融合人脸特征与密码算法的身份认证系统*
2022-09-28冷青松魏雨汐
赖 韬,冷青松,魏雨汐,朱 俊
(中国电子科技集团公司第三十研究所,成都 610041)
0 引 言
近十多年来,随着生物特征识别技术的成熟,利用生物特征的独特性,将其作为密钥已经成为密码领域的一个研究方向。
生物特征密钥技术中,经典的方案主要是模糊承诺(Fuzzy Commitment)[1]和模糊金库(Fuzzy Vault)[2],其应用较广。无论是模糊承诺还是模糊金库,密码算法要求输入必须是二进制向量,生物特征识别输出多是实值向量,因此需要将生物特征数据量化为二进制数据,量化过程通常会损失一定生物特征的鉴别能力。同时,生物特征由于受光照、角度、远近等影响,噪声较大,具有类内差别和类间差别。类内差距太大会带来错误拒绝率(False Reject Rate,FRR),即已注册的生物特征密钥不被识别而遭到拒绝的概率;类间差别太小会带来错误接受率(False Accept Rate,FAR),即未注册的生物特征被当作合法生物特征密钥的概率。因此,如何将存在类内差别的生物特征量化为尽似的二进制向量是生物特征秘钥技术中的一个难点。随着深度学习的卷积神经网络(Convolution Neural Network,CNN)在人脸识别领域的进展,Feng等人[3]基于卷积神经网络中的感知器构造了一个连续函数实现了一种量化方式,提高了可识别性;赵铖辉等人[4]在此基础上提出了一种新的基于卷积神经网络的BinaryFace网络来辅助生物特征的量化,取得了较好的实验结果。
本文结合领域内的研究结果,基于模糊承诺算法设计了一个融合人脸特征和密码技术的身份认证系统,并提出了一种稳定程度较高的人脸特征量化方法。首先通过多样本组计算特征的平均欧式距离,清洗掉误差较大的样本组后重新获得一个均值特征样本;再通过阈值将特征向量实值区域划分为多个区间,每个区间对应一个二进制数,每维特征向量落在哪个区间就量化为对应的二进制数。期望通过新的量化算法,可以降低FRR,消除FAR,使得身份认证系统能在高安全要求的环境下使用。
1 基于人脸特征的身份认证系统设计
1.1 系统身份认证过程模型
基于密码和生物特征识别的身份认证系统模型中的实体包括应用服务器、应用客户端、身份认证服务器、身份认证客户端和传感器,其中传感器配合身份认证客户端完成认证过程中的人脸特征的采集、上传;身份认证服务器完成认证过程的人脸特征识别;身份认证系统嵌入应用系统中,完成使用者身份认证,使其能调用对应权限的应用业务。身份认证过程模型如图1所示。
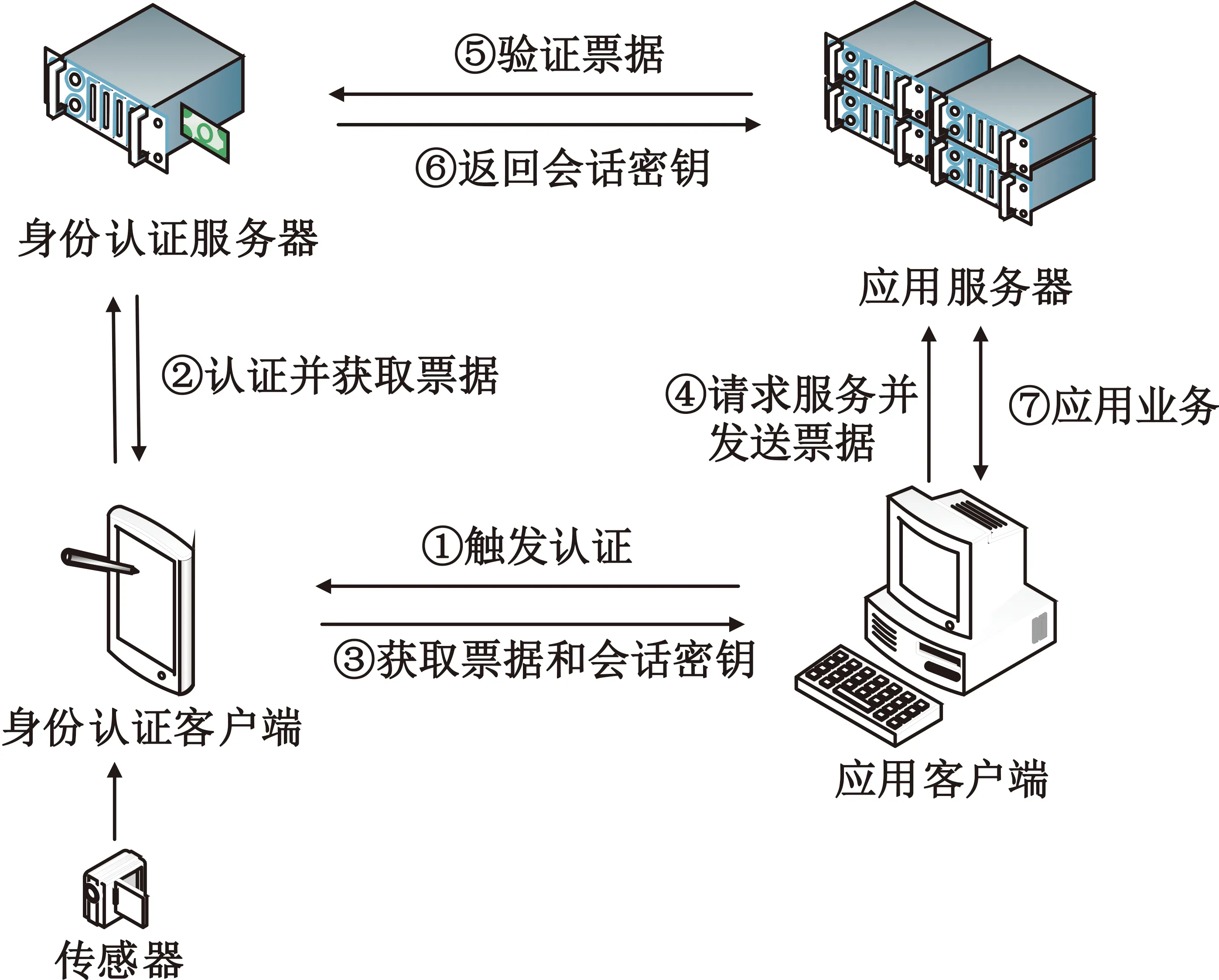
图1 身份认证系统模型示意图
