农业科学数据集的本体构建与可视化研究*
——以“棉花病害防治”领域为例
2022-09-24刘桂锋
刘桂锋 杨 倩 刘 琼
(江苏大学科技信息研究所 镇江 212013)
0 引 言
2001年,国家科技部启动了“科学数据共享工程”,该项目应用现代信息技术,整合离散的科学数据资源,实现对科学数据资源的规范化管理及利用[1]。农业科学数据共享中心(项目编号:2005DKA31800)在“国家科学数据共享工程”建设总体框架下,以国家科学数据共享的规划为依据,以满足国家和社会对农业科学数据共享服务需求为目的,立足于农业部门,通过集成、整合、引进、交换等方式汇集国内外农业科技数据资源,规范化加工处理、分类存储,最终形成覆盖全国,联结世界,提供共享服务的网络体系[2]。我国学者对国家农业数据的研究主要集中在农业科学数据中心资源和共享服务等建设,从数据资源、共享服务、网络环境、组织管理、标准制定等角度介绍中心的现状[3-4],分中心建设现状[5],多个数据平台比较分析[6],论述国内外数据平台发展历程[1,7],中心的搜索引擎技术的研究[8]等方面做出探讨。虽有学者[9]曾提出国家农业科学数据中心未能实现不同数据集间关联的重点问题,但并没有得到广泛的关注、深入和有效的探索。因此,利用本体构建并发现中心数据资源之间相关的研究尚未发现。
本文以国家农业科学数据中心的数据库为研究对象,从中抽取相关领域的数据,实现农业数据资源各类数据资源间的关联和检索结果的可视化。首先以“棉麻类作物病原真菌病害数据库”和“微生物农药数据库”为例实现两个数据库之间的数据关联,其次利用Protégé5.5.0本体构建工具构建“棉花病害防治”领域本体,实现农业科学数据中心各数据集之间一站式管理、检索和获取,最后创建并可视化数据资源的关联,呈现以数据作为对象的去中心化立体网状结构。
1 研究综述
1.1 农业领域本体构建的现状
国外对本体构建的研究开展得较早,关于农业领域相关的本体构建也在逐步发展中。联合国粮农组织(FAO)提出农业本体服务(AOS)[10]后,对我国农业本体建设具有重要意义。联合国粮农组织(FAO)曾启动农业本体服务项目(Agricultural Ontology Service,AOS)致力于推进农业本体相关研究,并且创建渔业本体(Fishery Ontology)、作物-有害生物本体、抗菌本体等[11]。随后,大量农业本体被研究与开发,如作物本体(Crop Ontology)、基因本体(Gene Ontology,GO)、农业活动本体(Agriculture Activity Ontology)等。
