钢卷自动拆捆机器人捆带定位系统研发与应用
2022-10-03王荣浩张文博盛博文王景云
王荣浩,徐 斌,张文博,盛博文,王景云
(1.机科发展科技股份有限公司,北京 100044;2.中国国际工程咨询有限公司,北京 100048)
0 引言
随着我国冶金行业转型升级进入关键时期,国内各大钢厂均对产线的智能化改造提出了迫切的需求。钢卷拆捆是硅钢生产工艺中的重要环节。截至目前大多数钢厂的钢卷拆捆仍采取人工作业的形式进行,为了解决人工拆捆作业中存在的工作环境恶劣、拆捆断带伤人和断带落入运输小车轨道威胁设备运行安全等一系列问题,同时提高拆捆作业的效率,部分龙头钢厂先后开始引入工业机器人系统进行自动拆捆作业[1~3]。机器人自动拆捆作业完全依赖于捆带定位结果的引导,因此是否可以准确地定位捆带的位置,直接决定了机器人能否实现自动拆捆功能。

图1 钢卷表面捆带
目前已在钢厂中投入使用的非接触式捆带检测自动拆捆机器人大多采用以下两种方式进行捆带识别定位:一种是点激光扫描测距[4],另一种是机器视觉算法图像处理[5~7]。点激光扫描测距法在机器人第六轴末端安装点激光传感器,工作时首先对钢卷位置进行定位[8],使点激光垂直照射在钢卷外表面,机器人带动点激光从钢卷的一个端面沿轴向扫描至另一端面,当点激光测距数值发生突变并持续一段距离时,认为发生突变的位置为捆带所在的位置。这种方法原理简单,易于实现,在不锈钢冷轧、精整机组等钢卷表面形貌较好的产线上使用捆带检出率可达90%以上,但这种检测方法的缺点同样明显,在带有氧化镁涂层的硅钢FCL机组等钢卷表面平整度较差的工况下捆带检出率只有不足50%,且周围电磁干扰严重时激光测距结果会出现无序跳动,严重影响检测结果的获取,显然无法满足生产需求。
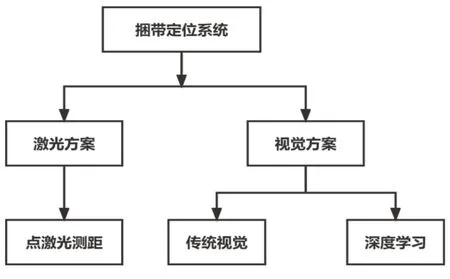
图2 捆带自动识别定位系统方案
针对以上现状,重点分析复杂环境和背景条件下的捆带识别定位的视觉解决方案,本文对比有限规则的传统视觉捆带识别算法及其运行结果,研发了一套基于深度学习目标检测算法的捆带视觉定位系统。深度学习强大的自主学习能力使其能够适应更加复杂多变的目标检测应用场景[9]。硅钢FCL入口开卷机组自动拆捆机器人试运行结果表明基于深度学习目标检测算法开发的捆带识别定位系统能够满足冶金行业复杂环境条件下的捆带定位需求,部署了该系统的自动拆捆机器人能够节约人工成本,保障作业安全,提高生产效率。
1 捆带视觉识别定位系统简介
1.1 系统设备组成
捆带视觉定位系统主要由六轴工业机器人、CCD相机、光源、光源控制器和工控机组成。工业机器人布置在安全围栏内,相机固定安装在机器人第六轴末端,拍摄图像时始终保持相机光轴所在直线与钢卷轴心所在直线垂直且相交。视觉光源安装在相机下方,光源中心轴与相机主光轴重合。工控机和光源控制器安装在围栏外的操作柜中。
传统视觉捆带识别定位系统和深度学习捆带识别定位系统均由上述硬件组成,两者的差异仅体现在算法层面。

图3 机器人末端视觉组件
1.2 系统软件
基于Visual Studio平台下的C#语言、halcon机器视觉算法库和百度飞桨PaddleX平台的深度学习目标检测开发包,编写了捆带识别定位上位机软件,使用WinForm设计了人机交互界面。软件能够控制CCD相机进行图像采集,通过图像处理获得捆带定位信息,并且能够对检测结果进行展示和保存,提高了生产过程的可追溯性。

