基于地域特征的物流仓储中心逆向选址算法
2022-09-29苗将张仰森李剑龙刁艳茹
苗将,张仰森,2*,李剑龙,刁艳茹
(1.北京信息科技大学计算机学院,北京 100101;2.国家经济安全预警工程北京实验室,北京 100044)
随着京津冀区域经济的快速发展,完善京津冀区域物流一体化,将是京津冀高质量发展的突破口。物流是中国社会经济发展的重要组成部分,物流与经济之间相互影响、共同发展[1],是区域经济发展引擎中的重要齿轮[2]。物流仓储中心选址作为物流配送路径的根本源头,很大程度上决定了完成物流配送所需要的时间,对于大幅提升物流配送效率具有重要意义[3]。
王勇等[4]提出了一种基于数学视角物流仓储中心选址策略,即求一个点到多个确定点的距离最小。该方法属于数学正向求解,距离参数权重过于苛刻,缺少其他复杂约束条件支撑。物流仓储中心选址问题具有较多复杂的约束条件,具有非确定性多项式困难(non-deterministic polynomial hard,NP-hard)的性质。舒孝珍[5]提出了一种非线性规划模型求解物流仓储中心选址策略,注重了多级指标选取和计算。刘善球等[6]提出了一种基于遗传算法模型的物流仓储中心选址策略,通过引入概率的适应与突变增强求解能力。李卫星[7]提出了一种基于灰狼算法的物流仓储中心选址策略,通过引入扰动因子跳出局部最优。孟军等[8]提出了一种基于飞蛾算法的物流仓储中心选址策略,通过引入非线性惯性权重增加意外影响。虽然这些算法对于解决物流仓储中心选址问题起到了一定的效果,但仍陷入局部最优、搜索重点偏差和收敛速度慢等缺点。
为此,,基于京津冀物流发展的实际情况之上,提出了一种KMBR(K-means in Monarch butterfly with roulette)算法,通过建立物流仓储中心选址的数学模型,基于机器学习聚类特征,对标准帝王蝶优化算法进行改进,加入轮盘赌策略,为京津冀物流仓储中心选址的问题提供有力依据。
1 构建选址数据集
1.1 京津冀地区中心坐标
随着北京原密云和延庆撤县设区、天津原蓟县撤县设区,当地人员正式加入直辖市的管制,享受各种政策直接帮扶,促进政府资源的调度[9]。北京、天津各区和河北各地级市的政务中心是当地范围的核心地段,就业、居住、医疗、教育等资源都紧紧围绕,是人口集中的密集点。故通过百度地图开发者文档功能,确立各行政中心经度和纬度。
1.2 各地区经济适应量
北京和天津作为直辖市,其邮政管理局并未公布各区详细的物流数据,故提出经济适应量参数作为替代[10]。经济适应量的数学模型为
(1)
式(1)中:m为直辖市或省地级市;n为对应直辖市或省地级市所属的区域;Eij为当地区域的经济适应量;Pij为当地区域的常住人口;Yij为当地区域的15~69岁人口比例;Gij为当地区域的生产总值;Tij,total为当地区域所属的直辖市或省地级市的生产总值之和。
对区域进行脱密处理,以相应代号进行指代。故京津冀选址数据集如表1所示。

表1 选址数据集Table 1 Location data set
