基于Transformer 的多特征融合的航空发动机剩余使用寿命预测
2022-09-26马依琳陶慧玲董启文
马依琳,陶慧玲,董启文,王 晔
(华东师范大学 数据科学与工程学院,上海 200062)
0 引 言
随着在线购物的日益普及,我国物流行业蓬勃发展.航空物流作为现代物流的重要组成部分,具有高时效性的显著特点,能够满足人们对物流速度更高的需求.在近两年全球疫情形势下,航空物流更是表现出了其重要的战略作用.我国航空物流的体量较大,2020 年我国航空货邮周转量完成了240.2 亿吨公里,规模稳居全球第二[1].但相比发达国家,我国航空物流发展的起点较晚,存在前期投入高、运营成本高等问题.根据国际咨询机构Armstrong &Associates 估算的数据,2019 年中国物流费用约占GDP 的14.50%,相比美国8.00%的占比,仍有很大的发展潜力[2].在复杂多变的国际形势下,如何降低航空物流的成本,提高服务质量,保障国内国际双循环,是我国航空物流下一阶段发展的挑战[1].
确保飞机安全运行是整个运输流程中首要保证的环节,一旦飞机发生意外事故,不仅会造成巨大的财产损失,更会造成不可挽回的人员伤亡,后果不堪设想.对飞机进行维护和修理的费用在航空公司运营成本中占据了很大部分,单机单次检修的成本高达100 万元至800 万元[3].发动机作为飞机最核心的部件,它的可靠性和安全性在飞机整体运行中起着至关重要的作用.由于航空发动机的结构十分复杂,零部件众多,又经常处于高温、高压、高速旋转的高负荷工作环境,不可避免地会出现性能退化或故障的情况.有资料显示[4],航空发动机的维修成本占飞机总维修成本的1/3 以上.
传统的发动机维修方式可以分为基于故障的维修和基于时间的维修[4].基于故障的维修是指当故障发生以后,对特定的故障零部件进行维修或更换,这种事后的维修方式无法对未来可能发生的故障起到预防的作用.基于时间的维修是指根据发动机制造商所提供的维修时间表,定期地对发动机进行检查和修理,是一种预防性维修方式.但是定期维修没有考虑到发动机的个体差异,无法对每个发动机制定科学合理的维修时间间隔,过度维修会加重维修成本负担,而缺乏维护则会导致严重的事故发生.如何在降低维修成本的同时,确保航空发动机的安全性和可靠性,是航空发动机发展中所遇到的难题.
故障预测和健康管理 (Prognostics and Health Management,PHM) 是美国等航空发达国家所提出的一种健康管理技术[5],旨在推动维修保障模式改革,提高发动机的安全性和经济性.其中,剩余使用寿命 (Remaining Useful Life,RUL) 预测是指根据设备当前的健康状态、工作环境和传感器监测信息等,结合物理模型、历史数据,对未来故障发生的时间进行预测,估计设备的剩余使用寿命,是故障预测技术中最具挑战性和最核心的部分.根据所预测发动机的剩余使用寿命,可以合理地制订飞行计划和检修计划,及时地发现隐蔽的故障,预防事故的发生,进行健康管理.
目前,国内外对RUL 预测的研究大致分为3 类: 基于物理模型的方法、数据驱动的方法和两者混合的方法.基于物理模型的方法是指根据发动机的失效机理或损伤法则、设备的结构特点以及专家经验等多方面因素,对研究对象构建相应的物理模型,该物理模型能够具体地解释产品退化规律,如Paris 等[6]针对机械材料疲劳裂纹扩展问题而建立的Paris-Erdogan 模型,经过不断的改进和更新,得到了广泛的应用[7-9].虽然基于物理模型的方法准确性较高,但它对研究对象的先验知识要求非常高,而且对于航空发动机这类结构特别复杂的设备,通常难以构建准确、全面的物理失效模型,适用性较低.
数据驱动的方法是指对大量的监测数据直接建模,从数据中得到设备的潜在退化规律,从而预测设备的RUL.数据驱动的方法不要求研究者具备大量关于设备运行原理的先验知识,而且从数据中更能发现一些难以人工发现的、比较隐蔽的故障特征.因此,数据驱动的方法在航空发动机RUL 预测问题中被广泛研究.根据所使用的算法不同,数据驱动的方法又可以细分为基于统计分析的方法、基于传统机器学习的方法和基于深度学习的方法.基于统计分析的方法将传感器数据拟合为某一用来模拟产品退化过程的随机过程模型,如基于维纳过程的模型[10-11]、基于伽马过程的模型[12]和基于逆高斯过程的模型[13]等,以此估计产品的剩余使用寿命.此类方法通常对产品的退化过程做了一定的限制和假定,在实际过程中很难被保证,从而限制了其实用性和可靠性.与之相比,机器学习的方法不对设备的退化过程做任何前提假设,直接建立从输入数据到RUL 的映射模型,对发动机这类复杂设备来说,此类方法更具有实用意义.一些早期的研究使用了传统机器学习的方法,如Nieto 等[14]实现了基于混合粒子群优化支持向量机参数的模型对发动机RUL 进行预测、Khelif 等[15]使用支持向量回归拟合RUL.传统机器学习方法只能以标量的形式独立地处理时序数据,在特征处理方面具有一定的局限性;而基于深度学习的方法不需要进行繁琐的特征工程,且更适合处理大量的、高维度的数据.因此,基于深度学习的方法在航空发动机RUL 预测问题上具有更广阔的应用前景,受到了更多的关注.
