基于多维识别体系的民族地区贫困测度
2022-10-12毕晶晶
毕晶晶
(华东政法大学 政管学院, 上海 松江 201600)
一、引言
一直以来,贫困问题都是影响人类发展的重大议题之一,对拥有14 亿人口的中国来说更是如此。 消除贫困、改善民生、逐步实现共同富裕,是社会主义的本质要求,是中国共产党的重要使命[1]。随着2020 年小康社会的全面建成, 我国贫困人口从2015 年底的5 575 万人减少到2019 年底的551 万人[2],提前十年完成《联合国2030 年可持续发展议程》减贫目标,我国正式进入“后减贫时代”。 在这一时期,学界对贫困的研究从绝对贫困转向相对贫困,从单一维度转向多个维度,多维贫困成为研究的重点。 但在研究方法上,现有多维贫困的研究在指标体系的建构上多采用等权重法,具有较强的主观随意性。 而对于广西、云南、宁夏、西藏等少数民族聚居地区来说,经济要素水平、资源条件、基础设施等显性约束和语言、民族文化差异等隐性约束[3]更使其难以脱离贫困陷阱。因此,基于少数民族地区的实际情况构建多维贫困指标体系对监测民族地区贫困程度及扶贫工作具有重要意义。
多维贫困最早是基于阿马蒂亚·森的可行能力理论提出的,森认为可行能力指“人们能够做自己想做的事情、过上自己想过的生活的能力”,具体包括健康、教育、体面的工作、安全等多个维度。那么如何判断个人或群体的贫困程度?以及个人或群体是否发生了多维度的贫困?这就需要建立相应的指标体系来测度个人或群体的贫困程度。 因此在已有的研究中倾向于注重多维贫困的识别与测度。 当前学术界应用最广泛的测度方法是Alkire 与Foster[4]提出的AF方法,又称“双临界值法”,即先通过一个指标的临界值判断个人或群体是否在该维度上被剥夺,然后再通过维度临界值判断个人或群体在几个维度上发生了贫困。 但这一方法由于没有包含收入维度而受到部分学者的批判。 此外,H-M 指数、HPI(人类贫困指数)、HDI(人类发展指数)也是目前常用的多维贫困识别方法。
在多维贫困的指标选取上,国内研究多采用联合国开发计划署和牛津大学贫困与人类发展中心联合发布的MPI 指数,并在此基础上进行补充调整。 例如李东、孙东期[5]在对中国多维贫困的动态分析中就沿用了全球多维贫困指数,同时根据数据可获得性,对住宅地面类型和炊用燃料贫困标准进行了调整。李振宇、张昭[3]在MPI 指数的健康、教育、生活状况三个维度基础上结合中国实际情况又增加了食物支出和收入水平两个维度。 值得注意的是,由于其研究对象的特殊性, 在教育维度中还增加了普通话熟练程度这一指标来判断少数民族与主流社会的融合程度。 王恒、王博等[6]则是从乡村振兴的视角出发,在综合考虑后构建了包括收入、教育、健康和生活水平在内的四个维度10 个指标对秦巴山区农户的多维贫困状态进行识别与测度。
在各维度与指标权重的确定方面,高艳云、马玉[7]对常用方法进行了梳理总结,指出常用的方法有等权重法、频率法和统计法。 等权重法即各维度内指标实行权重均等划分,典型代表有HDI、MPI;频率法是将物品或服务越普遍的维度赋予更大的权重,该方法常用于模糊集方法中;统计法则主要是主成分分析、因子分析以及层次分析法。 但在实际的研究中,等权重法因其简便易行、操作简单而受到研究者的欢迎。 但一些学者认为这种方法过于武断,进而尝试运用主成分分析和因子分析法进行权重的探索,但其中常出现负值,无法进行合理解释。 相比较而言,层次分析法虽然属于主观赋权的方法,但因其首先要通过各个指标的两两比较来构建矩阵,再通过方根法计算权重而具有相当的客观性和科学性。
