基于分离混合注意力机制的人脸表情识别*
2022-09-28余久方李中科
余久方,李中科,陈 涛
(1.南京工业职业技术大学 计算机与软件学院,南京 210023;2.南京理工大学紫金学院 计算机学院,南京 210023)
0 引 言
人脸表情是人类情绪和状态的最直接表现,自动识别人脸表情在智能医疗、智能交通、公共安全、智能学习及娱乐等领域具有重要意义[1]。如何识别人脸表情进而感知人类情绪,近年来大量的学者对此开展研究并取得了一定的进展。
卷积神经网络在图像识别领域取得了巨大成功,逐渐被用于人脸表情识别[2-4]。表情只和人脸面部相关,因此从原始图像中识别出面部区域对于后续表情识别至关重要。2014年汤晓鸥[5]团队提出了深度学习人脸识别算法DeepID,在LFW数据库上取得较高识别率。2016年Zhang等[6]提出了一种多任务卷积神经网络(Multi-task Convolutional Neural Networks,MTCNN)的人脸识别方法,目前在人脸识别中应用较多。该算法能适应不同大小的人脸图像输入,因此本文选用该算法进行面部识别。
本文设计了一个混合注意力网络,分离原注意力机制中的通道注意力和空间注意力,在注意力后引入软阈值抑制噪声,形成新的软阈值通道注意力(Channel Attention Soft Thresholding,CA-ST)和软阈值空间注意力(Spatial Attention Soft Thresholding,SA-ST)。通道注意力嵌入深度可分离卷积中,形成深度可分离卷积软阈值通道注意力(Channel Attention Soft Thresholding Depthwise Separable Convolution,CA-ST-DSC),增强网络的通道特征学习能力;空间注意力放在普通卷积后,增强网络的跨通道相关性学习能力。相比上述提及的研究成果,本文设计的网络用于人脸表情识别准确率更高,收敛性更好,所用参数相对较少。
1 数据预处理
