云边端全场景下深度学习模型对抗攻击和防御
2022-10-14蔺琛皓杨雨龙方黎明
李 前 蔺琛皓 杨雨龙 沈 超 方黎明
1(西安交通大学网络空间安全学院 西安 710049) 2(智能网络与网络安全教育部重点实验室(西安交通大学) 西安 710049) 3(南京航空航天大学计算机科学与技术学院 南京 210016)
近些年,得益于数据数量和质量的提升、高性能硬件所带来的计算能力增长以及算法上的不断突破,以深度学习为代表的人工智能技术得到了前所未有的发展和应用[1].从指纹解锁、刷脸支付,到语音助手、产品推荐,再到智慧制造、无人驾驶,深度学习正全方位改变着人类的生产和生活方式[2].同时,模型轻量化技术的成熟也可将原本依赖于高性能图形处理器(graphic processing unit, GPU)的大型神经网络进行轻量化处理,让其在计算资源有限的嵌入式设备和物联网设备上也可部署运行.随着云边端计算架构的成熟,边缘计算正在日益走向智能时代的舞台中央.为了对各场景下产生的数据进行分析处理,越来越多的深度学习模型正在全球范围内大规模地被部署在云边端全场景,惠及人类生产生活的方方面面.
然而,随着人工智能技术的日益普及,深度学习模型的安全性和可靠性问题也逐步暴露,引起了学术界和工业界的广泛关注[3-5].2014年,Szegedy和Goodfellow等人率先注意到了深度学习模型中存在对抗样本(adversarial example)[6-7].Goodfellow等人指出,深度神经网络的高度非线性和数据分布空间的高维性导致其预测结果一般不可验证和解释,致使了模型推断盲区,即对抗样本的存在.2016年,美国前国家情报总监Clapper表示,人工智能系统的欺骗性和破坏性难以预测和理解,将会对国家安全和关键敏感信息的基础设施建设带来巨大危险;2018年,美国密歇根大学的研究表明,自动驾驶的无人车容易被对抗攻击所欺骗,导致严重的交通事故[8];2020年中国科学院院士姚期智在浦江创新论坛的演讲中指出深度学习的鲁棒性是通往通用人工智能道路的三大瓶颈之一;2022年Gupta等人的研究[9]打破了人们之前关于量化网络鲁棒性较强的认识,首次揭露了量化网络中存在的对抗攻击安全风险.由此可见,深度神经网络的鲁棒脆弱性问题已经成为其进一步发展的瓶颈之一.攻击者可以利用对抗攻击以诱导各场景下部署的人工智能系统,威胁其安全运行[10-11].因此,深入研究云边端各个场景下深度学习模型脆弱性问题并设计安全的对抗防御方法亟待解决并具有重大意义.
针对以上问题和挑战,研究者从不同的角度对深度神经网络的鲁棒对抗问题进行了调研和综述,包括针对语音识别[12-15]、图像处理[16-19]、自然语言处理[20]、多媒体信息处理[21]、强化学习[22]等任务的对抗攻防.然而,现有的深度学习模型对抗攻防相关文献综述大多针对特定的场景和应用,且仅围绕普通大型网络模型展开介绍,而缺乏针对轻量化网络模型攻击与对应的防御研究的系统性详细介绍.另一方面,针对轻量化模型,个别研究者目前仅从实验角度对其对抗鲁棒性进行了初步探索[23]:比如陈光耀等人[23]实验探究了模型压缩技术对模型对抗鲁棒性的影响;Qin等人[24]实验对比了二值量化网络(binarized neural networks, BNN)在白盒对抗鲁棒性和黑盒对抗迁移性方面的差异;Gorsline等人[25]实验研究了量化网络的对抗鲁棒性,发现量化网络与对应全精度网络之间的相对鲁棒性取决于攻击强度.然而,这些工作缺乏对轻量化网络的对抗攻防技术的系统归纳和总结.
随着边缘计算的发展,大型网络和轻量化网络均在实际场景中有越来越多的部署.为了更加全面深入地了解云边端全场景下深度学习算法的对抗攻防问题,需要对大型网络和轻量化网络的对抗攻防技术做整体分析和整理.
如图1所示,在云边端全场景下,由于端侧往往以轻量化模型为主,而云侧和边侧更多会部署大型网络,因此需要为二者分别设计针对性的对抗攻击与防御方法.本文从云边端全场景为出发点,分别整理了近年来针对大型网络和轻量化网络的对抗攻击安全风险以及相应的对抗防御技术.最后,本文梳理了目前研究尚未解决的重大挑战,展望了该领域未来可能的发展方向.
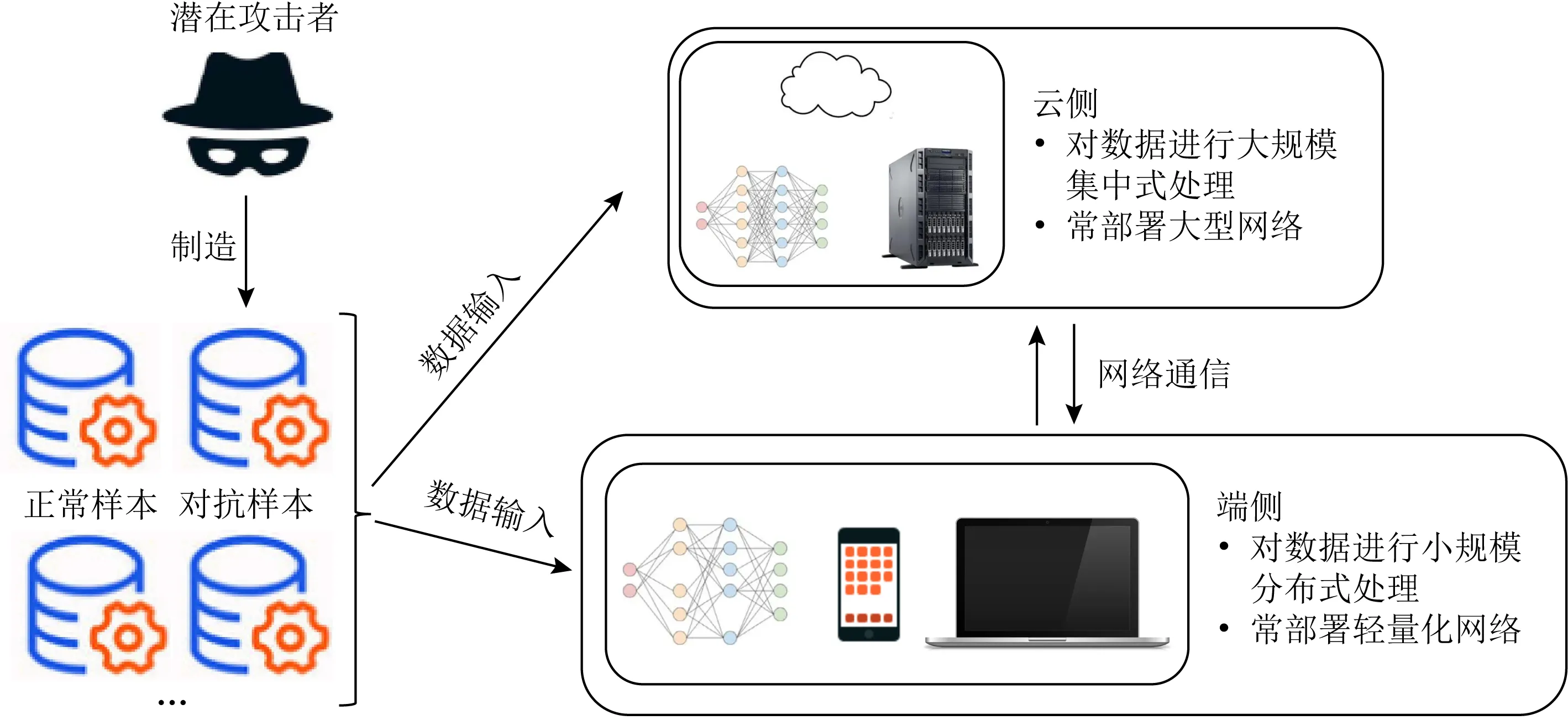
Fig.1 The illustration of adversarial attack and defense under the edge computing scenario
1 深度学习模型的对抗攻击安全风险
本节对深度学习模型所面临的对抗攻击安全风险做简单介绍,包括对抗攻击的定义和分类,以及对抗样本的机理解释.
1.1 对抗攻击的定义和分类
2014年,Szegedy等人首次发现了深度神经网络中对抗性样本的存在[6].攻击者可在正常样本x中加入对抗扰动σ生成对抗样本x′,x′=x+σ,使得目标模型给出错误的预测结果:f(x′;θ)≠f(x;θ).如图2所示,能够被深度神经网络(deep neural networks, DNN)正常预测为“大熊猫”的正常样本被恶意攻击者加入人眼不可察觉的对抗扰动后生成对抗样本,被DNN错误预测为“长臂猿”.为了使对抗扰动σ难以被人眼察觉,保证对抗攻击的隐蔽性,一般使用某种度量对扰动大小进行限制,比如p范数:其中ε是攻击者预先规定的扰动大小的上限值.Szegedy等人还发现了对抗样本的迁移性(transferability),即针对某一模型生成的对抗样本可在多种不同的目标模型上攻击成功.对抗样本的迁移性能够让攻击者生成一次对抗样本而攻击不同的目标模型,甚至是未知结构和参数的目标模型.