循环神经网络 (Recurrent Neural Network,RNN)和卷积神经网络 (Convolutional Neural Network,CNN) 是在RUL 预测中最常使用的两种深度学习神经网络.由于RNN 存在梯度消失和梯度爆炸的问题,其变体长短期记忆网络 (Long Short Term Memory,LSTM)和门控循环单元 (Gated Recurrent Unit,GRU) 通过门控制单位对其做了改进,得到了更广泛的应用,例如: Shuai 等[16]提出了基于LSTM 的RUL 估计方法,并在3 个广泛使用的公开数据集上进行了验证;Ren 等[17]使用多尺度全连接GRU 网络对轴承的RUL 进行了预测;Wang 等[18]提出了基于双向长短期记忆 (Bidirectional Long Short Term Memory,BiLSTM) 的方法,实现了RUL 预测;Hu 等[19]等提出的双向递归神经网络(Deep Bidirectional Recurrent Neural Network,DBRNN)集成方法,构建了几种不同的DBRNN,将得到的一系列RUL 值重新封装,从而得到最终的结果;Li 等[20]首先利用主成分分析 (Principal Component Analysis,PCA) 对传感器数据进行降维,然后利用LSTM 对提取的时间序列数据进行预测,建立RUL 预测模型;Li 等[21]提出的基于深度卷积神经网络 (Deep Convolutional Neural Network,DCNN) 的RUL 预测模型,沿时间维度进行卷积运算;Li 等[22]采用时间卷积网络 (Temporal Convolutional Network,TCN) 来估计RUL;Zeng 等[23]提出了一种新的深度注意力残差神经网络模型用于RUL 预测;Abderrezek 等[24]提出了卷积自动编码器 (Convolutional Auto-Encoder,CAE) 和BiLSTM 网络混合的模型来预测RUL;Remadna 等[25]提出的使用CNN 提取空间特征和BiLSTM 网络提取时间特征的混合RUL 预测模型.
然而,基于RNN 的方法由于本身结构的限制,无法充分利用并行计算,存在运行效率低的问题.基于CNN 的模型在处理时序特征上视野受卷积核大小的限制,存在无法捕获远距离特征的问题.Transformer 模型是由Vaswani 等[26]提出的一种基于自我注意力机制的网络,该模型既能有效处理随时间变化的长期依赖关系,又能通过并行计算提高运行效率,在自然语言处理等领域取得了巨大的成功.最近,已有学者将Transformer 模型应用到RUL 预测问题上,例如: Mo 等[27]将Transformer 编码器作为模型的主干,并使用1 个门卷积单元合并每个时间步局部上下文的信息,实现了RUL 的预测;Zhang 等[28]使用完全基于自注意力的编码器解码器结构,提出了由传感器特征和时间步长特征作为输入的双编码器Transformer 结构,取得了不错的预测结果.
以上研究中,缺乏对输入数据时间步长选取的考虑,以及对操作条件和传感器之间、传感器与传感器之间的影响关系的研究.针对现存的问题,本文提出了一种基于Transformer 的多编码器特征输出融合的模型,主要工作有以下3 个方面.
(1) 选取2 个不同时间长度作为输入,利用Transformer 模型的并行计算能力,分别输入2 个编码器层进行独立的训练,将这2 个编码器层的输出结果进行融合,增强短时间序列特征信息的同时,保留长期依赖关系.
(2) 通过添加排列熵嵌入层,将能够反映信号单调性和变化趋势的排列熵信息融合到传感器数据,使模型能更好地捕捉不同传感器之间的关系信息.
(3) 将操作条件和传感器数据分离,使其各自作为独立的输入通过不同的编码器层训练,避免操作条件和传感器数据之间的干扰,提升模型的预测精度.
本文将所提出的模型在航空发动机CMAPSS (Commercial Modular Aero-Propulsion System Simulation)数据集上进行了验证,且与目前先进的模型相比,得到了更好的预测效果,体现了本文方法的有效性.本文的后续结构: 第1 章介绍所提模型的具体结构和理论基础;第2 章描述实验细节,展示实验结果,并进行结果分析以及消融研究;第3 章对全文工作进行总结,并展望未来工作的方向.
1 RUL 预测模型搭建
1.1 模型总体架构
本文基于Transformer 的结构,提出了多编码器特征输出融合的模型,其具体架构如图1 所示.由图1 可知,模型主要分为多编码器层和解码器层2 个部分.多编码器层可以同时对不同的输入分别进行特征提取,包括2 个不同时间步长的编码器层、传感器排列熵编码器层以及操作条件编码器层.各个编码器层的输出经过融合后,作为解码器层的输入,通过解码器层对来自不同方面的特征进行提取后,通过前馈全连接网络输出RUL 的预测值.