为了让图像中的面部细节特征突出,考虑使用直方图均衡化对人脸图像进行处理,让图像中具有不同灰度的部分对比度增强,增强网络的泛化能力。自适应直方图均衡化[7]仅考虑局部区域数据,忽略了其他区域数据,并且有可能放大局部噪声,限制对比度自适应直方图均衡化(Contrast Limited Adaptive Histogram Equalization,CLAHE)统一考虑了局部区域内和区域外的数据并且能抑制噪声放大的情况。本文使用该算法对图像进行处理,简化原算法中的参数设置,优化剩余像素的处理。算法步骤如下:
Step1 原始图片按照固定大小切分为若干块,计算每块的直方图H(N),N表示该块内的灰度级数。
Step2 计算截取限制值β,块内超出该值的像素将在后续处理中被截去,其在原算法中计算公式为
(1)
式中:α为截断系数,取值范围[0,100];lmax为最大允许斜率,建议最大为4;S为块内的像素数。本文在实现中简化截取限制值的计算,只需设置一个参数为
(2)
Step3 对块内超出限制值β的像素进行剪切,截取到的像素总数为
(3)
截取后的像素根据N个灰度取平均值为
(4)
Step4 把截取的像素分配到直方图中:
(5)
Step5 每个块内进行直方图均衡化和双线性插值。
原算法执行Step 4后可能有部分像素剩余,本文实现中对剩余像素按照公式(4)计算后再次执行Step 4,直到分配完成。
为增强网络泛化能力,还在训练过程中随机对训练样本进行变换以使网络适应不同的输入。根据人脸数据集特点,考虑针对姿态和面部大小进行变换,因此对样本进行角度变换及比例缩放处理,在处理中进行随机的水平镜像。角度变换矩阵为
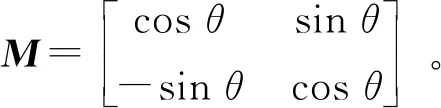
(6)
式中:θ为变换角度。缩放变换矩阵为
(7)
式中:Cx、Cy分别为水平和垂直方向的缩放比例。变换角度在(-20°,20°)之间随机选取,缩放比例在原图的20%范围内,效果如图1所示。其中,第一行为原始图片,第二行为角度变换效果,第三行为缩放变换效果,变换中增加了随机的水平镜像。

图1 图像变换效果
2 本文网络模型
2.1 本文网络设计
现有的注意力机制多是聚焦机制内部实现,没有结合主干网络全局考虑,准确率提升并不明显,因此本文重新设计了主干网络和注意力网络。