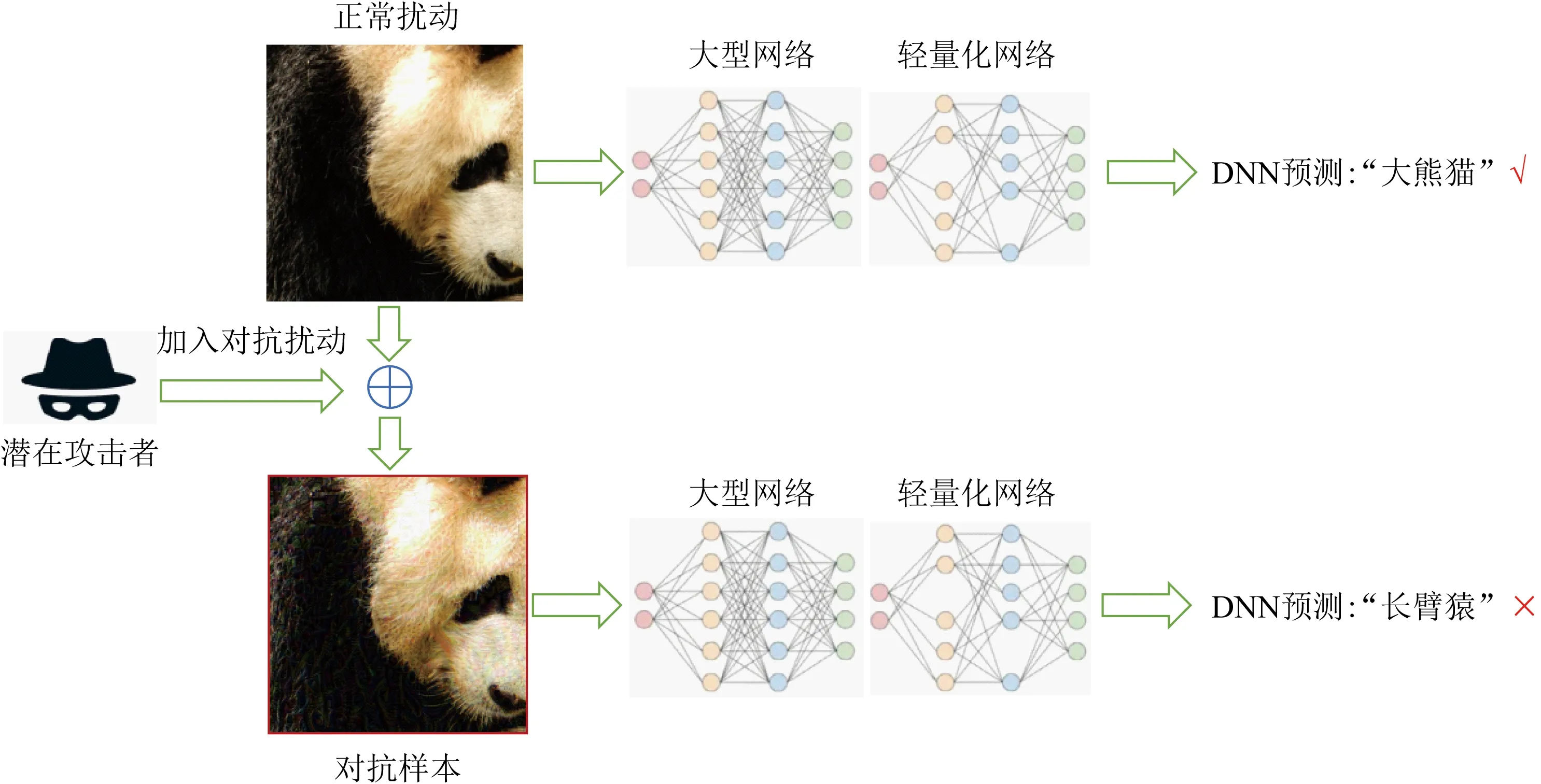
Fig.2 Illustration of adversarial example
按照攻击者所掌握有关目标模型信息的多寡,对抗攻击可分为白盒攻击(white-box attack)和黑盒攻击(black-box attack).白盒攻击假设攻击者已获得关于目标模型的一切信息,如模型结构、参数、梯度、训练过程和训练数据.黑盒攻击则假设攻击者只能访问目标模型的输出,而不能访问其内部参数和梯度信息.相比之下,黑盒攻击更加接近于真实的攻防场景,而白盒攻击常被用来作为一种最坏情况下的模型鲁棒性评价方式.按照攻击目标的不同,对抗性攻击可以分类为有目标攻击(targeted attack)和无目标攻击(non-targeted attack).有目标攻击致力于将模型的输出误导至一个攻击者预先指定的错误类别;无目标攻击则仅希望模型预测结果发生错误,以降低目标模型的可用性.需要注意的是,对抗攻击在大型网络和轻量化网络上都具有普遍的攻击效果.因此在云边端场景下,需要对大型网络和轻量化网络两者的对抗鲁棒性加以全面考虑.
1.2 对抗攻击的机理分析
由于对抗样本为深度学习模型带来了广泛的安全威胁,许多研究者开始关注对抗样本的存在机理.目前的研究者主要从数据和模型的角度给出分析解释.在数据角度方面,一些研究认为对抗样本之所以能够导致模型预测错误,是因为它们位于数据流形(data manifold)的低概率密度区域:Arpit等人[26]分析了神经网络记忆训练数据的能力,发现记忆程度高的模型更容易受到对抗样本的影响.在模型角度方面,Goodfellow等人[7]认为深度神经网络的线性性质和样本输入特征空间的高维度是对抗样本存在的重要机理.虽然深度神经网络使用非线性激活函数,但是为了避免诸如梯度消失等问题,人们使深度神经网络仅在激活函数的线性区域内运行,如常用激活函数ReLU和Maxout的线性部分.这种做法导致对抗扰动能够沿着网络逐层累加,直到扭转DNN的预测结果.此外,还有一些研究者[27]认为卷积神经网络(convolutional neural network, CNN)倾向于学习数据集中的统计规律,而非高度抽象的概念.CNN的这一这种特性可能与对抗样本的迁移性密切相关:不同的深度学习模型可能学习了相同的统计数据,因此容易受到迁移的对抗攻击.
2 针对大型网络的对抗攻击
如第1节所述,对抗攻击可按攻击场景分为白盒攻击和黑盒攻击.白盒攻击主要有基于梯度的攻击和基于优化的攻击2种算法实现思路;黑盒攻击则分为黑盒迁移攻击和黑盒查询攻击.在这些基础攻击算法的基础上,最新的研究又发展出了集成白盒攻击和自动化黑盒攻击,进一步提高了对抗攻击成功率并降低了算法调参门槛.
2.1 基于梯度的白盒攻击
基于梯度的白盒攻击利用目标模型的梯度信息指导对抗扰动的生成,包括2种典型方法:单步式梯度攻击快速梯度符号法(fast gradient sign method, FGSM)[7]和投影梯度下降法(projected gradient descent, PGD)[28].FGSM首先计算模型关于输入数据的一阶梯度信息,然后沿着梯度上升方向进行单步优化生成大小为ε的对抗扰动(扰动大小不超过预定义的ε时可保其视觉隐蔽性),即:
x′=x+ε·sgn(∇xL(f(x),y)),
(1)
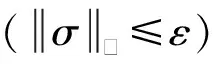
Madry等人[28]在BIM的基础上引入了随机初始化,称之为投影梯度下降法(projected gradient descent, PGD),进一步提高了白盒攻击的成功率.PGD是目前理论上最优的一阶对抗攻击算法.经过随机初始化之后,PGD反复利用一阶梯度信息优化对抗扰动σ,一旦σ的扰动值超出限定范围S,就用投影操作将对抗样本x′投影到规定范围x+S之内.PGD的迭代公式为

(2)
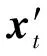
2.2 基于优化的白盒攻击
基于优化的攻击将对抗样本生成的攻击成功目标和扰动不可察觉性目标分别写为目标函数或者限制性条件,构成一个带有等式或不等式约束的限制性优化问题.然后可使用拉格朗日松弛法(Lagrangian relaxation)将其转化为非限制性优化问题,并应用某种优化算法进行求解.目前基于优化的白盒攻击的最典型方法是C&W攻击[30].
C&W攻击的优化目标是使攻击目标类别和除了目标类别之外置信度最高的类别的Logit值的距离最小,直至攻击目标类别的Logit值反超其他所有类别的Logit值,从而将模型的预测结果误导为攻击者所指定的目标类别.在模型的预测结果发生翻转后,C&W攻击会继续增大目标类别的Logit值与第二大Logit值之间的差距,直到达到一个预设值κ.这种做法使生成的对抗样本具有一定的攻击冗余度,能够稳定地使目标模型出错.另外,κ还具有提升对抗样本迁移性的作用,高的κ值会提高对抗样本的迁移性.基于此,C&W攻击成功攻破了使用防御性蒸馏(defensive distillation)[31]的目标模型,证明了该模型的防御方法是不可靠的.
2.3 集成白盒攻击
PGD攻击和C&W攻击虽然已经达到了相对较高的白盒攻击成功率,但是仍有一些研究者在继续进行尝试,并成功推动了白盒对抗攻击的边界.其中的典型代表就是集成对抗攻击AutoAttack[32]和CAA[33].相比于PGD,AutoAttack主要做了以下3点改进:1)从强化学习的角度引入攻击步长的探索-利用策略,代替原来的固定步长策略;2)引入新的替代损失(surrogate loss)代替原来的交叉熵损失(cross entropy loss);3)用4种特点各异的攻击形成并行集成攻击,取代原来单一的攻击模式.在AutoAttack基础上,CAA进一步引入串行集成,并用启发式智能搜索算法自动化搜寻攻击策略和超参数配置,进一步提高了集成白盒对抗攻击的攻击成功率.
2.4 黑盒迁移攻击
PGD等对抗攻击虽然实现了较高的白盒攻击成功率,但是由于需要获取目标模型的梯度信息,无法在黑盒场景下生成对抗样本.为了解决这一问题,一种简单直接的做法是在一个代理模型(surrogate model)上生成对抗样本,然后利用对抗样本的迁移性(transferability)攻击黑盒目标模型[34].因此,黑盒迁移攻击的关键在于如何提高生成的对抗样本的迁移性.MI-FGSM[35]是最早的提升对抗样本迁移性的攻击算法之一.它采用迭代方式生成对抗样本.与传统的白盒梯度迭代攻击不同的是,MI-FGSM在迭代式上加入动量项(momentum term),以稳定下降梯度,减轻过拟合,提升对抗样本的迁移性.在MI-FGSM的基础上,后续研究者又从多种角度提出了对抗样本迁移性的提升方法,比如基于改进梯度方向的攻击NI-FGSM[36],VMI-FGSM[37]等;基于输入变换的攻击如DIM[38],TIM[39],SIM[36]等;基于中间层特征的攻击如FDA[40],FIA[41]等.此外,也有一些研究者从模型结构的角度研究对抗样本的迁移性,比如Wu等人[42]发现DNN中的跳跃连接(skip connection)结构有利于迁移性更强的对抗样本的生成.在多个代理模型上以集成的方式生成对抗样本,也可以大幅度提升对抗样本的迁移性.
