基于图卷积门控循环网络的个体地铁出行预测
2022-10-09翁小雄覃镇林张鹏飞
翁小雄,覃镇林,张鹏飞
(华南理工大学 土木与交通学院,广东 广州 510630)
0 引 言
随着城市智能化的推进,准确预测个体出行行为对于进一步理解人类移动性越来越重要。尤其是地铁的个体出行,基于其出行信息进行预测分析能够带来大量潜在价值的应用,如运营调度和个性化信息推送。当前预测个体出行预测的研究根据采用的数据不同可以分成两种。一种是基于个体出行的GPS数据[1-2]。这类研究需要将出行范围划分成大量网格,而且由于GPS数据本身噪声较大以及不同的网格数量会导致不一致的误差,这类研究的个体出行预测精度一般不高。另一种是基于IC卡刷卡数据。这种数据的出行范围确定,噪声较小,更适合用作个体出行预测的研究。这类研究通常对个体出行数据进行时间序列建模,采用的方法主要有马尔科夫链[3],多项逻辑模型[4],n-gram模型等[5]。然而,这些模型仅仅对时间序列进行建模,只考虑出序列中与时间相关的周期性规律,而忽略了个体出行的空间信息。
地铁的个体出行不仅存在周期性出行的规律,还会因为地理位置限制而导致个体基于同一种活动目的地出行选择了不同的站点上车。为了进一步理解个体出行的内在移动性规律,充分全面地考虑个体出行时空特性,笔者结合图卷积神经网络(graph convolutional network, GCN)和门控循环单元(gating recurrent unit, GRU)的网络模型,提出图卷积门控循环网络(graph convolutional network-gating recurrent unit, GCN-GRU)进行个体地铁出行预测。该模型结构如图1,在嵌入层和图卷积层对出行特征进行提取,然后在时空特征向量门控层实现时空特征融合,再通过门控循环层实现时空特征的学习,最后通过全连接层推断出预测结果。
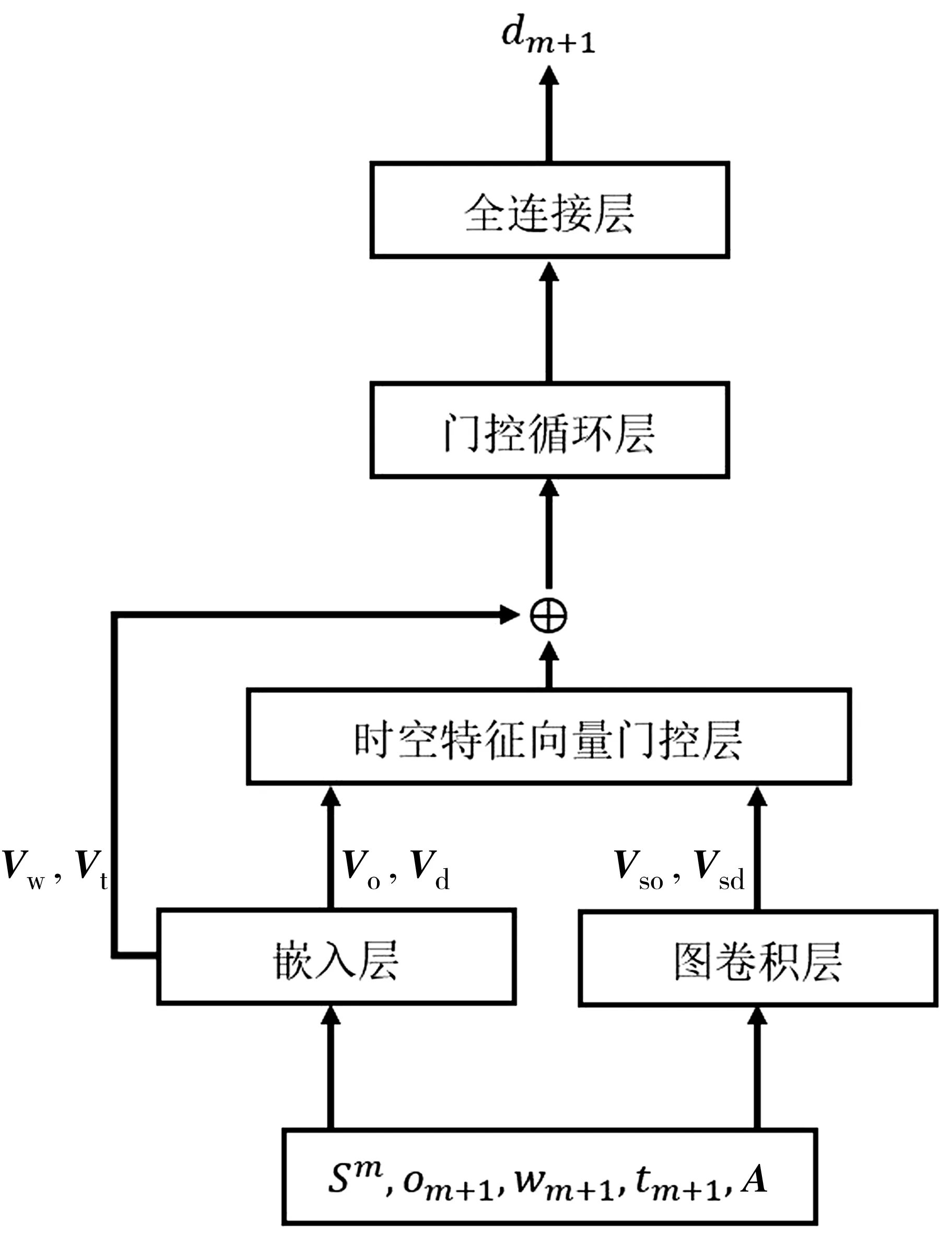
图1 卷积门控循环网络
1 问题定义和空间特征构建
1.1 个体地铁出行预测的问题定义
研究的个体地铁出行预测主要通过建立模型输入一定时间段内的历史出行记录来预测下一行程目的地。为了正式定义个体出行预测的任务,笔者首先引入两个基本概念。
其一为出行元组,可以通过一个四元组来描述一次出行为:Q(o,d,w,t)。
其中:o、d、w、t分别为一次出行的出发站、目的站、星期几和入站时间。没有将出站时间纳入分析的原因是出站时间并不由出行个体的行为模式所决定,而主要是由地铁系统来决定的,例如地铁发车时刻和地铁站内客流拥挤度等。由于其具有高度不确定性,对预测下一次出行的目的站不能提供有效信息,故不予以考虑。根据出行元组的定义,进一步定义出行序列为:
Sm={Q1,Q2,…,Qm}
(1)
