基于边缘样本的智能网络入侵检测系统数据污染防御方法
2022-10-14刘广睿张伟哲李欣洁
刘广睿 张伟哲,2 李欣洁
1(哈尔滨工业大学网络空间安全学院 哈尔滨 150001) 2(鹏城实验室 广东深圳 518055)
入侵检测系统是防护网络设备免受恶意流量攻击的重要手段之一[1].然而随着网络环境的日益复杂化,传统基于规则匹配的检测方法已经无法应对手段多样的黑客攻击[2].各大安全厂商陆续将人工智能引入网络入侵检测系统[3],期望深度学习技术可以自动化检测更多未知的网络攻击.
但是由于流量样本存在概念漂移现象[4],样本的特征分布与类别情况会随着时间变化,这使智能入侵检测系统必须频繁更新以适应新的特征样本分布.目前主流的更新方式有2种:
1)离线更新模型[5-7].将线上模型替换为线下的新模型,是线下有监督训练模型.
2)在线更新模型[8-11].将实时捕获的网络流量作为模型的训练样本,是线上无监督训练模型.
离线更新模型的性能取决于训练样本的选择.训练样本的来源主要有网络环境收集和厂商合作交换2类.前者的样本标签依赖已有模型识别结果,后者的样本标签依赖合作方工作.在以上2种情况下,模型维护方都无法确定样本标签的准确性,这导致目前训练样本的筛选严重依赖人工检查.
在线更新模型虽然可以减少人为干预的工作,但多数现有研究工作[8-11]将所有测试样本作为模型训练数据.而真实的网络环境中存在海量流量数据,这种更新方式需要耗费大量运算资源,并且网络中流量的情况复杂多变,直接在线训练模型存在多种安全隐患[12].可见,缺乏样本筛选的在线更新方法不具备实用性,这导致多数厂商仍选择离线方法更新模型[13].
如图1所示,目前智能入侵检测系统更新方法存在3个问题:
问题1.人工检查样本工作量大.人工筛选训练样本的工作量不比设计传统的检测规则的工作量少,这令基于深度学习的检测系统维护成本比传统规则匹配的更高.
问题2.更新导致模型准确率不增反降.训练样本可能存在标签错误或数据不平衡等问题[14],人工修正标签或调整数据分布只能依靠专家经验,导致经常出现模型更新后准确率降低的情况[15].
问题3.无法有效过滤被污染的投毒样本.最新的工作指出[12]攻击者可以在网络中传输看似无害的对抗性流量样本,这些流量与正常流量别无二致,但其会使得模型被数据投毒或被构造后门.
目前已有的工作对上述问题解决效果并不理想.对于问题1,现有工作[8]注重将特征提取流程自动化,但缺乏考虑数据清洗与过滤工作.选择哪些样本加入训练集,不同类别间样本量比例以及样本分布如何调整仍需依赖专家经验.问题2和问题3本质上都属于数据污染[16].现有工作主要有2类方法:1)投毒样本检测方法[17-20]集中于识别单独样本的毒性,会引起较高误报率,且模型复原代价高;2)增强模型鲁棒性方法[21-24]会影响训练样本分布,降低模型准确率.
本文旨在解决以上3个问题,为智能网络入侵检测系统设计一套支持污染数据过滤的通用模型更新方法.其主要存在4项挑战:
挑战1.通用自动化样本筛选.对基于任意常见人工智能算法的网络入侵检测系统的新增训练样本实现污染过滤.
挑战2.正向稳定更新.在环境样本分布不发生剧烈变化的情况下,避免模型准确率出现更新后不增反降的情况.
挑战3.投毒攻击检测.能够及时发现训练样本中的中毒数据,有效识别数据投毒攻击.
挑战4.中毒模型修复.在模型被污染数据影响后,以较小的代价复原模型,保证模型可以正常训练并使用.
本文基于一个常见的前提假设[8-9],即虽然流量样本存在概念漂移现象,但通常样本分布不会发生剧烈变化,而模型的每次更新也应该平滑过渡.如果网络环境发生剧烈变化,如节假日,应积极加入人工检测或单独设计样本过滤算法应对特殊情况.
本文的主要贡献包括4个方面:
1)为解决挑战1,提出了一种通用的智能网络入侵检测系统数据污染防御方法.通过监控模型更新前后的变化,实现自动化污染数据过滤与模型修复,对模型的性能和健壮性起到保障作用.
2)为解决挑战2,提出了一套基于衡量训练样本子集污染程度的模型更新方法.通过检查新增训练样本与原模型的均方误差(mean square error,MSE)保证模型平稳更新,提升模型准确率.
3)为解决挑战3,设计了一种计算模型分类界面边缘样本的生成对抗网络.通过检查新模型对旧边缘样本的Fβ分数,判断模型分类界面是否被投毒攻击拉偏,及时对投毒攻击进行预警.
