基于决策树模型的区域PM2.5污染管控时空识别
——以关中地区为例
2022-09-24贾册,陈臻,韩梅
贾 册, 陈 臻, 韩 梅
(1.中国人民大学环境学院,北京 100872;2.中国科学院科技战略咨询研究院,北京 100190;3.中国科学院大学公共政策与管理学院,北京 100049;4.陕西省环境调查评估中心,陕西 西安 710054)
《2020中国生态环境状况公报》显示,2020年全国337个城市累计发生大气环境严重污染345 d,重度污染1152 d,可见当前中国大气环境污染形势仍然很严峻。这些重污染天气的出现不仅影响居民身心健康,还对社会经济发展造成了很大的损失[1-5]。重污染天气出现的核心原因是由于气象条件的变化,使得大气环境中的污染物不能被及时清除而累积形成。相关研究表明,在重污染天气期间进行预警能有效降低人的出行,减少移动源等污染物的排放从而达到减缓重污染的程度[6-10]。当前国内应对重污染天气的过程中也采取了预警的方式来应对。根据空气质量情况,地方政府适时启动红色、橙色、黄色级别的重污染天气应急预警,要求工业源、移动源等污染排放在一定时间内做出不同的污染物减排,实现空气质量的改善[11-12]。国内外进行污染预警的过程均是通过模型进行预测未来24 h、48 h甚至一周的空气质量变化情况来随时调整预警的级别。这种不确定预警时间和预警时长的方式严重干扰了企业的正常生产,据统计咸阳市2019年1—3月和11—12月期间共预警76 d,占到总天数的一半。当前污染预警管控的过程中是以地级市政府为主体发布预警,要求辖区内企业进行相应的污染物减排,而部分地级市存在行政区过大,同一时间内的PM2.5可能存在两极分化的情况。
由于重污染天气发生一般是区域性的[13],重污染区域内应该统一进行管控,并有效识别需要进行管控的时间段。对于确定的区域而言,短时间内对其大气污染物环境容量影响最大的是气象因素的变化[14-17],高爽等[18]提出基于气象分型的大气环境容量测算,但该研究是通过人工对气象进行分类识别,该方式存在划分依据受人为主观影响的问题,现有研究气象和排放对环境中PM2.5浓度变化的相关文献,基本没有突破行政区划来体现污染区域,也没有深入挖掘所分类气象条件下的污染物变化规律,无法有效指导在不利气象条件下污染排放管控[19-20]。故需要相关研究来对PM2.5的管控时空进行识别,从而实现精确管控和预警,使工业企业提前做好应对,减少经济损失。基于此,本文基于决策树模型提出了一种简易的区域PM2.5污染管控时间段识别方法,以期有效指导重污染天气期间PM2.5污染管控。
1 研究方法
1.1 研究思路
PM2.5污染现象主要出现在冬防期(11月至次年3月)[21],本文基于冬防期PM2.5的浓度数据并结合地形等数据对所研究区域在时间纬度上进行空间聚类,识别不同的PM2.5污染区域;基于PM2.5浓度数据对不同区域的气象数据分别构建决策树模型,识别不同区域影响PM2.5浓度最不利扩散的气象条件,对最不利扩散气象条件下的PM2.5变化情况进行模型构建,确定不同研究区域的PM2.5管控时间段(图1)。