2 物流仓储中心选址数学模型
提出的物流仓储中心选址问题为,从X个直辖市和省地级市所属的区域中,确定Y个出发点作为物流仓储中心[11]。由于各物流仓储中心所处地理位置不同、面向区域不同,故建立带多种约束条件的物流仓储中心选址数学模型为
(2)
Dij≤Z
(3)
(4)
Ej≤V
(5)
式中:C为代价函数;X为直辖市和省地级市所属的区域的数目;Y为物流仓储中心数目;Ej为第j个区域的经济适应量;Dij为第i个物流仓储中心与第j个区域之间的距离;Tij为第i个物流仓储中心向第j个区域出仓发货;Z为当前区域到最远物流仓储中心的距离;V为当前区域物流仓储中心涉及的经济适用量总量。
式(3)表示每个区域的所需物品都必须有一个物流仓储中心完成出仓发货;式(4)表示一个区域的所需物品只能从一个物流仓储中心完成出仓发货;式(5)表示每个区域的经济适用量都应小于等于与其对应物流仓储中心涉及的经济适用量总量。
3 聚类算法
3.1 K均值聚类算法
聚类是一个将相似数据分类的过程[12],同类数据相似度尽可能大,异类数据相似度尽可能小。K均值聚类算法是一种无监督迭代聚类算法,采用欧氏距离作为相似度指标,力求同类数据与所在类的误差平凡和达到最小。K均值聚类算法基于以下规则:①从数据集中随机选择指定数量的数据作为初始的质心向量;②计算每个新加入的数据与各个质心向量的距离,将该数据加入对应距离最小的类别中;③重新计算质心向量。
基于上述规则,得出K均值聚类算法的迭代公式如下。
数据到质心向量距离的计算公式为
(6)
式(6)中:Xi为第i个对象;Cl为第l个聚类的中心;Xit为第i个对象的第t个属性;Cjt为第j个聚类中心的第t个属性。
质心向量更新计算公式为
(7)
式(7)中:Sl为第l个聚类中对象的个数。
3.2 改进K均值聚类算法
K均值聚类算法初始选择质心向量时是一个随机选取,单纯的随机选取易产生不同的聚类结果。且在更新质心向量时以各类均值为依据,若聚类中有一个远心点便破坏了聚类效果的紧密性。针对京津冀地域京津紧密,冀分散的特点,对K均值聚类算法进行改进。
对初始的质心向量选择引入单点密度和多点间距参数因子。单点密度是指以某一点为核心,以指定长度为半径的圆内其他数据个数。多点间距是指多个单点密度间对应的距离。聚类效果一般遵循同类距离较小,异类距离较大的准则。但在引入单点密度和多点间距参数因子后,如果两个点的密度都较大,且两个点之间距离较小,但这样的两个点都选做质心向量得到的聚类效果也是很好。改进K均值聚类算法的迭代公式如下。
单点密度的计算公式为
(8)
式(8)中:Sij为点i到点j之间的距离;Sb为指定长度距离。
多点间距的计算公式为
(9)
式(9)中:Pi为点i的单点密度;most为所有数据的单点密度最大值;SiI为点i到对应单点密度中最远点I的距离。
对应单点密度和多点间距的乘积较好的体现了各个数据点的综合性能,然后由高到低筛选并选取指定数量的乘积值,根据乘积值对应的数据作为初始质心向量。
4 帝王蝶优化算法
