高光谱图像分类的ReliefF-RFE特征选择算法构建与应用
2022-10-09项颂阳许章华张艺伟李一帆
项颂阳,许章华, 张艺伟,张 琦,周 鑫,俞 辉,李 彬,李一帆
1.福州大学地理与生态环境研究中心,福建 福州 350108 2.福州大学环境与安全工程学院,福建 福州 350108 3.福州大学数字中国研究院(福建),福建 福州 350108 4.福建省资源环境监测与可持续经营利用重点实验室,福建 三明 365004 5.空间数据挖掘与信息共享教育部重点实验室, 福建 福州 350108 6.福州大学信息与通信工程博士后科研流动站,福建 福州 350108
引 言
随着计算机科学和光谱成像学的发展,高光谱图像被广泛应用于精准农业、环境监测和公共安全等诸多领域。高光谱图像波段连续且数据量大,光谱和空间特征丰富,为地物解译与图像分类提供了更多可用的信息。但是,直接使用高维度特征进行地物分类并不合适。高维数据中含有大量的冗余信息和噪声,当参与分类的特征波段数不断增加,分类精度和特征数并不成正比,而是出现先上升再下降的“休斯(Hughes)现象”[1]。在保证地物分类精度的情况下,如何从原始波段中析取相关性小、维数低、信息量大且冗余度小的高光谱数据,解决维度灾难问题是十分必要的[2]。特征提取和特征选择是高光谱图像的两种主要降维方法。较之于特征提取,基于特征选择的降维方法既能不改变既有的特征空间和特征值,保留原始地物信息,又能够剔除大部分与实际地物不相关或冗余的特征,从而达到大量减少特征个数,提高模型精度,减少运算时间的目的[3]。
为解决高光谱图像分类中存在的多维度、强相关和多冗余等问题,学界围绕特征选择开展了相关研究。特征选择按照和学习器的不同结合方式,主要囊括了过滤式(Filter)、封装式(Wrapper)、嵌入式(Embedded)和集成式(Ensemble)四种方法[4],其中,过滤式和封装式已在高光谱图像中得到较为有效的应用。例如,Ren等[5]利用改进的分区过滤式ReliefF算法,实现高光谱图像的显著降维;Ye等[6]采用跨域ReliefF(corss-domain ReliefF,CDRF)算法以特征权重的跨域更新规则来考虑源域和目标域的跨场景特征选择问题,有效提高了跨场景高光谱数据集的分类精度;张东彦等[7]利用ReliefF算法筛选对大豆识别最有效的特征,发现基于优选特征提取精度明显高于原始波段反射率,虽然略低于全部19个特征的分类效果,但是数据量降低了63.16%;刘代超等[8]研究了封装式特征递归消除算法(recursive feature elimination,RFE)与随机森林分类模型相结合方法对林地与非林地的识别潜力,发现特征选择可以有效减少数据输入维数,并取得最高分类精度。然而,单一的过滤式或封装式算法并不能兼顾分类精度和分类效率。过滤式方法在进行特征选择时,具有结构简单、训练速度快、独立于具体训练模型、易于设计和理解等优点,但因其并不考虑特征之间的相关性,故不能有效减小特征之间的冗余,其得到的特征子集也不是最优的;而基于特征子集搜索的封装式方法考虑了特征维之间的相互作用,有效去除特征之间的冗余,能选出最优特征子集,但因搜索过程与分类器紧密相关,所以特征子集搜索时间复杂度较高[9]。
