基于大数据的交通运输公众评议指数设计及应用
2022-09-28刘勇凤成倩倩李绪茂
李 弢,刘勇凤,成倩倩,李绪茂
(1.交通运输部规划研究院,北京 100028; 2.综合交通规划数字化实验室,北京 100028)
0 引言
交通运输是经济社会发展的“先行官”。经过改革开放40 a来的不懈努力,我国已迈入交通大国行列,基础设施网络规模居于世界前列,客货运运输量稳居世界第一,科技创新处于世界先进水平。当前我国已迈入建设社会主义现代化强国阶段,对交通运输提出了更新更高的要求,交通运输的开路先锋作用日益增强,因此我国交通运输事业发展的当务之急是加快实现从交通大国向交通强国的转变。党的十九大提出了“交通强国”发展战略,需要综合推进交通运输业各方面共同进步,包括基础设施的发展、服务水平的提高、转型工作的落实等等[1]。实现“交通强国”战略,首先需要对我国目前的交通运输综合服务能力进行科学客观的评价。
互联网的飞速发展为建立更加准确真实的评价体系提供了新思路。近年来,互联网规模持续增长、成果显著普惠化。在交通运输方面,我国网络出行服务发展迅速,在线购票服务已成为人们长途出行的主要选择。同时,依托共享经济形成的共享出行市场也在不断发展。截至2021年底,我国网约车用户总规模已超过4.5亿人,基于互联网的交通出行业务逐渐普及,大量公众出行的交通运输行业数据也被相关企业收集积累起来,行业大数据由此产生。通过对相关海量数据挖掘与应用,可对目前交通运输行业发展情况进行整体评价。
为了更好、更真实地反映我国交通运输业的综合服务能力,本研究提出4类新型的基于大数据的交通运输公众评议指数,包括客运企业评议指数、货运企业评议指数、运输行业十大事件公众舆情情感度指数、1次死亡10人及以上道路运输行车事故舆情情感度指数。上述指数基于大型运输服务企业的在线评价或在线社交应用上发布的交通运输相关内容,综合公众对于其提供的直接或第三方服务的评价、意见、投诉等,通过文本分析方法对其整体表现进行综合评价,并得出相应指数。
1 文献综述
基于大数据的评议指数较传统指数,其来源更加直接,内容更加全面,对于信息的挖掘更加深入,能够作为对传统评价指标的补充。一般来说,基于大数据的评议指数主要包含舆情分析、公众评议、服务评价等若干方面。
1.1 舆情分析
舆情分析是指针对某一社会热点问题,通过社交媒体等渠道了解民众对该问题的态度,并对其进行分析研判,进而提出相应的舆情引导策略[2-7]。舆情分析的发展主要包括以下3个阶段:传统舆情分析、基于互联网的舆情分析、基于大数据的舆情分析。
随着大数据时代的到来,越来越多的研究者采用大数据分析技术对社会热点问题舆情进行分析。
1.2 公众评议
公众评议是通过搭建公共对话平台,让我国民众有效参与到政府绩效评估的形式之一。公众评议作为政府绩效管理的重要组成部分,对公共服务水平的提升和公众满意度的提高都具有重要影响。
互联网的不断发展与普及,为公众评议带来了新的发展方向,如在线电子政务的产生带来了网上评议的新模式[3]。然而,在实践过程中,出现了参与程度低、评议结果不透明等问题[4]。
目前,各省(市、县)交通运输厅(局)均采用公众评议方法收集群众意见,经过整合相关建议后,确定进一步的整改方案,同时进行交通运输服务的绩效考评。已有的公众评议渠道包括12328交通运输服务监督电话系统、相关部门电子政务网站等。
1.3 综合运输服务能力
提高交通运输服务能力要求构建普惠均等、便捷高效、智能智慧、安全可靠、绿色低碳的综合运输服务系统,不断优化升级,进而增加社会公众的满意度和获得感[5]。
为了有效衡量我国综合运输服务体系的发展成效,需提出科学客观的指标体系对公众满意度进行评价[6]。依照交通运输行业的分类规则,综合运输服务能力可分为客运服务能力和货运服务能力。同时,“安全可靠”作为交通运输服务能力的重要体现之一,也应对公众态度加以考量。
