基于YOLOv4网络的棉花顶芽精准识别方法
2022-09-28刘海涛韩鑫兰玉彬伊丽丽王宝聚崔立华
刘海涛, 韩鑫*, 兰玉彬, 2, 伊丽丽, 王宝聚, 崔立华
(1.山东理工大学农业工程与食品科学学院, 山东淄博 255000;2.山东省农业航空智能装备工程技术研究中心, 山东淄博 255000;3.山东绿风农业集团有限公司, 山东滨州 256600)
我国是世界上较大的棉花生产国和消费国, 棉花产业与人们的日常生活息息相关。近年来,由于种植成本高昂、机械化生产程度低等因素导致我国棉花种植面积和产量自2011年以来不断减少[1-5]。棉花打顶是田间栽培管理过程中的重要环节, 摆脱人工打顶促进机械化打顶是降低成本、提升棉花生产效率的重要手段[6-7]。对于棉花打顶机的设计, 首要任务和工作重点是在复杂的田间环境、枝叶对顶芽的遮挡以及不损伤棉桃的情况下, 精准去除顶芽。因此对棉花株顶的精准定位是关键。
传统的棉花打顶机基本上采用仿形装置和测量棉株高度2种方法进行棉株的识别定位。滕华灯等[8]研制了3FDD-1800型打顶机, 通过对仿形轮结构的优化对比, 最终选择斜拉式仿形轮进行棉田地块的仿形。然而该设计忽略了棉株生长高度的差异, 不能对棉株直接仿形, 打顶效果不佳。姚强强等[9]设计了接触式仿形装置, 通过调整仿形板质量、仿形板与切割器之间的位置参数等, 使打顶率达到了88.64%。但该装置对仿形板质量要求高, 对仿形效果影响大。周海燕等[10]对不同传感器测量株高进行了对比试验, 结果表明, 相较于超声波传感器, 激光传感器测量误差小, 更适合测量棉株高度。但外界环境对传感器测量精度影响大且价格昂贵。彭强吉等[11]采用光电传感器设计了一套测量光幕装置, 通过发射器产生的等间距光束扫描棉株从而实现高精度的实时测量, 但该方法也未能考虑实际环境对测量精度的影响, 且价格高昂贵。综上所述, 不论是采用仿形装置还是使用传感器都未能很好地解决打顶机对棉株的精准定位以及外界环境给测量过程带来的干扰问题, 进而影响打顶刀轴的作业精度, 存在漏刀、过切、对棉桃的损伤等问题, 给大规模应用推广带来阻碍[12-13]。
随着图像处理与人工神经网络等相关技术的发展, 基于棉株顶芽的颜色特征、形态特征进行识别定位的研究也取得进展。研究人员通过对采集的棉株图像进行灰度化、二值化、除噪、边缘提取等处理, 最终获得分割后的顶芽信息, 从而实现棉株的识别定位。刘俊奇[14]提出一种基于BP神经网络的棉株顶尖识别方法, 基于顶尖图像信息, 利用BP神经网络进行识别, 但该方法对图像分割结果要求高。瞿端阳[15]通过对比棉株顶芽在HSI、YIQ、YCbCr不同颜色空间下的分割效果, 最终确定采用YCbCr颜色空间进行分割, 其正确率达到了86%。采用BP神经网络对分割结果进行训练, 最终在测试集的识别精度为85.7%。