一种融合用户相似性与评分距离的个性化推荐算法
2022-10-10苏湛,黄忠,艾均
苏 湛,黄 忠,艾 均
(上海理工大学光电信息与计算机工程学院,上海 200093)
1 引言(Introduction)
随着互联网技术的广泛应用,在网上“遨游”的人们时时刻刻都在生产出大量的数据,人类从信息匮乏变成信息过载。海量数据使消费者很难找到自己最感兴趣的信息,而互联网上的商家也需要一种技术来帮助他们找到真正对产品感兴趣的潜在消费者。尤其是当下新型冠状病毒肺炎疫情促使人们越发依赖互联网进行消费、学习和交流,从而进一步加剧了这一问题。
能够解决这一问题的个性化推荐算法具有重要的应用价值,设计恰当的模型去理解用户偏好,预测用户行为,对人工智能和机器学习理论的进一步发展也具有重要的推动作用,因此个性化推荐算法在相关领域得到了广泛的研究。亚马逊、Facebook、京东、淘宝等公司都拥有自己的个性化推荐系统和算法,此外包括电影、音乐推荐等细分领域对个性化推荐算法的应用也同样广泛。
本文通过研究用户间共同评分相似性对潜在用户进行筛选,使用筛选之后的邻居集合预测目标的评分,然后按照预测结果生成推荐列表,在有效的数据集上验证算法的有效性。
2 相关工作(Related work)
2.1 推荐系统分类和问题
根据领域内的一般理解,个性化推荐算法可以分为四种主要类型:基于内容的推荐算法、协同过滤推荐算法、基于知识的推荐算法和混合推荐算法。
第一类,基于内容(Content-based)的个性化推荐算法用物品的描述性属性来进行有针对性的推荐。“内容”指的就是对物品特征的描述,表示内容特征的标签就是这一类推荐算法的一种常见计算形式。例如,当一个用户对“史诗”类型电影常常给予高评价时,带有“史诗”标签的新电影就可以推荐给该用户。算法会基于用户历史数据判断出用户对这一内容标签的偏好概率,并计算任意一个带有该标签的电影被该用户喜欢或不喜欢的可能性,例如通过比较两个偏好的朴素贝叶斯概率大小就是一种预测用户对该电影偏好的常见方法。
第二类,基于记忆(Memory-based)的协同过滤(Collaborative Filtering,CF)算法和基于模型(Model-based)的协同过滤算法是协同过滤算法的两个子类型。基于记忆的协同过滤算法,无论是基于物品还是基于用户,都基于相似的个体表现出相似的评分模式行为,相似的对象更容易获得相似的评分这样的假设。例如,要预测一个目标用户对某个电影的评分,如果能够找到一组和这个用户具有高度相似历史评分的用户群体(通常被称为邻居用户),因为这些邻居用户历史上的评分和目标用户高度相似,那么邻居用户对目标物品的评分可以很自然地作为目标用户对该物品评分的参考数据。这类个性化推荐算法在预测中综合考虑用户评分均值差异和用户之间相关性差异来得到最终的预测结果。
另一方面,基于模型的协同过滤个性化推荐算法包括聚类模型、距离模型、最大熵模型、矩阵分解模型和相似性网络模型等多种类型的设计方案。基于模型的协同过滤算法同样需要预测目标用户和社区用户的评分数据,但这类推荐算法通常先构造描述推荐系统的某种模型,并训练获得这些模型的必要参数,然后基于这些训练获得的参数来对未知评分进行预测。矩阵分解模型本质上拟合平均矩阵中高度相关的那些用户评分,通过分解来对评分矩阵降维,抽象出用户特征矩阵和物品特征矩阵。在这一过程中,那个不易被拟合的评分被适当忽略。
第三类,基于知识的个性化推荐算法有两种常见形式,包括基于约束条件的推荐算法和基于案例的推荐算法。在实际生活中,很多商品的消费行为常常是频度很低的,如房屋、汽车、珠宝等,肯定不能像书籍、电影或外卖一样被用户高频度消费和评价。一方面,因为这些物品的价格更高;另一方面,一个用户的评价对另一个用户的参考价值也相对更低。因此,基于知识的个性化推荐系统需要将已知的物品数据基于专家知识进行建模和抽象,抽象结果数值作为知识系统存储,并在用户提出自己需求的时候,通过约束条件叠加进行筛选和推荐,或者基于案例筛选并通过参数条件的替换进行推荐。
第四类,混合推荐算法则综合上述多种不同类型的推荐算法,力求获得更好的推荐性能,或者满足不同条件下的推荐需求,其混合方案包括加权型、切换型、交叉型、特征组合型、瀑布型、特征增强型和元级型等混合推荐策略。