而在研究主题上,陈闻鹤等借助CiteSpace 可视化研究工具指出,国外研究主要集中于美洲及非洲国家的贫困问题、社会排斥影响亚文化群体的贫困程度和能源贫困测度等方面[8],国内研究多聚焦于精准扶贫、连片特困区和县域贫困。 在多维贫困视角下对少数民族地区的贫困研究较少,如张润君、张瑞[9]是从社会治理角度研究西北深度贫困,邢伯伦等[10]是从精准扶贫角度研究深度贫困地区。
总而言之,已有的研究从多维贫困的维度选取、权重设置和测算方法等多方面展开,较为充分地测算了不同人群的多维贫困状况,但对民族地区的研究还不是很全面。 此外,常采用的等权重法也有可以改进的空间,层次分析法作为可以判断指标重要程度的科学方法,能够为多维贫困的不同维度科学赋权。
因此,本文通过使用层次分析法(AHP)确定各维度及指标的权重,构建适用于少数民族聚居地区的多维贫困指标识别体系,在此基础上再利用AF 法进行多维贫困测度。
二、研究方法及数据来源
(一)研究方法
本文采用AF 法和层次分析法相结合的研究方法,AF 法是在2008 年由牛津贫困与人类发展中心(OPHI)的Alkire 和Foster 提出的方法。 根据其发表的《计数和多维贫困测量》一文可知, 多维贫困测度通常包括多维贫困的识别、 加总和分解三个步骤。 通过AF 法测算得出的MPI 指数不仅能反映一个国家或地区多维贫困发生率与多维贫困发生的强度, 还能从微观层面反映个人或家庭的被剥夺量。 该方法由于指数选取的维度面广,能够全方位、多方面地反馈贫困人口的生活境况,被认为是目前较先进的相对贫困测算方法。
在多维贫困识别阶段,本文选择层次分析法进行维度及指标权重的确定,以此建立民族地区的多维贫困识别体系。 层次分析法主要是将定性与定量方法相结合, 使决策过程科学化、可测量化的一种决策分析方法,常用的使用场景包括多方案决策选择和方案内指标权重确定。 它的提出者Saaty 认为层次分析法包括四个步骤。 1)建立递阶层次结构。 递阶层次结构最顶层为目标层,并根据影响目标达成的要素设置准则层和方案层。 2)构建两两比较矩阵。 将每两个指标进行重要性的比较并赋予其相应数值。 一般采取Saaty 提出的1 至9 标度法进行判断,也就是以数值1 至9 以及它们的倒数表示其重要性,数值的具体含义如表1 所示。 3)在构建比较矩阵的基础上,采用“方根法”计算各级指标的单排序数值,得出比较矩阵的排序向量。 4)进行一致性检验。 一般认为,CR<0.1 表示比较矩阵通过一致性检验,计算误差可以忽略不计。

表 1 数值及含义
结合AF 法和层次分析法可以避免主观的等权重法带来的随意性, 使多维贫困指数的测算具有更强的客观性和科学性。 参考张庆红、祝志川等的研究[11-12],多维贫困指数的测算步骤如下:
1)构造矩阵。构造 n×d 维矩阵,即 X(n,d)。xij代表矩阵中的元素,其中 i=1,2,3,…,n; j=1,2,3, …,d,元素 xij表示个体 i 在 j 维度上的取值。
2)确定维度及指标①的权重。 借助层次分析法确定多维贫困指标体系中各维度及其下设指标的权重,便于后续贫困识别及加总。
3)确定指标的剥夺标准Zk,形成贫困剥夺矩阵:
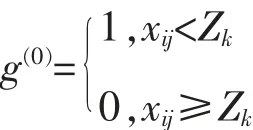