4)为解决挑战4,在系统受到投毒攻击后,通过让模型学习恶意边缘样本,抑制投毒样本对模型的影响,同时保证其他正常样本仍可作为训练数据,大幅降低了修复模型的代价.
为了与现有工作对比,我们在常用流量数据集CICIDS2017[25]中测试了本文提出的更新方法.对比现有最先进的方法,该方法对投毒样本的检测率平均提升12.50%,对中毒模型的修复效果平均提升6.38%.
我们公布了框架源码(1)https://github.com/liuguangrui-hit/MseAcc-py,其已在多种智能入侵检测系统中测试运行[5-9],均实现了模型的稳定正向更新,同时完成数据污染的过滤与修复.对于在线更新模型,该框架需搭载在特征提取器后;对于离线更新模型,则可搭建在模型外.
1 相关工作
1.1 智能网络入侵检测系统
Mahoney等人[26]将人工智能引入网络入侵检测系统(network intrusion detection system, NIDS),让模型学习从链路层到应用层的协议词汇表,以检测未知攻击.近年来人工智能技术快速发展,多种深度神经网络都已被引入到不同NIDS中,典型的包括深度神经网络(DNN)[5]、循环神经网络(RNN)[6]、长短期记忆神经网络(LSTM)[7]、多层感知机(MLP)[8]以及门控循环单元(GRU)[9]等.虽然智能NIDS对传统恶意流量的识别率很高,但是现有的以离线有监督方式训练模型的系统[5-7]缺乏对数据投毒攻击的防御以及修复方法,而以在线无监督方式训练模型的系统[8-11]也没有考虑如何在训练样本被污染的情况下稳定更新模型.表1对比了不同智能NIDS的具体实现算法.
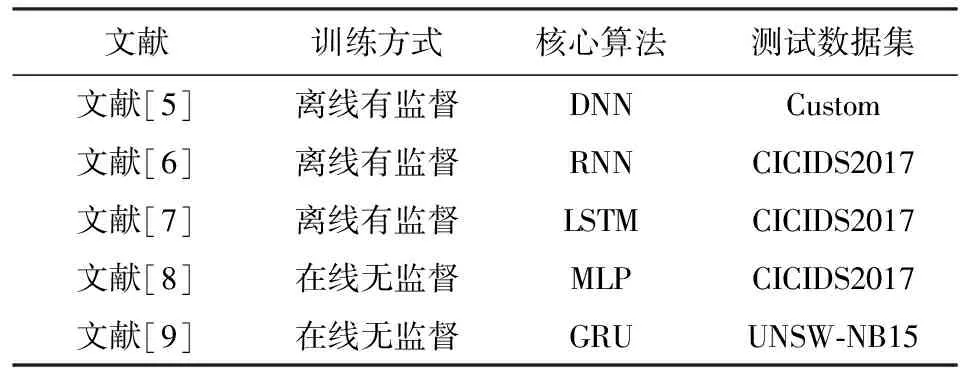
Table 1 Comparison of Typical Intelligent Intrusion Detection System Work
1.2 数据投毒攻击技术