其二为地铁系统网络,用G来表示。笔者使用未加权图G(V,Z) 描述地铁系统网络的拓扑结构,并将每个站点定义为一个节点,其中V是节点的集合,V={v1,v2,…,vn},n是节点数,而Z是所有相邻的两个节点之间的边的集合。为了描述两个节点之间的连接情况,使用0和1分别表示相连和不相连的邻接矩阵A∈Rn×n来表示整个地铁网络的连接。
对于给定的出行序列Sm={Q1,Q2,…,Qm}和已知最后一次出行的部分信息,(om+1,wm+1,tm+1)以及邻接矩阵A,个体出行预测任务可以转化成对映射F建模以实现输入这些信息到输出最后一次出行的目的站点的预测,其数学定义如下:
dm+1=F[A;Sm;(om+1,wm+1,tm+1)]
(2)
1.2 个体出行序列的空间特征
为了从空间角度描述关于个体出行序列,构造个体出行的空间特征是一个至关重要的问题。笔者首先提出了一种通过独热编码(one-hot)[6]实现的OD表示形式,用来量化OD的空间信息,定义其为出行矩阵并表示为:
Ti=[HO,HD]
(3)
式中:HO、HD分别为O、D的独热编码向量,假设G有n个地铁站点,则它们分别是n维向量。
通过给出出行矩阵的定义,进一步得到空间移动矩阵B,空间移动矩阵指的是在给定出行序列Sm时,对序列所包含的所有出行矩阵T1,T2,…,Tm在时间维度上进行累加,表示个体在单位出行序列中以各个地铁站作为出发站或者目的站的出行频率:
(4)
2 图卷积门控循环网络模型
2.1 图卷积提取空间特征
与传统的卷积神经网络(CNN)相比,GCN在处理非欧式数据方面具有更好的性能,例如社交网络[7],个性分类[8]和道路网络交通流量[9]。在地铁系统网络中,由于活动地点的确定和固定交通设施的限制,个人出行受到地理和系统结构的限制,这意味着从一个车站进入的个人不可避免地会从另一个车站离开。因此,地铁出行数据具有显著的非欧拓扑特征。根据空间移动矩阵的定义,在研究的问题中构建个体出行序列的空间特征时需要添加最后一个起点的信息:
(5)
由于在实际的模型对输入进行处理的时候,需要反映数据内部的相对关系而具体的数值并不重要。故对空间移动矩阵进一步归一化处理,得到空间移动概率矩阵为:
E=softmax[mask (B)]
(6)
式中:softmax函数的作用是进行平滑归一化处理,并且分别作用于O和D两个方向。mask的作用在于将B中数值为零的位置置换成一个很大的负数(负无穷大),使得E经过softmax函数后,原来数值为零的位置仍然保持为零,仅仅对数值不为零的位置进行了归一化。空间移动概率矩阵,表示为个体在单位出行序列中以各个地铁站作为出发站或者目的站的出行概率。然后,使用两层图卷积实现将E转化为更抽象的空间特征U为:
(7)
U=Gf[tanh(GfEW1)]W2
(8)
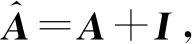