当xij小于剥夺标准Zk时,代表个体在该指标上陷入贫困,将g(0)赋值为1;反之,则表示个体没有在该指标上被剥夺,g(0)为 0。
4)贫困的识别与加总。通过计算平均剥夺份额(A)和贫困发生率(H)得到样本的多维贫困指数(MPI),即:

其中,q 表示贫困人口数;n 代表样本总数;Wi表示各指标的权重;gij代表个体发生贫困的指标剥夺值,即0 或1;ci(k)代表在k 个指标下,样本被剥夺的总权重分数。
5)贫困分解。 确定各指标对贫困的贡献度,分析影响多维贫困的主要因素。
(二)数据来源
本文采用中国家庭追踪调查第5 轮调查数据(CFPS 2018)作为数据来源,运用stata 16 进行家庭成员库、个人库和儿童库的数据合并与清洗、变量编码等工作。 因本文研究对象为少数民族地区,根据国家统计局官方口径,将被称为“民族八省”的贵州省、云南省、青海省、新疆维吾尔自治区、广西壮族自治区、西藏自治区、宁夏回族自治区、内蒙古自治区列为研究对象,最终选取3 068 个样本数据,主要分布于贵州、广西和云南地区,包含除汉族之外的苗族、壮族、布依族、瑶族、彝族、白族等20 个少数民族,其中主要以苗族、布依族和壮族为主。
三、少数民族地区多维贫困指标体系构建
(一)维度及指标选取
多维贫困的维度及指标选取并没有统一的标准,研究者通常根据自己的研究需要对前文提到的国际通用指标进行调整。 由于本文研究对象少数民族地区主要位于我国北部和西南部,涵盖高原、山地和丘陵等多种地形,地理环境复杂,生态环境相对脆弱,这种客观存在的地理环境一定程度上导致了民族地区在教育、 基础设施建设以及经济发展等方面相对滞后[13]。因此,本文结合民族地区的实际情况和已有贫困特征及脱贫绩效方面的相关研究[14-18],并借鉴联合国计划开发署和牛津大学贫困与人类发展中心联合发布的MPI 指数,选择将健康、教育、生活状况、经济收入四个维度纳入多维贫困识别体系。 具体维度及其指标选取作如下描述。
1.健康维度
选取看病点条件满意度和是否参加医疗保险两个指标。由于这里的看病点主要指距离居民区较近的社区卫生服务中心或村卫生室,主要负责慢性病和基础性疾病的恢复阶段,因此条件完备的看病点有利于保障群众的基本健康。 此外在CFPS 问卷中看病点条件不仅指医、药、就诊、住院等条件,也包括求医的路程远近、交通便利程度,所以受访者对看病点条件的满意度也能在一定程度上反映民族地区的交通便利情况。而医疗保险是国家分担社会成员疾病风险的基本保障,是否参加医保对个人遭遇疾病风险后维持个人及其家庭的正常生活具有重要影响。
2.教育维度
选取适龄儿童入学情况、成人受教育年限和汉语水平3 个指标。 反贫困理论认为,教育通过提高人口素质、提升人的综合发展能力能够从根本上阻断贫困对下一代的影响,因此教育层面是必须要考虑的维度。 适龄儿童入学情况可反映家庭长远的抗风险能力,成人受教育年限则反映劳动人口的劳动能力,这两个指标都是影响一个家庭能否摆脱贫困以及个人衡量自身发展能力的重要因素。 而汉语作为我国的官方语言,少数民族人口自身的汉语水平会直接影响其接收信息和融入社会的能力。
3.生活状况维度
包括饮用水、电、生活燃料3 个指标。 这3 个指标都是直接影响民众基本生活的要素。
4.收入维度
选取家庭人均纯收入、耐用消费品数量和住房3 个指标。 收入是个体是否发生贫困的显性特征。 有学者指出,“中国不存在一般发展中国家的绝对贫困,只存在相对于现金收入能力的贫困化”,因此在收入维度的指标选取上,非现金财产也应纳入进来,耐用消费品和住房面积是非现金财产的典型代表。