但该方法识别耗时长, 且未考虑遮挡等情况。近年来基于深度学习方法在农产品的识别和病虫害检测方面的应用发展迅速, 这也为棉株顶芽的识别研究带来新思路。沈晓晨[16]借鉴YOLOv3的栅格思想, 利用迁移能力较好的VGG16网络对棉株顶芽图像进行训练, 经过1 000次迭代, 模型最终在测试集上的识别精度达到了83.4%。该研究探索了利用深度学习框架进行棉株顶芽识别的可行性, 但由于采集图像数据量少, 模型在训练过程中产生了过拟合现象。研究人员利用传统的图像处理方法对顶芽图像进行了大量研究, 而使用深度学习在棉花顶芽的精准识别方面研究还不够深入, 检测精度不理想, 未能考虑不同自然环境以及叶片遮挡等情况对棉花顶芽识别精度的影响。因此, 为提供在复杂棉田环境下对棉株顶芽进行非接触式、低成本的精准识别方法, 本文基于YOLOv4模型在复杂环境下对棉株顶芽的精准识别定位进行了研究。
1 材料与方法
1.1 图像采集
图像采集于山东绿风农业集团有限公司棉花基地(山东无棣), 棉花品种为鲁棉532, 种植模式为一模三行, 76 cm等行距, 采集设备为索尼HDR-CX900E全高清摄像机, 分辨率为5 024像素×2 824像素。采集时间分别在每天上午6:00—9:00、下午3:00—5:00之间, 为了模拟棉花打顶机摄像头的拍摄姿态, 在距离棉花顶叶30~50 cm的自然光照下采取俯视角度进行拍摄,共采集到2 900张顶芽图像(表1), 涵盖了顺光、逆光、侧光等拍摄方式, 晴天、阴天、雨天等光照条件以及单株、多株、遮挡等植株自然状态(图1)。顺光指光线照射方向与照相机拍摄方向一致且二者夹角在±10°以内, 逆光指光线照射方向与照相机拍摄方向相反或二者成钝角关系, 侧光指光线照射方向与照相机拍摄方向成90°或二者成锐角关系。

图1 自然环境下的棉花顶芽图像Fig.1 Image of cotton top in natural environment
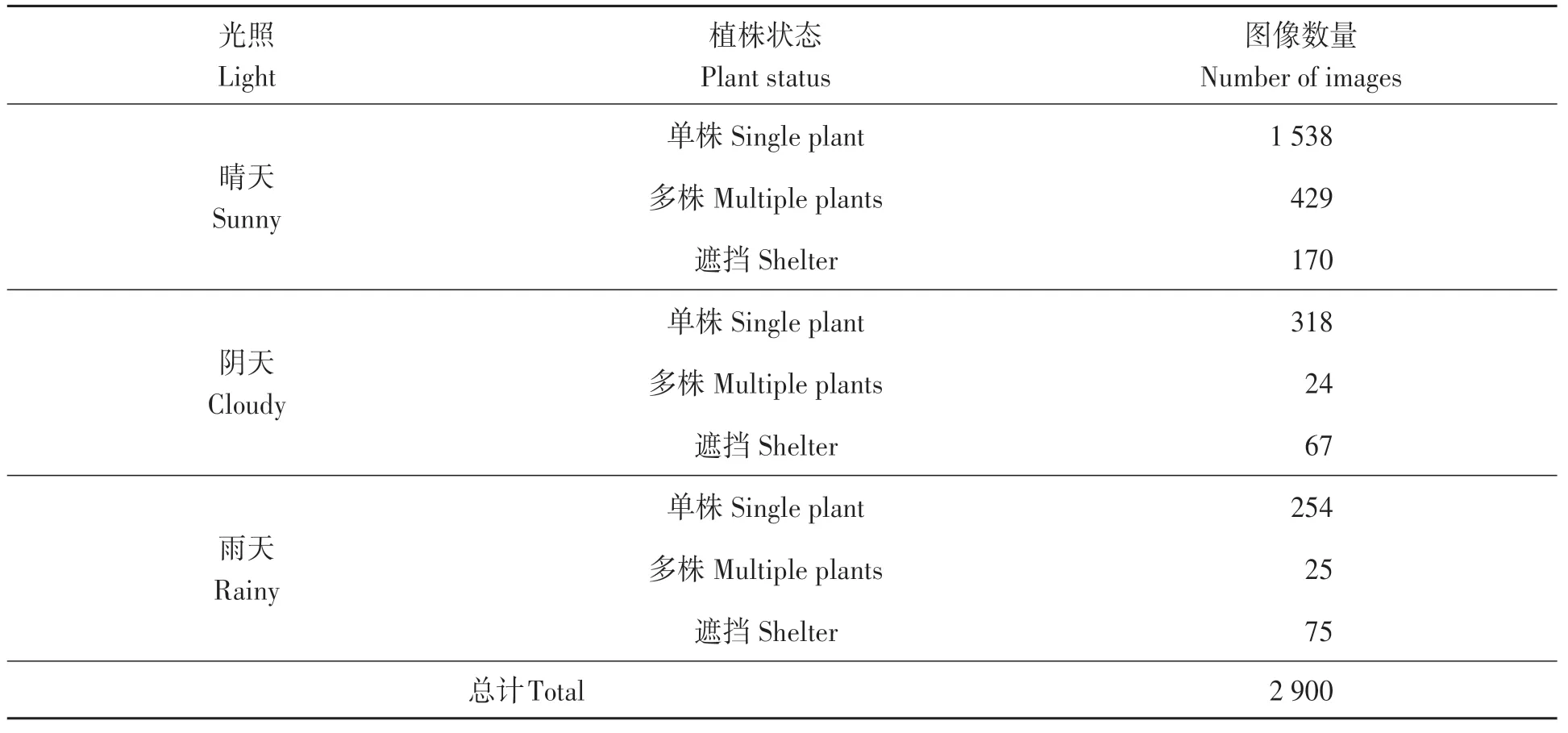
表1 不同条件下棉花顶芽数量统计Table 1 Statistics of cotton top leaves under different conditions
1.2 数据集制作
在训练深度网络模型时, 为了保证棉花顶叶图像数据的多样性, 提高网络泛化能力, 避免过小的数据量使训练网络产生过拟合[17-19], 利用数据增强方法对原始图像进行数据扩展。利用左右翻转、裁剪、旋转、添加高斯噪声及调整色调饱和度等方法, 得到14 500张有效图像来制作数据集, 其中旋转角度在-90°到90°范围内随机选择。使用LabelImg工具对检测目标进行人工标注制作样本标签, 然后按照8∶1∶1的比例划分训练集11 745张、验证集1 305张、测试集1 450张, 并且将生成的xml类型文件, 按照PASCAL VOC数据集的格式进行保存。