2.5 黑盒查询攻击
黑盒查询攻击通过反复查询目标模型的输出结果对样本梯度进行估计,从而实现对抗样本的生成.黑盒查询攻击不需要训练代理模型,但是往往需要大量查询目标模型.如何在生成攻击成功的对抗样本的前提下降低查询目标模型的次数,是黑盒查询攻击研究的主要问题.根据目标模型提供的输出结果的不同,黑盒查询攻击又可分为基于分数的攻击(score-based attack)和基于决策的攻击(decision-based attack).ZOO[43]是最早的黑盒查询攻击之一,是一种基于分数的攻击.ZOO用坐标梯度下降算法生成对抗样本,在优化过程中使用对称差分来估计梯度.基于决策的攻击的3种典型方法是基于边界的攻击(BA[44],QEBA[45]等),基于优化的攻击[46]和基于进化算法的攻击[47].类似于集成白盒攻击CAA,目前已有研究者利用程序生成(program synthesis)、静态分析(static analysis)、剪枝搜索等技术开发出自动化黑盒攻击AutoDA[48],能够大幅度降低黑盒查询攻击的查询复杂度.
3 针对轻量化网络的对抗攻击
轻量化网络同样面临着对抗样本的安全威胁.目前针对轻量化网络的对抗攻击还处于初级阶段.现有的研究主要基于传统对抗攻击方法对轻量化网络与大型网络的对抗样本鲁棒性进行了对比分析和实验验证.在量化网络的白盒鲁棒性方面,已有研究者设计出有效的迭代式攻击算法PGD++,能够克服量化网络中的梯度消失问题,从而实现更有效的攻击.
3.1 轻量化模型对抗攻击安全风险
模型轻量化是通过改变神经网络的参数表示、稀疏度、运算过程、网络结构,从而生成适应于终端设备部署的轻量化模型的过程.目前主流的模型轻量化技术包括模型量化(model quantization)、网络剪枝(network pruning)、低秩矩阵近似(low-rank approximation)、知识蒸馏(knowledge distillation)和紧凑网络结构设计(compact network arihitecture design)[49].以上各种方法从不同角度出发实现模型轻量化,不同轻量化方法也可同时使用,以达到更高的压缩率.
1)模型量化(model quantization).将用32位浮点数表示的DNN参数替换为低精度浮点数或定点数以实现模型的压缩和加速.常用的量化精度有16位、8位、乃至1~5位.目前,8位以上的模型量化技术已经非常成熟,能够实现在预测准确率几乎不变的情况下大幅缩小模型大小并提高推理速度,进入到了工业化部署阶段.两大深度学习框架PyTorch和TensorFlow都在新的发行版本中推出了对8位模型量化的支持.更低精度的量化仍然处在理论研究和算法创新阶段.模型量化有多种技术细节可供选择和考虑,包括量化值的均匀性、量化区间的对称性、激活值的校准方法、量化粒度、微调流程等.在实践中,往往需要根据应用需求和数据集规模来决定具体的量化方案.
2)网络剪枝(network pruning).其基本假设是脑损伤效应(brain damage effect)[50]:DNN的模型参数存在大量冗余,因此即使去掉大量模型参数,也依然能基本保持模型性能.依据这一假设,网络剪枝删除DNN中大量的冗余参数,从而实现DNN模型的稀疏化.按照剪枝粒度的不同,网络剪枝可分为过滤器级的剪枝(filter-level pruning)、组级剪枝(group-level pruning)、向量级别和2D卷积核级别的剪枝(vector-level pruning and 2D kernel-level pruning)和细粒度剪枝(fine-grained pruning).在算法实现上,一般对每个参数矩阵引入一个同型的掩码矩阵来表示该处参数的去留.参数矩阵与掩码矩阵相乘即可获得剪枝后的参数矩阵.在剪枝时,可使用反向传播算法对掩码矩阵进行优化.为了解决优化过程中剪枝操作不可导的问题,可使用STE算法.
3)低秩近似(low-rank approximation).通过将DNN参数矩阵进行低秩分解,从而实现参数的稀疏化存储和计算加速.DNN卷积核参数是一个4D张量W,4个维度分别是卷积核的宽、高、输入通道数和输出通道数.如果可以将4D张量中某几个维度合并,形成低维矩阵W′,但依然保持卷积运算结果不发生大的变化,就能实现模型的压缩和加速.这就是低秩近似的出发点.矩阵分解的常用方法是奇异值分解(singular value decomposition, SVD).低秩矩阵近似技术的2个关键点在于如何对4个维度进行重排,以及在哪些维度上引入稀疏化限制条件进行优化.根据将卷积核参数矩阵分解的部分个数,低秩矩阵分解可大致分为3类:两成分分解、三成分分解和四成分分解.
4)知识蒸馏(knowledge distillation).使用一个大模型(也称为教师模型,teacher model)对一个小模型(也称为学生模型,student model)进行训练,从而实现模型的轻量化.在训练过程中,大模型的预测结果(也称为软标签,soft label)取代普通标签的独热编码,作为小模型的训练标签.知识蒸馏能将教师模型所包含的信息传递到学生模型中,使学生模型达到和教师模型相近的预测准确率,而学生模型的规模和大小要远小于教师模型,因此可以实现模型压缩和加速.除了使用软标签对学生模型的训练进行指导之外,研究者也发展出了利用大模型的中间层特征指导学生模型的训练.
5)紧凑网络结构设计(compact network archi-tecture design).它从模型结构的角度实现模型的压缩和加速.NIN(Network-In-Network)是一种较早的紧凑网络结构,其中大量使用了1×1卷积,以在有限计算复杂度的情况下提升模型容量.NIN还放弃了全连接层的使用,转而使用全局平均值池化(global average pooling).分枝(branching)也是常用的紧凑网络结构设计方法之一,被紧凑模型SqueezeNet[51]大量使用.SqueezeNet能够以0.5MB的模型大小实现AlexNet级别的预测准确率,并实现了13倍加速.MobileNet[52]在ShuffleNet的基础上进一步使用了分枝策略,在VGG16模型的基础上实现了32倍压缩和27倍加速,但模型预测准确率却和VGG16相当.目前,MobileNet已经实现了移动端部署,在多种移动端深度学习应用中被使用.
与大型网络一样,轻量化网络也同样面临着对抗样本的安全风险.然而由于轻量化模型在模型参数、稀疏度、运算机理等方面与大型网络存在诸多不同,因此在对抗鲁棒性方面也具有不同的表现.已有很多研究者从实验角度进行对比分析,以研究轻量化网络的对抗鲁棒性.目前的研究主要集中于量化网络和剪枝网络方面.
在量化网络的对抗鲁棒性方面,Galloway等人[53]最早对BNN的白盒鲁棒性进行了实验探究,发现BNN存在梯度掩码(gradient masking),普通的迭代式对抗攻击对BNN的攻击成功率比较低.Bernhard等人[54]则关注于量化网络的黑盒鲁棒性.他们发现由于量化漂移(quantization shift)和梯度偏移(gradient misalignment)现象,对抗样本在不同精度的量化网络之间的迁移性比较差.
在剪枝网络的对抗鲁棒性方面,研究者普遍认为将大型网络进行剪枝能够提升剪枝后网络的白盒对抗鲁棒性.Matachana等人[55]则实验测评了剪枝网络和量化网络在UAP黑盒攻击上的鲁棒性.
以上工作均是基于传统的对抗攻击方法对轻量化网络的鲁棒性进行测评.然而,轻量化网络相比于大型网络具有自身的独特性,仅使用传统攻击方法有可能高估轻量化网络的鲁棒性.为此,已有少量研究尝试针对轻量化网络设计更为有效的对抗攻击.
3.2 针对量化网络的白盒对抗攻击
目前针对轻量级模型的对抗攻击研究还比较少,主要集中于针对量化模型和紧凑网络结构的对抗攻击方面.模型量化将用32位浮点数表示的DNN参数替换为低精度浮点数或定点数以实现模型的压缩和加速.常用的量化精度有16位、8位、乃至1~5位.模型量化有多种方案可供选择.按照模型训练流程来分,可分为量化感知训练(quantization aware training, QAT)和后训练量化(post training quantization, PTQ).QAT量化对模型准确率损失较小,但计算开销大;PTQ对模型准确率损失较大,但计算开销小.
早期的研究普遍发现相比于全精度模型,极低精度(1~4位)的量化模型更难被对抗攻击,尤其对于二值网络(binarized neural network, BNN)防御效果更为明显[56].2022年,Gupta等人[9]指出基于QAT得到的二值网络表现出更强的对抗鲁棒性是因为其存在着梯度掩码问题[57],而梯度掩码已被证明可被攻破,是一种不安全的防御.为了解决迭代式方法攻击二值网络时产生的梯度掩码问题,Gupta等人提出了基于温度缩放(temperature scaling)的迭代式对抗攻击PGD++,成功将量化模型在白盒场景下的鲁棒性降低到0.对于不存在梯度掩码问题的目标模型,PGD++仍可保持和传统的PGD方法相同的攻击成功率.
3.3 针对紧凑网络结构的白盒对抗攻击
Huang等人[58]指出,部署在手机等移动端设备上的深度学习模型可以被攻击者用软件逆向技术提取.他们发现,很多手机应用软件(application, APP)使用的深度学习模型为开源模型,或者是基于开源模型进行微调的模型.根据对这些APP中使用的模型进行对比分析,他们发现TensorFlow Lite的开源MobileNet预训练模型被广泛使用,这使攻击者可以对这些紧凑网络结构发动极具针对性的对抗攻击.Huang等人用FGSM,PGD等常见对抗攻击算法对10种不同的安卓(Android)手机APP进行了攻击测试,发现可达到平均23%的攻击成功率.Huang等人的工作通过实验揭露了移动端轻量化模型所面临的对抗攻击安全威胁,并指出大量使用的开源预训练模型和对深度学习模型知识产权保护的不重视是导致这一威胁如此严重的重要原因.