(二)层次分析法确定权重
1.建立递阶层次结构
多维贫困识别体系可以分为三层:目标层、准则层和方案层,目的在于分解和构建多维贫困识别体系的重要指标。 如图1 所示,目标层为多维贫困识别体系,用A 表示;准则层则表示这一体系主要从健康、教育、生活状况和经济收入四个维度来构建,分别表示为B1、B2、B3、B4;方案层表示衡量各个维度的细分指标,这一层用C 表示,总计11 个指标。
2.构建判断矩阵并计算权重
1)确定一级指标权重
结合图1 可知,这里的一级指标为准则层的健康、教育、生活状况和经济收入四个维度。要确定其权重,首先需要构建比较判断矩阵,即A-Bi矩阵(i=1,2,3,4);其次通过方根法计算Bi的权重,即:
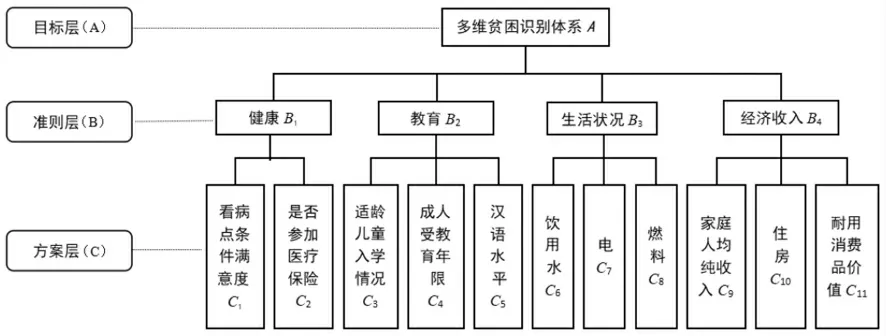
图1 多维贫困识别体系

其中,bi表示矩阵内的数值,n 表示矩阵的阶数,Wi* 表示矩阵的每行乘积,Wi表示Bi的权重。最终结果如表2 所示。
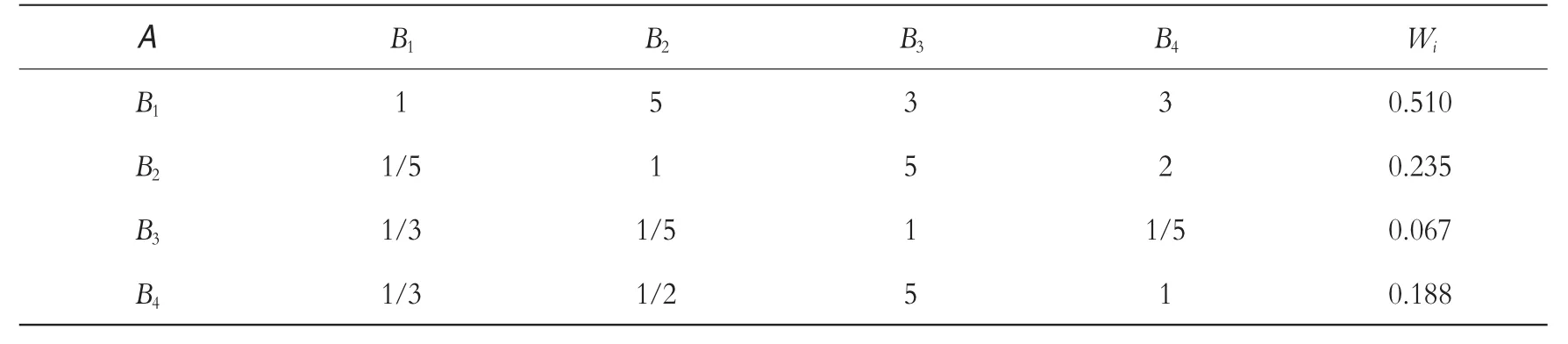
表 2 A-Bi 比较矩阵及权重
2)进行一致性检验
一致性检验是为了判断各指标的权重是否合理。 当一致性比率CR<0.1 时,可以认为各指标权重的不一致性在合理区间,具备满意的一致性,通过检验。 计算公式为:

其中,CR 代表一致性比率,λmax代表最大特征根,Wi表示进行比较的维度的权重,AWi表示矩阵内数值与所得权重Wi的乘积,n 表示矩阵阶数,RI 为已知的随机一致性系数,如表3 所示。

表3 随机一致性系数RI
根据公式(8)和(9),可以得出最大特征根 λmax=3.982,继而可得 CR≈-0.36<0<0.1,通过了一致性检验,表明表2 矩阵具有良好的一致性。
3)确定二级指标权重并进行一致性检验
在确定一级指标权重的基础上,构建二级指标(即方案层C 层)的比较判断矩阵并利用公式(5)、(6)、(7)计算二级指标的权重。 表 4 为二级指标的比较判断矩阵、所得权重和一致性检验结果。 由于二级指标隶属于一级指标,其最终权重应为方根法计算结果与所属维度的权重相乘,见表4 中的最后一列。
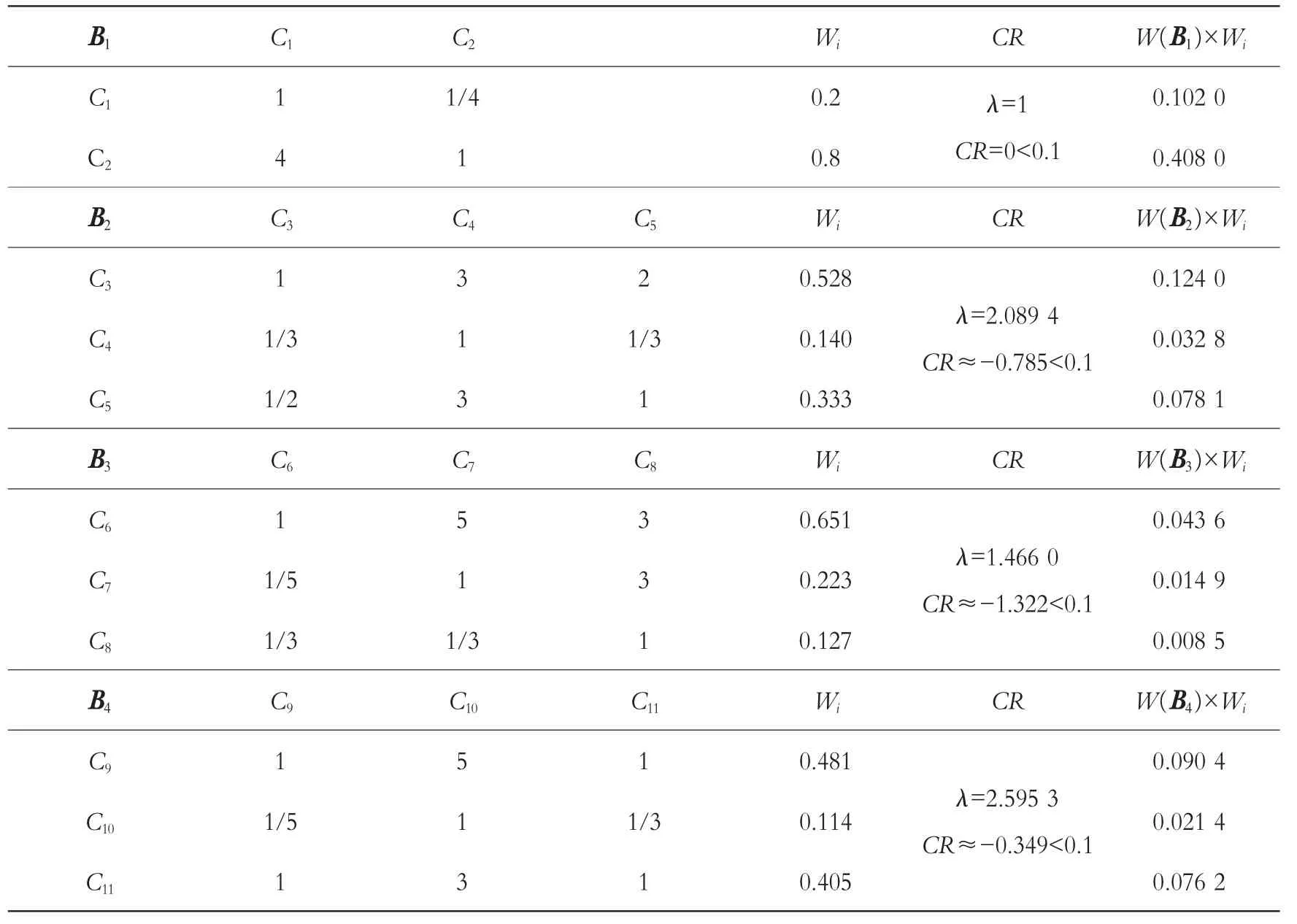
表4 二级指标的比较判断矩阵、所得权重和一致性检验结果
(三)AF 法确定临界值
从表4 可知,上述矩阵都具有较好的一致性,可得到多维贫困指标体系。 下一步根据AF双临界值法,确定各指标的剥夺临界值(第一临界值)和多维贫困的临界值(第二临界值),以识别个体是否发生贫困以及在哪些指标上发生贫困。
剥夺临界值一般赋值1 和0 来表示, 赋值为1 表示个体在该指标上受到剥夺, 赋值为0则表示未受到剥夺。 是否受到剥夺的标准主要依据前人的研究和所得数据来确定,本文各项指标的剥夺标准描述如下:
依据2018 年中国家庭追踪调查问卷中对看病点就医条件的回答,将答案“不满意”和“很不满意”视为在这一指标上受到剥夺,赋值为1;回答为“一般”“满意”和“很满意”则视为未受到剥夺,赋值0。 考虑到基本医疗保险的抗风险性,将未参加任何形式的基本医疗保险的个体赋值为1,反之赋值为0。 结合2011 年我国2 300 元的国家贫困线标准,将家庭人均年纯收入低于2 300 元的个体赋值为1,反之,赋值为0。家庭人均月用电费基于统计局给出的家庭人均月用电量和平均电价计算得出,我国家庭人均月用电量取整为70 kWh,平均电价为0.6 元,因此家庭人均月用电费的剥夺标准为42 元,低于42 元的视为在这一指标上受到剥夺,赋值为1,反之赋值为0。人均住房面积参考仲超、林闽刚[18]的研究,规定少于15 平方米即认为受到剥夺,赋值为1,反之赋值为0。 根据国家统计局标准,耐用消费品包括家用汽车、摩托车、电动车、洗衣机、电冰箱、微波炉、彩色电视机、空调、热水器、抽油烟机、移动电话和计算机,本文认为少于两项属于在这一指标上发生了贫困。 其余指标的剥夺标准在表5 中加以说明。

表5 多维贫困指标识别体系
多维贫困的临界值指个体至少同时在多个指标上发生贫困的指标数。 国际上通常规定多维贫困的临界值为3,即个体至少在3 个指标上存在贫困,就认为该个体发生了多维贫困,一般表示为k≥3。
四、多维贫困指数(MPI)测度与分解
(一)少数民族地区多维贫困测度分析
依据公式(1)、(2)、(3)、(4),可计算得出表 6 数据。 其中 k 值表示,如果一个家庭在 11 个指标(维度)中的任意k 个及以上指标同时存在贫困,就定义该家庭发生k 维贫困[19]。 从表6中可以看出,贵州、云南、青海及内蒙古、新疆、西藏、宁夏、广西8 个省市自治区中最多存在9维贫困,不存在10 个指标及以上的多维贫困。当k=1 时,多维贫困发生率为99.51%,平均剥夺份额为26.61%。 表明民族地区存在普遍的单维贫困,99.51%的人都至少在1 个指标上陷入了贫困。 而平均剥夺份额仅为多维贫困发生率的四分之一,说明当k=1 时,贫困群体陷入贫困的程度较轻,比较容易从贫困的境地中脱离出来。 高贫困发生率和低贫困深度表明少数民族地区普遍存在单个维度上的相对易于摆脱的贫困问题。 此外,多维贫困发生率随着k 值的增大不断降低,平均剥夺份额却不断增加,意味着随着发生贫困维度的增多,越来越少的人口陷入贫困,但他们的贫困深度却逐渐加深。 这也就是说,越是在更多维度陷入贫困的人口,靠自我发展能力摆脱贫困的可能性相对较小,更需要社会资源的支持。
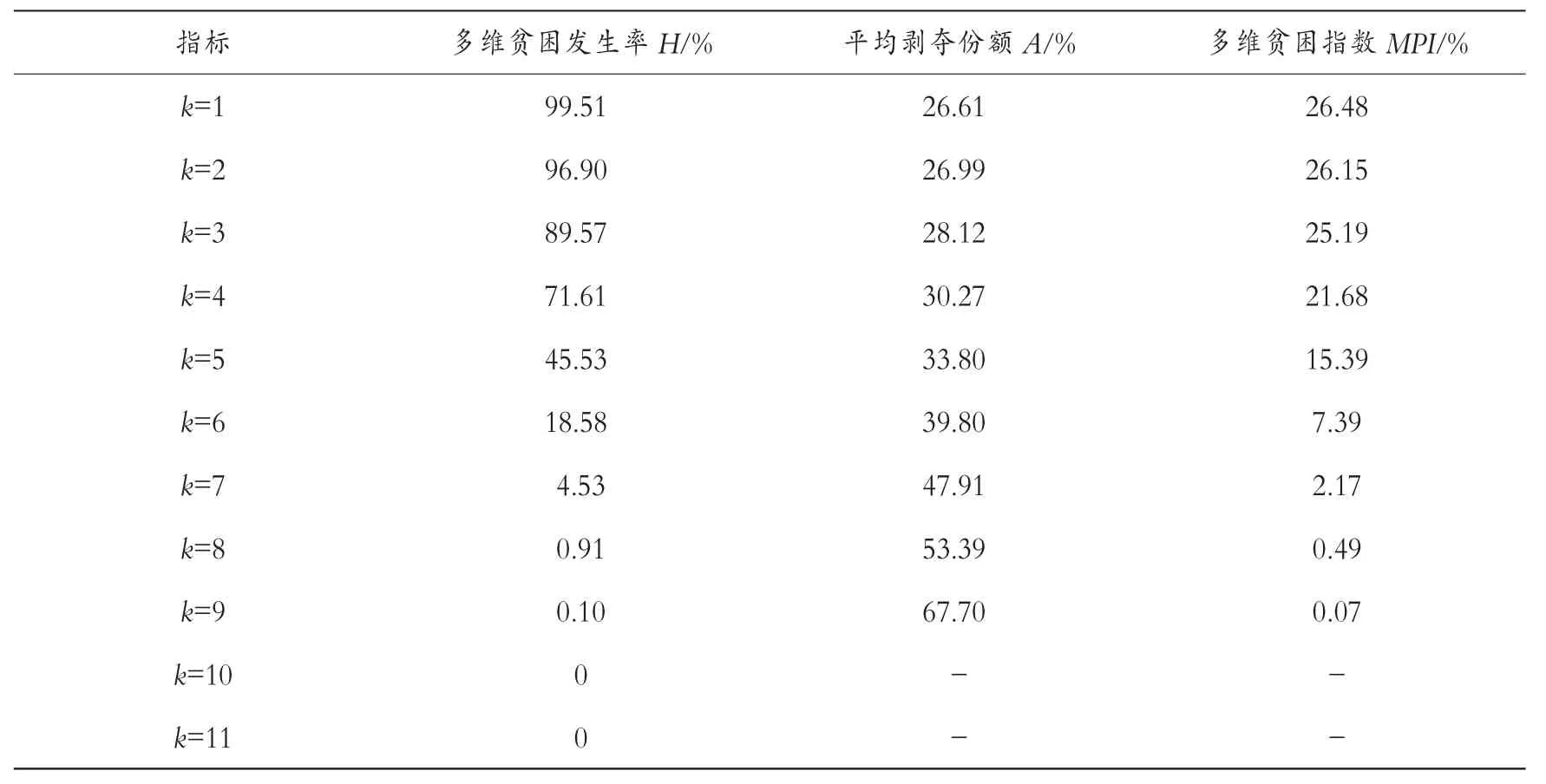
表6 少数民族地区多维贫困指数
从样本包含的民族来看,苗族、布依族、壮族是分布人数较多的民族。 根据表7 可知,三个民族之中,苗族的贫困覆盖面最广,因为不论在k 取何值时,苗族的多维贫困发生率整体高于布依族和壮族。 并且,苗族存在同时在9 个及以上的维度中发生贫困的现象,布依族最多同时在8 个及以上维度上存在贫困现象,壮族次之,k 值最大取到7。然而从数值上看,k=9 时,苗族的多维贫困指数仅为0.12%,而k=8 时,布依族的多维贫困指数为1.02%,是苗族的两倍左右。此外从贫困深度来看,布依族的贫困深度是三个民族中最高的,整体高于苗族和壮族,而且其多维贫困指数也平均高出苗族和壮族3 个百分点左右。 因此,在三个民族之中,壮族的贫困范围和贫困深度最轻,发展情况最好,其次是苗族,第三是布依族。 这表明相对而言,壮族具有较强的摆脱贫困的能力,自我发展能力较高。
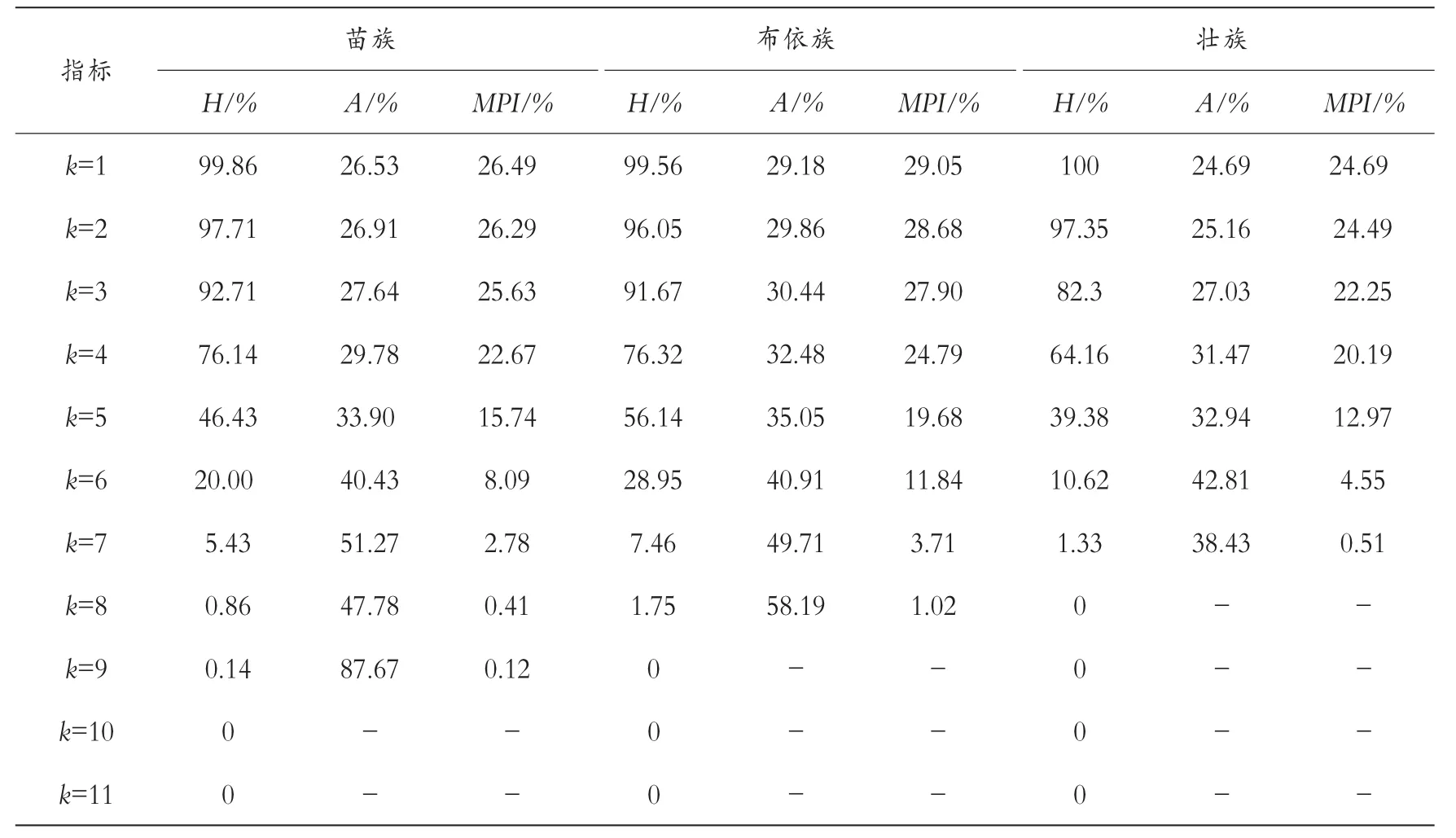
表7 主要民族多维贫困测度