将过滤式算法和封装式算法结合能够筛选出与地物类别密切相关且相互之间冗余度最小的特征子集。Marwa等[10]提出了Filter与Wrapper的高维数据特征构造的多目标混合滤波器包装进化算法,结合两者算法能够优势互补,在消除冗余特征方面效果显著;Yuan等[11]将最大化特征空间与类编码空间之间的相关信息法与递归特征消除相结合,能够有效地集成高维蛋白质数据;Lin等[12]提出了一种交互增益递归特征消除(IG-RFE)方法,该方法基于对称不确定性和归一化交互增益相结合,迭代去除不重要的特征,能够在生物数据分析中综合特征个体的识别能力和特征之间的相互作用,可以更好地评估特征的重要性。
针对高光谱图像分类中过滤式算法无法有效去除冗余特征和封装式算法时间复杂度较高的问题,提出一种结合过滤式和封装式的ReliefF-RFE特征选择算法,该算法可综合过滤式算法训练速度快、结构简单以及封装式算法能有效去除特征之间冗余的优点。尝试运用该算法对Indian pines,Salinas-A与KSC等3个标准数据集进行特征选择与分类,分析其分类精度、特征维数及运算时间,并将其与单一的ReliefF算法和RFE算法进行比较,验证ReliefF-RFE算法在高光谱图像分类特征选择中的综合性能。
1 实验部分
1.1 ReliefF算法原理
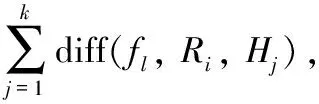
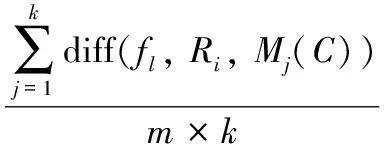
(1)
式(1)中:Wi(fl)为第i个样本中第l个特征f的权值;Hj(j=1, 2,…,k)为与Ri同类的k个最近邻样本中的第j个样本;P(C)为在训练样本中属于类别C的样本所占比值;P(label(Ri))为与同类的样本占总样本的比值,其中label(Ri)为Ri的标签;Mj(C)(j=1, 2, …,k)为与Ri不同类的k个最近邻样本中的第j个样本。距离计算公式为
(2)
式(2)中:diff(f,R1,R2)为样本R1与R2在第f个特征上的归一化距离,R1f和R2f分别为样本R1和R2的第f个特征,max(f)和min(f)分别为所有样本中对应特征f的最大值和最小值。
1.2 递归特征消除算法原理