本文的网络设计中将原混合注意力机制中的通道和空间注意力分离,把通道注意力机制置于通道特征提取后,空间注意力机制置于跨通道特征提取后。受文献[8]启发,在注意力机制中引入软阈值化处理,以抑制注意力学习中的噪声信息,增强高层特征的判别性。借鉴文献[9]的研究,在注意力机制处理后迭加输入以避免网络加深时性能下降。
本文设计的通道注意力机制CA-ST结构如图2所示。在通道注意力特征学习后进行软阈值处理,以去除通道注意力中的噪声。
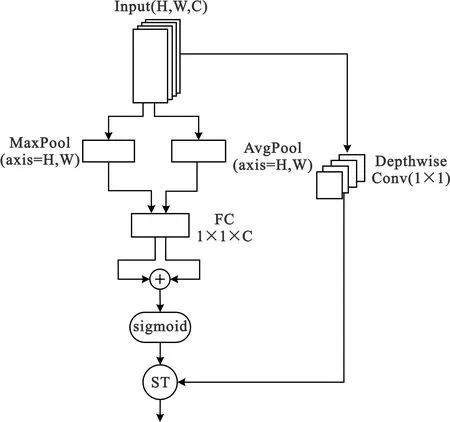
图2 CA-ST结构
首先输入特征图通过高、宽方向的最大池化和平均池化提取对应的通道特征,再经过共享的全连接层学习通道注意力后进行相加,得到的通道注意力特征为
EC(I)=f(AvgPoolH,W(I))⊕f(MaxPoolH,W(I)) 。
(8)
式中:f为全连接层操作,I为输入特征图(下同),H、W、C分别代表高、宽、通道(下同)。和原通道注意力不同的是全连接层中不再对通道进行压缩,以保留足够的通道信息,然后通过激活函数sigmoid把学习的通道注意力特征转化到(0,1)之间,得到通道注意力系数
(9)
式中:Ei(I)为第i个通道注意力特征。通道注意力系数反映通道对最终识别结果贡献的大小,通道注意力软阈值由通道平均池化特征乘以通道注意力系数得到:
τ=σ·AvgPoolH,W(|I|) 。
(10)
最终得到的通道注意力由输入根据软阈值机制处理后得到,消除其中的噪声数据,处理方法如下:
(11)
式中:Xc为输入特征经过1×1深度卷积后的输出。
深度可分离卷积在每个通道后进行卷积操作提取通道特征,这是深度可分离卷积的深度卷积操作。本文网络把通道注意力机制CA-ST嵌入深度可分离卷积的深度卷积之后,可以更有效地提取通道特征,再利用其后的点卷积学习跨通道相关性。本文的通道注意力融合深度可分离卷积的结构CA-ST-DSC如图3所示。
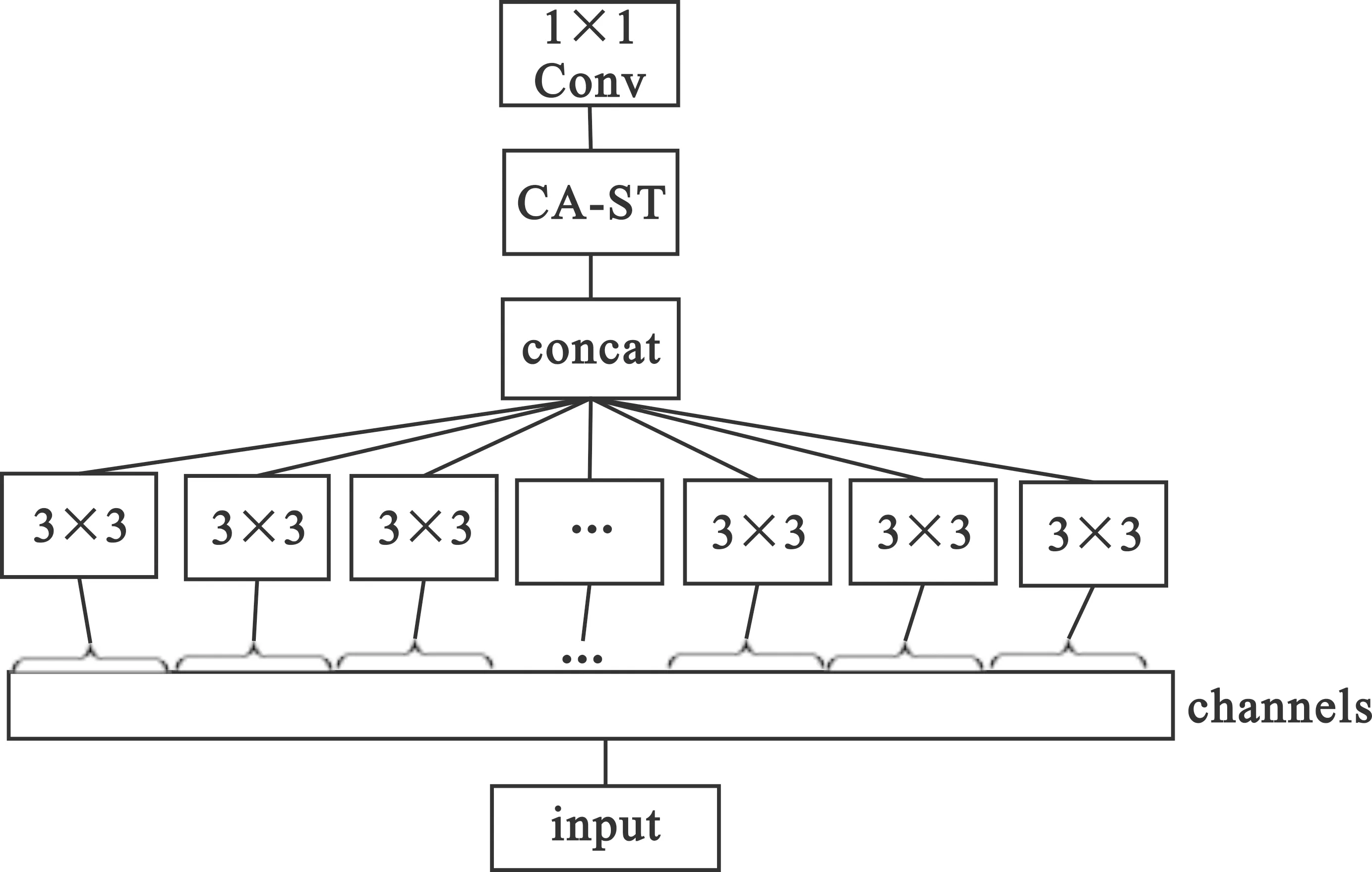
图3 CA-ST-DSC结构