从发生贫困的具体维度来进行分析,如表8 所示。 在11 个指标中,“医疗保险”和“家庭人均纯收入”这两个指标的贫困发生率较低,均低于10%,尤其是“医疗保险”,贫困发生率仅在5%左右,与我国当前95%的医疗保险参保率相吻合,这表明全民医保政策在民族地区也得到了充分的实施且取得了良好效果。 而在“家庭人均纯收入”这一指标上发生贫困的概率较低,说明国家的精准扶贫政策在少数民族地区发挥了重要作用,在很大程度上少数民族地区已摆脱了收入带来的绝对贫困。
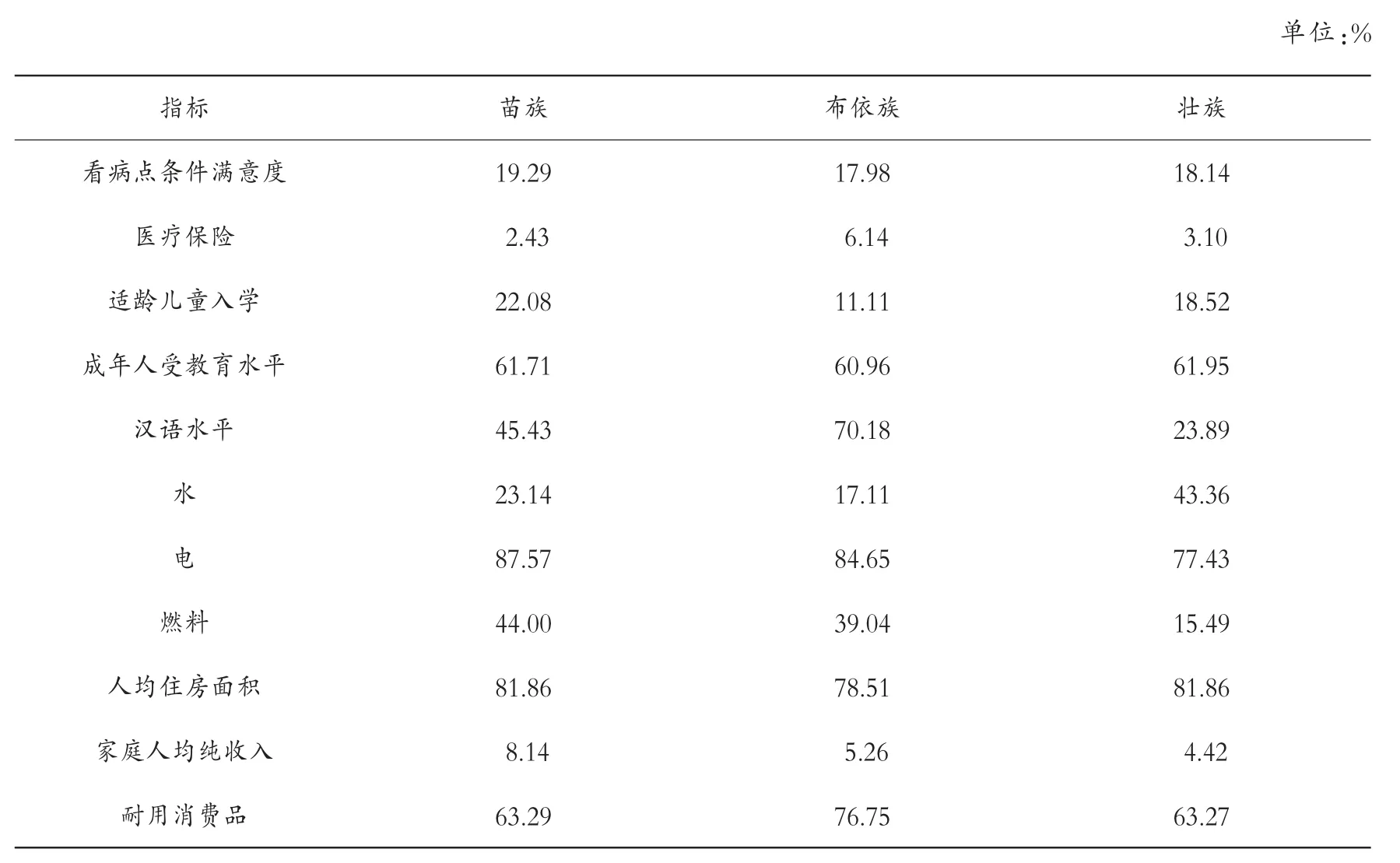
表8 主要民族单维度贫困发生率
贫困发生率排名前四的指标是“电”“家庭人均住房面积”“耐用消费品”和“成年人受教育水平”。 其中,“电”和“家庭人均住房面积”这两个指标都是影响个体和家庭生活水平的重要指标,80%左右的贫困发生率表明有绝大多数的少数民族群众仍然处于缺电、少电的困境,民族地区的基础设施建设还有进一步完善的空间。 人均住房面积低于15 平方米,少数民族地区的生活用电和住房问题还需要进一步加大力度,向这两个领域投入更多资源。 “耐用消费品”指标是一个家庭生活水平的重要象征,三个少数民族在这一指标发生贫困的概率较高,说明少数民族地区无力购买必要的一些耐用消费品,如汽车、微波炉等,影响了生活水平的提高。由于此样本中各个年龄段分布较为均衡,因此“成年人受教育水平”这一指标的高贫困发生率可以说明少数民族地区的民众受教育水平普遍较低,未能完成9 年义务教育的人口占八成左右。 此外值得指出的是,布依族在“汉语水平”这一指标上的贫困发生率较高,为70.18%,说明其主要使用的语言仍是方言或民族语言,汉语水平不高,而其他两个民族仅为45.43%和23.89%。 这可能会对少数民族与以汉语为主要语言的主流社会的融合产生阻碍,不利于其长期的发展。
从样本包含的发生贫困区域来看,贵州、云南、广西是主要地区。 从表9 中可以看出,三个地区的多维贫困指数相差不大,且被剥夺维度数相对集中,主要集中在k=3、k=4 和k=5。 其中在k=3 时,多维贫困指数最高,这表明三个省份的贫困人口主要在3 个及以上维度陷入贫困。从具体指标来看,当k 值增加时,多维贫困指数(MPI)总体呈现不断减小的趋势,贵州从26.27%降低至0.05%,广西从26.11%降低至0.24%,云南从27.66%减少至0.14%。 对比三个省份的平均剥夺份额可以发现,贫困深度整体较高的是云南省,贵州次之,广西最轻。 且从贫困覆盖面来看,广西也是三个地区中情况最好的,说明广西在脱贫攻坚战中取得了较其他两个省份更好的效果,具备较强的多维贫困反贫困能力。
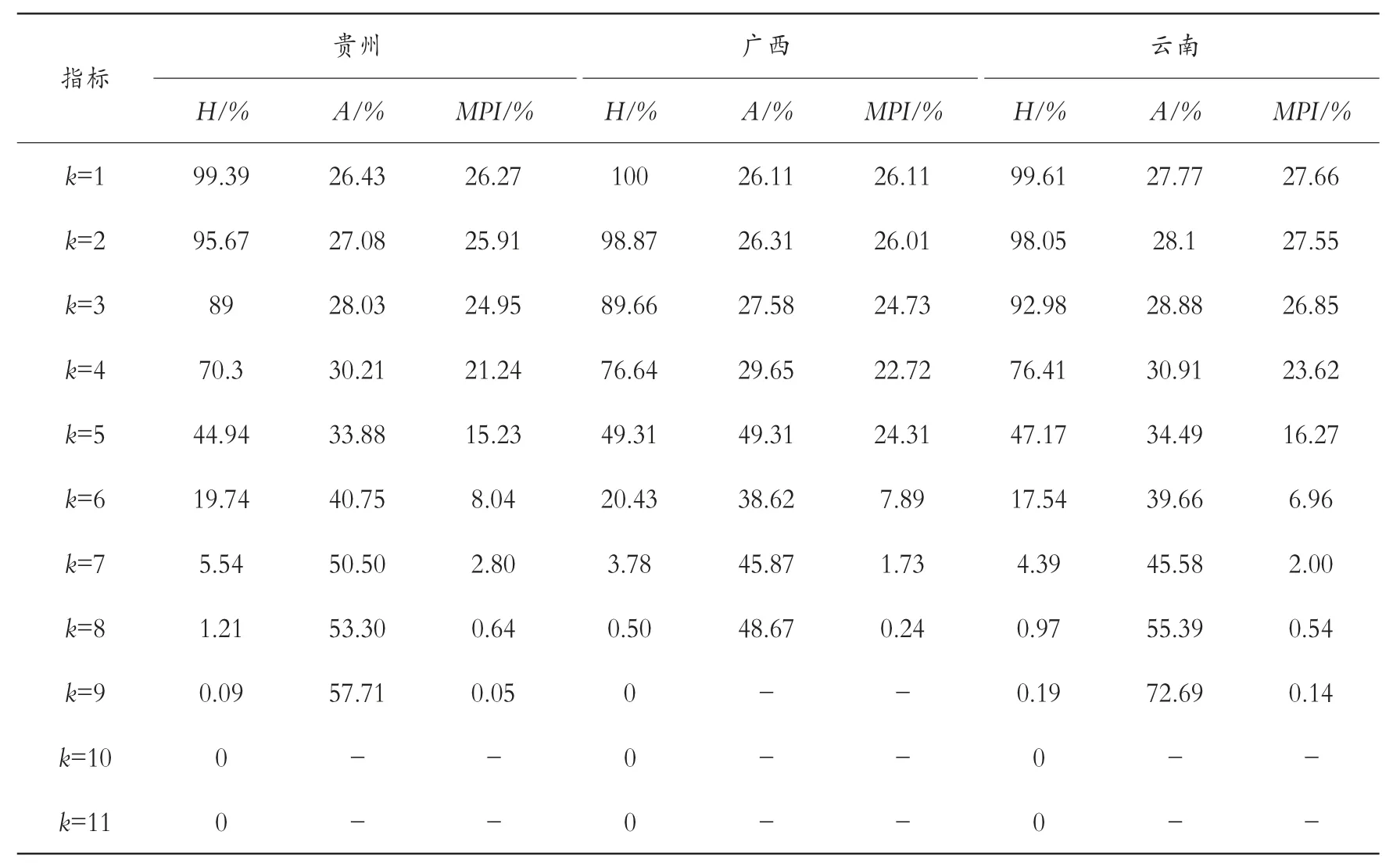
表9 主要省份多维贫困指数
(二)多维贫困的分解分析
对多维贫困的分解意在发现影响相对多维贫困的关键因素,为相对贫困地区可持续发展提供方向,避免返贫现象的发生,不断巩固和扩大我国脱贫攻坚行动的成果。 一般来说,AF 法可以按维度或者地区分解多维贫困指数[12]。 但因为本文已运用层次分析法确定各维度和指标的权重,已经体现了各指标的贡献度,因此选择按地区(省份)分解和按城乡分解。
1.按地区分解的多维贫困指数的贡献度
多维贫困指数的贡献度Con 按地区分解表示为:

其中,n 表示第i 个地区的人口数,N 表示样本总数,n/N 代表该地区所占的权重;nq表示在k=1,2,3,…,d 时第 i 个地区被剥夺的人口数,Nq代表在 k=1,2,3,…,d 时样本总数被剥夺的人口数。 mpi 代表在贫困阈值k 下第i 个地区的多维贫困指数,MPI 代表贫困阈值k 下少数民族地区总体的多维贫困指数(见表6)。
