基于链路变化的增量式动态网络社团检测模型
2022-10-01陈少剑付立东史丹丹
冯 健,陈少剑,付立东,史丹丹
(1.西安科技大学 计算机科学与技术学院,陕西 西安 710054;2.成都天软信息技术有限公司 宽频通信开发中心,四川 成都 610041)
0 引 言
复杂网络指将自然界中存在的大量复杂系统抽象为由节点和边形成的网络。大量研究表明,结构性和动态性是复杂网络的本质特性。结构性体现为社团,是指复杂网络中的节点呈现出以簇为特征的聚集状态,簇内节点联系紧密,簇间节点联系松散。动态性则指节点会持续地加入和离开网络,并且节点间链接的强度在不断变化,导致网络中的社团结构也随时间发生演化[1]。检测随时间演化的动态社团结构有助于揭示网络的组织原则和功能特性,理解网络演化的动力学过程,具有十分重要的理论和应用价值。
演化聚类法是动态网络社团检测的两种主要研究方法之一,总体思想是以历史时刻网络社团划分为基础,根据当前时刻网络的变化进行社团结构的调整。目前存在的主要问题包括:初始社团划分不精确,以及随时间推进或社团突变导致的累计误差。
为了解决这些问题,提出了一个改进的增量式动态网络社团结构检测模型LID(link increment based dynamic community detection method)。该模型除初始时刻、社团结构剧烈变化的时刻以及累积误差超过一定范围的时刻对全部节点进行计算外,其它时刻充分利用已知的社团划分结果进行补充计算,降低了算法的总体复杂度;同时有效解决了紧邻时刻社团结构剧烈变化的问题和累积误差的问题,对社团结构的变化具有较高的敏锐性。
1 相关研究
复杂网络中社团检测的研究起源于社会学的研究工作者Newman和Girvan等对静态社团的检测。最经典的算法是Newman等提出的基于分裂的GN算法,其基本思想是不断地找到介数中心性最大的边,通过将其删除来形成社团[2];Newman等提出的快速算法FN通过计算社团的模块度增量进行社团结构划分[2]。其它有代表性的方法包括谱聚类算法[3]、层次聚类算法[4]等,已形成较为成熟的理论体系。
国内外获取动态网络社团结构的算法可分为两大类:独立聚类法和演化聚类法。两类算法都将要分析的网络按时间分段,且都以每个时间片段为单位展开研究。早期的独立聚类法通常利用静态社团发现算法得到各个孤立网络快照的社团结构,然后在相邻时间片段间探索社团之间的变化。如Wang等对每个时间片段的网络进行矩阵分解得到社团结构[5],Yu等根据三方决策理论发现重叠社团[6]。在这些研究中,社团检测和社团演化分别在两个阶段进行,每个时刻单独进行的社团划分增加了冗余计算量,且忽略了不同时刻的影响关系。演化聚类法又分为进化式聚类和增量式聚类。进化聚类基于动态网络变化缓慢的基本特征,在对每个时刻的网络进行聚类时,既要使聚类结果与当前时刻网络的静态快照尽量一致,又要与历史时刻的网络结构差异较小。例如,Facetnet在获得初始社团结构后通过非负矩阵分解结构对其进行演化[7],文献[8]提出一种映射的方法定位成员和社团的关系,Li等则解决了多目标演化的问题[9];而增量聚类通常在前一时刻网络的社团结构上,基于当前时刻网络的变化更新社团结构。例如,Sun等通过滤除不变子图提高社团检测的效率[10];此外,还有其它研究将经典算法改进为增量聚类方法,如OLCPM通过局部社团更新检测重叠社团[11];DSBM算法首先通过随机块模型生成初始社区划分,然后通过节点在每个时刻的期望值,利用贝叶斯方法调整节点的社团归属[12]。这类方法采用动态更新策略,能充分利用前次检测的结果,因此运算效率较高;但随着时间的推移,由于累积效应使得聚类精度降低。另外,演化聚类算法大都需要人为设定社团数目,且假设社团数目在演化过程中不发生变化,这限制了算法的应用和推广。