本文设计的空间注意力机制SA-ST模型如图4所示,输入特征图基于通道维度分别进行最大池化和平均池化得到两组空间特征,通过concat操作后进行两次3×3的卷积得到空间注意力特征为
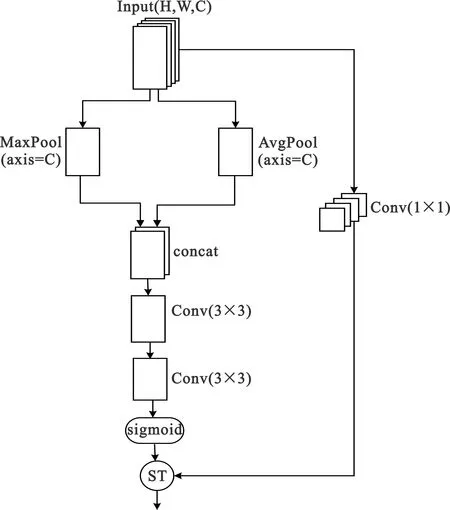
图4 SA-ST结构
EH,W(I)=Conv3(Conv3(AvgPoolC(I);MaxPoolC(I))) 。
(12)
然后经过sigmoid激活函数处理,把空间注意力特征变换到(0,1)之间,得到空间注意力系数
(13)
式中:Ei,j(I)代表位置(i,j)处的空间注意力特征。空间注意力系数反映特征图每个位置对识别结果贡献的大小,空间注意力软阈值由空间平均池化特征乘以空间注意力系数得到:
τ=σ·AvgPoolC(|I|) 。
(14)
最终得到的空间注意力由输入经过软阈值机制处理后得到,消除其中的噪声,处理方法如下:
(15)
式中:XH,W为输入特征经过1×1卷积后的输出。
结合本文设计的注意力机制的人脸表情识别网络结构如表1所示。其中,Entry flow和Exit flow使用普通卷积和深度可分离卷积进行特征抽取;classification flow中使用全连接层进行分类处理;Attention flow中使用带有软阈值空间注意力机制SA-ST和软阈值通道注意力机制CA-ST进行重点特征学习并去除噪声,把两个注意力机制分别置于普通卷积后和深度可分离卷积中,提高网络的跨通道相关性和通道特征学习能力。在注意力机制排列上,文献[10]实验表明先通道后空间更优,作者认为通道注意力关注全局信息而空间注意力关注局部信息。本文问题场景较为特殊,人脸面部每种表情之间差异小,需要先定位到需要关注的面部部位,然后再全局判断各通道特征对表情识别贡献大小,因此在本文网络中采用先空间后通道的方式,在实验过程中也发现该种方式对表情识别效果更优。在卷积操作后增加批正则化(Batch Normalization,BN)[11]和激活函数ReLU处理来增强网络的稳定性。
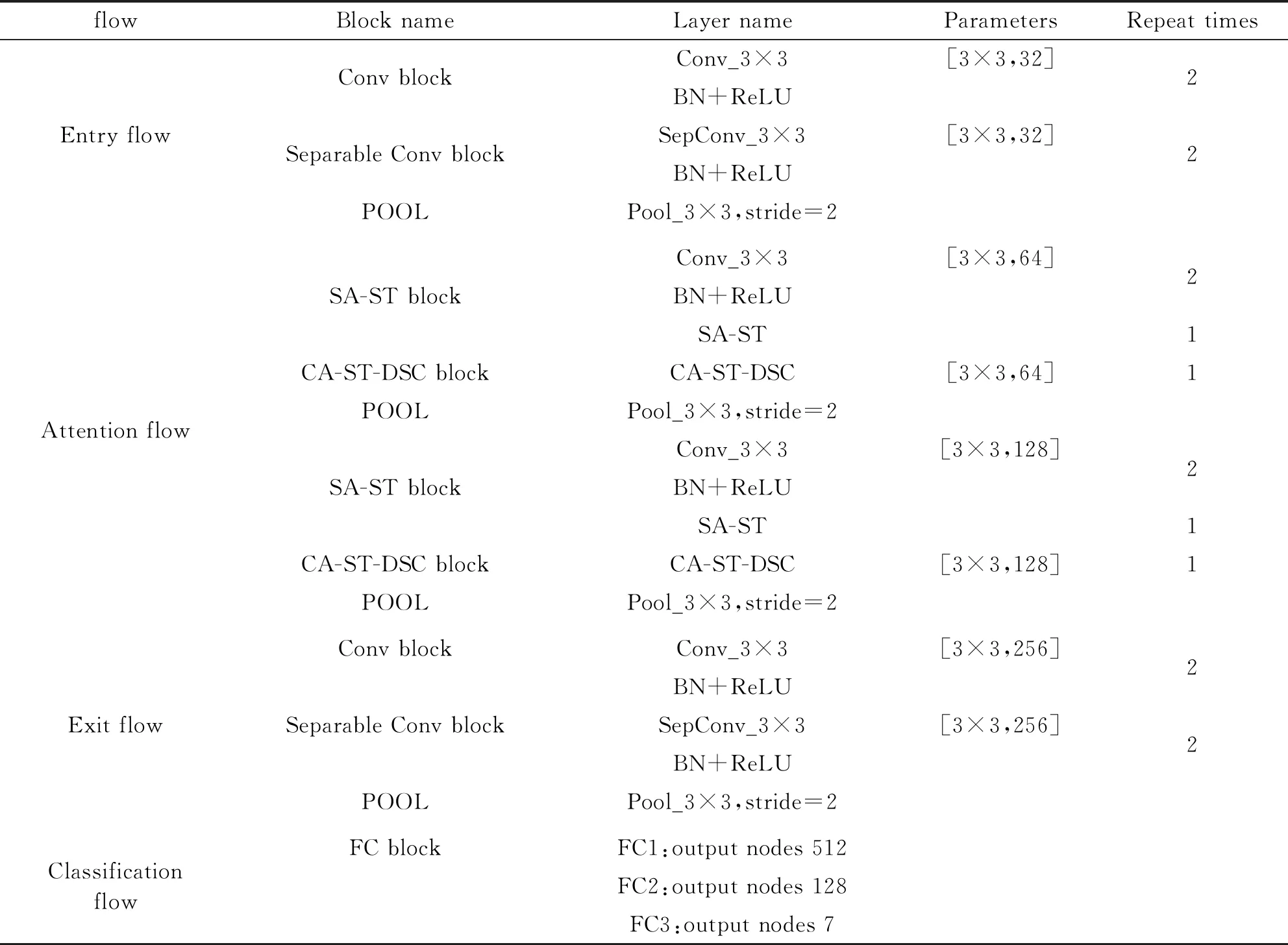
表1 本文网络结构