身份认证过主要分为注册和认证两个阶段。在注册阶段,身份认证服务器与每一个注册用户共享一个秘密密钥,记为MK,并分配用户唯一标识,记为IDc。其中,秘密密钥MK加密存储在身份认证服务器中,同时也通过模糊承诺算法保护存储在身份认证客户端。对于秘密密钥MK,将其拆分为MK1和MK2,分别用于身份认证过程中的消息鉴别和密钥保护,表示为
MK=MK1+MK2。
(1)
在身份认证阶段,应用客户端通过认证系统的API触发身份认证客户端向服务端发起身份认证申请,调用传感器采集用户人脸特征,并通过模糊承诺算法提取密钥存储于认证客户端的MK;获取到MK后,身份认证客户端便能基于身份认证协议与身份认证服务器完成身份认证,并从服务端获取票据T和会话密钥SK,票据T包含用户身份、用户网络地址、票据有效期以及应用客户端和应用服务器通信所需的会话密钥SK;然后,应用客户端向应用服务器发送票据T,应用服务器调用认证服务器完成票据验证过程;完成验证后,认证客户端返回通信过程中需使用的会话密钥SK至应用服务端;最后,应用客户端和应用服务器采用会话密钥SK进行应用业务数据的保护。
身份认证客户端与身份认证服务器通过身份认证协议进行认证,从而获取会话密钥和票据,认证协议如图2所示,其中大括号中的内容表示协议中传递的内容要素,HMK(x,y,z)表示用MK对x、y、z计算杂凑值,EMK(x)表示用MK对x进行加密。
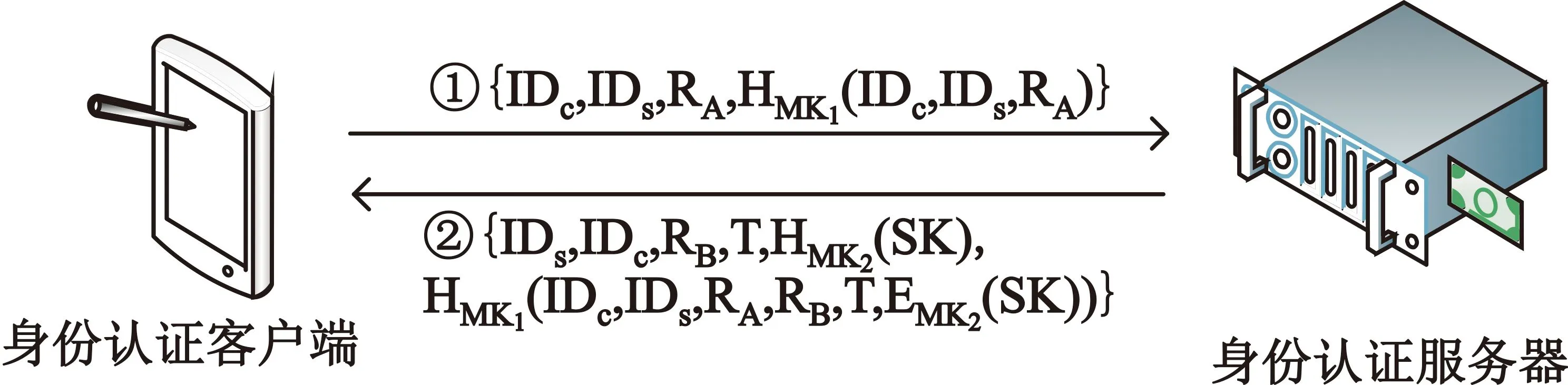
图2 身份认证协议示意图
身份认证客户端发送的认证请求消息中包含用户IDc和身份认证服务器IDs,随身份认证客户端产生的随机数RA及IDc、IDs和RA的杂凑值,杂凑运算的密钥为MK1。
身份认证服务器获取认证请求消息后,产生应用客户端和应用服务器通信所需的会话密钥SK和票据T。将会话密钥SK用MK2加密保护;票据T由身份认证服务器的自身的秘密密钥加密,身份认证服务器之外的其他实体无法获取票据T的明文内容。
1.2 人脸特征数据处理模块
1.2.1 人脸数据采集
应用客户端调用身份认证客户端的人脸采集模块API,通过传感器(摄像头)获得视频流数据,API模块调用openCV[5]库,从视频流中获得图像数据帧,基于人脸识别从图像数据帧获得人脸特征数据。
1.2.2 人脸识别
系统采用Dlib框架下的face_recognition[6]来实现人脸特征数据采集。采用了HOG(Histogram of Oriented Gradients)[7]模型作为人脸特征描述子。该模型通过HOG特征检测算法结合支持向量机(Support Vector Machine,SVM)线性分类器、图像金字塔和滑窗检测机制实现对目标样本的特征提取。HOG征提取过程如图3所示。

图3 HOG特征提取流程图
主要步骤如下:
Step1 色彩空间归一化是将图形转化为灰度图和进行Gamma校正[8],以便减少光的影响。
Step2 图形梯度计算是计算水平和垂直方向的梯度及梯度方向,捕获轮廓信息,并进一步弱化光照的干扰。通常做法是以[-1,0,1]和[1,0,-1]T为算子做卷积运算获得水平和垂直方向的梯度分量,然后计算像素点的梯度大小及方向。
Step3 梯度方向直方图构建是将图像划分成若干个小单元(记为cell),在每个cell内按照梯度方向划分为N(通常方向为360°,N为9)维特征向量,并按照梯度方向角度进行加权投影,这样就为局部图像区域提供了一个编码。
Step4 重叠块归一化是由于图像中光照和背景的变化多样,梯度值的变化范围会比较大,所以需要对梯度强度做归一化。通常是将多个单元(cell)组成一个块(记为block),然后对block进行归一化,一个block内所有cell的特征向量加起来便得到该block的HOG特征。
Step5 HOG特征收集是将所有块的HOG特征收集起来,输入到SVM分类器中,判别是否有人。
上述步骤后,即可在图像中定位人脸的位置,输出人脸位置矩形框。然后在矩形框内对人体面部的68个关键点(嘴巴、鼻子、眼睛、眉毛等)进行检测,获得这些关键点位置。最后是人脸对齐,获得一个标准脸,并仿射变换为一个128维实值特征向量,这个128维特征向量即为所需的人脸特征数据,如图4所示。

图4 人脸特征数据(特征数据做了模糊处理)
对于人脸识别,当两个128维特征向量之间的欧氏距离小于某个阈值时,可以认为是同一人。对于不同的数据样本,此阈值的取值不同,在Dlib默认的训练模型集LFW(Labeled Faces in the Wild)下,欧美人脸的阈值约为0.6,亚洲人脸的阈值约为0.4。
1.2.3 活体检测
为防止使用静态照片或者录制好的视频对系统进行恶意攻击,需要在人脸特征提取时做活体检测。为配合模糊承诺密钥保护需要用到多组图像来提高稳定性,选择了配合式动作检测的方式进行活体检测。
在配合式动作检测中,设定了面部的眨眼、左转、右转、张嘴、点头五个动作,认证时随机选择其中的三个动作要求用户在限定时间内完成,如图5所示。

图5 活体检测流程
动作检测主要基于Dlib和openCV这两个库来实现,原理是通过openCV将获得的连续图像帧使用Dlib库的获取每帧的嘴、鼻、眼、眉等关键点位置,然后计算连续帧内这些对应关键点位置的距离,判断是否为指定的动作。如眨眼判别,首先从第一帧图像中使用face_landmarks获取关键点位置,获得眼睛在图片中的像素坐标:
'left_eye':[(66L,76L),(70L,74L),(74L,75L),(78L,79L),(74L,78L),(69L,77L)];