1.4 基于大数据的综合运输服务能力公众评议
由于传统的公众评议方法存在参与度低、数据失真等问题,将基于大数据的舆情分析与已有的政府绩效公众评议方法结合起来,利用大数据海量、真实的特点弥补传统公众评议数据收集过程中存在的问题。提出基于在线社交媒体的海量数据,从民众的日常发布内容中发掘其对于交通部门公众服务能力水平的态度。在此基础上,为更加全面地衡量综合运输服务能力,分别对货运、客运、运输行业10件大事和1次死亡10人及以上道路运输行车事故4个方面的舆情展开分析,分别得到相应的评议指数[7]。
2 评议指数计算模型
基于大数据应用的综合运输能力评议指数模型(以下简称 “综合评议模型”),是结合机器学习模型与自然语言处理模型,对民众在社交媒体等平台中发布的交通运输相关内容进行综合分析后加权得出相关指数。综合评议模型的应用架构如图1所示,主要包含数据收集、数据预处理、模型训练、指数计算4个部分[8]。

图1 评议指数计算框架Fig.1 Evaluation index calculation framework
2.1 数据采集
首先,确定数据来源。为了能够全面地对我国交通运输客货运、重大事件、重大安全事故等方面的公众态度进行分析,针对上述4个方面选择了5类数据源。其中,共享交通平台、在线票务平台、出行服务平台用来进行客运企业评议指数的测算,电子商务平台用来进行货运企业评议指数的测算,社交媒体平台则用来进行各领域(客运企业、货运企业、重大事件和重大安全事故)公众情感度的测算[9]。
其次,确定搜索关键词。根据平台对应指数进行数据爬取,如在线票务平台和出行服务平台中,以“火车”、“航班”、“机场”等词语作为关键词,在海量评价数据中进行搜索,得到需要的发布内容。其中,运输行业10件大事和1次死亡10人及以上道路运输行车事故的搜索关键词可参照中国交通新闻网等网站公布的年度报告[10]。
而后,针对不同平台的特点进行文本数据的爬取。部分平台为研究者提供数据接口,通过调用相应接口即可得到所需数据。部分网站平台可以通过网络爬虫等方式,将数据由线上下载到本地数据库,以便后续处理。确定爬取模式后,根据需要频率定期获取数据[11]。
2.2 数据预处理
数据预处理主要包括数据清洗、数据集成、数据转换3个流程。
数据清洗从样本和词语2个层级分别进行。首先,删除重复的、内容过短(少于10个字符)的样本;其次,对爬取到的文本进行处理,将其中包含的数字、链接、停用词、标点符号、空白符、特殊字符等去除,只保留具有实际意义的文本。
数据集成是将文本的内容按照综合运输服务能力的4个方面分别进行融合。后续模型构建的工作将分别在细分好的4个数据集上进行。
数据转换是指随着增量数据的不断累积,根据适合的数据结构对数据本身进行转换。
2.3 模型训练
为了能够更好地综合评价运输服务能力,将分别从文本的内容和文本的感情值2个方面对其进行衡量。
2.3.1 文本分类器
训练文本分类器的过程中,首先要对文本特征进行提取,常用的文本向量特征表示方法包括文本分词、词集模型、词袋模型等。在将文本进行向量化处理后,通过机器学习模型对文本进行分类,常用的模型包括传统的机器学习模型及深度学习模型等。基于Lu等[12]的研究,在试验中采用独热码(one-hot encoding)对文本特征进行提取和表示,而后采用卷积神经网络模型对文本进行分类。
训练领域分类器的过程中,首先将搜索文本时使用的标签所属领域进行融合,如“航班”、“机场”、“机票”等标签下的文本内容归为“客运空运”,并将归纳好的大类作为因变量展开训练。