图1 模型总体架构图Fig.1 Architecture of the proposed model
1.2 双时间步长编码器层
发动机当前的状态信息,由当前时间点的传感器信号和过去一定时间点的信号得到.本文采用滑动时间窗口方法对时间序列数据进行分割,图2 展示了采样过程.

图2 滑动时间窗口采样示意图Fig.2 Sliding time window sampling process
如何选取滑动窗口的时间长度,对预测结果起到很关键的作用.如果时间长度过长,距离当前时间点过久的信息可能会成为无用信息甚至是干扰信息,混淆模型的预测结果;如果时间长度太短,又会造成信息的丢失,影响预测结果.现有的研究通常尝试不同的时间步长作为输入,最终选取效果最好的1 个时间步长作为模型的输入.
Transformer 模型相较于传统的RNN、CNN 等深度学习模型,具有可并行计算的优点,随着计算力的发展,可以在一定程度上牺牲内存换取更好的实验结果.利用Transformer 模型的并行性,本文创新性地提出了选取2 个不同时间步长的输入,分别独立地进行特征提取,一方面保留了长时间序列的特征信息,另一方面又能更集中高效地处理短时间序列的特征信息,最终将2 个编码器层的特征输出进行融合.
本文所使用的多个编码器层的结构相似,具体如图3 所示.从图3 可以看到,每个编码器层由多个结构相同的子编码器层堆叠而成;每个子编码器层包括多头自注意力层和前馈全连接层,并且都应用了残差连接以及标准归一化操作,以防止梯度消失,加速模型收敛.

图3 编码器层结构Fig.3 Structure of the encoder layer
由于输入数据具有时序性,而Transformer 的自注意力机制无法直接捕捉到输入的顺序.因此,在原始数据进入双时间步长编码器层前,需要先通过1 个位置编码层,对其添加相对位置信息,使模型能更好地捕捉到时序特征.本文采用Transformer 中最常用的位置编码模式,即正弦位置编码和余弦位置编码[26].相应计算公式为

公式 (1) 中:t表示时间点;d表示传感器的维度; 2i表示偶数位传感器,用正弦函数(sin)来编码;2i+1表示奇数位传感器,用余弦函数(cos)来编码.
自注意力机制是Transformer 模型中的核心部分.将上一层的输出矩阵X分别与3 个权重矩阵Wq、Wk和Wv相乘后得到对应的3 个向量,分别为查询向量Q、键向量K和内容向量V.对应公式为

通过计算Q和K的点积获得关联矩阵,经过Softmax 函数激活后得到每个位置对应的权重,最后再将此权重叠加到V得到自注意力输出.具体公式为

本文所提的模型中,多头自注意力层采用了多头注意力机制,即计算了多组Q、K、V,再将多组注意力输出拼接后作为最终输出,以均衡同一种注意力机制可能产生的偏差,从而提升模型效果.相应计算公式为
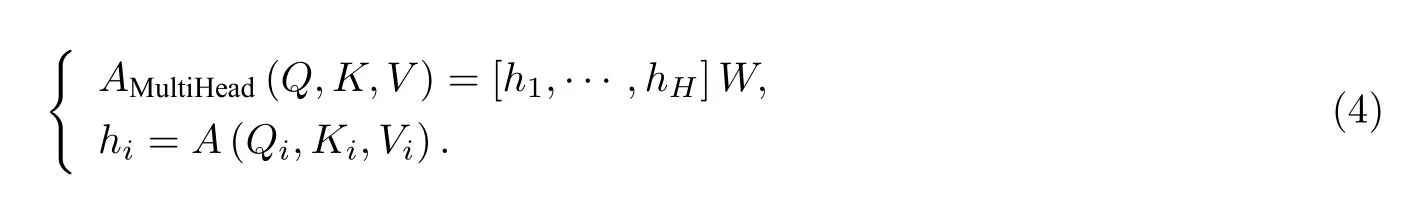
公式 (4) 中:W表示多头注意力权重矩阵;hi指第i个自注意力输出;H为注意力头数.
1.3 传感器排列熵编码器层
通过对时间步长数据进行转置,得到传感器排列熵编码层的输入,传感器排列熵编码器层将沿着传感器的维度进行特征提取.然而,由于传感器之间的位置关系不明确,模型不能够有效获取不同传感器之间的位置信息.二阶排列熵是一种能够反映信号的单调性和变化趋势的非线性动力学参数[29],能够放大时间序列的微弱变化,度量时间序列的复杂性,从而有效地反映不同传感器的特征.在输入编码器层之前,本文添加了排列熵编码层,先对输入数据进行了排列熵编码处理,以此注入传感器之间的关系,使编码器层能更好地学习到不同传感器之间的影响.
