工目视方法进行,检测效率低、功能单一,易受监控人员主观因素影响造成统计错误,且速度和精度难以满足实时要求。视频图像分析监控人流的方案十分具有前景,是计算机视觉领域长期活跃的基础性问题,随着计算机科学技术的不断发展,越来越多基于人工智能,特别是基于深度学习的特征检测技术不断涌现,成为目前视频图像分析监控研究的热点问题。
1 系统设计
本装置旨在通过TinyYOLOv2神经网络对数字图像传感器采集的图像进行处理,检测图像内是否存在人脸目标并对其进行标记,同时统计当前图像内存在的目标数量、估算本装置单次运行周期内检测到的目标总数,并最终实现监控区域内部人流量的目的。
1.1 TinyYOLOv2介绍
YOLO算法作为一种“单阶段”检测算法,在处理图片时,首先会将图片缩放为448×448像素,以匹配全连接层对于固定大小向量输入的需求。此外,YOLO算法先将图片分割为7×7的网格(grid),并允许每个网格出现2个边界框,总计98个候选区域,随后再对每个候选区域进行目标识别以及定位。YOLOv2算法在YOLO算法的基础上进一步优化,采用了称为Darknet-19的网络模型结构,计算量减小约33%,速度更快、准确率更高、可识别的对象更多。此外YOLOv2在YOLO的基础上还进行了以下改进:
(1)添加批归一化(Batch Normalization),即通过在YOLO中的所有卷积层上添加批归一化,平均精度均值(Mean Average Precision, mAP)提高了2%以上。
(2)使用高分辨率图像微调分类模型,使mAP提高近4%。
(3)借鉴了Faster R-CNN的做法,采用先验框(Anchor Boxes),同时移除了全连接层与一个池化层,使网络卷积层的输出具有更高的分辨率。这项改进将召回率提高88%,但降低了一些mAP。
(4)引入聚类提取先验框尺度(Dimension Cluster),即相较于Faster R-CNN手工设定先验框的做法,YOLOv2尝试通过聚类分析的方法寻找更加合适的先验框。
(5)使用直接位置预测(Direct Location Prediction)的方法以提高模型的稳定性。
(6)开创性的引入了直通层(Pass-through Layer)以更好的检测出较小的目标。
(7)使用多尺度训练(Multi-Scale Training)以应对不同尺寸的图像。
TinyYOLOv2是YOLOv2算法的轻量化版本,原理与YOLOv2相同但参数数量有所减少。TinyYOLOv2只有9个卷积层而YOLOv2有24个,TinyYOLOv2以牺牲准确度为代价获得了比YOLOv2更快的速度与更少的计算量,适用于算力有限的嵌入式系统。
1.2 基于K210的实现
本装置在设计目标上追求轻量化、低功耗和可快速部署的特点。主要由以下三部分组成:数据处理与运算单元、数字图像传感器及人机交互。数据处理与运算单元使用K210核心系统实现,数字图像采集部分及人机交互界面分别使用OV2640数字图像传感器模块以及2.8寸LCD液晶显示屏。如图1所示,本装置使用OV2640数字图像传感器模块采集图像,并通过柔性电路板(Flexible Printed Circuit, FPC)排线与之连接将数据传入K210核心系统进行处理,最终将处理结果传入由FPC排线连接的LCD液晶显示屏中供用户查阅,图2为系统逻辑框图。

图1 装置实物图

图2 系统逻辑框图
装置上电后即开始执行预设好的程序。首先读取预先存放在固件boot.py文件内的脚本程序,随后执行该脚本程序。在脚本内,程序首先进行各项外设、网络的初始化,随后进入脚本主循环体。程序主体和脚本主循环程序流程图如图3和4所示。
2 实验与讨论
2.1 静态模拟
模拟静态测试使用了由中国科学院自动化研究所发布的人脸数据集CASIA-FaceV5作为数据来源模拟现实中存在的目标,该数据集包含了来自500个人的2 500张彩色人脸图片。CASIA-FaceV5的面部图像是用Logitech USB摄像头在同一段时间内拍摄的。其中包括研究生、工人、服务员等。所有的面部图像都是24位彩色BMP文件,图像分辨率为640×480。典型的类内变化包括光照、姿态、表情、眼镜、成像距离等。测试将使用该数据集内100人的5张人脸图片共100×5=500张图片作为测试数据源。

图3 程序主体流程图

图4 脚本主循环流程图
为提高测试效率,本文使用开源计算机视觉库OpenCV编写测试程序。如图5(a)所示为进行单目标检测的模拟测试场景,15.6英寸的屏幕上以1帧/秒的速度动态显示CASIA-FaceV5数据集的部分人脸图片,设备通过摄像头采集计算机屏幕的图像进行检测,图5(b)所示为检测结果样例,测试参数及结果如表1所示。