'right_eye':[(95L,82L),(99L,81L),(103L,82L),(106L,84L),(102L,85L),(98L,84L)]。
然后计算眼睛的长宽比(如左眼):
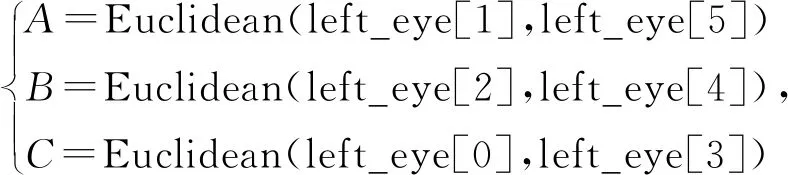
(2)
(3)
式中:A、B为两组眼睛垂直标志欧氏距离,C为眼睛水平标志欧氏距离,scale为长宽比。如果长宽比低于某个阈值(如眼睛为0.25),即认为是眨眼,在连续多帧内,根据眨眼次数来判别用户是否按要求实现了眨眼动作。
1.3 人脸特征密钥保护模块
在基于生物特征的身份认证系统中,由于生物特征自身所具备的噪声特性,采集人脸特征时受环境光照、拍摄角度、受体远近等因素影响,存在类间差距,即相同生物特征每次提取的特征向量是不一致的。而传统密码学中的加解密过程都需要完全一致的密钥方能完成对目标内容的提取或解密。所以,想要使用生物特征结合密码学来保护、提取特定的秘密密钥,需要一种容错机制来规避采集、鉴定人脸数据时其自身的模糊性对密钥提取过程的影响。
本系统采用了模糊承诺方案,此算法结合了纠错编码技术和密码学技术,将采集到的生物特征进行纠错编码,使之能达到接近于原始数据的状态,从而达到提取密钥、获取目标内容的目的。
1.3.1 人脸特征数据量化
人脸识别出的特征数据是一个128维的浮点数,要将其作为模糊承诺算法的密钥,还需要量化为一定长度的二进制数。量化过程极其关键,相同人脸的特征数据量化后要使得其差异位尽量地小。
二值量化为最常用的量化方法,即根据优化算法,找到一个最合适的阈值λ,大于该阈值的值量化为1,小于该阈值的值量化为0,即

(4)
对于人脸特征数据,一般阈值取值为0,128维的人脸特征数据量化为128 b位的二进制数,如图6所示。

图6 二值量化人脸数据
参考人脸识别原理可知,二值量化方法本质上就是和标准人脸对齐后基于正负偏移取1和0,这样的量化导致人脸特征数据损失过大,从而造成系统误识率和拒识率较大。于是,本文提出了一种多值量化人脸特征数据的方法,保证了量化后数据的相较原数据的相似性,降低了系统的误识率和拒识率。
多值量化是将每个维度的特征向量量化为一个4 b位二进制数,128维的人脸特征数据量化后就成为了128×4=512 b二进制数据。分析和统计人脸特征数据的分布发现,128维人脸特征数据主要为分布在(-0.5,0.5)区间,于是,选取合适的阈值(经过大量数据和实验验证,系统阈值设置0.07为最佳)为步长,将步长累加后形成多个区间段,每个区间段对应一个4 b的二进制数,人脸特征的特征向量落在某个区间,即将该维数据取值为该区间段的4 b二进制数。为保证相邻区间的差异位尽量小,设计了如下量化公式:

(5)
高位代表符号位,即正值区间段为0,负值区间段为1。式(6)表示了负值时的量化关系:

