基于FFA-Net与YOLOv5的雾天行车障碍检测技术研究
2022-09-29赵世吉张金钊林立飞燕伟杰
赵世吉 张金钊 林立飞 燕伟杰
(山东科技大学交通学院,山东 青岛 266590)
为了提高雾天天气下行车安全感知的识别精度,保障无人驾驶的安全性。国内外在图像去雾算法、目标检测算法等方面进行了相关研究。
He等(2011)提出了一种利用暗通道先验知识进行去雾的方法,但该方法容易过度去雾,去雾后会造成大量信息丢失[1];基于Retinex理论,Jobson等(1997)提出了一种多尺度去雾算法,可以将失真图像的色彩恢复,但复杂度较高[2];Li等(2017)提出了AOD-Net算法,使用卷积神经网络联合估计全局大气光值和透射率来恢复无雾图像,使重建误差进一步缩小[3]。综上所述,大多数图像去雾算法在去雾时,去雾网络平等地处理图像像素和通道特征,不能区别处理雾浓度不同和通道加权的图像,所以本文选用FFA-Net(Feature Fusion Attention Network)算法[4],它可以具体对待不同的特征和像素,并基于注意力融合不同层次的特征,从而直接恢复无雾图像。
在目标检测方面,Girshick等(2015)提出了Fast-RCNN算法,大大地提高了训练和检测的速度,但存在候选区域建议速度较慢的问题[5];随后,Ren等(2017)提出了Faster-RCNN算法,具有较高的检测精度,但容易漏检小目标物体[6];2020年,Wu等提出YOLOv4算法,提出了CSPDarknet53特征提取结构,大大提高了检测精度和速度[7]。随后,在YOLOv4的基础上人们又提出了YOLOv5,在保证检测效率的同时进一步提升了检测精度。因此,本文选用YOLOv5网络模型作为行车障碍检测的基本模型,将YOLOv5与FFA-Net去雾算法相结合来对雾天障碍物进行检测。
1 FFA-Net去雾算法
如图1所示,FFA-Net由3个群结构(G-X)、通道注意力机制(CA)、像素注意力机制(PA)、卷积块四部分构成,每个群结构由19个基本块结构组成,每个基本块又包含卷积层、激活函数ReLU层、通道注意力机制(CA)和像素注意力机制(PA)四部分。
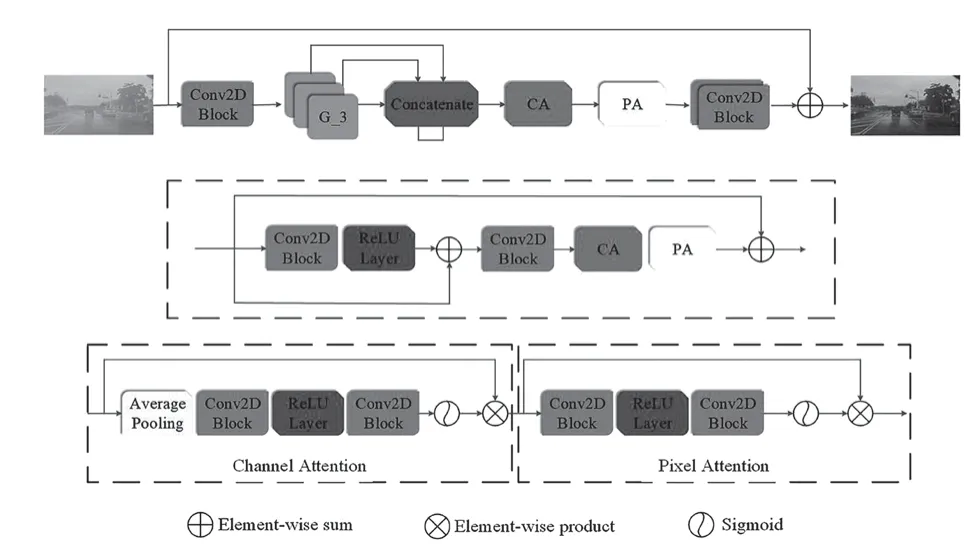
图1 FFA-Net网络结构
