高速互连网络中基于网卡的归约计算硬件卸载机制*
2022-10-04常俊胜熊泽宇徐金波
常俊胜,熊泽宇,徐金波
(国防科技大学 计算机学院, 湖南 长沙 410073)
计算机技术的快速发展,越发突显高性能计算在各学科领域研究中的重要性,高性能计算机技术是计算机技术乃至整个信息技术发展的制高点。目前,高性能计算在情报处理、原子核建模、天气预报、天体物理、遥感图像处理和生物系统等科学和工程计算中都发挥着举足轻重的作用。但随着大数据和人工智能等在各领域的应用与发展,迫切需要高性能计算机提高性能,提供更强大的计算能力。为满足需求,高性能计算机通过增加处理器数量和高速并行工作模式相配合,峰值计算速度和持续速度得到不断提升。2022年6月发布的TOP500高性能计算机排行榜中,排名第一的“前沿”(Frontier)高性能计算机系统的峰值性能已经达到E级,即计算性能可达到每秒百万万亿次浮点计算[1]。
1 目的
高性能计算(high performance computing,HPC)的快速发展,使得系统规模越来越大,在提高性能的同时,也带来一些问题。大规模的并行应用程序中,节点间的通信受网络链路影响,存在一定的通信延迟,而且每次通信,通信消息都要频繁进出内存,这将带来一定的启动和接收延迟,且这些延迟会随着系统规模的增大而成倍增加[2]。从应用的角度来看,在科学和工程计算中,高性能计算机的性能主要体现在应用程序的执行时间上。高性能计算中,许多并行程序的执行都是计算和通信交替进行,在计算阶段,各个进程在处理节点上独立运行,通信阶段进程则在互连网络中执行同步和数据交换;在通信阶段,处理节点实际上是处于等待状态,不进行任何计算操作,这极大地降低了高性能计算机的效率,并行程序难以获得理想的运算速度和并行效率[3]。
消息传递并行编程模型[4](message passing interface,MPI),是目前解决并行应用主要的编程模型,在高性能计算机系统中被广泛采用。聚合通信是MPI中的重要组成部分,在并行系统中,聚合通信通常是应用程序中一组进程间的互相协作,通过进程间的消息传递来实现任务控制、数据交换和数据计算。有数据统计表明,在大规模的科学和工程计算中,聚合通信开销占据很大比例,有时甚至可达到全部消息传递开销的80%[5]。与此同时,聚合通信可以高效管理消息缓冲区,避免缓存占用大及其管理开销过大的问题。因此,聚合通信的使用及其优化对提升高性能计算机性能,提高并行应用程序的执行效率具有重要意义。
在高性能计算机中,通信系统的异构性会导致系统内不同层级的通信性能存在一定程度的差异,这给聚合通信的优化带来了更加艰难的挑战[6]。目前,针对具体应用程序中的同步、广播和归约等聚合通信操作,有很多研究在算法领域或硬件上提供了较为有效的优化方案。但受制于基础环境和特定聚合通信操作的内在因素影响,不存在某一种优化方案在各种场景都能取得良好的优化效果。因此,在大规模的聚合通信场景下,面对高性能计算机内存在不同层级的通信性能变化,找到合理且有针对性的优化方案变得尤为重要。
本文主要针对聚合通信中的归约操作进行优化,提出了一种软硬件结合的支持归约计算网卡卸载机制,通过在网卡(network interface card,NIC)上嵌入归约操作逻辑部件,包括触发逻辑部件和浮点计算单元。方法中将原来由CPU执行的计算卸载到NIC上执行,实现了数据在传输过程中的计算,减轻了CPU的负担,降低了通信延迟。
2 现状
聚合通信的实现方式可以根据硬件的支持程度划分为三类:基于软件方式、基于硬件方式和软硬件结合的方式。最理想的情况是纯硬件方式实现,但硬件实现的复杂度高,经济投入巨大,因此本文不做详细讨论。
2.1 软件实现
软件聚合通信是在点对点通信的基础上结合算法实现的,是当前应用较为广泛的一种方式。软件算法实现具有良好的普适性,可以在不改变原语的情况下,在各平台实现。
最早的软件聚合通信算法于1988年被提出,是基于传播算法来实现的同步操作[7],至今仍被大量使用。此后,Watts和Geijn[8]提出一种广播算法,该算法将进程要发送的消息分成若干小消息,然后将这些小消息发散给不同的进程,接着各进程使用组收集操作使得每个进程都得到所有的小消息,以此完成某一进程向其他进程广播消息的目的。由于此种算法会频繁使用各进程的缓冲区,在互连网络中容易形成拥塞。Rabenseifner[9]在广播算法的基础上提出了对组归约操作的新算法,算法中将组归约操作分成两步,步骤一中做散发操作,步骤二中进行一次组收集操作。该算法的目的是将集中到根进程的计算分散到其他子进程中完成,从而改变根进程是组归约操作中的瓶颈问题。Thaur等[10]对MPICH库的实现进行优化,大大提高了同步、广播、归约和组归约等的操作性能,为软件聚合通信操作的使用与优化提供了一种重要方法。