(6)
经多值量化后的人脸特征数据示例如图7所示。

图7 多值量化人脸数据
1.3.2 BCH编码与模糊承诺算法
由于类内差距和量化损失,生物特征难以量化成一个固定唯一的二进制数据,因此在模糊承诺算法中需要进行纠错。由于生物特征量化后的二进制向量属于中短码,BCH较适合,加上其低复杂度、实现简单等优点,因此本系统采用的纠错码为BCH编码。
形如BCH(255,128,16)码,其中255表示承载的码字长度(符号记为n),128表示携带的信息长度(符号记为k),16代表纠错数量(符号记为t),生成多项式阶数位n-k。BCH码的码元取自二元有限域中,记为GF(2),其扩展域记为GF(2m),取m0=1,δ=2t+1,设是GF(2m)的本原域元素,则由BCH码的定义可知,若码以α,α2,…,α2t为根,则二进制BCH码的生成多项式为[9]
g(x)=LCM{m1(x),m2(x),…,m2t(x)}。
(7)
式(7)中LCM表示取最小公倍式,mi(x) 是αi(1≤i≤2t)的最小多项式,能纠正t个错误。在特征为2的GF(2m)域上,α2i的最小多项式与αi的相同,所以多项式也可以写成
g(x)=LCM{m1(x),m3(x),…,m2t-1(x)}。
(8)
因此,二进制BCH码以α,α3,α5,…,α2t-1为根,码长为
n=LCM(e1,e2,…,e2t-1)。
(9)
所以,对任何正整数m和t,一定存在一个二进制BCH码,它以α,α3,α5,…,α2t-1为根,其码长n=2m-1或是2m-1的因子,能够纠正t个随机错误,校验位数据为m×t个。
本系统为了使256位的密钥采用分组纠错编码后形成512位码字,将每组128位数据经过BCH(255,128,16)编码后获得的255位码字进行填充,最终形成2组256位码字。
在本系统的模糊承诺方案中,包括承诺和密钥提取两个步骤,如图8所示。
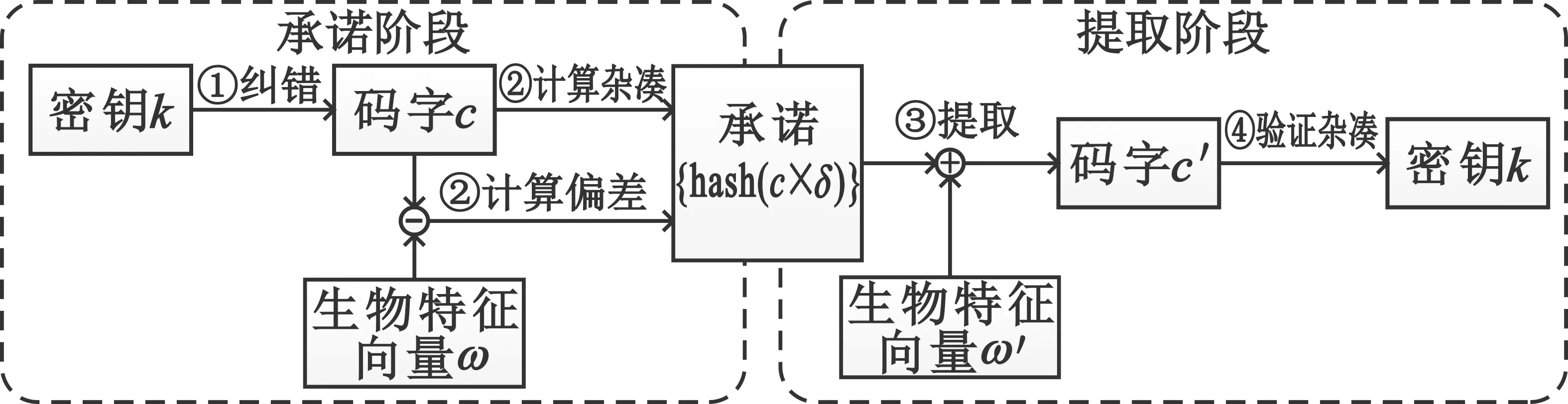
图8 模糊承诺算法原理示意图
在承诺过程中,首先随机生成或输入一个密钥k,并对其计算某种纠错码体系中的码字c,其长度与生物特征向量ω相同,然后计算偏差δ=ω-c,最后形成承诺为{hash(c),δ}。在密钥提取过程中,用户输入一个生物特征向量ω′,再从承诺中解出码字c′=ω′-δ,如果ω和ω′在某种距离测度下足够接近,同时通过杂凑密码算法验证hash(c′)与hash(c)相等,则可认为c′和c一致。
系统中的杂凑密码算法是数据完整性保护和检测、消息鉴别、构造数字签名和认证方案等不可缺少的工具,具有压缩性、简易性、单向性、抗碰撞等性质,在信息安全和密码学领域应用非常广泛。本系统采用的SM3杂凑密码算法是中国密码管理局2010年公布的商用密码杂凑算法标准,消息分组为512位,输出杂凑值256位,采用Merkle-Damgard结构[10]。该算法在模糊承诺算法中用于验证密钥的完整性。
