一种改进的Turbo 码结构设计及DSP 实现*
2022-09-24梁立林
梁立林
(中国电子科技集团公司第十研究所,四川 成都 610036)
0 引言
1993 年,Turbo 码的发明掀起了信道编码理论和技术的一场革命,对该领域的理论和工程实现产生了深远的影响。如今,Turbo 码被广泛用于民用3G 和4G 通信以及数据链通信等系统中。
在5G 发展的推动下,2016 年,以Ericsson和Orange 为代表的一些公司和机构提出了增强型Turbo 码方案。该增强型Turbo 码在长期演进(Long Term Evolution,LTE)标准Turbo 码的基础上进行了一系列的改进,如文献[1]提出了咬尾编码方案,使增强型Turbo 码在短码时也有良好性能,同时也解决了高码率下的错误平层问题;文献[2]通过引入更多的校验比特分支,使低码率场景性能得到了提升。此外,增强型Turbo 码也引入了新的打孔、交织方案等。增强型Turbo 码相比于传统Turbo 码性能提升明显,且实现结构改动较小,易于工程实现,具有极高的研究价值。
随着近些年军事装备的高速发展,数据链通信领域对抗干扰性和通信速率提出了更高的要求,因此编译码器需要更高的误码率(Bit Error Ratio,BER)性能和更大的码率范围。本文基于增强型Turbo 码方案,进行了并行译码算法的研究。首先参考增强型Turbo 码的设计思路,采用咬尾码方案,提升了高码率下的性能;其次设计了更低码率的编译码结构,改善了低码率场景下的性能;最后结合并行译码算法和数字信号处理器(Digital Signal Processor,DSP)芯片的优化技术,对译码器的DSP 实现进行了优化,使译码计算效率得到了大幅提升。
1 算法设计
1.1 增强型Turbo 码
增强型Turbo 码采用咬尾编码结构,编码时先进行一次预编码,根据预编码输出状态计算得到能咬尾的初始状态,再用该初始状态进行第二次编码,从而得到编码输出。此方法使每个分量编码器的初始和最终状态都是相同的,并且咬尾编码结构没有引入额外的传输比特,因此没有码率损失。同时,码的网格图可看成环,迭代译码的过程可以看作是在网格图上的不断循环,循环的结构避免了低权重截断码字的出现,因此采用咬尾的方式能有效解决目前Turbo 码存在的错误平层问题[1]。