图1 研究思路Fig.1 Research idea
1.2 基于时间维度的污染区域划定
受地形、经济发展、产业布局和气象条件等因素的影响,污染区域分布往往与行政区划不一致,进行区域污染联防联控尤为重要。本文所研究的关中地区(西安市、咸阳市、渭南市、铜川市、宝鸡市、韩城市及杨凌区)具有相对独立的地理环境,包括关中平原和围绕着关中平原的北山山系、秦岭以及崤山等山脉,具有相对独立的地形气候[22-23]。基于此,本文在进行污染区域的识别和划定过程中,综合考虑时空纬度,识别不同气象条件下需要协同管控的污染区域。
首先是对所研究区域每日空气质量监测站点的PM2.5浓度进行空间聚类,将每日聚类的分区结果进行相关性聚类分析,识别在研究时间段内应该集中进行管控的区域。对于所识别的区域,在排除外来传输污染的情况下,工业源、移动源、无组织面源等的污染减排,都将会降低该区域的PM2.5浓度。在进行聚类过程中先由监测点生成泰森多边形,对生成的泰森多边形进行聚类分析,以保证所识别污染区域的连续性。
1.3 决策树模型
分类算法中比较常见的有决策树(分类树)、随机森林、支持向量机、神经网络分类等算法,其中决策树算法能够直观地给出详细的分类过程,其他模型更偏向于黑箱模型预测。决策树算法由Leo Breiman 等学者在1984 年提出[24],并发展出C4.5、C5.0等算法模型。决策树的表现形式为二叉树,在进行模型构建的过程中可分为生长和剪枝2个过程。生长的过程中主要是对输入的众多变量中选取最佳变量以及对所选取的最佳变量寻找最佳分割点。剪枝的过程是找到最佳变量和分割点后将其他影响模型精度的树枝减掉。其中,最佳的分组变量和分割点是被分类变量异质性下降最快的对应参数。该模型能够从繁杂的数据指标中有效识别最有利于划分PM2.5浓度的气象指标因子及相关指标阈值。
1.4 数据来源
研究时段为2016—2019年间的冬防期,每年11月1日至次年3月31日。所使用的PM2.5监测数据来自关中五市的国控点及省控点环境空气质量监测站,共87 个有效监测点,空气质量数据来源于陕西省空气质量实时发布系统。气象数据来源于中国气象数据网(http://data.cma.cn),中国地面气候资料日值数据集(V 3.0)包括平均风速、最大风速、平均本站气压、日最高本站气压、日最低本站气压、平均气温、日最高气温、日最低气温、平均地表气温、日最高地表气温、日最低地表气温、平均相对湿度、是否降水、累计降水量、小型蒸发量、日照时数等指标。
2 结果与分析
2.1 聚类分析