表1中Layer name为操作名称,其中Conv为卷积操作,SepConv为深度可分离卷积操作,Pool为池化操作,BN为批正则化操作;Parameters为卷积核大小和通道数;Repeat times为对应的操作重复执行次数,未标出的操作重复次数为1。
2.2 损失函数设计
输入特征图经过网络处理输出后,通常使用softmax处理并计算交叉熵损失:
(16)
式中:xi为第i个样本最后的全连接层之前的输出,其所属的类别为yi;wj为第j个全连接层权重参数;wyi为第yi个全连接层权重参数;m为一次训练中的batch大小;n为类别数目。
为了让同一类表情在特征空间中尽可能靠近,参考文献[12-13],把样本到类中心的距离作为损失函数的一部分,该距离即为中心损失,其计算方法为
(17)
式中:cyi为第i个样本所在的类别中心。类别中心在迭代训练中进行更新,类别中心的更新要使中心损失最小化。另外,为防止新的中心抖动过大,在更新值中增加一个系数。第i个样本类别中心的更新值公式为
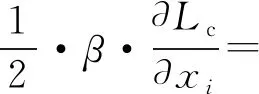
β(xi-cyi) 。
(18)
式中:β为类别中心更新系数。总的损失计算函数为交叉熵损失迭加类中心损失,即
L=Lcross+λLc。
(19)
式中:λ为中心损失系数,表示中心损失在总损失中的权重。
3 实验结果与分析
3.1 人脸表情数据集
本文使用CK+和fer2013两个数据集进行实验。
CK+数据集是在 Cohn-Kanade 数据集的基础上扩展而来,该数据集包含了123个参与者的593个图片序列,其中327个图片序列有标签,每个图片序列包含了一个参与者从情绪平静到情绪峰值的过程,每张图片的分辨率为640 pixel×490 pixel。实验中选取了每个人物带有标签的图片序列中的两张图片:一张是情绪峰值图片,一张是情绪相对较次峰值图片。一共654张图片,包含7种情绪,分别是1(愤怒)、2(蔑视)、3(厌恶)、4(害怕)、5(高兴)、6(伤心)、7(惊讶)。各类表情数量分布见表2。
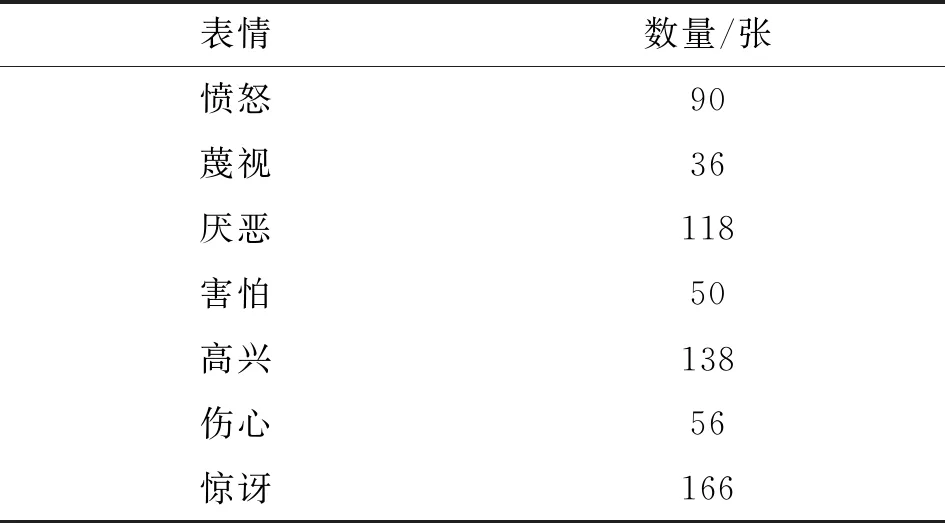
表2 CK+数据集中各表情数量