通过软件实现聚合通信方法较简单,但由于是基于点对点通信实现,所以通信消息会频繁进出系统内存,使通信过程中存在延迟,并且当进行归约操作时,计算与通信操作不能同时进行,当消息在网络中传递时,处理器将处于空闲状态,使得效率低下。
2.2 软硬件联合实现
通过软硬件结合实现聚合通信操作的方式包含了软件与硬件分别实现的优点,使得高性能计算机在执行聚合通信操作时可以兼顾编程简便、延迟降低以及计算与通信重叠,大大提高聚合通信的性能。
最早的软硬件结合方法由Buntinas等[11]提出,在Myrinet上实现了基于网卡卸载的同步、广播和归约等聚合通信操作,与软件聚合通信相比,性能有很大的提升。受此启发,Moody等[12]在QsNet上提出基于网卡卸载的归约算法,该方法在网卡端集成了浮点计算单元,将本该由CPU进行的计算卸载到网卡端执行,从而提高计算与通信的重叠率以及归约性能。实验证明,卸载到网卡端执行的归约操作,整数归约性能提高了121%,浮点数归约性能提高了40%。之后,IBM公司也在其Blue Gene系列系统上提出软硬件结合的聚合通信方法,该方法通过直接存储器访问(direct memory access, DMA)和浮点计算单元等部件实现卸载操作,并在通信不满足专用网络拓扑时设置有专用的聚合通信网络。经验证,Blue Gene系列系统上聚合通信操作性能相比MPI软件实现得到很大提升[13-14]。CM-5系统同样采用了专用的聚合通信网络,专用网络为两套二叉树,其中一套实现归约操作,一套实现广播操作。Portals网络上,通过在网卡端集成Portals单元和DMA部件来实现聚合通信操作的卸载执行[15]。Portals单元中包含与处理器计算速度相当的浮点计算单元,大大降低系统在执行归约操作时的各种时间延迟。实验证明,在多节点树形算法的情况下,利用此种方法实现的归约操作性能比软件聚合通信提高了1.8倍左右。
此外,一些公司也通过交换机来实现聚合通信操作[16],如Voltaire公司的FCA(fabric channel accelerator)和Nvidia公司的交换机中实现SHARP协议。Voltaire公司产品通过在MPI库中集成FCA技术[17],使得聚合通信操作在执行时能够获取物理拓扑网络的信息,并根据拓扑网络构建聚合通信树。在聚合通信树中,一旦父节点得知计算结果,利用FCA就可以通过交换机进行广播操作,将结果通知其他节点。FCA技术还可以将聚合通信消息与交换机中的其他消息隔离,从而消除竞争。SHARP是Mellanox公司推出的将聚合通信操作卸载到网络中执行的技术,该技术实现了消息在传输过程中就进行计算,使得交换机成为协处理器,降低处理器的负担,加速归约计算速度,提高系统性能[18-19]。SHARP同时适用于深度学习、大数据计算等领域,并有良好的应用性能。
通过软硬件结合实现聚合通信操作的方法,能够大大提高系统在进行聚合通信操作时的性能,降低通信延迟,提高计算与通信的重叠率[20]。但通过网卡或交换机实现硬件卸载,势必增加硬件设计的复杂度,从而导致经济投入增大。
3 方法
高性能计算领域的不断发展为软硬件开发提供了更多便利,为提出更有效的聚合通信优化方案提供了基础。针对“天河”超级计算机系统的需求,本文提出了一种软硬件结合的支持归约计算网卡卸载机制,将原来由CPU执行的计算卸载到NIC上执行,实现了数据在传输过程中的计算,降低了CPU的负担以及通信延迟。
“天河”高速互连网络在聚合通信优化方面的设计思想类似于Portals网络,都是在网卡端加入特殊的硬件来卸载处理机端的事务,不同的是“天河高速互连网络”的网卡端加入的硬件更加简单,这样,在无须大幅增加硬件复杂性和经济成本的情况下仍能使聚合通信的操作性能有了很大的提升。相比Portals网络,本文提出的方法经济成本低,使用硬件程序产生的软件额外开销小。
3.1 聚合通信网卡卸载机制硬件设计
硬件实现结构示意图如图1所示,主要包含请求发送模块、请求接收与处理模块、请求消息接收队列和算术逻辑单元(arithmetic logic unit, ALU)。