面向智能NIDS的数据投毒攻击方法主要分为标签翻转和模型偏斜2类.表2对比了12种典型的对智能NIDS的数据投毒攻击技术.
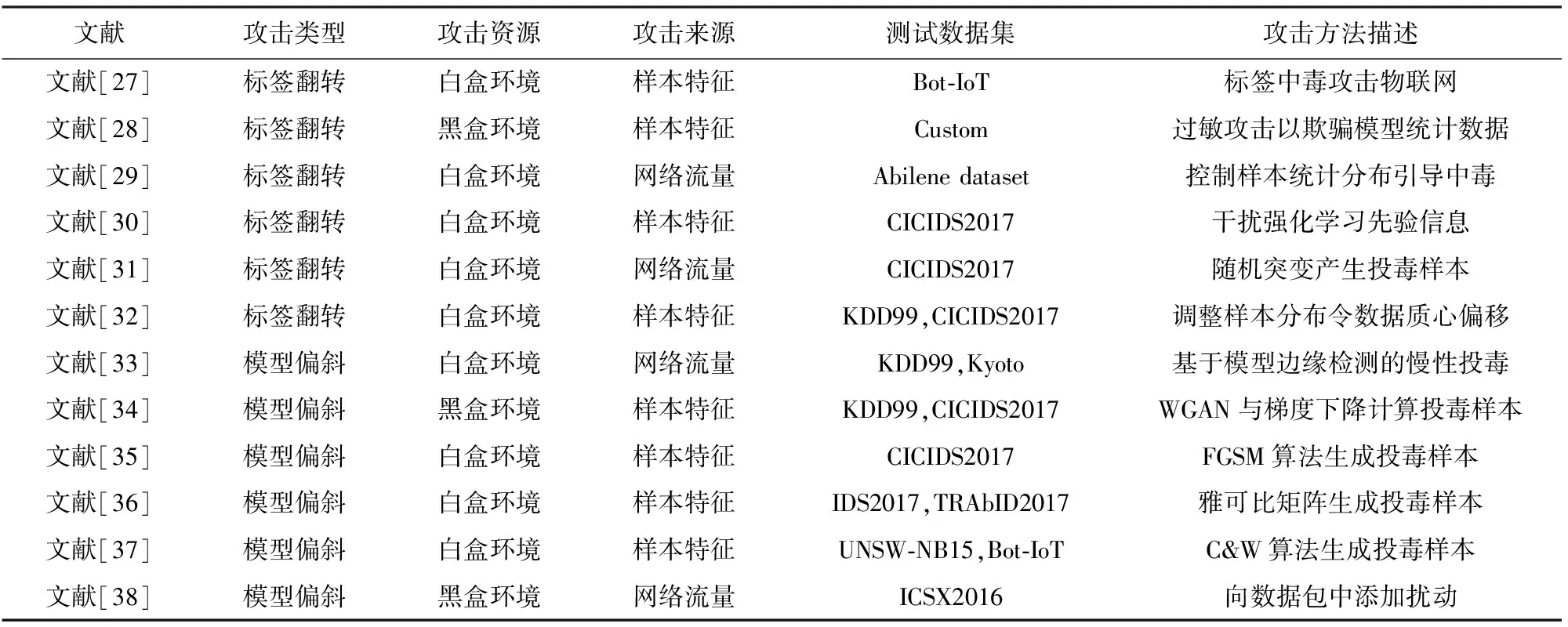
Table 2 Comparison of Typical Data Poisoning Attack Techniques for Intelligent NIDS
1)标签翻转假设攻击者可以控制智能NIDS的部分训练过程,并通过引入错误标签的训练样本干扰模型学习.文献[27-32]分别通过标签污染、过敏攻击、控制样本分布、干扰先验信息、随机突变以及质心偏移等方式对模型进行投毒攻击;
2)模型偏斜是一类通过输入大量良性对抗样本拉偏模型分类边界的攻击方法,其可在黑盒条件下实施投毒攻击.文献[33-38]分别使用边缘检测、生成对抗网络(GAN)、快速梯度符号方法(FGSM)、雅可比矩阵、C&W、向数据包添加扰动等算法生成影响模型训练的对抗样本.
1.3 数据污染防御技术
数据污染的诱因有误差噪声和数据投毒2种,由于现有对数据投毒攻击的防御技术通常也对误差噪声有一定过滤能力,所以将对误差噪声和数据投毒的防御统称为对数据污染的防御,并统一评价.
面向智能NIDS的数据污染防御技术主要分为数据清洗和鲁棒性学习2类.表3对比了8种典型的对智能NIDS的数据污染防御技术.
1)数据清洗是一种避免将污染数据输入到模型中或降低输入样本毒性的技术.文献[17-18]分别通过样本格式化和消除输入扰动降低样本毒性.文献[19-20]分别通过类别分布差异和神经网络敏感度检测投毒样本.此类方法可达到较高的准确率,但也会引起较高的误报率,且模型复原代价高.
2)鲁棒性学习是一种通过增强模型鲁棒性,保证训练样本中即便混入污染数据,也不会对模型造成严重影响的防御方法.文献[21-24]分别通过稳定样本分布、引入脉冲神经网络、特征缩减、对抗训练方式增强模型的抗毒性.此类方法通常要以降低模型准确率为代价.