图4 自动拆捆机器人系统上位机软件界面
1.3 系统工作原理
钢卷由运输小车输送至拆捆工位后,运载设备锁定,PLC发出拆捆指令,机械人左右移动机头,带动末端CCD相机对钢卷表面进行数据采集并进行视觉算法处理,通过事先计算出的标定矩阵将捆带中心位置像素坐标转化为世界坐标,引导机器人进行拆捆作业。捆带识别定位的具体流程如图5所示。
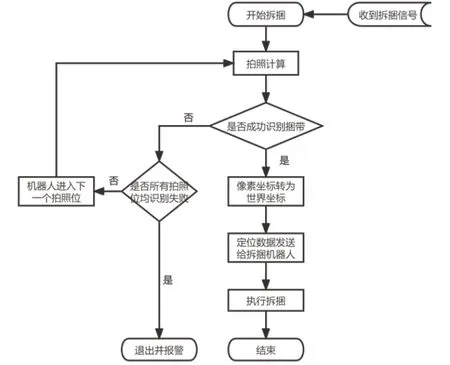
图5 捆带定位流程图
2 传统视觉捆带定位
为了解决部分工况下激光检测适用性较差的问题,引入视觉方案进行捆带定位识别。在捆带定位的需求中,待检捆带是宽度为32mm,厚度为1mm的均匀带状钢材,且紧密环绕在钢卷外表面。在不考虑钢卷运输过程中捆带发生严重变形的情况下,捆带自身的视觉特征一致性较好,基本满足传统视觉算法的使用条件。本系统传统视觉研发过程中分别采用边缘提取和模板匹配两种算法对捆带中心进行识别定位。
2.1 边缘提取检测算法
边缘提取捆带检测算法提取图象中捆带边缘的像素数据并加以分析判断进而定位出捆带所在的位置。该算法具体分为下几个步骤:
1)图像预处理,对捆带图像进行高斯滤波,消除部分噪声干扰;
2)边缘提取,利用canny算子对图像中捆带边缘的像素数据进行提取;
3)特征选择,设置边缘长度阈值,当检出的边缘像素数组长度在设定的阈值区间时认为该边缘为有效边缘;
4)直线拟合,通过最小二乘法对所有有效边缘像素坐标序列进行拟合[10];
由直线拟合的最小二乘法公式推导结果可知,离散点集(xi,yi)(i=0,1...m)的直线拟合结果为y=a*+b*x,其中:


5)宽度计算,设置边缘对宽度阈值,根据平面点到直线的距离公式为:
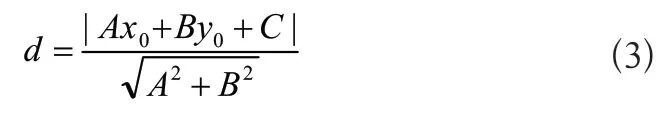
其中,A=b*,B=-1,C=a*
计算每条有效边缘的中点到其他所有有效边缘拟合直线之间的距离,作为有效边缘对之间的等效距离,有效边缘对之间的距离d在设定的阈值区间时认为该边缘对为识别出的一条捆带的两条边缘;
6)计算捆带中心,在识别出的捆带边缘对中,取其中一条边缘的中点像素坐标记为点M(xM,yM),点M到另一条边缘的垂足记为点N,M、V连线的中点P(xP,yP)即为捆带中心的定位点,其中:

利用上速算法对捆带进行识别定位的可视化过程如图6所示。

图6 边缘提取捆带识别
2.2 模板匹配检测算法
模板匹配是一种用于在较大图像中搜索和查找模板图像位置的方法,主要分为基于灰度的匹配方法和基于特征的匹配方法。基于灰度的匹配方法通过待测图像与模板图像之间的相关性定位目标也称为相关匹配算法,其工作原理是模板在原始图像上从原点开始滑动,计算模板与图像被模板覆盖区域的差异,找到图像中的与模板图像中最相似的像素点,再根据模板的宽度和高度,标记出对应的区域范围。基于特征的匹配方法主要通过提取待测图像的颜色特征、纹理特征、形状特征、空间关系特征与模板图像进行匹配。
相较于捆带材质不同和钢卷长时间热处理导致的图像中捆带部分像素灰度差异明显这一问题,捆带自身形状一致性较好,边缘特征明显,相对更适合基于形状特征的匹配算法进行模板匹配,选择halcon提供的creat_shape_model算子创建捆带模板图像,使用find_shape_model算子进行模板图像检出,通过匹配结果评分阈值控制检出目标的质量[11]。

