基于改进SSD的苹果叶部病理检测识别*
2022-10-11严康华梁晓菡
李 辉, 严康华, 景 浩, 侯 锐, 梁晓菡
(河南理工大学 电气工程与自动化学院,河南 焦作 454000)
0 引 言
在苹果的生产过程中,保果的基础是保叶[1],由于我国农民通常是自我经验来对病害进行识别,很容易造成误判,影响苹果的质量和产量。因此研究苹果叶部病理检测智能化的意义重大。
随着计算机技术的普及,深度学习[2]迅猛发展并应用于农业病害检测中[3],Zeng W H等人[4]提出了一种自注意力卷积神经网络(self-attention convolutional neural network,SACNN),提取作物病害点的有效特征来识别作物病害。Waheed A等人[5]提出了一种用于玉米叶病识别和分类的优化稠密卷积神经网络(DenseNet)结构,监测作物的健康状况。Zhong Y等人[6]提出基于DenseNet—121的深度卷积网络对苹果叶病的回归、多贝尔分类和焦点丢失函数三种识别方法。师韵等人[7]提出一种基于主成分分析(principal component analysis,PCA)算法的苹果病害识别方法。刘翠翠等人[8]利用图像处理、PCA、支持向量机(support vector machine,SVM)等技术开发麦冬叶部病害识别系统。郭小清等人[9]通过粒子群优化(PSO)算法实现参数自动寻优的SVM模型,识别番茄叶部病害。周敏敏研讨通过Faster R-CNN算法对苹果叶面5种病害的检测,5种病害的均值平均精度(mean average precision,mAP)为76.55 %[10],但该方法对病斑小目标的识别精度和速度较低。
以上研究表明,在农业病害检测领域中,基于卷积神经网络(convolutional neural networks,CNN)的目标检测算法得到了广泛的应用。基于的目标检测算法包括二阶(two-stage)目标检测算法以Fast R-CNN、Faster R-CNN等为代表。一阶(one-stage)目标检测算法以SSD(single shot multibox detector),YOLO等为代表[11],本文选择精度和效率高的单级目标检测算法 SSD 作为基本框架。
在苹果叶部病理检测时,存在以下问题:较小的目标难以识别;部分背景区域识别为目标;重复识别目标。针对此,对SSD算法进行改进,包含以下3点:1)融合SSD的高低层特征图的特征,各层取长补短,提升小目标的识别精度;2)考虑到苹果叶部病害目标易受背景干扰,一些背景信息可能分布在特征图的某些通道上,对用于生成候选区域的不同尺度特征图引入通道注意力机制;3)引入Focal Loss,代替原有的损失函数,主要解决正负样本比例失衡的问题。在不增加模型参数的数量上,提升了检测的精度,实验结果验证了本文提出的改进算法的优越性。
1 苹果叶部病理检测算法
1.1 特征融合模块