训练内容分类器的过程中,首先应用无监督机器学习方法(如聚类)基于文本特征向量的相似性对样本进行划分。而后,根据领域知识,对划分后的类进行合并标注,得到有标签样本;应用标注后的样本训练机器学习分类模型。
在对增量文本进行判断时,对分类错误的文本进行人工分析,并将正确标记后的文本分类作为样本加入到训练集中。
2.4 情感分析器
情感分析主要分为基于情感词典和基于机器学习2种方法。但由于在现实情况中,标注好的文本数量很少,如果使用基于机器学习的情感分析需要首先对文本进行人工标注,消耗很多时间和人力。因此,在对收集的文本进行情感分析时,本研究采用基于情感词典的分析方法[13]。
基于情感词典的分析方法指根据已构建的情感词典,对待分析文本进行文本处理抽取情感词,进而计算该文本的情感倾向,即根据语义和依存关系来量化文本的情感色彩[14]。
常用的中文情感词典有清华大学李军中文褒贬义词典、台湾大学NTUSD简体中文情感极性词典、知网Hownet情感词典等等。同时,在已有的权威字典的基础上,针对性地添加或修改综合交通运输方面的词汇,并且使用N-Gram方法来进行新词的挖掘,以期获得更好的性能。
训练情感分析器将文本中体现的民众对综合运输服务的态度分为5种等级,包括非常消极、较消极、中性、较积极、非常积极。在训练过程中,通过调整各情感等级间的阈值来提高模型分类能力。
2.5 指数计算
在定义指数时,为不同领域、不同内容赋予不同的权重,将文本中的情感值和领域内容方向的权重相结合,得到相关评议指数。
确定权重时,采用专家打分法请交通运输领域专家为各个具体的方向给出分数,该方法具有简便、直观、计算简单等特点[15-16]。
随着交通运输行业的不断发展,可以根据计算得出的指数值与整体行业发展情况定期对权重进行更新。
3 实证分析
3.1 平台选取
大数据平台的选择是影响基于第2节中模型框架计算得出的评议指数质量的重要因素。交通运输服务综合影响人们生活的方方面面,因此可以从多渠道、多角度、多平台挖掘人们对于运输服务水平的看法与态度。为了更加全面、客观、真实地反映公众对于我国交通运输服务水平的感受,在确定文本数据来源的过程中,将以下指标作为各交通运输子领域(如共享交通、旅游出行、快递物流等)数据平台的选择标准。
3.1.1 页面浏览量(page view, PV)
页面浏览量是每个用户对网站中任意网页的访问次数的总和,同一用户对同一页面的多次访问,其访问量累计。页面浏览量可作为衡量网站流量的重要指标,用来反映网站用户的活跃程度。页面浏览量越多,则表示该网站在其所在领域受到公众任认可的程度越高。
3.1.2 独立用户数量(unique visitor, UV)
独立用户数量又称独立IP数量,是指一定时期内访问网站的用户的数量,通常通过IP地址来代表1个唯一的用户。独立用户数量是网站流量的另一重要指标,其更加真实地描述了网站的访问量。
3.1.3 重复用户数量(repeat visitor,RV)
重复用户数量又称重复访问者,是指在一定时期内访问网站2次及以上的用户数量。该指标侧面反映了网站对于用户的价值水平,当且仅当网站中的内容对用户有价值时,用户才会选择再次访问。
3.1.4 文本数据量
文本数据量是指网站中由用户发布所有文本的数据总量。通常数据越多,训练得到的模型其表现效果越好。因此,将文本数据量指标作为公众评议指数计算选取数据平台的指标具有重要意义。
综上,前3个指标是通过网站访问量的各项指标来表示网站在其领域的用户覆盖及内容价值水平,而第4个指标则是针对公众评议指数基于文本数据进行分类计算的特点,用来反映数据平台是否有助于提高指数准确性。
3.2 数据获取
基于第3节中提出的模型框架,利用不同的平台和搜索关键词可计算得出4个不同的指数。本试验以客运相关企业评议指数为例,根据4.1节中提出的选择指标,选取马蜂窝在线出行服务平台,爬取平台中对于客运相关服务的评价文本作为试验数据[17]。