递归特征消除法是一种贪婪的优化算法,是封装式算法的代表。该算法的主要思想是反复创建模型,逐步剔除最不重要特征。该方法是一个循环过程,每个过程都包含以下3个步骤:(1)用当前数据集训练分类器,获得与分类器特征相关的信息即每个特征的权重;(2)根据事先制定的规则,计算所有特征的排序准则分数;(3)在当前数据集中移除对应于最小排序准则分数的特征。该循环过程一直执行到特征集合中剩余最后一个变量时结束,执行的结果为获得一列按照特征重要性排序的特征序号列表,这个迭代循环过程实际上是一个序列后向选择的过程,它在整个循环过程中先是去除了与判别不相关的特征,保留了对判别相对重要的优化特征子集,因而可以达到优化特征子集选择,提高判别精度的目的。然而,封装式由于每次与特征子集的评价都要进行分类器的训练和测试,计算复杂度很高。因此,封装式特征选择的计算开销通常比过滤式特征选择要大得多。
1.3 ReliefF-RFE算法构建与原理
过滤式算法运算高效,但是其并不考虑特征之间的相关性。然而,与类相关性强的单个特征组合在一起并不一定有利于分类[15],是因为相关特征中包含一些与其他相关特征具有相同分类信息的特征,即“冗余特征”。这类特征不仅会增加分类器的计算复杂度,而且可能导致分类器性能急剧下降。因此,需要寻找一种比较高效的特征搜索算法,从而获得最佳的分类特征子集。封装式算法的特征选择与具体分类器紧密相关,因直接使用分类器的识别率来评价特征性能,并将选择所得特征直接用于构造最终的分类模型,所以封装模型相对于过滤模型具有更好的分类识别性能。但是,由于每一次选择都涉及到分类器的建模计算,所以封装式算法的运算时间要比过滤式算法慢很多。综合考虑过滤式算法和封装式算法的优缺点,在过滤式ReliefF算法基础上,选取考虑到特征之间相关性的封装式RFE算法,构建ReliefF-RFE算法。首先利用ReliefF算法对不同的特征赋予不同的权重,通过权重阈值有效剔除无关特征并保留有助于分类的特征,减少后续特征子集搜索范围,其次,将ReliefF算法筛选后留下的特征,利用RFE算法进一步筛选出与特征间相关性最大且相互之间冗余性最小的最佳分类特征子集。
设输入训练集x,最近邻样本个数k,步长step,输出xk为训练集x与目标类别有最大相关性且相互之间具有最小冗余性的特征子集,那么,ReliefF-RFE算法具体可分为以下8个主要步骤:
(1)从训练集x中进行随机抽样选择一个样本Ri;

(3)根据与Ri不同类样本所占比值,最终计算出特征的权重Wi(fl);
(4)筛选出权重系数总和达95%的特征子集,通过权重阈值剔除无关特征,得到ReliefF算法筛选后的特征子集xj;
(5)将特征子集xj作为RFE算法的输入,同时设置最优特征子集xk为空,max=0;
(6)在特征子集xj构建随机森林分类器,并通过随机森林的feature_importances_属性获得每个特征的重要性;
(7)将特征子集xj中每个特征的重要性进行排序, 根据步长step从当前的这组特征集合中修剪最不重要的特征,计算修剪后集合的Accuracy值。若Accuracy≥max,则max=Accuracy,且取当前集合为最优特征子集,否则max和最优特征子集不变;
(8)在修剪的集合上递归地重复该过程,逐次进行迭代,直到找到Accuracy值最高的一组特征子集xk。
1.4 数据与方法