图卷积网络本质上是一个消息传递模型,它将节点的信息传播到其相邻节点。如图2,每一层图卷积操作可以将非零值的顶点的信息传播到邻接的顶点。图2表示2层图卷积运算,即表示每个节点都可以获取2跳以内的相邻节点的信息。这意味着空间移动概率矩阵可以通过图卷积层映射成与出行范围有关的抽象特征表示。然后,使用式(7)中一样的带mask的softmax函数来计算移动范围概率矩阵J。
图2 卷积层运算
J=softmax[mask(U)]
(9)
空间移动概率矩阵相当于对长度为m的出行序列在时间维度进行降维,得到个体在各个站点作为出发站或目的站的概率。而移动范围概率矩阵则进一步从个体以作为出发站或者目的站的具体的站点的概率分布,变成该站点包含其邻居站点所在区域的概率分布。
2.2 时空特征嵌入
由式(1)给定的四元组出行属性,具备了离散和分类的特性,由于将其直接输入神经网络模型进行处理时,模型更偏向将其当成连续的属性进行识别,因此需要引入词嵌入的方法进行处理。词嵌入已经大规模应用于自然语言处理的序列分类任务[10],将分类数据转成低维向量更有利于神经网络计算数据之间的语义关联。因此,采用词嵌入的方法将四元组数据转换成向量,其运算可以看作是分类数据的热独编码形式右乘一个嵌入矩阵为:
Vo=HO×MO
(10)
Vd=HD×MD
(11)
Vw=Hw×Mw
(12)
Vt=Ht×Mt
(13)
式中:H为数据对应独热编码向量;M则是对应的嵌入矩阵,该矩阵所有参数通过梯度下降进行学习。该部分对应图1的嵌入层。
在采用循环神经网络进行训练时,网络往往容易学到关于数据中周期性的规律,比如个体的通勤出行。这些规律的抽象语义主要通过式(10)和式(11)嵌入到向量Vo和Vd中,这两个向量可以认为是模型训练过程中生成的关于出行的时间特征。为了使模型能学习个体出行的空间特性,通过将J沿O和D方向分解,分别右乘对应的嵌入矩阵则可得到空间特征的嵌入向量,计算过程为:
VsO=JO×MO
(14)
VsD=JD×MD
(15)
个体出行的时间特性和空间特性在一定程度上是互斥的。时间特性意味着个体出行在时间上的周期性规律,而空间特性意味着出行受到空间的制约而不得不进行近邻站点的选择上车。因此,笔者使用一种近似于门控循环单元的方法对关于两种特性的向量进行了融合,具体过程如图3。图3的计算过程为:
g=σ[Wg(Vt,Vst)+bg]
(16)
Ct=tanh(WtVt+bt)
(17)
Cst=tanh(WstVst+bst)
(18)
Vstl=(1-g)⊙Ct+g⊙Cst
(19)
式中:⊙为哈达玛积;Vt为输入o或d的时间特征的向量(Vo或Vd);Vst为输入o或d的空间特征的向量(VsO或VsD);g为控制两种特征信息比例的门控系数矩阵,通过式(17)和式(18)生成关于Vt和Vs的关联信息向量并通过式(19)进行融合而得到时空特征向量Vstl。该部分对应图3的时空特征门控层。