本研究通过“飞机”、“火车”、“大巴”、“晚点”、“准时”等关键词进行问答搜索,得到75 879条文本数据。去除其中的重复文本以及对于国外交通信息的问答,得到38 906条有效数据。数据爬取通过python 3.5实现[18]。
3.3 评价指标
本次试验使用了正确率(precision)、召回率(recall)、F均值(F1)作为评价指标来检验试验效果。
(1)
(2)
(3)
式中,TP(True Positive)为将样本归类为其实际的分类;FP(False Positive)为将样本归类为该类别但实际不是;FN(False Negative)为将样本标记为其他类别但实际为该类别。
3.4 试验结果3.4.1 领域分类器
试验中,将分别从空运、道路、铁路3个领域对客运服务进行领域划分。文本样本的领域标签是通过爬取该文本时使用的标签进行标注的,文本样本的分布见图2。
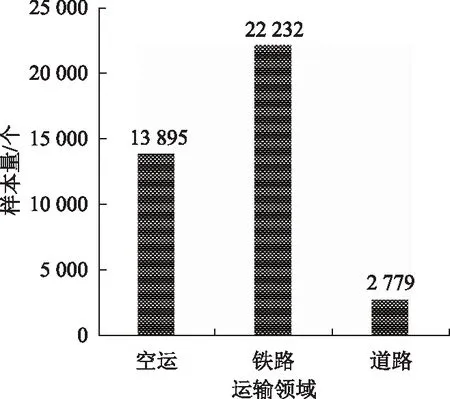
图2 马蜂窝问答领域分布Fig.2 Domain distribution of hornet’s nest question and answer
训练所得的领域分类器分类表现如表1所示,结果表明,分类器可以将75%以上的问答文本正确分类。虽然根据搜索关键词对问答文本进行分类会导致数据噪声较大,但其操作简便、效率较高,省去了人工标注的工程,因此,认为使用该方法在初始状态下进行标注是可行的。

表1 领域分类器初始分类结果Tab.1 Initial classification result of domain classifier
同时,也进一步提出,在定期采集数据更新评议指数的过程中,对增量数据文本中少量的误判样本进行人工分类校正后,将其放入训练数据集中,重新训练模型。在此过程中,逐渐对初始自动分类导致的信息偏差进行纠正。
在验证过程中,在训练模型时,首先在训练数据集中剔除最近10个月的文本数据,应用已训练好的模型对新加入的接下来1个月的文本数据进行分类;选出分类错误的文本样本,并对其进行人工标注,将人工标注与原始标注不一致的样本加入到训练数据集中重新训练模型。如此重复10次,其正确率结果如图3所示。

图3 模型迭代结果变化趋势Fig.3 Change trend of model iteration result
从图3可以看出,随着新的人工标注样本的补充,分类模型的效果也会首先稳步提升,此后稳定在较高水平。转折点是在第5次模型时,其模型效果提升速度最快的是道路领域,其次是铁路,最后是空运。在实际应用过程中,可在计算评议指数的前5次对模型进行迭代更新。
3.4.2 内容分类器
试验中,将聚类后的文本内容分类分别标注为依法行政、业务工作、服务态度、安全保障4种类型。各内容类型文本分布图如图4所示。
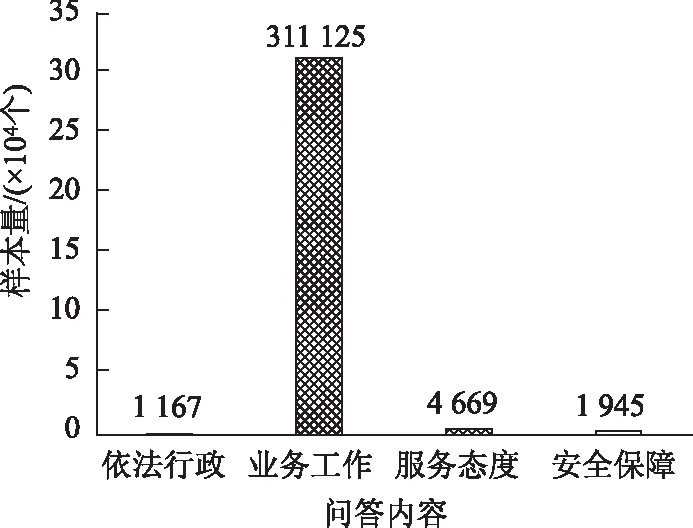
图4 马蜂窝问答内容分布Fig.4 Content distribution of hornet’s nest question and answer
训练得到的内容分类器分类表现如表2所示。结果表明,利用无监督算法辅助文本标注的方法切实可行,分类器的准确率可以达到79.68%。但由于样本分布过于不均,导致样本量少的“依法行政”、“服务态度”与“安全保障”3类文本内容的分类准确度过低。
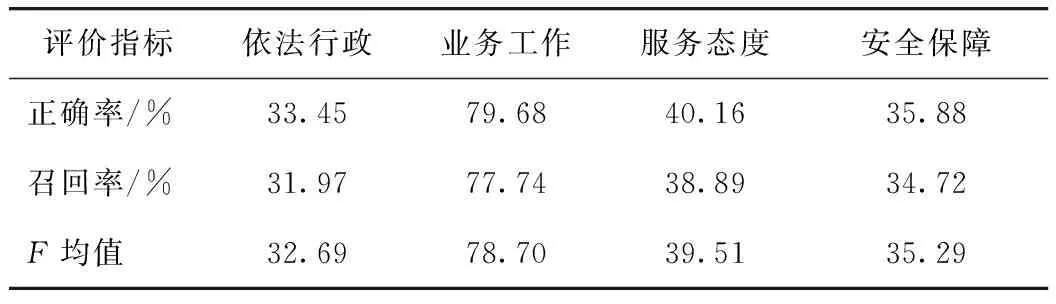
表2 内容分类器初始分类结果Tab.2 Initial classification result of content classifier