常春[11]将AOS介绍到国内,是我国农业本体研究的开端。自2000年以来,农业本体相关研究不断出现。农业领域本体的构建原则、构建流程、构建方法被许多学者阐述研究[12-13]。在此基础上,学者们基于农业领域的特殊性提出了适合农业领域的构建原则与方法、构建流程[14]。除了构建过程与本体理论的研究外,还将本体构建的实践应用到农业领域的多个方面。农业本体构建主要对象面向于农作物的生产栽培、农作物病虫害防治、农作物销售经济等方面。其中,农作物病虫害防治的本体相关研究最为广泛,学者们对以下具体领域关注程度依次递减:水稻病虫害[14]、玉米病虫害[15]、茶病虫害[16]、柑橘病虫害[17]、番茄病虫害[18]、鱼病[19]、蔬菜病虫害、猕猴桃病虫害、枸杞病虫害、蚜虫天敌等。其次,农作物的生产与栽培也有较多的研究,包括水稻栽培[20]、玉米栽培[21]、猪生产学[22]、奶牛养殖、茶叶生产、水产养殖、田养鸭生态种养、农作物种质资源等。再次,对农作物销售与农作物经济相关的研究,包括农业经济[23]、农产品分类[24]、水稻销售、涉农商品等。除此之外,相对罕见的领域研究有花卉学[25]、古农学[26]、农业古籍、农业灾害应急处置、农业生产资料等。
1.2 农业数据本体研究现状
大数据环境下资源对象类型呈现多样化,其组织形式由文件为核心向数据为中心转化,数据和数据之间通过富含语义链接的形式构成了蕴含价值的数据网络。数据既为领域应用提供了便利,也为便利性的实现提出了难题,需要采取不同的知识组织方法[27],元数据、本体、关联数据为面向领域的大数据知识组织方法提供了具体技术。大量农业领域的数据存在不同的系统中,缺少统一的形式化表达,难以对其进行整合和利用,因此学界对农业数据的知识组织开展了大量研究工作。
农业领域的本体研究主要集中在农业数据采集、数据存储和数据再利用阶段。a.数据采集。Aydin等学者提出了一个通用的基于本体的数据采集模型,创建了基于模型-视图-控制器(MVC)设计模式的榛子农产品相关数据采集表,以快速、独立地获取所需数据,为利益相关者提供在农业开放数据平台上发布和使用[28]。b.数据存储。de Castro等学者通过数据清理、术语提取和排序、链接到相关本体或词汇表术语,以通过标签连接找到其他相关数据集,并开发了 Relevant Tag Extractor (RTagE),实现从数据集中提取术语,对它们进行排名并将其与外部资源相关联[29]。c.数据再利用。Neves等学者针对公有云和私有云环境的本体,架构处理进程级别的语义模型,以满足粮食生产决策时需要各类型数据系统之间的关联数据[30];Rodríguez-García等学者基于现有的自然语言处理资源开发了一个自动本体填充工具将来自多个不同来源的数据建立一个完整的农业知识库,建立一个基于知识的作物害虫识别器,能够识别多种重叠的害虫,帮助农民做出有关病虫害控制的决策[31];Nimmagadda等人采用设计科学研究 (DSR) 方法,具有全面的多维本体,设计和开发基于本体的数据仓库框架,实现各种基于农业的复杂网络系统之间的关联[32]。
