基于子词级别词向量和指针网络的朝鲜语句子排序
2022-09-28闫晓东解晓庆
闫晓东,解晓庆
(1. 中央民族大学 信息工程学院,北京 100089;2. 国家语言资源监测与少数民族语言中心,北京 100089)
0 引言
正文句子排序的目标是将一组句子排列成连贯的文本。在多文档自动摘要任务中,对文摘句子进行排序是一项关键任务,其效果直接影响最后生成的摘要的可读性。在阅读理解的答案排序过程中,也涉及句子排序问题,其最终结果也会决定答案的可读性。
朝鲜语是我国具有文字的少数民族语言之一,在朝鲜语信息化处理的过程中[1],同样也涉及自然语言处理的各种任务。因此朝鲜语句子排序也是一个值得关注的问题。本文结合朝鲜语的特点,提出了基于子词级别词向量的朝鲜语句子排序模型,可以增强句子语义逻辑关系的捕获能力,进而获取句子的合理排序。为后续的朝鲜语多文档自动摘要、朝鲜语机器阅读理解等任务奠定一些基础。
通常,在一个文本段落中,文本的可读性往往依赖于正确的句子顺序。对于句子排序问题,前人已经做了大量的工作: Danushka等人将多文档摘要中的句子排序问题建模为学习确定两个给定句子之间排序的偏好专家的最佳组合的问题,并定义了五个偏好专家,从而更好地捕捉一个句子相对于另一个句子的偏好来解决句子排序问题[2]。Cao等人在递归神经网络 (R2N2)上开发了一个排名框架,用于对多文档摘要的句子进行排名。它将句子排序任务看作层次回归过程,同时测量解析树中句子及其成分(如短语)的显著性,并通过句子和单词的排名来有效地选择信息和非冗余句子从而生成摘要[3]。栾克鑫等人提出了通过引入注意力机制的句子排序模型,以增强句子语义逻辑关系的捕获能力,进而获取句子的合理排序[5]。
随着深度学习方法在自然语言处理任务中广泛应用,很多方法也被引入到句子排序任务中。康世泽等人利用神经网络模型融合前人已经提出过的标准来决定任意两个句子之间的连接强度,并提出了一种基于马尔科夫随机游走模型的句子排序方法,该方法利用所有句子之间的连接强度共同决定句子的最终排序[5]。Chen等人将句子排序作为一个独立的任务,通过探索数据驱动的方法来学习句子的顺序,并不依赖于人工设计的特征。Logeswaran提出了一种基于集合到序列映射框架的端到端的方法来解决句子排序问题[6]。Gong等人提出了一种端到端的神经网络方法来解决句子排序问题,该方法利用全部上下文信息并使用指针网络(Pointer Network)来缓解错误传播问题[7]。
本文的主要贡献如下:
(1) 对朝鲜语句子排序问题进行研究;
(2) 将同形异义词信息融入朝鲜语词向量的训练;
(3) 使用形态素和子词级别n元词向量进行训练,并对比效果;
(4) 使用两种词向量训练方法得到词向量,再使用两种不同的句向量训练方法得到句向量,最后进行句子排序实验,并对比效果。
1 朝鲜语句子排序模型
1.1 任务描述
对于多文档摘要、问答和文本的生成来说,排序是一项困难但重要的任务。在多文档摘要中,信息是从一组源文档中选择的,无法通过定位句子在一组文档中的某一篇文章中的位置对句子集合进行排序。句子排序任务要解决的问题就是把一组乱序的句子,排列成连贯、通顺的段落。
设给定一组乱序的句子集S=(s1,s2,…,sn),句子排序的任务目标是将其排列成顺序o*,对于顺序o*如式(1)所示。
(1)
在给定句子集S的情况下,顺序o*的概率P(o*|s)大于其他任何顺序的概率,可以表示为:
P(o*|S)>P(o|S), ∀o∈Ψ
(2)
其中,o表示句子集S的任一种排序,而Ψ表示句子集S的所有可能的排序的集合。
1.2 模型架构
我们采用指针网络模型(Pointer Network)[8]对句子集S进行排序。指针网络由Nallapati等[9]提出,该算法的思路是选取输入结合的元素作为输出,可以有效缓解OOV问题。
指针网络模型的结构非常简洁,如图1所示,是基本的seq2seq+attention架构。

图1 指针网络模型结构
基于指针网络的句子排序模型如图2所示。该任务可以表示成计算以顺序o为集合S排序的概率P(o|S),计算如式(3)所示。
(3)

