基于自适应空间特征融合的YOLOv5安全帽检测系统设计*
2022-10-09郑楚伟吴晓明刘孝炜凌福龙
郑楚伟,林 辉,吴晓明,刘孝炜,凌福龙
(韶关学院智能工程学院,广东韶关 512005)
0 引言
在施工现场正确佩戴安全帽能有效地防止施工人员在生产过程中遭受坠落物体对头部的伤害。然而在实际生产活动中,仍然出现个别工人不按规定佩戴安全帽的情况,给企业的安全生产管理带来不便。
由于安全帽检测具有很大的应用价值,目前国内对安全帽检测有了初步的研究成果,孙国栋等[1]提出了一种通过融合自注意力机制来改进Faster R-CNN 的目标检测算法,对于不同场景不同尺度的安全帽有着较好的检测效果;农元君等[2]以Tiny-YOLOv3 检测网络为基础,首先通过改进特征提取网络和多尺度预测优化网络结构,其次引入空间金字塔池化模块和CIoU 边界框回归损失函数以提高安全帽检测精度;徐传运等[3]提出将训练集中随机抽取的图像中的检测目标随机缩放后,粘贴到另一随机场景图像上的任意位置,通过场景增强扩充安全帽佩戴训练数据集,增加训练数据集的多样性;马小陆等[4]在YOLOv3 输出端引入了跳跃连接构成残差模块,同时改进分类损失函数以平衡正负样本、难易样本对模型的影响,提高了识别的准确度;施辉等[5]提出基于改进YOLO v3 算法的安全帽佩戴检测方法,通过采用图像金字塔结构获取不同尺度的特征图,在训练迭代过程中改变输入图像的尺寸,增加模型对尺度的适应性,具有较高的检测准确率;李天宇等[6]提出将跳跃连接和注意力机制CBAM 技术引入双向特征融合的特征金字塔网络PANet模块中,同时采用了CIoU 来代替IoU 进行优化锚框回归预测,有效提高了安全帽检测的识别精度;张锦等[7]提出在YOLOv5 的特征提取网络中引入多光谱通道注意力模块,从而加强网络对前景和背景的辨别能力,并在训练迭代过程中随机输入不同尺寸的图像,以此增强模型的泛化能力;赵睿等[8]采用DenseBlock 模块来代替YOLOv5 主干网络中的Focus 结构,在网络颈部检测层加入SE-Net 通道注意力模块,改进数据增强方式,增加一个检测层以便能更好地学习密集目标的多级特征,提高模型应对复杂场景的能力。吴宏毅等[9]提出一种基于Transformer 自注意力编码特征融合轻量级的目标检测网络,采用轻量级的主干网络提取特征,注意力机制融合多尺度特征,提出质量焦点损失方法,改善目标检测模型训练和测试阶段推理过程不一致问题。赵红成等[10]将原始YOLOv5s主干网络更改为MobileNetV2,再对模型进行压缩,通过在BN 层引入缩放因子进行稀疏化训练,判定各通道重要性,对冗余通道剪枝,再通过知识蒸馏辅助模型进行微调,改进后的模型具有较高的准确度。
综上所述,现有的安全帽佩戴检测方法研究缺乏将理论研究应用到实际系统开发与部署的实例,因此本文将提出一个应用深度学习技术的工业现场安全帽佩戴检测系统解决方案。解决施工现场对安全隐患和违规行为无法及时做出预警的问题,将事后追责变为事前预警,降低安全隐患;事中及时发现问题,并通知管理人员及时处理;事后将违规现象记录存档,便于溯源追责,真正做到安全生产智能化管理。