引入一个轻量级特征融合模块[12,13],选用VGG16作为改进SSD的Backbone,输入图像的大小为300×300,利用VGG16的Conv4_3、FC7,额外层Conv7_2做特征融合,先将1×1Conv降低特征图的通道数变为256,并将Conv4_3的特征图设置Base尺度为38像素×38像素对应Stride=8,设置Conv6_2的stride=1,则Conv7_2 的分辨率也为10像素×10像素。对于尺度小于38像素×38像素的特征图的 FC7 和 Conv7_2 就使用双线性插值做上采样操作,尺度缩放为38像素×38像素;在空间维度信息保持一致后,将FC7 ,Conv7_2与Conv4_3连接做Concate得到一个合并层,如图1虚线框所示,接着BN(batch normalization)以正则化该合并层,以此层为Base Layer,通过Down-Sampling Blocks生成新的特征金字塔,并最终在新生成的特征金字塔上检测叶部病斑,补充的细节信息在一定程度上也能够提高模型的识别精准度,且新增的速度消耗也非常小。

图1 特征融合模块
1.2 通道注意力模块
本文使用通道注意力网络 SENet (squeeze-and-excitation networks)[14],SENet中的注意力机制分为3个部分:挤压(squeeze),激励(excitation),以及注意(attention),其结构如图2所示。

图2 通道注意力模块
图2中,最左边是输入特征图X∈RH×W×C,X有C个通道,每个通道的权重都是通过对特征图在空间维度H×W进行压缩得到。为了可以自适应生成各通道的注意力权重,使用具有一个隐含层的多层感知机,隐含层的神经元个数为C/r,r为缩放比例,合适的r可以提高计算效率,本文的r取2。使用Sigmoid得到最终的权重,公式如下
Sc=Fex(Z,W)=σ(g(Z,W))=σ(W2δ(W1Z))
(1)
式中δ函数为ReLU激活函数,σ为Sigmoid激活函数,Sc的维度为1×1×C,Sc对应生成的通道注意力权重。
最终使用得到Sc对输入通道进行调整,通道注意力加权公式为
(2)
1.3 Focal Loss损失函数
在一阶中,由于样本不均衡带来的主要问题是网络学不到有用信息,训练被大量负样本所主导,少量正样本所提供的关键信息不能在损失函数中正常发挥作用,无法对苹果叶部病斑小目标进行准确分类,造成漏检和误检。本文引入的Focal Loss函数[15]是在对交叉熵损失(cross-entropy loss)函数的基础上进行的修改。
Focal Loss 在交叉熵损失的原有基础上,增加了一个因子γ,自动降低Easy Examples的损失,帮助模型集中于训练更加困难的样本。Focal Loss函数定义公式如下
FL(pt)=-at(1-pt)γlog(pt)
(3)
式中pt为不同类别t的概率;平衡因子at为Positive和Negative的比例,用来平衡样本不均衡;γ为聚焦参数,来调节简单和困难样本权重降低的速率;pt越大,通过增大γ,权重(1-pt)γ就越小,通过权重对简单样本进行抑制,当γ增加时,平衡因子at也在增加。根据实验经验,本文实验中的参数at,γ分别取0.25和2。
