新型智能化培训系统设计探究
2022-09-28屠月海吴锋豪
赵 磊,杨 昀,屠月海,吴锋豪,吴 熙
(国网浙江省电力有限公司 建设分公司,浙江 杭州 310000)
化工、电力行业是国民经济的支柱,也是人民生活的重要保障。化工、电力等企业基建施工过程关系到诸多建设环节,每个不同的环节就需要大量的技术学习才能上岗,建筑设计中的员工培训范围广、技术面宽、难度大,一个工程项目通常包括几百个、甚至上百个技术难度,常规的人工培训方法和信息共享系统就难以满足项目建设的需求。
针对上述问题,现有技术也进行了相关技术研究,文献在施工管理的过程中充分利用信息技术和互联网技术,提高了自身管理能力,完善了工程的管理工作,但该技术无法实现基建施工不同项目的自我学习和培训。文献基于学习型组织方式,设计了企业员工培训体系,通过该文献的设计,员工能够在诸如基建等陌生的环境中积极适应环境,通过自我学习,能够获取陌生外界事物。但该学习机制智能化程度太差,无法实现智能学习、培训和评估。
针对上述技术的不足,本研究构建了新型的智能员工培训系统,并对其关键技术进行研究。
1 智能员工培训系统设计
本设计的基本概要为:
(1)构建了具有数据层、分析层、智能学习交互层和应用层的人工智能培训系统,能够实现从基建施工知识网络、员工学习画像、员工学习课程个性化推荐及学习行为监测方面出发,全面展示员工学习行为过程,实现电网员工学习智能化。
(2)构建了人工智能学习算法,能够实现培训效益指标的评价,实现了员工个性化学习和电网项目实时缺陷管理等功能,提高了员工的自我学习能力和培训。
基于上述要点,本研究设计出如图1所示的智能员工培训系统架构图。

图1 智能员工培训系统框架图
由图1可知,研究的数据层源于员工和课程信息数据;员工画像层由员工画像标签体系和画像类型组成;智能学习交互层由个性化推荐和学习行为监测构成;应用层有学习培训、知识库和知识搜罗等。所谓的企业员工培训,就是企业通过各种学习形式来增强和丰富员工的知识和技能。本文所开发的智能员工培训系统在考虑员工学习培训个性化、碎片化及高效管理缺陷的基础上,还包括缺陷管理、在线学习推荐、学习行为监测、互动问答、知识搜罗、维护员工信息等。通过实现这些功能,帮助员工及时施工管理、高效学习,提高企业及社会经济效益。
2 关键技术
为了评估员工经过培训后产生的未来效益,本研究构建员工培训效益评估模型,并采用优化方法来提高评估模型的预测精度。
2.1 员工培训效益评估模型构建
本研究基于灰色理论构建员工培训效益评估模型,其主要分为2步骤。
步骤1:定义多级指标体系。企业员工培训效益在实际应用中具有多维特征,但是在这些多维影响因素中,有4个主要因素,其中包括人才效益、技术效益、经济效益和社会效益等;将指标体系划分一级和二级两个级别的权重属性,分别表示子项重要度和要素重要度。但是类似地,该模型的权重属性应满足一定的约束条件,即所有权重之和应为1。其满足以下约束条件条件:
