基于Q学习模型的无信号交叉口离散车队控制*
2022-10-11钱立军陈欣宇
钱立军,陈 晨,陈 健,陈欣宇,熊 驰
(1.合肥工业大学汽车与交通工程学院,合肥230009;2.南昌理工学院机电工程学院,南昌330044)
前言
当前,各国主要大型城市已建立为自动驾驶服务的高智能化基础设施,并开展了车辆位置实时采集、低时延通信等功能测试。自动驾驶汽车为主体的无信号灯交叉口自动管理策略已成为一个研究热点。
离散的分布式控制是一类有效的车辆控制策略,能分摊控制器的计算负荷。此时,各车拥有单独的控制器,能够识别相邻车的运动并协商通行权。为了降低控制算法的复杂度,可根据不同的行驶任务对交叉口的物理空间进行划分。一般地,车辆在无信号灯交叉口的任务被分解为:状态观察、到达时间优化和轨迹跟踪控制。由于离散化程度越高的分布式方法拥有更好的实时性,则将最小控制单元转化为车队可以有效减少控制对象的数量。
在提升交通性能方面,车队已被证明具有足够的应用潜力,并在高速场景中得到验证。但是,大部分拥堵和事故发生于交通瓶颈处,在非高速场景验证车队的优势也十分必要。一方面,运动趋势相同的车辆在进行组队时,可以减少通信开销。另一方面,在自适应巡航等自组织策略中,适当规模的车队将会使道路通行能力得到成倍提升。此外,车队可使信号灯交叉口的交通性能指标得到优化。
然而,固定规模的车队无法适应不同密度的车流环境。考虑到城市场景中车流量的不确定性,无信号灯交叉口环境下需要更为灵活的组队策略。另外,受限于基础设施的范围和带宽,队形调整的时间和空间并不充裕。因此,研究快捷且智能的队形选择系统来应对复杂的城市交通环境有一定必要性。
近年来,强化学习(reinforcement learning,RL)因其适应性强的特点在交通领域得到深入研究。除了调控信号灯配时之外,RL也逐渐被应用于车辆的视觉学习、转向控制、运动规划等方面。考虑到车辆的动力学特性具有马尔科夫性,可使用无模型的RL方法来求解部分可观测的马尔科夫决策过程。但是,信号灯周期仍然是当前智能体学习过程中不可缺失的参数之一,而RL在无信号灯交叉口的研究并不充分。
为此,本文在基于Q学习的组队决策过程中结合固定时距跟车模型,提出一种基于多车队协同规划的交通流离散策略,设计了包含车队选型与车辆轨迹规划的计算框架。并且,结合了基于车队的交通流模型和多车队协同策略,定义了一个车队通行时间的安全约束。
其次,考虑到车队组合中的状态变量有限,选择高效的Q学习方法进行建模,设计奖励函数的同时考虑了通行效率、行车延误和燃油经济性等指标。并且,根据交叉口功能区间定义了初始状态和动作空间,用于确定车队组合状态。
最后,在建立多车队协同最优控制问题时,设计了一个预防追尾碰撞的安全约束。基于高斯伪谱法对合流区内的车队轨迹进行预求解。通过仿真试验,分析了所提策略有效性和车队协同的优势。
1 问题描述与建模
在智能交通环境下,道路专用短程通信技术(dedicated short range communication,DSRC)覆盖范围内的交叉口路网可被划分为缓冲区、核心区和自由驾驶区。本文聚焦于孤立交叉口,根据文献[14]选择一个典型的单车道十字路口为研究场景。交叉口中的观察区、协同区和合流区分别对应于路网中的功能区间,如图1所示。、和分别表示观察区、协同区和合流区的长度尺寸,为车道宽度。