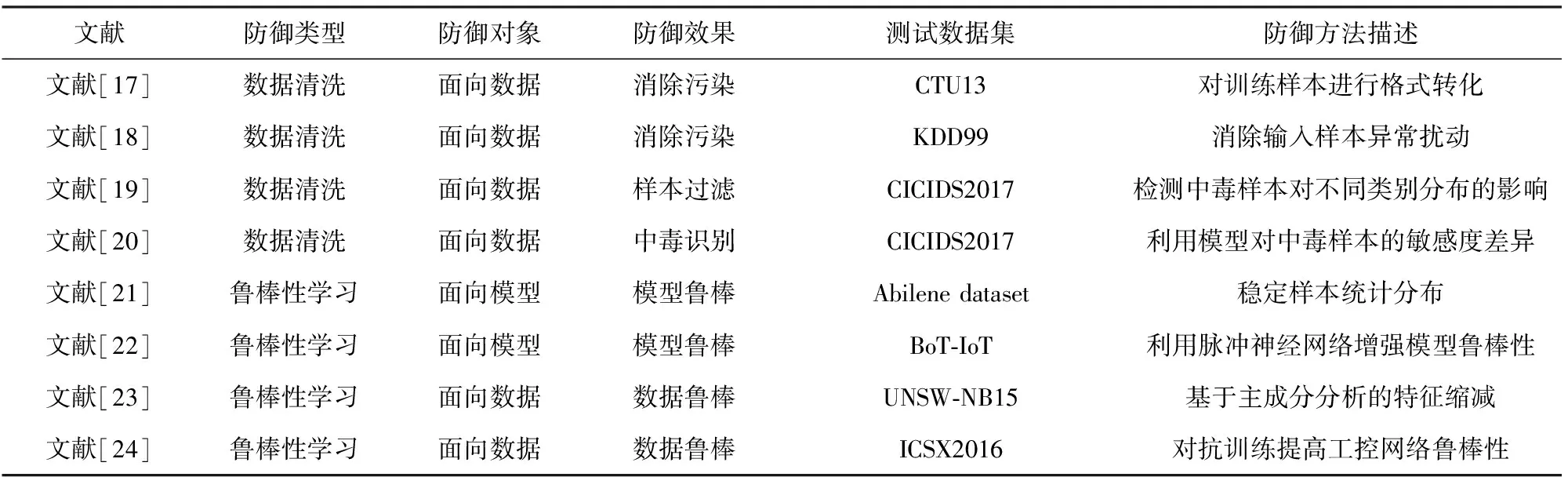
Table 3 Comparison of Typical Contaminated Examples Defense Techniques for Intelligent NIDS
2 通用智能入侵检测系统更新方法
本节主要介绍如何实现智能NIDS中模型的安全稳定更新.说明如何计算模型分类界面附近的边缘样本,怎样利用边缘样本识别训练数据中被污染的样本子集,以及在模型中毒后如何快速修复.
2.1 边缘样本生成算法
攻击者对智能NIDS的数据投毒一般是为后续攻击所做的准备[39-40],因为仅令NIDS失效对攻击者而言没有直接受益.投毒攻击的目标是令模型无法识别部分恶意流量.如图2所示,对智能NIDS投毒的本质是将模型的恶意分类区域缩小,即将分类边界向恶意分类区域内部推动,使后续恶意流量更容易绕过NIDS检测.而模型更新时分类边界变化一般为相反方向.由于网络环境中可能仍存在旧有攻击流量,基于规则匹配的NIDS不会因系统更新而删除旧有规则,而基于人工智能的NIDS也不因模型更新而使恶意分类区域大幅缩小.
我们设计了边缘样本生成算法,以快速确定模型分类边界的变化情况.最新工作已经讨论了在特征空间内对抗样本和分类边界以及数据流形的位置关系,并证明了对抗样本位于模型分类边界附近[41-42].基于此,我们设计了一种可以快速生成边界样本的算法.首先利用人工智能模糊测试技术[43](AI Fuzzing)寻找模型错误识别的样本,其存在于真实网络中;然后利用EdgeGAN算法生成处于模型分类边界附近的对抗样本集合,其存在于特征空间中.由模糊测试启动EdgeGAN的判别器可以缩小边缘样本搜索范围,加快EdgeGAN收敛速度.模糊测试得到的错误分类样本包含接近分类边界的样本簇和远离分类边界的异常点,通过令EdgeGAN的判别器与生成器对抗,使生成器分布拟合分布较广的边缘样本.
EdgeGAN算法结构如图3所示.通过迭代训练判别器与生成器,使生成器拟合可令模型错误分类的对抗样本.通过限制扰动向量z的模值,避免生成器向异常点拟合.其优化目标为
E(xtr,z)~p(xtr,z)(xtr,z)[log(1-D(G(xtr+z)))].
(1)
其中,xtr∈T和xfa∈F,T,F分别为错误分类和正确分类的样本特征向量集合;pxfa(xfa)为xfa的概率分布,p(xtr,z)(xtr,z)为xtr与噪声z的联合概率分布;G(xtr+z)为对抗样本.
EdgeGAN中生成器G利用已有边缘样本进行训练,其目标是生成与边缘样本分布相近的对抗样本.而判别器D则致力于区分边缘样本和生成器G产生的对抗样本.
LD=Exfa~pxfa(xfa)[logD(xfa)]+
E(xtr,z)~p(xtr,z)(xtr,z)[log(1-D(G(xtr+z)))].
(2)
式(2)为判别器D的损失函数,其表达了D识别边缘样本的概率分布与G生成对抗样本的概率分布之间的差距.对于一个确定的对抗样本,当生成器G固定时,该损失函数值越小代表D的推理能力越强.
LG=E(xtr,z)~p(xtr,z)(xtr,z)[log(1-D(G(xtr+z)))].
(3)
式(3)为生成器G的损失函数,其表达了G生成的对抗样本对D的欺骗能力.在判别器D固定时,该损失函数越小代表G生成的对抗样本越接近模型分类边界.
迭代训练判别器D与生成器G,使G生成的对抗样本不断逼近模型边缘.当训练完成后,向生成器G中输入任意流量样本即可返回边缘样本.使用生成对抗网络而不是简单插值计算边缘样本可使该框架适用于更多的智能NIDS,减少人工计算成本.EdgeGAN边缘样本生成器的具体训练算法如算法1所示.
