基于VMD与改进DAE人车地震动包络信号识别算法
2022-09-29刘文杰邹瑛珂张珊贾云飞
刘文杰,邹瑛珂,张珊,贾云飞*
(1.东南大学苏州联合研究生院,苏州 215127;2.南京理工大学机械工程学院,南京 210094)
近年来,随着中国科技工业高速发展,包括核电站、大型水电站、国家级数据中心在内的各种国家级重大设施的建成极大提高了中国人民的生活水平。但如何在这些敏感关键设施周边使用多种目标检测手段进行有效的安全预警成为了重要课题。针对人车目标,可以使用其移动所产生的地震动信号特征的不同对其进行识别探测,从而可以采取正确的对应措施以应对两类不同目标。为达到这一目的,需要一种可靠的特征提取与分类识别算法来对两个目标进行有效识别。
针对人车地震动信号识别所开展的研究相对较少,成果主要集中在对该类信号进行降噪的研究领域。严守靖等[1]利用卡尔曼滤波对该类信号进行有效降噪。但其主要是在沥青地面进行的,并不适用于野外的应用场景。以经验模态分解方法(empirical mode decomposition,EMD)为代表的分解算法虽然在该条件下对人车地振动信号的降噪分解表现仍然较好,但分解子信号数量不可控,并且其容易造成模态混叠、端点效应等固有缺点,使其不方便应用于实际场景中。为改善该缺陷,李奇等[2]也提出了利用Cubic Hermite插值改进EMD过程的方法,有效抑制了端点效应。但该方法并未解决模态混叠的问题,且分解出来的子信号数量不固定,影响实际使用。因此需要使用一种计算量可控,容易应用于实际环境中的相关算法来应对该种震动数据的特征提取。
目前,常用的特征提取方法有:过零点检测方法[3]、基于线性阵列包络线偏移叠加的检测方法、利用小波HHT变换来帮助识别人车信号的方法[4]等。上述传统算法在面对水泥地面等传震性好的路面表现较好,但面对野外硬质土地条件大都表现不佳,靠人工寻找合适的特征量不太能表征出两种目标的不同特征。而深度学习算法(deep learning,DL)的提出有效解决了这一问题。该种算法可从复杂数据中自动获取强表征性的特征,因此各种DL算法被运用到了模式识别、信号处理等多个领域。其中,深度自编码器(stacked auto encoder,SAE)因其对一维信号强大的特征提取能力被广泛用于信号的特征提取。但由于SAE属于一种无监督学习算法,因此提取出来的特征对分类问题的表征能力较弱,导致其效果不佳,因此需要进行改进。
针对人车地震动信号噪声较大,且找到合适特征量不易的问题,同时结合野外环境下采集的人车地震动信号成分复杂,噪声较大的特点,提出一套完整的信号特征提取与分类算法:首先对希尔伯特变换后所得的包络信号使用变分模态分解,并用相关系数对分解得到的本征模函数(intrinsic mode function,IMF)信号进行筛选,并将相关度较高的分量加权合成为高信噪比的中间信号,再对中间信号使用提出的改进深度自编码器——监督深度自编码器(supervised deep auto encoder,SDAE)进行特征提取,使用随机森林算法来强化算法的泛化能力,以期提高识别的准确率。
1 算法原理
由于地震动信号中除了人车地震动有效信号外还包含了大量由于动植物活动和采集设备本身干扰而产生的高频噪声信号,因此需要对其进行包络检波解调以提取其较低频的有效地震动信号。
希尔伯特变换(Hilbert transform,HT)是一种常用的提取信号包络线的方法。能将低频信号从被调制过的信号中解调出来,是在该变换方法可以看作是一个正交滤波器,可将所有的正频率分量移相-90°,对负频率分量移相90°,从而能将一个实信号变换为一个复信号的虚部。通过求解该复信号的幅值即可求得原信号的包络,将其低频分量解调出来[5]。因此常被运用于包络检波等领域。
一个实信号x(t)的希尔伯特变换定义为

(1)