基于本体的知识表示方案通过建立属于底层域的不同术语之间的关系而蓬勃发展,利用本体技术对农业领域的数据进行统一规范化后形成知识组织,已经成为提高农业数据利用价值、为决策服务提供支撑的一种有效途径,但国内的相关研究明显偏少,农业领域各子域之间的自动化识别、不同术语之间可能存在的关系依然具有挑战性。农业数据的本体构建方法采用最多的是半自动构建,即将农业叙词表和知识分类组织转化为本体的研究。常用的农业叙词表有中国农业科学院农业信息研究所编制的中国农业叙词表(Chinese Agricultural Thesaurus,CAT)、FAO创建的AGROVOC(多语种农业主题词表)、美国国家农业图书馆创建的NALT美国国家农业图书馆叙词表、欧盟创建和维护的EUROVOC(欧盟农业主题词表)。
2 数据来源与理论基础
2.1 数据来源
国家农业科学数据中心数据资源丰富,以“数据库-数据集”的模式存储着519个数据库(集),96个汇交数据库(集),9个专题数据库,13篇数据论文,大量且跨主题跨学科的数据资源通过分类体系被组织与整合。
国家农业科学数据中心曾采用过三种分类方法:学科数据分类、中图数据分类、数据产品分类,目前国家农业科学数据中心门户网站所采用的是学科数据分类的方法。国家农业科学数据中心按照学科分类,下设12个一级类目,52个二级类目。国家农业科学数据中心分类组织了作物科学、动物科学与动物医学、热作科学、渔业科学、草地与草业科学、农业资源与环境科学、植物保护科学、农业微生物科学、食品营养与加工科学、农业工程、农业经济科学、农业科技基础、果树科学、生物安全等14个学科的数据资源。其中,作物科学、动物科学与动物医学、热作科学、渔业科学、草地与草业科学、农业资源与环境科学、农业科技基础等7个学科分别设立分中心,分中心因各学科特色又设置更为细致的多级层次类目划分。
本文梳理国家农业科学数据中心的分类组织体系,运用本体构建工具Protégé5.5.0在OntoGraf窗口可视化国家农业科学数据中心类目层级,可见一级类目与二级类目,二级类目与三级类目的关系是subClass-Of的种属关系,其中,棉麻类作物病原真菌病害数据库是三级类目中“病虫害”的实例,如图1所示。
2.2 理论基础
为了实现服务于用户需求,达到数据集的定位、查询与检索,国家农业科学数据中心对数据集描述做了明确规范,《农业科学数据公共数据元标准》[33]包括《农业科学数据公共数据元标准(NADC004)》《农业科学数据分类与编码标准(NADC005)》《农业科学数据元数据标准(NADC006)》。其中,《农业科学数据元数据标准(NADC006)》定义了完整描述一个具体对象时所需要的数据项集合,各数据项目语义定义和著录规则等。核心元数据是数据描述的重要组成部分,农业科学数据中心核心元数据元素是元数据子集和实体中必选的元数据元素,可用于数据集编目、数据交换网站活动和对数据集的描述,农业科学数据核心元数据是唯一标识一个数据集所需的最少元数据内容[9]。数据集包含一个或多个数据资源[34],针对描述数据集的核心元数据详见表1。第一列是核心元数据的中文名称,第二列是核心元数据的英文名称,第三、四列是对核心元数据的定义及注解。