算法1.边缘样本生成器EdgeGAN训练算法.
输入:流量样本集T={x1,x2,…,xn}、当前NIDS模型f、判别器初始参数ω0、生成器初始参数θ0;
输出:判别器参数ω、生成器参数θ.
① whileθ未收敛do
②AI-Fuzzing(xi,f),i=1,2,…,n;
/*将流量样本输入NIDS模型中进行
模糊测试*/
③T←xtr,F←xfa;/*正确识别的样本留在集合T,错误识别的样本放入集合F*/
④ 从F中抽取一批样本xfa;
⑤ 生成器G根据xtr计算对抗样本G(xtr+z);/*z为服从正太分布的随机噪声向量*/
⑥ 从T中抽取一批样本xtr;
⑦ 判别器D输出xfa和对抗样本G(xtr+z)的预测标签;
⑧T←G(xtr+z);/*生成器G生成的对抗样本G(xtr+z)补充集合T*/
⑨ 根据判别器D的预测标签沿着梯度∇ωLD下降方向更新判别器参数ω;
⑩ 根据判别器D的预测标签沿着梯度∇θLG下降方向更新生成器参数θ;
2.2 污染数据过滤
首先使用人工筛选的少量干净数据集预训练模型,然后利用本文的更新框架自动化更新模型.在模型更新过程中,为避免因高误报率导致频繁人为干预,数据污染的检测由传统的单独样本毒性检测[22]变为样本集污染程度分析.将全部待训练数据分为若干子集,分批迭代更新模型.
为了让模型平稳更新,在每批训练样本子集输入模型前,检测新增训练样本与原模型的MSE值,以判定新训练数据与现有模型的偏差.MSE的计算公式为
(4)
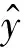
更新允许出现偏差,但如果偏差过高,即MSE值超过阈值,则表明该批样本中错误标签过多,需要修复模型.标签错误的原因有2种,因误差产生或因标签翻转攻击产生.MSE值可有效识别以上2种数据污染.
2.3 投毒样本检测
由于模型偏斜攻击的投毒样本均为良性对抗样本,其真实标签和模型预测标签均为良性,MSE值无法有效检测.模型偏斜攻击的目标是缩小模型恶意分类区域,通过输入大量良性对抗样本影响样本平衡性,使分类边界向恶意分类区域内移动.而训练后模型对原模型边缘样本的Fβ分数可以显示训练样本对模型分类边界的影响.Fβ的计算公式为
(5)
(6)
(7)
其中,TP为真阳性样本数量,即被模型正确识别的良性样本数量;FP为假阳性样本数量,即被模型错误识别的恶意样本数量;FN为假阴性样本数量,即被模型错误识别的良性样本数量.
Precision为精确率,表示被模型识别为良性的样本中识别正确的样本占比;
Recall为召回率,表示模型在识别良性样本时能够正确识别的样本占比;
Fβ分数展现了样本的平衡性,Recall的权重是Precision的β倍.
如图4所示,在检测投毒样本时,对恶意边缘样本被识别为良性的容忍度低,即避免恶意分类区域缩小,对FP值限制严格;对良性边缘样本识别为恶意的容忍度高,即允许恶意区域扩大,对FN值限制宽松.所以精确率的权重高于召回率,故0<β<1.
更新允许出现不平衡,但如果平衡性过低即Fβ分数低于阈值,则表明该批样本中存在投毒样本,需要修复模型.值得注意的是,如果Fβ分数出现异常,则明确表明环境中存在针对该系统的投毒攻击者.
2.4 中毒模型修复
由于MSE值与Fβ分数的阈值选择受到子集样本数量、特征与标签数量以及网络环境等因素影响,无法给定标准值.可通过记录模型训练干净数据时二者的波动情况设定阈值.
当发现训练样本已被污染,即MSE高于阈值或Fβ分数低于阈值时,需立即修复模型.如果拥有大量训练数据,可以选择丢弃该子集内样本.但由于训练样本子集可能仅部分被污染,直接丢弃该子集会造成较大损失.此时模型可正常训练,并通过在训练子集中加入边缘样本中的恶意样本修复模型.恶意边缘样本可以抑制模型恶意分类区域向内缩小,以抵御投毒攻击.
传统方法依赖梯度计算[17]或存储历史参数[18]等方式修复模型,其对于大规模智能NIDS不具备实用价值.依赖梯度计算需要大量人工操作,且依赖于特定模型,缺乏通用性;而存储历史参数需要存储海量模型参数,且无法确定模型应恢复到哪一参数状态.我们的方法通过存储少量的更新前模型边缘样本,无需存储模型历史信息,即可完成污染检测与模型修复.智能NIDS中模型完整的更新流程如图5所示:
3 实验及分析
本节展示了我们提出的模型更新方法在5种典型的智能NIDS[5-9]上的效果.使用2类常见数据污染算法[32,38]对模型进行攻击测试.实验验证了新方法在污染数据过滤上的有效性,并与现有最先进的方法[19-20,23-24]对比了投毒样本的检测率与中毒模型的修复效果.