(2)
得到该复信号后,通过求其幅值则可得到其复包络信号为

(3)
该复包络信号则为较高信噪比的有效信号。
1.1 变分模态分解与相关系数
即使原信号的包络信号已经过滤了大多数的高频噪声信号,但仍然保留了能量较高,频率较低的噪声信号,导致原信号的包络信号仍然是一类低信噪比的非线性、非平稳信号。针对该类信号一般使用EMD将其分解为多个平稳信号后再进行处理。但此方法容易产生波形混叠、端点效应等负面现象,严重影响对信号的分解。且由于自身迭代算法的原因,分解得到的IMF信号数量无法确定,影响该算法在实际场景中的应用。针对以上缺陷,2014年,一种全新的自适应分解方法——变分模态分解(variational mode decomposition,VMD)[6]被提出,该方法不但可以极大程度缓解EMD的模态混叠的缺陷,且分解出的IMF分量数量可以人为设置,以准确分解出不同频率段的信号,其核心是通过迭代搜索约束变分模型的最优解来自动获取固有模态函数的带宽以及核心频率,从而按照频率对信号进行分解。利用其约束变分模型引入二次乘法因子来降低干扰,同时使用拉格朗日乘子法将其转化为非约束变分问题。最后得到增广拉格朗日表达式为[7]


(4)
式(4)中:δ(t)为冲激函数,是信号处理基础函数;f为原始信号;uk为所得模态函数;ωk为各个模态中心频率;α为惩罚因子;λ为拉格朗日因子;∂t为对其求时间的导数;K为分解信号的个数;k为第k个分解信号。
最后利用交替方向乘子法迭代更新ωk、uk、λ从而求得该模型的解。由于参数中有ωk,因此将uk转化至频域,最后可得更新公式为[8]
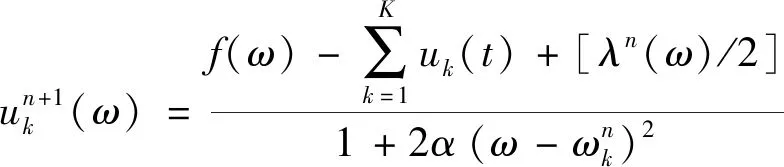
(5)

(6)

(7)
式中:ω为频率;n为迭代次数。

为过滤掉信号中含有的噪声,需要对分解得到的IMF信号与原信号的相关程度进行量化,以筛选出与原信号相关程度最高、在原信号中占有主要成分的IMF信号。因此,使用皮尔森相关系数ρXY对其进行衡量,可表示为

(8)

通过筛选并进行加权则可得到高信噪比的中间信号,以便进行下一步工作。
1.2 自编码器与深度自编码器
自编码器(auto encoder,AE)结构类似BP神经网络,属于一种典型的三层结构的神经网络,其结构如图1[7]所示。

图1 自编码器结构[7]Fig.1 Self encoder structure[7]

H=f(WX+b)
(9)

(10)
式中:W为输入层到隐层的权值向量;Wo为隐层到输出层的权值向量;Zi为隐层输出;b为输入层到隐层的偏置向量;bo为隐层到输出层的权值向量,以上参数与隐层都是需要求解的向量集合;f(·)为激活函数。
由于使用权值和偏置后只能表征输入层与输出层的线性关系,因此需要引入激活函数来加入非线性因素。通常使用sigmoid函数或tanh函数。使用的激活函数为双曲正切函数,变化敏感区间较宽,可将信号压制到[-1,1],导数值渐进于[0,1],符合人脑神经饱和的规律,与sigmoid函数相比可以延迟函数饱和期,可表示为[8]。

(11)
神经网络中用损失函数衡量网络输出与期望输出的误差,该处的损失函数采用均方损失函数,可表示为

(12)
式(12)中:MSE为损失函数值;n′为维度总数;y′i为网络输出向量第i维度的值;yi为网络输出向量第i维度的值。
利用损失函数对W、Wo、b、bo进行反向传递更新可表示为

(13)
式(13)中:N为需要调整的相关参数(即W、Wo、b、bo);ε为学习率。
利用梯度下降法进行迭代计算,使得期望输出与网络输出无限接近,完成网络训练,其隐层向量即为自编码器所自动提取的特征向量。
由于AE只是一个三层网络结构,其提取的特征较浅,针对高维输入向量不能很好地表征其特点。因此需要增加多个隐藏层得到可以提取深层抽象特征的深度模型——深度自编码器。该深度模型网络以前一层输出作为下一层输入,与单个AE相比,DAE可以深度挖掘数据的信息,基于以上功能,其常被运用于各种故障识别、含噪信号降噪、特征提取、数据清洗等方面[7],其拓扑图如图2所示。

图2 深度自编码器结构示意图Fig.2 Deep self encoder structure
在深度自编码器中编码器和解码器的输出公式分别为
Zi=f(WeXi+be)
(14)
Zo=f(WoZi+bo)
(15)
式中:We、Wo分别为编码器和解码器的隐藏层权重矩阵;be与bo分别为编码器和解码器对应偏置向量。训练完毕后将测试集放入网络中进行计算,取其编码特征则可得到信号的特征向量。
1.3 监督深度自编码器
由于深度自编码器属于一种无监督机器学习方式,未能利用到数据集中所给出的标签,因此其提取的特征对该种标签的表现性不强,进而造成分类效果较差。因此为了在特征中包含数据集的标签以提升分类效果,需要对深度自编码器进行改进。
为了利用训练数据集中所有的标签,深度自编码器的改进型——监督深度自编码器(supervised deep atuo encoder,SDAE)在最后一层输出层中,加入了标签神经元并对其进行全连接。改进后的深度自编码器拓扑结构图如图3所示。