该问题可通过4.3.1节中介绍的利用增量数据集的方式加以解决,即将新爬取的“依法行政”、“服务态度”与“安全保障”3类文本数据全部加入到训练集中,直至4种类型的文本数据基本平衡或模型效果达到稳定状态。
3.4.3 情感分析器
试验中,将所有文本数据采用独热码对向量特征提取和表示后,利用现有的情感词典进行计算,每条文本均得到1个0到1之间的值作为其情感值。
通过人工抽样标注的方式,协助模型调整参数确定阈值,根据情感值将文本数据分为非常消极、较消极、中性、较积极、非常积极5种态度。
将所有文本按照确定的阈值进行分类后,其分布如图5所示。为了验证模型的有效性,从中抽取100条(之前未抽到的)样本进行人工分类,其结果与分类器判断的情感态度一致的样本占抽出样本的95%。
3.4.4 指数计算
经过上述3个分类器,此时每个样本都带有3个标签,分别是领域标签、内容标签和情感标签。综合交通运输评议指数的最终目的是反映民众对客运、货运、重大事件、重大事故的整体情感态度。因此选取交通行业的领域专家,分别根据领域标签和内容标签下的分类方向对综合运输的支持作用,赋予该标签不同的权重。
将每个方向下每个文本的情感值分别乘以领域标签和内容标签对应的权重后求和,即可得到评议指数。
由于本试验只选取了马蜂窝1个平台,其内容不足以使得计算得出的指数具备实际意义,因此在文中未给出具体数值。
3.5 讨论
本试验以马蜂窝平台中的问答数据为例,论证了第3节中提出的公众评议指数计算框架的可行性。试验结果显示,该框架能够简单、高效地完成模型的训练并达到较高的分类准确率,在实际应用中具有可行性优势。
结合图2与图3可以发现,领域分类模型效果提升速度由快到慢依次是道路、铁路、空运,与其领域分布下的样本数量成反比。这有可能是因为初始样本不足导致的模型得到信息不足的情况在后续增量数据的补充过程中得到了缓解,这同时也解释了初始分类结果中3个领域分类结果的排名。
利用上述发现,提出了解决内容分类器样本不均衡导致的分类准确率低问题的方法。该方法有效地利用了评议指数需定期更新这一特点,利用增量数据来平衡各类别样本的数量。
4 结论
为了更加准确客观地评价我国综合运输服务能力,为实现“交通强国”战略打好基础,提出了基于大数据的交通运输公众评议指数。该指数利用我国现有的在线出行服务等平台积累的海量民众发布的文本数据,采用自然语言处理技术对其含有的情感态度进行分析,加权整合后用来反映我国民众在一定时期内对客运服务(长短途出行等)、货运服务(快递服务等)、重大事件以及重大事故的态度看法。得出的主要结论如下:
(1)基于大数据的指数评议方法较传统指数来源更加直接,内容更加全面,对于信息的挖掘更加深入,基于大数据的舆情分析与已有的政府绩效公众评议方法结合起来,利用大数据海量、真实的特点可弥补传统公众评议数据收集过程中存在的参与度低、数据失真等问题。
(2)提出了基于文本分析算法和情感分析算法的公众评议指数计算模型,该模型针对我国交通运输客货运、重大事件、重大安全事故等方面的公众评议,通过网络爬虫等方式在相关数据源上获取数据并对数据进行清洗、集成与转换。基于领域、内容、情感分析器对模型进行训练,最后通过对不同领域、不同内容赋予不同的权重,将文本中的情感值和领域内容方向的权重相结合,得到相关评议指数。
(3)利用指数评议方法对客运相关企业进行指数评议,通过正确率、召回率、F均值等指标验证验证了综合评议指数计算框架中提出的领域、内容、情感3个分类器的有效性。结果表明,领域、内容、情感分类器的准确率分别为75%, 79.68%, 95%。因此,确立的计算框架能够高效地完成模型的训练并达到较高的分类准确率。针对分类器样本不均衡导致的分类准确率低的问题,通过增量数据的方法,使得各种类型的文本数据基本平衡或模型效果达到稳定状态。