关中区域在研究时间段有87 个空气质量监测点,基本上保证了关中各区县有1 个空气质量监测点,通过对所有监测点的2016 年11 月至2019 年3月的1—3 月、11—12 月期间每日的PM2.5浓度值进行空间聚类,共生成453 个聚类结果。聚类过程中采用R语言的rgeoda包K均值聚类方法进行空间聚类。在对关中地区进行聚类的过程中,通过选择不同的聚类系数并结合F-Stat、地形等因素后,发现关中地区在进行PM2.5浓度空间聚类的过程被分成两类最优的聚类。对453个聚类的结果求相关性系数识别需要集中管控的区域,相关性系数结果见图2。将相关性系数进行聚类可将87个空气质量监测点划分为两类(图2 中黑色方框所包含的区域),这些点在整个研究时间段内会呈现高度一致性,可在地理上划分在一个区域中进行集中管控。在条件允许下,可进一步细化分区管控区域,本文将关中地区分为两类进行研究。将图2分区后的监测点生成泰森多边形,整体区域边界采用函数将边缘进行光滑处理在行政区地图中进行体现(图3a),区域一(白色区域)对应空气质量监测点有37个点,气象观测点有7个点,PM2.5浓度平均值为116.55 μg·m-3,超过24 h PM2.5标准值的天数为192 d,占总天数的42.38%。区域二(灰色区域)对应空气质量监测点有50 个点,对应的气象观测点有4 个点;PM2.5浓度平均值为112.05 μg·m-3,超过24 h PM2.5标准值的天数为294 d,占总天数的64.90%。

图2 关中地区空气质量监测点PM2.5浓度聚类结果相关性Fig.2 Correlation of concentration clustering results at PM2.5 in Guanzhong area
将分区结果投影至关中地区的高程图,由图3b可以看出,区域二划定的范围基本与关中平原所在位置重叠,可见关中地区处于低海拔区域的地方有非常强的区域性[25],同时也说明了PM2.5浓度变化与地形有较大的关系,这与张波等[26]的研究基本一致,有效证明了当前分区的合理性。

图3 关中地区PM2.5浓度地区聚类分布Fig.3 Regional cluster distribution of PM2.5 concentration in Guanzhong area
2.2 地形影响分析
综上所述,关中地区的PM2.5浓度变化与地形有很大的关系,将研究时段内各环境空气质量监测点的PM2.5浓度平均值采用反距离权重(IDW)方法进行空间差值,按照投影到东西、南北和高程3 个维度,进行趋势分析(图4)。结果表明,从东到西PM2.5浓度呈先增加后下降并逐步趋于平稳,在经度109°左右达到了最高点(图4a)。从南到北而言,PM2.5浓度呈先上升后下降再上升的变换趋势,在纬度34.3°左右达到了最高点(图4b)。从海拔来看,PM2.5浓度从低海拔地区随着海拔上升的过程中先下降,当海拔达到100 m左右之后,PM2.5浓度基本趋于稳定,在85 μg·m-3(图4c)。结合图3a 可以看出,关中地区PM2.5浓度最高的区域集中在西安市城区,PM2.5浓度从西安市城区向四周的西咸新区、咸阳市、渭南市、铜川市的平原(低海拔)地区逐步过渡,形成较强区域性的污染区域。随着四周海拔的不断上升,PM2.5浓度又开始出现下降的情况,当海拔达到一定高度后,海拔将不在是影响PM2.5浓度变化的因素,更多是地区污染排放在影响其变化。