尽管针对推荐系统已经涌现了很多研究并应用比较广泛,但仍有一些挑战吸引着相关领域的科学家,例如冷启动问题、数据稀疏性问题、算法的可扩展性、预测的准确性、运行时间和推荐多样性。
冷启动指的是加入系统的新用户和新物品在没有评价数据等关键信息条件下的推荐问题;数据稀疏性则是指用户或物品评价评分数据量不足造成的推荐不准确或不适当问题;算法的可扩展性既包括算法训练、预测时间复杂度,也包括算法学习之后需要存储的模型相关数据大小代表的空间复杂度;预测的准确性则可以从推荐算法对评分的预测误差数值大小、对用户喜欢和不喜欢两种偏好评价的预测准确性或推荐列表是否能将用户喜欢的物品排在前列这三种情况进行度量;推荐多样性则考查推荐的物品列表中,各种物品的特征差异大小,一般情况下一个推荐列表中的物品相似性越低,物品流行度越多样,推荐算法的多样性就越好。
最紧迫的问题仍然是提高推荐预测的准确性,为此许多学者提出了改进的相似性计算算法。为了测量相似性,HAWASHIN等人基于用户兴趣设计了一种混合的相似性度量方法。SINGH等人在确定相似性时分别考虑消费者对单个商品相似特征的好恶。AI等人使用相似性来建模用户-用户网络,并将中心性度量作为提高预测准确性的一个因素。通过引入指定的距离函数,MU等人增加了Pearson相似度。JOORABLOO等人提出了一种新的用户/项目邻域重新排序方法,该方法考虑了用户/项目相似性的未来趋势,如Slope One算法及其变体,将评分差异视为用户之间的距离,并使用该距离来预测推荐的未知评分。所有这些技术都提高了推荐预测的准确性。
尽管Slope One算法计算过程简洁,其模型简单,易于理解,可解释性强,但它将所有符合条件的用户都作为邻居使用,不考虑用户间的相关性大小,这就导致这一算法在应用中需要缓存大量的邻居间距离数据作为学习结果。
本文探索的核心科学问题是与预测目标负相关的用户在基于距离的推荐模型中是否对预测起到正面作用,这些作用有多大;这些潜在的正面作用是否可以适当牺牲来降低预测需要的邻居,以换取算法可扩展性的提升。
概括地讲,本文的研究主要有两点贡献。
(1)基于实际数据研究了相关性较低邻居用户的推荐的影响,发现负相关和相关性低的邻居用户可以在预测中省略,这种省略会给推荐过程中的预测带来多方面的正面作用;
(2)基于上述发现,本文设计了基于融合用户相似性与评分距离的个性化推荐算法,该方法成功降低了传统距离模型算法的空间复杂度,显著减少了预测时所需的用户数量,同时还提高了预测准确性、推荐列表排序质量和推荐列表的多样性。
2.2 用户相似性度量
基于用户共同评分物品集合计算的用户相关性,在推荐系统研究中一般被称为用户间的相似性(User Similarity)。以基于记忆的协同过滤推荐算法为例,其核心思想就是通过利用与目标用户兴趣偏好相似的用户群体的喜好程度来预测和推荐。具体来说就是计算目标用户与其他所有用户两两之间的相似性,再通过相似性从高到低来选择必要的个邻居,最后根据邻居的评分来对目标用户进行预测,相似性是这一过程的核心。
因此,推荐系统领域提出了许多方法来解决这个问题,例如皮尔逊相关系数、余弦相似、欧几里得距离、置信度相似度、均方距离、用户行为概率、Jaccard、Spearman相关性向量相似度、Bhattacharyya系数及用户意见传播等。这些相似性算法各有特点,考虑不同的因素和计算方式来度量用户间的相似性。
2.3 基于距离模型的协同过滤
基于距离模型的协同过滤不考虑用户间的相似性,以Slope One算法为例,该算法是一种基于模型的协同过滤推荐算法,先基于用户评分计算用户间的评分距离,其核心思想是根据两用户间之前的电影评分采用线性回归分析方法。假设用户和之间的评分具有线性关系:=+。在预测时,不用刻意选择那些相关性高的用户,所有对目标物品评过分,且与目标用户有距离的用户都将被选择作为邻居来进行预测。根据计算的两用户间评分的偏差值,加上已知用户评分来计算未知评分。最终的预测结果是所有符合上述条件预测的平均值。
3 算法设计(Algorithm design)
3.1 符号说明