综上,针对现有动态社团检测方法存在的问题,拟寻找一种高效的演化聚类社团检测算法,在保证聚类精度的同时,既能够满足社会网络在演化过程中变化较平稳的特性,又能够及时发现演化过程中出现的突发事件。
2 问题描述
动态社团发现所研究的对象是动态网络。动态网络G={G1,G2,…,GTOTAL} 是由TOTAL个时刻的网络组成的序列。表1给出了基本符号及其定义。
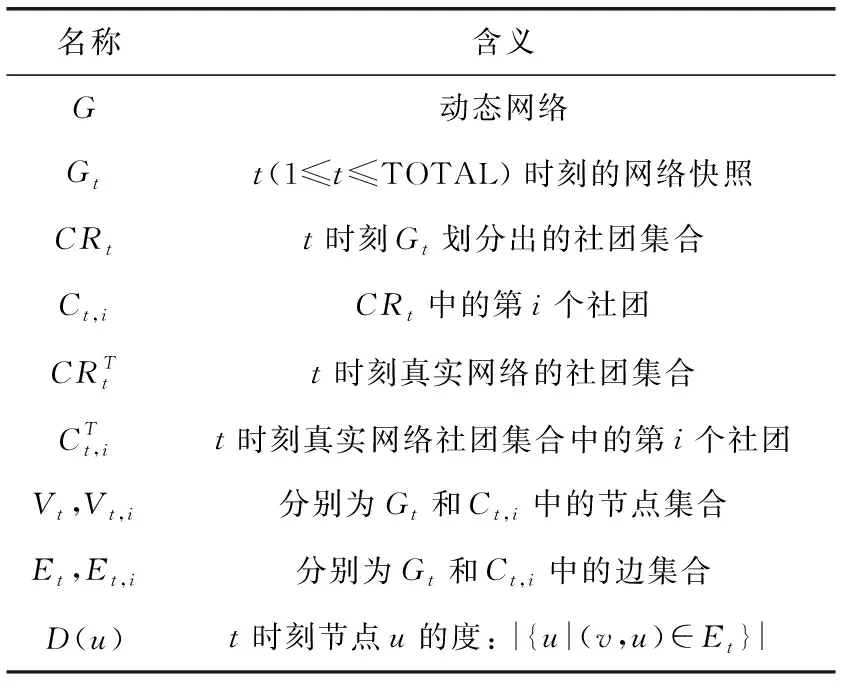
表1 基本符号
全文中 |x| 表示取x的个数,如 |CRt| 表示t时刻Gt划分出的社团个数。
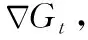
3 LID
3.1 总体思想
本文设计的动态网络社团检测模型主要包含静态社团检测和动态社团检测两个算法,其中静态社团检测采用GN算法。具体步骤如下:
(1)利用GN算法检测t=1时网络Gt的静态网络社团结构,获取初始的社团集合CR1。
(2)对t>1时刻的网络Gt, 如果相对于t-1时刻的网络发生了突变,则通过GN算法得到当前时刻的社团集合CRt; 否则,根据相邻时刻之间网络的增量相关节点及变化链路,通过动态社团检测算法对网络社团进行局部调整得到CRt; 判定动态社团检测算法划分结果的稳定性,若累积误差过大,则利用GN算法重新进行社团划分;记录该时刻的CRt。
3.2 LID模型设计
LID的出发点是充分利用前一时刻的社团划分结果合理高效地发现当前时刻的社团结构,并克服相邻时刻社团结构发生剧变以及增量聚类带来的累积误差持续增大的问题。算法的基本思想是,在初始时刻、社团结构剧烈变化的时刻以及累积误差超过一定范围的时刻,采用GN算法进行社团划分;其它时刻则在前一时刻社团结构的基础上,根据链路变化仅对社团结构发生变化的社团进行调整。获得当前时刻的网络结构后,计算其网络结构稳定性,判定结果是否有效。
具体地,在对社团结构进行增量调整时,将t-1时刻的社团结构CRt-1中在t时刻依然存在的点构成的集合记为CR′t。 若t-1时刻的社团个数为m, 在t时刻把所有新加入的点先放入新社团C′t,m+1, 则将CR′t和C′t,m+1合并即得到Gt的初始聚类结果 {C′t,1,C′t,2,…,C′t,m,C′t,m+1} 作为t时刻的预备社团。相比于Gt-1,Gt加入或删除了一些节点和边。如果把节点的变化映射为边的变化,则节点的增加可以看做是与该节点相连的边的增加,节点的删除可以看作是与该节点相连的边的删除。这些边的变化又可以分为预备社团内部的变化和预备社团与其它社团间边的变化两种。若在预备社团内部增加边,或在预备社团与其它社团之间删除边,则社团结构不发生变化,但得到增强,这样的社团称为增量无关社团;反之若在预备社团内部删除边或外部增加边时,社团结构发生改变,社团结构被削弱,这样的社团称为增量相关社团。在增量聚类时仅需对增量相关社团进行调整。