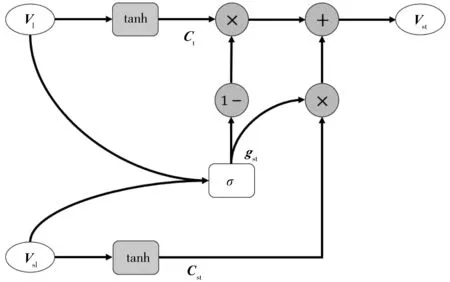
图3 时空特征向量门控层运算
2.3 时空特征学习
对个体的出行序列进行时序处理采用门控循环单元(GRU),该方法被广泛应用于交通流预测中[11]。在提取关于个体周期性出行的规律的同时,由式(19)得到时空特征向量,使得模型可以进一步学习数据中的个体出行的空间特性。连接通过式(12),式(13)和式(19)得到的嵌入向量和时空特征向量作为该模块的输入,具体运算如图4。图4中的计算公式为:
ri=σ[Wr(xi,hi-1)+br]
(20)
zi=σ[Wz(xi,hi-1)+bz]
(21)
(22)
(23)
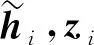
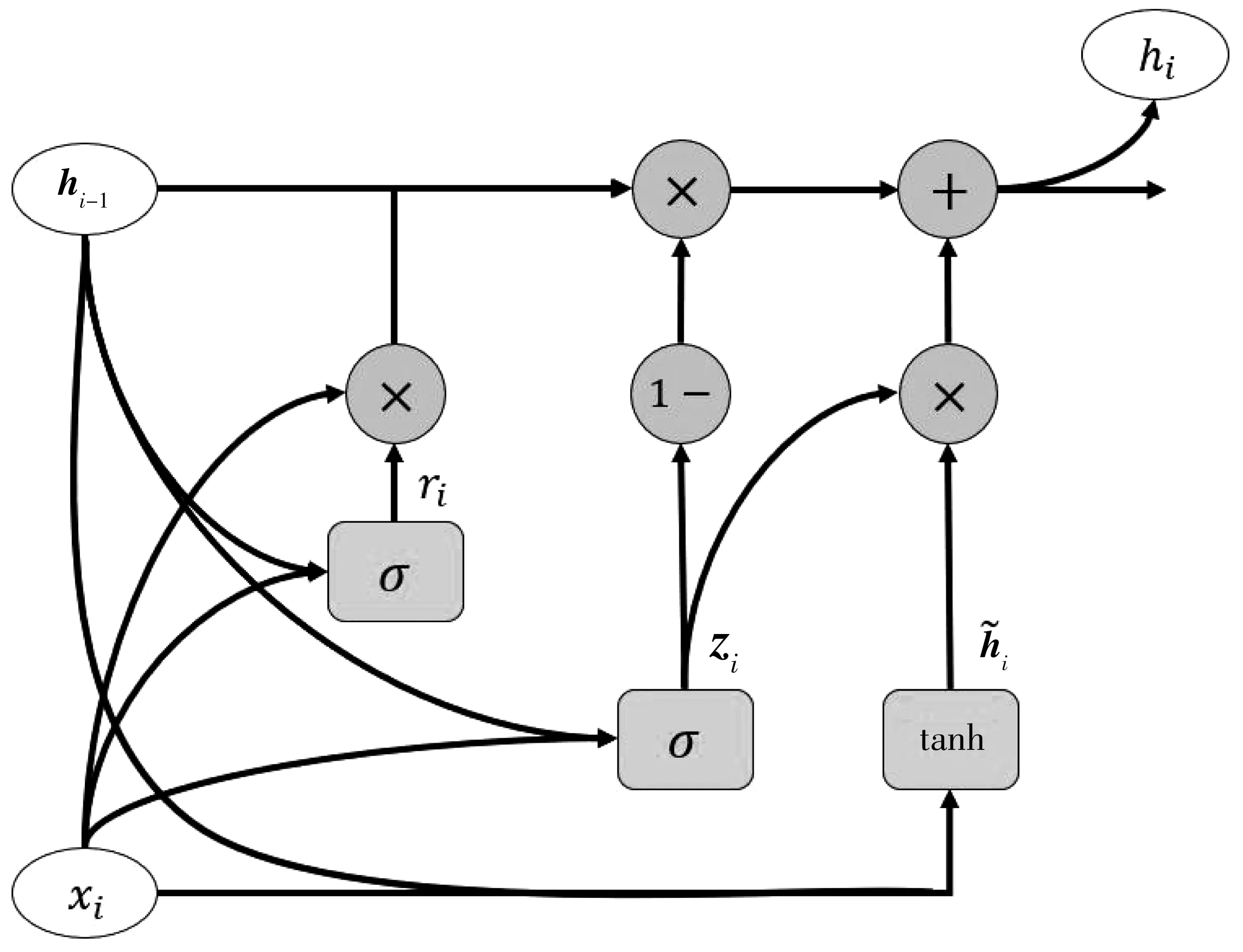
图4 门控循环层运算
2.4 模型预测
在通过门控循环层而得到第m个隐向量后,将该向量与最后一次出行(w,t)的嵌入向量和o的时空特征向量相连,使用全连接层输出模型的预测矩阵:
(24)
式中:ReLU(·)为线性整流函数。该部分对应图1的全连接层。
3 实 验
3.1 数据集和评价指标
模型性能通过广州地铁羊城通刷卡数据进行验证。该数据记录的时间跨度为2017年4月2日至2017年6月30日。由于APM线的数据无法获得,数据中总共有9条地铁线路和157个地铁站。
从过去的研究的经验中,深度循环网络模型的训练通常需要海量的训练样本。为了有效学习数据中的个体出行模式,选取了月平均出行30次以上的乘客出行记录。然后随机选取了20 000个乘客的出行记录来构建数据集。根据出行元组的定义取得每一条记录的出行属性,然后将所有乘客的出行序列按8∶2的比例分为训练集和测试集。此外,通过广州地铁2017年的地图构造邻接矩阵。
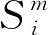
(25)
式中:1≤i≤M-m+1 ,长度为M的出行序列可以产生M-m+1个长度为m的子序列。
个体地铁出行预测任务选取准确率作为评价指标来判断模型性能效果为:
(26)
式中:T和N分布为预测准确的样本数和预测错误的样本数。
3.2 模型参数设置和性能评估
提出的模型的出行元组(o,d,w,t)的嵌入向量的维度大小分别为20,20,1,2,循环网络的隐藏层维度大小为128,图卷积的隐藏层维度大小为4,训练样本的批大小设置为2 048,优化器选择Adam和学习率设置为0.001。模型训练的损失函数设置为交叉熵函数。
为了验证提出的图卷积门控循环网络,将该模型与目前文献中的地铁出行预测模型Markov,RNN,LSTM和GRU进行性能对比。各个模型的准确率如表1,其中对比模型的设置如下:
表1 模型性能比较
1)Markov:对于给定的出行序列,计算每一个站作为o到每一个站作为d的条件概率,即(o,d)的转移矩阵,然后根据最后一次出行的o查询转移矩阵得到作为d最大概率的站为预测的地铁站。
2)RNN:经典的循环神经网络,输入到输出之间没有门控机制,通过对每一时间步的输入连接上一个时间步的隐向量进入一个带tanh激活函数的线性层而得到下一个时间步的隐向量。
3)LSTM:长短期记忆网络,带门控机制,输入到输出之间通过输入门,遗忘门和输出门的运算,得到下一个时间步的隐向量。
4)GRU:详见2.3节。
通过表1的实验结果可以看出,对比传统的Markov模型,提出的GCN-GRU模型在3种不同序列长度的数据集的平均准确率提高了11.61%。Markov模型没有将关于星期和出行时间的信息输入处理,而且不能如深度学习通过梯度下降来进行全样本的学习个体出行规律,故预测效果较差。其次对比RNN,GCN-GRU的平均准确率提升了2.69%,主要因为RNN对于出行序列处理没有采用高效的门控机制,没有充分掌握对个体出行的周期性规律。采用了门控机制的LSTM和GRU在性能上相差较小,都比RNN平均高出大约2%,但GRU在平均准确率上比LSTM略高出0.2%。最后,GCN-GRU比GRU的平均准确率高出0.71%,说明该模型在捕获到个体出行的时间特性的基础上,还能进一步对空间特性进行学习。
3.3 模型空间特性检验
为了检验提出的模型关于空间特性的学习,需要进一步对模型鲁棒性进行检验。首先,通过实验探索模型输入(o,d)和(o,d,w,t)的嵌入向量的不同差异,如图5。该结果显示只嵌入(o,d)仅比嵌入(o,d,w,t)低大约2%的平均准确率,因此可以认为关于地铁出行模式的语义信息主要通过(o,d)的嵌入矩阵进行表征。
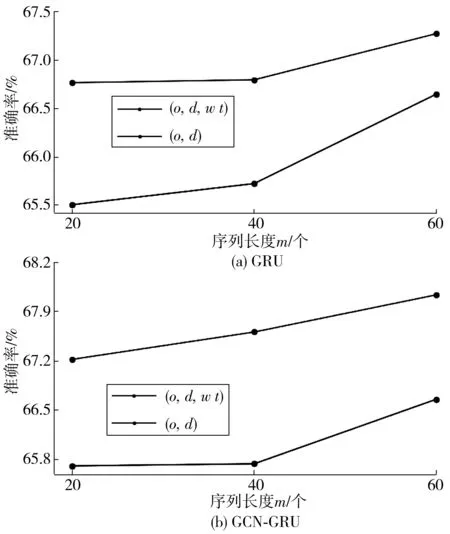
图5 两种嵌入方式作为输入的模型性能对比
因此,笔者主要从(o,d)的角度构造一种基于空间特性的出行模式的人造数据,并将不同比例的真实数据替换成该人造数据。这种基于空间特性的出行模式表示为:假设每个个体有两个不同的出行活动,然后每个活动有两个相邻的出发站和一个目的站,而且对应的(o,d)组合数量相同,而最后一次出行也基于这两个活动之一,但出发站为该活动对应的两个出发站的邻接站点。这两个活动在前m个出行有相同的个数,一共有4个不同的出发站和2个不同的目的站,第m+1个出行的出发站和这4个出发站不同。生成一个该出行模式的数据样本的算法如下:
算法1:空间特性出行数据生成
输入:邻接矩阵A,地铁站总数n,出行序列长度m
输出:一个数据样本(Sm,tripm+1)
Tris←∅,Pairs←∅,Sm←∅
fori∈{1,2,…,n} do
a1,a2,…,as是Ai中元素为1的下标