LTE Turbo 码的母码率为1/3,通过打孔和重复方式可改变码率。增强型Turbo 码相对于LTE Turbo码增加了两路校验位,可支持更低的母码率,低码率下更具性能优势[2]。
增强型Turbo 码采用的是近似正则置换(Almost Regular Permutation,ARP)交织器[1]。为取得更好的性能,增强型Turbo 码的交织器和打孔采用了联合设计方法。增强型Turbo 编码器的结构如图1所示。
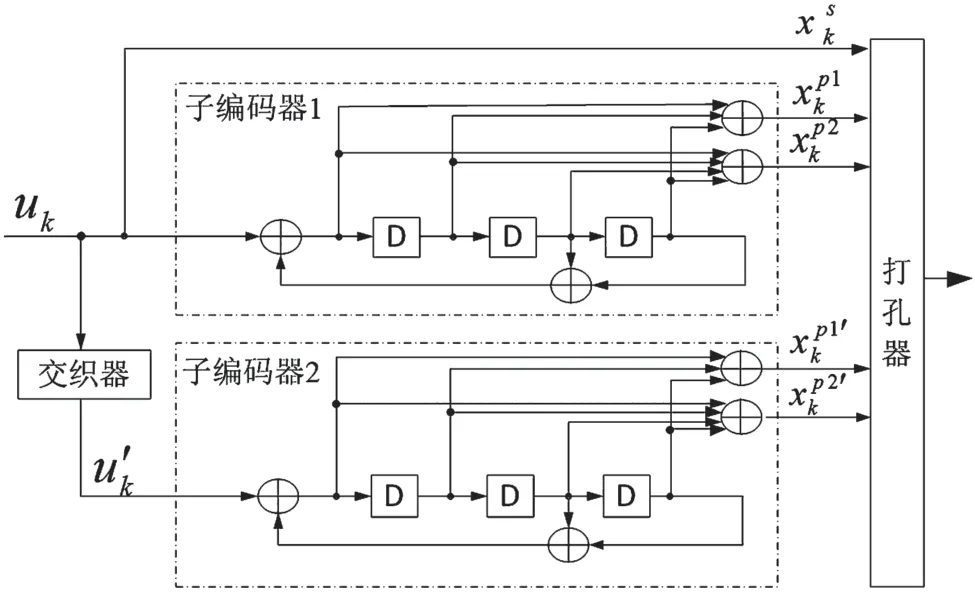
图1 增强型Turbo 码编码器结构
采用咬尾编码方案后,码的网格图可看成环。最大后验概率(Maximum A Posteriori,MAP)迭代译码的过程可以看作是在环状网格图上的不断循环,且无须进行尾比特特殊处理,第一次迭代时前向和后向度量可初始化为等概率值。通过两个软输入软输出译码器循环不断地交替译码,来改善相互传递的外信息[3]。
Turbo 译码器结构如图2 所示。接收信息经解打孔器后得到ys,y p和y^p,分别为系统位信息、校验位信息和经过交织的校验位信息。L为译码器输入的先验信息,Le为译码器输出的外信息,LLR为最终译码输出的对数似然比。
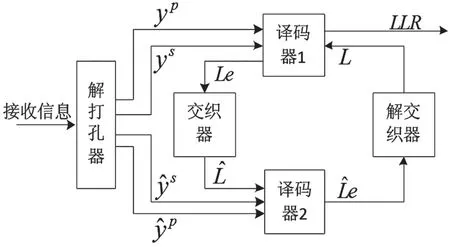
图2 Turbo 译码器结构
1.2 MAP 译码算法
目前常见的MAP算法有Log-MAP、Max-Log-MAP、SF-Max-Log-MAP 等。相对于Max-Log-MAP,SFMax-Log-MAP 仅增加了在外信息传递时乘以SF 修正因子的步骤,性能却得到了较大提升,并与Log-MAP相差不到0.1 dB[4]。因此在实际工程中,更适合采用SF-Max-Log-MAP 算法来降低运算复杂度。
SF-Max-Log-MAP算法基于编码的网格图,其中,s´为前一个状态,s为当前状态,为k时刻对应的发射系统位,为对应的发射校验位,为对应接收到的系统位信息,为接收到的校验位信息。定义Ak(s)为对数前向状态度量;Bk(s)为对数后向状态度量;Γk(s´,s)为对数分支度量;Lc为信道信噪比参数;L(uk)为先验信息;LLR(uk)为对数似然比;Le(uk)为外信息;SF为比例因子,取值为0.75。