小结:目前研究者已经开发出了各种威胁模型下的大型网络对抗攻击算法,能够较为全面地暴露大型网络的对抗样本脆弱性,并为后续的对抗脆弱性修复提供铺垫.针对轻量化网络的对抗攻击研究工作只有白盒攻击和黑盒迁移攻击各一篇,相比之下研究仍显不足,需要后续的研究者进一步探索.对抗样本的威胁在各种深度学习模型上均普遍存在.在研究深度学习模型的对抗样本安全威胁和设计防御方法时,需要结合模型本身的特性和应用场景进行分析.本文将以上攻击方法总结如表1所示,表中部分数据来源于Dong等人的研究[59].需要注意的是,理论上所有的对抗攻击均可以任意模型为目标模型,根据攻击方法最初设计是否考虑目标模型为大型网络或者轻量化模型时对攻击效果造成的影响,本文对抗攻击方法进行了总结,如表1所示:
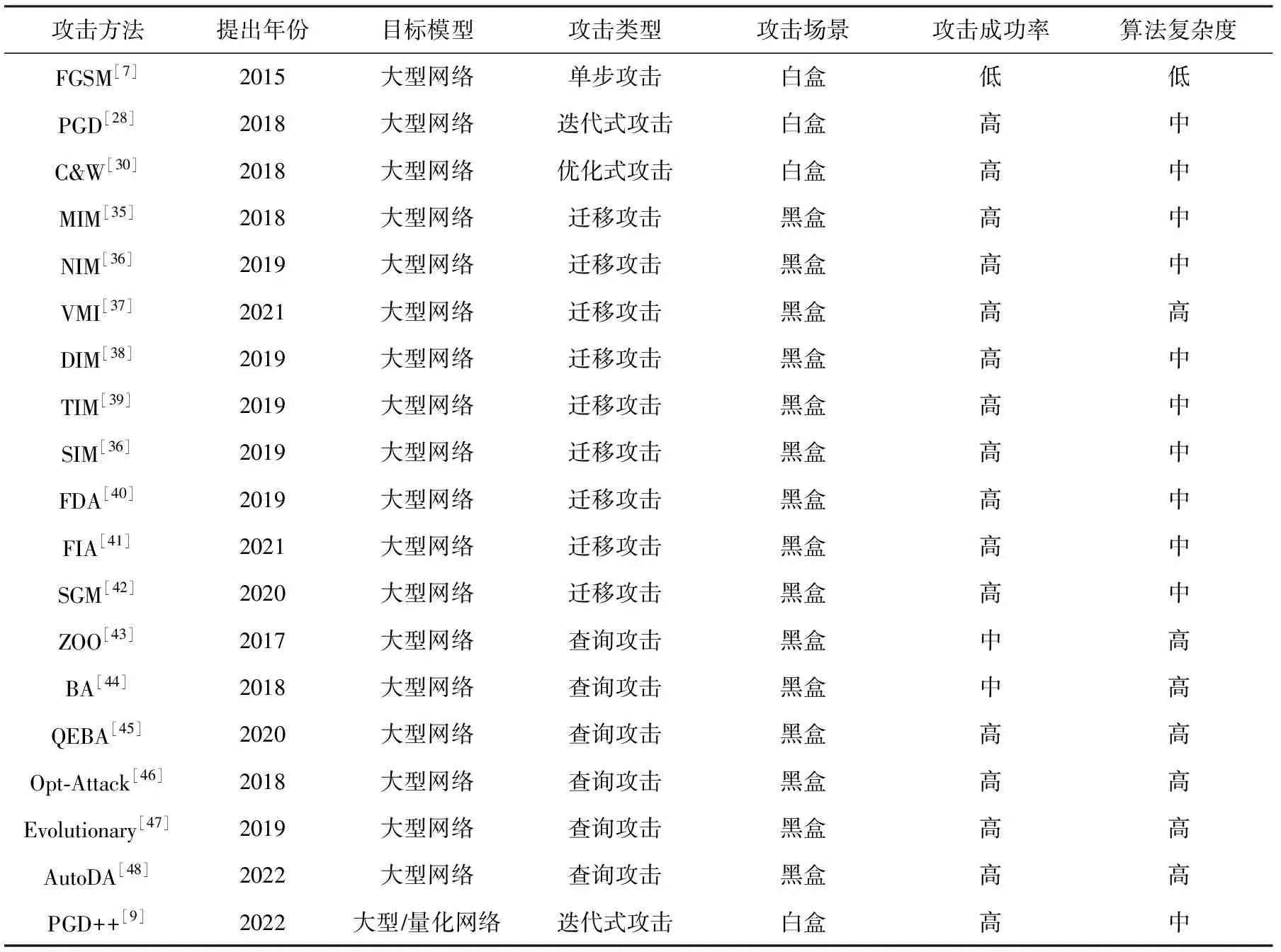
Table 1 Summary of Adversarial Attacks
4 针对大型网络的对抗防御
自从研究者发现DNN中存在对抗样本以来,许多研究者尝试设计对抗防御方法.本节总结了目前较为主流的3种对抗防御方法,分别是基于对抗训练、基于模型正则化和基于模型结构的对抗防御.这3种方法各有优劣,也面临不同的挑战和问题.
4.1 基于对抗训练的防御
对抗训练首次在2015年由Goodfellow等人提出[7],是目前防御对抗攻击最为有效的一类方法.对抗训练通过在训练集中加入对抗样本,从而提高模型在对抗样本上的鲁棒性.在对抗训练过程中可以使用任意一种攻击方法来生成对抗样本.如FGSM,PGD等.
1)FGSM对抗训练.FGSM对抗训练[7]是首个对抗训练方法,它在模型训练时使用的数据中注入FGSM对抗样本,将正常样本和对抗样本同时输入到模型中进行训练.FGSM对抗训练的目标函数对正常样本训练损失和对抗样本训练损失做加权和,从而使模型能够兼顾正常样本准确率和对抗样本准确率.FGSM对抗训练算法虽然简单且计算复杂度小,能够在一定程度上提升模型的对抗鲁棒性,但被后来的研究者Tramèr等人[60]证实,基于单步攻击的对抗训练存在梯度掩膜(gradient masking).这意味着FGSM对抗训练并非一种安全的防御方法,可以被更强的攻击如R+FGSM和SBA攻击攻破.另外,FGSM对抗训练只能保证针对FGSM之类的单步式对抗攻击的防御效果较好,而对迭代式攻击如BIM,PGD等攻击的防御效果较差.FGSM对抗训练的另一个缺陷是标签泄漏(label leakage)问题[29].即,FGSM对抗训练的模型在FGSM对抗样本上甚至获得了比正常样本更高的准确率.这是因为单步的FGSM攻击所生成的对抗扰动模式过于简单,以至于对抗扰动比正常样本的特征更容易被模型学习到.在这种情况下,模型实现对FGSM对抗样本的高准确率,并非是因为它正确提取了对抗样本中所包含的正常样本的正确特征信息,而是因为它学习到了对抗扰动和正确标签之间的相关关系.这样一来,标签泄露现象就会导致模型针对FGSM对抗样本过拟合,从而无法防御用其他攻击算法生成的对抗样本.
2)PGD对抗训练.PGD对抗训练[28]解决了FGSM对抗训练存在的种种问题,是一种较为有效的防御方法,成为了如今绝大多数新型对抗训练方法的基础.2018年,Madry等人[28]从鲁棒优化的角度出发来研究对抗鲁棒性,提出使用PGD攻击生成对抗样本进行对抗训练.如前所述,PGD是一种通用的一阶攻击,并且是理论上最优的一阶攻击.与FGSM对抗训练将正常样本和对抗样本混合在一起进行训练不同,PGD对抗训练只在对抗样本上训练模型.PGD对抗训练可视为在以p范数为距离度量的输入空间上的Min-Max的鞍点优化问题[61].通过在输入空间中每个样本邻域上最差情况(worst case)下的对抗样本上进行训练,PGD对抗训练可以维持模型在样本邻域上预测行为的稳定性,从而提高模型在局部区域的鲁棒性.无梯度攻击SPSA的实验表明,PGD对抗训练不存在梯度掩码,是一种有效的防御算法[62].PGD对抗训练的性能与模型容量密切相关.与小容量模型相比,大容量模型可从这种防御方法中获得更多鲁棒性增益.
虽然PGD对抗训练算法原理简单且防御效果好,但它只能保证模型在对抗训练时所使用的攻击类型上具有鲁棒性,而不能扩展到未知的攻击类型.另外,PGD对抗训练会损害模型在正常样本上的预测准确率.PGD对抗训练的另一个缺点是其高昂的计算开销.由于使用迭代式攻击PGD作为对抗样本生成的算法,PGD对抗训练的计算开销随着攻击迭代轮数的增加而增加.训练一个PGD对抗训练的鲁棒模型,其计算开销往往要比正常训练大一个数量级,这使得PGD对抗训练难以扩展到大模型和大规模数据集上.
3)集成对抗训练.集成对抗训练(ensemble adversarial training, EAT)[60]为了避免PGD对抗训练带来的计算开销问题,使用在其他预训练模型上迁移攻击生成的对抗样本进行防御模型的训练.EAT用FGSM攻击多个预训练模型生成具有迁移性的对抗样本,用这些样本来训练所需的防御模型.EAT的计算开销远远小于PGD对抗训练,可以扩展到大规模数据集如ImageNet,且对黑盒迁移攻击具有良好的防御性.
4)TRADES对抗训练.为了缓解PGD对抗训练损害模型在正常样本上的预测准确率问题,Zhang等人[63]将模型误差分解为正常预测误差和鲁棒性误差.通过对误差进行分解分析,TRADES对抗训练为训练过程引入鲁棒正则化项,使决策边界尽量远离训练样本点,从而更好地权衡模型正常预测准确率和模型鲁棒性之间的冲突.
5)MMA对抗训练.MMA对抗训练(max-margin adversarial training)[64]从模型决策边界优化的角度考虑对抗防御问题.在训练过程中,MMA对抗训练针对每个样本点设置大小不同的对抗扰动,最大化样本点与决策边界的距离,从而提高模型的鲁棒性.
6)快速对抗训练.2020年,Wong等人[65]提出快速对抗训练(fast adversarial training),将随机初始化的快速梯度符号法FGSM应用于对抗训练的过程.快速对抗训练算法的设计原理在于维持甚至提升对抗训练带来的模型性能的改进,大幅度降低对抗训练引入的高昂计算成本,使得对抗训练更有实际应用价值.