假设第i个传感器的测量序列为{si(1),si(2),···,si(t)},采用相空间对其进行重构,并取嵌入维数为2,得到相空间重构矩阵
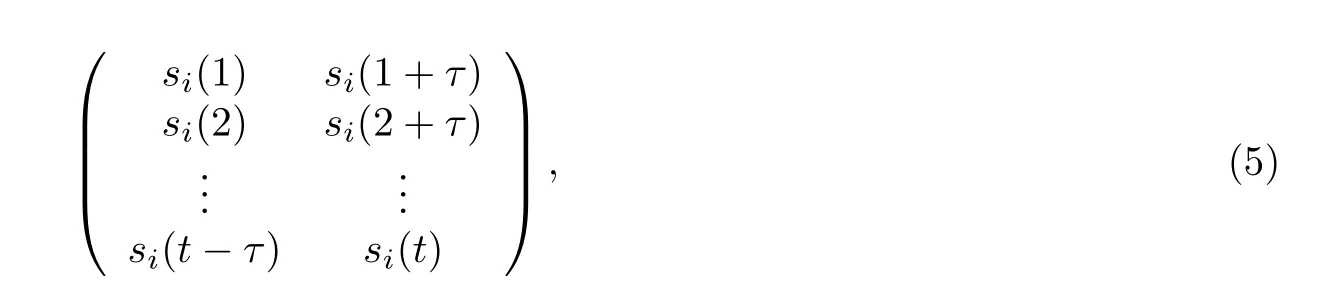
其中τ表示延迟时间.将矩阵中的每一行看作1 个重构向量,对其进行升序排列,得到索引的2 种排列方式;统计对应排列方式出现的概率并记为p1和p2;最后使用公式
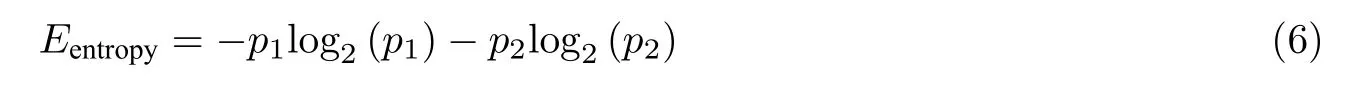
求得该传感器的排列熵.
计算得到每个传感器的二阶排列熵后,对其进行线性映射以适应输入矩阵的大小;在排列熵编码器层对输入矩阵进行编码,添加排列熵信息.添加公式为

公式 (7) 中:X表示输入矩阵;S表示传感器二阶排列熵向量;We表示排列熵权重矩阵.
1.4 操作条件编码器层
操作条件是指现实环境和运行条件数据与传感器信号数据之间的相关性较弱,现有的研究通常将操作条件数据和传感器信号数据混为一谈.编码器层中自注意力机制会计算不同传感器之间的相关性,假如操作器数据也在其中,会加重模型的计算负担,却不能得到一个合理有效的结果.本文将操作器数据和传感器信号数据分离,并行地作为另一个编码器层的输入提取特征,在减少对传感器信号数据干扰的同时,不浪费操作条件中所包含的特征信息,从而提升模型的预测效果.
在多个编码器层完成特征提取后,需要进行特征融合;特征融合层将各个编码器层输出的结果连接后,通过线性映射作为多编码器层融合的输出O.相应公式为

公式 (8) 中:Ot1、Ot2、Os、Oc分别对应时间步长1 编码器层、时间步长2 编码器层、传感器排列熵编码器层和操作条件编码器层的特征输出结果;Wo表示特征融合权重矩阵.
1.5 解码器层
解码器层和图3 中编码器层的结构类似,由多个子解码器层组成,每个子解码器层包括2 个多头自注意力层和1 个前馈全连接层.相应地,每个层都进行了残差连接和标准归一化: 第一个多头自注意力层添加了掩码操作,即将QKT向量点乘1 个同样大小的上三角掩码,避免模型提前观察到未来时间点的数据;第二个多头注意力层为编码器解码器注意力层,将前一层的输出作为查询向量,将解码器层的输出作为键向量和内容向量进行计算;最终,依次通过展开层和全连接层输出所预测的RUL,得到最终结果.
2 实验分析
2.1 数据集介绍
CMAPSS 数据集是由美国国家航空航天局 (National Aeronautics and Space Administration,NASA) 阿姆斯研究中心,在其开发的航空推进系统仿真平台CMAPSS 上,对涡扇发动机的关键部件退化过程进行大量仿真实验所得到并公开的1 组数据[30],在航空发动机RUL 预测问题上被广泛使用.图4 展示了CMAPSS 中涡扇发动机仿真模型的结构图.其中,Fan 表示发动机风扇,LPC (Low Pressure Compressor)表示低压压气机,HPC (High Pressure Compressor)表示高压压气机,Combustor表示燃烧室,N1 表示风机轴,N2 表示核心轴,LPT (Low Pressure Turbine)表示低压涡轮,HPT(High Pressure Turbine)表示高压涡轮,Nozzle 表示喷嘴.