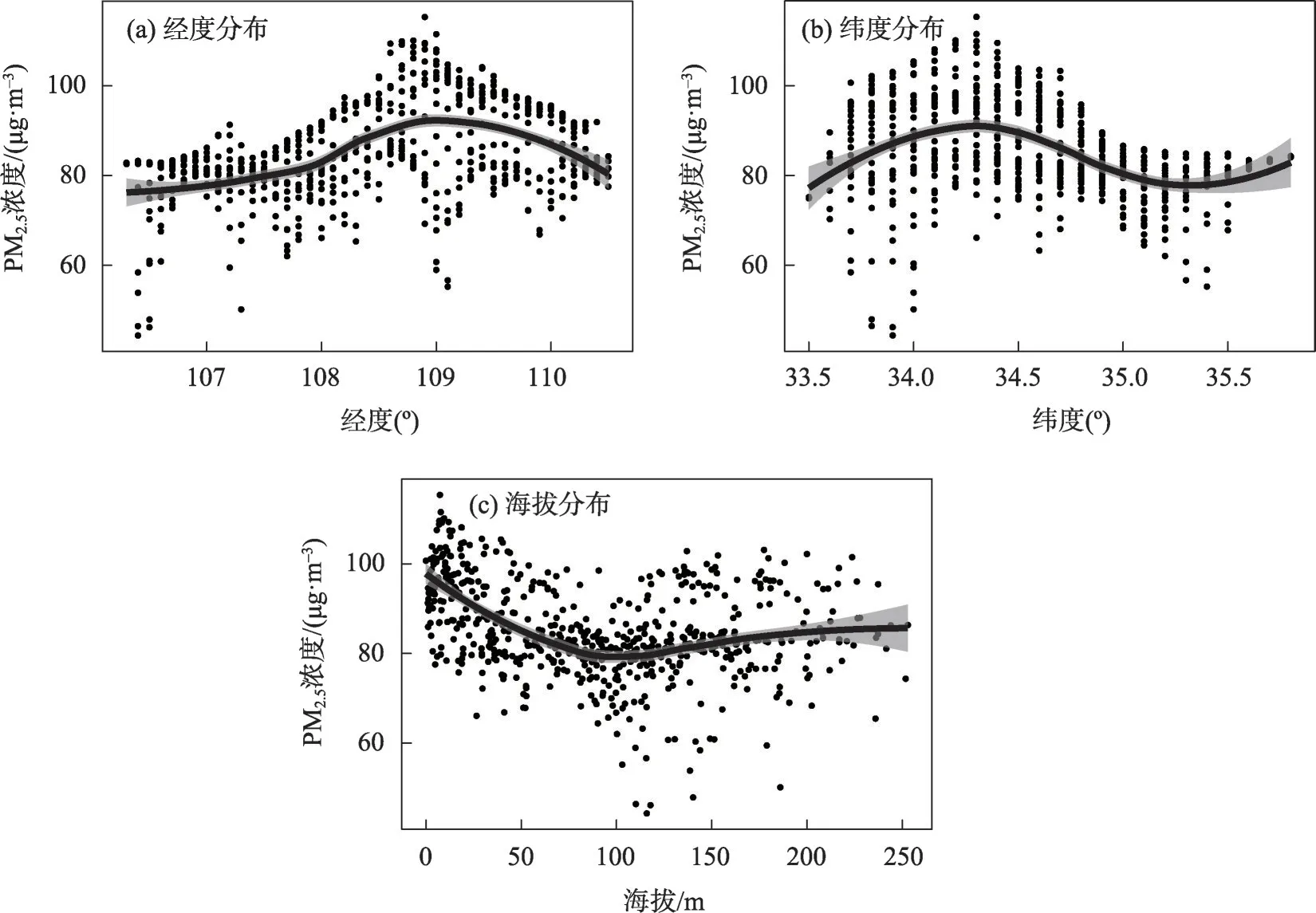
图4 PM2.5浓度分布与地形关系分布Fig.4 Relationship between PM2.5 concentration distribution and topography
2.3 决策树模型下气象分类结果
由于地形和污染企业数量在一定时间范围内是不会发生特别大的变化,而气象条件随时在变化,主要研究气象对PM2.5浓度变化的影响。由于PM2.5浓度的变化是污染排放和多项气象因子综合作用的结果,人工对气象因子进行判断和划定相关阈值会导致较大的主观不确定性。为了规避人为主观因素的影响,采用较为成熟的决策树模型来识别不同区域影响PM2.5浓度的关键气象因子[27]。决策树模型可以通过气象因子对PM2.5浓度变化情况进行分割,在分割过程中充分考虑PM2.5浓度和气象因子之间的关系,并将具有共线性的气象因子进行剔除,有效减少干扰因子。同时该方法能够通过图形表达,更直观地对分类过程给出依据,相较于其他黑箱决策树模型有更好地解释性。
故采用决策树模型来识别影响PM2.5浓度的关键气象因子和分类阈值。在识别过程中以PM2.5浓度为y,所有气象因子为x,采用rpart函数进行分类,初始分类结果结合复杂度参数最佳cp值进行剪枝,结果见图5。其中,区域一在模型构建的时候选取日照时数、最大风速、日最低地表气温、平均本站气压4 项指标对气象进行分类,针对PM2.5浓度的变化情况将气象分为6类。区域二在模型构建的时候选取小型蒸发量、平均相对湿度、日照时数、累积降水量、平均风速5项指标进行分类,针对PM2.5浓度的变化情况将气象分为6 类。区域一、二的气象分类结果见表1,区域一、二中均识别出日照时数的变化主要是由于PM2.5污染造成的。风速对于PM2.5的去除有非常大的效果,也被模型所识别,其中日最大风速和日平均风速是高度相关可替代的因子。除日照时数和风速因子外,区域一处于海拔相对较高地区,还识别了日最低地表气温、平均本站气压作为关键变量,而区域二处于低海拔平原地区,并且PM2.5浓度严重程度远高于区域一,在不考虑排放的情况下主要是由湿度、降水的变化而导致的波动。通过对所有参与模型的气象因子重要程度进行分析(图6),可以看出,区域一二所选择的模型有效涵盖了相关重要因子,所识别的关键气象因子在胡琳等[28]的研究中也得到了有效支持。

图5 PM2.5浓度气象决策树Fig.5 PM2.5 concentration meteorological classification tree

图6 气象因子重要度分析Fig.6 Importance analysis of meteorological factors

表1 决策树模型识别气象分类结果Tab.1 Classification for regional meteorological
为了有效验证所构建分类模型的可信度。以区域一为例,对基于PM2.5分类后的气象类别再次采用决策树预测模型进行验证分类结果的准确性。通过选取70%的训练集和30%的测试集对分类结果进行验证,测试集预测结果的准确率达到了81.2%,有效证明了该方法的可行性。
