基于组合预测模型下某区碳排放的预测研究
2022-09-23陈莎莎
陈莎莎
(广东一方环保科技有限公司,广东 广州 510000)
0 引言
为完成对区域内碳排放的有效预测,国内外相关研究人员提出了较多的预测模型。在碳排放影响因素解析方面,现阶段常用的模型算法主要有LDMI(对数平均迪式分解法)、Kaya(卡亚不等式)等,为碳排放量的预测奠定了基础。在碳排放预测方面,相关研究人员提出了CSO(鸡群算法)、FLN(快速学习网)等很多模型算法,但单一的模型存在预测精度方面的缺陷,为解决该问题,该文对CSO与FLN两种算法模型进行组合应用,旨在解决区域内碳排放的精准预测难题。
1 碳排放计算方法与影响因素
1.1 碳排放计算方法
碳排放的计算涉及的碳源包括能源消费、秸秆燃烧、工业生产、废水排放、粪便发酵以及甲烷排放等内容,需要核算的碳汇包括城市绿地、耕地林与果园等区域,碳排放结果即为碳源与碳汇的差值,相关技术参数见表1、表2。

表1 各类能源碳排放的相关系数

表2 秸秆燃烧碳排放计算主要参数
1.2 碳排放影响因素
为研究影响区域内碳排放的影响因素,该文通过STIRPAT模型进行评估分析。该模型能够对环境压力、技术、富裕度以及人口之间的联系进行分析,如公式(1)所示。

式中:为常数;为误差;为估算指数。通过两边取对数得到公式(2)。

基于STIPRAT模型对上述公式进行扩展,将产业结构、能源结构、对外开发纳入模型,如公式(3)所示。

式中:即为碳排放量;为能源结构;为产业结构;为对外开放;人口为年末常住人口;技术取决于能源强度;富裕度为人均GDP。
对外开放取决于外商投资比重,能源结构取决于煤炭消费量占比,产业结构取决于第二产业GDP增加比重。相关数据需要从国家统计局网站、统计年鉴、能源平衡表等获取。
2 碳排放组合预测模型创建
2.1 鸡群算法(CSO)
CSO算法具有较高的全局寻优能力,但在小样本碳排放预测精度和方面存在一定问题。在CSO算法模型应用过程中,假设个体在种群中的数量为,食物搜索空间及优化问题维度为维;公鸡数量为,母鸡为,小鸡为,妈妈母鸡为。第次迭代时,用表示第个个体的位置;为个体数量,数值为1~;为维度,数值为1~。适应度值为,在优化过程中,适应度最差的个体划分为小鸡,最好的为公鸡,其余为母鸡。公鸡适应度最优,占据主导地位,位置更新情况如式(3)所示。

式中:表示第个个体第次迭代时的位置;(0,) 即标准差与均值分别为和0的高斯分布随机数;为适应度,与分别表示公鸡和公鸡,均为个体;为常数,用于避免公式分母为0。
母鸡根据子群的公鸡或种群的母鸡、公鸡进行食物寻找工作,随着迭代次数增加,位置受时刻的影响将持续降低,其位置更新情况见式(4)。

式中:为二次非线性递减权重函数;与为影响因子权重,分别与子群公鸡以及种群母鸡或公鸡存在关联;与为个体,分别表示子群公鸡和种群母鸡或公鸡,两者不会为同一个体;即为[0, 1]的随机数;如公式(5)所示。

式中:为迭代的最大次数;设定为0.9,即为惯性权重最大值;反之,数值设定为0.4。小鸡位置跟随妈妈母鸡移动,位置更新情况见式(6)。
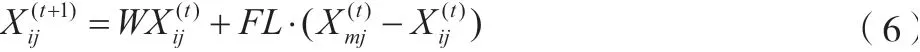
式中:为妈妈母鸡,由小鸡跟随;为[0, 2]内的系数;含义参考母鸡位置更新公式。
为提升算法应用效果,须对母鸡与小鸡的位置更新公式进行改进,具体如下。
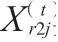
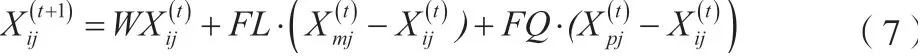
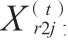

小鸡可以跟随子群里的公鸡或母鸡寻找食物,而非单独跟随母鸡,如公式(9)所示。

式中:为子群公鸡;为[0, 2]的系数。
2.2 快速学习网算法(FLN)
FLN算法适用于小样本高精度预测工作,但在样本取值过程中难以保证所随机样本的实用性。FLN算法应用过程中,假设样本数量为,样本用{(X,T)}(=1, 2, …,)表述;X=[x,x, …,x]即为样本的维输入向量,属于R;取值范围为~,即为样本输出值,取值范围为R。
在碳排放预测过程中,只需要一个输出层节点。隐含层节点数量设定为1,激励函数为g(x),阈值向量用 [,…,b]表述。输入权重矩阵即为W=[,…,W],输入与输出层连接权重用α表述,隐含层与输出层连接权重用表述,=[,…,α]且=[,…,β]。则FLN算法模型如下。