在计算前向和后向状态度量时,随着迭代次数的增加,计算结果幅度逐渐增大,会导致定点实现时结果溢出,所以采取最大值归一化方法来限制其幅度。整理算法公式如下:


1.3 并行译码算法
MAP 译码算法采用的是递归的计算方式,这导致译码器难以实现并行化,因此为了减少译码延迟,可采用并行译码算法。常用的并行译码算法有传统的分块并行译码算法和较为先进的全并行译码算法[5]。分块并行译码算法中的边界状态迭代分块并行译码算法中[6],各子块间没有交叠,每完成一次迭代,将各子块交换相邻边界处的前向和后向状态度量作为下一次迭代的初值,随着迭代的进行,边界值也将不断逼近真实值。增强型Turbo 码采用了咬尾编码方案,因此各子块相邻边界处的前向和后向状态度量也能自然衔接,更加符合边界状态迭代分块并行算法的结构。此外,考虑DSP 实现的复杂度,选用边界状态迭代分块并行译码算法。
设原始码块长度为L,将其分成M个并行子块。分别表示m子块在第i次迭代时k位置处的前向和后向状态度量,m编号为1~M。初次迭代时,将前向和后向状态度量的初值设置为等概率值。后续迭代中,将第i次迭代中m子块的前向状态度量最终值作为第i+1 次迭代时,mod(m+1,M)子块的初始值将第i次迭代中mod(m+1,M)子块的后向状态度量终值作为第i+1 次迭代时,m子块的初值
1.4 改进的低码率设计
增强型Turbo 码增加了1/5 的母码率设计,在文献[7]的仿真中,相对于从1/3 码率简单重复得到1/5 码率的Turbo 码有0.5 dB 的BER 性能提升。参考这一思路,本文提出了1/7 和1/9 的母码率设计方案,编码器结构如图3 所示。
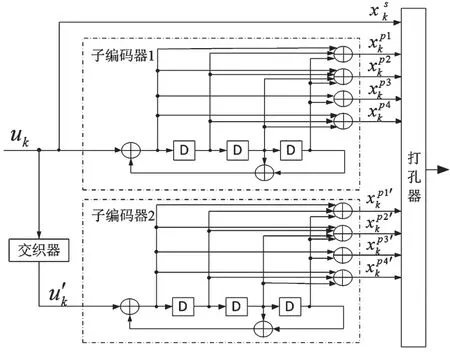
图3 改进的Turbo 编码器结构
在码长为2 020,调制方式为二进制相移键控(Binary Phase Shift Keying,BPSK),信道为加性高斯白噪声(AdditiveWhiteGaussianNoise,AWGN),BER为10-5的仿真实验场景下,迭代12次,仿真验证结果如图4 所示。相对于以1/3 码率重复得到1/5 码率的方案,1/5 母码率方案有0.6 dB的BER性能提升;相对于以1/5 码率重复得到1/7码率的方案,1/7 母码率方案有0.5 dB 的BER性能提升;相对于以1/7 码率重复得到1/9 码率的方案,1/9 母码率方案有0.4 dB 的BER性能提升。