图1 国家农业科学数据中心分类图

表1 描述数据集的核心元数据

续表1 描述数据集的核心元数据
国家农业科学数据中心不同学科数据集独立地存储于不同分类体系的数据库下,各个分数据库中的数据无法进行关联检索,不能呈现数据集之间的相关性,本文将通过本体构建,对不同分类体系数据库的数据进行关联,以实现数据增值与知识发现的功能。
由于国家农业科学数据中心对数据集描述的规范存在必选项、可选项、条件必选项三种情况,两个数据集所使用的元数据不完全一致。因此要实现国家农业科学数据中心所有数据集的关联,需要选择标准规范下数据集核心元数据必选项进行关联。要对任意两个数据集实现关联,仅需要选择两个数据集共同拥有的元数据进行关联。
以三元组模式进行假设,
现选取“棉麻类作物病原真菌病害数据库”和“微生物农药数据库”两个数据库作为上述关联原理的实证。关联是事物相互之间发生牵连和影响,注定了关联的主体至少两个以上。选择“棉麻类作物病原真菌病害数据库”和“微生物农药数据库”的原因在于二者之间有很强的关联性,体现在元数据和描述内容的一致上,即三元组中谓语集合与宾语集合中分别存在一致性的元素。而且,以上两个数据库不仅在数据库(集)存在可关联性,其数据内容本身也存在可关联性,可作为“棉花病害防治”本体构建的数据来源。
通过国家农业科学数据中心门户网站获取描述“棉麻类作物病原真菌病害数据库”和“微生物农药数据库”的信息,发现二者的数据集负责人姓名都是“张克诚”,即核心元数据数据集负责方信息。分别用三元组表示为<棉麻类作物病原真菌病害数据库,数据集负责方,张克诚>与<微生物农药数据库,数据集负责方,张克诚>。图2是运用Protégé5.5.0构建对数据库描述的相关本体,并在OntoGraf窗口“Search”搜索框输入“张克诚”进行查询,可以得到“张克诚”是“微生物农药数据库”的生产者,同时也是“棉麻类作物病原病害数据库”的生产者。通过关联的实现,用户可以实现语义检索,并能够直观表明检索内容与其他相关内容。可视化的浏览模式满足用户方便快速的获取需求,满足用户准确定位、知识发现的需求。

图2 基于数据库元数据的OntoGraf检索
3 “棉花病害防治”领域本体构建
在“棉花病害防治”本体构建的过程中,是以“国家农业科学数据中心”的“棉麻类作物病原真菌病害数据库”和“微生物农药数据库”中的数据为主要数据源,并结合《中国分类主题词表》《农业科学叙词表》《汉语主题词表》《中国图书馆分类法》中的分类和术语进行构建。本文采用自上而下和自下而上相结合的方法,根据构建主题的需要,在7步法的基础上制定出适当合理的构建顺序。