将已知评分数据集分为训练集trainingSet和测试集testSet。通过训练集进行学习,基于学习的结果对测试集中的评分进行预测,并考查预测结果和真实结果之间的差异,从而度量算法的性能。

3.2 算法原理
已知用户、和三人对物品的评分分别为1、2、4.5,对物品的评分分别为3、2.5、1,预测的目标是用户对物品的评分,而已知r=1.5,r=2。
按照皮尔逊相关系数计算相似性,s=1.0,s=-1.0。按照Slope One算法计算用户间评分距离,得到=0.25,=-0.5,
从这个例子可以看出,相似性和距离模型对用户间关系的计算是有明显差异的。可以对这一差异加以利用,以提升推荐算法的可扩展性和预测性能。
基于上述分析,本研究设计了一种融合用户相似性与评分距离的个性化推荐算法(Fusion of User Similarity and Distance,FSD)。理论上,该算法既可以应用于用户间相似性与评分距离的融合,也可以应用于物品间相似性与评分距离的融合。为了简便起见,本文在讨论中仅讨论用户间的相似性和评分距离。
通过观测上述例子和分析原理可以发现,用户评分距离不带有相关性含义,评分距离近的邻居并不一定比评分距离远的邻居更具参考意义。相反,相似性高的用户在理论上与预测目标更相关,在预测中应该有更高的权重。
因此,FSD假设相似性低的邻居用户在距离模型中作用更低。阈值T表示相似性在FSD模型中可以保留邻居的最小值,通过这一设置,去除一部分权重小的邻居,再基于距离模型考查预测特征的变化,以决定T合适的取值。
这样,FSD模型融合了用户间相似性与距离特征,进行推荐系统的评分预测。
3.3 FSD算法的计算方法
本文设计的FSD使用皮尔逊相关系数,基于评分训练集计算用户之间的相似性。一般来说,两个用户之间的相似性越大,两个用户的评分相关性就越强,该邻居用户在预测中的重要性就越高。

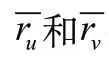
FSD用户之间的评分距离计算公式定义如下:


FSD算法根据公式(1)计算用户之间的相似性,并通过公式(3)过滤用户,选择符合条件的用户作为预测目标的邻居用户。

其中,N是用户选择的邻居集, s是用户和的相似性,T是FSD设定的阈值。
在此基础上,公式(2)用来计算用户间的评分距离,公式(4)用来预测未知用户对物品的评分。