式中:为输入;为输出;取值范围为1~。
转化为矩阵如下。
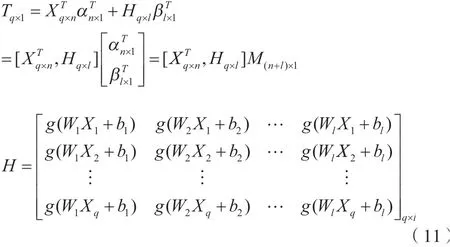
式中:输出权值矩阵、期望输出矩阵与隐含层输出矩阵分别为、T、H。
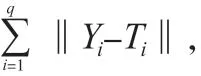

在() 可微的情况下,随机分配b与W,能够取得矩阵,FLN模型的训练即为G·=这一线性系统最小二乘解的求解,G=[,],见式(13)。

式中:即为的广义逆矩阵。具体计算过程为先将阈值与权值随机生成,再求解和,最终将分解为和Т。
2.3 CSO-FLN组合预测模型
FLN模型训练期间存在阈值或权值随机数值为0的情况,为避免出现随机过程过于盲目的情况,选择利用CSO算法迭代的方式选择最优的隐含层阈值和输入权值,以此来强化FLN模型的预测准确性。在CSO算法中将权值与阈值视为个体,均方根误差为适应度值,数值越低则选择的阈值与权值越优,如公式(14)所示。


3 模型应用情况分析
3.1 既有碳排放量计算结果
通过调查数据对某区碳排放情况进行计算,如图1所示。

图1 1995—2019年某区碳排放量及碳排放强度图
3.2 碳排放量影响因素
为掌握序列数据平稳性情况,规避伪回归问题,该文采用EVIEWS软件通过单位根、协整两方式检验各变量,结果表明,各变量二阶差分后均得到平稳的序列,且各变量间的关系稳定均衡。通过SPSS对各影响因素、碳排放量进行多重共线性检验和最小二乘回归分析,结果表明各变量均具有超过10的VIF方差膨胀银子,变量直接的多重共线性问题较为严重,不利于对影响因素进行分析。为此,该文选择利用扩展STIRPAT 模型岭回归计算进行分析。计算结果见表3,结果表明,碳排放量与、、三种影响因素呈负相关,与、、三种影响因素呈正相关;产业结构对碳排放起到较强的促进作用,、、的影响程度则无明显差异。

表3 扩展STIRPAT模型岭回归结果
3.3 CSO-FLN组合预测模型结果准确度
采取归一化处理的方式解决各类原始数据存在较大量级差别的情况,如公式(14)所示。


在训练过程中,假定CSO模型个体数量为100,迭代次数最大值为500,每10次迭代更新一次关系,rpercent=0.5,hpercent=0.65,mpercent=0.5。影响因素数量即输入层神经元为6,输出为碳排放量,隐含层4个神经元。激励函数()=1/(1+-),从所调查的1995—2014年数据中选择20个样本作为训练样本,预测样本选取2015—2019年中的5个样本,以此来检验组合模型的预测结果准确度。通过训练发现,组合模型的适宜度数值在迭代次数持续增加的过程中不断降低,达到最大迭代次数后,适应度数值达到1.3466这一最优值,结果表明鸡群算法能够有效解决FLN算法在阈值与权值随机过程中存在的局部最优或过早收敛问题。
以某区2015—2019年的碳排放量已知数值作为参考,对比CSO-FLN组合预测模型与FLN模型之间的精度,具体需要从、与3种误差指标入手,各误差指标如公式(15)所示。
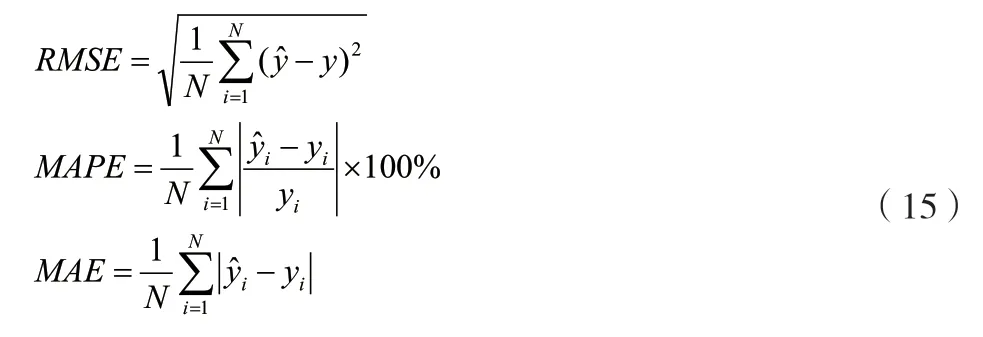
在设定相同参数、样本数值、输入变量的情况下,分别利用2种算法进行50次的数据运算,取平均值作为预测结果,2种模型的误差指标结果见表4。

表4 各模型误差指标计算结果
结果表明,组合预测模型相对FLN模型具有更高的预测精度,相对实际值之间的误差更小,即CSO算法有效改善了FLN算法的预测精度,利用组合预测模型能够更好地解决碳排放预测精度难题。
4 结论
研究结果表明,自1998年来,研究区域内的碳排放量处于上升趋势,但排放强度逐年降低,碳减排工作依然面临严峻挑战。通过扩展STIRPAT模型对碳排放量的影响因素进行研究,结果表明,碳排放量能够随产业结构、富裕度以及人工规模的提升而增加,随着能源结构、技术水平以及对外开放程度的提升而降低;CSO-FLN组合预测模型在精度方面比单一的FLN等模型更具优势,能够有效解决区域内小样本碳排放预测难题,对研究碳排放发展趋势具有参考意义。