图7 模板匹配捆带识别
2.3 传统视觉算法检测检出率计算
通过准确率(accuracy)、误检率(false)和漏检率(loss)三项量化指标评价传统视觉算法的精度。将传统视觉算法的检出结果和人眼观察结果进行对比,所有真实的捆带实例记为p,正确地检测为是捆带个数记为tp,错误地检测为是捆带的个数记为fp,错误地检测为不是捆带的个数记为fn,则有:
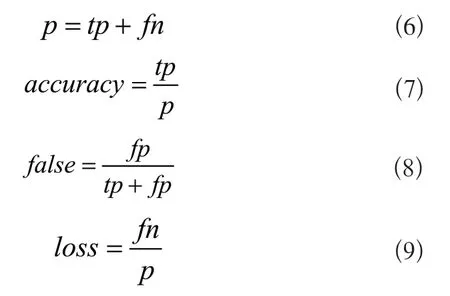
其中准确率作为算法的主要精度指标,误检率和漏检率作为参考项。
3 深度学习捆带定位
深度学习目标检测算法与传统视觉算法的特征提取方法有所不同,前者通过将大量待检图像数据输入卷积神经网络(CNN)进行自主学习的方式训练出用于预测目标分类和识别定位信息的推理模型。值得一提的是,每当数据集扩增时,都可将原有推理模型作为预训练模型和新的图像数据一起输入深度学习神经网络再次学习,这使得深度学习目标检测算法可以适应不断变化的环境和规则,从而对目标物体进行更准确的分类识别和定位。
3.1 深度学习目标检测算法
当前深度学习目标检测算法主要分为Two-stage算法和One-stage算法两类。Two-stage算法由两步组成,第一步由选择性搜索、边界框等方法生成候选区域,第二步结合CNN提取特征并回归分类。Two-stage算法检测准确率高,但检测速度较慢。典型的Two-stage算法有R-CNN、Fast R-CNN、Faster R-CNN以及Mask R-CNN等。One-stage算法则采用直接回归的方式同时进行候选区域选择和目标分类识别,这极大地提高了算法的运算速度但也导致了准确度有所下降。典型的Onestage算法有YOLO系列、SSD系列等[12~14]。本文系统研发过程中,分别选择Two-stage算法中高检测精度的Faster R-CNN算法,和One-stage算法中已在工业领域成熟应用的YOLOv3算法训练模型进行捆带检测。
3.2 模型训练
在硅钢FCL入口机组生产现场,通过工业相机采集了1177张照片作为捆带检测的数据集,经过数据标注、转换和切分后的VOC数据集包含训练集照片825张,验证集照片235张,测试集照片117张。通过PaddleX深度学习平台自带的训练接口加载卷积神经网络和训练集数据进行模型训练。训练端服务器的CPU为Intel(R)Core(TM)i9-10920X,主频3.50GHZ,GPU为NVIDIA GeForce RTX 3080,使用GPU进行深度学习训练,并通过CUDA架构的cudnn深度神经网络库加速。训练完成后对模型进行压缩剪裁,提高模型的推理速度。
3.3 深度学习模型精度评估
训练后对模型进行精度评估,评估过程中用到的指标主要有交并比(IoU)、精确率(Precision)、召回率(Recall)和平均精度(AP)。

图8 深度学习捆带识别
深度学习目标检测的预测结果是一个包含检测目标的预测框,将其记为PredictBox(PB),正确的标注框记为GroundTruth(GT),则IoU的计算公式如式(10)所示:
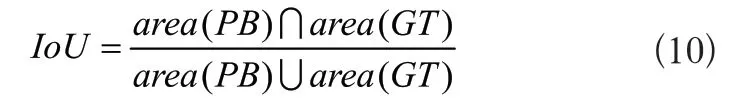
当IoU大于预设的IoU阈值时,认为目标检测结果有效。
精确率和召回率的计算公式如式(11)、式(12)所示:
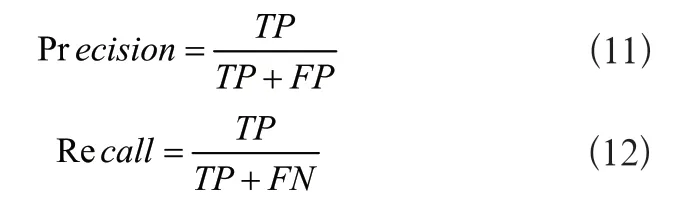
其中,TP为被正确地检测为正实例的个数,FP为被错误地检测为正实例的个数,FN为被错误地检测为负实例的个数。
对于本系统单一的目标种类这种情况来说,可以使用AP来反映模型的整体精度[15],将不同阈值下精确率和召回率之间的映射记为P(r),则AP的计算公式为:

4 实验与分析
为了验证上述传统视觉和深度学习捆带识别定位算法的性能,在硅钢FCL入口机组自动拆捆机器人系统调试过程中进行实验,现场部署端选用win7系统普通工控机,CPU为Intel(R)Core(TM)i7-8700主频3.20GHz,使用CPU进行深度学习预测。
将捆带数据集照片分别输入传统视觉算法接口、Faster R-CNN目标检测模型和YOLOv3目标检测模型预测接口进行检测,设置置信度阈值和IoU阈值均为0.8,分别计算传统视觉检测算法的准确率、误检率、漏检率和深度学习目标检测算法的精确率、召回率和AP,得到的测试结果如表1和表2所示:

表1 传统视觉捆带识别结果

表2 深度学习捆带识别结果
5 结语
1)传统视觉边缘提取和模板匹配算法在硅钢FCL入口开卷机组这种环境光照变化剧烈、捆带及背景钢卷表面特征复杂多变的情况下检测精度较低,无法满足自动拆捆机器人捆带识别定位的需求。
2)基于YOLOv3算法训练的深度学习捆带检测模型整体检测精度为90.85%,捆带识别的平均速度为4fps,能够满足硅钢FCL入口自动拆捆机器人的生产节拍和90%以上的拆捆率要求,经过优化后可以在性能较低的现场工控机上部署应用。