为验证算法的适用性,采用高光谱图像分类领域所公认的Indian pines,Salinas-A及KSC等3个标准数据集,数据集中包含了许多地物类别(图1和图2)。Indian pines数据集与Salinas-A数据集的地物类别分别为16类和6类,地物的分布比较规则,每类地物的分布整体性好;而KSC数据集的地物类别共13类,分布较为分散。各数据集描述如表1所示。

图1 各标准数据集的高光谱图像

图2 各标准数据集的真实地物参考图
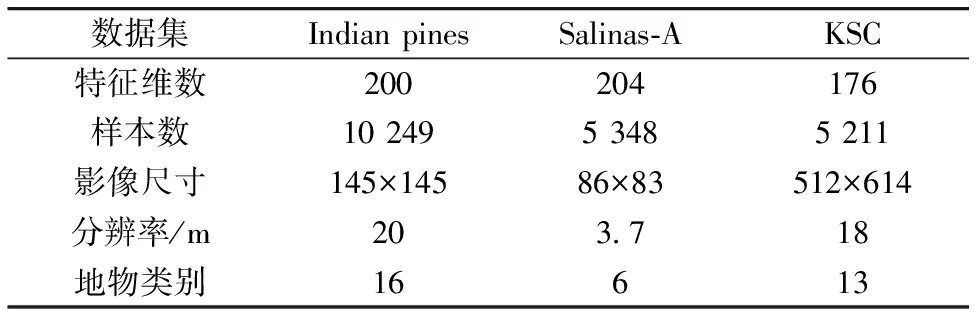
表1 高光谱数据集描述
(1)Indian pines数据集是使用AVIRIS成像光谱仪获取的美国印第安纳州西北部地区的试验区域图像,地表覆盖类型混合了林地、农田、道路、房屋建筑等。标记样本分布不均衡,部分类别样本较少。各种农作物基本都处于生长初期,对地表的林冠覆盖程度只有5%,裸地和作物残渣对植被像元分类影响明显。以上原因导致数据集类间相似度非常高,分类难度大大增加。Indian pines图像大小145×145像素,波长范围0.4~2.5 μm,220个波段,空间分辨率20 m,去除坏波段和水体吸收后剩余200个波段。
(2)Salinas-A数据集也是用AVIRIS成像光谱仪拍摄的,同Indian pines图像相似,是对美国Salinas山谷进行成像。它区别于Indian pines的是,Salinas-A数据集能够达到3.7 m的空间分辨率。图像原本包含的波段有224个,对没有水反射的108~112,154~167以及第224波段都需要剔除,剩余波段图像有204个。
(3)KSC数据集由佛罗里达肯尼迪航天中心的AVIRIS传感器收集,包含224个波段。该数据集由512×614个像素组成,其中每个像素具有8 m的空间分辨率。同时,光谱覆盖范围为0.4~2.5 μm,去除48个噪声比较高的波段后,共使用了176个波段。
为验证本算法的可靠性,将ReliefF-RFE算法及单一的ReliefF、RFE算法分别应用于前述3个高光谱数据集,分析并比较3种算法的分类效果,分类器统一采用随机森林分类器。在进行实验比较之前,先设置不同算法的参数。ReliefF算法通过随机抽样选择样本计算某个特征的权值,为了有效处理权重偏差,避免最终运算结果的权重不同,对某一特征的不同权值,通过10次运算求取平均值作为该特征的权值,设定最邻近样本数k为10,对大多数分类任务最为可靠有效;随机森林的最佳参数通过网格搜索交叉验证工具(GridSearchCV)进行参数寻优。随机选取70%的样本作为训练样本,30%样本作为验证样本,统计十折交叉验证下最佳特征子集的总体精度(overall accuracy,OA)、F-measure、Kappa系数和筛选的最小特征维数以及特征选择算法的运算时间,各指标的值越大,特征维数和运算时间越少,说明对应特征选择算法的性能越好,具体公式如式(3)—式(7)
(3)