由于本文所构建实例领域范围较小,需要依据国家农业科学数据中心提供数据集抽取数据,提取概念术语和关系,可借鉴参考的本体可能性不大。因此,本文将7步法第二步骤复用现有本体减略,进入第三步骤定义本体的概念术语。7步法是在定义完属性之后创建实例,笔者认为不符合Protégé本体构建工具的构建环境,本文是在添加完实例的前提下确定属性。属性在Protégé5.5.0中,表现为object property(对象属性)、datatype property(数据属性)、annotation property(描述属性),annotation property可以在定义概念术语时添加,确定属性的工作主要分为确定object property和确定datatype property,即为“定义类的属性”和“定义类的分面”。本文在“棉花病害防治”本体构建中,定义属性的侧重点在确定object property。7步法与本文构建步骤,见表2。
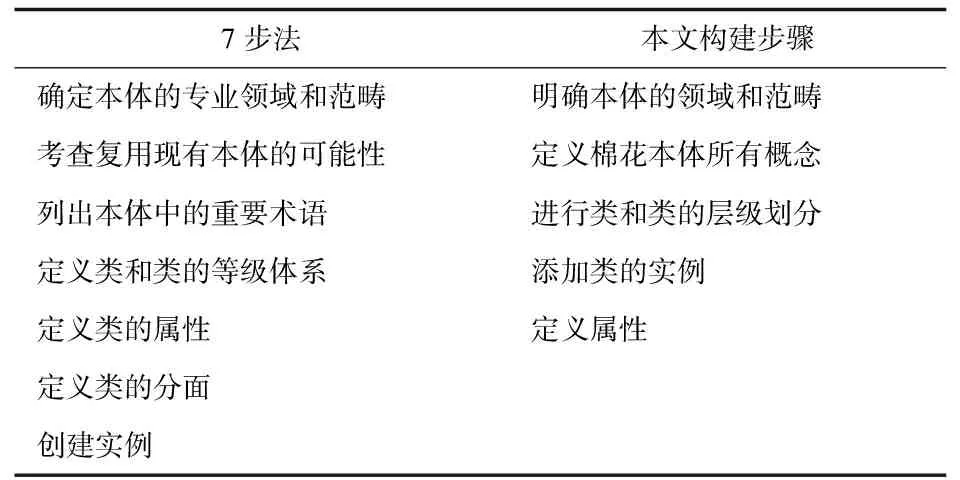
表2 7步法与本文构建步骤比较
本文对国家农业科学数据中心揭示数据资源的研究,通过抽取数据集资源内在数据,以跨“数据集”“数据库”的方式发现数据间的关系,构建“棉花病害防治”领域本体,将呈现出以数据作为对象的去中心化立体网状结构。最终,将推动实现农业科学数据的管理、检索和获取,揭示农业科学数据资源,创建并可视化数据资源的关联关系。
3.1 明确本体的领域和范畴
“棉花病害防治”是一个具有系统性,涉及多方面范畴的主题,包括农业科学、植物保护、化学、农药学等。“棉花”相关的知识非常复杂庞大,本体构建不可能包括“棉花”所有的知识。因此,此次本体的构建主要以“棉花病害防治”为主题,将为“国家农业科学数据中心”的数据使用者提供服务作为应用目标。农作物病虫害防控知识本体就是刻画农作物病虫害领域知识概念、公理、属性、关系、规则和过程的一种规范形式化模型,其目标是实现农作物病虫害防控知识融会、共享和重用。
3.2 定义棉花本体所有概念
依据“棉花病害防治”领域本体的范畴,抽取“棉麻类作物病原真菌病害数据库”和“微生物农药数据库”中的数据,主要以“形态”、“病害”、“棉花”、“农药”等相关概念作为顶层概念框架进行定义。通过查询《中国分类主题词表》《农业科学叙词表》《汉语主题词表》《中国图书馆分类法》等词表,比如:可以确定“棉”归属于“S农业科学-S5农作物-S56经济作物-S561纤维作物”,同属于“Q94植物学-Q949植物分类学-Q949.4种子植物-Q949.7被子植物亚门-Q949.72双子叶植物纲-Q949.757锦葵”。