1.3 模型构建与优化
1.3.1 YOLOv4模型YOLOv4目标检测模型是YOLO(You Only Look Once)系列的第4个版本[20], 该模型基于回归的思路, 在完成目标定位的同时实现目标分类, 不再生成候选区域框[21-25]。YOLOv4主干特征提取网络为CSPDarknet53, 即在Darknet53网络基础上引入CSPnet结构。CSPDarknet53主要由2个网络模块构成(图2), CBM模块即卷积模块包括卷积(convolution)、批量归一化(batch normalization, BN)、Mish激活函数操作;Resblock_Body为残差模块, 其中Res_unit为残差单元。此外YOLOv4结合了SPP(spatial pyramid pooling)[26]、PANet(path aggregation network)[27]2种特征金字塔结构, 利用SPP模块的1×1、3×3、5×5、13×13尺度的池化核对最后特征图层进行最大池化处理, 如图3所示。YOLOv4在特征金字塔网络(feature pyramid networks, FPN)基础上添加了自下而上的路径增强, 即PANet结构, 通过2次步长为2的上采样和2次步长为2的下采样实现特征图信息由深层特征到浅层特征、浅层特征到深层特征的双向融合。
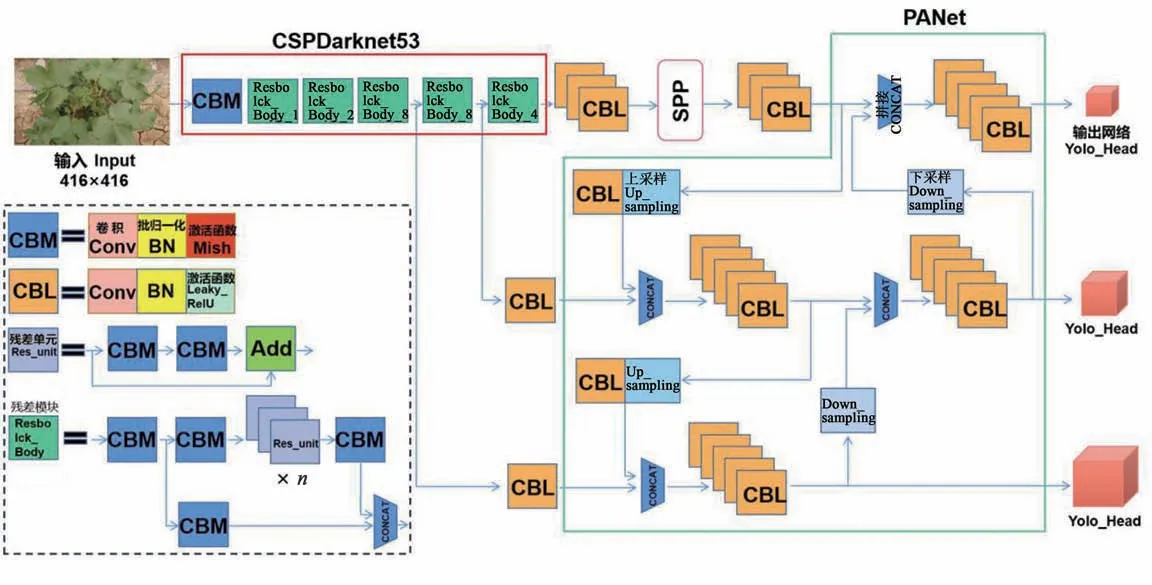
图2 YOLOv4网络结构Fig.2 YOLOv4 network structure

图3 SPP网络结构Fig.3 Network structure of SPP
1.3.2 边界框分类预测与损失函数YOLOv4有2种像素输入模式, 本文采用416像素×416像素将输入的棉花顶芽图像缩放至该像素大小, 经CSPDarknet53主干网路以及SPP、PANet网络模块的特征提取与融合, 最终输出3个大小为13×13×18、26×26×18、52×52×18的有效特征图像来检测棉花顶芽, 其中13、26、52为特征图像素大小, 18为3个预测边界框的位置。调整信息可用x、y、w、h、C来表示, 其中x、y为预测边界框的中心位置调整参数,w、h为预测边界框的宽高调整参数,C有2部分, 分别是当前单元网格中是否存在棉花顶芽目标以及预测概率, 最后通过得分排序和非极大值抑制(non-maximum suppression, NMS)从中筛选出棉花顶芽预测框。
不断优化网络损失函数, 降低误差提升网络检测精度。YOLOv4利用CIOU损失[28-29]优化, 考虑真实框和预测框之间的重叠面积、中心点距离、长宽比3个因素, CIOU loss将框的宽高以及中心点联系在一起, 使得预测框回归误差小, 定位精准。