图1 交叉口功能区间示意图
1.1 交通流离散控制框架
在以车队为通行单元的要求下,以任意车辆为例来说明其组合分配、队形排列和通过路口的过程。其中,以交叉口中心点为原点,车道上第辆车的位置记为x。该车辆驶过交叉口过程中须经历以下4个步骤。
步骤1:位置观察阶段。首先,车辆位于观察区以外,X表示所有在观察区内车辆位置的集合。当该车进入观察区后(x≤++),其位置、速度和加速度等信息被路侧单元所识别。识别到的车辆会被添加进集合中,即X=X∪x。
步骤2:组合分配阶段。定义同时间段内协同通过交叉口的车队集合为一个组合。在协同区内,将采用Q学习方法,于X中选择最优的车队规模。当有车辆到达协同区时(x=+),建立Q学习的可用状态空间。基于所建立的奖励函数和约束条件,选择当前情况下的最优组合状态=(,,,)。
步骤3:车队排列阶段。此步骤同样发生在协同区内。根据得到的最优车队规模,各车道上的车辆将受到以下控制:(1)各车道上位置最靠前的车辆被定义为领航车,其他车辆为跟随车,且所有的领航车将同时到达合流区,即x()=;(2)跟随车将在时刻之前,与其领航车排列成标准车队。被选中的车辆也将从X中被剔除。
步骤4:轨迹跟踪阶段。文献[15]表明,可通过寻找离线的运动方案来提高协同运动的实时性。基于此,在时刻之后,所有的车队将在合流区内跟踪事先储存的安全轨迹,直至其通过交叉口。此交通流离散控制框架如图2所示。

图2 离散控制框架流程图
经过上述步骤,各车道上连续的交通流被拆分为多个小规模车队,并在不同时间段内受到分布式控制。
1.2 车队离散模型
对于车道上规模为n∈Ν的车队,其领航车的运动学模型为

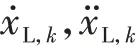


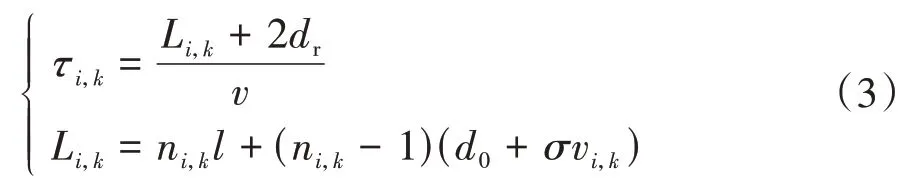
式中:L为车队总长度;v为车队通过交叉口的平均速度。虚拟车队如图3所示,图中蓝色箭头形象描述虚拟车队的构造。当多个车队形成的组合进入交叉口时,有冲突隐患的车队可以被视为虚拟队列,该虚拟车队被定义为一个组合。假设各车队在交叉口处的平均速度均为常数,则此组合的交叉口占用时间为
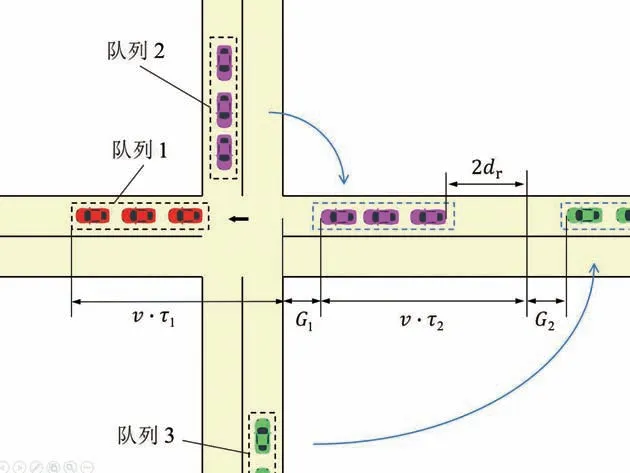
图3 虚拟车队与间隙

式中:表示此组合的时间窗口;表示在该组合中包含的车队数目;τ为此组合中第个车队在交叉口的占有时间;G表示组合中两个车队之间的排队间隙与交叉口尺寸的差值,表示这些差值的总和。基于此,交叉口的瞬时吞吐量(辆/h)为