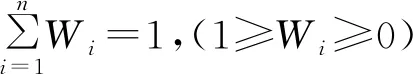
(1)
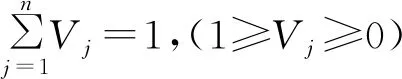
(2)
式中:为第1级权重属性中的权重的值;为第2级权重属性中的权重的值。这些参数的具体数值是通过设计人员的经验来确认的。
步骤2:构建员工培训效益评估模型。在定义智能化培训效益指标体系后,本研究从理论层面、应用前景和思想广度3个角度来构建员工培训评估模型,这个三角模型的领域就是教育训练的效果。另外,通过该模型的3方面进阶协调,可以实现区域(培训效益)的最大化。其企业员工培训效益的计算:
=···-·
(3)
式中:为对员工进行培训的收入;为对员工进行培训的收入时间;为一个培训班的员工人数;为平均效率方差;为员工培训的人均费用;为表示效率参数,其计算公式:
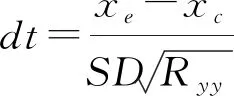
(4)

通过对企业员工培训的收入进行了研究,并由以下公式表示:
=(1+)
(5)
关于边际净值模型:
=(1+)-
(6)
关于培训效益模型为:
=(1+)+(MRP-MLC)
(7)
式(5)~式(7)中:为对员工进行培训教育的收入数;为当前资本年利率;表示进行员工培训的投资额;MRP表示教育培训的边际资本收入;表示进行员工培训的投资周期;MLC表示人均培训费用。
2.2 评估模型中的优化方法
针对基于灰色理论构建智能培训效益评估模型误差高的缺陷,本研究通过设置分割点构造滑动窗口,并结合3种平滑指数算法对灰色模型数据进行实时分割,获得数据的实时统计特征,构造序列误差预测与压缩比之间的函数关系,利用误差预测序列以进行分割点判断并提高评估模型的准确性。该优化方法具体步骤如下。
步骤1:构造滑动窗口。在分割形式的平滑度指标预测中,假设在时刻获得模型的预测输出;在时间的实际企业员工培训价值为,则预测结果的误差为-,且该预测误差满足以下定义特征:
设置表示长度为的企业员工培训时间数据序列;是在设定的分割点处企业员工培训的预测误差;设置SKPS={,…,}作为分割点集,为设置长度;具有随机变量特征,在依赖形式内满足相同的分布特征,并且还满足正态分布[,]的特征,其表达式:

(8)
式中:、分别表示正态分布中的期望值与方差。
从中心极限理论可以看出,如果样本数趋于无穷大,则产生的具有随机特征的数据满足正态分布特征。将当作随机变量,则表示分割点的预测误差。如果企业员工培训时间序列趋于无限长,则预测序列误差满足正态分布特征。因此,其子序列也满足正态分布[,]的特征。