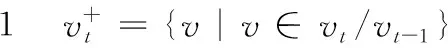
定义2 社团Ct,i内部边的数量IN(Ct,i)
(1)
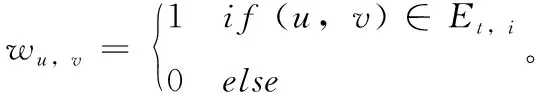
定义3 社团Ct,i外部边的数量OUT(Ct,i)
(2)
定义4 增量相关社团RCt, 是指相对于t-1时刻,内部删除边或者外部增加边的社团集合。定义为
RCt={Ct-1,i|IN(Ct-1,i)-IN(C′t,i)>0∨
OUT(C′t,i)-OUT(Ct-1,i)>0, 1≤i≤m}+{C′t,m+1}
(3)
定义5 增量无关社团NCt, 是指相对于t-1时刻,内部增加边或者外部删除边的社团。定义为
NCt=CR′t-RCt
(4)
定义6 网络变化度VAR(CRt-1,CR′t)
(5)
式中: |E′t,m+1| 为t时刻新增点的边数。这个定义通过网络中边的变化情况来衡量前后两个时刻网络的整体波动情况。在LID算法中通过判断该值是否超过阈值γ来判定网络在t时刻是否发生剧变。通过实验发现γ=0.6较为适宜。
定义7 社团稳定度STB(CRt-1,CRt)
(6)
该定义通过相邻时刻各社团重合节点数之和与两个时刻节点总数的比值,反映了相邻时刻社团集合的包含程度。该值越大,社团演化越稳定;反之,社团演化越剧烈。通过实验发现取阈值ω=0.7较为合适。
LLD模型的具体描述如下:
输入:Gt-1,CRt-1,Gt,γ,ω,m
输出:CRt
(1)CRt={};
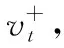
(3)若VAR(CRt-1,CR′t)>γ, 转至(4);否则:
1)找到CR′t中的增量无关社团NCt和增量相关社团RCt;
2)CRt=NCt;
3)通过GN算法计算RCt的社团结构CRtemp,CRt=CRt+CRtemp;
4)若STB(CRt-1,CRt)<ω, 转至(4);否则转至(5);
(4)通过GN算法计算t时刻的社团结构CRt;
(5)结束。
4 实验分析
为了定量验证本文所提模型的可行性和有效性,在真实网络和人工合成网络环境下与有代表性的动态社团检测算法分别进行了综合评测。
4.1 评价指标与对比算法
采用的量化指标如下:
(1)模块度
模块度Q是由Newman和Girvan提出的一种用于评价划分结果的重要指标[9],计算的是每一社团内任意两点连边与否和随机连边概率的差异。定义为
(7)
式中:M为网络G的边数总和,Aij为节点i和节点j的邻接矩阵;Ci和Cj分别是i和j所属的社团,当Ci=Cj时,δ(Ci,Cj)=1; 否则,δ(Ci,Cj)=0。 模块度的取值范围是[-1,1],值越大表示网络的社团化程度越高,相应地,认为社团发现算法性能越好。
(2)标准化互信息(normalized mutual information,NMI)
给定网络中真实社团CRT及其划分结果CR, 构建 |CRT|*|CR| 的混淆矩阵N, 其中每一行对应一个真实社团,每一列对应一个发现社团,Nij表示真实社团i和发现社团j重合的节点个数,Ni·和N·j分别即为矩阵第i行元素和第j列元素之和, |N| 为矩阵中的节点个数,则NMI(CRT,CR) 为CRT和CR两个划分的相似性[13],定义为