(4)
(5)
(6)
(7)
式中:Precision表示精确度;Recall表示召回率;TP(true positive)表示被模型预测为正的正样本;TN(true negative)表示被模型预测为负的负样本;FP(false positive)表示被模型预测为正的负样本;FN(false negative)表示被模型预测为负的正样本;R为类别数;xii为第i行第i列上的数目;xi+为第i行的总数目;x+i为第i列的总数目;N为数据集总数目。
2 结果与讨论
2.1 Indian pines数据集算法应用分析
分别将3种特征选择算法与随机森林分类器相结合,对Indian pines数据集进行分类,由此获得该数据集的最佳特征子集。利用验证样本计算混淆矩阵评价分类精度,统计3种特征选择算法的OA,F-measure和Kappa系数以及特征维数和运算时间(表2)。结果表明,ReliefF算法的分类精度最低且筛选出的特征维数最高,其原因可能与ReliefF算法筛选出来的特征仍存在冗余,增加了模型复杂度和过拟合的风险,不利于提高模型可解释性,使用的特征维数越多,并不意味分类预测效果越好;RFE算法取得了较高的分类精度,同时大幅降低了建模所需的特征数量,增强了模型的泛化能力,但是单独采用RFE算法进行特征选择所需要的运算时间较长,当数据集规模足够大时,搜索最佳特征子集的运算时间将不能够被接受;较之于ReliefF算法,采用过滤式和封装式相结合的ReliefF-RFE算法,其OA提高了0.75%,F-measure提高了0.85%,Kappa系数提高了0.008 2;在特征维数方面,ReliefF-RFE算法能够去除ReliefF算法的冗余特征,其特征维数是ReliefF算法的29%;在运算时间方面,ReliefF-RFE算法是RFE算法的85%,说明ReliefF-RFE算法降低了封装式算法的运算时间,提升了模型的整体运算效率。
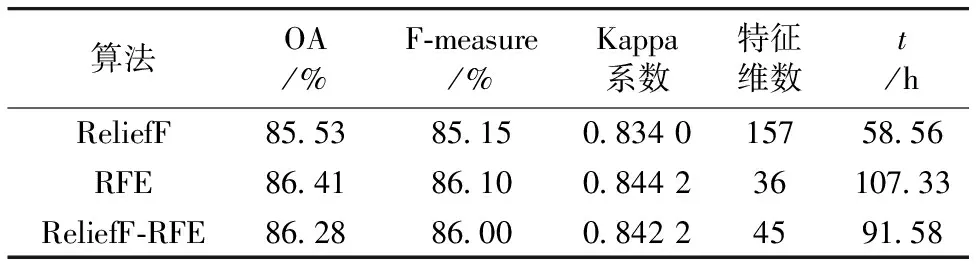
表2 Indian pines数据集最佳特征子集下的各评价指标
从3种特征选择算法的分类结果图可知(图3),部分地物存在一定的错分误分现象,但总体上,各算法的分类效果与真实地物参考图基本接近。
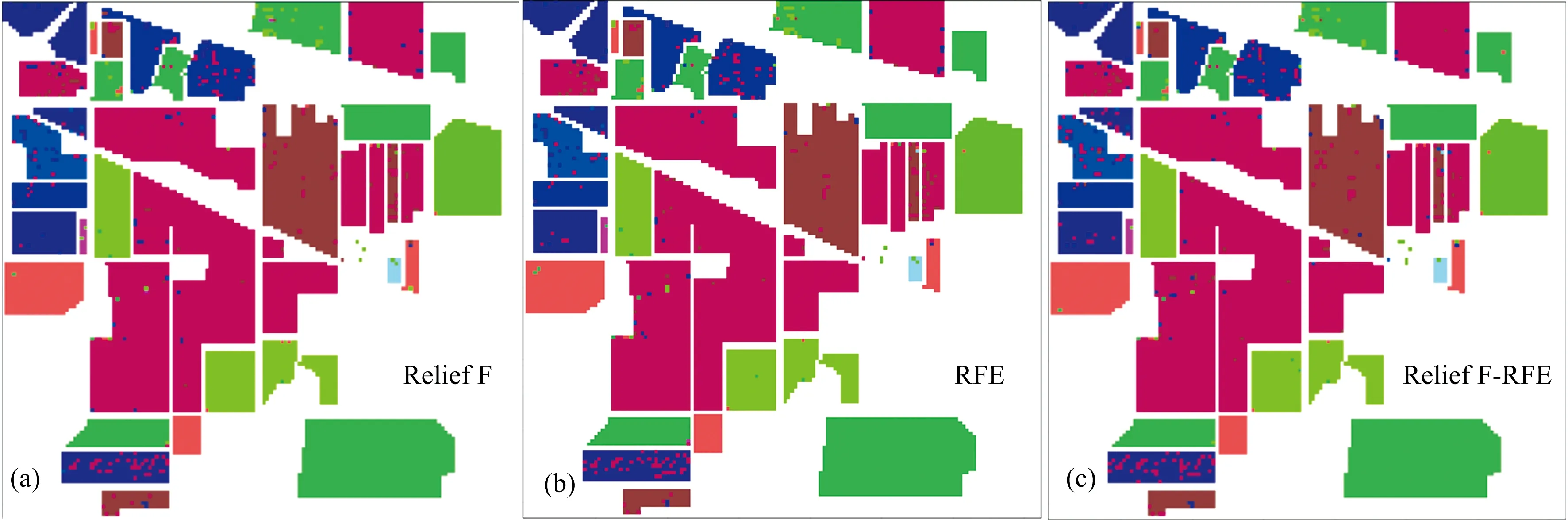
图3 Indian pines数据集高光谱图像3种特征选择算法的分类结果
2.2 Salinas-A数据集算法应用分析
利用随机森林分类器结合3种特征选择算法得到Salinas-A数据集的最佳特征子集,可以发现,3种算法都取得了较好的预测效果(表3)。ReliefF算法的特征维数最高,RFE算法以较长的运算时间为代价,用最少的特征数实现了和ReliefF算法相同的预测效果,这也说明RFE算法能够进一步剔除冗余特征,减少数据集处理的复杂度。