3.1 数据集与目标系统
1)数据集预处理
本文采用改进版的CICIDS2017数据集[25],其修正了原始数据中的标签错误和丢失问题,并改善了类别不平衡情况.
我们删除了CICIDS2017数据集中特征缺失样本并将相似类别合并,得到共2 823 541条流量样本记录.其中包含PortScan,Web-Attack,Bruteforce,Botnet,DoS,DDoS这6种恶意类别和Benign这1种良性类别.每个样本xi(1≤i≤n)拥有78维特征xij(1≤j≤78)和1维流量分类标签yi.通过z分数标准化消除不同维度的特征量纲.
(8)
(9)
(10)
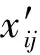
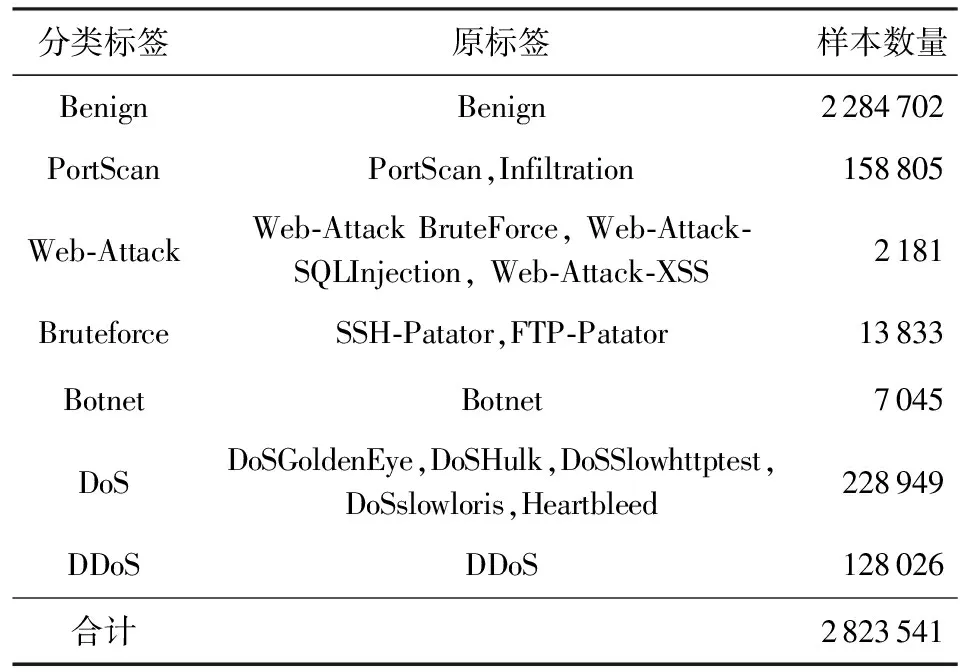
Table 4 The Components of the Processed CICIDS2017 Dataset
2)目标智能网络入侵检测系统配置
本文选用5个典型的智能NIDS作为更新方案实验对象,它们分别为文献[5]提出的基于DNN的NIDS、文献[6]提出的基于RNN的NIDS、文献[7]提出的基于LSTM的NIDS、文献[8]提出的基于MLP的NIDS,以及文献[9]提出的基于GRU的NIDS.
(11)
本文使用准确率(Accuracy)评价模型性能,式(11)中TN为真阴性样本数量,即被模型正确识别的恶意样本数量,其他变量含义见2.3节.随机抽取训练集各类别中0.01%数量的样本作为预训练数据集.5种不同NIDS模型在使用预训练数据集训练后,在测试集上的准确率如表5所示.各NIDS模型以此作为基础进行3.2节与3.3节的有效性实验与对比实验.

Table 5 Accuracy After Intelligent NIDS Pre-training
3.2 有效性实验
1)MSE值与Fβ分数的阈值设定
新增训练集10 000 000条,划分为20个训练样本子集,即每个子集包含500 000条样本.子集中样本按类别标签等比例随机抽取.每轮更新计算模型500条边缘样本.
表6和表7展示了5个智能NIDS在正常完成20个干净样本子集训练时的MSE值与Fβ分数的波动情况.5个模型的MSE最大值均低于0.3,Fβ分数最小值均高于0.9.因此选取MSE阈值为0.3,Fβ阈值为0.9,β值取0.5.