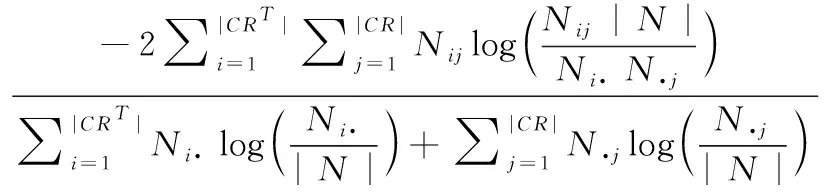
(8)
NMI的取值范围是[0,1],取值越大说明算法得到的网络结构和实际网络结构越匹配,算法的准确率越高。
综上可知模块度通过刻画社团内部节点之间的紧凑程度来度量社团结构的显著性,而NMI用来描述发现的社团结构与真实社团结构之间的相似性,即社团划分结果的准确度。
实验对比的方法为FacetNet[7]和DSBM[12]。其中FacetNet是一种典型的进化聚类方法,利用非负矩阵分解架构同时分析社团和它们的演化,而DSBM则是增量聚类方法,首先通过随机块模型生成初始社团划分,然后在每个时刻对节点进行期望值计算,再通过贝叶斯方法对节点的社团划分进行调整等。FacetNet方法中,设置alpha=0.8。 实验环境是主频为3.2 GHz,内存大小为16 GB的Intel Core i5处理器,程序运行环境为Matlab 2015b。
4.2 LID算法评测
采用真实网络和人工合成网络两类数据集验证动态社团划分的效果,数据集的基本属性见表2。
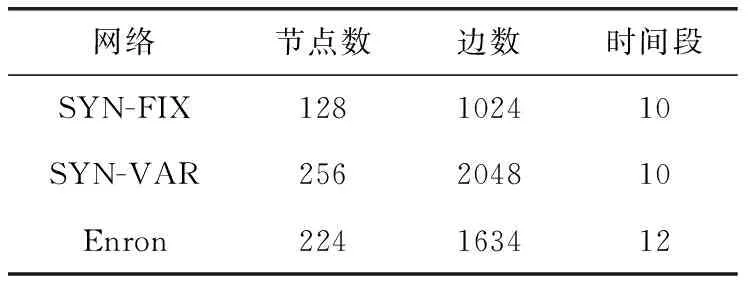
表2 动态测试网络的基本属性
(1)人工合成网络
采用文献[10]的方法生成两组结构已知的人工动态网络SYN-FIX和SYN-VAR。
SYN-FIX的大部分时刻社团数目固定。由10个时刻网络构成,每个时刻都包含4个内含32个节点的社团。为了模拟社团的动态变化,从第2个时刻开始,将每个社团中的3个节点随机放入其它社团。这些新加入的节点以较高概率和当前社团中的其它节点建立连接,以较低概率与其它社团节点建立连接。通过调节社团内部和社团外部连接的概率,保证平均节点度为16。
SYN-VAR也是由10个时刻组成,但每个时刻的社团数目都在发生变化。最初时刻网络包含256个节点,分成类似均匀的4个社团。从第2时刻开始,从每个社团中选择8个节点并生成一个新的32个节点社团,这个过程持续5个时刻,然后节点数目逐步恢复到最初的社团。因此,10个时刻的网络社团数目依次为4,5,6,7,8,8,7,6,5,4。
引入e参数控制动态网络中的噪声比例,它表示一个节点和其它社团中节点连边数平均值。我们进行了e=3和e=5两组实验,由于实验结果相似,限于篇幅,以下仅对e=3的情况进行分析。图1对比了LID、FacetNet、DSBM在SYN-FIX以及SYN-VAR上社团检测结果的模块度Q值和NMI。
从图1可以看出,对于结构变化较平滑的网络SYN-FIX,相比FacetNet和DSBM,LID得到的社团结构具有最好的Q值和NMI值。而SYN-VAR网络结构变化较大,LID除了在初始时刻NMI值低于DSBM,其它时刻取得最好的结果。这说明该方法能较好地探测各时间片的社团结构。另外,观察3种方法在上述两种数据集上的Q值和NMI的变化趋势也能发现,LID的社团检测结果比较稳定,FacetNet次之,DSBM随时间片的增加性能衰减严重。这是因为FacetNet是进化式方法,对任一时刻的网络社团划分都需要重新计算,这使得其社团划分的质量较高。同时虽然也保持网络结构变化的短时平滑性,但总体NMI值变化较频繁,不够稳定。