图3 监督深度自编码器结构示意图Fig.3 Supervised Deep self encoder structure
训练完毕后将待提取特征的数据集放入网络中进行计算,最后取其编码层则可得到包含标签信息的高可分度特征向量。
1.4 随机森林算法
随机森林(random forest,RF)运用Bagging的思想,对训练集进行有放回的随机抽样生成很多分类树共同对数据进行分类判断,每个树都是一个独立的判断分支,互相之间彼此独立。由于其训练样本较为独立,因此生成的每棵树对特征的关注点各不相同,所形成的随机森林泛化能力比传统的支持向量机算法(support vector machines,SVM)强。由于其核心仍是决策树算法,所以无论是判断过程还是训练过程的计算量都较小。其生成过程如下。
步骤1利用Bagging法从原始数据集中重采样有放回地抽取N个数据集作为对应决策树的训练集。
步骤2生成多棵决策树。从训练集评估出最好特征作为当前节点的分类属性并分裂成2支。评估方法采用基尼指数Gini,可表示为[9-10]

(16)

(17)
式中:D为整个训练集集合;Ck为训练集中每种样本的数目;D1、D2为每个按特征分类的两种类别集合。
基尼指数越小代表集合不确定程度越小,取基尼指数最小的特征作为当前最好特征。
步骤3在分裂处的两个分支重复步骤2,直到w2样本全部分类完毕或达到指定生长层数。
2 信号仿真实验
基于所述的特征提取算法计算步骤如下。
步骤1去除数据偏置后对数据进行希尔伯特变换,获取其包络线,对其平滑处理与归一化并分帧得到数据样本集。
步骤2对样本集进行VMD分解,求所得IMF信号的相关系数,按照相关系数的大小加权得到高信噪比中间信号。
步骤3将数据集投入监督深度自编码器中进行训练,用于提取特征向量,再对得到的特征向量使用随机森林分类算法得到该模型的分类结果。
算法流程图如图4所示。

图4 算法流程图Fig.4 Algorithm flow
2.1 数据预处理
在晴天、低速风(风速不高于3级)、均质土壤的环境中通过美国国家仪器有限公司(National Instruments,NI)采集卡和VAS-100地震动传感器获得人车原始信号,采集频率为1 000 Hz。地震动传感器插入地表大约20 cm处位置,测试车辆为某品牌SUV,在距离传感器100 m匀速向着传感器方向行驶;测试人员为单人,从距离传感器50 m处向着传感器方向正常匀速行走。某帧车辆和人员的原始信号如图5和图6所示。

图5 车辆原始信号Fig.5 Vehicle original signal

图6 人员原始信号Fig.6 Person original signal
由于信噪比较低,因此必须对其进行希尔伯特变换以获取其包含较纯净人车地震动信号的包络线。由于包络线中仍然含有高频噪音,因此需要使用滤波算法将其滤除。通过观察可以看出,人行走所产生的冲击信号是一种类冲击信号,进行的平滑滤波处理不可以过滤该类信号。考虑到二者性质,使用滑动平均滤波可使信号平滑的同时保留冲击信号特征,其滤波公式为

(18)
式(18)中:nf为帧长,nf取1。
将所得到的人车地震动信号分为2 s一帧的样本集,通过希尔伯特变换并滤波后得到其包络线如图7和图8所示。

图7 车辆包络线信号Fig.7 Envelope of vehicle signal

图8 人员包络线信号Fig.8 Envelope of person envelope signal
可以看出,人员信号的包络信号把人行走时脚步落下所产生的信号很好地保留了下来,频率较低。而车辆信号的包络线在一帧内具有多个波峰且连续,频率较高。但二者信号仍然含有部分中高频噪声。
2.2 VMD分解实验
将所得到的人车地震动信号包络线分为2 s一帧的样本集,得到图9、图10所得实验信号。以不同的K值(分解信号数量值)进行VMD分解,观察分解所得IMF信号。经过实验分析,当K>4时,利用VMD分解所得到的信号中相关系数排序前3的IMF信号就可以完整表征车辆的高频连续信号特征(IMF1、IMF2、IMF3)。VMD分解所得信号如图9所示。

