多尺度分割和深度学习相结合的倾斜摄影三维影像建筑物震害信息提取*
2022-10-10帅向华荆帅军郑向向
帅向华 荆帅军 郑向向 刘 钦
1) 中国北京 100045 中国地震台网中心
2) 中国郑州 450016 河南省地震局
3) 中国北京 100083 中国自然资源航空物探遥感中心
引言
建筑物震害信息是评估建筑物破坏等级的重要指标,如何准确识别、定量提取建筑物震害信息是目前研究的热点.随着深度卷积神经网络模型的发展及其在图像处理领域的应用深化,该技术在地物识别分类方面也展现出巨大的特征学习表达能力,即通过自动对样本集中的研究对象不断深层次学习,获取地物高层次的抽象特征,掌握不同地物的纹理、形状属性信息,取得了很好的提取效果,弥补了地物特征信息分类提取的不足.国内外学者利用深度学习技术对建筑物震害信息提取开展了较多研究.Vetrivel 等(2018)综合运用卷积神经网络和三维点云数据特征进行建筑物震害损伤区域的检测,精度达到85%;李强(2018)基于2010年海地MS7.0地震光学遥感影像GeoEye-1数据,使用卷积神经网络模型CAFFE (Convolutional Architecture for Fast Feature Embedding)框架提取研究区域中的基本完好建筑物、中等破坏建筑和损毁建筑物,总体分类精度达到90%以上;陈梦和王晓青(2019)利用全卷积神经网络模型提取玉树地震后空间分辨率为0.2 m的玉树县城区航空正射影像的建筑物震害信息,总体分类精度达到82%;周阳等(2019)利用深度卷积神经网络(deep convolutional neural networks,缩写为DCNN)全连接层特征支持的向量机检测2010年海地震后倾斜摄影影像中的建筑物震害损毁区域,正确率高达89%.相较于传统的识别方法,深度卷积神经网络在建筑物震害识别方面具有很大的优势.
受传统遥感影像的限制,许多学者利用正射影像定量地提取建筑物震害信息,如吴剑等(2013)基于像元和面向对象方法提取建筑物震害信息,总体精度分别为76.84%和90.38%;赵妍等(2016)采用多尺度分割和k邻近方法提取遥感影像中建筑物的形状、面积等变化信息,提取精度为79.68%;倾斜摄影技术从多个角度拍摄建筑物的顶面和侧面,能够获取建筑物丰富的纹理信息和细节信息,弥补正射影像的不足(荆帅军等,2019).目前学者基于倾斜影像多采用目视解译或监督分类方法定量地提取建筑物侧面震害信息,例如:Gerke和Kerle(2011) 采用监督分类方法提取航空倾斜影像中单体建筑物外墙、完整屋顶、破坏屋顶等的震害信息,建筑物震害信息提取精度达到63%,总体分类精度达到70%;李胜军(2013)采用面向对象中的模糊分类方法,对倾斜航空影像震后建筑物进行多角度损毁评估,损毁区域分类精度达到70%以上,总体卡帕(Kappa)系数达到80%以上.这些方法虽然成功地提取到了建筑物侧面的震害信息,但是在识别提取时需要结合影像手动进行大量的试验来选取最优特征组合,利用一系列阈值条件提取目标地物,导致目标地物识别分类不准确,影响分类精度和效率.而面向对象多尺度分割算法根据多个分割尺度将不同地物分割到不同的对象中,很好地解决了地物分割不开的问题(冯丽英,2017).结合面向对象多尺度分割和深度卷积神经网络的方法可以有效提高地物分类识别精度.
本文将已获取的倾斜三维影像作为震害识别的数据,采用面向对象多尺度分割与深度卷积神经网络相结合的方法,拟对建筑物屋顶和墙体影像进行震害信息提取,克服分割难、样本少的困难,以解决震害信息提取不完整,识别不准确的问题.
1 倾斜摄影三维影像建筑物震害提取方法
1.1 总体技术流程
倾斜摄影三维影像建筑物震害提取方法将倾斜摄影影像数据作为震害提取的数据基础,提取的主要步骤为:① 从倾斜影像数据获取建筑物顶面和侧面影像;② 目视解译建筑物顶面和侧面的震害信息;③ 采用卷积神经网络模型训练样本;④ 对建筑物顶面和侧面的影像进行多尺度分割;⑤ 利用训练成功的卷积神经网络模型对分割后的影像进行识别和提取;⑥ 进行精度对比分析.
1.2 面向对象多尺度分割方法
面向对象多尺度分割方法将像元按照类内同质性最大、类间异质性最大的原则合并到对应的地物对象中,对不同地物进行分割.基本原理是:从单个像素开始,以选取的形状因子、光谱因子和分割尺度为准则,分别与其邻近像元进行合并计算,从而降低对象的异质性;当一轮合并结束后,对上一轮生成的对象,在给定分割尺度下继续分别与其相邻的对象进行合并计算;以如此方式持续进行,直到在用户指定的尺度上不能再进行任何对象的合并为止,最终得到不同尺度下的分割结果.这种异质性是由两个对象的光谱和形状差异所决定,异质性度量准则的计算公式为