图5 单目标模拟测试场景及结果样例
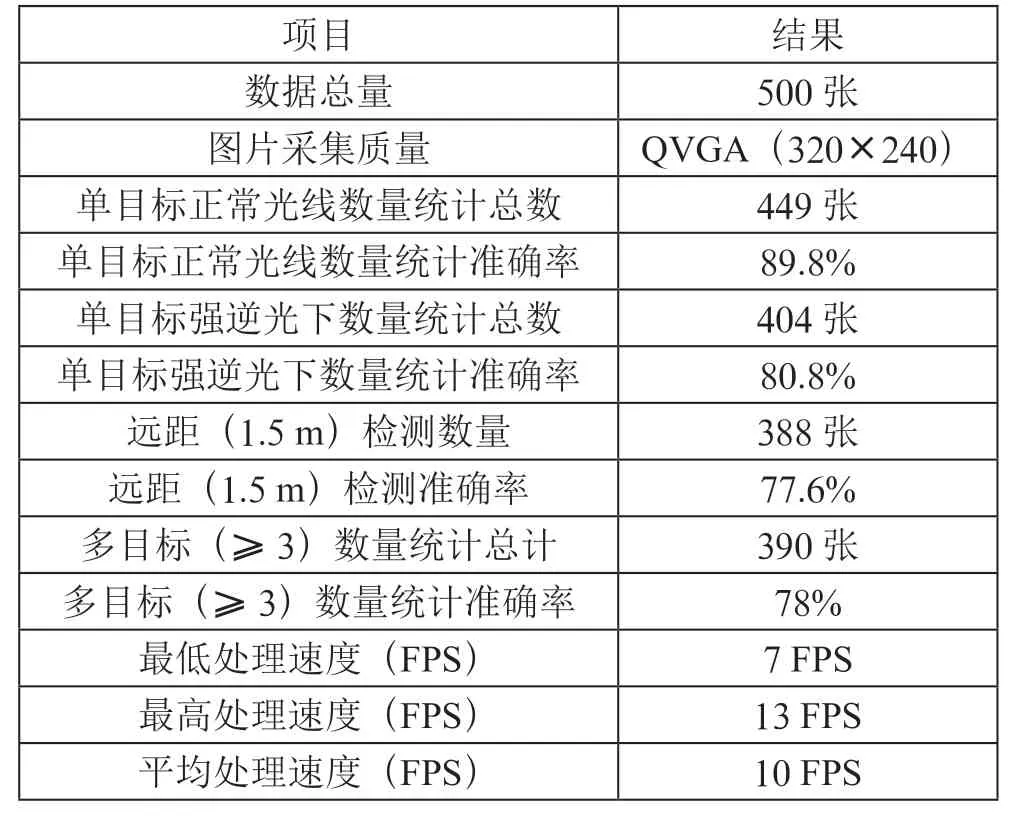
表1 单目标模拟测试参数及结果
其中准确率计算方式由以下公式给出:

由模拟静态测试可见,本装置在顺光、近距(检测距离≤1.5 m)且同时出现的目标数较少(≤2个目标)的固定环境使用场景下可以达到接近90%的人数统计准确率。此外,在目标检测准确率方面,对于1.5米左右的目标仍然能达到77.6%的检测准确率。在同时检测到6个目标的情况下仍然有平均7.9 FPS的处理速度,在面对多目标同时出现的使用需求场景,本装置的人数统计准确率可以达到78%。
2.2 实景测试
实景动态测试中,本装置将被部署在非紧急情况下时建筑物的唯一出入口处,针对20分钟内通过该出入口的人员总数进行统计,以本装置统计人数与人工计数相比对的方式测试本装置在实际使用中的具体效果。测试最大检测距离为2.3米,平均处理速度为12 FPS,最大移动目标(移动目标的移动速度参考人类正常步行速度,不超过1.5 m/s)检测数量为5个,最大静态目标检测数量为6个,其中面部可检测角度(水平方向)为45°左偏~45°右偏,面部可检测角度(垂直方向)为45°仰角~15°俯角(双眼与镜头之间的视线与地面平行时视作基准0°),具体测试结果如表2所示。
其中人数统计准确率计算方式由如下公式给出:


表2 现实使用场景测试项目及结果
测试中发现,本装置在目标距离超过2.3米后检测成功率将会降低至不可接受的程度,推测受到如下因素制约:
(1)TinyYOLOv2相对于YOLOv2提高了速度但降低了准确性,导致该在检测小目标时准确度低。
(2)远于2.3米后,人脸目标在图像中过小,且TinyYOLOv2在处理图像时会进一步降低图像分辨率,使得目标难以被TinyYOLOv2检测。
由于移动目标成像模糊,导致TinyYOLOv2神经网络难以检测,导致本装置对移动目标的效果弱于静态目标,该现象在目标移动速度增加时尤为明显。如表2所示,以人工统计数为基准,本装置在20分钟内对人员密集场所的人员数量统计准确率为96.5%,达到预期效果。
3 结 论
本装置使用TinyYOLOv2神经网络模型对人脸目标进行检测,并实现了对一段时间内途经某一地点的总人数进行统计的功能,可以辅助公共场所的管理人员对小范围空间内的人流进行监控,对场所进行针对化管理。本装置具有轻量化、功耗低、可快速部署、误差小的特点,具有一定的使用价值。