图9 车辆包络线VMD分解结果Fig.9 VMD decomposition results of vehicle signal’s envelope

图10 人员包络线VMD分解结果Fig.10 VMD decomposition results of person signal’s envelope
对于人员信号,需要使K>6,利用相关系数排序前3的IMF信号(IMF4、IMF2、IMF1)才可得到能够完整表征人员的低频连续信号特征。VMD分解结果如图10所示。
因此选择K=6时分解所得到的相关系数排序前3的IMF信号进行加权得到纯净中间信号。经过试验,由于相关系数排序第3的IMF信号表征人车信号特征的效果统计意义上劣于排序前2的IMF信号,排序前2的IMF信号效果在不同信号样本中优劣各不相同,针对以上特点得到加权公式为
u(t)=0.4IMF1(t)+0.4IMF2(t)+0.2IMF3(t)
(19)
式(19)中:IMF1(t)、IMF2(t)、IMF3(t)分别为相关系数排序第1、2、3位的IMF信号分量。
加权得到的人员与车辆信号如图11、图12所示。

图11 VMD加权后人员地震动包络线信号Fig.11 Personnel ground motion envelope signal after VMD weighting

图12 VMD加权后车辆地震动包络线信号Fig.12 Vehicle’s ground motion envelope signal after VMD weighting
可以看出,噪声分量信号强度得到了较大幅度降低,很好地保留下了人车地震动信号的特点,为后续提取特征提供了高信噪比的中间信号。
2.3 改进深度自编码器特征提取实验
样本分别投入所提改进型算法与深度自编码器算法中进行训练与特征的提取,学习率lr=0.003,训练轮数epoch=80,特征编码维度为64。其网络构造如图13所示。
训练完毕后取第6层作为64维的特征向量。为了验证提取的特征聚类情况,对提取到的特征进行核主成分分析(kernel principal component analysis,KPCA)[11]将维度为64的特征向量转化为二维向量将其可视化,两种算法结果分别如图14、图15所示。

数字表示每一层神经元的数量图13 监督深度自编码器模型构造Fig.13 Construction of supervised depth self encoder model

蓝点为人员信号;红点为车辆信号图14 DAE特征提取分布Fig.14 DAE feature extraction distribution

蓝点为人员信号;红点为车辆信号图15 SDAE特征提取分布Fig.15 HT-SDAE feature extraction distribution
两种算法特征提取人车信号分布聚散情况比较分明,但监督深度自编码器所得特征更加线性可分,因此SDAE特征可分性更强。但从图15中可以看出要实现该类数据的分类需要使用泛化能力较强的分类器。
2.4 随机森林分类实验
将所得的特征编码、其他传统方法所得特征量使用随机森林算法进行训练并进行测试。车辆训练样本数量为200组,人员训练样本数量为200组,车辆测试样本数量为200组,人员测试样本数量为200组,测试样本和训练样本相互独立。并与使用DAE-SVM[12]、SDAE-SVE、DAE-RF算法的测试结果进行对比,对比结果如表1所示。
由表1可知,若不经过VMD加权直接使用DAE进行特征提取,识别率较低,而使用VMD加权后由于过滤掉了大多数的噪声信号,使后续提取的特征更能体现数据的种类,整体识别率提高了6%。

表1 本文算法与其他算法识别结果比较Table 1 Comparison of recognition results between the proposed algorithm and other algorithms
而在特征提取方面,所提出的监督深度自编码器算法在训练过程中考虑到了训练集的标签,因此所提取出来的特征更具区分度,和原特征提取算法相比,在未显著提高识别过程中计算量的同时识别效果更好。
若使用SVM算法[10]作为分类,由于该算法的泛化性能较为平庸,因此针对该类数据的分类正确率低于RF算法。而利用同种特征提取算法,采用较高泛化性能的随机森林算法的实验中其分类正确率较SVM分类算法有所提升。
3 结论
针对在野外环境中对人车地震动信号进行正确识别这一问题,提出了通过希尔伯特变换提取包络线来实现降噪,并在深度自编码器的基础上提出改进型自编码器——监督深度自编码器对包络线的特征量进行自动提取。最后使用随机森林分类算法进行人车识别。通过实验可得出以下结论。
(1)使用VMD分解得到IMF信号再通过相关系数选择加权后生成的中间信号相比于原信号,能够有效过滤掉频率相近能量占比较高的噪声信号,从而较大幅度提高信噪比。
(2)使用的改进深度自编码器算法相比于未改进的深度自编码器算法特征针对人车地震动信号的特征提取结果可分性更好,同时计算量并未有显著提升。
(3)针对人车地震动信号,选用泛化能力强的随机森林分类算法分类结果优于传统SVM算法。