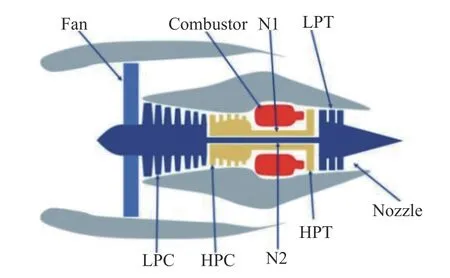
图4 发动机仿真模型结构图[30]Fig.4 Structure of engine simulation model
CMPASS 数据集共包含4 个子数据集,分别仿真了在不同工作状况和不同的故障模式下涡扇发动机的传感器数据.本文选取包含同一种工作状况的数据集1 和数据集3 对本文模型进行验证: 数据集1 模拟了高压压气机性能退化这一故障;数据集3 模拟了高压压气机性能退化和风扇退化这2 种故障模式.每个子数据集包括训练集和测试集: 训练集包括100 台发动机从某一时刻开始到完全失效这一时段内每个飞行循环的操作条件数据和传感器数据;测试集包括另100 台发动机在某段时间内每个飞行循环的操作条件数据和传感器数据,并给出了对应的剩余使用寿命.数据集1 和数据集3 都用飞行循环作为衡量单位.其中,操作条件数据包括飞行高度、马赫数和油门解算器角度这3 个发动机工作环境参数;而传感器数据则记录了21 个传感器测量值,每个传感器的详细描述详见表1.由于本文采用的CMAPSS 数据集是由NASA 提供的公共数据集,因此,本文描述传感器数据时,遵照了该数据集的官方设置,所使用的单位是航空动力学领域的常用单位.
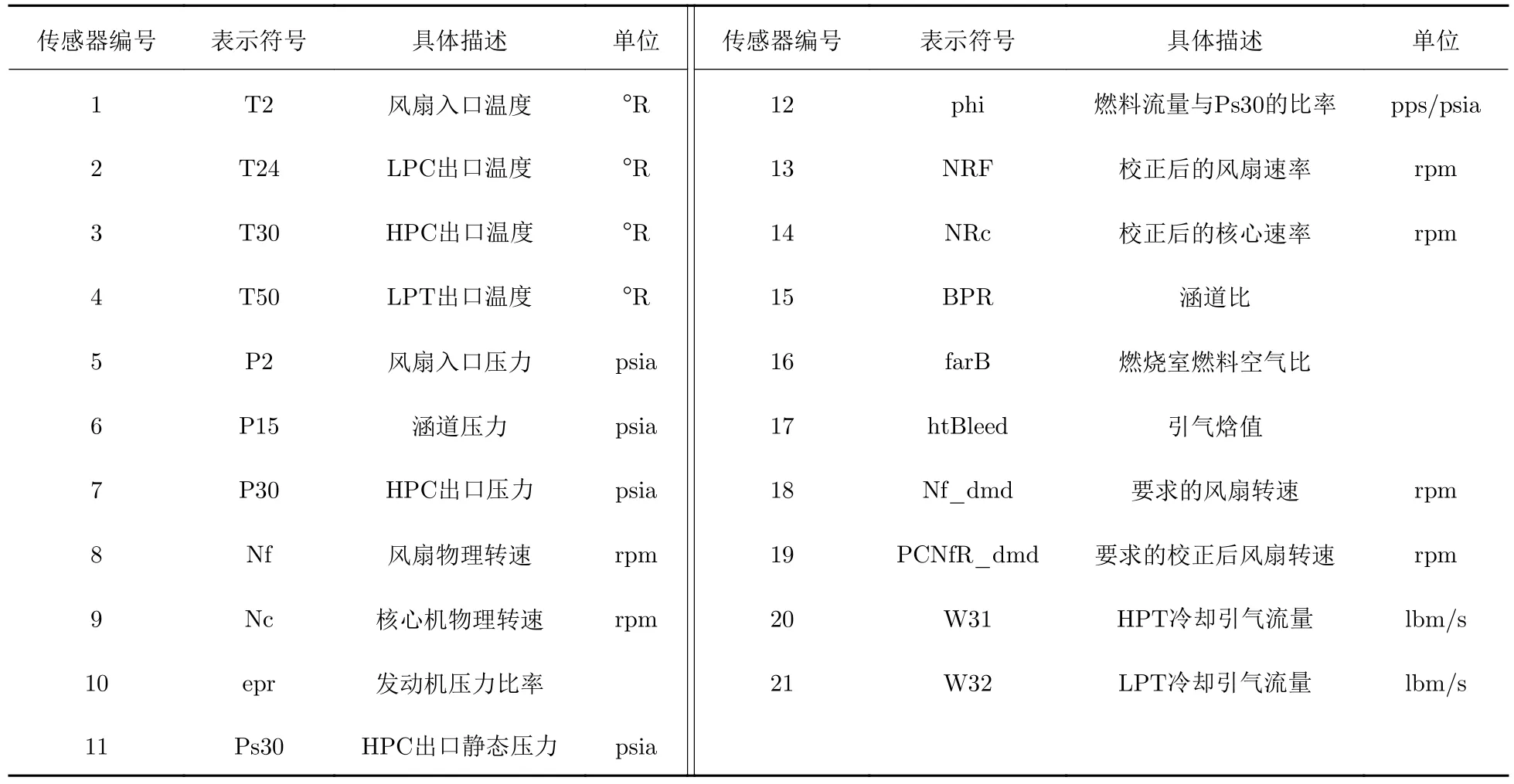
表1 传感器详细描述Tab.1 Description of sensors
2.2 数据预处理
2.2.1 数据归一化
从表1 可以看到,各个传感器的数值单位不一致.为了增强不同传感器数据之间的比较性,提高模型的收敛速度和精度,本文先对传感器数据做了缩放处理.在对比了标准归一化和最大–最小归一化后,本文选择效果更好的最大–最小归一化方法.计算过程为

公式 (9) 中:xi表示当前时间点的值;分别指当前传感器在所有时间点内的最大值和最小值;表示归一化计算后所得到的数据.