式中:表示该组合中的车辆总数;n表示第个车队的规模。以为自变量对求偏导,可得
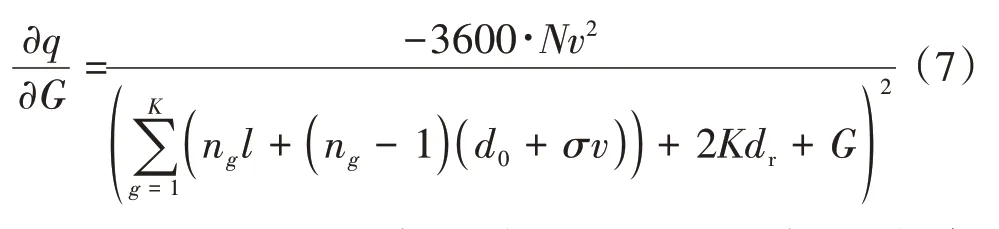
由于式(7)恒为负,可知减少虚拟间隙是提高瞬时吞吐量的有效途径。并且,图3和式(7)展示了以下规律:对任何控制策略,=0时,控制效果与虚拟队列的最优效果相当;>0时,过大的车队间隙会增大交叉口的占用时间;当<0时,将优于虚拟队列的控制效果。因此,在选择组合形式时,定义一个强制性约束:

2 车队组合分配
根据步骤2所定义,在协同区内的车辆将根据集合X来选择最优的组合形式。由此,无信号灯交叉口的车队协同通行问题被转化为车队间的组合问题。由于在通信范围限制下车队组合形式有限,故选择Q学习算法对车队组合情况进行寻优。
在协同区中,转化后的强化学习问题为一个无模型的Markov决策过程。在每个时刻,一个动作a∈将有的概率使环境状态s∈转变为新的状态s。在状态s下的动作a将获得一个价值r∈。Q学习方法中的价值迭代公式为
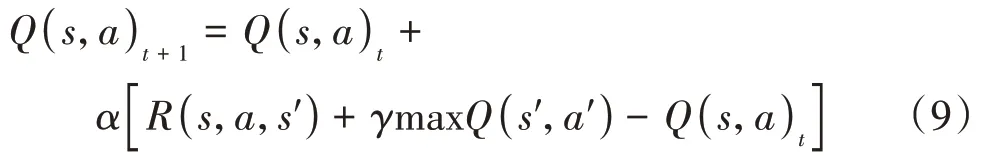
式中:∈(0,1)为学习率;∈(0,1)为系统折扣因子。
2.1 状态向量设计
对于车队而言,车速、跟车间距、规模等是影响其运动状态的重要参数。在尺寸受限的场景中,车队规模的影响高于其他参数。尤其在失去信号灯控制的平面交叉口,过大的车队规模将延误其他车辆。因此,将状态空间定义为车队规模的组合情况。对于四向单车道交叉口而言,状态向量由4个元素组成=(,,,)∈S,其中n表示在此组合中第车道上的车队规模。
基于此,在所研究的固定场景中,状态量的总数为

式中表示单一车队中的车辆数目上限。
2.2 动作空间设计
由于状态向量是车队的组合类型,所以智能体的动作是筛选一个合适的车队组合。为了满足状态向量之间的切换条件,定义动作为
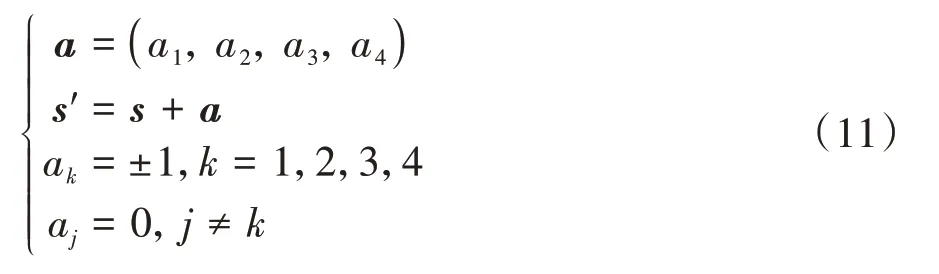
式中a表示该组合中位于车道上车队的规模增减,且每次变动的车辆数目为一辆。并且,状态转移过程中必须满足边界约束:

然而,在实际计算中并不是所有动作都是可行的。因此,可使'满足式(8)且'⊆X时的定义为一个有效动作。
2.3 奖励函数设计
通行效率和行车延误等参数是最能反映控制策略有效性的指标。为了提高交叉口流量上限并降低延误,在设计奖励函数时同时考虑了~4个指标。
表示各状态下在合流区内呈现的瞬时效率。
表示车辆平均等待时间:

式中ε为各车队的行车延误。
为各车队的行程时间标准差(standard deviation of travel time,SDTT):
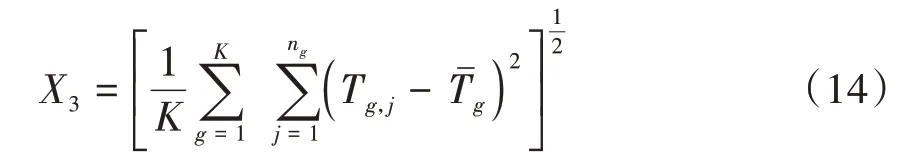

为合流区内的平均燃油消耗(L/100 km):

式中为车辆的平均瞬时油耗,L/h。
明确评价指标之后,状态下的奖励值定义为
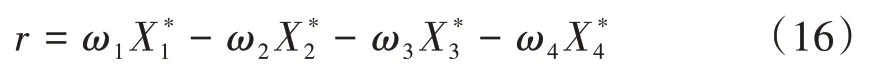
式中:X为对各指标的样本标准化处理后的值;、、和表示权重系数,且∑||=1;负号表示该指标值呈负相关关系。
对于大流量的城市交叉口而言,减少拥堵是首要目标。因此,瞬时效率的重要程度要远高于其他指标。由于权重赋值过程具有强烈的主观性,采用G1法对评价指标进行重要度排序,并确定权重系数的具体数值。
2.4 初始状态设计
在确定可行动作空间和奖励值之后,需对状态的寻优过程设计一个初始值。类似于二维路径规划的过程,从不同初始点出发找到的运动路径也是不同的。在观察区的尾部定义一个尺寸为的子区间,如图4所示。该子区间只用于确定初始状态,对其他过程不产生干扰。
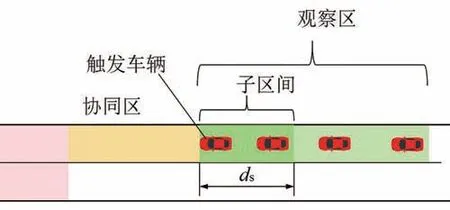
图4 子区间示意图
此时,智能体初始状态被定义为

式中:n为车道上被选入初始状态的车辆数目;(⋅)表 示 在 时 刻中,满 足x()∈[+,++]的x的个数。当有车辆到达协同区的时刻,将触发和n的计算流程。并且,首个到达协同区的车辆被定义为触发车辆。例如,图4所示车道上的n=2。因此,由式(11)可知Q学习模型中状态的变化过程为
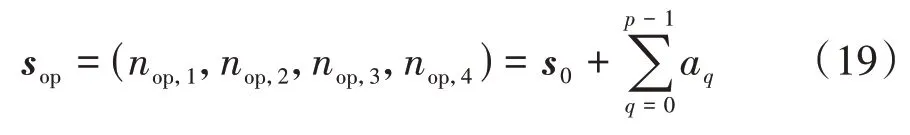
式中:为最优状态;为最优状态下位于第车道上的车队规模;表示学习步数;表示Q学习迭代次数。
3 车队轨迹规划
3.1 协同区内轨迹规划
根据式(19)确定最优状态后,被选中的车辆将在各车道内协同组队,其过程分两个阶段。
阶段1:车道上的前辆车将组合成一个车队。第1辆车为领航车,位置记为x。其他车辆根据式(2)所示的跟车策略,调整与领航车之间的相对位置。
阶段2:不同车道的领航车也将调整其相对位置。为了适应合流区内的预存轨迹,对领航车的轨迹进行规划时必须满足下列条件:
对于∀∈S,∃>0,有x()=成立,且≠0。为领航车到达合流区的时刻。为提升交通效率,将协同过程定义为一个时间最优的控制问题,构建的Bolza问题如下:

式中为触发车辆到达协同区的时刻。并且,为了交叉口占用时间不重叠,须施加时距约束:

式中表示组合中领航车到合流区的时刻。此外,当领航车执行其最优轨迹时,同车道内的跟随车将根据式(2)进行跟车运动。
3.2 合流区内轨迹规划
到达合流区的任意组合将受到全局的多车队协同控制,这也是Q学习的建模基础。考虑所有车辆的安全约束,同样以时间窗口为最优化目标,构建最优控制问题为