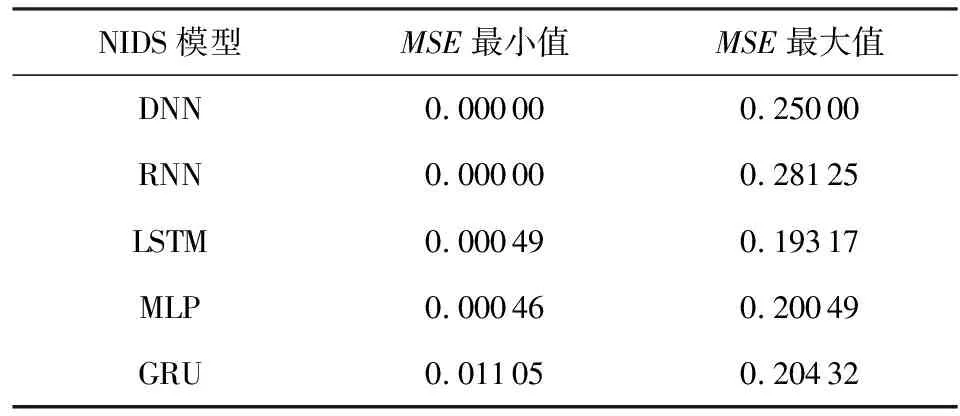
Table 6 MSE Fluctuations of Different Models During Regular Training
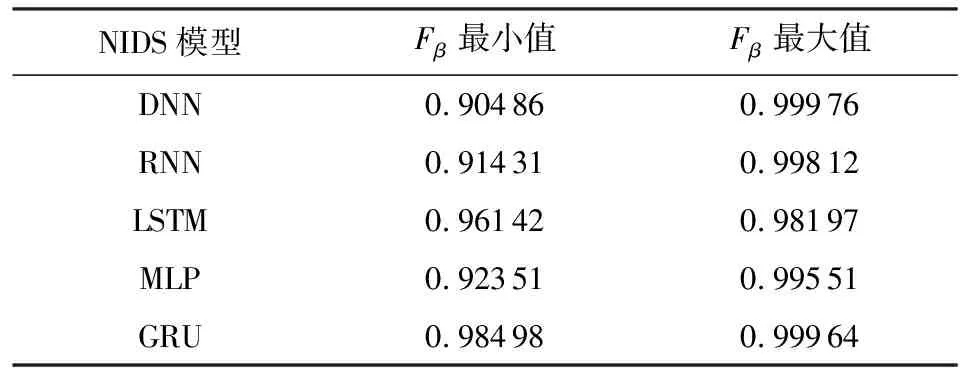
Table 7 Fβ Fluctuations of Different Models During Regular Training
2)污染过滤与模型修复效果
5个智能NIDS模型预训练后初始准确率如表5所示.在此基础上按照本文提出方案(如图5所示)训练20个样本子集.对第11~14个样本子集进行数据污染,污染样本占总样本数的10%.数据污染方式选取文献[32]与文献[38]的投毒攻击.文献[32]通过修改训练样本标签造成的数据质心偏移,用以测试标签错误与标签翻转造成的数据污染;文献[38]通过向训练样本中添加良性对抗样本干扰模型训练,用以测试模型偏斜造成的数据污染.
实验对5种不同模型的NIDS依次测试其在5种情况下的参数变化:1)受到标签翻转攻击(投毒-标签翻转);2)受到模型偏斜攻击(投毒-模型偏斜);3)受到标签翻转攻击后修复模型(修复-标签翻转);4)受到模型偏斜攻击后修复模型(修复-模型偏斜);5)正常训练的对照组(未投毒).其中,“-”前是区分投毒且不修复(记作“投毒”)或投毒且修复(记作“修复”);“-”后是区分投毒攻击类别为“标签翻转”或“模型偏斜”.图6~10展示了模型训练过程中MSE值、Fβ分数及准确率变化,MSE值主要体现本文方法对标签翻转的识别效果,Fβ分数主要体现本文方法对模型偏斜的识别效果,准确率对比了模型在5种场景下的性能变化.
实验验证了本文方法对标签翻转攻击与模型偏斜攻击的识别与修复能力.实验结果表明,本文方法在5中不同模型的NIDS中均能有效识别出投毒攻击并进行模型修复.当受到投毒攻击时,MLP和DNN模型会立刻发生变化,可以快速识别投毒样本子集;而由于RNN和LSTM模型具有时序性,使中毒效果延迟,也导致了投毒识别的延迟与漏报;GRU虽然也具有时序性,但其时间步距较大,无法推迟投毒效果,所以可以及时识别出其中毒情况.观察5种模型在修复时的准确率变化,可以看出虽然模型修复可以抵御投毒攻击并使中毒模型准确率逐渐恢复正常,但也会抑制模型的训练,所以边缘样本应仅在模型中毒时加入训练集.