FFA-Net的去雾过程就是给定一幅雾天图像,然后经过一个卷积层进行浅层特征提取,接着被输入到3个具有多跳连接的群结构中,之后通过特征注意模块(CA和PA)融合3个群结构输出的特征。最后,融合后的特征会被传递到重构部分和全局残差学习结构,从而实现去雾。
2 雾天行车障碍检测模型
本文选用YOLOv5s网络作为行车障碍检测的基本框架,其模型架构如图2所示,整体结构主要包括Backbone、Neck和Head三部分。首先,Backbone是整个YOLOv5框架结构的主体,主要包括Focus、Conv、C3、SPP等基本模块。Focus模块可以对输入的图像进行切片。Conv模块是YOLOv5基本的卷积操作单元,负责对输入的图像进行卷积、正则化、激活等一系列操作。C3模块由一种经典的残差结构Bottleneck组成,输入数据经过两个卷积层提取特征后,再与原始特征进行Add操作,在维持原有输出深度的基础上,对残差特征进行传递。SPP模块负责对特征图进行最大池化操作,特征图利用Concat进行特征拼接,保持输出深度与原始输入深度相同。

图2 YOLOv5网络结构
如图3所示,雾天行车障碍检测模型主要包括FFANet去雾和YOLOv5模型训练两部分,本文首先利用已有训练权重直接使用FFA-Net进行去雾,去雾后输入到利用KITTI图像数据训练好的YOLOv5模型进行检测。本文设置了基于YOLOv5s检测框架分别检测FFA-Net去雾后的图像和带雾交通图像来进来行横向对比实验,从而验证本文雾天行车障碍检测方法的有效性。
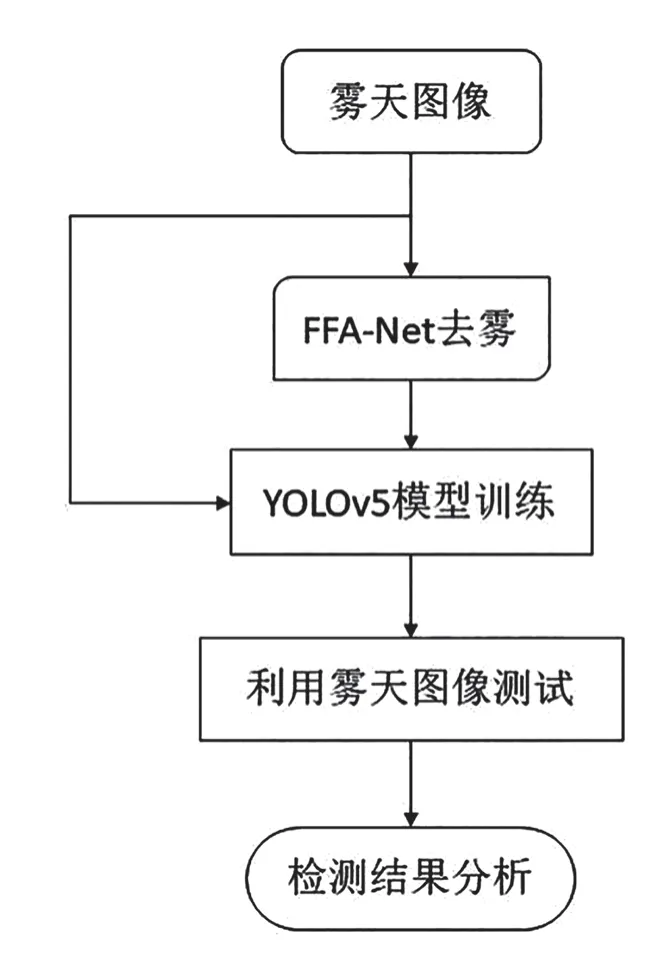
图3 雾天行车障碍检测模型构建
3 实验与结果分析
3.1 构建数据集
雾天行车障碍检测实验检测的障碍物主要有“Car”“Pedestrian”和“Cyclist”三个类别,实验的训练集选用KITTI [31]图像数据集进行模型训练,其中包括5 985张晴天交通图片用于训练,749张晴天交通图片用于验证。实验中雾天测试集由749张无雾图像基于Koschmieder定律依据大气散射模型添加不同程度的人工噪声所获得。
3.2 实验参数设置
实验利用GPU进行训练,显卡为NVDIA RTX 2060s,显存8 G,训练中batch size设置为16,共300个epoch,初始学习率为0.01,最终学习率为1,训练图像尺寸为[640,640]。基于上述方案,通过PyTorch完成对网络的搭建。
3.3 结果分析