式中:-的负号表示车辆驶离;为所有车辆离开合流区的时刻;安全约束的集合=[,,…,,…,d];且d表示不同车队中车辆之间的距离。具体地,每辆车都将与其他车队的所有车辆进行约束,即
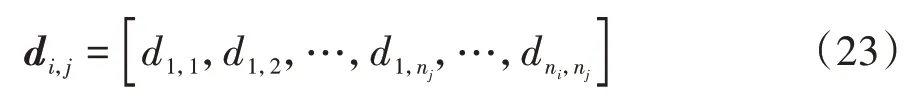
式中n和n分别为车队和车队的规模。使用高斯伪谱法对式(20)和式(22)所示的最优控制问题进行转化,并选择snopt求解器进行计算。
4 仿真结果与分析
设计了两种工况,对基于Q模型的组队过程进行描述,验证所提策略的有效性。在不同车流量工况下,与非组队方法及传统虚拟队列方法进行对比,验证所提方法的优势。
设计式(16)中奖励权重时,前后指标间的比值分别选为1.8、1.8和1.4,由此确定的权重系数以及其他Q模型参数如表1所示。

表1 Q模型仿真参数
4.1 组队过程分析
选择主支路型、流量均衡型交叉口为研究场景,在Matlab/Vissim仿真平台中定义各车道流量,仿真所需的道路及车辆参数如表2所示。
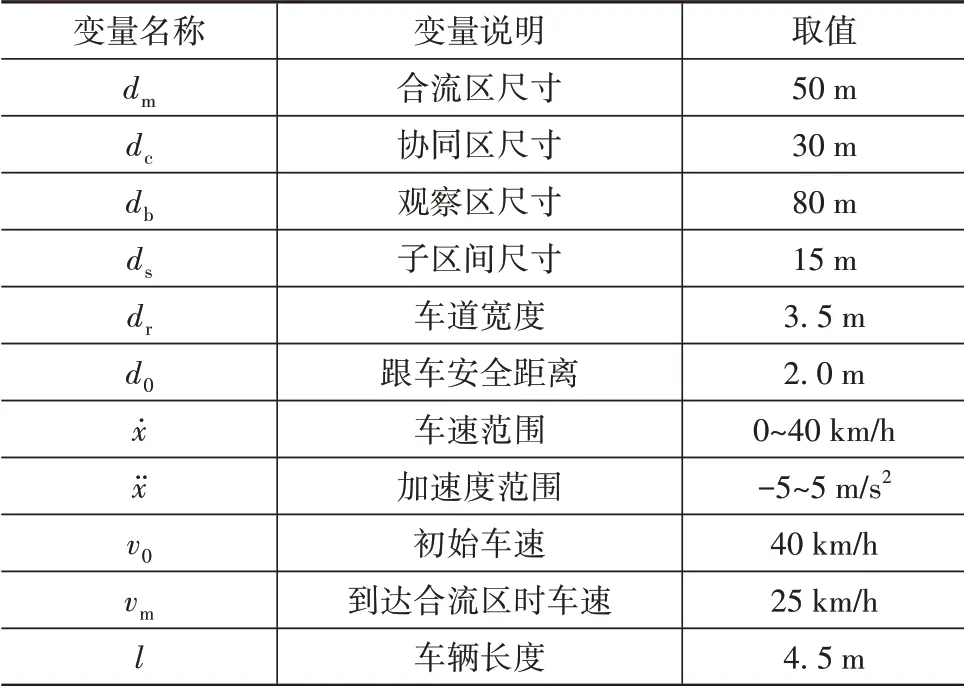
表2 道路及车辆参数