4.2 基于模型正则的对抗防御
基于正则化的对抗防御方法是从模型的预测分布、输入梯度的敏感性等角度出发,在模型训练的损失函数上引入正则化约束项,以抵御输入扰动对模型预测的干扰,改善模型防御性能的方法.基于正则化的对抗防御可以被视为一种将先验知识整合到模型中的方法.这种先验知识包括数据不变性,以及神经网络中权重和激活值相关的先验知识.正则化是机器学习中一个重要的研究领域.
1)Weight decay正则防御.Weight decay[66]是一种常见的正则化方法,它与随机梯度下降结合时等价于2正则化.Dropout[67]也是一种常见的正则化方法.Dropout也可以看作是在神经网络中间层的一种特征空间数据增强的形式.深度收缩网络(deep contractive network, DCN)早期利用一种正则化来提高深度神经网络的防御能力的方法,这种正则化来自于收缩式自动编码器(contractive autoencoders)[68].收缩约束鼓励模型对输入空间中无关方向上的小扰动保持不变.这种方法在分类损失,即要求网络捕捉输入中的有用信息和收缩损失,即鼓励丢弃冗余信息之间建立了一种约束.因此,该模型通常对对抗攻击引入的小扰动具有一定的防御能力.
2)Mixup正则防御.2018年提出的Mixup是一种简单有效的正则化技术[69].它将来自2个不同类的独立样本进行混合后输入网络,并使用相同数量的混合标签作为目标,对神经网络进行正则化,以便在训练样本之间实现简单的线性行为.
Manifold Mixup[70]是Mixup从输入空间到特征空间的推广.Mixup首先随机选择网络的某一层k,然后从输入层开始执行正向传播直到到达该k层,在该隐藏层进行Mixup操作继续正向传播,并根据Mixup改变目标标签向量.也就是说,Manifold Mixup是利用样本语义组合作为额外的训练信号,获得深层表征下具有平滑决策边界的神经网络.
3)鲁棒优化正则防御.另外,一些研究通过将模型鲁棒性优化目标与正则化方法融合来改进模型的鲁棒性,以防御对抗样本.比如,2018年Jakubovitz等人[71]将双反向传播(double backpropagation)方法[72]应用于对抗防御.该方法从理论分析角度出发,通过最小化模型雅可比矩阵的Frobeniu范数来达到防御目的.该方法被证明在保持网络测试精度的同时具有相对较强的鲁棒性.随后,Ross等人[73]证明了梯度正则化可以使模型更加鲁棒,并可作为模型预测的机理解释.Li等人[74]提出了类间样本引导的跨决策边界自适应对抗调优方法,通过优化模型次优的局部决策边界来提高模型的鲁棒性.
4)LLR正则防御.从对抗样本生成迭代过程的角度考虑,如果使用迭代轮数较低的攻击算法来生成对抗样本,就有可能降低对抗训练的计算开销.然而,这样的做法虽然可以产生对弱攻击具有鲁棒性的模型,但会产生梯度混淆问题,在强攻击下往往会失效.特别是,深度神经网络往往通过高度非线性化来学习基于梯度的攻击,这使其更加容易发生梯度混淆现象.深度神经网络的网络非线性降低了用少量迭代轮数快速生成对抗样本的可行性[62].相反,如果深度神经网络在训练样本的邻域内是线性的,那么就可以通过局部线性化近似计算梯度,从而避免梯度混淆问题.基于以上发现,Qin等人[75]引入了一种新的正则化器LLR(local linearity regularization),鼓励深度神经网络在训练数据点附近线性化,在提高鲁棒性的同时惩罚梯度混淆.
5)梯度正则防御.梯度正则防御由于其强的解释性和理论支撑引起了研究者们越来越多的关注.Hoffman等人[76]提出通过迫使输入类分布与分类器输出的雅可比矩阵的近似性,从而用更低的计算成本最小化雅可比矩阵的范数.Simon-Gabriel等人[77]证明了利用双反向传播方法训练的模型等价于采用2生成样本进行对抗训练的模型.Li等人[78]从高判别梯度映射形成机理出发,通过样本正确预测的概率分布先验行为约束模型的梯度信息,提出基于梯度显著性信息分布偏置的类雅可比防御方法.Etmann等人[79]使用双反向传播训练鲁棒模型,研究了非线性模型中的鲁棒性和特征对齐之间的联系.
4.3 基于模型结构的对抗防御
一些研究者尝试通过引入辅助检测器或去噪器来实现对抗防御.MagNet[80]是最早利用一对自动编码器即一个Detector和一个Reformer网络来防御对抗攻击的方法之一.具体而言,Detector网络用于检测输入样本是否具有对抗性,而Reformer网络用于从对抗输入中清除对抗干扰,然后将样本放入到干净数据的集合中.但是,整个MagNet是可微的,这使得它在白盒设置中很容易受到攻击.为了防御白盒攻击,在实践中可以采用多个Detector网络和Reformer网络的方式,在推断时随机选择2个候选的Detector网络和Reformer网络.实验表明MagNet可以防御多种对抗攻击包括FGSM,BIM,DeepFool和C&W攻击.然而,Carlini和Wagner的研究[81]发现MagNet针对SBA攻击仍然是脆弱的.
2018年,研究者提出了PixelDefend[82]和Defense-GAN[83]对抗样本去噪方法.这些方法仅使用在正常样本上训练过的生成模型来消除对抗干扰,其核心思想是将对抗样本映射到生成器的流形分布上,从而可以将对抗输入中的扰动剔除.尽管额外的梯度下降步骤增加了计算复杂度,但是Defense-GAN更难被基于梯度的攻击所欺骗,因为攻击者必须进行梯度下降迭代优化操作.
与在输入空间中操作的基于去噪的防御方法不同,FN网络(fortified networks)[84]是在神经网络的表征层中操作的一种基于去噪的防御方法.在隐藏层中而不是在输入空间中执行去噪操作的优点之一是隐藏层中允许使用简单的生成转换模型,如去噪的自动编码器DAE(denoising autoencoders)[85]等.但是前人的研究表明,在输入空间中使用生成转换模型的防御机制效果并不理想.此外,与输入空间的特征相比,神经网络的表征层特征具有更简单的统计特征(statistical properties)[86].
最近,相似于FN网络,Xie等人[87]提出了一种去噪特征映射方法,该方法利用经典的去噪算法Non-local Means构建去噪模块,并接入Skip connection将去噪前后的特征映射相连接,避免去噪过程中带来的信息损失.Yang等人[88]提出了一种基于预处理的防御方法,称为ME-Net.该方法对模型输入进行预处理,即先按照一定的概率p在输入图像中随机丢弃像素值,希望破坏对抗性噪声的结构.然后利用矩阵估计(matrix estimation, ME)算法重构输入图像.
不同于基于去噪的防御方法,2020年研究者还提出了一种利用附加BN(batch normalization)层来进行对抗防御的方法[89],该方法用一个的BN模块去估计对抗样本的分布,而用另一个BN估计干净样本的分布.此外,2021年Bai等人[90]提出通道感知激活(channel-wise activation)模块,在不同的通道之间学习一个不同的权重,使与类别无关的通道做一些压缩.
4.4 梯度掩码
梯度掩码(gradient masking)是一种不可靠的防御方式,可以被攻击者采用相应的方法攻破.在对抗防御的研究史上,人们一开始并没有意识到梯度掩码的不安全性,直到后来带有梯度掩码的防御方法被一一攻破.如今,研究者在设计新的对抗防御方法时都会确保防御效果不是由梯度掩码效应导致的.
1)温度编码.温度编码(thermometer encoding)[91]是一种基于假设的防御方法,即神经网络的线性特性使其容易受到攻击[7].温度编码将输入数据量化和离散化,有效地忽略了对抗攻击所带来的微小扰动的影响.具体地,输入信号首先根据所需的离散化水平l进行量化.给定输入信号xi的第i个元素,量化函数q(xi)返回最大的索引k∈{1,2,…,l}.可以看出,小于最小离散阈值的微小扰动不会对温度编码的信号产生影响.此外,温度编码可以作为一种防御方式,因为其是非线性和不可微的,这使得攻击者更难计算梯度.Buckman等人[91]研究表明温度编码与对抗训练的结合具有较强的对抗鲁棒性,性能甚至超过PGD对抗训练.然而,温度编码被认为依赖于梯度掩模[57],即该方法为了增加模型的攻击难度和攻击求解预算,对模型的梯度信息进行隐藏.攻击者可采用近似模型梯度的方式,并且对BPDA攻击失效.
2)防御蒸馏(defensive distillation)[31].防御蒸馏是一种通过训练2个网络来工作的防御方法.其中一个Student模型被训练去逼近另一个Teacher模型.具体而言,它首先在输出层使用温度(temperature)常数T修改Softmax函数训练Teacher模型,而更高的温度导致Softmax更平坦,从而可在决策过程中引入更多的噪音.训练完第1个模型(Teacher模型)后,使用第1个网络的预测作为训练数据的标签来训练第2个模型(Student模型).而在模型推断过程中,蒸馏模型的温度常数设置T=1.Papernot等人[31]展示了如何增加Softmax函数的T导致概率向量随着T→∞ 收敛到1/C.换句话说,Teacher模型和Student模型的预测都被训练得很平稳.模型关于输入特征的雅可比矩阵与T成反比,即,T值越高,对输入特征的依赖性越低.因此,当在模型推断期间将T恢复到1时,只会使概率向量更加离散,而不会改变模型的雅可比矩阵,从而得到一个对输入的微小扰动敏感度比较低的模型.尽管防御蒸馏对JSMA-F攻击展示出了较强的鲁棒性,但是对后续提出的更强的攻击算法如JSMA-Z攻击[92]、SBA攻击[92]以及C&W攻击[30]无法实现有效的防御.Carlini和Wagner对这种防御进行了评估,并指出防御蒸馏模型如何产生比标准模型更高的Logit值.