fer2013数据集一共有35 887张图片,其中用于训练集的图片有28 709张,用于验证集和测试集的图片各有3 589张。该数据集每张图片大小为48×48,包含了7种人脸表情,分别为0(生气)、1(厌恶)、2(害怕)、3(高兴)、4(伤心)、5(惊讶)、6(中性)。各类表情数量分布见表3。该数据集含有较多非正面人脸图片,人工识别该数据集只有65%左右的准确率。
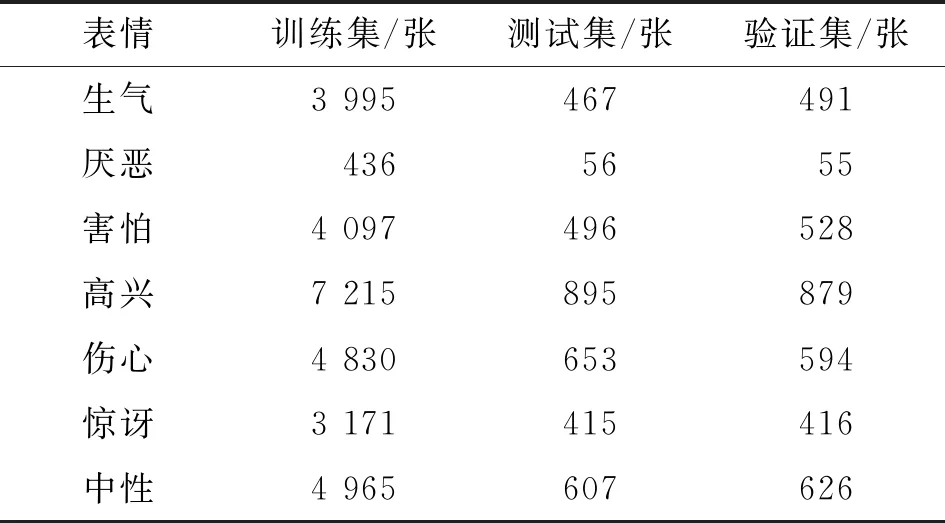
表3 fer2013数据集中各表情数量
3.2 实验环境及参数设置
本文实验所用的环境:硬件为CPU Intel Xeon E5 V3 2600@2.3 GB,内存16 GB,显卡为NVIDIA GTX1080Ti,显存11 GB;操作系统为Ubuntu16.04,软件框架为tensorflow1.14。
在实验中CK+数据集和fer2013数据集训练的batch大小分别设置为50和128。在CK+数据集上采用K折交叉方式进行验证:数据集分为K份,其中1份作为测试集,其余K-1份作为训练集,实验K次,本文实验中K取10。为方便比较,两个数据集均展示测试集的实验结果。fer2013上使用的是数据集自身的测试集,CK+数据集使用的是K折交叉方式提取的测试集。
在网络训练中初始学习率设置为0.01,采用指数衰减方式来逐步减小学习率,衰减率为0.5。优化器使用标准动量优化方法,动量设置为0.9。损失函数中β取0.6(公式(18)),λ取0.001(公式(19))。
3.3 实验结果分析
3.3.1 预处理结果分析
本文选用的CK+和fer2013数据集通过MTCNN网络进行人脸检测,对于能完全识别出人脸5个特征点的图片进行裁剪,其余图片不做处理。对于CK+数据集,识别率为100%。根据特征点进行人脸裁剪后,使用双线性插值统一缩放到64×64大小;对于fer2013数据集,识别率为82%,进行人脸裁剪后统一缩放到48×48大小。