1.3.3 K-means聚 类YOLOv4模 型 延 续 了YOLOv3在先验框尺寸设置的策略, 使用K-means算法得到9个不同尺寸基于COCO数据集的先验框。初始先验框的选择对模型预测精度和速度均会产生影响, 本文识别的棉花顶芽对象与COCO数据集在类别数目和目标尺寸以及分布上差异较大, 因此YOLOv4模型预先设定的先验框尺寸并不适于顶芽识别, 使用K-means算法对棉花顶芽数据集进行聚类分析, 优化先验框尺寸, 得到YOLOv4-Kmeans模型。不同于传统的聚类方法使用欧氏距离, YOLO系列引入平均交并比(average intersection over union, AIoU)[30]方法对Kmeans聚类结果进行评价以降低误差, 并定义了距离参数D。

式中,D(i,box)为标注框与聚类中心距离;IoU(i,box)为标注框与聚类中心的交并比;i为随机设置的聚类中心;box为标注框。其中, IoU(i,box)值越大, 说明重合程度越高, 标注框与聚类中心的距离就越短, 聚类效果好。
随机设置9个聚类中心对棉花顶芽数据集进行聚类分析, 得到平均交并比与聚类中心数之间的关系。
1.3.4 试验环境与参数 棉花顶芽检测模型试验平台为台式计算机, 处理器为Intel Xeon CPU E5-2670@2.6GHz(2处理器), 32 GB运行内存, 显卡为8 GB的NVIDIA GeForce GTX2 060s GPU, 软件环境为Windows 7操作系统, 采用Pytorch深度学习框架进行模型训练。训练时, 32张图像为1个批次(batch size), 初 始 学 习 率(learning rate)为0.001, 动量(momentum)设置为0.9, 权值衰减率(decay)为0.000 5, 训练代数(epoch)为150, 进行49 950次迭代。
1.3.5 评价指标 模型的性能评估可以反映模型训练结果的优劣, 并为后续改进优化提供参考, 本文以棉花顶芽的精准、快速识别为研究目的, 要求在保证检测精度的同时兼顾速度。因此, 本文选择平均精度(average precision, AP)、调和平均值(F1)、准确率(P)、召回率(R)、检测时间(t)作为评价指标, 计算公式如下。

式中,TP为正样本, 被检测为正样本的数量;FP为负样本, 被检测为正样本的数量;FN为正样本被检测为负样本的数量;n为类别数目;AP为平均精度,f(P,R)为P-R曲线所包围的面积;F1为调和平均值。此外, 检测时间t为单张棉株图像平均处理时间(s)。
2 结果与分析
2.1 先验框数量与平均交并比之间的关系