而DSBM属于增量式方法,最初时刻社团采用静态划分算法,社团划分质量较高;但随着时间推移,累积误差使得社团划分结果与真实社团结构的偏离逐渐增大,导致严重的性能衰减,甚至不能有效区分社团;而LID克服了上述方法的缺点,在进行增量分析之前考虑了网络突变、在增量分析之后考虑了社团划分结果的稳定性,且在增量计算过程中仅对增量相关社团进行调整,不像DSBM那样调整幅度较大,这就使得LID能更好地处理网络变化,并有效化解累积误差。还有一点值得注意,那就是FacetNet和DSBM在计算时需要事先确定社团个数,而LID能自动识别社团个数。
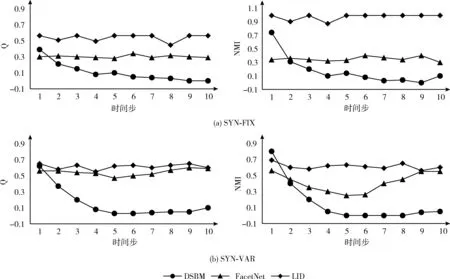
图1 在人工合成网络上社团检测结果对比
(2)真实网络
Enron邮件数据集是Enron公司内部的邮件联系网络[8],是高级管理人员之间的通信记录。由于在2001年内发生了标志性的事件(公司申请破产保护),导致网络发生突变,为了验证这一事件对社团结构的影响,本文实验截选时间跨度为2001年1月至2001年12月的数据集,以月为单位对应得到12个网络快照。
由于真实网络社团结构未知,我们采用了和QCA同样的方法得到Enron网络的社团结构[12],并以此作为计算NMI的基准。图2对比了LID和FacetNet在Enron上社团发现结果的模块度Q值和NMI。
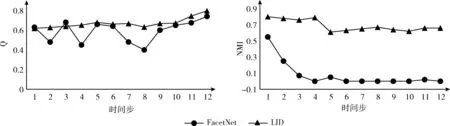
图2 LID和FacetNet在Enron网络上社团检测结果对比
从图2看出FacetNet的Q值在不同的时刻变化剧烈,NMI值则随时间推移有明显下降。这是由于FacetNet基于网络平稳发展的假设,通过非负矩阵分解来分析社团以及其变化,没有应对网络动荡的方案。而实际上,由于Enron公司在2001年12月申请破产保护,导致2001年内邮件网络各时间段社团结构不稳定,更在12月份发生突变。LID的Q值和NMI均好于FacetNet,说明它能很好地发现此类真实网络的社团结构。特别地,由于考虑了网络突变的情况,使得在对2001年12月这个时间片的网络进行分析时发现其发生了网络突变,因此重新采用GN算法计算社团结构,得到了准确的结果。
上述实验结果表明,LID能较好地探测到动态网络各个时间片的社团结构,且能有效应对现有动态网络社团划分中存在的累积效应和网络突变的问题。
5 结束语
针对已有动态网络社团检测方法不能很好地解决网络突变和累计误差的问题,提出了LID模型,根据链路变化实现增量式动态社团检测。在初始时刻和必要时刻,LID基于节点重要性进行静态社团发现,其它时序则依据链路变化实现增量式动态社团发现。特别地,提出将重要节点作为社团初始聚类中心的思想,也克服了演化聚类中进化式和增量式动态社团发现的固有缺陷。通过在多个数据集中的对比实验结果表明,LID能较好地探测到动态网络各个时间片的社团结构,且能应对网络突变和累积误差的问题,比经典的FacetNet和DSBM更稳定。
为了提升应用价值,未来还一些问题值得深入探讨。例如,①如何对算法进行并行化以加快算法的速度,使得其能够适用于超大规模的网络;②当前算法仅根据网络的拓扑图进行结构挖掘,而忽略了个体对社团形成的作用。如何对除结构外的其它因素进行分析将是下一步工作的重点。