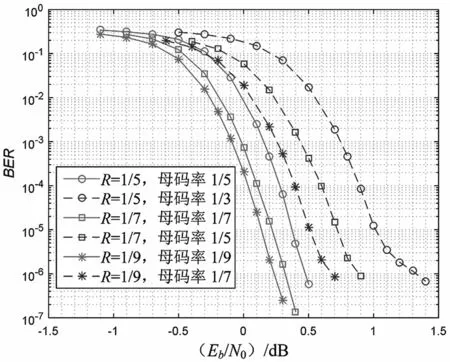
图4 低母码率方案性能对比
2 DSP 实现
2.1 DSP 芯片简介
本文选用的是TEXAS INSTRUMENTS(简称TI)公司的TMS320C6678 多核DSP 芯片。TMS320C6678是TI 基于KeyStone 的多核数字信号处理器,主频高达1.25 GHz,集成了8 个C66x CorePac,其中每个核都有各自独立的L1 和L2 缓存,具有4 MB 共享内存空间[8]。
TI 针对C66x 系列内核程序优化,提供了高效的编译器,可自动进行软件流水优化。同时,也提供了很多高效的数学计算内联函数,因此可利用内联函数进行并行计算优化,提高计算效率[9]。例如,使用_dsadd2()内联函数可实现4 个short 类型的并行饱和加法。
2.2 定点量化
根据硬件实现的需求,译码器实现时,需将浮点数据转换成相应的定点数据。通常输入译码器数据按照6 bit 量化时,可以获得接近浮点的算法性能。根据项目需求,如表1 所示,本文设计接收信息y位宽为8 bit。参考文献[10]的分析,结合MAP 算法计算公式,可设计Γ位宽为11 bit,A和B位宽为13 bit,LLR位宽为15 bit,Le位宽为11 bit。最后根据DSP 的运算单元数据类型,设计接收信息y使用8 bit 的char 型数据,Γ,A,B,LLR和Le相应扩展数据位宽,并使用16 bit 的short 型数据。
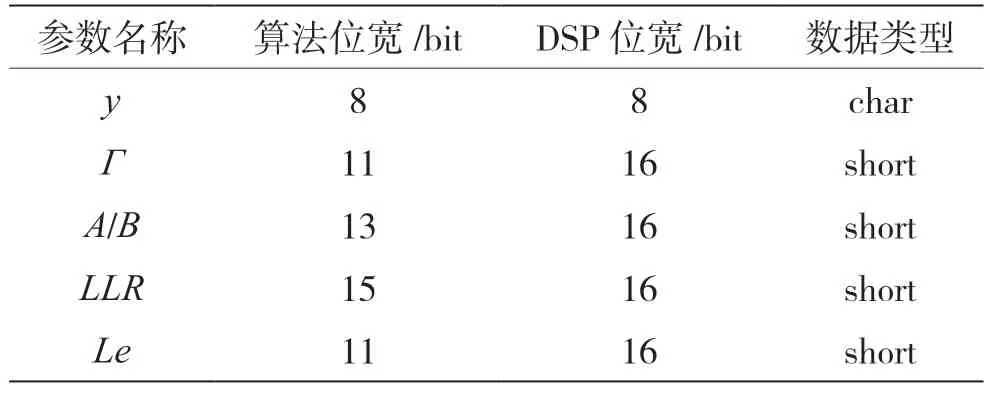
表1 定点量化设计
2.3 实现优化
根据前面推导的译码算法的计算过程,可将DSP 实现归纳为以下步骤:
(1)计算分支度量Γ;
(2)根据Γ计算状态度量A和B;
(3)根据A和B计算外信息Le;
(4)将外信息经过交织或解交织后得到的信息作为另一分量译码器的先验信息;
(5)重复1~4 步骤,直到完成设定的迭代次数,将最后一次的LLR判决译码输出。
