阶跃式和交变性能耗的异常检测与能效优化*
2022-10-09印四华杨海东徐康康朱成就王亚利
印四华,杨海东,徐康康,朱成就,王亚利,金 熹
(广东工业大学机电工程学院,广州 510006)
0 引言
高耗能机器的生产条件复杂,且长期满负荷运行,能耗异常的概率很高。典型的高能耗机器主要包括液压机、工业窑炉等[1]。在生产过程中,这些高能耗机器的能耗数据具有阶跃式、交变性和周期性的特点。机器的异常能耗通常伴随着大量的能量损失和能源效率的降低,甚至会导致停机和不可估量的安全事故,从而影响整个生产线的正常生产。随着时间的推移,机器的磨损程度会逐渐增加,从而导致机器的能耗增加[2]。早期发现异常能耗是优化能效的关键。中国宣布的目标是到2030年达到碳排放的峰值,并到2060 年进一步实现碳中和。工业排放在国家排放清单中发挥着主导作用,而能源密集型工业中与能源相关的排放需要更快地达到峰值[3]。解决减少排放的问题需要努力优化能耗行为。随着不断上涨的电价,以及对温室气体效应的担忧,人们越来越关注能效问题[4]。因此,开发一种可靠、快速和自动的能耗异常检测技术具有重要意义。有了这些新方法,生产企业可以对高能耗机器进行监控和处理,避免能源损失,优化能源效率。
异常检测主要用于检测数据集中偏离正常模式的异常数据,是数据挖掘领域中最受欢迎的研究领域之一。被广泛应用于能耗、机械设备中的故障、网络入侵检测等领域[5]。所研究的能耗数据属于一种时间序列数据。而时间序列异常检测是计算机科学的研究热点,它已成为制造和能源领域的重要问题[6]。时间序列数据异常检测方法主要包括:基于距离的异常检测、基于预测的异常检测、基于聚类的异常检测等方法[7]。关于基于距离的异常检测方法,Huo 等[8]提出了一种基于距离的时间序列数据在线异常检测算法。该方法采用K-均值和时空权衡机制来降低时间复杂度,具有良好的有效性和通用性。对于基于预测的异常检测方法,需要大量的数据训练来建立模型。因此,当数据和模型本身存在问题时,该方法的检测性能就会很差[9]。对于基于聚类的异常检测方法,“聚类算法”是指将原始数据分类为相应的近似类,使类之间的相似性低,类内相似性高。李熙等[10]采用K-means 聚类方法对牵引能耗模式进行了识别,然后提出了一种针对牵引能耗时间序列的异常分析方法。Li 等[11]采用模糊C-Means 聚类的扩展版本对数据集进行了聚类,在此基础上提出了一种基于聚类的异常检测方法。其目的是检测多元时间序列中的振幅异常和形状异常。一些学者也提出了其他的异常检测方法。Liang 等[12]提出了一种基于约束超图的方法,该方法利用子序列上的约束来检测异常,其目的是用于工业时间序列异常检测。
传统的异常检测方法分为基于局部的异常检测方法和基于全局的异常检测方法。由于缺乏适当的优化,它们的检测效率低,适应性差。综上所述,现有的异常检测方法各有不足:(1)局部异常检测方法假设异常数据可以在局部明显显示,可以通过一维时间信号分析进行检测,然而,这种方法过于注重局部的小变化,导致误报率较高,可扩展性差;(2)全局异常检测方法的前提是某些异常数据不能在局部清楚地显示,因此需要在全局范围内进行检测,但因忽视局部轻微异常,漏报率高。传统的异常检测方法不能准确地检测具有阶跃式和交变性特征的能耗数据,存在漏报率、误报率高等缺点。本文致力于解决阶跃式和交变性能耗数据的异常检测所面临的挑战。所提出的方法可以提供节能决策的依据,其目的是指导能源管理工程师实现能效优化。
1 问题描述
典型的高能耗机器主要包括液压机和工业窑炉等。在生产过程中,这些机器的能耗数据具有阶跃式、交变性和周期性等特点。该能耗数据的一个正常周期可分为3 个阶段:空载前进、负载前进和空载后退。在一个周期中的一个特定位置,数据通常会有一个跳跃式的增加。该位置位于空载前进数据段的末端,同时也就是爬升数据段的前端。该数据通常是由正常预操作引起的。如图1中的第3个周期所示。