小结:到目前为止,对抗训练仍然是最为有效的提升模型鲁棒性的方法.但是对抗训练通常会降低模型在正常样本上的预测准确率,并且无法保证能够对未知的新攻击具有鲁棒性.对抗训练在训练时需要生成对抗样本,生成对抗样本的过程大大提高了模型训练的计算开销.一方面,对抗样本的分布不同于正常训练数据分布,这使得对抗训练需要更多的训练轮数才能收敛;另一方面,生成对抗样本的过程需要进行额外的迭代攻击计算.这些都极大地增加了对抗训练的计算开销.因此对抗训练虽然有效,但却并非高效的防御方式.如何在模型正常预测性能、模型鲁棒性和计算开销之间进行很好地权衡,是未来对抗训练领域的重要研究问题.
总体而言,上述基于模型结构的对抗防御方法大多仍然是基于经验的启发式算法,无法提供理论上的鲁棒性保证.且存在训练周期漫长、适用范围有限等问题.很多防御方法在很短的时间就会被后来的对抗攻击算法攻破.由此可见,研究和发展与模型参数结构直接相关的具有理论支撑和保证的鲁棒对抗防御方法,以及对现有实验防御(empirical defense)的有效性机制进行可信程度解释是未来的重要发展方向.目前,已经有研究证明梯度掩码(gradient masking),是一种不可靠的防御方法.梯度掩码可分为粉碎梯度(shattered gradients)、随机梯度(stochastic gradients)和梯度爆炸/消失(exploding/vanishing gradients).攻击者可以分别利用无梯度攻击或迁移攻击、EOT(expectation over transformation)攻击和温度放缩(temperature scaling)方法来破解3种梯度掩码,实现成功的对抗攻击.因此,在评估新的防御方法时,应该确保这种防御方法所带来的模型鲁棒性不是由梯度掩码导致的.针对大型网络的对抗防御总结如表2所示:
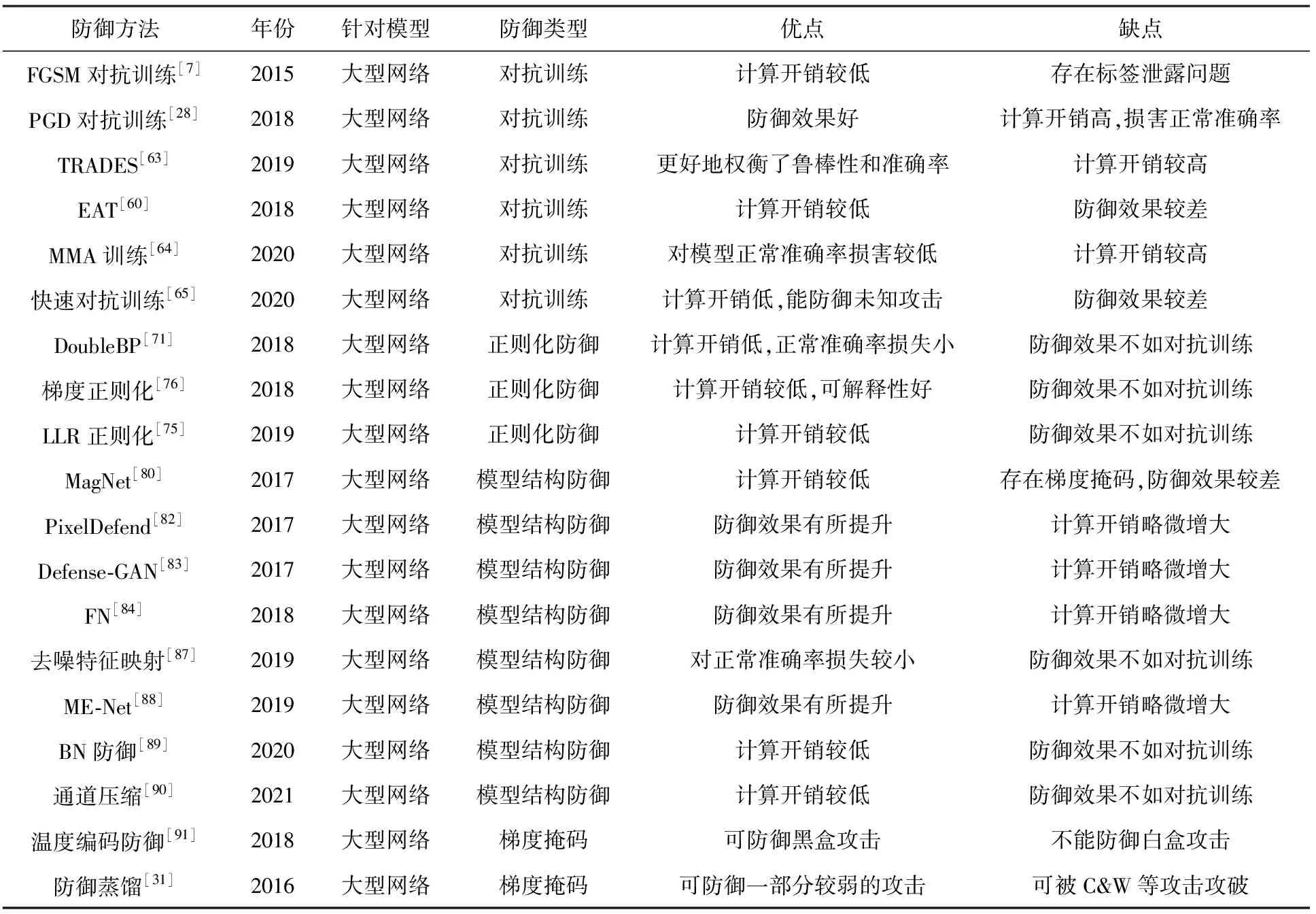
Table 2 Summary of Adversarial Defenses for Large DNNs
5 针对轻量化网络的对抗防御
针对轻量化网络的对抗防御常常需要考虑如何在模型正常准确率、模型鲁棒性和模型轻量化三者之间进行权衡.为轻量化网络设计对抗防御往往考虑如何将针对大型网络的对抗防御方法迁移到轻量化网络上,并结合轻量化网络自身特点进行改进.本节总结了目前最新的轻量化网络对抗防御技术,包括对抗训练、模型正则化和多精度模型集成.
5.1 基于对抗训练的对抗防御
如何将原本针对大型网络设计的对抗训练迁移到轻量化网络,达到模型正常准确率、模型鲁棒性和模型轻量化三者的兼容和权衡,是针对轻量化网络的对抗训练技术的关键难题.目前的研究已经针对模型量化和网络剪枝分别提出了相应的对抗训练方法,包括随机精度对抗训练、基于ADMM的稀疏化对抗训练以及对抗预训练模型的轻量化.
1)随机精度对抗训练.随机精度对抗训练是一种基于模型参数量化的轻量化模型防御技术,以2021年提出的Double-Win-Quant方法为代表[93].Double-Win-Quant利用了前人发现的对抗攻击在不同量化精度的模型之间迁移性较差的特点[54],提出运行时随机改变网络的量化精度来提升模型的鲁棒性.Double-Win-Quant以可切换量化(switchable quantization)技术作为基础,将对抗训练与可切换量化的训练框架相结合,从而达到运行时可随机切换量化精度的目的.Double-Win-Quant在鲁棒性方面相比PGD对抗训练有较大幅度的提升,但所能达到的压缩率比较有限,且要求硬件对多种不同精度的运算具有一定的支持.
2)基于ADMM的稀疏化对抗训练.研究者发现对抗训练往往需要较大的模型容量,这使得模型的鲁棒性和模型的轻量化要求互相矛盾.为了能够更好地权衡模型鲁棒性和轻量化目标,研究者提出在对抗训练目标函数的基础上,引入模型轻量化的限制条件,构成一个带有不等式约束的限制性优化问题,并用交替方向乘子法(alternating direction method of multipliers, ADMM)进行求解[93-94].
Ye等人[94]从网络剪枝的角度实现了基于ADMM的稀疏化对抗训练.他们发现,直接从剪枝后的轻量化模型开始进行对抗训练无法获得较好的鲁棒性,因此提出基于ADMM算法在训练的过程中同时进行对抗训练和剪枝.Gui等人[95]则进一步基于ADMM算法提出了对抗训练、网络剪枝、低秩矩阵分解和模型参数量化的统一框架,在保持正常预测准确率和对抗鲁棒性的前提下最大化提高了压缩率.
以上2种方法虽然能够比较好地权衡模型正常准确率、模型鲁棒性和模型轻量化目标,但是也存在着两大缺点:其一,ADMM框架需要人为预先指定每一层的稀疏比,因此依赖于领域知识且常常需要多次训练以找出最好的稀疏比配置;其二,对抗训练是非凸优化问题,ADMM算法对该问题没有收敛性保证.为了能够达到模型收敛,往往需要延长模型训练时间.为了解决上述问题,动态网络重装配(dynamic network rewiring, DNR)方法[96]提出使用一个包含模型正常准确率、对抗鲁棒性、模型稀疏度3方面目标的混合损失函数进行模型训练,并结合稀疏学习(sparse learning)方法的优点,极大地减小了ADMM稀疏化对抗训练的计算开销.DNR方法只需定义一个整体的稀疏率,且可以与结构化剪枝方法相结合.
3)对抗预训练模型的轻量化.基于ADMM的稀疏化对抗训练是一种从零开始训练模型的方法.与之不同,一些其他的研究者致力于在对抗预训练模型的基础上进行网络剪枝和模型量化等以实现模型鲁棒性和轻量化的双重目标.这种方法能够直接利用已经过对抗训练过的防御模型,从而能够减少一部分重复的计算开销.
2019年,Sehwag等人[97]尝试了各种从对抗预训练模型出发得到经过网络剪枝后的轻量化模型的方法,发现“对抗预训练→启发式剪枝→对抗训练微调”这一套流程的效果较好.然而,这套方法仍然比较原始,启发式剪枝不能很地在剪枝过程中反应模型鲁棒性的优化目标,导致只能取得次优结果.因此,2020年,Sehwag团队进一步提出了对抗预训练模型的剪枝方法HYDRA[98].HYDRA将对抗训练的目标函数加入网络剪枝的目标函数中进行求解,从而实现对抗训练和剪枝之间的良好配合.在剪枝后的对抗预训练模型的基础上,还可以进一步做8位网络参数量化,进一步提高模型的压缩率.
