人工智能又开“画展”了
2022-10-04
2022年4月的时候,OpenAI曾展示了它新的图像生成神经网络DALL-E2,它可以几乎按照任何要求来生成高分辨率的图像,并在大多数方面都超过了最初版本的 DALL-E。
可仅仅过了1个月,Google Brain就在近日也发布了自己的图像生成人工智能——Imagen,而它的表现甚至比DALL-E 2要更好。
Imagen是一种文本到图像的扩散模型,具有深层次的语言理解能力,可以通过输入文本创建逼真的图像。Imagen使用大型frozen T5-XXL编码器将输入的文本编码为 嵌入,然后条件扩散模型将文本嵌入映射到64×64像素的图像中,之后再进一步利用超分辨率扩散模型生成256×256像素和1024×1024像素的图像。
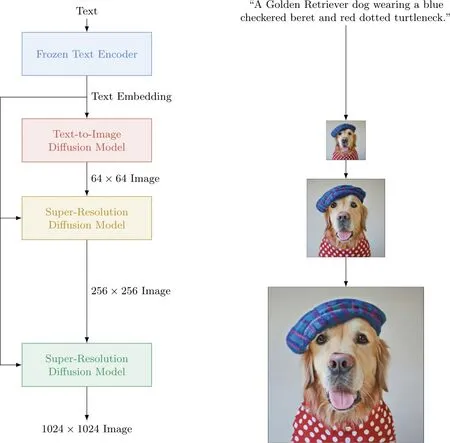
输入“一只穿戴着蓝色格子贝雷帽和红色波点高领毛衣的金毛犬”后Imagen的动作


DrawBench对Imagen、DALL-E2、VQ-GAN和LDM的测试结果
据了解,谷歌通过引入测试基准DrawBench,对Imagen、DALLE2、VQ-GAN+CLIP和LDM几类模型进行了深入地评估与对比。结果得出,无论是在样本质量还是图文对齐方面,Imagen的评分都位居第一。
例如,DALL-E2在面对一些同时出现两个颜色的文本时表现不佳,而Imagen可以很好地应对这些情况。此外,当文本中出现有位置和效果指向的具体字样时,Imagen也比DALL-E2的表现更好。

面对同时出现两个颜色的文本,Imagen和DALL-E2生成的图像对比

Imagen和DALL-E2对“马骑着宇航员”文本分别生成的图像
不过,在反常识文本的情况下,目前Imagen和DALLE2都未能准确地理解并输出对应的图像。
另外,相比以往出现的图像生成器,谷歌在Imagen中做了一项重要的改变,使其工作效率和质量得到了进一步提升。此前,图像生成器多是通过CLIP来把文本映射图像中,再指导一个生成对抗网络或者扩散模型来输出最终的图像;而在Imagen中,文本编码的训练任务仅由纯语言模型来完成,文本映射图像的生成任务则全部交给了图像生成模型。
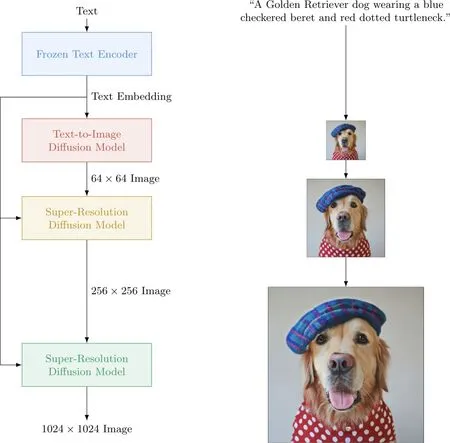
Imagen的可视化工作流程
文本理解方面,CLIP的图文对训练集是有限的,而T5-XXL编码器含有800 GB 的纯文本语料训练库,比CLIP要全面得多。在保真度和语义对齐上,T5-XXL编码器的能力也更强。
研究中,谷歌还发现,“在Imagen中,语言理解模型的规模大小对图像效果的积极影响胜于图像生成模型,增加语言模型的大小可以大大地提高样本保真度和图文对齐度。”