步骤2:计算序列数据分割误差。假设企业员工培训时间序列数据的压缩分割率为,则可以得到以下不等式关系:
2(2)-1≤1-
(9)
式中:为平均误差范围;为分布累积函数。它们符合正态分布特征。
假设企业员工培训时间序列的压缩分割比例为,则分割点的可能概率小于1-。越接近,分割点的概率越大;越远,分割点的概率越小;平滑度指数分割预测过程假定分布范围满足偏差平均值的标准偏差。因此,分割点在[-2,+2]的区间内分布;同时,分割点的存在概率小于1-。假设代表随机变量,则可以得到:
{-2<+2}≤1-
(10)
式中:{}表示概率函数。
通过变换式(10),可得到:
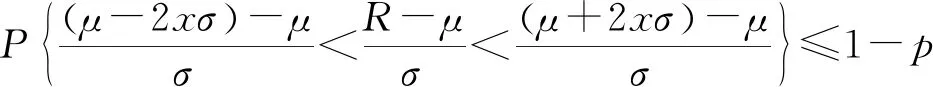
(11)
根据中心极限定理,经过随机变量转换后,所得到的(-)应满足正态分布(0,1)的特征。因此,可以通过式(11)推断出式(9)成立。
根据预测误差,可以实现企业员工培训时间序列数据的细分子数据序列。该序列满足单一趋势,在独立区间内具有一定的稳定性。如果在一个数据趋势和当前序列趋势之间产生了较大的偏差,则该点就是可能存在的数据序列分割点。
步骤3:得出3平滑指数。在与这2指数的基础上,构建3个平滑指数模型,可以得到:
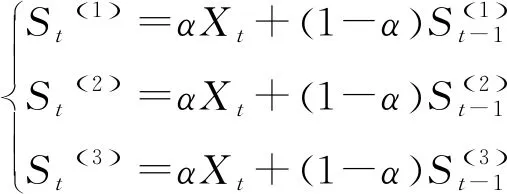
(12)
式中:=2,3,…,是时刻的1次平滑指数值;是时刻的2次平滑指数值;是时刻的第3平滑指数值;是时间时企业员工培训的时间序列数据{}的真实收集数据;是平滑度因子,且满足区间∈(0,1)。
在+时刻企业员工培训的预测值为:
+=++
(13)
式中:为企业员工培训数据的预测视觉长度,一般值为正整数。
在3个平滑指数预测过程中存在2个问题,需要妥善处理:
(1)初始值、、平滑度参数设置;
(2)平滑度因子参数的设定。
步骤4:效益评估模型预测过程。基于滑动窗口的平滑度指数预测过程是使用分段算法对企业员工培训的历史时间序列数据进行趋势预测,以达到数据历史值与预测值之间的均方误差。实现该算法的具体程序流程如图2所示。
由图2可知,为平滑度指数预测的值;为企业员工培训的实时值;为分段算法的初始指数设置值,=(++)3;是平滑度指数设置权重,=02;是用于保存预测误差的向量;Seg是存储分割点的集合;是原始序列和拟合序列之间的分割点残差值。
从图2还可以看出,在平滑指数预测算法中;是实时数据的当前时间;用于保存预测误差值;基于分段更新策略,计算均方差,得到误差的预测内部。根据设定的压缩比和引理1计算均值偏差。最后,可以得到Seg集合。上述预测过程将循环执行直到实时数据处理结束为止。

图2 三平滑度指数预测过程