Guo等人[99]从神经网络结构搜索(network architecture search, NAS)的角度探究了深度神经网络结构对模型鲁棒性的影响.他们首先用对抗训练得到一个较大的鲁棒模型Supernet,然后使用one-shot NAS进行剪枝,微调之后获得轻量化的鲁棒模型RobNet.在大量的实验数据的基础上,他们发现稠密链接的网络结构与模型鲁棒性成正相关,并且发现FSP(flow of solution procedure matrix)指标能够很好地度量网络的鲁棒性.相比于传统的深度学习模型,RobNet能够成倍缩小模型大小,为将来轻量化鲁棒模型的设计提供了一种思考方向.
5.2 基于模型正则的对抗防御
对轻量化模型的正则化对抗防御常常以模型参数量化技术为基础,从量化模型的对抗扰动传播机理分析入手,在相应的理论和实验假设下提出正则项以压制对抗扰动的传播,提升模型的鲁棒性.目前这方面的研究常常以Lipschitz正则为基础来提升模型的鲁棒性.
1)防御性量化.防御性量化(defensive quanti-zation, DQ)[100]假设普通量化技术无法实现对抗防御的原因在于错误放大效应(error amplification effect),也就是量化操作会进一步放大对抗扰动对模型正常预测过程带来的损害.因此,DQ提出使用Lipschitz正则化来压制量化模型中的错误放大效应,不仅能够提升深度神经网络的鲁棒性,也对正常预测准确率有一定的提升效果.然而,DQ仅仅针对激活值量化进行了防御,而激活值量化不能实现模型压缩.其次,DQ的防御过程也并未将量化和防御2方面进行机理上的深度融合,仍然保留很大的改进空间.
2)基于反馈学习的正则.Song等人[101]同样使用Lipschitz常数和错误放大效应为理论分析工具,并结合实验发现了对抗训练和模型量化之间的冲突:对抗训练会导致极低精度(3位)量化损失的成倍增加,使得模型鲁棒性和轻量化的目标相互冲突.为了缓解这一冲突,Song等人提出使用反馈学习(feed back learning)对防御模型进行微调,并引入非线性映射作为一种防御白盒攻击的梯度掩码.然而,以上方法只针对3位量化进行防御.为了进一步减小量化误差和对抗误差之间的冲突,Song等人后续又提出以Lipschitz常数为指导,为每一层设置不同的量化精度[102].该方法的缺点是混合精度模型的设计对硬件配置要求较高.
5.3 多精度模型集成
Sen等人[103]提出了多精度模型的继承防御EMPIR.该方法基于对抗攻击在不同精度模型之间迁移性较差的假设,使用全精度模型和低精度模型做集成以防御对抗攻击.该方法的原始设定场景虽然是针对全精度模型做防御,但该方法表明云边端协同场景下,构建分级多层次防御体系是大有裨益的.EMPIR的集成策略比较简单,未来如何深度结合全精度网络和轻量化网络各自的特点,在云边端协同场景下实现各部分在防御上的更好配合,将会是重要的研究方向.
5.4 梯度掩码
Dhillon等人提出了一种基于随机策略的防御机制,称为SAP(stochastic activation pruning)[104],它在模型推断过程中随机修剪或丢弃一些激活元.每一层的神经元被剪枝的概率与其激活值成正比,这意味着SAP倾向于保留激活值较小的神经元.重新调整激活的目标是使剪枝模型在处理非对抗性输入时的行为类似于原始模型.由于SAP中的随机性导致攻击者很难计算梯度,因此使模型对对抗样本更加鲁棒.这种方法类似于在测试期间执行Dropout[105].不同的是,Dropout剪枝的节点概率是均匀分配的,而SAP是根据激活的大小分配,并重新调整幸存节点的大小.然而,这些差异允许SAP添加到任何预先训练的模型中,而不需要进行微调,同时可保持干净数据的准确性.但是,SAP已经被证明依赖于梯度掩模,并且容易受到基于随机期望计算梯度的迭代攻击所攻破[57].
小结:首先,目前的轻量化模型防御研究常常基于强大的对抗训练方法来对相应的模型轻量化技术做有机结合,基本能够实现模型正常准确率、模型鲁棒性和模型轻量化目标之间的有效权衡.然而,目前的方法很少从软硬协同设计的角度考虑算法实际部署于终端硬件时的计算开销.其次,现有的研究还尚未将一些模型训练加速技术比如梯度量化应用于对抗训练中,未来的轻量化模型在正常准确率、模型鲁棒性、模型轻量化3方面目标上仍有提升的潜力.
针对轻量级模型的正则化对抗防御的研究仍然处于初级阶段,在理论框架和算法上均有一定的提升空间.未来的研究一方面需要考虑如何基于理论分析将量化和对抗误差进行联合优化,另一方面需要考虑如何将正则化对抗防御与更多的防御以及量化技术相结合,以达到在实际场景中的更优效果.针对轻量化模型的对抗防御总结如表3所示:
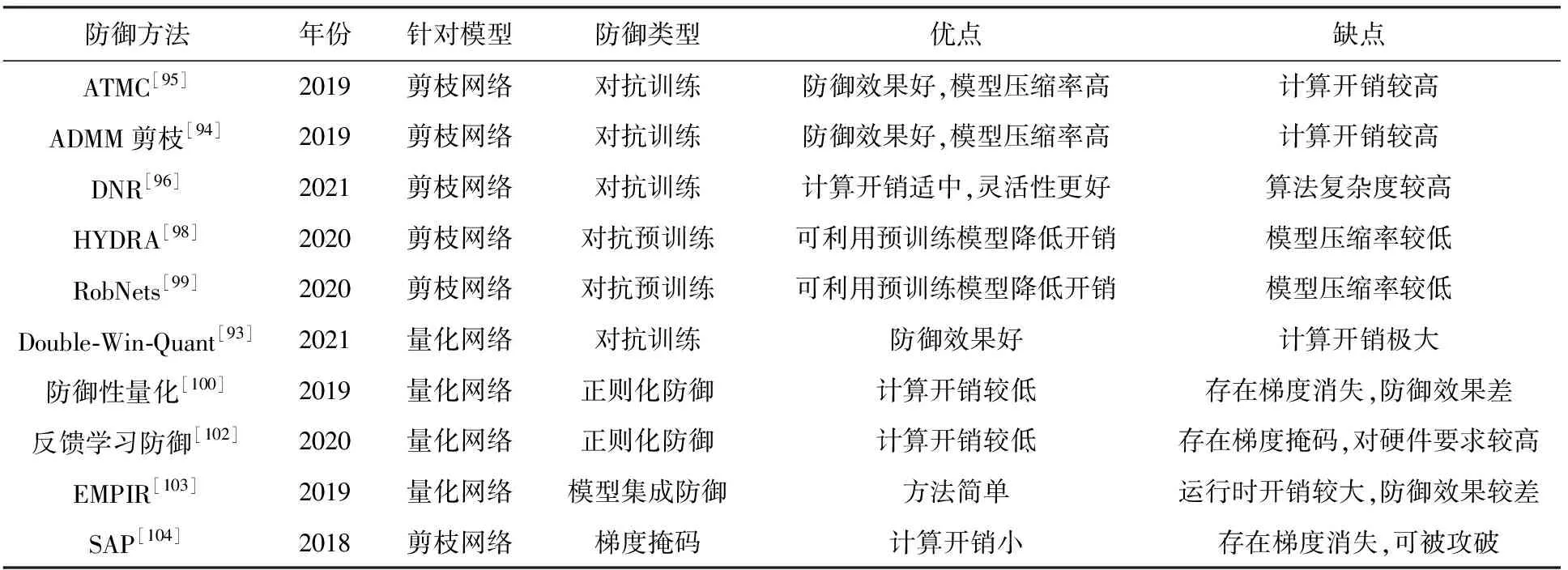
Table 3 Summary of Adversarial Defenses for Lightweight DNNs
6 现存挑战与未来趋势
近年来,针对大型网络和轻量化网络的对抗攻击和防御方法都取得了一定的成果,然而该研究整体上仍处于较为初级的阶段,相关的攻击与防御方法在真实复杂环境中的性能、通用性等方面有许多关键问题尚待解决,且尚未形成完整的技术理论体系,并且难以在实际应用场景中实现规模化部署.总之,在理论和应用2方面,现有研究仍然存在着许多亟待解决的关键问题与挑战,需要未来的研究加以解决.本节从大型网络和轻量化网络2方面入手,分别总结了针对每种DNN的对抗攻击和防御研究中亟待解决的问题与挑战,并探讨了未来的研究趋势.
6.1 大型网络对抗攻防发展趋势
1)在基础理论方面.虽然现有研究已经探索出了对抗防御等一系列可靠防御技术,但是难以提供理论层面的对抗鲁棒性保证.为此,需要发展有理论保证的对抗防御方法.一般来说,对抗训练等方法能够取得较好的防御效果,但是对模型鲁棒性无法给出理论保证,防御方无法得知是否将来会有更强的攻击算法将现有防御攻破.事实上,在对抗防御的研究历史上,很多在当时被认为是非常成功的防御方法,在几年后又会被新的对抗攻击算法攻破.因此,发展具有理论保证的可证明的对抗防御算法,为对抗攻击下的模型鲁棒性提供理论保证,是当前重要的研究方向之一.一方面,研究者须解决可证明防御方法设计过程中所面临的种种挑战,包括保证DNN在邻域内预测的一致性、将防御性能与模型决策边界相关联、解决对抗学习中的梯度结构优化问题等;另一方面,还需发展对抗学习理论框架,以支持可证明防御以及其他防御方法的发展.
其一,如何真正保障深度模型在邻域预测的一致性,是保证防御方法可靠和可解释的重要途经.对抗样本在语义上位于原始样本的邻域,因此模型在该邻域上的预测行为应表现出一致性.然而,现有研究提出的对抗训练则关注于估计最优扰动以确保模型在此扰动下的识别正确性,没有对邻域预测分布的相似性进行直接约束[106-107].因此,现有的防御方法对训练集中对抗样本所用攻击算法具有依赖性.虽然新的对抗防御在不断提出,但如果新的防御方法不能保证DNN在局部邻域内的预测一致性,就难以保证其不被更新的攻击算法攻破.因此,未来研究应着眼于经人工合成的虚拟样本(包括对抗样本等)和原始数据在邻域分布的相似性,基于虚拟样本围绕原始样本的先验分布行为,研究多特征层级的邻域分布探索机制.可以利用虚拟样本与原始样本模型预测分布差异作为监督学习信号,建立样本邻域预测分布的一致性保守约束.这样一来就可以在恶意对抗干扰下显式地加强模型预测的稳定性,为鲁棒对抗防御奠定理论基础.