基于模糊承诺理论,在系统的注册阶段,密钥保护过程设计如图9所示。
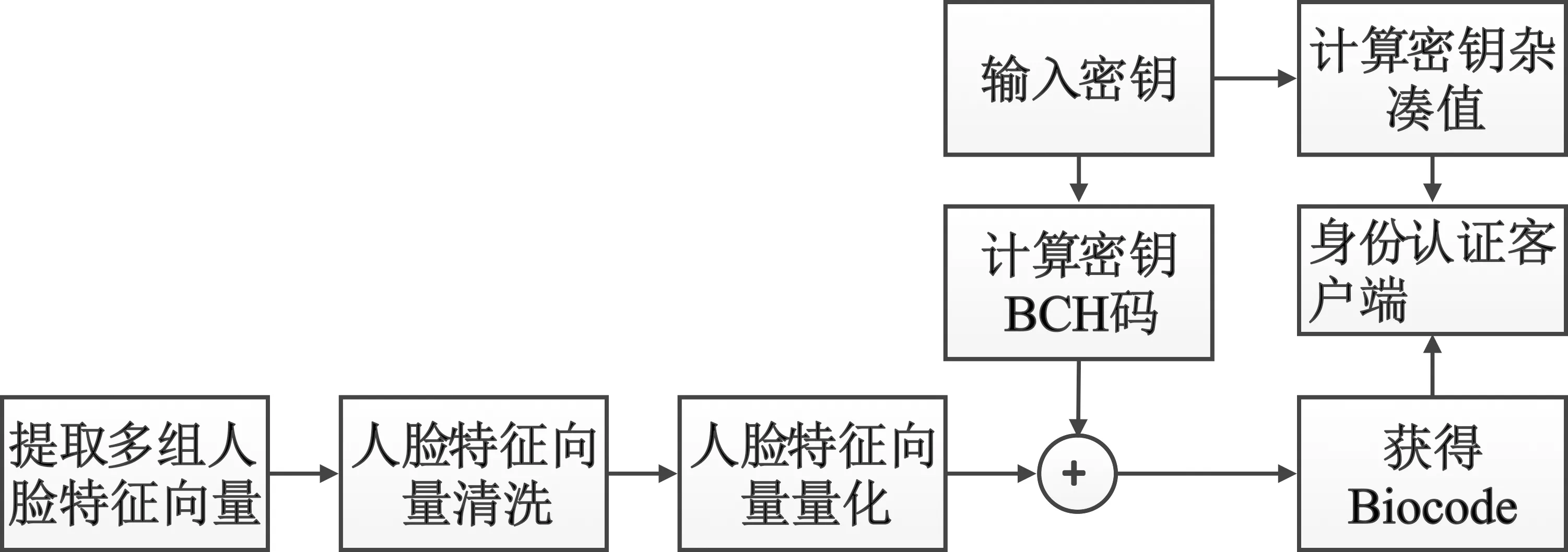
图9 密钥保护过程示意图
首先,需要提取多组人脸识别向量,并对其进行清洗。采用多组人脸特征向量能够大大提高人脸特征数据的稳定性。实验发现,在提取多组人脸特征向量时,偶尔会出现一组数据因拍摄光线和人脸角度问题,导致特征数据出现较大偏差,影响实验结果,因此需对特征向量进一步清洗,去除与平均值距离最大的人脸特征向量。人脸特征向量距离的计算公式为
(10)
然后,对剩下的样本数据计算平均值,从而获得一组新的128维特征向量。最终得到当前注册的人脸特征数据Xfinal为
(11)
接着对清洗之后的特征数据进行量化。本系统采用多值量化方法,需要注意的是量化设计时应满足人脸特征数据差值越小、变化位越少的特性。量化后即可获得512位的码字Y,即
(12)
同时,将256位秘密密钥MK分为2组(每组128位),并分别对2组采用BCH纠错码对秘密密钥MK进行编码,获得512位码字。秘密密钥经过编码后,把编码后的结果与上一步获取的512位特征码字异或,形成512位码字的生物识别码,记为Biocode,并与秘密密钥MK的杂凑值一起存储在身份认证客户端。
在认证阶段,密钥提取过程如图10所示。
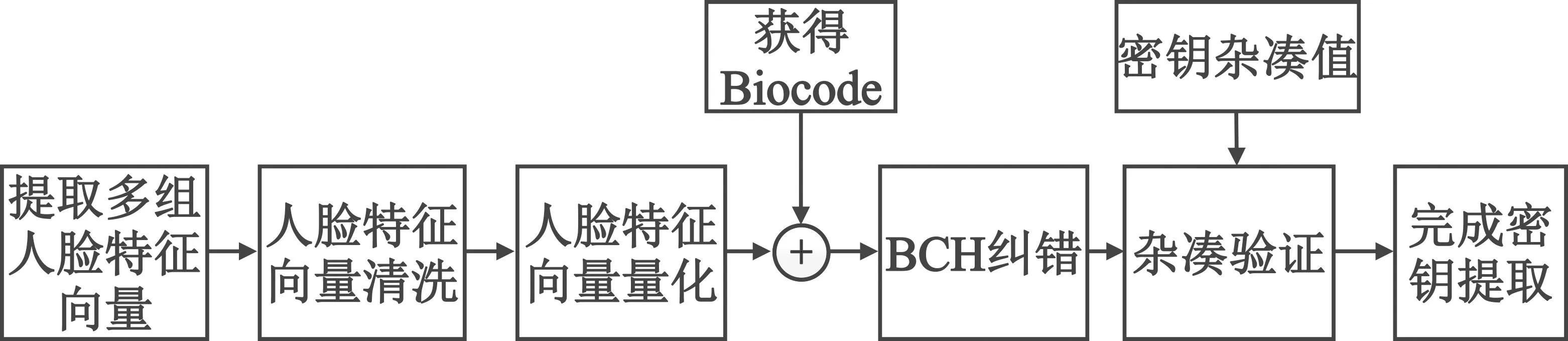
图10 密钥提取过程示意图
首先仍然提取多组人脸特征向量,并对其进行清洗和量化,其方法与注册阶段相同,即可获得512位的码字。然后,将512码字与Biocode异或,根据亦或运算的自反律,得到输入密钥的近似数据。再将获得的结果分成2组(每组256位),对每组数据进行BCH纠错,可获得2×128位数据,记为MK′。完成密钥提取获得MK′后,再对其进行杂凑计算,并与注册阶段产生的密钥杂凑值进行比较,若一致,则密钥提取成功,否则密钥提取失败。
2 系统实验及对比
2.1 实验条件
通常,基于生物特征的身份认证系统的性能是由精确度、速度等数据来评估的,其中精确度是最重要的技术指标,一般又使用识别率进行标示,由误识率和拒识率来测定。单纯的生物特征身份认证技术实际应用时,难以达到误识率和拒识率绝对理想状态。以Dlib识别人脸为例,通过计算人脸特征数据的欧氏距离是否小于一个容错率来判别是否为同一个人,使用样本测试数据(亚洲人脸数据)获得如图11所示的测试结果。
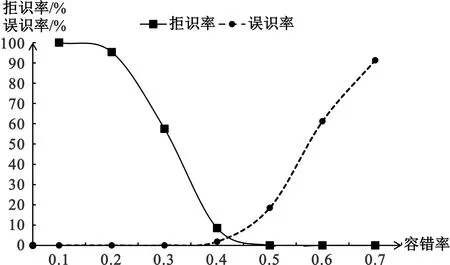
图11 Dlib样本数据识别率