3.3 进行类和类的层级划分
在确定本体的相关概念后,对类和类的层级进行划分。以顶层本体作为本体构建的框架,本体框架对本体构建的稳定性具有重要意义。因此,将形态、病害、棉区、农药、植物、农作物作为顶层本体。二级类划分如下:形态——整株;病害——非侵染性病害、侵染性病害;棉区——中国棉区;农药——农用抗生素;植物——锦葵科棉属植物;农作物——经济类纤维作物;运用Protégé5.5.0构建类与类的层级,“Class hierarchy”界面进行展示,见图3。
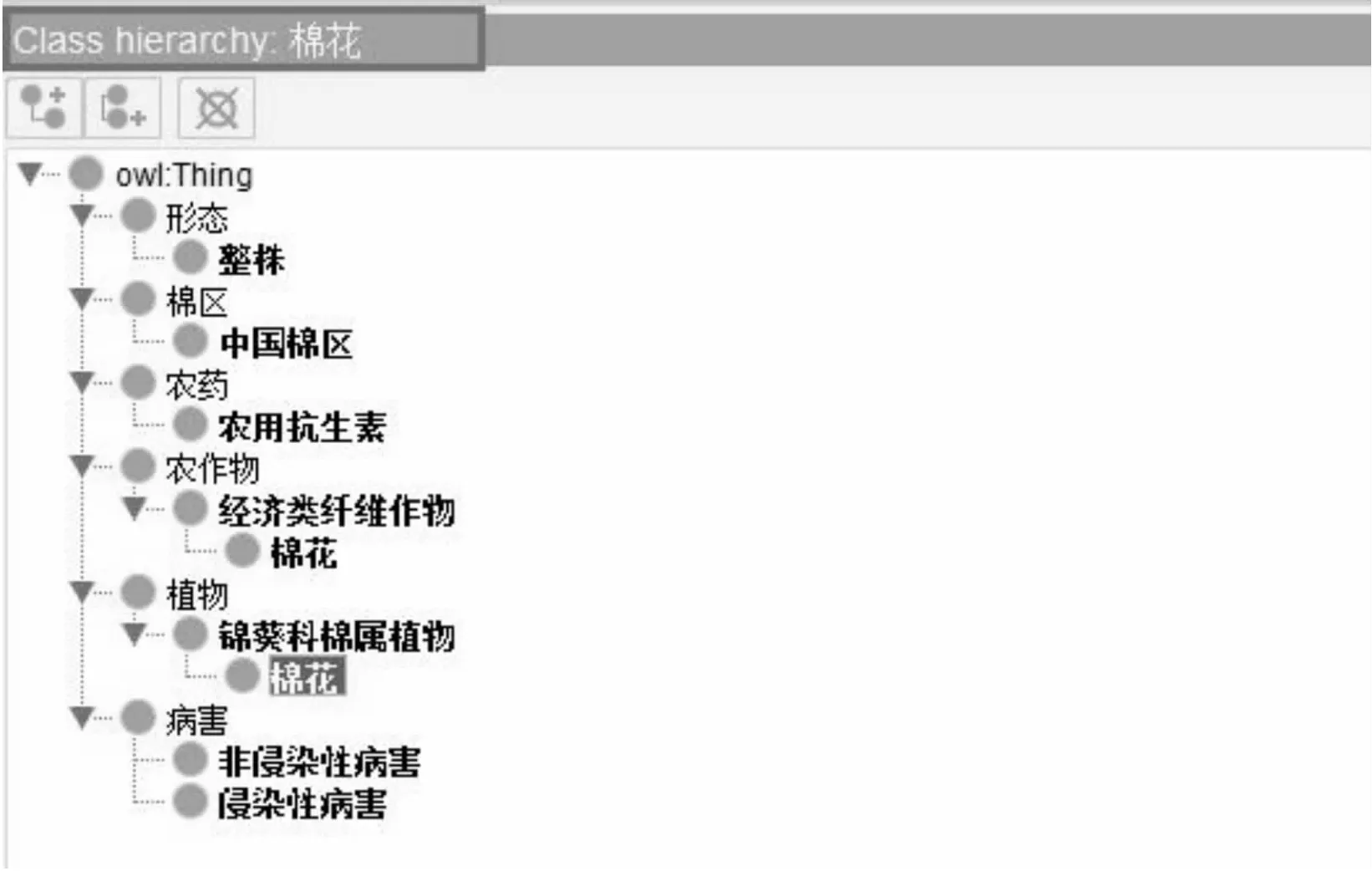
图3 “棉花病害防治”类层级图
3.4 添加类的实例
本体中的实例是指附属于某个具体本体术语的成员,是本体中被处理的具体数据对象。添加“整株”实例:根、茎、叶、蕾铃、果枝;添加“侵染性病害”实例:棉花枯萎病、棉花立枯病、棉花黑根腐病;参考《中国农业区划的理论与实践》对中国棉区的划分,添加“中国棉区”实例:长江流域棉区、黄河流域棉区、西北内陆棉区、北部特早熟棉区、华南棉区;添加“农用抗生素”实例:武夷菌素、井冈霉素、梧宁霉素。本体构建工具Protégé5.5.0 “Individual by Class”界面进行展示,如图4。

图5 “棉花病害防治”添加实例图
3.5 定义属性
属性的数据类型分为数据属性(datatype property)和对象属性(object property),对象属性(object property)指的是概念术语与概念术语之间的关系,主要是指类与类之间的关系、实例与实例之间的关系,具有明显的指向性;数据属性(datatype property)是指描述自身的属性,是与RDF(XML Schema)数据类型之间的关系,包括字符型、数值型、布尔型、时间日期型等,数据型的值域是对属性的取值范围和约束条件的限定性说明。
对属性规范化定义,描述明确概念之前的关系,从而形成直观立体的语义关系网[35]。本文研究中,概念体系涉及的通用语义关系见表3。

表3 本体通用语义关系表
除了通用语义关系,创建者还可以根据构建本体的需求自定义关系。本研究自定义关系见表4,创建者并规范了自定义关系的定义域(Domains)和取值范围值域(Ranges),将定义域(Domains)中的个体连接到取值域(Ranges)的个体。Domains是指属性左侧的个体所属的类,Ranges是指属性右侧的个体所属的类。比如属性Destroy将属于“病害”类的个体,连接到属于“形态”类的个体。
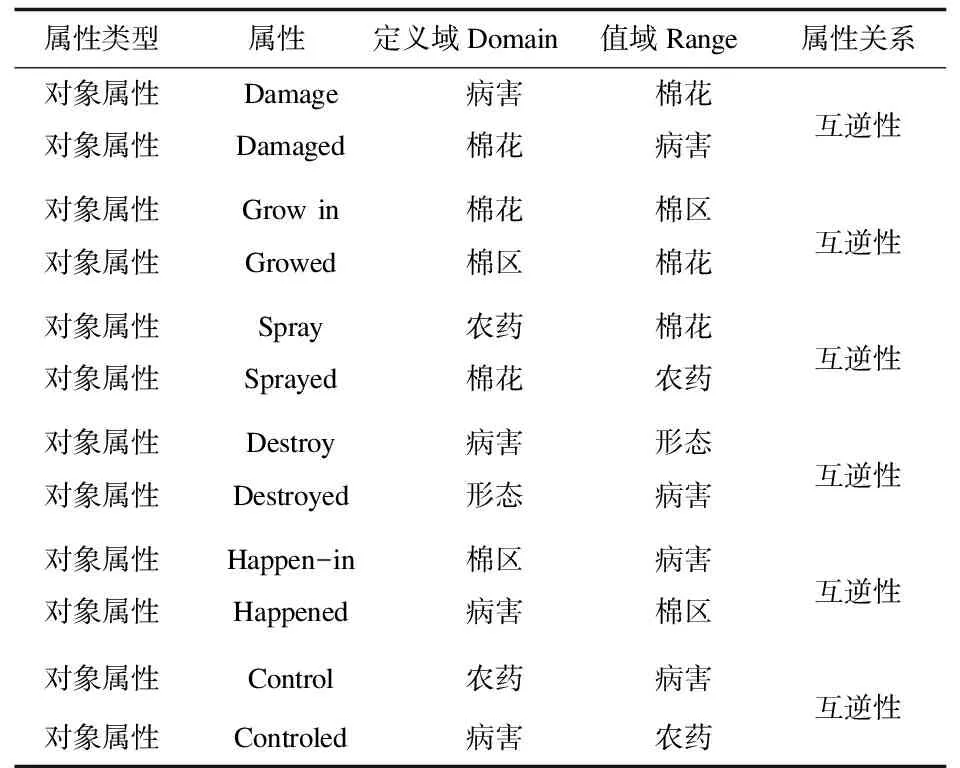
表4 本体自定义关系表