两个数据集进行人脸识别、裁剪、直方图均衡化后处理效果如图5所示,图中第1行为人脸识别、裁剪后的输出,可见人脸识别精确;第2~5行分别为限制系数M(公式(2))取1、2、5、10时直方图均衡化后的输出,可见M越大处理后的图片对比度越强,细节部分越突出,但面部细节太突出影响网络对表情的识别效果,经过实验对比本文M取2,块大小取(6,6)。

图5 人脸识别、裁剪,直方图均衡化结果
3.3.2 表情识别结果分析
使用本文方法在CK+数据集上进行了150 epoch的训练,结果如表4所示,在测试集上得到了98.6%的准确率,相比其他方法准确率较高。本文方法在fer2013数据集上进行了140 epoch的训练,在测试集上准确率达到了72.1%,相比其他方法准确率较高,准确率对比如表5所示。
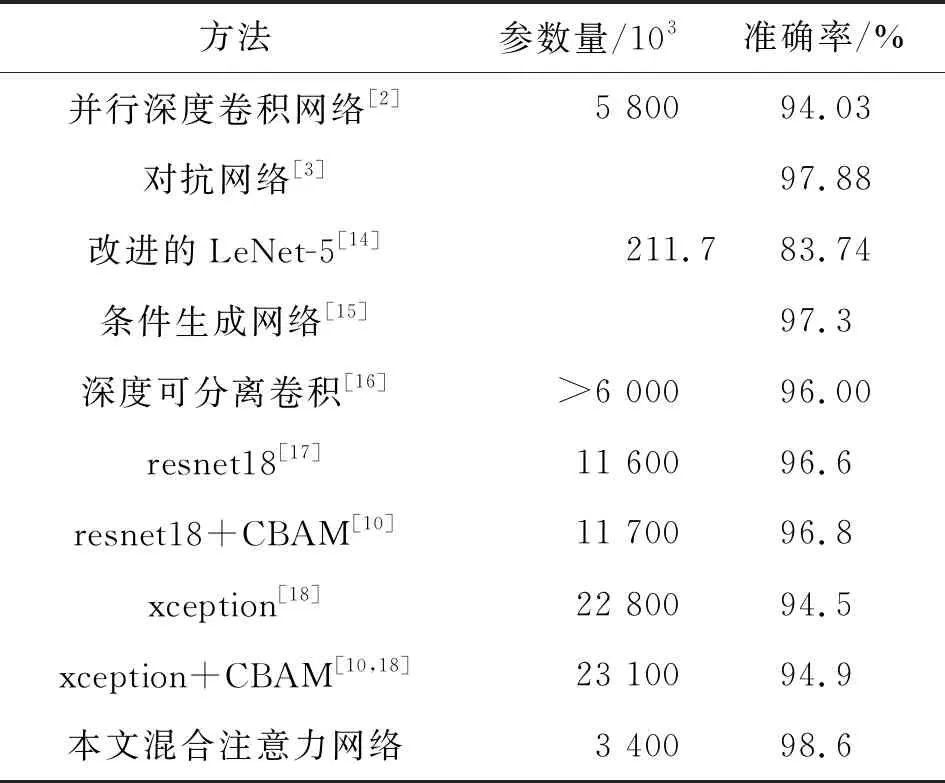
表4 不同方法在CK+数据集上识别结果
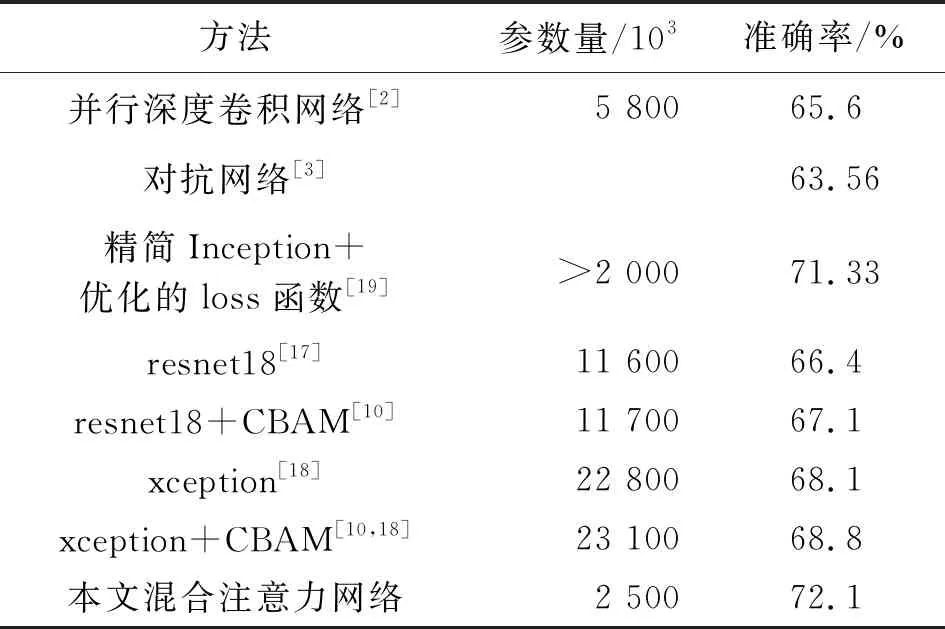
表5 不同方法在fer2013数据集上识别结果
CK+数据集每种表情识别准确率如图6所示,其中,高兴、厌恶、愤怒三类表情识别率相对较高,蔑视、害怕的表情数量较少,识别率相对也较低。在7类表情中,蔑视、愤怒、害怕这几类表情容易混淆。
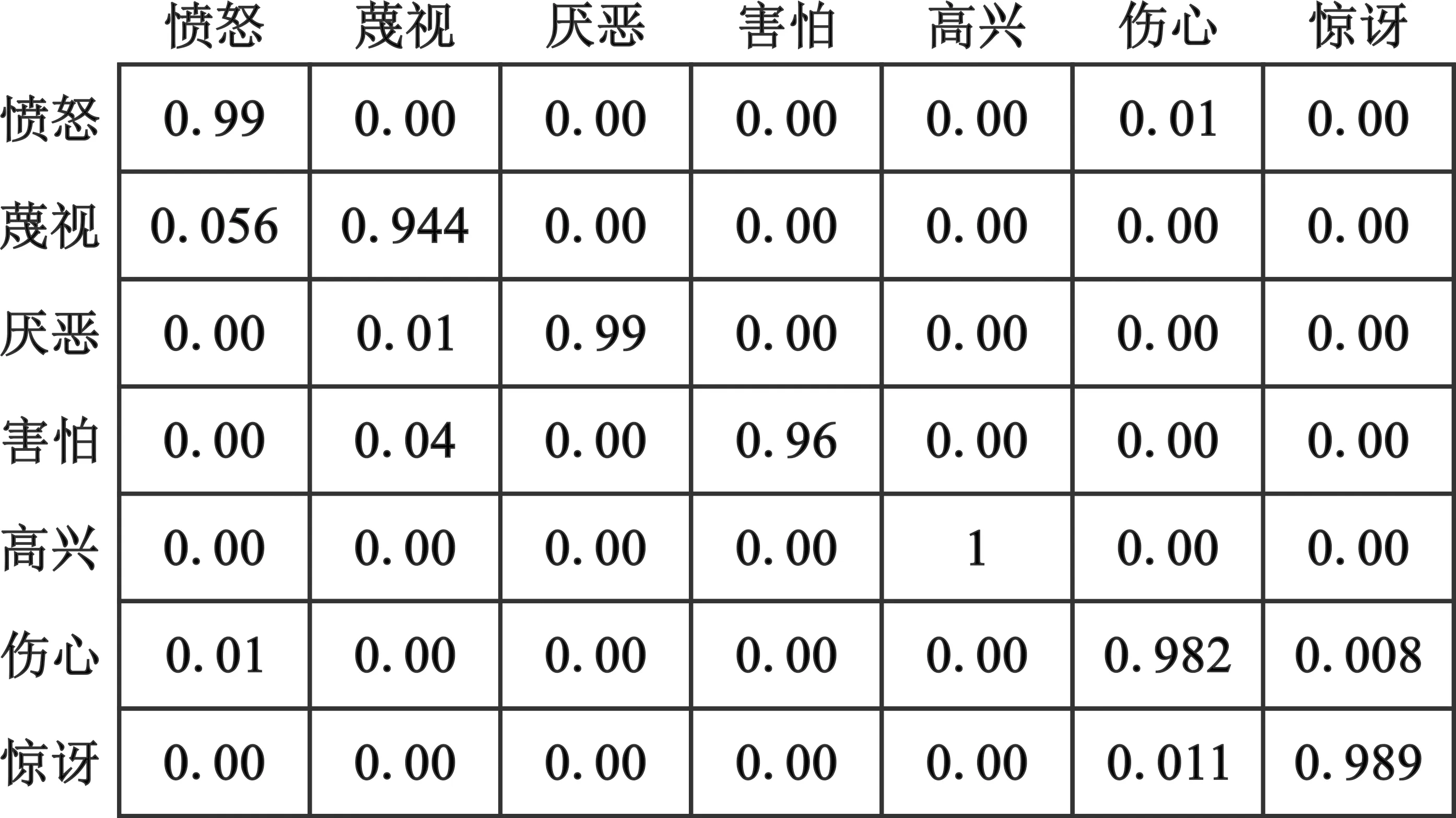
图6 CK+数据集混淆矩阵
fer2013数据集每种表情识别准确率如图7所示,其中高兴、惊讶两类表情的识别准确率较高,害怕、伤心、中性三类表情识别率较低。这三类表情的数据集数量并非最少,识别率低主要是由于误识别为其他表情,害怕和伤心、伤心和中性、厌恶和生气这几组表情容易混淆。
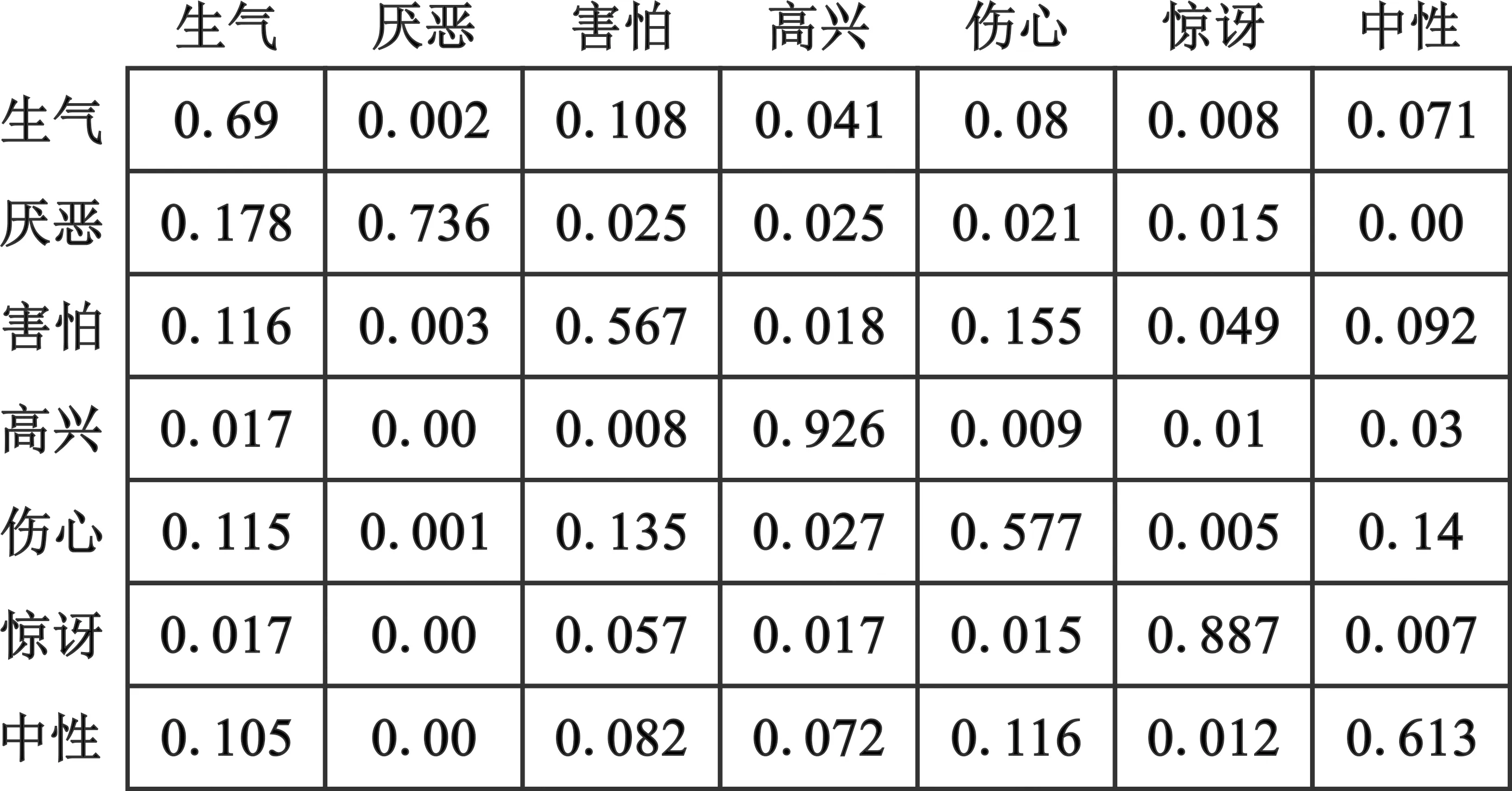
图7 fer2013数据集混淆矩阵
在参数量上本文网络在CK+数据集上为3.4×103,在fer2013上为2.5×103,网络在最后的卷积操作后没有对特征图进行全局池化,因此不同的输入在全连接层参数量有差异。由表4和5可以看出本文网络需要的参数量相对较少,两个表中的resnet18、resnet18+CBAM、xception网络直接使用原文献中的网络结构,xception+CBAM结构为在xception网络中的入口流程中每个可分离卷积块以及中间流程之后迭加CBAM机制。以上四个网络在实验时的超参数及损失函数和本文网络相同。