3.3.1 损失函数收敛性分析
如图4所示,从损失函数的收敛特性可以看到,随着epoch的增加,网络中的各项损失在训练过程及交叉验证集中基本实现了收敛,可以证明研究中的YOLOv5训练模型是有效的。

图4 损失函数收敛性
3.3.2 检测结果分析
为了证实FFA-Net去雾算法与YOLOv5结合检测方法的有效性,分别采用YOLOv5常规训练、FFA-Net+YOLOv5常规训练两种方法对雾天障碍物进行检测,对两种方法用于行车障碍物检测与分类性能进行对比,结果如表1所示。
对于雾天障碍物的检测任务,由表1可知,使用YOLOv5常规训练模型直接检测雾天图片,Precision值、Recall值和mAP值均较低,分别为62.5%、48.3%、47.4%,由此可见,雾天天气因素会直接影响行车障碍物的检测精度。与YOLOv5常规训练模型相比,利用FFA-Net+YOLOv5常规训练模型对目标检测性能有了较大的提升,Precision值提升了30.2%,Recall值提升了34.4%,mAP值提升了41.8%。综上所述,FFA-Net+YOLOv5常规训练模型在雾天行车障碍检测实验中具有较好的鲁棒性。
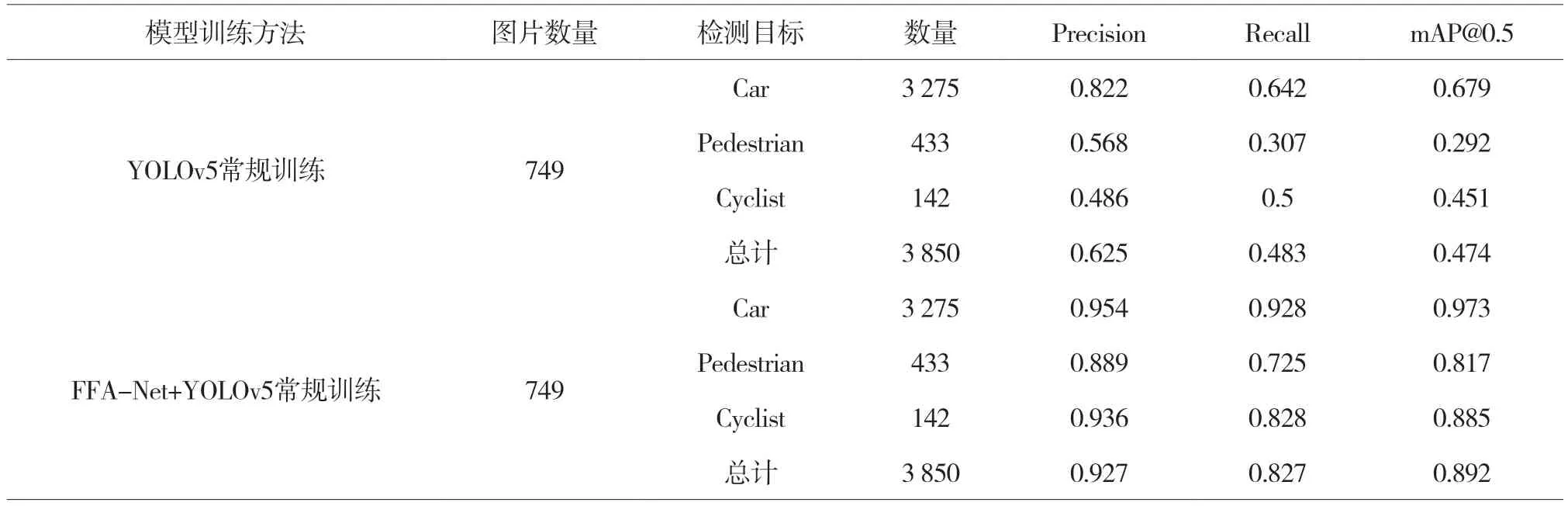
表1 两种检测方法在雾天图像测试集中障碍物检测性能对比
分别采用两种检测方法对雾天图像测试集进行检测,部分结果可视化如图5所示。直接使用YOLOv5常规训练模型进行检测,检测精度较低,大部分障碍物不能被识别出。相反,使用FFA-Net对大雾图像进行去雾后,再通过YOLOv5常规训练模型进行检测,行车障碍检测精度有了较大的提升。

图5 检测结果可视化
4 结论
本文将FFA-Net去雾算法和YOLOv5目标检测算法进行结合,针对雾天天气下交通场景中的车辆、行人和非机动车等障碍物进行检测。与直接使用YOLOv5算法进行检测相比,该方法在雾天行车障碍检测中,Precision提高了30.2%,Recall值提升了34.4%,mAP值提高了41.8%。FFA-Net的特征注意机制,使得图像中的雾浓度分布不均时,仍然能很好地对车辆和行人进行检测,具有较好的鲁棒性。由于本文的行车障碍检测方法包括去雾和障碍检测两部分,所以在实时性上仍需提高,在后续的研究中会对FFA-Net进行改进以缩短单幅图像去雾时间,从而提升雾天障碍物检测的实时性,进一步提高无人驾驶环境下的感知性能。