图2 基于指针网络的句子排序模型
概率P(o|S)可以通过指针网络计算,计算如式(4)、式(5)所示,其中,ej,dj分别是指针网络编码端和解码端的输出。
P(oi|oi-1,…,o1,S)=softmax(ui)oi
(4)
(5)
1.2.1 编码端
指针网络的编码器模型可以表示为式(6),其中,Enc(soj)表示句子soj的编码。
ej=LSTM(Enc(soj),ej-1),j=(1,…,n)
(6)
1.2.2 解码端
指针网络的解码器模型可以表示为式(7),其中,Enc(soi)表示句子soi的编码。
di=LSTM(Enc(soi),di-1),i=(1,…,n)
(7)
1.3 句子顺序概率


(8)

1.3.1 贪心算法

(9)
1.3.2 集束搜索算法

(10)
2 模型训练
2.1 词向量训练
在自然语言处理的发展过程中,不同的词向量表示方法被相继提出,例如,Word2Vec、GloVe、ELMO。但这些模型大多数应用于英语。他们把单词作为一个基本单位,无法学习单词的内部结构变化线词根词缀的信息。对于形态丰富的语言来说,无法连接使用这些模型训练的分量。
朝鲜语句子由多个语节构成,使用空格分写,而每个语节(eojeol)由一个或多个形态素组成。其中语节是朝鲜语中的一个分写单位,而形态素则是具有实际意义的最小语言单位[10]。例如,图3的句子中共有5个语节,其中每个语节由一个或多个形态素构成,图中以“+”作为形态素的分隔符。若仅仅通过语节来训练词向量,那么由于朝鲜语的词尾形态变化丰富,使得训练得到的词向量的语义表示能力不足。为了解决这一问题,本文将采取以下两种朝鲜语的词向量训练方法: ①先将语节拆分成多个形态素(变换原形)的组成形式,再对拆分好的形态素进行词向量训练; ②以朝鲜语子词(音节和字母)为单位,用skip-gram模型训练词向量。上述两种方法都考虑了朝鲜语的形态信息,训练得到的词向量语义表达能力更强。

图3 朝鲜语句子中的语节和形态素
2.1.1 形态素词向量(Morpheme Vector, MorV)



图4 多任务训练模型示意图
为了使模型获得更准确的形态素拆分能力,在这里我们采用seq2seq模型,将词性信息与形态素原型转换两个任务同时进行训练,并将同形异义词作为不同单词进行训练。由于朝鲜语的形态素和词性息息相关,同时对这两个任务进行训练可以有效提升拆分效果。

朝鲜语作为黏着性语言,具有形态丰富的特点,通过上面训练好的模型将朝鲜语转换为其最小单位,并去除其形态变化丰富的干扰因素。然后我们采用Word2Vec对其最小单位进行词向量训练,最终得到得形态素词向量。
2.1.2 融入子词级别信息(Subword Gram, SG)
形态素拆分过程比较复杂,容易出现错误,于是提出了基于字母和音节的词向量表示方法[13]。将一个语节拆分成字母序列,再进行音节级别和字母级别的n元划分。
音节拆分规则每个朝鲜语音节可拆分成由3个字母组成的序列,例如“”可拆分成{,,}。如果有的音节只由两个字母组成,那么就用一个占位符“e”代替第三个字母,例如“”拆分成{,, e}。使用“|<”作为音节的开始标志,“>”作为音节的结束标志,这样语节“”可以拆分成字母序列{<,,,,,, e,,, e, >}。
字母级别的n元划分由于朝鲜语的黏着性,只考虑音节级别的n元,无法捕捉到形态变化信息,因此还需要考虑字母级别。

2.2 标题句向量表示
句向量又可以称为句嵌入[16],句嵌入模型的输入为词向量,输出为表示句子的向量,该向量可以作为具体任务的输入进行预测和训练。自然语言处理的任务大多数都是序列化的信息,如何发掘序列输入之间的信息是自然语言处理任务的关键。在当前研究成果中,主要有两大解决方法: 一是以循环神经网络为基础的解决方案;二是以卷积神经网络为基础的解决方案。本文将采用这两种方案对句子进行向量化,并对比不同的句向量训练方法对句子排序结果的影响。
2.2.1 卷积神经网络模型
卷积神经网络(Convolutional Neural Networks,CNN)[17]仿造生物的视觉机制,包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。将包含nw个单词的句子$s$通过卷积神经网络编码的过程可以表示如式(11)、式(12)所示。其中,Wcov∈R(dlf)df和bcov∈Rdf是可训练的参数,其中,φ(·)是tanh函数。k=1,…,nw-lf+1。其中的lf和df都是卷积神经网络模型中的超参数,分别是过滤器(filter)的长度和特征图(feature map)的个数。
2.2.2 长短时记忆网络模型
长短时记忆网络(Long Short Term Memory,LSTM)[18]是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失问题和梯度爆炸问题。LSTM的存储单元c∈Rdr由三种门控制: 输入门i∈Rdr、遗忘门f∈Rdr输出门o∈Rdr,表示如式(13)~式(15)所示。其中,Wg∈R(d+dr)4dr和bg∈R4dr是可训练的参数,∅(·)是表示存储单元和门控单元的维度的一个超参数。t=1,…,nw其中σ(·)是sigmoid函数,∅(·)是tanh函数。
我们将通过长短时记忆网络编码的句子向量表示如式(16)所示。
踢鸽子的人走开了,但那位妇人追上他,说:“你叫什么名字?家住哪儿?我要去告发你。”那男子恼恨地说:“别在这儿把鸡毛当令箭。”她说:“我想你把一只可怜的小鸟当作鸡毛吧?”“嗨,不是令箭,凶杀不是令箭。”那两个少年中的一个双手插在外衣的口袋里,站在那里咧开嘴笑笑说。他的朋友机灵地接口说:“你说得不错,鸡毛是凶杀,但令箭不是凶杀。”“说得好,”第一个少年说,“鸽子什么时候才能成为令箭呢,只有在它成为鸡毛的时候。”(2014:406)
Enc(s)=hnw
(16)
2.3 目标函数训练