工况1:主支路型交叉口两个方向上的车流量差距显著,设计各车道上的流量为=1600辆/h,=700辆/h,=1800辆/h,=600辆/h。为了描述车辆排队的过程,以前两个组合的运动轨迹举例说明。
如图5所示,前两个组合包含14辆车,仿真前10 s内所有车辆均在协同区外。在第10.81 s时,第1辆车到达协同区,根据车辆位置确定组合1的状态向量为=(2,2,2,2)。随后,组合1中的领航车同时在19.84 s到达合流区,记为。
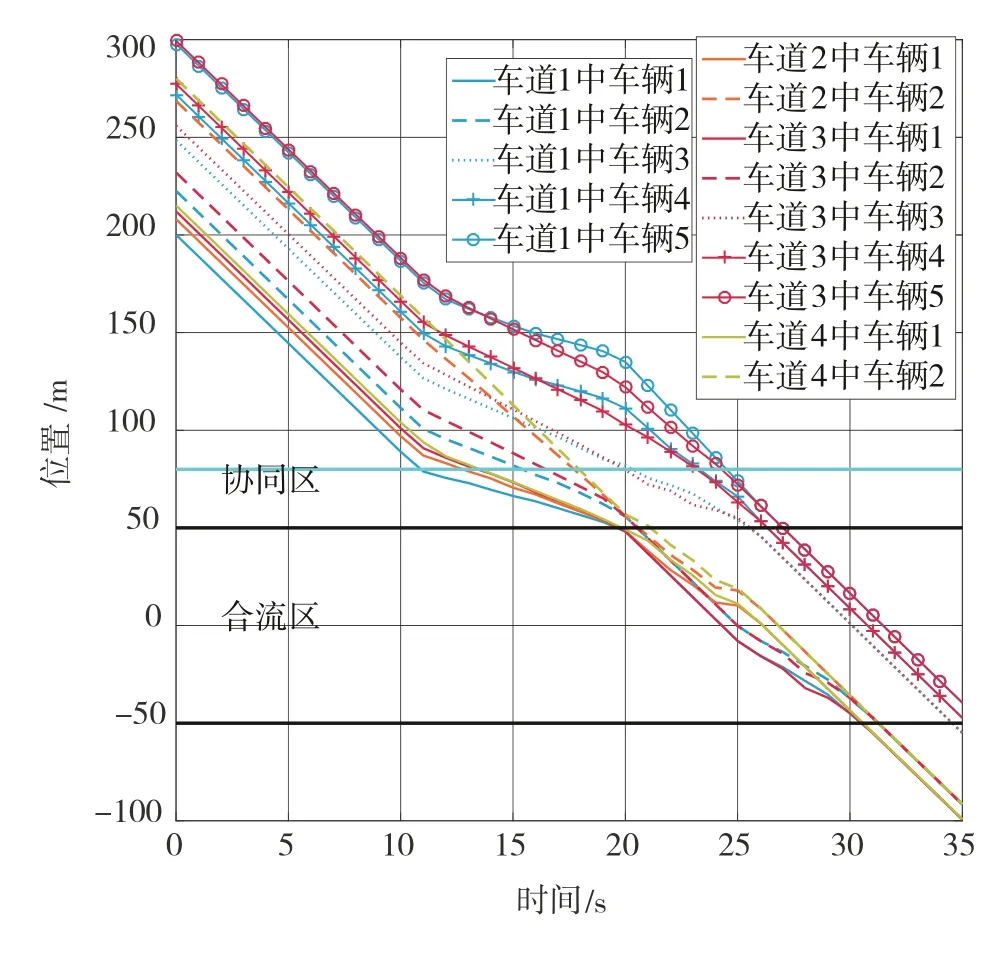
图5 工况1中的车辆轨迹
另一方面,组合1以外的车辆在第19.75 s到达协同区,并同时确定组合2的状态向量为=(3,0,3,0)。组合2中的车辆在经过位置调整后于第25.64 s到达合流区,记为。
为检验安全性,给出同车道内相邻车辆间的距离,如图6所示。车流密度的差异导致各车道上的初始车距相差明显。当组合1中的车辆于10.81 s时开始组队,其跟车距离逐渐减小。在组合2形成后,受式(21)的时间间隔约束,相同车道上不同组合的车辆间距开始明显增大,如车道1与车道3中的。并且,车队进入合流区后将保持车距队形,即在运动的全过程中车距均大于,说明没有追尾事故发生。