1 系统总体架构
本系统分为监控视频数据采集模块、安全帽佩戴检测模块、后端数据处理模块、前端实时展示模块。其中,监控视频数据采集模块通过在QT 环境下调用OpenCV 库显示海康威视网络摄像头获取的实时视频流。安全帽佩戴检测模块使用改进的YOLOv5 网络模型,通过自适应空间特征融合网络充分利用不同尺度特征图在不同空间位置像素点的贡献度,以更好地适应不同尺度的目标检测任务;同时根据YOLOv5 的定位信息裁剪出未佩戴安全帽的人脸区域并进行Base64 编码,再通过POST 网络请求的方式将其传递到百度智能云进行人脸识别,获取违规人员信息并生成违规通报。后端数据处理模块采用Mybatis 作为持久层框架,数据库采用MySQL,统一管理历史违规记录、违规图像、人员信息等。前端实时展示模块设计了微信小程序和QT 客户端,管理者只需通过权限认证后,就具有批量审核员工信息、实时接收违规通知、查询历史违规记录等权限。系统总体架构如图1所示。

图1 系统总体架构
2 监控视频数据采集模块
从监控视频中抽帧图像进行后续处理是本系统的基础功能。本系统使用海康威视网络摄像头,开发基于QT 环境调用OpenCV 库显示网络摄像头获取的实时视频,流程如图2 所示。用户在QT 界面内点击“设备管理”按钮后,跳出模式对话框提示用户输入网络摄像头的IP 地址、用户名、密码等信息,随后在QT 的槽函数中将根据这些信息整理成RTSP 协议地址,并打包成JSON 格式数据,写到内存中,以共享内存的方式让Python 读取这些数据并解析,然后在Python 端调用OpenCV 库根据RTSP 协议地址获取网络摄像头的视频数据,并使用YOLOv5 网络模型检测安全帽。同时,根据检测结果绘制安全帽边界框,并把这些图像和检测结果写入内存中,让QT 端读取并显示在交互界面上。
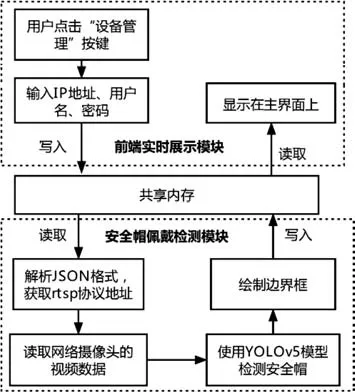
图2 连接网络摄像头实时检测安全帽流程
3 安全帽佩戴检测模块
3.1 YOLOv5网络模型原理
基于YOLOv5 的安全帽佩戴检测模块是本系统的核心功能。YOLOv5 是单阶段目标检测算法,在YOLOv4 的基础上添加了一些改进,使其速度与精度都得到了极大的性能提升。在网络结构不变的情况下,可通过深度因子和宽度因子调节网络的深度和宽度,形成YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x共4种网络模型。