式中:w1为权重值,0≤w1≤1;x为光谱异质性;y为形状异质性.
本文使用面向对象多尺度的分割方法,其实质是选择多个尺度阈值对遥感影像上各个目标地物分别进行分割,从而获得目标地物的最佳分割效果,确保所提取的地物分割效果,尤其是对大小、颜色相同的建筑物和道路分类分割有很好的效果.
1.3 卷积神经网络模型
手动选取建筑物震害特征依赖于解译员的专业经验和知识,而震害特征又相对复杂,深度学习强有力的学习能力和深层次的网络结构在地物特征识别方面展现出了巨大的优势.深度学习网络中,卷积神经网络模型凭借其自动识别特征和学习特征的能力,在低层次特征到高层次抽象特征的学习过程中展现出了非常好的性能,仅使用原始影像利用波段、空间和形状等信息即可提取建筑物震害特征,因此在图像特征提取方面具有很大的优势(高扬,2018).本文应用深度卷积神经网络模型进行建筑物震害的识别与分类.卷积神经网络模型一般由卷积层、池化层、全连接层和分类器组成(Lecunet al,1998).
1) 卷积层.作为原始图像与卷积核之间的线性运算,卷积层一般是将多个卷积层放在一起进行重复卷积操作,得到线性结果,然后通过非线性运算得到特征图像,再将其作为下一层的输入特征图像,计算公式如下(史路路,2018):

式中,*为卷积运算,f是非线性函数,k为一定大小的滤波器,g为附加偏差.式(2)表示当前第L个卷积层中第n个特征图层,即L-1层的卷积特征输出后,经非线性函数运算获得.
2) 池化层.该层的目的是压缩输入图的特征数,以去除不重要的参量、噪声和数据波动,提升特征提取精度,也就是下采样(范荣双等,2019).计算公式为

式中,down表示下采样,β为乘子偏差,g为附加偏差,L为卷积层,n为特征层.
3) 全连接层.综合前面层次训练学习到的不同特征并投影到标记样本中去,即将特征分类到不同的样本中.
4) 分类器.应用分类器进行目标地物分类提取.
随着深度学习的兴起以及相关模型结构的完善,深度卷积神经网络在目标特征自动识别、学习和分类等方面的巨大的优势,被应用于诸如遥感地物分类、人脸识别等多个领域.VGGNet (visual geometry group networks)是卷积网络模型中分类精度较好的模型,按网络结构层数被分为16和19两种结构(Sunet al,2019).本文使用VGGNet-16结构模型进行样本集的特征识别学习(图1).该网络结构输入默认大小为224×224×3的二维图像;16层网络结构中有13层是卷积层,卷积层的卷积核大小为3×3,两个或三个卷积层作为一组;多次重复卷积后将结果输入到池化层进行处理,该层采用最大池化方法处理以减少图像大小,并对特征进行精简;最后用三个全连接层进行特征分类(Huet al,2016;Yuan,2016).
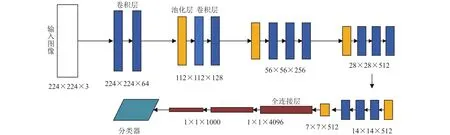
图1 VGGNet-16网络模型结构,模型下方数字为图像大小(宽×高×深)Fig.1 VGGNet-16 structural framework where the number under the structural is the image size (width×high×deep)
2 震例分析
2.1 研究区域基本概况
据中国地震台网测定,2017年8月8日21时19分,四川省阿坝藏族羌族自治州九寨沟县(33.20°N,103.82°E)发生MS7.0地震,震源深度为 20 km,造成 29人死亡,1人失踪,543人受伤.笔者在震后采集了重点区域的倾斜摄影数据.选取位于四川省九寨沟县漳扎镇的千古情风景区和漳扎镇小学及其周边作为研究区域.这两个区域位于地震烈度Ⅷ度区,倾斜摄影影像面积约为0.3 km2.
2.2 建筑物震害信息
千古情风景区和漳扎镇小学及其周边倾斜摄影三维建筑物顶面、正面、后面、左面和右面的影像如图2和图3所示,本文将分别对千古情和漳扎镇小学建筑物的顶面和侧面影像进行目视解译.