Imagen生成的一个图像
除此之外,谷歌对Imagen的扩散模型进行了优化,其通过在阈值扩散采样器增加无分类器引导的权重提升输出图像的图文对齐度,又增多了低分辨率图像的噪声以解决扩散模型的多样性不足,还引入新的Eff icient U-Net架构带来了更优的内存效率、收敛速度及计算效率。
完成以上改进的Imagen模型在未用流行目标检测数据集COCO训练过的情况下,在其测试中拿到7.27的FID高分。并且,其样本质量在图文对齐上与COCO训练集的参考数据不相上下。与此同时,Imagen也在COCO测试中暴露出在人物类图像表现不佳的缺陷。
实际上Imagen的许多图片都令人惊叹不已,不仅仅是因为图片内容有趣又奇幻,而且很多图片场景带来的真实感十分强烈。
就像OpenAI发布DALL-E时所做的一样,Google也用各种“拟人化动物”的可爱图片来宣传他们的工具,比如一只戴着宇航员头盔的浣熊,一只趴在寿司房子里的柯基,一只戴着皇冠坐在国王宝座上的博美等等。
但是,这些公开的大多数图片之所以都如此可爱,或许是经过精心挑选的结果。其实像DALL-E2和Imagen这样的模型,往往依赖于大量网络抓取的图像数据,而这些数据通常是未经处理的,其中既有好的数据,同时也会有不健康的数据。
Imagen团队表示 :“虽然我们对一部分训练数据进行了过滤,以去除噪音和不良内容,如色情图像和有毒语言,但我们也使用了LAION-400M数据集,众所周知,该数据集包含大量不当内容,包括色情图像、种族歧视和有害的社会刻板印象。Imagen依赖于在未记录的网络规模数据上训练的文本编码器,从而继承了大型语言模型的社会偏见和局限性。因此,Imagen存在对有害的刻板印象和表述进行编码的风险,这促使我们决定在没有进一步保障措施的情况下,不发布Imagen供公众使用。”
尽管DALL-E2和Imagen存在风险,但它们本质上大大地推动了人工智能领域的发展,使人工智能再次达到了新的高度。并且,这种人工智能图像生成的技术将有可能成为改变世界的一项技术。
回顾过往,你会发现人工智能在发展到一定程度之后都受到了一个瓶颈的困扰:主要的机器学习手段还是来自于蛮力计算,而且其依赖大量的数据来训练系统。这和人类的思考方式还是有很大区别的。人类在思考时可以进行泛化,例如,婴儿知道什么是猫之后,再见到其他的猫就能马上知道这是猫。
机器无法进行泛化,这从另外一个方面也反映了机器学习一直只能通过大量数据分析模仿人类的逻辑分析能力,故而一直难以实现人类大脑的另一强大功能——想象力。

一个大脑骑着火箭飞船向月球飞去

戴着大理石耳机的大理石考拉DJ

在雪地里戴着空手道腰带的火龙果

一只外星章鱼漂浮在传送门上阅读报纸

一只戴着太阳镜和沙滩帽的柯基在时代广场骑自行车

泰迪熊在奥运会400米蝶泳比赛中游泳
直到2014年,当时还是蒙特利尔大学博士生的古菲尔突然想到了这个问题的答案——对抗性神经网络。对抗性神经网络的原理是两个人工智能系统可以通过相互对抗来创造超级真实的原创图像或声音。对抗性神经网络赋予了机器创造和想象的能力,也让机器学习减少了对数据的依赖性,对于人工智能是一大突破。
对抗性神经网络被称作是近年来最有潜力的,解决了一直困扰人工智能领域数据来源问题的重要机器学习模型,可以说是真正实现了不依赖人类的无监督学习。对抗性神经网络更是在2018年入选了《麻省理工科技评论》“十大突破性技术”。
自2018年以来,由对抗性神经网络带来的无监督学习方法吸引了越来越多的关注,并使得人工智能在多个领域取得了巨大的进展。除了前面提到的图像生成领域,人工智能在文本创作领域同样表现不俗。入选2021年《麻省理工科技评论》“十大突破性技术”之一的GPT-3就是一种使用对抗性神经网络无监督学习算法的“大型语言模型”。
GPT-3由旧金山的研究实验室OpenAI创建。基于GPT-3,人工智能能够模仿人类书写文本,且逼真程度令人称赞,人们甚至认为GPT-3可以写出任何东西:同人小说、哲学辩论、甚至代码。GPT-3的出现也让我们可以期待人工智能将在未来走得更远。
最后,让我们尽情欣赏Imagen创造的各种“怪异而美妙”的“画作”吧!