1.4 基于改进的SSD网络结构
本文的检测结构如图3所示,特征融合Conv4_3,FC7,Conv7_2的合并层,与另外5个额外卷积层,且每个卷积层都能够减小特征图的尺寸,作为用于检测的特征图。其次,合并层与每个额外层作为SENet的输入X,经过全局平均池化与两个全连接层,再通过激活函数Sigmoid得到各通道的权值,与原输入X对应相乘得到最终用于检测的特征图,如图3下部虚线框SENet为具体网络结构。本文在SSD上新增一个轻量级的特征融合模块,利用浅层细节特征与高级语义特征相结合的高效特征提取能力,得到一个合并层,然后与5个额外层得到6种不同尺度的特征图,再经过通道注意力机制后得到最终特征显著的特征图,随后进行目标检测。
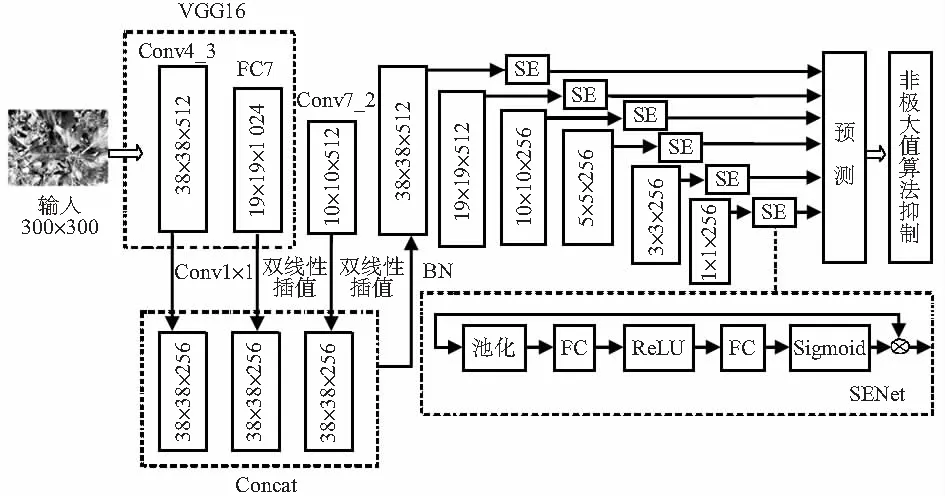
图3 基于改进SSD的苹果叶部病理检测模型结构
2 实验结果与分析
2.1 实验环境与数据集
本文使用PyTorch1.4框架进行实验,并采用图形处理器(graphic processing unit,GPU)进行加速运算,具体实验环境如下:Windows 10系统,PyTorch 1.4框架,Python 3.7语言,Intel®CoreTMi7—4790@3.60 GHz CPU,RTX 2060S GPU,16 GB RAM。
本文所设计的数据集共包括23 729张苹果叶部病理的大小为300×300图像,来源于百度AI公共数据集库,共分为5类叶部病害:斑点落叶病(alternaria)、褐斑病(brown)、花叶病(mosaic)、灰斑病(grey)、锈病(rust)。数据集中的训练集包含了16 251张病害图像,测试集和验证集分别含有3 739张病害图像。
2.2 评价指标
本文采用的评价指标为mAP,AP为各类检测精确率的评价指标。mAP和AP与精确率(precision,P)P=TP/(TP+FP),召回率(recall,R)R=TP/(TP+FN)有关, TP表示被正确识别正样本的数量,FP表示被错误识别正样本的数量,FN代表被错误识别负样本的数量。
通过计算的召回率R和精确率P组成P-R曲线,对该曲线围成的面积进行积分,得到的即是AP值,AP值越大,表示算法性能越好,其积分公式为
(6)
mAP为对5类苹果叶部病害的AP值计算均值,其公式为
(7)
式中M为类别总数, AP(k)为第k类的AP值。
本文中设定的阈值IoU为0.5,当IoU≥0.5时,表示目标被检测成功;反之,则目标没有被检测成功。
2.3 模型训练
本文采用端到端的方式对网络进行训练。其中,设置初始学习率分别为0.001,0.000 1,0.000 01三种情况下进行训练,设定迭代总数为120 000,在模型初始化中,对共享卷积层在ImageNet数据集上训练的VGG—16模型进行初始化,每次训练设置每500次保存一次模型,这样便于找到效果最好的模型。