4.1 帝王蝶简介
帝王蝶作为世界上最知名的昆虫之一[13],是鳞翅目中唯一的一种迁移性蝴蝶。大部分帝王蝶为躲避北美的严寒,每年秋季都要从洛基山出发,向墨西哥中部进军。而剩余部分的帝王蝶则选择留下来,通过适应环境进行生存。
4.2 标准帝王蝶优化算法
帝王蝶优化算法(Monarch butterfly optimization,MBO)是受帝王蝶迁移和适应环境的启发,于2015年提出的一种优化算法。在MBO中,每只蝴蝶都看成一个粒子,决策变量的产生由粒子位置是否变动来表示。该算法通过模拟帝王蝶在自然界中的迁徙行为,其基于以下4个规则。
(1)所有的帝王蝶只位于陆地1(美国北部)和陆地2(墨西哥),即理想化的将整个帝王蝶种群由陆地1和陆地2的帝王蝶组成。
(2)每只子代帝王蝶都是由陆地1或陆地2的帝王蝶通过生育(迁移)产生的,即帝王蝶通过迁移产生了相应位置的变动。
(3)为了维护种群数量恒定,一只父代帝王蝶只能生育一只子代帝王蝶,且生育完成父代帝王蝶就会死去。若新生子代帝王蝶没有表现出更好地适应度,则子代帝王蝶被抛弃,父代帝王蝶保持完整(适应环境),即通过适应环境避免位置的变动。
(4)通过迁徙或适应环境获得最好适应度的帝王蝶,将自动运用到下一次选择中,该行为无法被任何操作终止,即确保了帝王蝶种群质量不会随着选择的增加而下降。
基于上述规则,标准帝王蝶优化算法的迭代公式如下。
迁移操作计算公式为
(9)
适应环境操作计算公式为
(10)
4.3 改进帝王蝶优化算法
标准帝王蝶优化算法具有一定的搜索能力和收敛鲁棒性,但当陷入局部最优解问题时,缺乏有效手段打破该局部极值,全局搜索能力不断降低,最终导致无法搜索出全局最优结果。根据京津冀区域的人口分布特点,引入轮盘赌策略对标准帝王蝶优化算法进行改进。
轮盘赌策略可以将个体数据被选中的概率与经济适用量数值大小构建正比关系,同时也能防止经济适用量较小的数据直接被丢弃。轮盘赌策略基于以下规则:①数据个体的选择概率,即经济适应度数值大小越高的数据,它被选中的概率就越大;②不同数据个体的概率累积,即将数据个体的选择概率从大到小进行累积,总和概率为1;③选择随机个体,即通过随机生成0~1的数字找到对应的概率区间,便选择该数据个体。
基于上述规则,轮盘赌策略的迭代公式为
(11)
(12)
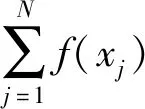
5 仿真实验与分析
5.1 实验数据和环境
为验证所提出的算法在逆向求解物流仓储中心选址问题中的正确性和有效性,采用京津冀选址数据集作为选址算例。采用Python框架进行相关模型的编码实现,在Windows10操作系统上采用Intel core i7-10750H处理器进行模型的训练和调试。
5.2 物流区域划分
为验证改进K均值聚类算法在区域划分的优秀性能,通过在京津冀选址数据集上划分6个区域,并与K均值聚类算法、K-modes聚类算法、K-medians聚类算法进行比较。同时提出了一种新的比较方法,通过引入固定点(114,36)作为起始点,再运用迪杰斯特拉算法得出6个区域的路径和,其路径和越小,所代表的聚类算法性能越优秀。改进K均值聚类算法区域划分结果如表2所示,4种聚类算法实验结果如表3所示。