通过自定义关系,可以据此构建类与类之间的关系,见图5。例如:“棉花”“damaged”“病害”,“棉花”“grow in”“棉区”,“棉花”“sprayed”“农药”。由于“damaged”与“damage”的互逆性,在Protégé中为“damaged”“inverse of”“damage”,得知“病害”“damage”“棉花”。

图5 “棉花病害防治”类之间关系图
通过手工提取“微生物农药数据库”与“棉麻类作物病害数据库”的数据,可以发现概念之间的关系,棉花立枯病危害棉苗,棉花枯萎病危害棉苗,棉花黑根腐病危害根茎木质部。而且,棉花枯萎病是世界性的危险病害,在我国大部分棉区均有发生。其中山东、河南、河北、山西、陕西、江苏、四川等省发病较重,即主要发病区为黄河流域棉区、北部特早熟棉区、长江流域棉区。棉花立枯病全国各棉区均有发生,以黄河流域棉区发生较重。棉花黑根腐病主要发生于新疆阿克苏地区,属于西北内陆棉区。武夷菌素可以防治棉花立枯病,井冈霉素防治棉花黑根腐病,梧宁霉素防治棉花枯萎病。依据上述关系,将实例与实例之间关联起来,见图6。

图6 “棉花病害防治”实例之间关系添加
4 “棉花病害防治”领域结果分析与实例展示
4.1 OntoGraf查询
在Protégé5.5.0本体构建工具OntoGraf界面“Search”搜索框输入“棉花立枯病”进行查询,可以得到“棉花立枯病”实例相关信息,图7中展示了“棉花立枯病”相关的类与实例,“棉花立枯病”属于“侵染性病害”超类,“棉花立枯病”破坏“棉苗”,“棉花立枯病”主要发生在“黄河流域棉区”,“武夷菌素”可以防治“棉花立枯病”。
4.2 可视化展示
图8是Protégé5.5.0窗口OWLViz对“棉花病害防治”的类目层级可视化,一级类目与二级类目,二级类目与三级类目之间保持父类与子类“is-a”的继承关系。

图7 “棉花立枯病”ontograf查询
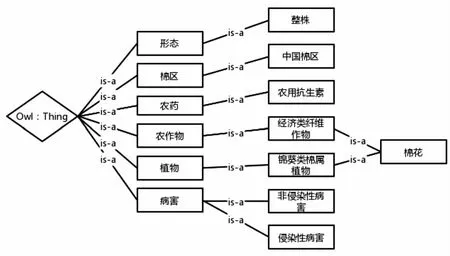
图8 “棉花病害防治”类层次OWL Viz图
5 结 语
利用本体思想对农业领域的数据进行标引,通过予以关系和推理规则将相关概念和信息进行关联,从而使分散的农业领域数据实现智能分析、知识组织和信息预测。国家农业科学数据中心分类体系庞大,数据集量大且独立存储,虽然都采用规范化存储,但互不交叉的存储方式不利于数据的再利用,不利于知识发现和智能搜索。利用本体构建实现农业领域不同子集之间的关联可视化,是当前本体构建的难点。本文根据国家农业科学数据中心的数据集的特点,对本体构建的七步法进行了改进,抽取国家农业科学数据中心“棉麻类作物病原真菌病害数据库”和“微生物农药数据库”的资源数据,发现数据间的关系,从而构建“棉花病害防治”领域的本体,实现了“棉花病害防治”相关信息的搜索和可视化,是农业数据再利用的实践应用,对于实现大数据背景下农业领域各类数据及其关系的精确发现、深层次挖掘、智能检索、数据利用、数据融合等具有重要的理论和实践指导价值。