2.4 最不利气象条件识别
将上述的气象分类与PM2.5的浓度相结合绘制时间序列图7。由图7 可以看出,对于区域一而言,PM2.5的浓度呈由气象条件驱动下的周期性变化。在气象Ⅰ-2、Ⅰ-5、Ⅰ-7条件下,PM2.5基本处于低浓度状态;在1 月中旬至3 月期间PM2.5的浓度周期性波动主要是Ⅰ-8类气象条件所导致,在Ⅰ-8类气象条件下,区域一PM2.5总体呈下降趋势,在清除PM2.5污染。在12 月至2 月中旬主要是Ⅰ-10 和Ⅰ-11 类气象条件驱动的PM2.5浓度变化,这两类气象条件所驱动的PM2.5浓度峰值会高于在Ⅰ-8 类气象条件下的峰值。对于区域二而言,在Ⅱ-3、Ⅱ-5、Ⅱ-7气象条件下,PM2.5基本处于低浓度状态。在Ⅱ-9类气象条件下,区域二PM2.5总体呈下降趋势,在清除PM2.5污染。在11 月至12 月中旬和2 月中旬至3 月期间主要是由Ⅱ-10 类气象条件所驱动,12 月中旬至2月中旬主要是由Ⅱ-11类气象条件所驱动导致PM2.5浓度周期性变化。由Ⅱ-11 类气象条件所驱动的PM2.5浓度周期性变化峰值会高于由Ⅱ-10类气象条件所驱动的峰值。

图7 PM2.5浓度与气象类型时序Fig.7 PM2.5 concentration and meteorological type sequence diagram
综上所述,区域一PM2.5高浓度主要发生在Ⅰ-10 和Ⅰ-11 气象条件下;区域二的PM2.5高浓度主要发生在Ⅱ-10 和Ⅱ-11 类气象条件。将此类气象条件标记为不利气象条件,在这些气象条件下,PM2.5环境容量会达到区域最小值。故需要对此单独进行研究。
2.5 PM2.5浓度变化
由于区域一中Ⅰ-10 和Ⅰ-11 两类气象条件比较相近,将区域一中Ⅰ-10和Ⅰ-11两类气象条件合并。选取区域一和区域二由Ⅰ-10、Ⅰ-11和Ⅱ-10、Ⅱ-11开始的气象条件,连续3 d及以上时间PM2.5浓度持续上涨;其中为了保证选取时间段的连续性,有个别时间段有1 d的其他气象类型或浓度下降的情况。最终区域一有13个时间段满足条件,初始平均浓度为90.02 μg·m-3,每段平均持续4.92 d;区域二Ⅱ-10 有11 个时间段满足条件,初始平均浓度为108.26 μg·m-3,每段平均持续4.22 d。区域二Ⅱ-11有7 个时间段满足条件,初始平均浓度为182.71 μg·m-3,每段平均持续5.14 d。
对区域一和区域二所选取的每一段进行回归构建最不利天气下PM2.5浓度的增长模型(图8)。图中标注了PM2.5浓度累积最快和最缓的回归直线方程。根据以上信息,得出区域一在Ⅰ-10、Ⅰ-11 最不利气象条件下,PM2.5浓度的平均变化方程为:y=21.693x+90.02(图8a);区域二在Ⅱ-10 最不利气象条件下,PM2.5浓度的平均变化方程为:y=18.746x+108.26(图8b)。区域二在Ⅱ-11 最不利气象条件下,PM2.5浓度的平均变化方程为:y=27.658x+182.71(图8c)。