其二,如何将防御机制的有效性与决策边界进行显式联系,是发展有理论保证的防御方法的又一挑战.借助模型的推断盲点进行漏洞修复,能充分发挥对抗样本所代表的歧义区域信息的重要作用.然而,现有研究更多关注于对抗样本作为训练阶段的数据增强策略,并未对其与估计决策边界关联程度进行判定、检测,导致对抗样本用于防御过程中的有效行为缺乏可解释性,甚至引入增强数据的冗余计算.因此,即使生成的样本具备更强的攻击性,但是该样本否可用于模型局部次优决策边界的调优仍然未知.总之,探测模型决策边界的预测歧义区域而不是局限在范数约束下的保守邻域,优化模型次优的局部决策边界来提高模型的鲁棒性是未来对抗防御研究发展的一个必然趋势.
其三,未来研究还需解决对抗学习中的梯度结构优化问题.在理想条件下,鲁棒的模型应能够突出输入中的显著性区域.然而,现有的标准梯度正则化防御方法以无差别的方式对各预测类别梯度进行范数最小化,将任务相关和无关特征的重要性视为相同,这导致最终训练模型的特征显著性映射和鲁棒性提升预期之间产生冲突.因此,未来对抗防御研究应从高判别梯度映射形成机理出发,结合最优扰动生成与线性化假设关系,研究梯度分布权重偏置策略.未来研究可以着重思考如何将模型雅可比矩阵值的结构化分布特征融入到训练过程中,以确保模型在样本局部线性区域上的预测稳定性,为复杂对抗场景下深度学习的鲁棒决策提供重要的理论依据.
其四,如何判断在对抗环境下模型的可学习性仍然是对抗学习理论框架尚未解决的重要问题之一.现有研究一方面扩展了PAC学习框架,定义了在对抗条件下的二元假设类,并证明了统计学基本原理中样本复杂度上界可以扩展到规避对抗攻击的情况;另一方面对线性模型的对抗拉德马赫复杂度(adversarial rademacher complexity)进行了泛化分析,并给出了单隐层神经网络的对抗Rademacher复杂度上界.此外,还有一些研究者在对抗环境下采用最优传输理论寻找分类错误的一般下界,并得到了对抗鲁棒性的匹配上界与下界.虽然对抗性与非对抗性Rademacher复杂度的区分有助于线性模型对抗学习的正则化器设计,但是现有关于对抗性机器学习的理论框架的研究普遍存在较强的假设,并且仅局限于特定的任务和模型结构.因此,未来研究可以针对对抗学习的特点,研究其在更一般的条件下的可学习性和复杂度并发展新的学习理论框架.
2)在对抗攻击实现方面.现有研究虽然已在各种威胁模型下开发出了大量针对图像任务的对抗攻击算法,但是针对其他任务的对抗攻击研究仍然不足.以语音识别任务为例,目前针对语音识别任务的对抗攻击算法的攻击成功率仍然不高,且有着苛刻的发动条件,比如须距离麦克风特别近、无环境噪声干扰等等.未来研究仍需在此类任务上深入研究,实现具备现实威胁的对抗攻击,更加全面地揭示各种深度学习任务的对抗鲁棒性缺陷,为更加鲁棒的深度学习模型设计提供铺垫.
3)在对抗鲁棒性测试方面.虽然研究者已经开发出了一些图像识别任务上的对抗攻击工具包和对抗鲁棒性测评框架,但是缺乏面向多任务和实际应用场景的对抗鲁棒性测试框架.
目前,学术界已经发展出了针对各种任务和应用场景的对抗攻击算法,揭露了DNN在各种应用场景下的对抗样本脆弱性.然而,由于各种任务和场景各具特点,难以构建统一的模型对抗鲁棒性测试框架,以供使用者全面了解所测试模型在实际部署环境下潜在的对抗样本威胁.现有的对抗鲁棒性测试基准系统主要集中于图像识别任务,并依赖于CIFAR-10,ImageNet等基准图像数据集,缺乏针对其他任务诸如语音识别、强化学习等的测评算法和框架,且与实际的应用环境仍然相去甚远.
以自动驾驶系统为例,目前学术界已经研究出了各种各样的物理域攻击方法,能暴露自动驾驶系统的对抗脆弱性.然而,构建统一的自动驾驶系统鲁棒性测试框架面临着以下挑战:其一,各种对抗攻击的评价标准不一致;其二,威胁模型(threat model)各异;其三,自动驾驶系统中各种子任务各具特点,导致对抗攻击算法也各不相同,难以统一整合;其四,需要采用合适的虚拟化技术模拟真实的驾驶环境;其五,需要对系统脆弱性精准定位和分析;其六,系统应该具备一定的可扩展性,以适应于未来新型攻防算法的测评.
另外,面向实际应用场景的对抗鲁棒性测试框架也需要考虑边缘计算场景,综合考虑大型网络和轻量化网络在真实环境中部署时所面临的安全风险.为此,需要集成各种针对大型网络和轻量化网络的对抗攻击和防御方法.
4)在对抗防御实现方面.虽然以对抗训练为代表的对抗防御已经取得了较好的防御效果,但是其存在着诸多缺点,使其难以在实际应用场景中实现规模化部署.
正如前文所述,目前主流的对抗防御方法是对抗训练.对抗训练虽然能够提供较高的模型鲁棒性,并且对不同的攻击算法都有防御效果,但其存在以下缺点,阻碍其在实际场景中大规模应用部署:
其一,对抗训练会损害模型在正常样本上的准确率,降低模型的可用性;
其二,对抗训练的计算代价极高.Vaishnavi等人的研究表明[108],对抗训练的收敛速度比正常训练平均慢7倍左右.对抗训练极高的计算代价不但大幅度增加DNN模型的训练成本,而且阻碍其应用于大规模任务和数据集;虽然已经有一部分工作已经降低了对抗训练的计算开销,如前文介绍过的快速对抗训练,但是这些方法仍然存在着正常准确率损失过高、模型鲁棒性提升较小等缺陷.未来的对抗防御算法应着重于解决以上2方面的问题.在保证模型鲁棒性和可用性的同时尽可能降低模型训练成本,开发可规模化应用的对抗防御技术.
6.2 轻量化网络对抗攻防发展趋势
1)在基础理论方面.虽然现有研究已经探索出了一些针对轻量化网络的对抗防御理论和方法,但是缺乏综合考虑模型轻量化、模型鲁棒性和模型准确率3方面指标的统一分析框架.
未来研究可以从理论层面深入分析各种模型轻量化技术与模型鲁棒性、准确率之间的相互作用关系,指导针对轻量化模型的对抗攻击和防御算法的设计.在此基础上,可以将可证明的对抗鲁棒性测试和对抗防御技术扩展到轻量化模型上,为轻量化模型的安全部署提供充足的理论支撑.可证明的鲁棒测评框架以及相应的可证明防御方法同样需要对轻量化模型做适应性改进.比如,很多常见的可证明防御技术,如随机平滑(random smoothing, RS)依赖于大量浮点运算,不适用于搭载CPU的终端设备.为了能在运行于终端设备上的量化模型上应用RS技术,需要对算法的理论框架、算法流程等方面进行重新思考,设计出基于定点数运算的IntRS可证明防御技术[109],以配合终端设备的部署要求.
2)在对抗攻击和鲁棒性测试实现方面.虽然目前对抗攻击研究已经趋于成熟,但是轻量化模型的对抗脆弱性仍有待进一步挖掘.目前针对轻量化模型的对抗攻击算法仅局限于白盒攻击,且集中于模型量化,研究仍显不足.未来的研究应深入考虑当目标模型为各种轻量化模型时的攻击算法设计,以期充分暴露各种轻量化模型的对抗样本脆弱性,为更加安全可靠的轻量化模型设计提供前提.
3)在对抗防御实现方面.现有防御方法已经在模型轻量化、模型鲁棒性、模型准确率三者的权衡上取得了一定的进展,但是距离实际部署仍然存在距离.一方面,由于附加了模型轻量化的过程,基于对抗训练的轻量化模型防御方法在模型收敛速度上比普通的对抗训练更慢,更加难以实现规模化部署;另一方面,其他防御方法如基于正则化的对抗防御、梯度掩码防御、可证明的防御等在轻量化模型上的防御性能往往表现不佳,抑或是存在被后续更强的攻击算法攻破的风险.最后,针对轻量化模型的对抗防御还需考虑实际部署平台的特性,实现软硬协同设计以最优化系统性能.
7 结 论
本文以云边端全场景为视角,全面分析了边缘计算场景下的深度神经网络对抗安全风险,并分别总结了目前针对大型网络和轻量化网络的防御方法.在总结和整理的基础上,本文阐述了该领域目前的发展现状,并分析了未来研究所面临的挑战.在针对大型网络的对抗攻防方面,已经有了大量的研究工作.本文介绍了几种典型的攻击算法,并以对抗训练和正则化对抗防御为例介绍了目前具有代表性的对抗防御方法.在针对轻量化网络的对抗攻防方面,目前对抗攻击研究较少,仍需进一步探索.本文着重总结了对抗训练和正则化对抗防御等主流防御方法如何与模型轻量化技术较好结合,实现模型鲁棒性、模型轻量化和模型正常准确率三者的权衡.最后,本文分析了大型网络对抗攻防和轻量化网络对抗攻防相关研究领域中存在的挑战,并总结出了可证明的对抗攻防、面向实际应用场景的对抗测评框架、可规模化部署的对抗防御技术等未来研究趋势.本文旨在帮助研究者对该领域的研究现状形成全面认识,以推动云边端全场景下对抗攻击和防御技术的发展.
作者贡献声明:李前和蔺琛皓为共同第一作者,负责相关文献资料的收集、分析,并提出写作思路,完成论文撰写;杨雨龙负责文献调研、内容设计和全文修订;沈超和方黎明为共同通信作者,负责指导论文撰写与修改、提出论文格式排版建议、校对全文并最终审核.