图2 千古情风景区的三维模型影像Fig.2 3D model images of Qianguqing scenic spot

图3 漳扎镇小学的三维模型影像Fig.3 3D model images of Zhangzha primary school
以漳扎镇小学的建筑物为例,倾斜摄影影像(图4)清晰地展现了建筑物的侧面震害信息.从图4可以看出该建筑物为三层,承重墙体的墙面、窗户口处、窗户间有多处大面积的墙皮脱落和水平裂缝,建筑物屋顶基本完好.

图4 漳扎镇小学的典型建筑物震害表现Fig.4 Seismic damage of typical building in Zhangzha primary school
2.3 训练样本的选取与构建
根据目视解译结果,选取包含各种震害信息的影像作为样本区,样片大小为100×100 像素,将样本区分为三类:完好建筑物面、破坏建筑物面和其它地物及背景.完好建筑物面的选取以样片中建筑物面完好为原则,破坏建筑物面的选取以样片内建筑物面有破坏信息为原则.同时由于使用的数据是无人机航拍的倾斜影像,针对样本量少的问题,从影像中建筑物的五个面选取样本,通过多次试验确定最佳的样片像素尺寸以增加样本量,通过多次迭代运算确定最优训练结果.最终确定的样本大小为100×100 像素,迭代次数为10 000.训练样本集如表1所示.

表1 分类样本集的选取Table 1 Selection of classification sample sets
训练样本选好后,使用VGGNet-16网络模型进行样本特征训练.VGGNet-16模型主要研究卷积神经网络层次与提取精度之间的关系,多次连续重复使用小尺度卷积层和池化层进行操作处理,并使用三个不同大小的全连接层进行特征分类,从而形成了16层的网络模型,获取了更加抽象的高层次样本特征,减少了参数量,大大提高了提取精度.
2.4 影像多尺度分割
为确保分割质量精确,采用人机交互方式,设置不同的最大分割尺度、尺度个数和尺度间隔进行多次分割试验,目视观察分割对象效果,以获取最佳的分割效果.选择最大分割尺度为80的三个尺度,尺度间隔为0.6,分割尺度分别为80,48,29.以千古情风景区正面影像为例,当分割尺度为80时,建筑物面与地物较好地分割,建筑物面分割得较为完整,不同建筑物面之间被较好地分割开;当分割尺度为48时,建筑物面与地物能够分割,但是建筑物面分割破碎;当分割尺度为29时,建筑物面被分割得很破碎,建筑物面与地物不能被分割开.对于以80为主体分割尺度的影像,在该分割尺度下不能较好分割的区域,将其转换成中尺度或者小尺度分割,分割结果如图5所示.
图5 千古情风景区正面的影像分割结果Fig.5 Segmentation result of the front of buildings of Qianguqing sceic spot
2.5 震害提取结果
影像分割完成后,使用2.3节训练的网络模型,分别对灾区建筑物顶面和侧面的震害信息进行识别、分类完成后,得到三个大致分类结果;为提高建筑物震害的提取精度,分类后通过调节差异度参数来获取最佳提取结果.差异度是将每个像素属于该类别的概率归一化至 [ 0,255 ]区间上,它以模型中该类别的像元概率为基础,将其与每个像元属于该类别概率进行差异程度比较,以此来度量两种像元的相似程度.差异度越小,两种像元的相似度越高,属于该类别的像元概率就越高,则地物的提取精度较高;差异度越大,两种像元的相似度越低,属于该类别的像元概率就越低,则地物的提取精度较低.公式如下:

式中:C为差异度,Pi,j为第i个像素属于j类别的概率,Pmax为概率的最大值,Pmin表示概率的最小值.
选取差异度时,以5为间隔,设置51个差异度值进行试验,分别对三个类别进行精细提取.试验结果表明,当完好建筑物面的差异度设置为165,破坏建筑物面的差异度设置为90,其它地物及背景的差异度设置为200时,得到最优提取结果.千古情风景区和漳扎镇小学的建筑物顶面和侧面的震害提取结果如图6所示.

图6 千古情风景区(a)和漳扎镇小学(b)的建筑物提取结果红色代表完好建筑物面,蓝色代表破坏建筑物面,黑色代表其它地物及背景Fig.6 Extraction results of seismic damage of buildings in Qianguqing scenic spot (a)and Zhangzha primary school (b)Red represents the intact building surface,blue represents the damaged building surface and black represents other ground objects and backgrounds
2.6 提取结果精度评估
本文采用混淆矩阵来评估提取结果的精度,混淆矩阵是分类方法中真实值和预测值以矩阵形式记录的数据.将深度学习提取结果作为预测值,目视解译提取的震害结果作为真实值,建立二者的混淆矩阵.
1) 千古情风景区的提取精度分析.深度学习和目视解译提取结果的混淆矩阵如表2所示.可见,破坏建筑物面、完好建筑物面和其它地物及背景的分类精度分别为65.5%,70.3%和92.8%,总体分类精度(正确分类的像元数与总体像元数之比)为82.1%,卡帕系数为68.7%.

表2 千古情风景区的建筑物深度学习和目视解译提取结果的混淆矩阵Table 2 Confusion matrix of deep learning and artificial visual extraction results of the buildings in Qianguqing scenic spot
2) 漳扎镇小学及其周边的提取精度分析.深度学习和目视解译提取结果的混淆矩阵如表3所示,可见,破坏建筑物面、完好建筑物面和其它地物及背景的分类精度分别为71.1%,77.6%和87.2%,总体分类精度为84.1%,卡帕系数为64.9%.

表3 漳扎镇小学及其周边的深度学习和人工目视解译提取结果混淆矩阵Table 3 Confusion matrix of deep learning and manual visual extraction results of the buildings in Zhangzha primary school and it’s vicinity
3 讨论与结论
通过研究多尺度分割方法和卷积神经网络模型各自的优势,采用两者相结合的方法对倾斜影像中建筑物顶面和侧面的震害信息进行提取.利用多尺度分割方法获取最佳的分割影像,然后运用卷积神经网络模型VGGNet-16对分割后影像进行识别和分类,并通过建立混淆矩阵对分类结果进行评估.结果显示,总体分类精度达到80%以上,卡帕系数达到60%以上,表明结果具有较强的一致性.试验表明,倾斜摄影技术在提取具有大面积墙皮脱落、明显裂缝等建筑物侧面震害信息方面具有很大优势,弥补了传统遥感只能提取建筑物顶面震害信息的局限.同时通过对分类结果进行定量提取和精度评估,有利于改进深度学习分类模型,进一步提高分类精度和效率.
需要说明的是,本文使用的倾斜影像是高维度、多层级的三维模型,这使得利用本文的方法基于倾斜影像提取建筑物侧面震害信息增加了难度:第一,当建筑物面的类型和颜色相同时,易将完好建筑物面误分为有破坏信息的建筑物面,因此仍然需要对深度学习模型进行改进来提高分类模型精度;第二,当建筑物间距较小、屋檐遮挡等造成倾斜摄影拍摄不完整时,无法完整清晰地获取某些建筑物的侧面数据,所以利用倾斜影像获取建筑物完整的侧面信息需要尝试新的方法如三维点云数据分割等.