如图4所示, 先验框数量为9(K=9)时, 平均交并比最大为87%, 因此将聚类结果定为先验框尺寸分别是(39,66)(49,87)(57,110)(62,95)、(69,131)(71,115)(83,144)(104,177)(110,87)。

图4 先验框数量与平均交并比之间的关系Fig.4 Relationship between the number of anchors and AIoU
2.2 棉花顶芽识别损失函数分析
图5所示为损失函数随迭代次数的变化曲线, 可以看出, 前5 000次迭代, 损失值迅速下降, 模型快速收敛, 至迭代10 000次损失函数趋于稳定, 而40 000次迭代以后损失值振荡幅度较小, 表明训练结果较好, 自此每训练1 000次, 输出1个权重, 共得到9个权重模型供后续选优。

图5 棉花顶芽识别损失函数曲线Fig.5 Relationship of cotton top loss function curve
2.3 训练权重分析
通过训练共得到9个权重模型, 性能参数如表2所示, 平均精度都在98%以上, 模型8的平均精度值最高达到了99.44%, 而兼顾了模型精确率和召回率的综合指标F1值最高为96.84%, 虽然模型4的平均精度值较模型8低了0.04个百分点, 但F1值和准确率提高了1.77个百分点和3.29个百分点, 表现更好。因此综合来看模型4可选作棉花顶芽测试模型。

表2 训练权重模型对比Table 2 Comparison of training weight models
2.4 模型优化对比分析
2.4.1 优化前后模型检测性能比较 本文在YOLOv4模型的基础上, 利用K-means算法对棉花顶芽图像数据集进行重新聚类, 优化了先验框的尺寸, 优化前后的网络性能对比效果如表3所示, 聚类后YOLOv4模型在各个指标方面均有不同程度的提高, 其中精确率提升幅度最大, 增加了1.73个百分点, 召回率提升了0.52个百分点,F1值提升了1.16个百分点, 平均精度提高了0.36个百分点, 并且单张图片的检测时间缩短了0.28 s。说明通过对先验框聚类可以提升棉花顶芽检测性能。

表3 优化前后模型性能的指标对比Table 3 Comparison of the performance indexes of the model before and after optimization
图6为YOLOv4模型聚类前后对棉花顶芽检测的P-R曲线(YOLOv4-Kmeans即为调整先验框后YOLOv4模型), 曲线下方所围成的面积即为该模型对应的AP值, 因此该曲线越靠近右上角或右下角说明模型检测效果越优, 可以看出对先验框优化后的YOLOv4模型表现好于未优化模型。

图6 P-R曲线Fig.6 P-R curve