在参数初始化之后,第1步,使用平滑单指数预测计算平滑度值,并将其作为时间的下一个预测值;第2步,获得真实的企业员工培训数据时刻通过收集,获得预测误差值-,并将该值保存在向量中;第3步,计算矢量标准偏差和平均值l,并更新这两个参数;第4步,验证分割点是否合适,如果不合适,则继续执行下一个循环点。设置此标记位置并缓存此分割点是合适的。如果以下数据点也满足分割点的要求,则将该点保存到Seg中;同时,重新初始化分割段的初始并继续执行循环操作。
3 实验与分析
实验硬件环境为Pentium()CPU、8核16 G内存,电脑的硬盘容量为512 G的硬件环境,软件的操作系统Windows10,JDK5.0,通过MATLAB软件系统进行仿真。本研究以某企业最近4年有关员工培训实际流向数据作为实验数据样本,通过构建智能员工培训指标体系得到该企业从2018年到2021年数据样本。由于指标较多,本文采用资产利润率、受训员工劳动效率以及受训员工技术水平这3种指标用于实验,其结果如表1所示。

表1 平滑度指标数据样本
通过MATLAB软件处理数据,采用统计表征作为受训人员个人因素的方式,采用概率统计作为其他影响因素的方法。资产利润率影响、受训员工劳动效率影响和受训员工技术水平影响产生的效益指标的概率密度如图3所示,这3个因素均采用归一化形式作为程序输入。
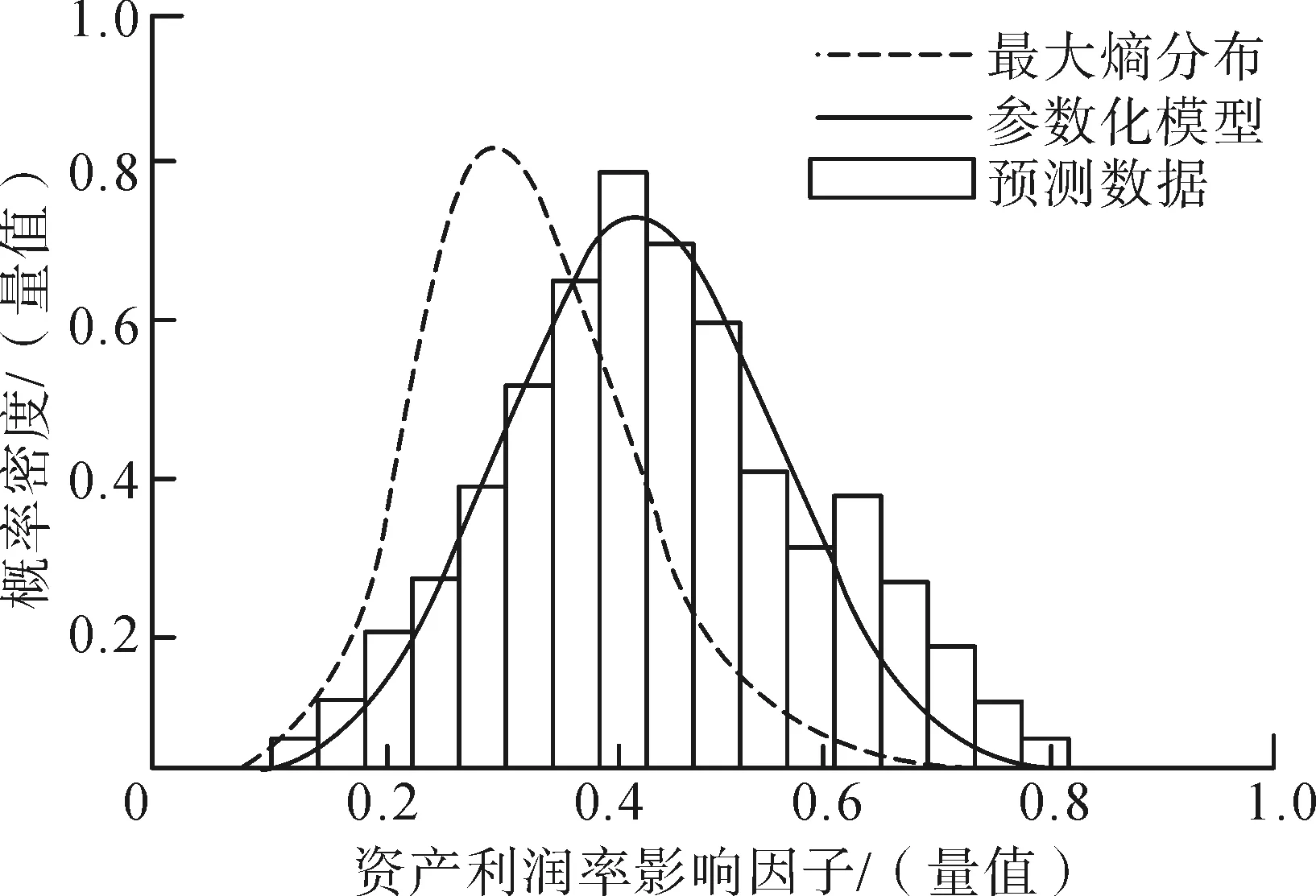
(a)资产利润率影响的概率密度
从图3可以看出,资产利润率影响、受训员工劳动效率影响以及受训员工技术水平影响这3个平滑度参数的不同值都会对培训效益产生一定的影响,并且都呈现先增加后减少的情况。可以看出,当资产利润率影响值在0.41左右时,效益目标最大;当劳动效率的价值在0.2左右时,效益目标最大;当受训员工技术水平影响值约为0.3时,效益目标最大。
为了验证本研究基于滑动窗口的员工培训评估模型比传统评估模型更加适用,以文献[2]中企业培训体系作为实验对比对象,本研究通过统计在2021年3月至6月期间的员工培训学习评估数据,计算这2种评估模型所预测评估值,并将预测结果与真实评估值进行对比,得出误差数值如表2所示。
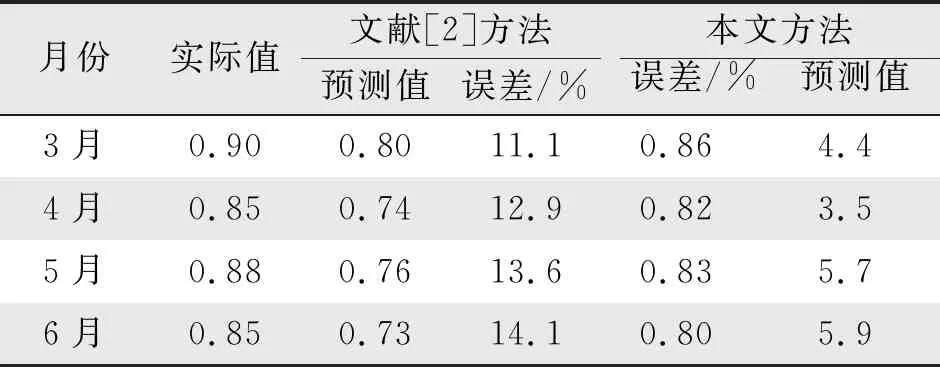
表2 2种预测模型评估结果对比
本文基于滑动窗口结合3种平滑指数算法对灰色模型数据进行实时分割,获得数据的实时统计特征,构造序列误差预测与压缩比之间的函数关系,利用误差预测序列以进行分割点判断,提高评估模型的准确性。
4 结语
针对企业基建施工,设计了一套智能化员工培训系统。基于灰色模型理论构建了员工培训计划评价预测模型,并建立回归预测目标函数;基于企业员工培训的多维特征,构建了评价指标和基于滑动窗口三指数的统计方法。所设计的智能化培训系统降低了培训学习成本,提高了员工自我学习和培训能力。