图6 工况1中的车间距
工况2:对于流量均衡型交叉口,各支路上的车流密度较接近,设计各车道上的流量为=1400辆/h,=1600辆/h,=1500辆/h,=1400辆/h。
此时,前两个组合中共包含24辆车。由于车流密度相近,每个车道上均有6辆车,其轨迹如图7所示。图中,车道2~4上的轨迹线型与车道1线型一致,且颜色属性与图5相同。不同于工况1,由于车辆分布均匀且密集,所分配的状态向量为==(3,3,3,3)。并 且,两 个 组 合 内 的 车 分 别 于 第11.08 s和第19.17 s开始组队,并于=18.60 s和=26.31 s到达合流区。
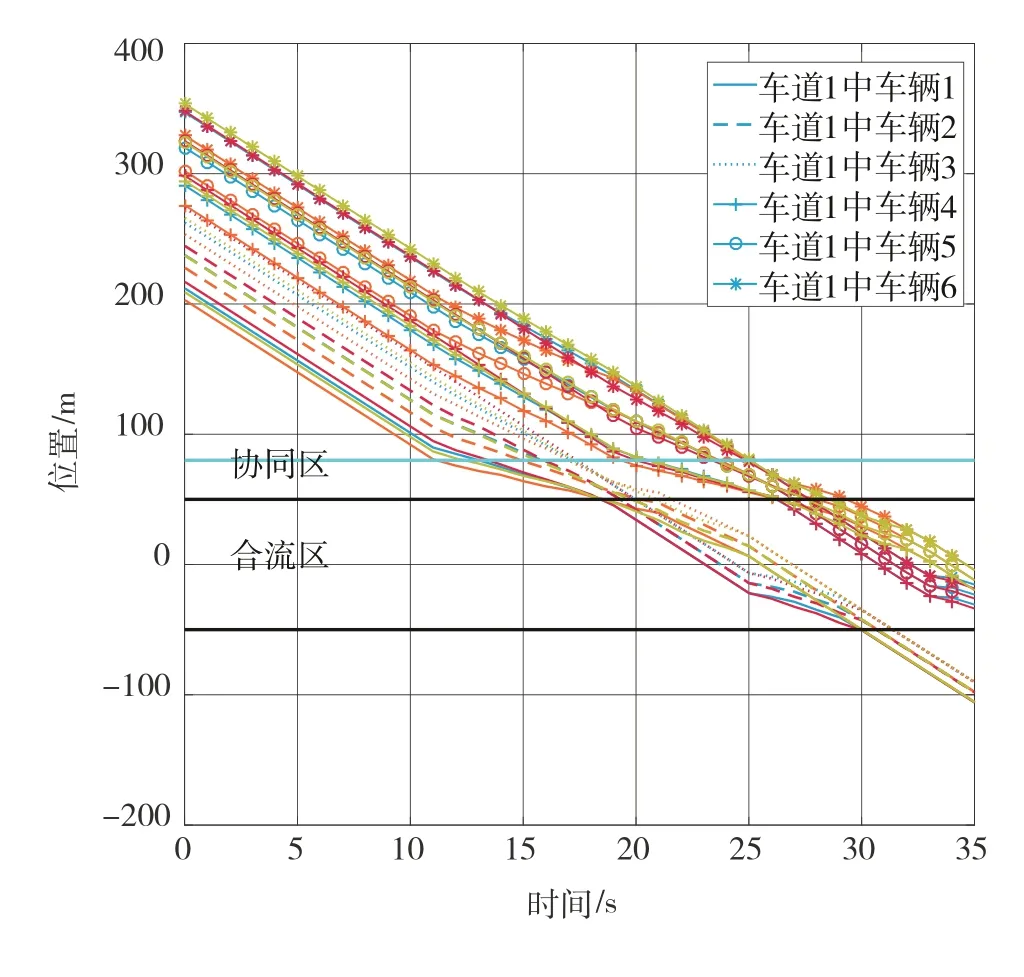
图7 工况2中的车辆轨迹
工况2中的车距变化曲线如图8所示,可以观察到与工况1类似的分组动作。并且,所有车辆之间均保持着足够安全的距离。