在分类精度方面,ReliefF-RFE算法首先通过ReliefF算法初步筛选掉一批无相关特征,再利用RFE算法进一步去除冗余特征,用较少规模的特征子集取得比单一ReliefF算法和RFE算法更好的分类精度,其OA提高了0.07%,F-measure提高了0.06%,Kappa系数提高了0.000 8;在特征维数方面,ReliefF-RFE算法是ReliefF算法的39%,有效降低了特征维数;在运算时间方面,ReliefF-RFE算法的运算时间是RFE算法的76%。
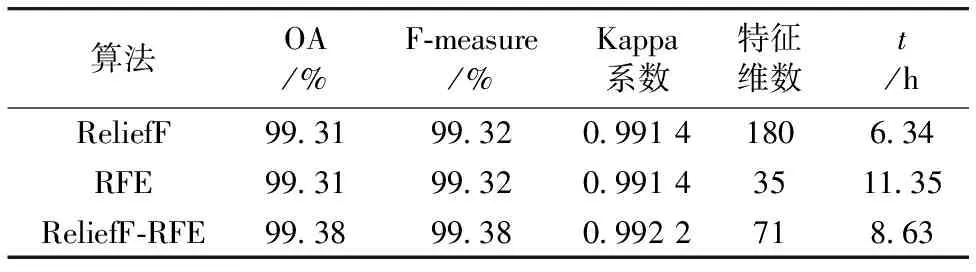
表3 Salinas-A数据集最佳特征子集下的各评价指标
从3种特征选择算法的分类细节上来看(图4),各地物的边缘区域会存在错分情况,ReliefF-RFE算法在总体上的错分情况较少。

图4 Salinas-A数据集高光谱图像3种特征选择算法的分类结果
2.3 KSC数据集算法应用分析
参照Indian pines与Salinas-A数据集的步骤,利用KSC数据集,对3种算法进行分析。结果发现,ReliefF算法筛选的特征维数依然较大,冗余特征的存在在一定程度上影响了模型性能;RFE算法以特征递归消除的方式搜索最优特征子集,具有更好的预测效果;ReliefF-RFE算法的降维效果最好,分别是ReliefF算法和RFE算法特征维数的44%和89%,并且在运算时间上具有显著的优势,是RFE算法运算时间的63%,在损失小部分分类精度情况下,大幅降低了特征选择算法的时间复杂度。
在KSC数据集中,相较于前两者算法,ReliefF-RFE算法的分类精度最低(图5),其原因可能在于:KSC数据集地物类别精细、数量高达13类,如湿地地物类别多达6种,然而其光谱曲线的可分性有限,同种地物类别会有不同的群体状况表现,增加了分类难度。
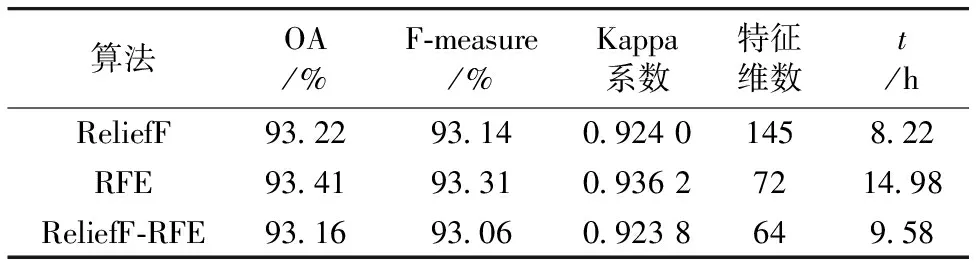
表4 KSC数据集最佳特征子集下的各评价指标
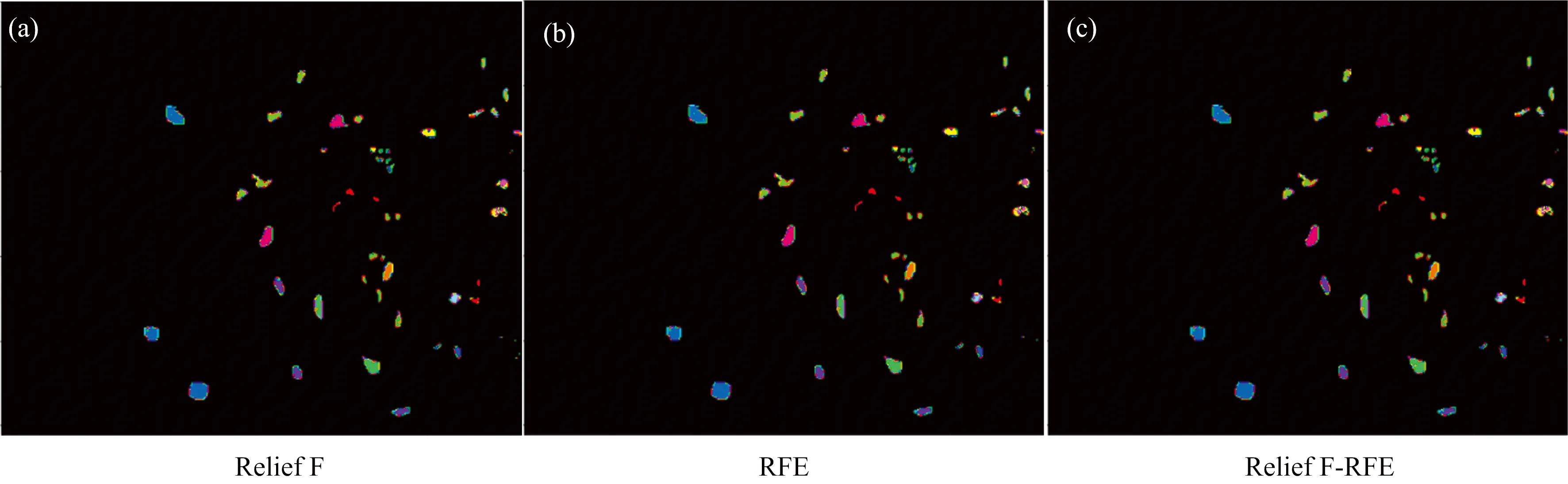
图5 KSC数据集高光谱图像3种特征选择算法的分类结果
2.4 3种算法特征选择的综合比较分析
对比ReliefF-RFE算法与ReliefF,RFE算法对3个高光谱数据集分类应用结果可以发现:其一,在分类精度方面[图6(a)],从总体分类精度可以发现,RFE算法最佳,其平均OA为93.04%、F-measure为92.91%,Kappa系数为92.06%;其次为ReliefF-RFE算法,其平均OA为92.94%、F-measure为92.81%,Kappa系数为91.94%;ReliefF算法最低,其平均OA为92.69%、F-measure为92.54%,Kappa系数为91.65%;从各数据集中可以发现,ReliefF-RFE算法在Indian pines数据集上比ReliefF算法拥有更好的预测性能,其OA提高了0.75%,F-measure提高了0.85%,Kappa系数提高了0.008 2,在Salinas-A数据集上,其OA分别较其他两种算法提高0.07%,F-measure提高0.06%,Kappa系数提高0.000 8。