图1 阶跃式和交变性能耗数据中的点异常特征
各种不确定的工况通常会导致能耗数据异常,从而降低机器的能源效率。在能耗数据的时间序列中,经常会出现瞬态低功率和瞬态高功率等异常能耗数据。这主要是由于不稳定的电流/电压负载、传感器损坏和异常通信造成的。数据的瞬时增加通常发生在空载后退数据段中,它通常是由短时误操作造成的。一种典型的异常能耗数据通常发生在空载前进数据段中。也就是说,数据在正常预操作前就会瞬间增加,称之为瞬时阻塞。它通常是由于高能耗机器运行过程中硬质材料堵塞引起的,也可能是由加工坯料中的材料异常引起的。个别能耗数据偏离正常范围较大,但邻域内数据正常,这称为点异常,如图1所示。
2 基于雨流计数法的异常检测
本文将雨流(RF)计数方法与局部离群因子(LOF)算法相结合,提出了一种基于雨流计数的局部离群因子(RF-LOF)的异常检测方法。该方法能够正确检测能耗数据的点异常。
2.1 雨流计数法
本研究采用雨流计数法对能耗数据时间序列进行预处理,其目的是删除爬坡和下坡位置的干扰数据。利用雨流计数法的数据压缩环节,将长度M的能耗数据处理成由局部极大值和极小值组成的峰谷序列。点Xi被识别为非峰谷点,如果:

式中:Xi为现场采集的能耗数据点,对于数据段的端点,它直接被认为是峰谷点。
2.2 高斯混合模型聚类
在本研究中,使用高斯混合模型聚类算法将雨流计数法处理后的数据划分为两个子空间。对于经过雨流计数法处理后的能耗数据,假定它的空间概率分布可以近似地用多个高斯分布概率函数表示。根据高斯混合模型聚类的理论,能耗数据x服从高斯分布:

能耗数据x的高斯混合模型的表达式为:

根据贝叶斯定理,能耗数据xj属于i类的后验概率为:

式中:1 ≤i≤k。
给每个能耗数据分类都分配一个系数。那么,能耗数据xj的分类公式为:


在上述方程中,分别对∑和μ求导,并且令导数为0。计算得到的均值向量和协方差矩阵分别为:

式中:λ为拉格朗日乘子。
在上述方程中,对αi进行求导,并且令导数为0。计算得到的混合系数为:

2.3 局部离群因子算法
局部离群因子算法属于一种基于密度的方法。该方法为每个数据分配一个局部离群因子,并根据局部离群值确定离群值。
2.3.1K-近邻可达距离
从点q到点o的K-近邻可达距离可表示为:
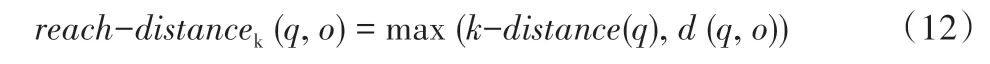
式中:d(q,o)为点q到点o之间的欧氏距离。
2.3.2 局部可达性密度
点q的局部可达密度可以表示为:

该公式表示从点q的K-近邻邻域中的所有点到点q的平均可达距离的倒数。局部可达密度代表一个密度,密度越高,就越有可能属于同一簇,当密度越低,就越有可能是离群点。
2.3.3 局部异常因子
点q的局部异常因子LOF(q)表示为:

采用局部异常因子LOF(q)作为判断点q是否异常的指标,当LOF(q)值接近1 时,表明q点是正常点,当LOF(q)值远大于1时,这表明q点更有可能是异常点。
2.4 归一化公式
在点异常检测过程中,所涉及的特征值的范围是不同的,因此需要对其进行归一化。本文对向量进行L2范数归一化处理,建立一个从c到c′的映射,使得c′的L2范数为1,也就是:

2.5 点异常阈值
为了判断某个能耗数据是否是点异常,本节提出了点异常的阈值δ如下:

式中:α为根据实际情况设定的点异常系数,如果LOF>δ,那么将该点判断为点异常。
2.6 基于RF-LOF的点异常检测算法
所提出的基于RF-LOF的点异常检测算法的综合框架如表1所示。

表1 基于RF-LOF的点异常检测算法
3 结果和讨论
3.1 点异常检测
为了验证所提出的基于雨流计数的异常检测方法的性能,本文采用了铝型材挤压机的实时能耗数据。这些数据来自华南某大型铝型材挤压制造企业的能源管理系统,采集频率为1 Hz。此外,为了商业保密,对数据进行了加密处理。能耗监测和控制终端如图2 所示。实验是在64 位,3.60G Hz 英特尔®核心TMi7 计算机上运行的,微软Windows10 和8 GB 内存。该方法是在MATLAB R2018a中执行的。