3.3 对比试验
1)基准方法与变量设置
在对比实验中,中毒样本检测实验的基准方法选取自文献[19-20],中毒模型修复实验的基准方法选取自文献[23-24].其中文献[19]利用中毒样本对不同类别特征分布的影响检测攻击,文献[20]利用神经网络对中毒样本和正常样本的敏感度差异检测攻击,文献[23]利用主成分分析进行特征缩减提升模型鲁棒性,文献[24]利用雅可比矩阵进行对抗训练提升模型鲁棒性.为便于与现有工作在样本检测率和模型修复效果方面对比,将新增训练集10 000 000条,划分为100个训练样本子集,即每个子集包含100 000条样本.子集中样本按类别标签等比例随机抽取.对随机抽取的20个样本子集进行数据污染,污染样本占总样本数的10%.每轮更新计算模型100条边缘样本.模型初始状态、MSE值与Fβ分数的阈值设定、β取值与3.2节相同.
2)中毒样本检测实验
本文使用中毒样本的检测率(poison detection rate,PDR)与误报率(false alarm rate,FAR)评价不同方法对数据投毒的识别能力.
(12)
(13)
其中,TruePoison表示被识别为中毒的样本中识别正确的样本;FalsePoison表示被识别为中毒的样本中识别错误的样本;TrueClean表示被识别为干净的样本中识别正确的样本;FalseClean表示被识别为干净的样本中识别错误的样本.PDR表示在识别中毒的样本集时,正确识别的集合占比;FAR表示识别为中毒的样本集中,错误识别的集合占比.
图11和图12分别对比了本文提出方法、文献[19]、文献[20]对标签翻转类和模型偏斜类中毒样本的检测率与误报率.
实验对比了不同方法对标签翻转攻击和模型偏斜攻击的中毒样本集识别能力.实验结果表明,对比现有先进方法,本文方法对标签翻转投毒的识别能力在5种智能NIDS上均有提升.由于标签翻转攻击直接修改样本标签,较易被识别.本文方法又在投毒样本的特征和目的2个方面进行检测,有效提升了识别能力;本文方法对模型偏斜投毒的识别能力在DNN,MLP和GRU模型上有显著提升,在RNN和LSTM模型上效果欠佳.由于模型偏斜攻击借助对抗样本引导模型中毒,较为隐蔽.本文方法通过边缘样本检测模型分类边界变化,而RNN和LSTM模型具有时序性记忆,使分类边界变化较为滞后,影响了该方法的检测效果.具体来说,与现有先进方法相比,本文方法对标签翻转投毒检测率平均提升12.00%,误报率平均降低7.75%,对模型偏斜投毒检测率平均提升13.00%,误报率平均降低10.50%.
3)中毒模型修复实验
图13和图14分别对比了在本文提出方法、文献[23-24]保护下的模型受到标签翻转攻击和模型偏斜攻击的准确率变化.
实验对比了在不同方法保护下的模型受到标签翻转攻击和模型偏斜攻击后的准确率变化.实验结果表明,对比现有先进方法,在模型受到模型偏斜攻击后,使用本文方法修复的模型准确率在5种智能NIDS上均有提升.由于模型偏斜攻击利用良性对抗样本推动分类边界,本文方法使用恶意边缘样本训练模型,可以有效稳定边界不向恶意分类区域移动;在模型受到标签翻转攻击后,使用本文方法修复的模型准确率在DNN,MLP,GRU模型上有所提升,在RNN和LSTM模型上效果欠佳.由于标签翻转攻击修改了训练样本的标签,使模型学习了错误知识,因此模型不易被修复.而RNN和LSTM模型又使中毒效应延迟,导致模型防御较为滞后.但标签翻转攻击属于白盒攻击,攻击条件较为苛刻,且时序模型本身对投毒攻击具有一定抵御能力,使准确率不会严重下降.具体来说,与现有先进方法相比,本文方法对对标签翻转的修复能力平均提升6.20%,模型偏斜中毒的修复能力平均提升6.56%.
4 结 论
本文提出了一种利用边缘样本保护智能网络入侵检测系统免受数据污染的防御技术.相比传统投毒识别方法,本文方法更加关注模型变化,而非数据异常,其适用于任意常见人工智能算法,可减少人工样本筛选工作,有效降低了投毒检测与模型修复的代价.该方法利用模糊测试使生成对抗网络快速拟合模型分类边界的边缘样本分布.通过监控新增训练样本与原模型的MSE值,以及新模型对旧边缘样本的Fβ分数,保证模型平稳更新,避免模型中毒.当模型受到投毒影响时,通过学习恶意边缘样本快速复原.对比现有方法,本文方法对投毒样本的检测率平均提升12.50%,对中毒模型的修复效果平均提升6.38%.本文提出的方法也可以应用于其他相似的智能威胁检测问题中.但该方法对时序模型的防御效果较弱,今后将通过检测样本集之间的时序变化优化本文方法.
作者贡献声明:刘广睿提出了算法思路并撰写论文;张伟哲提出指导意见并修改论文;李欣洁负责设计实验方案并完成实验.