从统计数据可以看出,容错率要小于0.2才能达到误识率为0的理想状态,但此时拒识率已超过90%,不具备实用状态。实际应用中,从平衡角度考虑,一般选择0.4的容错,误识率约为0.83%,拒识率约为6.1%。
身份认证系统是系统安全防护的重要防线,为提高系统安全性、提升易用性,本系统设计目标为确保误识率为0%,拒识率小于1%。为此,本文使用基于上述方案研发的身份认证系统进行实验验证,并通过获取拒识率和误识率进行参数调整和优化。身份认证系统认证界面如图12所示。
图12 身份认证系统认证界面
实验样本数据主要采用了两个公开数据集:一个是YaleB数据集,里面有10个人的5 760张图像,每个人包含了9个姿态、64种光照变化;另一个是CFP数据集,该数据集由500人的7 000张图片组成,每个人拍摄了10张正面照和4张侧面照。
2.2 阈值选择实验
在量化阈值选取过程中,如果阈值选取较小,会造成系统判断相同人脸的标准较为严格,进而导致系统的拒识率较高而不可用;同理,如果阈值选取较大,会造成系统判断不同人脸的标准较为宽松,进而导致系统的误识率较高而不可用。所以,找到一个能达到平衡的较优阈值对系统的可用性十分重要。
拒识率实验数据选择YaleB数据集的相同人进行密钥提取,误识率实验中选择CFP数据集中的不同人进行密钥相互提取,测试不同阈值对拒识率和误识率的影响,实验结果如图13所示。
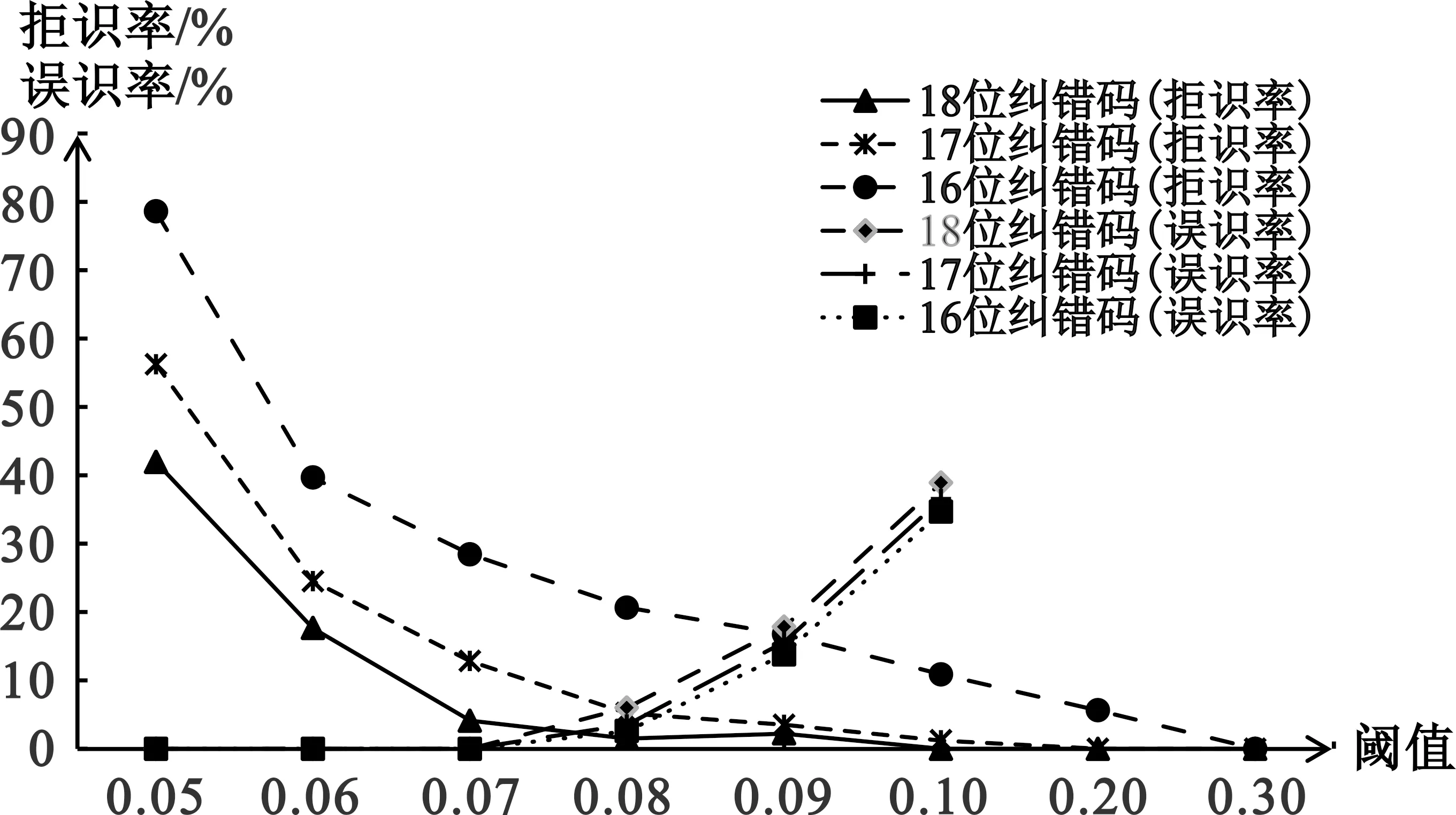
图13 多阈值拒识率、误识率实验图
从图13可看出,随着阈值的增加,拒识率整体呈下降状态,但当阈值超过0.08时,系统的误识率逐渐增加,当系统中有误识率存在时,证明该系统已达到不可用状态。基于此,将系统的量化阈值选定为0.07。
2.3 多样本组对比实验
在选取较优阈值0.07的基础上,使用YaleB数据集里面的样本照片数据进行拒识率测试。将相同人的数据按组划分,每组分别由1张、3张、5张、7张、9张组成;然后调整BCH纠错码的纠错位数,分别测试纠错位为16、17和18情况下每组与其他组之间的密钥提取情况,通过密钥提取失败次数反应拒识率,探究多样本组对拒识率的优化程度。实验结果如图14所示,详细结果如表1所示。
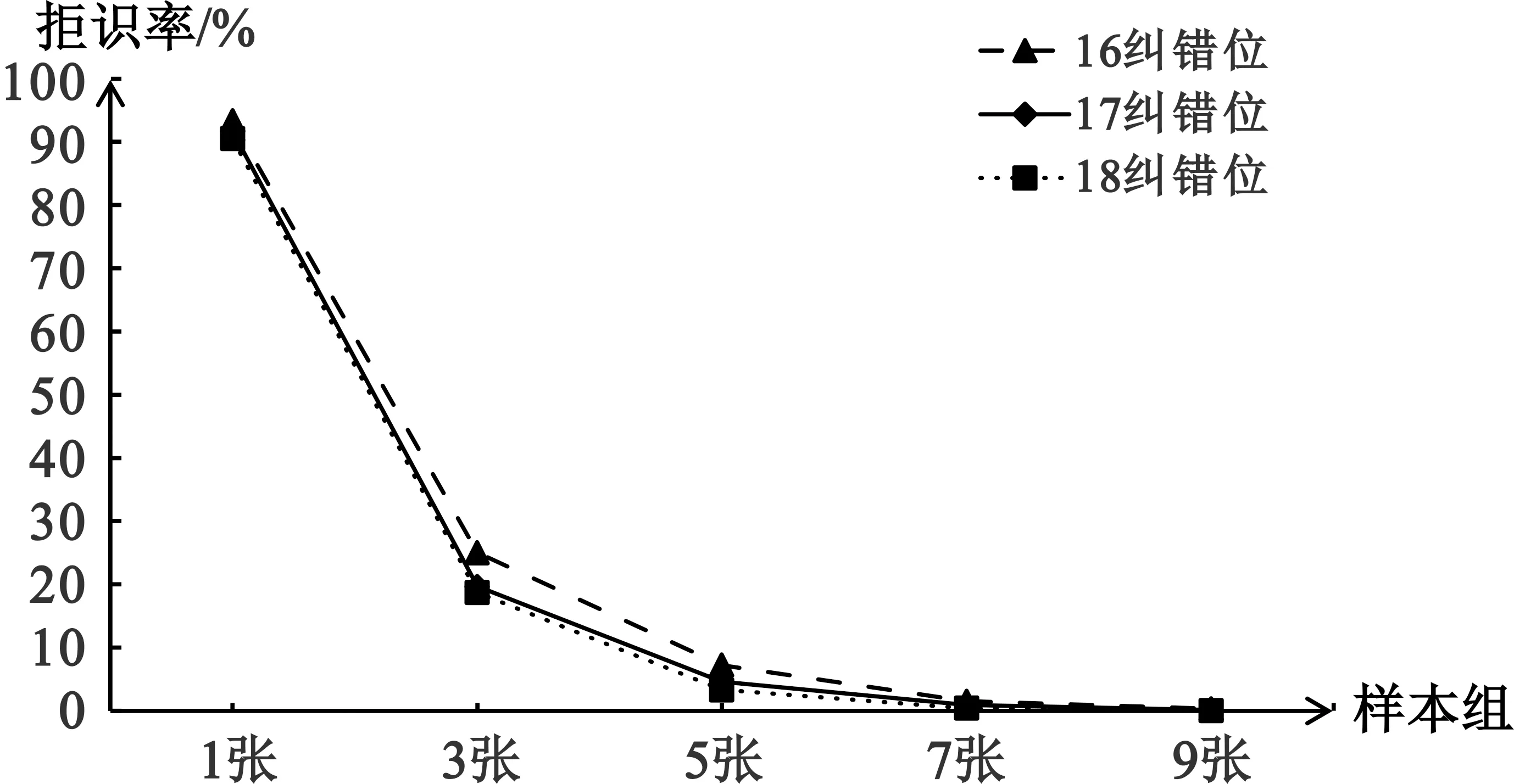
图14 多纠错位实验结果
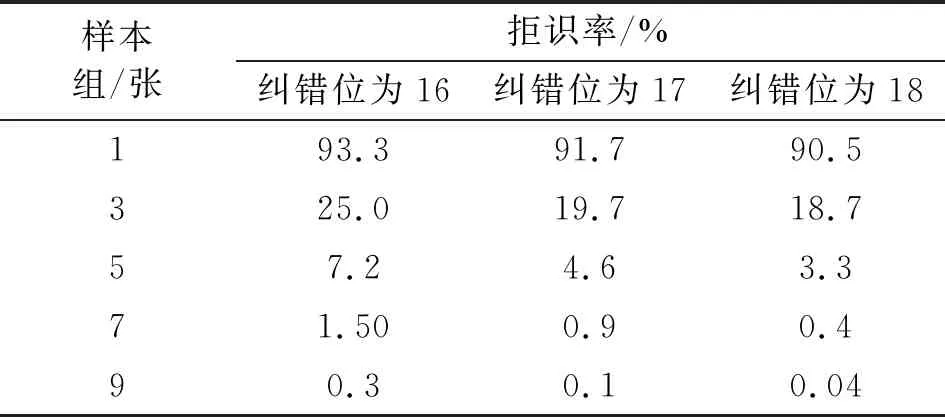
表1 BCH(255,128,X)纠错拒识率
从图14和表1中可以看出,在样本张数一定的情况下,随着纠错位数的增加,拒识率也在逐渐减少。对于BCH(255,128,X)纠错码,随着分组张数的增加,每组之间的提取也趋于稳定。
2.4 纠错位对比试验