图1 聚合通信硬件实现结构示意图Fig.1 Schematic diagram of the implementation of collective communication hardware
1)请求发送模块:请求发送模块用于解析本节点提交的描述符序列,然后产生相应的请求消息发送到目的节点。针对聚合通信描述符,模块内部实现了触发执行的机制。描述符格式如图2所示,描述符中设置有CP和CPCnt标志位;CP位域表示该序列中各描述符形成的报文到达目的节点时,将使对应虚端口的全局计数器CP_Counter加1;CPCnt表示触发描述符执行需接收的CP报文数量的阈值,该值与CP_counter进行比较,当满足CP_counter ≥ CPCnt时,触发描述符序列执行。同时,根据描述符中的SwpFlag位域决定是否在本模块中进行数据交换。
2)请求消息接收队列:请求消息接收队列用于接收并存储来自其他节点的请求消息。消息是否写入接收队列,受主机提交描述符中的SwpMp标志控制。NIC硬件中设置有一定深度的缓冲区,采用动态分配多队列方式管理;请求消息写入缓冲区,即认为消息已到达目的节点。在执行归约操作时,缓冲区可缓存最大归约分支度个归约请求消息。
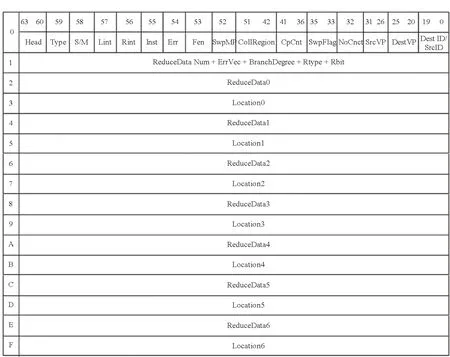
图2 聚合通信描述符格式Fig.2 Collective communication descriptor format
3)请求接收与处理模块:请求接收与处理模块基于本地描述符和接收到的请求消息进行计算操作,生成新的请求消息,并由请求发送模块通过网络发送到目的节点。请求接收与处理模块检查请求消息接收队列是否收到其他节点发来的请求消息,如果有,则对消息进行解析,并根据解析结果和描述符中相关数据发送到ALU部件中进行计算操作。ALU部件完成相应的计算操作后,将计算结果返回给请求接收与处理模块。对于归约操作,新的请求消息通常由描述符和接收到的请求消息中的数据通过一定的计算操作来产生。
4)ALU:由于NIC本身不具备进行浮点运算的能力,因此,本方法在NIC中嵌入ALU模块。该模块可实现对32位和64位数据进行归约计算。计算类型包括浮点加法、浮点求最大值或最小值且附加位置信息,有符号和无符号的整数加法、整数求最大值或最小值且附加位置信息,逻辑与、逻辑或、逻辑异或和位与、位或、位异或。
3.2 软硬件结合的归约操作实现
执行一次归约操作,首先由并行程序的一次MPI归约调用开始,进入MPI调用后,软件构造归约通信域,将参与线程与物理节点的映射关系发送给所有参与归约的节点。
基于软件线程号和通信域,构建归约操作相关的描述符,包括用于计算的归约描述符和用于通知的广播描述符。由软件按指定算法计算出归约操作中的叶节点、中间节点和根节点。由于并行应用程序使用线程标号进行归约操作,因此描述符以线程号作为源节点号和目的节点号。
基于各节点信息,完成线程号与节点号的映射,生成最终的归约描述符和广播描述符。生成的归约描述符中,需要包含源节点号、目的节点号、参与归约的数据个数、错误向量、归约分支度、归约类型、归约数据位宽、归约数据和位置信息等归约信息,硬件在解析描述符后,按规定执行归约操作。生成的广播描述符需指定源节点号、目的节点号,描述符本身无须准备数据,而是提交后在NIC中等待触发执行,并用归约计算结果替换对应的数据位域,最终完成广播操作。
用于归约操作的描述符生成后,软件向硬件提交描述符。所有NIC硬件收到归约描述符后,除叶节点对应NIC外,其他NIC在收到描述符后等待触发执行。叶节点NIC收到描述符后直接形成归约报文发往父节点;父节点NIC收到子节点发来的归约报文,并不会提交给节点,而是将归约报文存储于NIC中的请求消息接收队列中。然后请求接收与处理模块对请求消息进行解析,并按约定进行处理。首先将子节点发来的归约类报文送入ALU中进行计算,并在计算结束后触发父节点提交到NIC中的归约描述符,所提描述符与之前的计算结果再次进行归约计算,并在计算完毕后形成归约报文按算法向上发送,具体处理过程如图3所示。以此类推,直到根节点。根节点NIC中的归约计算与上述父节点中类似,不同的是根节点提交的归约描述符生成的归约报文的目的节点为自身,且分支度为1,因此该归约报文不会再进行归约计算,而是触发执行根节点提交的广播描述符,将归约计算结果通知给所有参与此次归约操作的节点。
归约描述符与广播描述符都执行完成后,按照描述符中的规定,所有NIC硬件向各自对应节点中指定内存地址写入完成值,完成值为计算结果。当软件收到硬件返回的归约结果后,则表示一次完整的归约操作结束。
不过,广东人对腊味的热衷不只是在冬季。广东素有“秋风起,食腊味”的说法,如今产业化的生产模式,更是让全年腊味不断。其中,最令老饕们偏爱的食物当属腊味煲仔饭。腊味煲仔饭是腊味饭的集大成者,肉质肥美,青菜爽口,米饭弹力十足,连煲底那一层焦香的锅巴,都让人难以忘怀。
如图3所示,当请求接收与处理模块检测到buffer中有报文,则将报文顺序读出,并对读出的报文进行计数,计数由Rcnt1开始。同时,将Rcnt1报文中的Branch、Rtype和Data等信息存入中间结果寄存器中;读出Rcnt2报文后,先后比较该报文与中间结果寄存器中的Branch和Rtype位域,如果一致,则将二者中的数据一起送入ALU中进行计算;ALU返回的计算结果直接更新到中间结果寄存器中;此时,比较Rcnt和Branch的值,如果不等,则继续读出报文进行计算,计算过程与前述一致;如果二者的值相等,则检查请求发送模块接收的第一个描述符,判断描述符是否为归约描述符(Rflag),继而比较描述符与中间结果寄存器中的Rtype,当描述符与Rtype一致时,将描述符与中间结果寄存器中的数据送入ALU中进行计算,并将计算结果再次更新到中间结果寄存器;当归约计算结束时,将中间结果寄存器中的数据替换到前述描述符中;如果请求发送模块接收的第一个描述符不是归约描述符,那么直接用中间结果寄存器中的数据替换此描述符中的数据位域。