图2 铝型材挤压机能耗监测与优化平台
在仿真实验中,利用6 个周期的铝型材挤压机的能耗数据对点异常进行了检测。每个周期的长度为100 s。采用椭圆标记了6个点异常,如图3(a)所示。点线表示整个周期的点异常阈值δ。若LOF值高于此点线,则判定对应点为点异常。仿真结果表明,本文提出的点异常检测方法(RF-LOF)是有效的。能自动准确判断该点是否为点异常,因此能够满足实际应用的要求。
在这里,使用所提出的方法(RF-LOF)和LOF方法进行比较实验。利用LOF方法直接对5 个周期的能耗数据进行点异常检测,仿真结果如图3(d)所示。明显观察到异常数据不能用LOF方法明确区分,正常数据点出现了一些误判,这是因为没有考虑能耗数据阶跃特性的影响。相反,基于RF-LOF的方法使点异常检测更加合理和可行。
本文中仿真所涉及的参数设置如表2 所示。初始簇中心数n设置为2。然后,高斯混合模型聚类算法可以正确地将“负载前进”和“空载前进和空载后退”分为两类。
为了分析该方法中的k值对检测结果的影响,对铝型材挤压机的连续能耗数据进行了采样和验证。分别利用k的不同值获得计算时间和检测率,如表3 所示。本文将检测率定义为检测到的异常数据与异常数据总数的比值。当k=6~10 时,检测结果良好,当k=8 时,检测结果最好。此外,当k≥11 时,所提出的检测算法不能收敛,这主要是由于空载前进和空载后退的数据段较短。在计算时间方面,当处理500 个能耗数据时,该方法的整个检测过程可以在0.3 s 内完成,这表明所提出的基于RF-LOF的点异常检测方法适用于在线使用。

表3 不同k值的计算时间和检测率
在这里,采用来自机器状态严重恶化的铝型材挤压机的能耗数据进行了仿真实验,结果如图4 所示。在本实验中,计算得到的LOF值的时间序列在较大的范围内波动,这意味着点异常检测结果的变化更剧烈。我们将点异常的阈值系数α提高到1.85,其目的是为了自动而准确地判断能耗数据是否为点异常。

图4 恶化能耗数据的点异常检测结果
在此,采用所提出的方法对正常能耗数据进行了异常检测,如图5 所示。在模拟实验中,没有发生误检测。雨流计数法将连续上升或者连续下降的3 个以上的点的中间的点删除。据此,可以及时发现不符合交变性特征的数据段,并且能够在时间维度上精确定位它们。如图5(b)所示,所提方法有助于及时发现传感器的潜在异常。

图5 正常能耗数据的点异常检测结果
3.2 能效优化分析
在华南某大型铝型材挤压制造企业的800 USt挤压车间中,初步测试了所提出的点异常检测方法,于2021年9—12月进行了对比实验。首先,在9月份对能源管理系统中的异常能耗进行检测。然后,组织能源管理专家对能耗异常的原因进行讨论和分析,其目的是制定节能策略。所采取的能效优化措施主要包括3个方面:(1)相关的设备维护、保养和更换;(2)加强生产工人的技能培训,其目的是提高生产技能、减少误操作;(3)加强对生产材料的质量检测与筛选。最后,在10月份,再次对异常能耗进行了检测,以验证所采取措施的结果。结果如表4所示。

表4 实验月异常能耗的检测结果
在2021年9月,所提出的检测模型检测出了288个点异常。其中35个点异常是由短时误操作引起的。75个点异常是由瞬时阻塞引起的。剩下的178 个点异常可能是由于仪表损坏和异常通信造成的。在9 月底,现场工程师对数据采集系统的传感器和通信线路进行了检查确认。并更换了相应的元器件。根据10月份的异常检测结果,知道瞬态低功率和瞬态高功率的次数都大大减少了。可以看出,采取的措施达到了预期的目的。这样就实现了能耗的精确测量,避免了数据采集系统带来的数据不确定性。然后,培训生产工人的技能,旨在提高他们的操作技能和节能意识。结果表明,这大大减少了短时误操作的次数。技能培训可以减少不必要的能源损失,并优化能源效率。最后,对铝型材挤压机进行了主动维护,并且对铝锭进行了严格的质量检测与筛选。其目的是消除瞬时阻塞所导致的能耗损失。研究结果表明,在9月底采取的这些措施取得了良好的节能效果。短时误操作和瞬时阻塞的次数都大大减少了。截至10 月底的统计数据表明,所提出的方法将机器的能源效率提高了2.9%。
4 结束语
考虑到能耗数据的阶跃式和交变性特征,本文提出了一种基于雨流计数的局部离群因子算法,其目的是应用于能耗数据中的点异常检测。实际生产数据的仿真实验表明,本研究提出的异常检测方法是有效的,具有较高的检测精度和检测效率,适合在线使用。雨流计数法可以处理爬坡和下坡数据,以减少它们对异常检测的影响。该方法的处理结果有利于及时发现异常的交变性数据。混合高斯模型可以正确地将一个周期的能耗数据划分成两个子空间,并且具有很好的鲁棒性。局部离群因子算法可以准确地发现子空间的点异常,这也是一种有效的异常特征提取方法。实践证明,该方法还可以完成实际生产环境中能耗的异常检测任务,帮助能源管理工程师实时优化能效。