由Γ的计算公式(5)可知,其中的g(xk,yk)不包含先验信息,可预先计算,而不必每次迭代重复计算。另外,根据图3 的编码器结构可推导出其编码状态转移表如表2 所示。观察编码状态转移表可知,在输出校验位的位数小于4 时,输出校验位取值有对称相等的情况,可利用其对称性减少分支度量的重复计算及数据存取。例如,校验位为3 位时,当前状态为0,输入比特为0 时,下一状态为0 和4 时的校验位输出都为000。
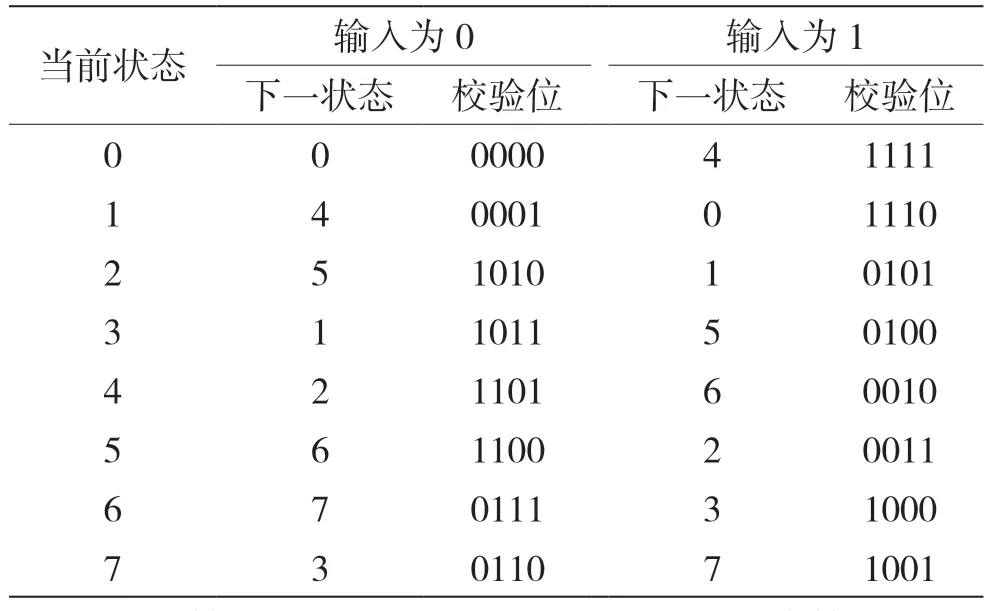
表2 编码状态转移表
译码算法主要是加法、减法和max 计算,可以选择DSP 支持的内联函数_dsadd2()、_dssub2()和_dmax2()。以上内联函数能够支持64 bit 的long long类型数据位宽,可同时对4 个short 类型数据进行并行计算。根据前面并行译码算法的分析,可将原始码块划分成4 个并行计算的子块,正好匹配4 倍并行内联函数,从而提高计算效率。
通过以上分支度量计算优化和并行译码算法的改进,极大提升了译码算法的计算效率。采用单核计算,利用DSP 芯片内timer 计数测量程序运行时钟周期,结果如表3 所示。所验证场景的码块长度为2 020,译码迭代12 次。

表3 DSP 实现优化计算效率提升
2.4 性能验证
对DSP 并行定点实现算法和非并行浮点算法性能进行仿真对比。在码长为2 020,调制方式为BPSK,信道为AWGN 的场景下,迭代12 次,验证码率分别为1/3,1/5,1/7,1/9 时,译码器的BER性能仿真结果如图5 所示。从图5 中可以看出,并行定点实现算法和非并行浮点算法性能一致,各码率下未出现明显的错误平层问题。此外,该DSP 实现的译码器在工程项目中得到了验证,性能也和仿真一致。
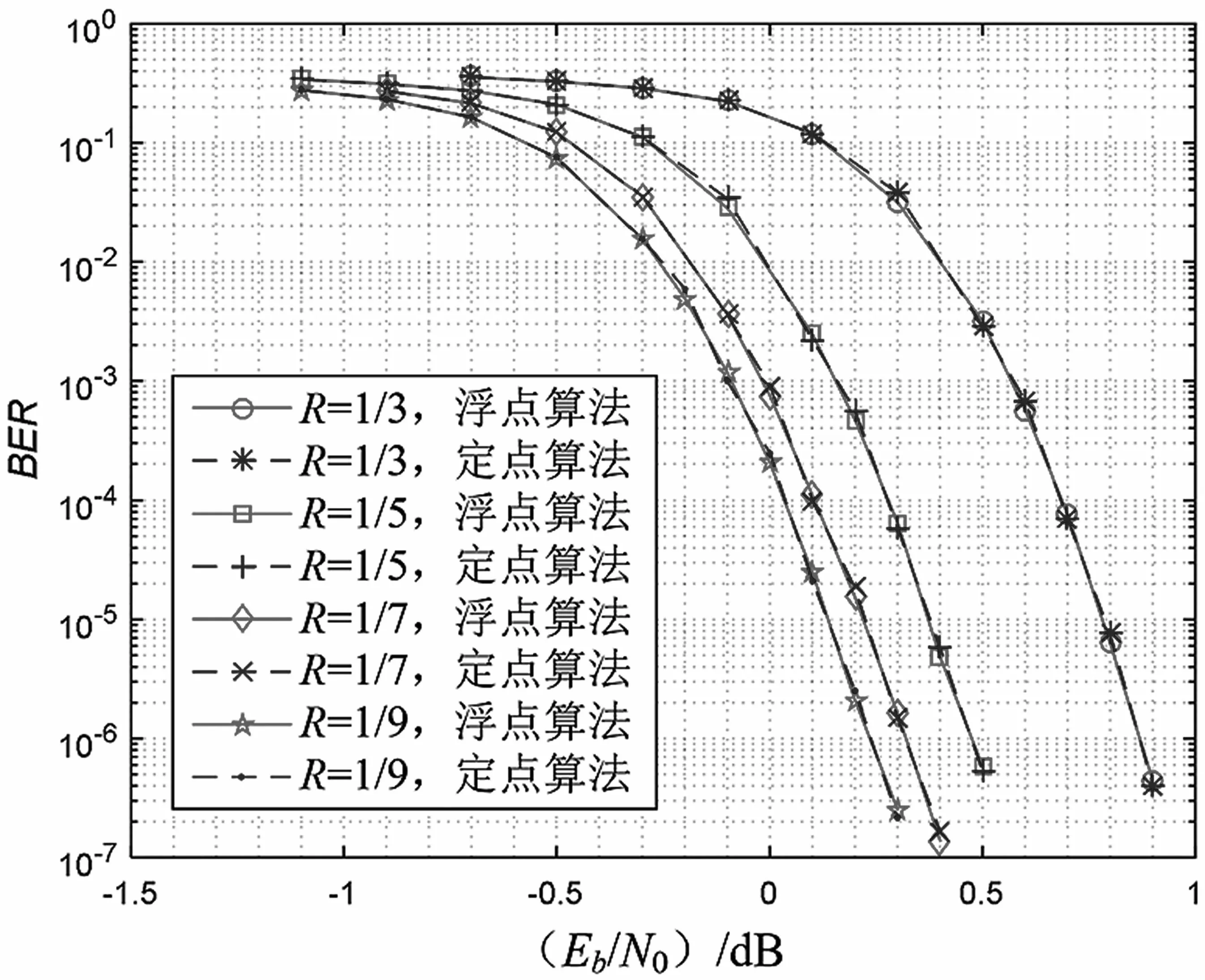
图5 译码器BER 性能验证
3 结语
本文在数据链通信系统的项目需求背景下,研究了5G Turbo 译码增强方案,针对传统Turbo 码的不足,提出了改进设计。此外,结合并行译码算法对译码器的DSP 实现进行了优化。仿真和项目验证表明,该设计性能达到预期,具有较高的工程应用价值。