ifs≥1 then
k∈{1,2,…,s} do
Pairs插入元素(i,ak)
end for
end if
ifs≥2 then
forj∈{1,2,…,s-1} do
Tris插入元素(i,aj,aj+1)
end for
end if
end for
从{6,7,…,23}随机选取t1,t2
从{0,1,…,6}随机选取w
从Tris随机选取Rtri
从Paris随机选取Rpair
fori∈{1,2,…,m} do
ifi是奇数 then
Sm插入元素(Rtri1,Rpair1,w,t1)
else
Sm插入元素(Rtri2,Rpair2,w,t2)
end if
ifw+1≥7 then
w=w+1-7
end if
Sm中所有元素随机打乱顺序
tripm+1←(Rtri3,Rpair2,w,t1)
输出样本(Sm,tripm+1)
与真实数据中主要的时间特性的出行数据相比,空间特性数据不具有明显的周期性规律,而算法1的过程更是特化了个体出行受到地理限制的性质,即在基于同一种活动目的地出行中,出行者在决定该次出行时,极有可能会从两个相邻的站点选择一个与当前位置最近的站点上车,然后前往同一个目的站。这种信息通常干扰模型识别较为规律性的出行模式,即一种活动只有一对出发站-目的站。因此,通过将不同比例的真实数据替换成该类型的数据,可以对个体出行预测模型的鲁棒性进行检验。在鲁棒性实验中,个体出行序列长度设为40。
根据表2的实验结果,人造数据所占比例≤0.4时会对模型进行干扰,导致模型性能下降。而当该比例≥0.6后,即数据集以空间特性的出行数据为主时,两个模型的性能都开始上升,但两个模型的性能差异也越来越大。当数据集全是空间特性的出行数据时,GRU出现大约21.09%的下降,说明GRU的性能更依赖于时间特性的数据。GCN-GRU在各个不同的人造数据的比例下表现优于GRU,说明当有足够多的空间特性的数据样本时,能更稳定地学习到数据中的空间特性,反映出其在个体出行预测任务中具有更好的鲁棒性。

表2 鲁棒性分析
4 结 论
构建了个体出行的空间特征,并使用图卷积网络进行空间特征的处理,结合门控循环网络学习个体出行的时间特征,解决了地理限制对地铁出行影响的个体出行预测问题。通过在真实数据和人造数据的实验中,得出以下结论:
1)个体地铁出行存在和时间相关的周期性规律,并且受到地理位置的约束,提出的方法可以同时学习这两部分信息,在真实数据集上的表现优于只对时间特性建模的模型。
2)在使用词嵌入的方法对出行特征进行处理时,关于个体出行模式的语义信息主要通过循环神经网络对出行序列的(o,d)的嵌入矩阵的学习。
3)通过构造特化出行空间特性的数据并按不同比例对真实数据进行替换和混合,验证了提出的模型可以学习出行数据中的空间特性,比只对时间特性建模的模型具有更好的鲁棒性。