图3 NIC中归约操作流程示意图Fig.3 Schematic diagram of protocol operation in NIC
具体的操作流程如下:
1)请求接收与处理模块检测buffer中的报文,当有报文则按顺序读出执行。
2)对读出的报文进行计数,由Rcnt1开始,并将Rcnt1报文中的Branch、Rtype和data等位域存入中间结果寄存器中。
3)检测Rcnt2报文与中间结果寄存器中报文(Rcnt1报文)的Branch和Rtype位域是否一致,如果一致则将二者报文中的数据送入ALU中进行计算。
4)ALU中计算结束后将计算结果更新到中间结果寄存器。
5)检查Rcnt是否等于Branch,如果不等于,则继续读出报文进行计算;如果相等,则检查本节点提交的第一个描述符是否为归约类型。
6)重复步骤3)、步骤4),直到步骤5)满足条件。
8)使用中间结果寄存器中的数据替换本地提交的描述符中的数据位域。
综上所述,“天河”高速互连网络基于触发实现归约操作的优化有以下优势:
1)硬件实现简单,没有大幅增加硬件复杂性和经济成本:由于“天河”高速互连网络只在网卡端加入了触发逻辑,而且触发逻辑只需实现简单的功能,从而“天河”高速互连网络的网卡较一般的网卡并没有增加太多的硬件,因此经济成本较之前的互连网络并没有太大的增加。
2)网卡端进行数据自动复制和自动触发发送,加快消息的传递速率,大大减少了节点端消息的停留时间,使得聚合通信对规模的敏感性降低,使得快速、大规模的归约操作成为可能。
3)网卡端自动处理数据而不需要处理机的参与,减小了系统噪声对归约操作的影响,增加了归约操作的性能和可靠性。
4)在进行聚合通信时网卡端进行消息处理的同时处理机端可以进行其他的计算工作,增加了计算与通信的重叠率。
4 实验
基于本文提出的支持归约计算的网卡卸载机制,在FPGA平台搭建了16节点规模的测试环境;基于xNetSimPlus模拟器[21]模拟实现了32、64、128、256节点的测试。在软件层面,将实现集成到“天河”超级计算系统的通信库MPICH_GLEX中,软硬件接口的整体结构如图4所示,MPICH_GLEX运行在用户层,调用用户层函数Libglex和内核层设备驱动接口gdev来进行网卡端软硬件资源的使用。具体实验步骤如下:

图4 软硬件接口整体结构Fig.4 Overall structure of software and hardware interface
1)配置节点规模、拓扑结构等参数。
2)root节点与leaf节点进行同步,root节点给leaf节点分配leaf id,交换内存地址等信息。
3)root节点进入循环,提交归约描述符与集合描述符,其中归约描述符设置coll_counter=num_of_leafs,接受节点发来的mp报文后触发,向自身发送mp报文;集合描述符coll_counter=1,受自身归约mp报文触发,得出归约计算结果并校验。
4)leaf节点进入循环,提交归约描述符,向root节点立即发送mp报文;等待接收root节点发来的集合报文。
5)统计结果并记录。
为了评价改进后聚合通信操作的性能,本文将使用k-aryn-tree 胖树拓扑来测试有无硬件卸载机制对聚合通信性能的影响。胖树拓扑是一种典型的多层次树形拓扑,在高性能计算机及数据中心中广泛使用,节点之间的通路自叶向根逐渐变宽,适应了通信带宽自叶向根逐渐变大的实际要求,实现了网络带宽的平滑扩展,胖树拓朴结构如图5所示。模拟时,默认每个节点上只运行一个进程,测试的节点规模选定为 16、32、64、128和256。

图5 胖树拓扑结构Fig.5 Fat tree topology
要准确评价聚合通信的性能,必须考虑整个聚合通信过程对并行应用的影响,在此基础上选取合适的评价指标。聚合通信由一组节点共同参与完成,其中某个节点进行聚合通信的时间并不能反映聚合通信的性能。Nupairoj和Ni[22]提出了以聚合通信操作的完成时间为评价指标来评测聚合通信的性能,聚合通信操作完成时间定义:让所有进程在t0时刻调用聚合通信操作,从t0开始直到所有节点都完成该操作为止的这段时间被定义为聚合通信操作的完成时间tc。
5 结果
图6给出了消息大小为8 Byte,节点数量为16、32、64、128、256时不同数据类型Reduce操作的完成时间对比图。不同消息大小下归约操作的完成时间如图7所示。

(a) 双精度浮点型(a) Double float

图7 不同消息大小下,归约操作的完成时间Fig.7 Completion time of All-reduce operation under different message sizes
通过调整实验中消息大小,得到了表1至表5中的实验结果。横向表头为操作数类型;“无”表示无聚合通信卸载,“有”表示NIC聚合通信卸载;纵向表头为节点数量;数据单位为μs。

表1 消息大小为16 Byte时不同节点规模通信时间

表2 消息大小为24 Byte时不同节点规模通信时间

表3 消息大小为32 Byte时不同节点规模通信时间

表4 消息大小为40 Byte时不同节点规模通信时间

表5 消息大小为48 Byte时不同节点规模通信时间
从图6可以看出,本文提出的支持归约计算的网卡卸载机制优势明显。从图7可以看出,在节点规模增大以及传输数据量变大时,卸载方案优势依然稳定,但当消息大小由48 Byte增大至56 Byte时,通信时间存在较大波动,这是由于聚合通信描述符在设计时最大只能携带48 Byte的Reducedata,当消息大小大于48 Byte时,传输一条消息时会生成更多的描述符用于数据传输,导致系统整体性能下降。
对比不同节点规模Reduce操作的实验结果,可以看出在256节点规模下,相比于无聚合通信卸载,NIC卸载方法最高能获得271%的加速效果,而利用Portals网卡进行卸载的同规模Reduce操作最高能获得180%的加速效果[23]。
6 结论
基于硬件卸载的聚合通信实现机制是提升高性能网络通信性能的重要途径。本文提出了一种基于网卡的归约计算硬件卸载机制,通过在网卡上嵌入归约操作逻辑部件,在数据传输过程中完成计算功能,减轻了CPU的负担,降低了通信延迟。实验表明,本文所提出的基于NIC的硬件卸载机制能有效减少聚合通信中归约操作的时间,提升通信性能。
后续的研究中,将考虑优化现有的归约实现机制,通过保证规约计算的顺序性,实现多次规约计算具有相同的结果。此外,考虑融合多核架构和网络功能,把更大规模数据通信相关的计算功能卸载在网络上进行实现,提升系统性能。