图8 工况2中的车间距
根据上述两个工况的仿真结果,可发现两个现象:(1)相比于车辆较为稀疏的情况,大流量工况更利于队列的形成,即当状态向量集包含足够多的元素时,所提方法趋向于找到价值更高的解,验证了Q学习模型的有效性;(2)在两种工况下,都能满足->的条件,说明前后组合之间存在式(21)中定义的空档期。由此可认为上述工况中的车流量均未达到所提方法的饱和流量。因此,为了验证组队方法在大流量工况下的优势,设计如下对比试验。
4.2 交通性能对比
为了验证车辆组队后的饱和吞吐量,在不同流量工况下进行对比仿真。此时,选择虚拟队列法和非组队的离散控制策略作为对比方法,对奖励函数中的评价指标进行比较。仿真时各车道平均流量为1 200~2 200辆/h,进行5次计算后统计对比结果。
如图9所示,虚拟队列法的饱和吞吐量约为3 200辆/h,由于仿真工况均超出其极限值,故计算结果标准差较小,在图中无法显示。对于非组队方法,其通行能力首先随着到达车辆的增加而增大。当平均流量超过1 800辆/h之后,可知其饱和吞吐量大约为6 250辆/h。因此,1 800辆/h可定义为非组队方法的极限工况。当车流量小于极限工况时,吞吐量的计算值会因各车道上车流密度的随机性产生波动,体现为较大的标准差状态。对于组队方法而言,即使平均流量达到2 200辆/h时其吞吐量约可为8 400辆/h,且未达到饱和状态。
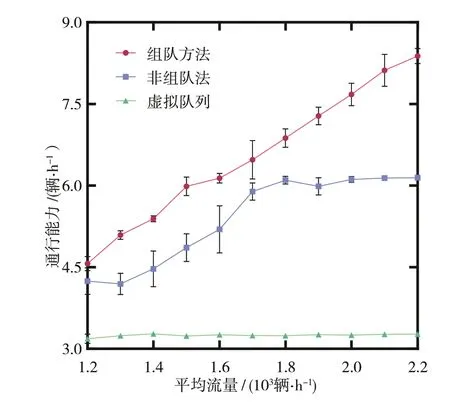
图9 通行能力对比结果
因此,可进一步对极限吞吐量的理论值进行对比。在流量足够大时,组队方法的最优状态向量为=(3,3,3,3)。类似地,非组队方法的最优状态向量为=(1,1,1,1)。此外,由于虚拟队列方法只允许一辆车进入交叉口,则其最优状态向量为=(1,0,0,0)。3种状态下的交叉口占有时间为4.96、2.25和1.10 s。由式(6)可知,其饱和吞吐量的理论值分别为8 710、6 400和3 273辆/h,与仿真结果相对应。因此,组队方式可提升约36.1%的通行能力。
通行能力的差异也表现在行车延误方面。如图10所示,虚拟队列无法处理大流量工况,随着车流密度的增大,行车延误也急剧增大。对于非组队方法,在平均流量低于极限工况时,行车延误变化不大;在突破极限工况后,延误数值急剧增大。对于所提的组队方法而言,由于未达到饱和状态,所以交通流的整体运动没有受到很大影响。并且,相比于非组队的方法,组队后的车辆最多可以降低约65%的延误时间。

图10 行车延误对比结果
SDTT和油耗在奖励函数中的权重远小于上述两个参数,因此其对比结果呈现出不同的特征。如图11所示,非组队方法的SDTT值最小,约为组队方法的1/3。就变化趋势而言,虚拟队列法因其行车延误的增加,SDTT也随着车流量的增大而增大。对于非组队和组队方法而言,得益于任务分解的控制策略,它们的SDTT值在高流量工况中呈下降趋势。

图11 SDTT对比结果
类似的特征同样表现在燃油消耗上,如图12所示。虚拟队列方法的油耗数值呈稳定增长状态。另外两种方法的油耗峰值出现在中等流量工况,此结论已在作者之前的工作中得到证明。

图12 燃油消耗对比结果
对比结果表明,在权重的影响下,尽管组队策略可以提升交叉口吞吐量,但会略微增加交通流的波动和汽车的燃油消耗。
5 结论
本文中提出一种考虑车队的离散控制策略。首先推导出多车队协同轨迹规划的筛选约束,并基于此约束设计了用于车队规模选型的Q学习模型,以通行效率、行车延误等为复合指标设计奖励函数。
其次,在安全性方面,以跟车模型为基础,提出了防追尾的安全约束。通过两种工况的仿真结果表明了车辆组队的有效性,并验证了过程中的安全性。
最后,将所提方法与其他方法进行比较,结果表明组队策略可以提升大约36.1%的交叉口通行能力,且无更大的行车延误。但是,由组队引起的自组织过程将使燃油消耗略微增加。因此,在提升交通效率的基础上,进一步降低车队油耗也值得深入研究。