(17)
3 实验
3.1 数据集
本文从延边日报朝鲜语版、人民网朝鲜语版等新闻网站爬取了20 000篇朝鲜语新闻作为实验数据集。将每篇新闻进行语段分隔,选取句子数目大于2的语段作为一个数据单元,将每个数据单元的句子打乱编号。例如将语段[s1,s2,s3,s4]编码为[4,1,2,3],然后再对该语段编码随机打乱为[3,2,4,1]。这样我们就得到一个训练样本([句1,句2,句3,句4], [4,1,2,3], [3,2,4,1]),第一项为顺序句子集合,第二项为正确顺序,第三项为乱序顺序。按照上述形式对所有数据单元进行编码再打乱,得到样本集合。对这些样本集合进行训练集、验证集和测试集的划分。划分结果如表1所示。

表1 实验所用语料
3.2 超参数设置
表2展示了上述模型中的超参数的设置。卷积神经网络的句子编码模型使用了3种不同长度lf的过滤器[21]。
3.3 测评方法
本文采用了3种不同的模型评测方法: ①成对度量法; ②最长序列比法; ③最佳匹配比法。

表2 超参数设置
3.3.1 成对度量法
成对度量法(Pairwise Metrics,PM)指的是,预测的相对顺序与原本真正顺序相同的句子对的分数越高越好。成对度量法可以表示为三个量化分数: 精确值P、召回率R和F值,如式(18)~式(20)所示。其中,函数S(·)表示一段文本中所有句子对的集合,绝对值符号表示的是集合的大小。
3.3.2 最长序列比法
最长序列比法(Longest Sequence Ratio,LSR)在一组序列中找到所有序列共有的最长子序列,如式(21)~式(23)所示。其中,函数L(·)表示的是最长正确子序列中元素的个数。
3.3.3 最佳匹配比法
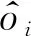
(24)
(25)
3.4 实验结果和分析
我们用两种不同的词向量训练方法,两种不同的句向量训练方法对句子进行编码,然后通过指针网络进行句子排序,在进行句子排序的过程中,使用两种不同的搜索算法: 贪心算法和集束搜索算法,结果分别用三种评测指标进行评测。结果如表3所示。

表3 不同方法的句子排序结果对比
根据表3我们可以看出,使用本文提出的形态素拆分模型(MorV)将语节拆分成形态素,再进行词向量训练,在三种评测方法下,可以使得朝鲜语句子排序效果更好。使用LSTM进行句子编码,相对于CNN,句子排序效果更好。增加集束搜索(beam search)过程后,句子排序的效果也有所提升。
从图5中也可以直观得出结论: 使用MorV词向量训练模型+LSTM句编码模型,句子排序效果最佳。表4给出的是句子排序示例。

图5 (a)PRM评测结果

图5 (b)LSR评测结果

图5 (c)PM评测结果

表4 句子排序示例
4 总结
句子排序是近年来自然语言处理中多文档摘要生成和机器阅读理解答案融合任务中的一个十分重要子任务。以往的研究主要是基于传统的机器学习方法,但随着深度学习方法的不断发展,句子排序任务也可以使用一些深度学习方法来解决。
在朝鲜语信息化进程中,也需要跟上深度学习发展的步伐。本文将深度学习模型用于朝鲜语信息化处理,使用多任务Seq2Seq模型进行形态素拆分,并且将指针网络用于朝鲜语句子排序,取得了较好的效果。接下来,我们将继续结合朝鲜语本身的特点,继续提高句子的排序效果,并将其用于多文档摘要任务中。