图8 区域一、二最不利气象条件下PM2.5回归模型Fig.8 PM2.5 regression model under the most unfavorable meteorological conditions in region Ⅰand Ⅱ
由表1可知,区域一在Ⅰ-2、Ⅰ-5、Ⅰ-7气象类型,区域二Ⅱ-3、Ⅱ-5、Ⅱ-7 气象类型下,PM2.5平均浓度基本满足环境空气质量标准(GB3095-2012)中规定的PM2.5日均值浓度75 μg·m-3二级标准。而区域一Ⅰ-10、Ⅰ-11 类和区域二Ⅱ-9、Ⅱ-10 类最不利气象条件下,区域一、二PM2.5浓度远超二级标准。
回归结果显示,在区域一Ⅰ-10、Ⅰ-11 类和区域二Ⅱ-9、Ⅱ-10类最不利气象条件下,PM2.5最高浓度分别超GB3095-2012中24 h平均PM2.5(标准数值75 μg·m-3)二级标准的2.62 倍,2.50 倍和4.33 倍。可以看出,相关区域出现所识别的最不利气象条件以及初始浓度达到一定程度时,相关主管部门应按不同的控制程度对企业污染排放设定时间段。由于PM2.5浓度与污染排放之间呈现的是非线性关系[29-30],且不同的工业源、移动源、农业面源、居民源等排放在不同的气象条件和不同区域下对PM2.5浓度的贡献不同[31-33]。
3 结论与建议
(1)关中地区根据冬防期日尺度PM2.5浓度均值结合地形数据,对空间聚类结果进行相关系数计算聚类后可划分为2 个污染区域:关中平原等低海拔地形区域和海拔相对较高的山脉区域。关中地区冬防期PM2.5平均浓度随着海拔的升高而降低,当海拔升至100 m 左右后,PM2.5日均浓度值逐渐趋于稳定。
(2)对于分区后的地区分别采用决策树对其气象类型基于PM2.5浓度进行分类,其中高海拔地区在模型构建的时候选取了日照时数、最大风速、日最低地表气温、平均本站气压4 项指标将气象分为6类。低海拔地区在模型构建的时候选取小型蒸发量、平均相对湿度、日照时数、累积降水量、平均风速5 项指标将气象分为6 类。高海拔区域在Ⅰ-10和Ⅰ-11 两类气象条件的PM2.5浓度较高;低海拔区域在Ⅱ-10 和Ⅱ-11 两类气象条件的PM2.5浓度较高;高海拔和低海拔区域分别在Ⅰ-8 类、Ⅰ-9 类气象条件下的PM2.5浓度呈下降趋势。
(3)回归分析显示,高海拔区域在Ⅰ-10、Ⅰ-11类和低海拔区域二Ⅱ-10、Ⅱ-11类最不利气象条件下,PM2.5浓度平均会持续上升4.76 d,到达最高浓度。最高浓度分别超GB3095-2012 中24 h 平均PM2.5二级标准的2.62倍,2.50倍和4.33倍。
(4)建议在某一区域发生所识别的不利气象条件时,应对该区域内城市同时发布重污染天气预警要求。为有效减少社会经济损失和对居民身体健康的伤害等,发布预警时应包含可能污染持续时长及可能的严重程度等信息,从而促使居民提前安排出行,污染企业提前做好生产任务安排。