YOLOv5 网络结构如图3 所示,分为数据输入、骨干网络(Backbone)、颈部(Neck)及预测部分(Prediction)。数据输入部分使用Mosaic 的方式进行数据增强,随机抽取4 张图片进行随机缩放、随机裁剪和随机排布后再拼接到一张图上,丰富了小样本数据集,同时自适应图像填充将不同尺寸的输入图像统一调整为640×640 大小。Backbone 部分使用CONV 模块、C3模块、SPPF 模块组合成特征提取网络,在不同分辨率图像上聚合并形成图像特征,构造具有层次结构的特征图,3 种模块结构如图3 所示。Neck 部分,YOLOv5 原始使用FPN+PANet 结构进行特征融合,将高层特征丰富的语义信息和低层特征丰富的细节信息相互融合,本文提出在YOLOv5的FPN+PANet结构融合的特征再使用自适应空间特征融合,加强不同尺度的特征融合以提高模型精度。Prediction 部分采用非极大值抑制对多个目标锚框进行筛选来提高对目标识别的准确度,采用二元交叉熵损失函数(BCE loss)计算置信度预测损失和分类预测损失,使用GIOU_Loss 计算Bounding box 的损失,GIOU_Loss 的公式如下:
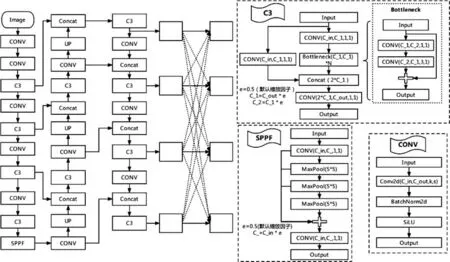
图3 改进YOLOv5网络模型
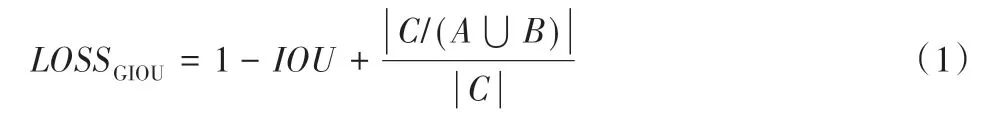
式中:A、B 分别为真实边界框和预测框;IOU为A与B的交并比;C为包含A和B的最小凸闭合框。
3.2 改进YOLOv5网络模型
在目标检测任务中,融合不同尺度的特征是提高性能的一个重要手段。YOLOv5 使用FPN+PANet 结构将高层特征丰富的语义信息和低层特征丰富的细节信息相互融合,如图4(a)所示,PANet 结构是在FPN 基础上增加了自下而上的融合路径[11],但其只是简单的通过卷积和上采样操作调整特征图的通道数和尺寸后再相加,无法充分利用各个层级特征图在不同空间位置像素点的贡献度。故本文提出在YOLOv5 的FPN+PANet结构融合的特征后再使用自适应空间特征融合(Adaptively Spatial Feature Fusion,ASFF)[12],如图4(b)所示,通过自适应地学习每个尺度上特征图融合的空间权值,将各权值参数图与对应的输入特征图进行加权求和,来决定输入特征图中各像素点的激活与抑制,以此调整不同尺度特征图在不同空间位置像素点的贡献度,更好地适应不同尺度的目标检测。
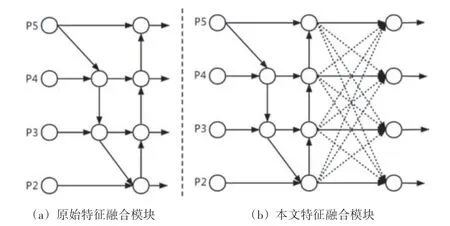
图4 原始特征和本文特征融合模块对比
具体实现步骤如下。
(1)特征缩放
由于YOLOv5 的Neck 结构输出的4 个层级的融合特征具有不同的分辨率和通道数量,所以需要做相应的调整以匹配对应的特征。对于上采样操作,先使用1×1 的卷积层压缩特征通道数量,再通过最近邻插值提高分辨率。对于1/2比例的下采样,使用3×3 的卷积层,步幅为2,同时调整通道数量和分辨率。对于1/4 比例的下采样,先使用步长为2 的最大池化层,再进行1/2 比例的下采样;对于1/4 比例的下采样,先使用步长为4的最大池化层,再进行1/2比例的下采样。
(2)特征融合

3.3 人脸识别模块