表10 为样本中主要地区对多维贫困指数的贡献程度,贡献度越高,代表该地区是影响少数民族地区摆脱多维贫困的主要因子。 从表10 可以看出,贵州、云南两地区的贡献度较高,广西地区相对来说贫困贡献度较低。 这与表9 中体现的云贵地区贫困深度高于广西地区相吻合,说明对少数民族八省份来说,云贵地区更需要外力扶持去摆脱贫困,相关部门有必要进一步加大对云贵地区的扶贫力度和精准度。
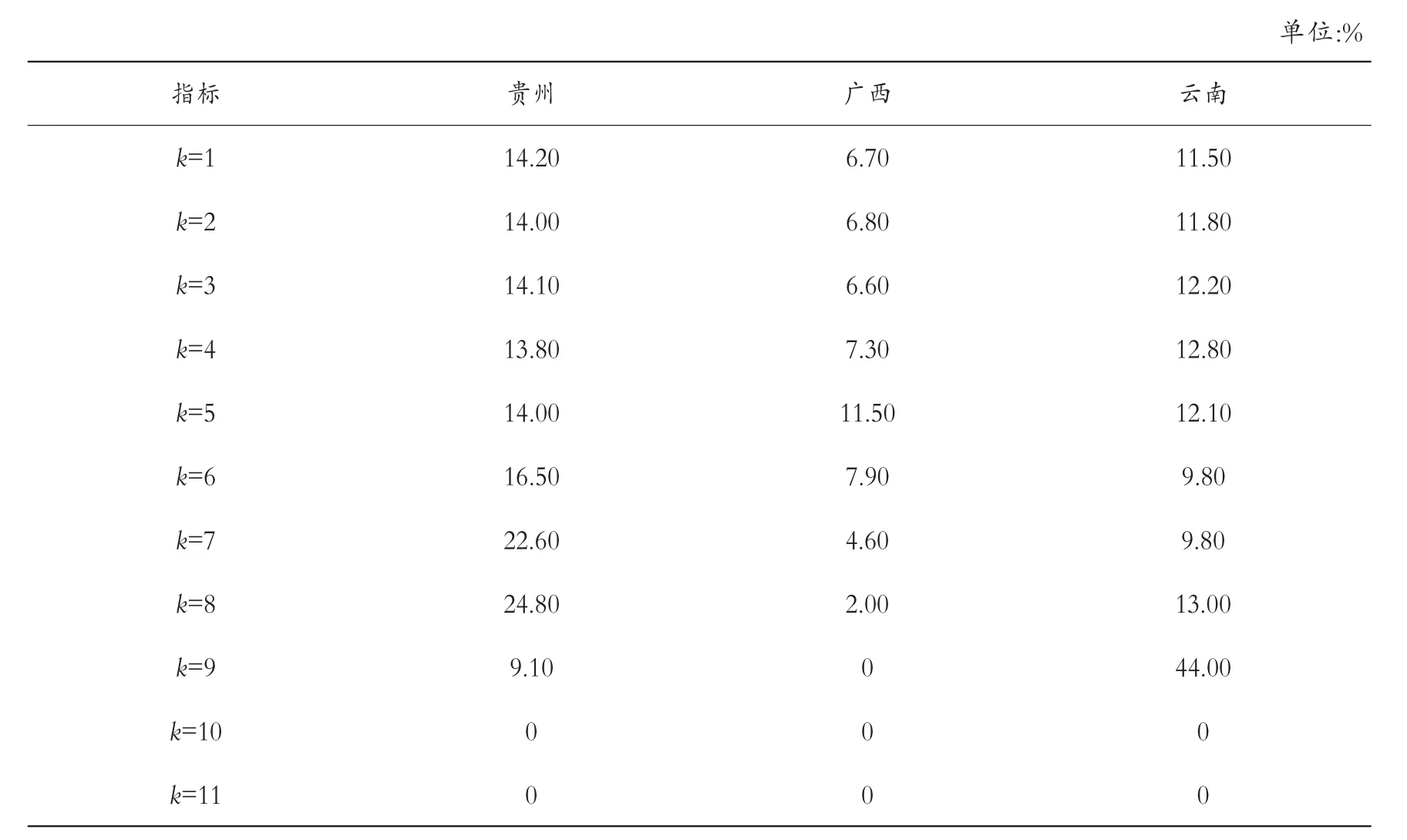
表10 各地区对多维贫困指数的贡献度
2.按城乡分解的多维贫困指数的贡献度
多维贫困指数的贡献度Con 按城乡分解表示为:

其中,Ci表示城镇或农村陷入多维贫困的人口数,C1代表城镇(i=1),C2代表农村(i=2),mpi(c)表示城镇或农村的多维贫困指数,公式内其他指标含义与(10)式相同。 城乡分解的结果如图2 所示。

图2 民族地区多维贫困的城乡贡献差异
由图2 可知,民族地区农村的多维贫困贡献程度远大于城镇,农村地区的贫困贡献度在57%~98%之间,而城镇地区的贡献度不超过0.5%,并且多维贫困的维度数较少,不存在同时在8 个及以上维度陷入贫困的现象。 也就是说民族地区的多维贫困主要集中在农村地区,且随着k 的增加,农村多维贫困的贡献度也在增加,表明农村的贫困是多维度、多方面的复杂的贫困状态,需要政府相关部门全方位、系统性的扶持,同时结合当前方兴未艾的乡村振兴战略,进一步细化民族地区的反贫和发展路径。
五、结论与政策建议
(一)结论
总体来说,经过前几年的脱贫攻坚行动,我国全面建成了小康社会,并且实现了人类历史上的伟大壮举——消除绝对贫困。 相应地,少数民族地区的生活状况也得到了极大改善,特别是在健康和收入层面,贫困发生率均在10%以下。 本文的研究可以得出以下结论:
一是少数民族地区在健康、收入以外的其他维度贫困发生率相对较高,基础设施和教育水平仍然是少数民族地区摆脱多维贫困的主要障碍。 具体表现为少数民族地区民众在生活用电、饮用水和生活燃料以及住房问题上仍然存在不同程度的贫困,且不同民族之间有所差异。适龄儿童入学率和成年人受教育年限及汉语水平的贫困发生率相对较高。
二是少数民族地区的多维贫困主要集中在农村地区,不论从单维还是多维来看,仍难以将城镇的贫困问题提高到和农村贫困同等的重视程度。
所以要想从根本上摆脱贫困,首先要建立完善的贫困识别体系,实现贫困人口的精准识别;其次要从教育和社会环境入手,培养少数民族地区群众的自我发展能力,增强其摆脱贫困的能力。
(二)政策建议
1.探索多维贫困识别体系的建立
在2020 年之后, 我国衡量是否贫困的标准不应再以收入等物质指标为主要标准,而是以影响民众体面生活的多个维度作为标准,如健康、教育、生活设施、主观感受等。 对少数民族地区来说也是如此。 依据上述研究可知,收入确实不再成为阻碍民族地区脱贫的主要因素,因此学界采用的等权重法不符合现实情况,应将收入层面的剥夺标准适当提高或者赋予其较低的权重。 而由于健康维度的标准受到主观差异的影响较大,不同的研究者会选用不同的指标来衡量,因此健康维度的权重要视所选取的衡量指标而确定。例如,如果以本文中选取的“医疗保险”“看病点条件满意度”为指标衡量,那么根据研究结果,它们的贫困发生率较低,在实际的贫困识别体系建立时就应适当降低健康维度及相关指标的权重,适当提高教育维度的权重,其他维度权重确定也应将其所选指标的含义作为参考。