为了从数据上对比本文注意力机制和原注意力机制,图8和图9给出了不同方法在两个数据集上的准确率随着epoch变化的曲线,可以看出本文方法收敛性较好并且最终的准确率较高。
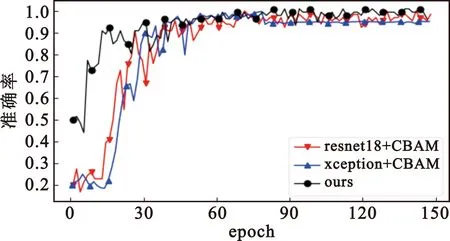
图8 不同方法在CK+数据集上准确率曲线
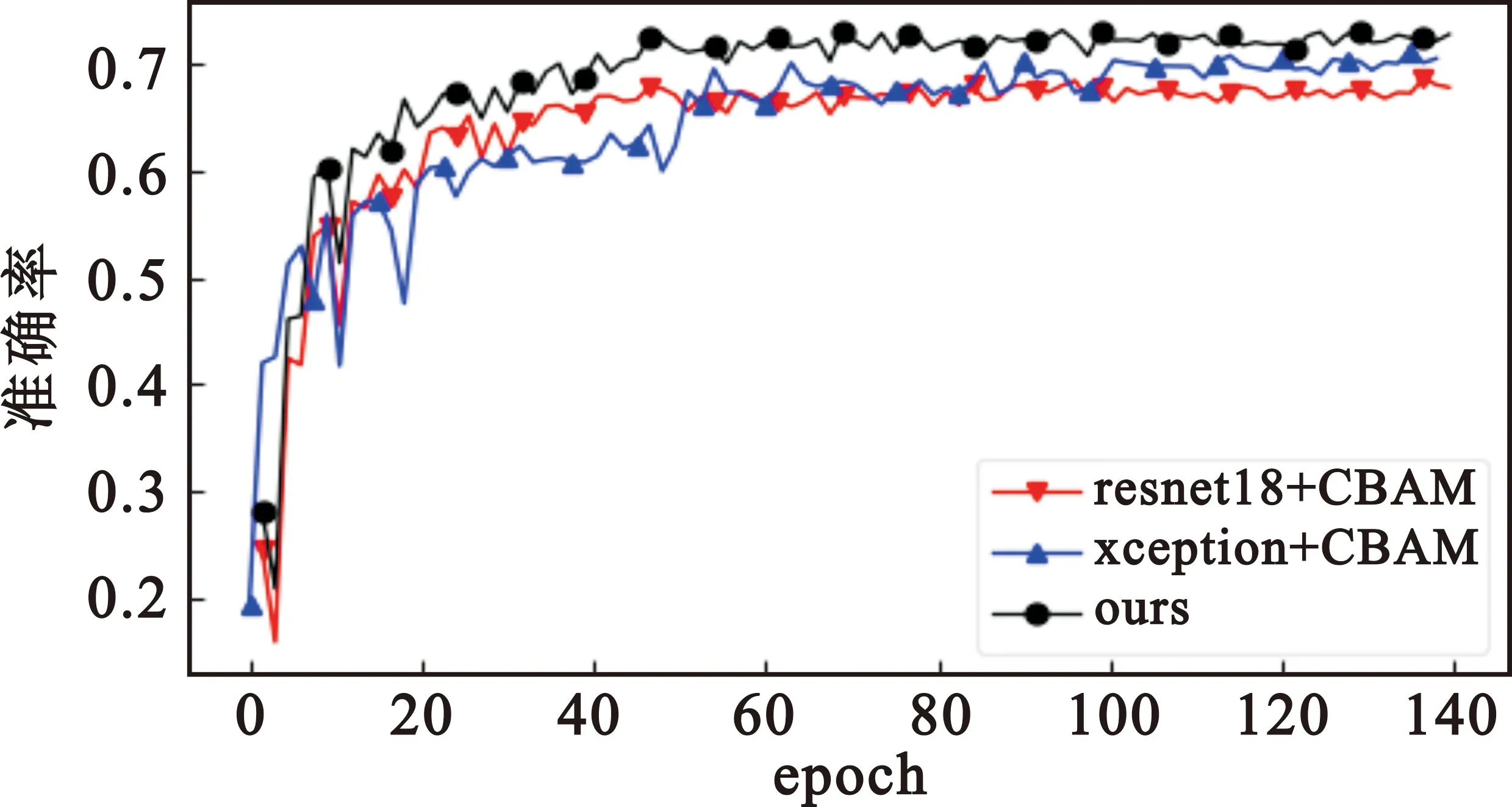
图9 不同方法在fer2013数据集上准确率曲线
为直观对比本文混合注意力机制和原注意力机制,输出浅层网络的特征图以便于观察。在本文网络的entry flow后分别迭加本文的SA-ST、CA-ST-DSC以及CBAM,分别经过50 epoch的训练后,提取网络部分输出如图10所示,其中第1行为网络输入,第2行为迭加CBAM机制输出,第3行为迭加本文注意力机制输出,可以看出本文的注意力机制能够保留对表情识别贡献较大的面部区域,同时对表情识别贡献小的区域进行抑制。
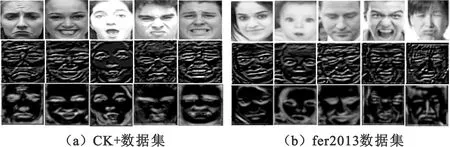
图10 网络中间输出
本文预处理中的直方图均衡化和角度变换、缩放以及镜像,可以有效增强网络的泛化能力,两个数据集增加预处理前后的准确率对比如表6所示。预处理前训练集准确率明显高于预处理后,而测试集上准确率变化相反,由此可知预处理前网络泛化性较差,而预处理能够缓解该问题,提升测试集的识别准确率。

表6 预处理前后准确率对比
4 结束语
人脸表情自动识别作为人工智能重要的研究领域之一,由于不同的人脸表情之间差异较小,同时由于人脸图像受光照、姿态等方面的影响,识别准确率一直有待提高。本文设计了一个分离混合注意力网络,把空间注意力和通道注意力分开,分别置于普通卷积和深度卷积之后,同时使用软阈值抑制噪声,在人脸表情数据集CK+和fer2013上取得了98.6%和72.1%的识别率,相比其他方法明显提高了识别准确率,所用参数相对较少,并且收敛性更好。下一步将重点研究如何提高容易混淆表情的识别准确率。