其二,在特征维数和运算时间角度方面[图6(b)],ReliefF算法在3个数据集上的特征维数均最高;ReliefF-RFE算法在3个高光谱数据集中筛选的特征维数远低于ReliefF算法,平均特征维数是ReliefF算法的37%,由此可以证明,高维数据集中含有与地物类别无关的特征及互相关性较高的冗余特征,结合封装式算法的特征选择能够去除过滤式算法中的冗余特征;RFE算法在3个数据集上拥有最高的时间复杂度,ReliefF-RFE算法在3个高光谱数据集中的运算时间均远低于单一的RFE算法,平均运算时间是RFE算法的75%,这是由于RFE算法每次都要结合分类器进行迭代,造成耗时过多,ReliefF-RFE算法则在ReliefF算法筛选结果的基础上降低了数据集的特征数,减小了特征子集的搜索范围,从而大幅降低了时间复杂度。总体而言,ReliefF-RFE算法能够克服过滤式ReliefF算法无法有效减小特征之间冗余以及封装式RFE算法时间复杂度较高的缺陷,在分类精度、特征维数、运算时间共3个方面拥有均衡的综合性能。
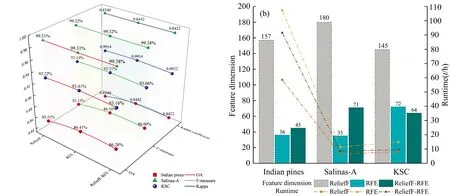
图6 3种特征选择算法的综合对比
3 结 论
针对高光谱图像波段连续且波段间相关性强的特点,在波段信息重复率较大的情况下,如果直接将原始波段信息用于地物分类,可能存在较多与地物类别不相关的冗余特征,由此引起“休斯现象”,影响模型的分类性能。在保证分类精度的情况下,本文提出一种将过滤式ReliefF算法和封装式RFE算法结合的ReliefF-RFE算法,并采用Indian pines,Salinas-A与KSC等3个标准高光谱数据集进行试验分析,结果表明:
(1)在3个高光谱数据集中,ReliefF-RFE算法的平均总体精度(OA)为92.94%、F-measure为92.81%,Kappa系数为91.94%,优于ReliefF算法但劣于RFE算法,总体精度良好。
(2)较之于ReliefF算法,ReliefF-RFE算法继承了RFE算法的降维优势,能够大幅降低特征维数,其平均特征维数是ReliefF算法的37%。
(3)较之于RFE算法,ReliefF-RFE算法继承了ReliefF算法运算效率高的特点,运算时间是RFE算法平均运算时间的75%。
综合来看,本文所提出的ReliefF-RFE算法能够发挥ReliefF和RFE的优点并规避两种算法的对应不足,将其应用于高光谱图像分类的特征选择,能够在保证分类精度的情况下,克服过滤式ReliefF算法无法有效减小特征之间冗余以及封装式RFE算法时间复杂度较高的缺陷,具有更为均衡的综合性能。ReliefF-RFE算法能够在特征选择时间要求较高的情况下,用最小的代价,处理大样本的高光谱数据集。