使用YOLOv5 网络模型进行安全帽佩戴检测后,若发现工人没有正确佩戴安全帽,则根据YOLOv5 的定位信息在原图中裁剪未佩戴安全帽的人脸区域,并将裁剪的图片依次进行Base64 编码,再通过POST 网络请求的方式将其传递到百度智能云的人脸搜索API进行人脸识别,将违规工人的人脸和数据库中已注册的人脸依次对比,确定违规工人的身份信息,用于后续生成违规通报。根据本系统对人脸识别的需求分析,需要满足的功能主要有3 个部分:人脸注册、人脸识别和数据库管理,人脸识别模块功能结构如图5所示,流程如图6所示。
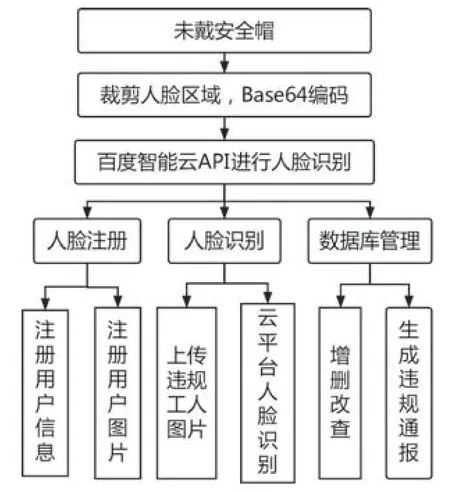
图5 人脸识别模块功能结构

图6 人脸识别模型功能流程
4 前端实时展示模块
4.1 QT交互界面模块设计
本模块的主要功能是提供QT 客户端的用户服务,用户在终端安装Qt Creator 后可调用登录接口,服务端将会对登录用户进行鉴权,根据不同的用户等级分配不同的用户权限,之后可使用服务端提供的其他云服务功能。本系统所设计QT 交互界面如图7所示。
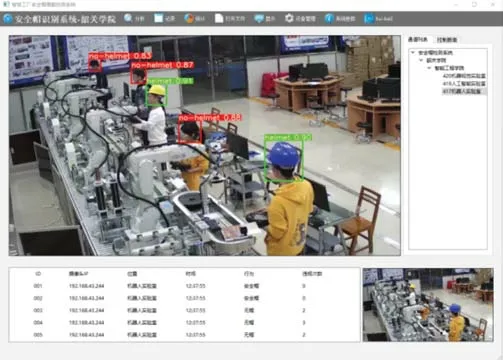
图7 QT交互界面
QT 交互界面中,用按键来作为信号的发生器,每次点击按键引起信号发生后,会自动执行相应的槽函数,在槽函数里面可以实现所需要的功能。图中,“设备管理”按键对应的槽函数是提示用户输入网络摄像头的IP 地址、用户名、密码等信息,从而连接网络摄像头来获取实时视频流,并将安全帽识别结果绘制在主界面区域;“记录”按键下,通过调用云服务器的文件管理模块接口获取未正确佩戴安全帽的违规图像并展示;“统计”按键对应的槽函数是获取MySQL 数据库中的违规历史数据统计结果并展示。
4.2 微信小程序模块设计
检测到施工人员未佩戴安全帽后,调用文件管理模块的接口保存该违规照片,同时根据人脸识别的结果在数据库中查询该员工的具体信息,生成违规通报并实时同步到微信小程序,将违规行为记录存档进数据库,便于事后查证。管理者只需通过微信小程序的权限认证后,即可实时查看工地的安全生产情况。
小程序的后端服务采用Spring Boot 框架,使用前后端分离的方式进行开发,接口采用RESTful 设计风格,数据库采用的是MySQL,所有服务均以docker 容器的形式在服务器上部署。微信小程序功能流程如图8 所示,普通用户可以在微信小程序中通过后端服务接口将人脸信息资料上传到系统的MySQL 数据库中,管理者具有批量审核员工信息、实时接收违规通知、查询历史违规记录等权限。
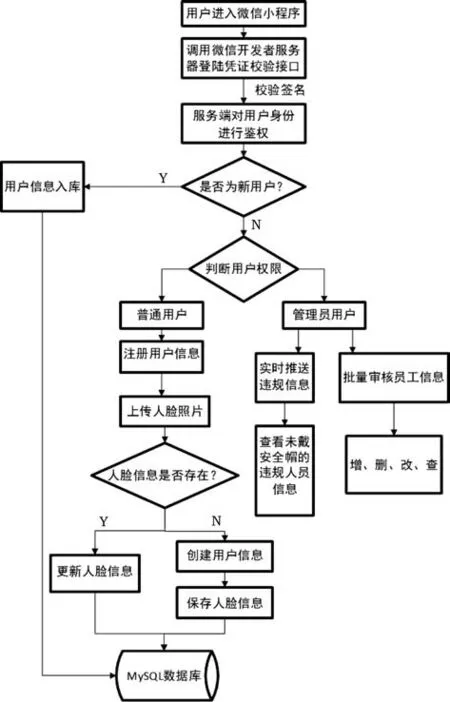
图8 微信小程序功能流程