2.4.2 模型检测性能比较分析 为了进一步探究先验框优化后YOLOv4模型与其他模型在棉花顶芽识别方面的优劣, 本文采用YOLOv3、Tiny-YOLOv4、SSD模型进行训练, 初始参数均相同。如表4所示, 在相同的测试集下, 4个模型的平均精度以及召回率都达到了99%以上, 其中聚类优化后的YOLOv4比YOLOv3、Tiny-YOLOv4、SSD模型在检测精确率方面提升明显, 分别增加0.48%、21.65和22.18%。同样,F1值也高出0.44%、12.85%、13.17%。而在检测速度方面, 由于Tiny-YOLOv4是轻量化模型, 因此检测耗时最短, 单张图像平均检测时间达到了0.53 s, 而YOLOv4模型单张图像平均检测时间对比YOLOv3、SSD模型分别缩短0.19和0.13 s。综合分析表明, 先验框聚类优化后的YOLOv4模型能够在复杂的自然环境下有效检测出棉花顶芽, 并且在识别精度和速度方面有优势。如图7所示, 在不同的拍摄环境下, 只有优化先验框的YOLOv4模型(YOLOv4-Kmeans)能够完整检测出多株棉花顶芽, 而其他模型均未能检测出位于图像左侧的1株棉株, 造成漏检。另外在雨天以及轻度遮挡环境下, 所有模型均能准确检测出棉株顶芽。

图7 复杂环境下5种模型棉株顶芽识别结果Fig.7 Recognition results of cotton top by 5 models under complex environment
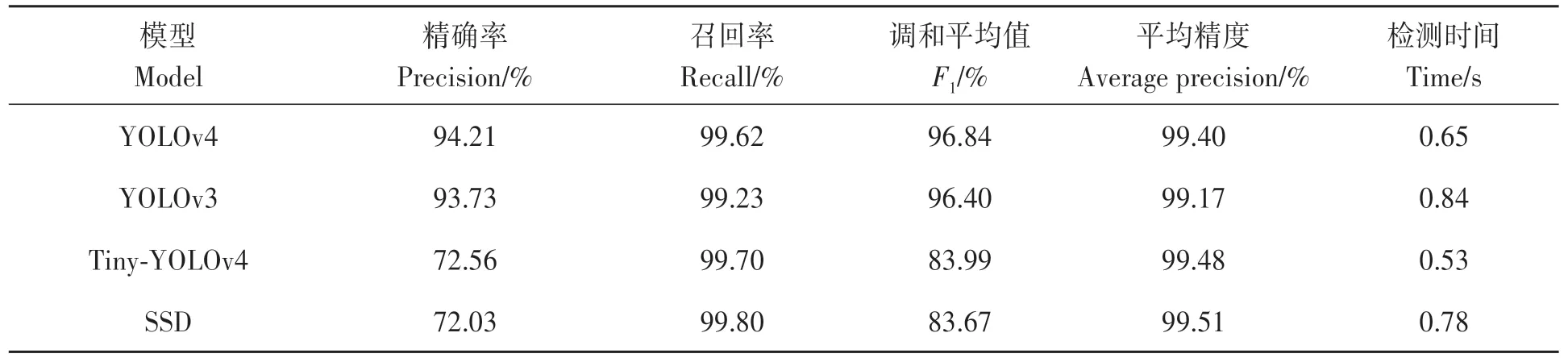
表4 四种模型识别棉花顶芽的结果Table 4 Recognition results of four models for cotton top
2.5 不同环境下模型检测效果分析
此外, 由于光照强度和光线角度的影响使得部分棉花顶芽图像反光严重, 顶芽特征丢失, 因此处理逆光以及遮挡状态的顶芽也是棉花顶芽检测的重点和难点。除上述试验外, 本文从测试集选取了334张存在逆光状态的图像以及138张存在遮挡状态的图像, 利用YOLOv4、YOLOv3、Tiny-YOLOv4、SSD模型对不同状态下的顶芽进行检测, 结果如表5所示。
由表5可知, 在逆光状态下YOLOv4和SSD模型对棉花顶芽的检测精度相差无几, 均达到了99.9%以上, 高于YOLOv3、Tiny-YOLOv4模型0.5、0.29个百分点, YOLOv4模型F1值表现好于SSD模型, 且相比于表3和表4, 各个模型平均精度并没有下降, 说明逆光环境对于棉花顶芽检测精度影响不明显。而在遮挡状态下, SSD模型AP值高于YOLOv4模 型0.04个百 分点, 高 于YOLOv3模 型0.29个百分点, 高于Tiny-YOLOv4模型0.73个百分点, 但SSD模型在2种状态下识别精确率偏低, 说明该模型对于棉花顶芽真假样本的辨别能力弱。