2.4 不同参数实验分析对比
改进的SSD算法在不同学习率情况下,5种苹果叶部病理的AP值对比,以及mAP值,如表1所示。
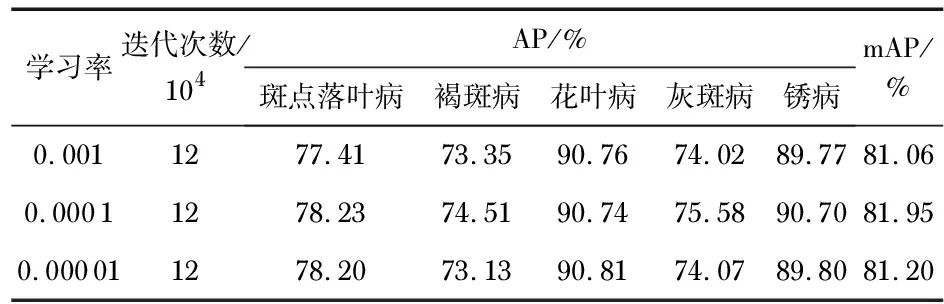
表1 不同参数的实验结果
由表1可知,学习率影响训练效果,在3种学习率不同的情况下,实验结果表明,在学习率设定为0.000 1,迭代次数为120 000次时,得到的网络模型效果最佳,mAP值为81.95 %,其中,斑点落叶病的AP值为78.23 %,褐斑病的AP值为74.51 %,花叶病的AP值为90.74 %,灰斑病的AP值为75.58 %,锈病的AP值为90.70 %。
2.5 不同算法实验分析对比
在上述实验中选取最佳效果的网络模型,将其与SSD,YOLO和Fast R—CNN,Faster R-CNN和ZF网络特征提取的Faster R—CNN算法做实验对比,结果如表2和图4所示。
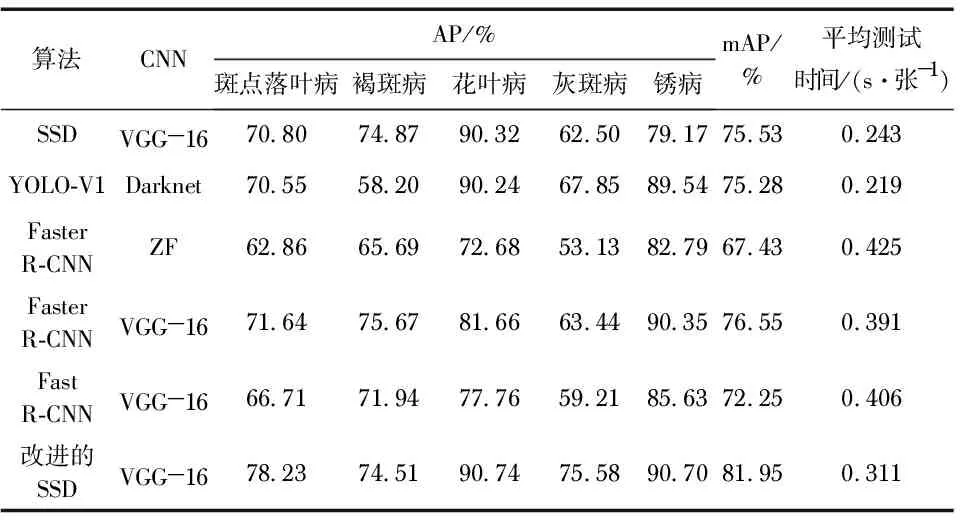
表2 不同算法的实验结果
由表2可知,本文的检测方法的mAP值明显高于其他5种算法。其中,在检测速度上,最快的YOLO—V1为0.219 s/张,这是因为只需要对一阶网络生成的Anchor框进行分类和回归,生成的Anchor框会映射到特征图的区域,然后该区域被重新输入到全连接层进行分类和回归,这样的分类和回归需要对每个Anchor映射的区域进行,所以一阶速度快了很多;但在检测精度方面,以特征提取网络VGG—16的Faster R-CNN为代表的检测mAP值达到76.55 %,这是由于一阶网络最终学习的Anchor有很多,但对最终网络学习有利的只有少数Anchor,而大部分都是不利的,而最主要影响整个网络学习的是这部分的Anchor,降低整体的准确率;虽然二阶网络最终学习的Anchor不多,但二阶不需要考虑太多样本不均衡的问题,所以它的准确率比一阶要高;相反,一阶会存在一个严重的正负样本失衡问题。实验结果表明,本文改进的SSD算法在引入Focal Loss函数,加入通道注意力机制、特征融合模块后,在精确度方面,本文模型的最佳检测效果mAP值为81.95 %,相比其他对比算法的最优mAP值高5.4 %;在检测速度方面,本文模型测试的平均时间为0.311 s/张,相比检测速度最优的算法仅相差0.092 s;这说明本文对SSD网络的3个方面进行的改进,在提高精度的同时,并没有增加过多的计算量。

图4 检测结果
3 结 论
针对苹果叶部病理目标小且相似度高的检测困难问题,本文提出了一种基于改进SSD的苹果叶部病理检测方法,首先,将浅层细节与高层语义相融合;其次,构建了通道注意力机制;最后,用Focal Loss函数替换原有的损失函数,提高模型精度。实验结果表明:与其他算法比较,本文改进的SSD算法的检测精度得到明显的提高,mAP达到81.95 %,速度损耗极小。下一步将继续研究特征融合和注意力机制,在尽可能不增加计算量的情况下,提升苹果叶部病理的检测精度。