微信小程序提供的服务通知功能是在出现新的违规信息的时候,就使用微信官方提供的模板消息接口,立即向管理者下发服务通知,提醒管理者查看最新违规信息。查询历史违规记录功能是通过官方提供的本地存储能力接口将数据存储到本地,能避免用户频繁请求接口而给服务器带来过多的压力,同时所有服务统一使用一个MySQL 数据库,当管理者在微信小程序端发送“查询历史违规记录”的请求时,服务器端就将数据库中的违规信息列表返回到小程序,再由小程序渲染生成违规信息列表,流程如图9所示。
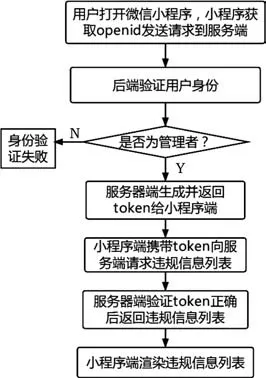
图9 查询历史违规记录流程
5 测试与结果分析
本实验使用开源安全帽佩戴检测数据集(Safety helmet wearing detect dataset,SHWD)训练网络模型,将SHWD 提供7 581 张图像按照9∶1 的比例划分为训练集和测试集。在训练过程中,设置最大迭代次数为100 个epochs,采用SGD 优化器,动量因子为0.937,权重衰减系数为0.000 5,使用余弦退火算法更新学习率。
本文使用精确度(Precision,P)、召回率(Recall,R)、平均精确度(Average Precision,AP)、平均精确度均值(mean Average Precision,mAP)指标来评估模型性能。计算公式如下:
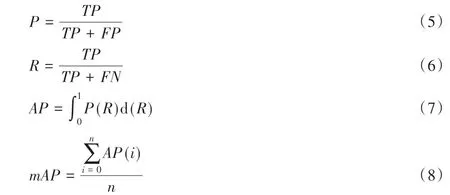
式中:n为类别总数;AP用于衡量模型对某一类别的平均精度;mAP为所有类别的平均AP值;TP为真正例;FN为假反例;FP为假正例;TN为真反例。
实验结果如表1 所示,其中mAP@.5 是IoU 阈值为0.5 的情况下每一类别的AP值的平均;mAP@.5:.95 表示IoU 阈值从0.5开始以0.05的步长增长到0.95所对应的平均mAP。从表中可以看出本文所提出的改进YOLOv5 网络模型相比原始YOLOv5 网络模型,在mAP@.5指标上提升了0.5%,在mAP@.5:.95指标上提升了0.6%。训练过程中的置信度预测损失、分类预测损失、Bounding box 损失情况如图10 所示,在90 个epochs 迭代以后,3种损失值都趋于平缓且接近0。
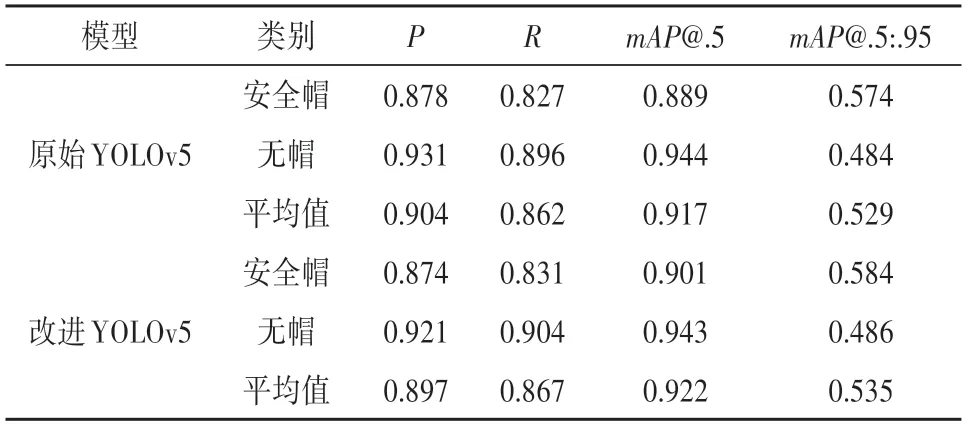
表1 YOLOv5模型性能参数比较
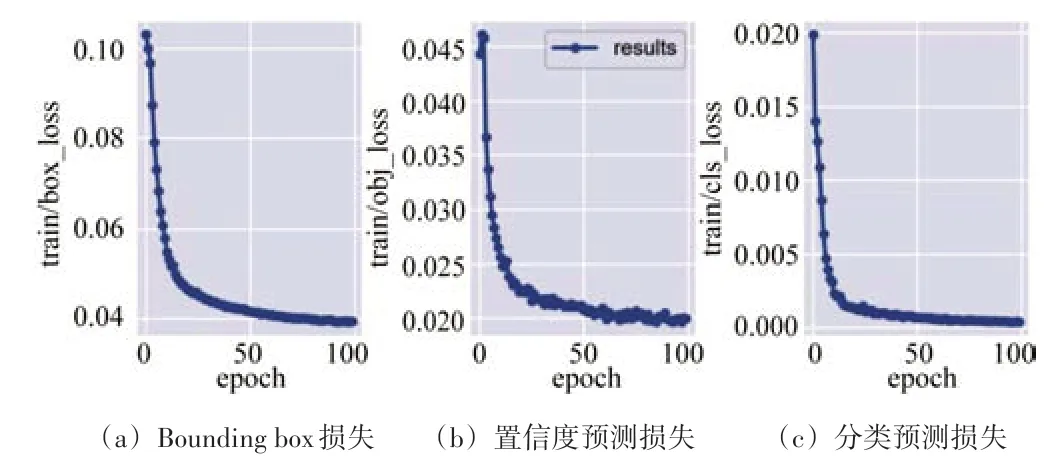
图10 训练过程损失情况
6 结束语
本文设计了基于改进YOLOv5 网络模型的智能安防监控系统,首先在QT 环境下调用OpenCV 库显示海康威视网络摄像头获取的实时视频流。其次,通过自适应空间特征融合网络改进的YOLOv5 网络模型进行安全帽佩戴检测,实验结果表明,本文改进的YOLOv5 在安全帽检测任务上的mAP值为92.2%,相比原始YOLOv5提升0.5%,满足复杂施工场景下安全帽佩戴检测的准确率要求。随后使用百度智能云进行人脸识别从而生成违规通报,并实时同步到微信小程序,将违规行为记录存档进数据库,便于事后查证。管理者只需通过微信小程序的权限认证后,即可实时查看工地的安全生产情况,实现了安全生产智能化管理。