2.2.2 传感器选择
通过观察发现,在21 个传感器的数据中,传感器1、5、6、10、16、18、19 的监测数据一直保持恒定.因此,应该剔除这些无法反映发动机退化信息的数据,只留下剩余的14 个有价值的传感器数据作为模型的输入.图5 展示了数据集1 中发动机的传感器数据.其横坐标为飞行循环,纵坐标为归一化后的传感器数据().
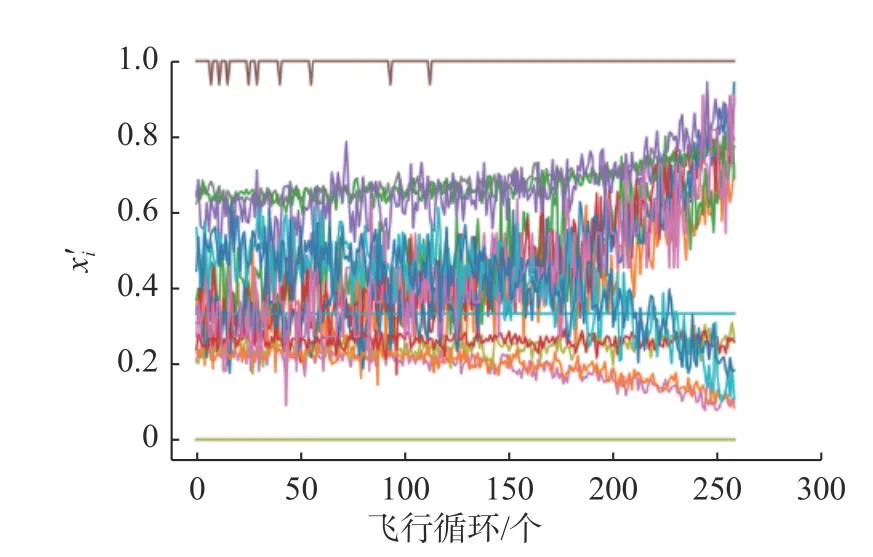
图5 发动机1 号归一化后的传感器数据Fig.5 Scaled sensor data of engine 1
2.2.3 排列熵计算
根据公式 (6),取延迟时间τ=5,计算得到14 个传感器的排列熵值,得到熵值如表2 所示.将计算所得的排列熵作为传感器二阶排列熵向量添加到排列熵编码器层.

表2 传感器二阶排列熵计算结果Tab.2 Computation results of the second permutation entropy of sensors
2.2.4 RUL 标签设置
有研究显示[31],分段线性退化模型能较好地处理CMAPSS 数据集的RUL 预测问题.该模型假设发动机在运行初期属于正常状态,各项传感器的数据较为平稳,因此,认为在这段时间里RUL 值均等于1 个根据经验设定的RUL 最大值.当发动机运行一段时间后,发动机进入退化状态,RUL 随着运行时长线性递减,如图6 所示.图6 中,横坐标为实际飞行循环数;纵坐标为设置的RUL 标签,表示剩余飞行循环数.本文采取分段线性退化模型对训练集中的数据设置RUL 标签,并根据预测效果,将RUL 标签最大值设定为125 个飞行循环.

图6 分段线性退化模型Fig.6 Piecewise linear degradation model
2.2.5 评价指标
为了验证模型预测结果的有效性和准确性,本文使用了2 个常用的指标来进行评价: 均方根误差(Root Mean Square Error,RMSE),本文用RRMSE表示;预测分数 (Score),本文用Sscore表示.这二者都是值越小,表示预测的效果越好.RRMSE是回归问题中常用的指标,其计算公式为
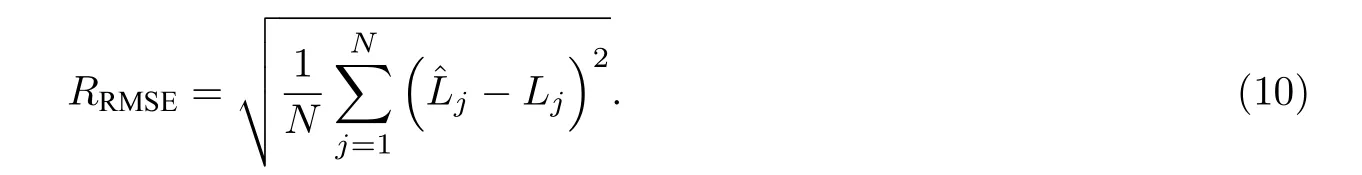
公式 (10) 中:N表示样本数量;表示样本j的预测RUL 值;Lj表示样本j的RUL 真实值.
Sscore是NASA 针对此公开研究问题提供的官方评价指标.在RUL 预测值小于真实RUL 时,意味着预测的发动机故障时间超前于真实的故障时间,根据这个测试结果所做出的维修决策偏向于保守,比较安全,Sscore的值较小;而当RUL 预测值大于真实值时,可能会导致意外的事故或危险发生,后果更为严重,此时Sscore的值更高.其具体的计算公式为
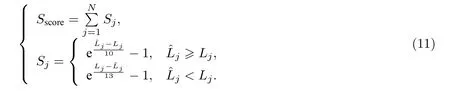
公式 (11) 中:N表示样本数量;表示样本j的预测RUL 值;Lj表示样本j的真实RUL 值.