此外, 在遮挡状态下4种模型的检测精度相较于表3和表4均有下降, 这可能是因为其他叶片的遮挡使得棉花顶芽图像部分特征缺失, 从而造成检测精度的降低。综上所述, YOLOv4模型在逆光状态下对顶芽检测性能好, 而在遮挡状态下表现并不突出, 且各个模型的检测精度在逆光条件下并未受到影响, 但在遮挡条件下的检测精度均有不同程度的降低。
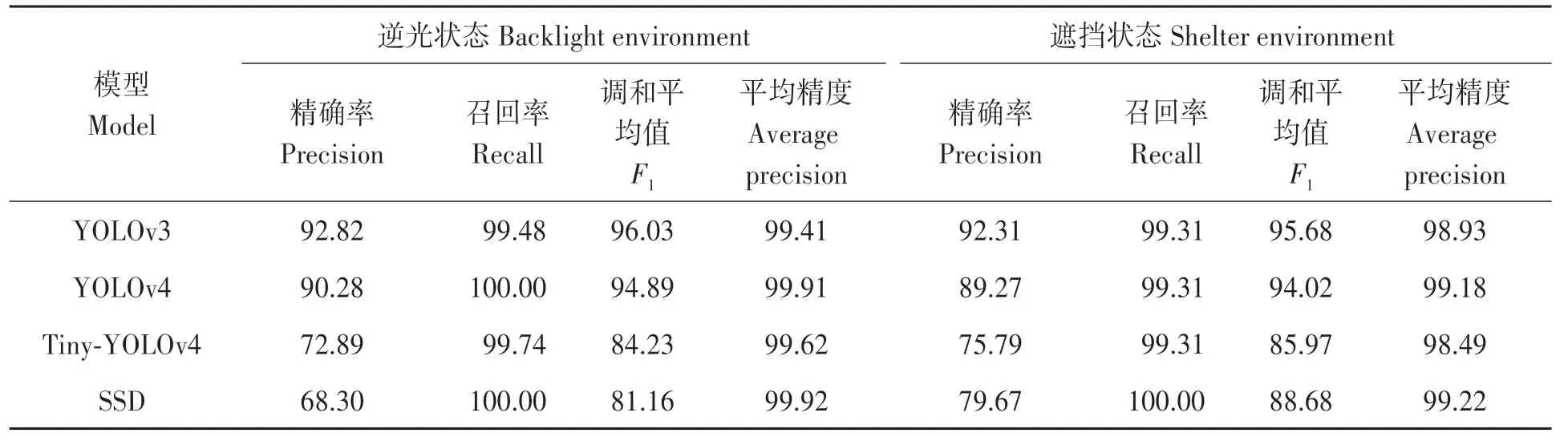
表5 逆光与遮挡状态测试集不同模型检测结果Table 5 Test results of backlight and occlusion state test sets by different models (%)
3 讨论
现阶段我国棉花机械化打顶仍存在精度低、棉株损伤率高等问题, 其中对棉花顶芽的精准识别定位是减少刀轴过切、漏切率, 提高产量的重要手段。当前对于棉株的识别定位研究多集中在利用传感器以及传统图像处理上, 随着5G的出现以及计算机硬件的更新换代, 更快的数据处理速度让深度学习方法在进行精准、快速的顶芽识别定位成为可能。YOLO是可以对目标实时识别和定位的端到端的深度卷积神经网络模型[31], 该网络在YOLOv3基础上集成了更多的特征提取与融合方法, 相较YOLOv3, 该网络的检测精度和速度都更高, 性能优异。本文选取YOLOv4深度学习模型对棉花顶芽进行了研究, 利用K-means算法对棉花顶芽数据集重新聚类, 优化先验框尺寸。对比原模型, 检测平均精度提升了0.36个百分点, 单张图像平均检测时间缩短了0.28 s, 说明对模型的先验框优化能够提升棉花顶芽检测精度。
与YOLOv3、Tiny-YOLOv4、SSD目标检测模型相比, YOLOv4模型的检测精确率和F1值最高, 说明该模型对精确率和召回率的兼顾性好;在检测精度方面, SSD和Tiny-YOLOv4模型均有好的表现, 但两者检测准确率和检测速度方面均不如YOLOv4。与沈晓晨[16]的方法相比, 本文数据集涵盖了多种气候条件, 丰富了数据多样性, 在克服过拟合现象的同时, 大幅度提升了检测精度。
本文在聚焦顶芽研究外, 还进一步探索了复杂的自然环境对棉花顶芽检测的影响。利用YOLOv4、YOLOv3、Tiny-YOLOv4、SSD模型进行测试试验,结果表明,各个模型在逆光环境下对于棉花顶芽检测精度并没有下降, 说明了逆光状态对棉花顶芽检测影响不明显。但在遮挡情况下各个模型检测精度均出现下降。
本文利用YOLOv4模型一方面为深度学习在棉花打顶领域的应用可行性作了探索研究, 另一方面也为后续实地试验奠定基础。未来需要提升棉株的检测速度, 对处于不同生长期的顶芽分类研究, 以实现精细化打顶是后续的研究重点。