其中,N是用户的邻居, d是用户和对物品的评分距离,||是邻居的数量。
4 实验设计(Experimental design)
4.1 实验数据集
本实验使用MoviesLens25 M数据集,包括有关电影属性和用户评分的信息。该数据集评分分数范围为0.5—5,评分间隔为0.5,包括162,541 个用户对62,423 部电影的25,000,095 个评分。本文实验随机选择其中1,000 个用户对62,423 个电影的146,533 个评分。
为了保证实验的可靠性,本文采用了十折交叉验证,在实验中数据集被随机分为10 份。每次使用1 份作为测试集,而其他9 组作为训练集,进行训练学习和预测检验,最终的结果为10 次实验的平均值。
4.2 基准算法
本文将所提出的FSD算法与原Slope One算法、加权Slope One算法(Weighted Slope One,2013)、信息熵皮尔逊协同过滤(Pearson Entropy,2020)、资源分配协同过滤(RA,2014)、用户观点传播(UOS,2015)、多级协同过滤(MLCF,2016)、用户行为概率(UBP,2021)等近几年领域内科学家们设计的经典算法进行比较。
4.3 评价指标
实验主要考查了设计算法FSD与基准算法间在评分预测误差、推荐列表排序质量、推荐列表多样性及算法可扩展性四个方面的性能差异。
本文使用平均绝对误差(MAE)、均方根误差(RMSE)来评估算法预测的误差水平,预测误差越低,算法对未知评分的预测越准确。采用半衰期效用指数(HLU)、归一化折扣累积增益(NDCG)来评估推荐结果的排序性能。推荐列表的质量越高,这两项度量参数的评分越高。
MAE反映了算法预测的用户评分与用户实际评分的偏差,RMSE表示算法预测的用户评分与实际评分之间偏差的均方根值。MAE值表示误差,RMSE在开方之前将误差的平方相加,从而增加对绝对值大于1的误差的惩罚,减小对绝对值小于1的误差的惩罚,故RMSE对大误差更敏感。MAE和RMSE值越小,预测结果与实际评分的误差越小,预测精度越高。实验中测试集预测目标数量用表示,用户的预测得分值用r'表示,用户的实际评分值用 r表示。MAE和RMSE的定义如下:

HLU评估用户真实评分和实际评分之间的差异,以衡量推荐列表对用户的实用性,其定义如下所示:
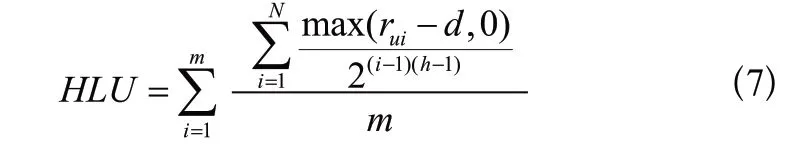
其中,为推荐给每个用户推荐列表中电影的数量, r为用户对电影的评分,为训练集中的平均评分值,为需要提供推荐的用户数量,为推荐列表的半衰期(本文实验中的值取2)。HLU的值越大,算法将用户喜欢的电影排在推荐列表前面的能力越强,系统排序质量越高。
NDCG假设用户最喜欢的电影在推荐列表中排名第一会更大程度上增加用户的使用体验。电影越相关,排名越高,用户对系统的满意度就越高,从而节省了用户的时间,其定义如下:

其中,DCG是根据每个用户的真实评分和预测评分列表计算的; R表示用户是否喜欢在中排名的电影,R=1表示用户喜欢该电影,R=0表示用户不喜欢该电影。本文实验中将用户评分高于平均评分的评价看作喜欢,将低于、等于平均评分的评价看作不喜欢。NDCG是DCG的归一化形式,由公式(9)得出,它将DCG归一化到0—1。
5 实验结果与分析(Experimental results and analysis)
依据公式(3),通过给定的相似性阈值筛选距离模型需要的邻居,图1中显示了相似性不同取值下,距离模型评分预测的误差大小。

图1 相似性阈值 Th 不同情况下FSD算法的评分预测误差大小Fig.1 Prediction error of FSD algorithm with different threshold Th
图1表明,合适的相似性阈值为T=0.0,所提出的FSD具有最佳预测精度,MAE为0.667,RMSE为0.874。此时,距离模型中相似性为负值的邻居均已经被除去。
图2中MAE的比较结果表明,当邻居数大于10时,所有算法的MAE都优于MLCF预测方法。所提出的FSD算法的MAE为0.6997,表明相比之下预测精度次高,仅次于UBP算法。原Slope One算法的MAE为0.7055,相比之下FSD减少了0.8%的误差。与所有其他算法相比,MAE平均提高了1.5%。

图2 FSD与其他算法的MAE对比结果Fig.2 MAE comparison result of FSD and other algorithms
如图3所示,RMSE也表示推荐系统预测误差的大小,和MAE相比,RMSE对较大的误差更敏感。FSD算法的RMSE最小,为0.8749;原始Slope One算法的RMSE次好,为0.8800。FSD将误差降低了0.51%,相比于其他几种算法,RMSE平均提高了2.3%。