2.3 模型超参数设置
在模型训练中,为了更充分地利用训练集的数据,本文采用了滑动窗口步长为1 对训练集中的数据进行分割,比较了不同时间长度的预测效果后.对数据集1,选取20 个和30 个飞行循环的时间长度作为双时间长度编码器的输入;对数据集3,选取20 个和40 个飞行循环的时间长度作为双时间长度编码器的输入.表3 描述和记录了模型中其他重要超参数的设置.

表3 模型超参数设置Tab.3 Setting of model hyperparameters
2.4 实验结果分析
使用表3 中的最优参数,将模型在数据集1 和数据集3 中进行训练和预测.在训练过程中,将训练集中90%的样本数据作为训练样本,在剩下10%的样本数据上进行验证;以均方误差(Mean Square Error,MSE)作为损失函数,使用Adam 算法优化模型权值;最后在测试集中进行测试,得到最终的结果.表4 展示了本文模型中所得到的RRMSE以及与其他模型的对比;表5 展示了本文模型所得到的Sscore以及与其他模型的对比.RRMSE和Sscore的值越低,代表模型的预测精度越高,效果越好.表4、表5 中,字体加粗显示的结果代表所有方法中最好的成绩,下划线显示的结果代表所有方法中第二好的成绩.

表4 RMSE 结果对比Tab.4 Comparison of RMSE results
从表4 和表5 中的对比结果可以看出,本文模型在数据集1 上取得了优于其他先进模型的效果,RRMSE和Sscore这2 个评价指标都得到了最好的结果: 对于Mo 等[27]提出的GCU-Transformer 模型,由于其原文并未提供Sscore指标的结果,因此,本文只比较了在RRMSE上的成绩,可以看到本文模型在RRMSE上取得了2%的降低;相较于Zhang 等[28]提出的DAST 模型,本文模型的RRMSE下降了3.4%;本文模型的Sscore相较于Li 等[22]提出的TCN 模型结果下降了13%.
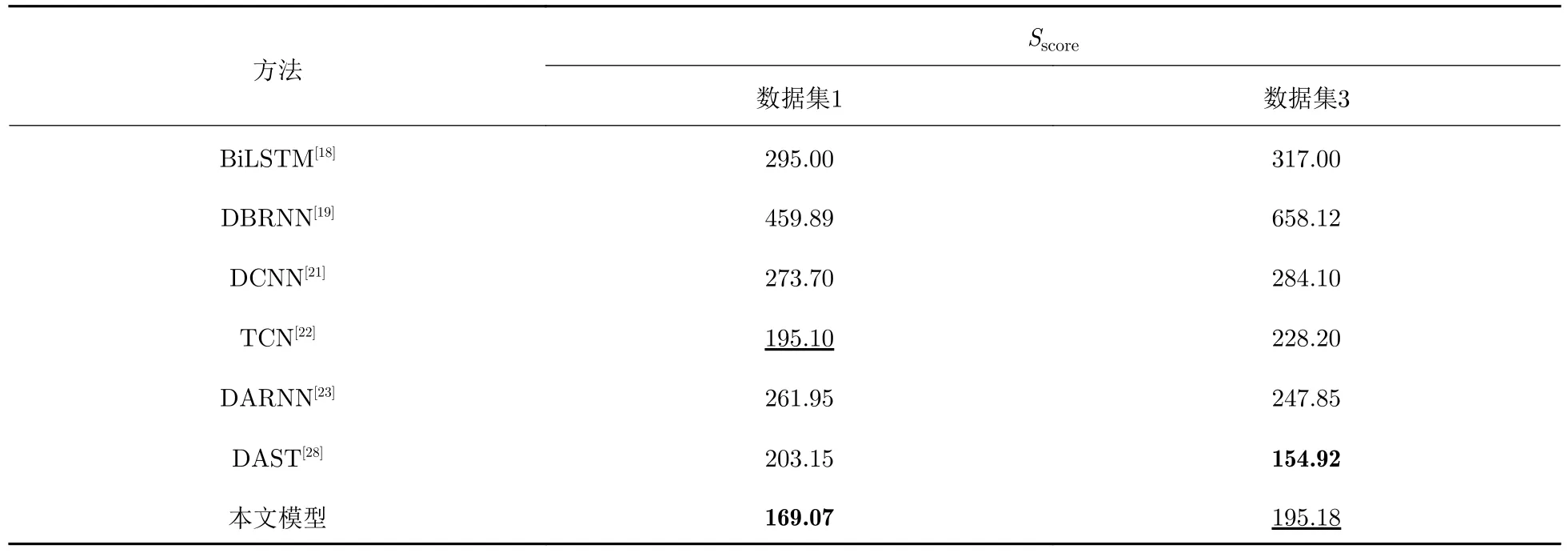
表5 Score 结果对比Tab.5 Comparison of score results
对于数据集3,从RRMSE来看,本文模型略高于Zeng 等[23]所提出的DARNN 模型,但在Sscore指标上大幅度地超过了DARNN 的结果,效果提升了35%;与DAST 模型相比,本文模型Sscore分数略高,但在RRMSE分数上取得了很大的下降,效果提升了5.6%.如前所述,与数据集1 相比,数据集3 包含更多的故障模式,因此,数据集3 的情况更为复杂些,对于RUL 预测任务而言更具考验.相比DARNN 模型和DAST 模型在其中一个指标上取得了最佳效果,而另一指标效果不佳的情况,本文模型在这2 个指标上都取得了第二的效果.由此可见,本文模型稳定性较好,可以实现整体性能和安全性的均衡.