基于0.07的量化阈值,使用CFP里面的样本照片数据进行误识率测试。把每个人的照片按照1张、3张、5张、7张、9张的方式分组,然后通过调整BCH纠错码的纠错位数,分别测试纠错位为16、17和18情况下相同数量分组下不同人之间的密钥提取情况,通过密钥提取成功次数反映误识率,详细结果如表2所示。
从表2中可以看出,在选取量化阈值为0.07的基础上,在17和18位纠错码下出现了误识率,分别对应0.000 8%和0.001 6%,其他情况下实验误识率均为0。
2.5 实验总结与对比
通过上述实验可得,影响系统误识率和拒识率因素主要有三个,即量化阈值、样本组数量和BCH纠错码纠错位数。阈值小,拒识率高,误识率低;阈值大,拒识率低,误识率高;增加样本组数量,可以降低拒识率,并增加特征数据稳定性。而纠错码BCH(255,128,X)会随着纠错次数X的增大降低拒识率,增加误识率。通过优化这三个变量,选择0.07的量化阈值,9张人脸特征数据作为样本分组,BCH(255,128,16)纠错码,系统误识率为0,拒识率为0.3%。
表3为本文方法与其他方法的对比。由于其他方法所采用的数据集无法支撑多样本组的系统试验,因此其数据均取作者实验中的最优值。
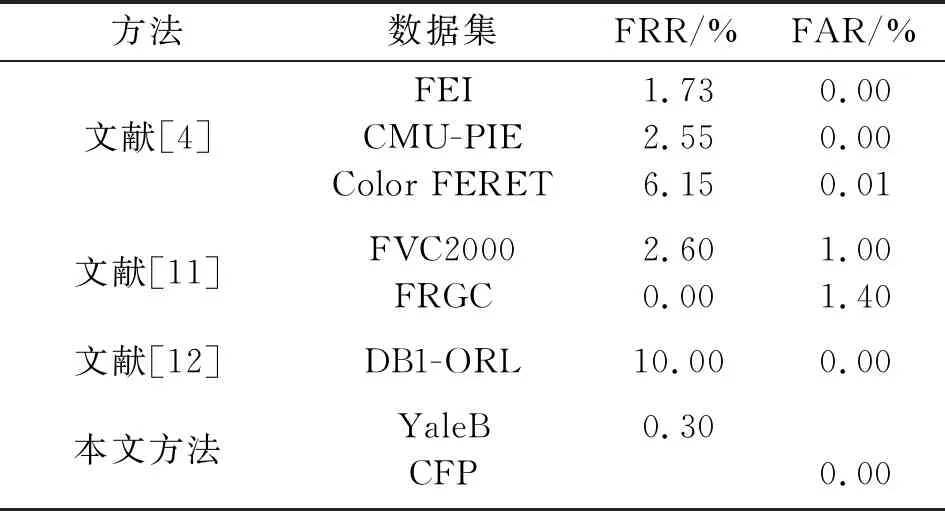
表3 各类方法拒识率、误识率对比
如表3所示,文献[4]中作者利用深度卷积神经网络,通过正交映射矩阵、量化损失函数、最大熵损失函数将人脸模板转换成二进制数据,利用BCH纠错处理,得到的最优误识率为0%,最优拒识率为1.73%;文献[11]中作者采用了二值量化的方法,利用汉明距离分类器,将人脸特征转换为二进制数据,当使用GRGC数据集时将拒识率降低为0%,但是并未消除误识率;文献[12]中作者将人脸和指纹融合为一个新的生物模板,利用该模板构建模糊金库,从而实现身份认证系统的认证过程,其将误识率降低至0%,但存在较高的拒识率。对于本文方法,通过设定多值量化的量化阈值,调整BCH纠错位数,加上多样本组提取,在消除误识率的基本要求下,将拒识率降低为0.3%,性能较优。
3 结束语
本文详细阐述了以模糊承诺为基础原理的基于密码和生物特征识别的身份认证系统的设计模型、人脸特征提取、活体检测、密钥保护和提取方法等方面,并通过大量样本数据进行实验,表明该系统的误识率和拒识率达到了可实用化程度。然而为满足实际应用的需求,还需进一步通过应用试点等方式开展海量数据和真实应用环境的验证,优化系统效率,提升用户体验,并探索和解决如双胞胎等相似外貌的人脸识别机制。随着社会网络化和信息化的发展,基于生物特征的身份认证势必将获得更加广泛的应用,密码作为信息安全的基石,生物特征加密技术也将持续发展和成熟,在人们生活、工作的各个领域发挥重要作用。