此外,多维贫困识别体系应该因地制宜。 我国幅员辽阔,从地理环境、资源禀赋、经济能力各个方面都存在巨大差异。 但就本文的研究对象而言,少数民族地区的发展环境类似,都存在一些地理环境带来的限制,同质性相对较高,可以为其建立统一的多维贫困识别体系,以利于进一步精准扶贫,不断扩大反贫困成果。
2.进一步发挥教育对贫困的阻断作用
少数民族地区多山的地理环境本就容易与主流的社会环境相脱离, 又因其独特的语言文字、民俗文化等与现代社会发展存在较大差距,不易实现接轨。上述研究也显示,云南和贵州地区的贫困深度整体较高,当地群众自我发展能力不足。教育作为提升人口综合素质,阻断代际贫困传递的重要手段对少数民族地区来说显得尤为重要[20],教育水平的高低关系到民族地区与主流社会的融合程度。因此在后减贫时代,要充分发挥教育在阻断贫困代际传递方面的重要作用, 进一步加大对少数地区基础教育的投入并尽可能提高投入的精准性。 首先,应在民族地区全面开展汉语和民族语言的双语教学,提高少数民族民众的汉语水平,为其在适应社会生活时减轻负担,尤其是布依族和苗族。其次,要加大民族地区的人才补贴力度,吸引当地高校具备双语能力的青年人留在当地,成为教学队伍源源不断的后备力量。最后,健全教师队伍建设的长效机制。张庆红[11]的研究显示,国家对民族地区的投入主要集中在教学设施和校舍环境的改善,而对教师的关注较少。 因此提高民族地区双语教师的待遇应成为教育扶贫的第一要事。 一方面,除薪资之外可以为其提供职称评定、住房保障等方面的倾斜政策,为教师提供良好的住宿环境与教学环境等;另一方面,完善民族地区的教师培训机制,定期开展地区间培训交流,为教师提供有前景的职业发展路径。
3.进一步完善基础设施建设,为提升民族地区可持续发展能力提供保障
基础设施是一个地区经济发展的基本物质条件,是群众生活品质的实体保障。 基础设施建设的完善程度制约着区域间的协调发展。 而民族地区由于地理环境的限制和生态环境的脆弱,基础设施建设相对不完善,部分地区仍然在用电、用水、生活燃料等方面存在不足。 此外,基础设施的不完善也造成民族地区与主流社会交流、贸易的机会相对有限,一定程度上限制了民族地区特色产业的发展以及产业的升级转型等。
所以在“后减贫时代”更应注意民族地区的基础设施建设。 首先,民族地区政府要加大对水、电的投入,加快推进电网改造和城乡供水工程,抢抓国家加大“新基建”投资的政策机遇,以县域为单元统筹完善农村基础设施建设,彻底畅通城乡道路、供电、通信、供水等基础设施网络的“肠梗阻”[21],为贫困人口的基本生活提供保障。 此外较为突出的住房问题也需加以重视。 少数民族地区多数民众还处于租房或人均住房面积低于15 平方米的现状。 其次,从国情来看,我国最大的相对贫困群体主要在农村[22]。 本文研究也显示,民族地区的多维贫困主要集中在农村。 因此,减贫战略要与乡村振兴战略相衔接,侧重加强交通网络及通信网络的建设,通过基础设施的通达度强化民族地区与主要经济中心之间的交流,使民族地区可以借助基础设施的辐射带动作用发展特色产业,从而实现可持续发展。
注释:
① 关于本文中“指标”与“维度”的含义:在运用层次分析法时,“维度”与“指标”含义不同,“指标”隶属于“维度”,属于“维度”下面的细分一级。 在AF 多维贫困测算法中,“维度”与“指标”同义。