图3 FSD与其他算法的RMSE对比结果Fig.3 RMSE comparison result of FSD and other algorithms
通过图2和图3可以看出,MAE和RMSE中的FSD算法与其他算法相比,具有更小的预测误差。这说明FSD算法既降低了整体误差,也降低了较大的预测误差。
图4展示了NDCG的比较结果。NDCG体现了推荐列表的排名质量,得数越高越好。FSD算法的最高分是0.7472,比原Slope One算法(其得分为0.7394)高出1%,加权Slope One表现要差些;与其他算法相比,平均提高了3.8%。

图4 FSD与其他算法的NDCG对比结果Fig.4 NDCG comparison result of FSD and other algorithms
HLU反映了用户对推荐列表的兴趣程度,如图5所示,其分数越高,用户对有限页面越感兴趣。FSD算法的得分为1.0065,原始的Slope One算法得分为0.977,提高了3%;与其他算法相比,平均提高了3.3%。

图5 FSD与其他算法的HLU对比结果Fig.5 HLU comparison result of FSD and other algorithms
通过分析图4和图5可知,FSD算法在NDCG方面有更高的值,说明FSD算法的排序能力较好;随着HLU值中邻居数的增加,略差于RA算法。但是FSD算法比Slope One等算法提高很多,而且比RA算法预测误差更小,所以在排序质量指标上有很好的表现,性能也更稳定。
图6显示了每个算法在预测过程中对测试集中所有目标使用的平均邻居数。图中除FSD和Slope One之外(与Weighted Slope One重合),其他曲线几乎重合在一起,这些算法选择的邻居数量是相同的。由于满足对目标电影评分条件的用户数量有限,预测的目标用户只能接触到少数符合条件的用户,因此增长缓慢,即使水平坐标中计划使用的邻居数量继续线性增长。尽管在图2中预测误差降低的绝对数值较小,但预测中使用的邻居数量如图6所示却减少很多,这提升了算法的可扩展性。

图6 用于预测的实际邻居数与算法计划选择的邻居数Fig.6 The actual number of neighbors for prediction and the number of neighbors the algorithm plans to choose
实验中,FSD算法平均使用55 个邻居进行预测,优于原Slope One算法的78 个邻居,其预测时所需邻居使用量减少了29.49%。这一巨大提升既加快了距离部分的计算速度,也减少了训练之后需要保存的数据数量(主要是用户间评分距离数据),通过增加相似性部分的计算和筛选,有效降低了算法的空间复杂度,进而提升了算法的可扩展性。
相同硬件和参数下算法训练测试所需时间如表1所示。相同条件下每种算法所需的计算时间差异较大,FSD算法在性能整体提升非常明显的情况下,需要将原Slope One算法的计算时间轻微增加1.9%。

表1 相同硬件和参数下算法训练与测试所需时间Tab.1 Time required for algorithm training and testing with the same hardware and parameters
6 结论(Conclusion)
本文为了提升距离个性化推荐算法的可扩展性和其他主要性能,将用户间相似性低于阈值的潜在邻居从预测目标的邻居集合中剔除,再利用用户间评分距离估计目标用户对未知物品的评分,设计了一种融合用户相似性与评分距离的个性化推荐算法。
与原距离模型算法相比,所提出的方法不仅在预测过程中所需的邻居数减少了29.49%,而且预测误差也降低了,推荐列表排名性能提高了3.8%,有效地提升了距离模型的可扩展性和其他各项主要性能。
研究表明,在推荐系统的预测问题中,通常是通过相似性选择过滤掉不是很相关的邻居。虽然相关性较低的邻居也可以计算出评分距离,但相关性不强,会对预测产生负面影响。与预测目标不够相似的邻居用户对预测造成的弊大于利,应该被丢弃。这种丢弃不仅可以提高算法的可扩展性,还可以提高其预测和推荐性能,应该在未来的研究中得到更多的考虑。
本文的不足之处是预测误差提升幅度不大,希望能在未来的研究工作中在融合相似性和评分距离的基础上,进一步扩展算法的性能。