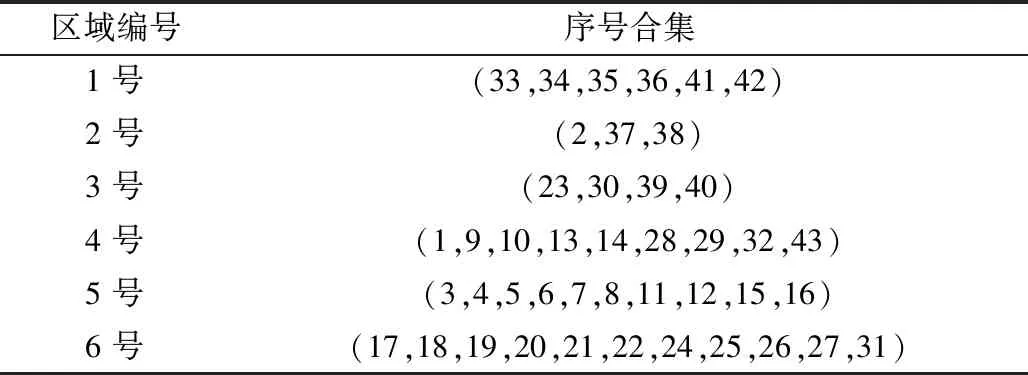
表2 区域划分结果Table 2 Regional division results
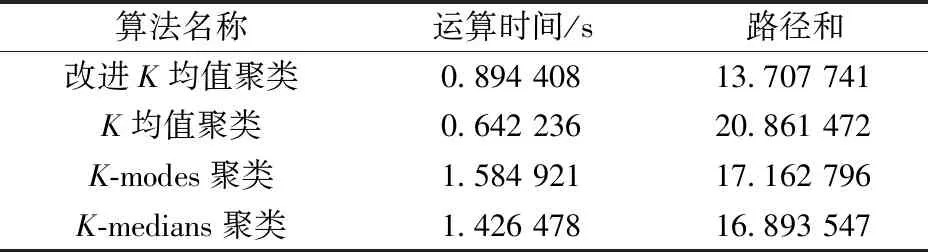
表3 4种聚类算法聚类比较Table 3 Clustering comparison of four clustering algorithms
对于京津冀选址数据集划分6个区域问题,改进K均值聚类算法取得了最小的路径和。因为改进K均值聚类算法是对K均值聚类算法进行了改进,增加了判定函数,故运算时间略高于K均值聚类算法,但同比低于K-modes聚类算法和K-medians聚类算法。故改进K均值聚类算法具有较好的区域划分性能。
5.3 物流仓储中心选址
通过改进帝王蝶算法对物流仓储中心进行逆向选址,从京津冀选址数据集提供的地理位置和经济适用量进行仿真实验,得出6个实际的经纬度坐标作为物流仓储中心的选址地点,并与标准鲸鱼算法(whale algorithm,WA)、标准萤火虫算法(Firefly algorithm,FA)和标准蝙蝠算法(bat algorithm,BA)得出的结果进行比较。同时提出对应区域内的所有数据点到选址点的距离和作为评价标准,距离和越小,该选址地点越优秀。改进帝王蝶算法求得的选址地点如表4所示,4种优化算法实验结果如表5所示。
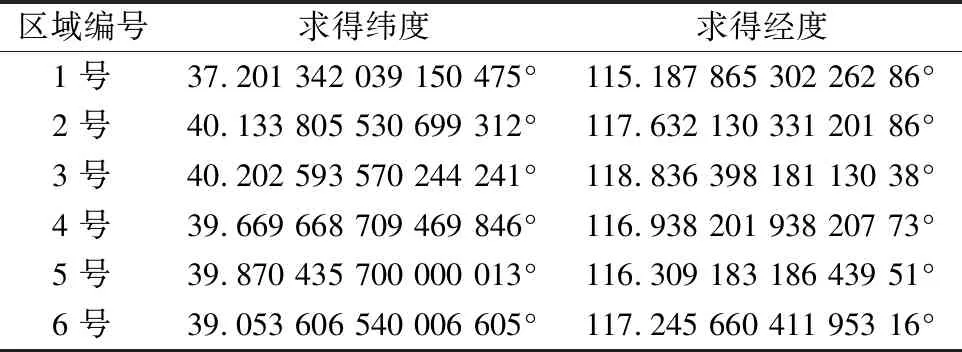
表4 6个区域选址地点Table 4 Six regional site selection sites

表5 4种优化算法选址性能比较Table 5 Comparison of location selection performance of four optimization algorithms
可以看出,相较于其他3种优化算法而言,改进帝王蝶优化算法对于选址策略具有更优的求解结果,表现方式为对应区域内的所有数据点到选址点的距离和最小。改进帝王蝶算法的迭代次数明显较小,算法运行时间也是最少,表明改进帝王蝶算法有着较高的收敛速度和求解速度。总体而言,相较于其他3种优化算法,改进帝王蝶算法可以更加快速、精准地逆向求解出物流仓储中心的具体地址。
6 结论
针对京津冀实际地域的物流仓储中心选址缺失的情况,考虑到人口、物流和经济三者之间的关系,提出一种基于聚类特征的改进帝王蝶优化算法,在满足精确求解选址前提的情况下,注重提高算法的全局搜索能力,提高了算法的收敛速度和经度,通过完成其他函数的对比试验,验证了算法的有效性,使其更加契合实际问题的解决。最终通过对算法构建模型,并完成仿真实验和相关分析,结果表明所提算法符合实际的需求,求解结果、迭代次数和收敛时间均优于其他算法,使得物流运输时间和成本都进一步降低。