综合来看,相比现有的先进模型,本文模型在2 个评价指标上都取得了不错的结果,且在2 个数据集上都得到了验证,显示出了本文模型的可靠程度较高.
2.5 消融研究
本文采用DAST 模型[28]作为基准模型.DAST 模型是由传感器特征和时间步长特征作为输入的双编码器Transformer 结构,得益于自注意力机制,它能够有效处理长时间序列数据.本文所提出的模型对其做了3 方面的改进工作: 一是使用双时间步长编码器输入;二是添加排列熵编码层;三是独立拆分操作条件输入.在数据集1 上进行消融实验,以研究每一部分工作对整体预测结果的影响.表6所示数据显示了消融实验的结果,验证了每一模块的有效性.
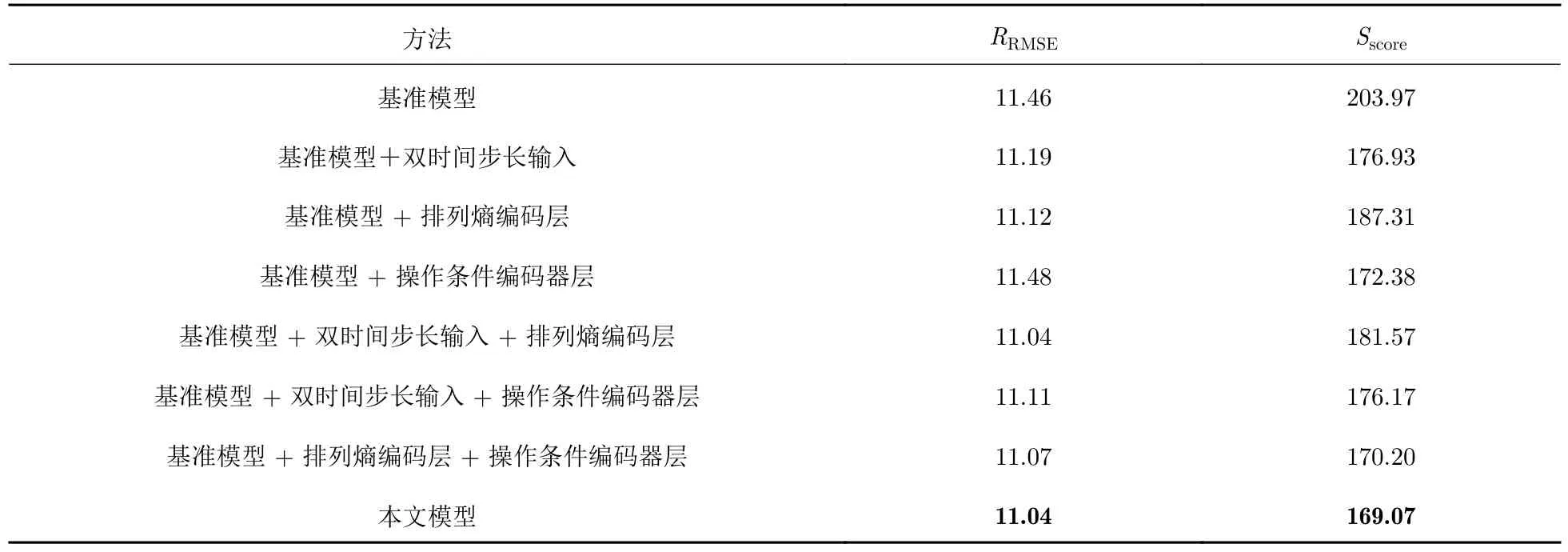
表6 消融实验结果Tab.6 Results of ablation study
3 结 论
本文提出了一种新的基于Transformer 的多编码器特征输出融合的RUL 预测模型: 使用2 个不同步长的编码器层分别进行特征提取,保留长短时间序列中不同的信号特征;采用二阶排列熵对传感器进行位置编码,使模型能更好地捕捉到不同传感器之间的影响关系,并将操作条件数据与传感器数据分离;使用独立的编码器进行训练.利用Transformer 模型可并行计算的优势,将多个不同的编码器层的输出进行融合后,通过解码器层得到最终的RUL 结果.通过在广泛使用的航空发动机CMAPSS 数据集上进行的实验,结果表明,本文模型的预测效果优于现有的其他先进算法,验证了本文模型能够有效提高航空发动机RUL 预测的精度.
在未来的工作中,可以继续以下3 方面的研究,以期进一步提升预测效果: 第一,可以研究更优化的标签设置方法;第二,可以探索数据中存在的不平衡问题;第三,可以尝试利用无监督数据进行预训练来提升模型性能.
