开源组件安全面对安全左移带来的挑战研究
2022-09-22陈克豪
陈克豪,程 伟,丁 荪,刘 杨,3
(1.浙江理工大学信息学院,浙江杭州 310018;2.思探明信息科技有限公司,新加坡 128424;3.南洋理工大学计算机学院,新加坡 639798)
0 引言
为节约成本、提高开发效率,大量开源组件被引入到在企业软件开发过程中,且程序员不愿意使用新版本组件[1-2]。新加坡软件安全公司Scantist 的调查报告显示,97% 的软件应用程序(包括企业软件)依赖于某种形式的开放源码[3],避免使用存在安全隐患的组件对于保证软件安全具有重大意义[4-5]。当前安全测试步骤处于软件开发过程中较为靠后的阶段,且开发人员对软件安全方面的技术不够了解,安全测试人员对于软件开发技术也不够了解[6],存在信息不对等现象。软件成分分析(Software Component Analysis,SCA)是指在开发过程中对应用程序进行分析,以检测开源软件组件是否存在已知的漏洞。例如,Imtiaz 等[7]对现有maven 和npm 源码扫描的SCA 结果进行了横向对比分析,着重对测试结果之间的覆盖情况进行了比较,发现不同SCA 工具的检测结果差异较大,并分析了这些差异可能产生的原因;Zhan 等[8]研究了安卓二进制文件SCA 识别的检测效率、版本识别、混淆恢复能力等问题;Dann 等[9]对开源代码的微小幅度修改对SCA 扫描准确性的影响进行了研究,并介绍了目前常见的开源组件修改方式及其对SCA 分析产生的影响;Dann 等[10]还对不同编译器产生的不同字节码文件对字节码匹配产生的影响进行了研究,并设计了一种工具SootDiff,用于解决不同编译器产生的字节码文件不同而导致的匹配不准确问题。
近年来,随着软件开发周期缩短、迭代速度加快,安全测试越来越难以全面覆盖[11],安全左移的概念随之被提出,即将安全程序(代码审查、分析、测试等)移至软件开发生命周期的早期阶段[12],从而防止缺陷产生并尽早找出漏洞,减少经济损失[13]。为此,本文尝试采用黑盒测试的方式研究安全左移的现状,以及安全测试过程中采用SCA 方法应对各种安全左移场景下组件和漏洞分析结果的准确性,以了解安全左移对开源组件安全带来的挑战。
1 准备工作
1.1 SCA工具准备
首先从现有学术文献和主流搜索引擎中检索以下关键词及其相应的组合,分别为开源、组件、依赖、软件成分、扫描、检测及其对应的英文描述,以尽量覆盖所有SCA 软件;然后对检索到的SCA 工具进行二次验证,发现有些文献中提及的SCA 工具无法在互联网上找到相应链接,排除后得到21 个SCA 工具;最后基于以下条件进行筛选:①非老旧项目;②对于开源工具有编译可执行文件,或可编译出可执行文件;③对于商业工具能够免费试用;④SCA 功能可正常使用。
通过筛选发现,大部分工具支持Java 语言,因此将不支持Java 的SCA 工具排除,最终筛选出Debricked、Github Dependabot、ScantistSCA、Synk、OWASP dependency check、Eclipse Steady 6 个SCA 工具。根据实际情况,在后续实验中选择合适的SCA 工具。由于每个SCA 工具产生的扫描报告标准与格式不统一,本文指定一套标准,将不同SCA工具检测结果转化为统一格式。
1.2 待测项目准备
为使测试结果更完备,待测项目应尽可能包含各种不同情况。选取国内开源社区Gitee 的GVIP 项目,这些项目覆盖了开发工具、服务器应用、运维、数据库、插件、人工智能、区块链等16 个不同领域的热门开源项目。为使项目结构更加多样化,挑选完全由Java 编写的单模块和包含多种语言的多模块项目,其中有些多模块项目明确定义了子模块,有些以互相依赖的方式相关联。下载这些项目对应的源码并进行适当修改,使其能在本文实验环境中通过编译,最终筛选出13个工程共68个子项目。
1.3 安全左移场景梳理
现有文献很少对安全左移场景进行系统性梳理,且由于大部分SCA 工具的具体实现原理是对用户屏蔽的,很难直接评判这些工具是否支持相应的安全左移场景。为此,本文定义了一些规则和认定标准,梳理出以下安全左移场景:①开发过程中只使用经过审核的开源组件;②对上游厂商提供的组件进行安全检测;③在项目正式开发前确定了依赖组件,希望能够提前了解项目的安全性;④在开发过程中了解当前项目的安全情况。
对搜集到的SCA 工具进行左移场景支持情况统计,结果见表1。
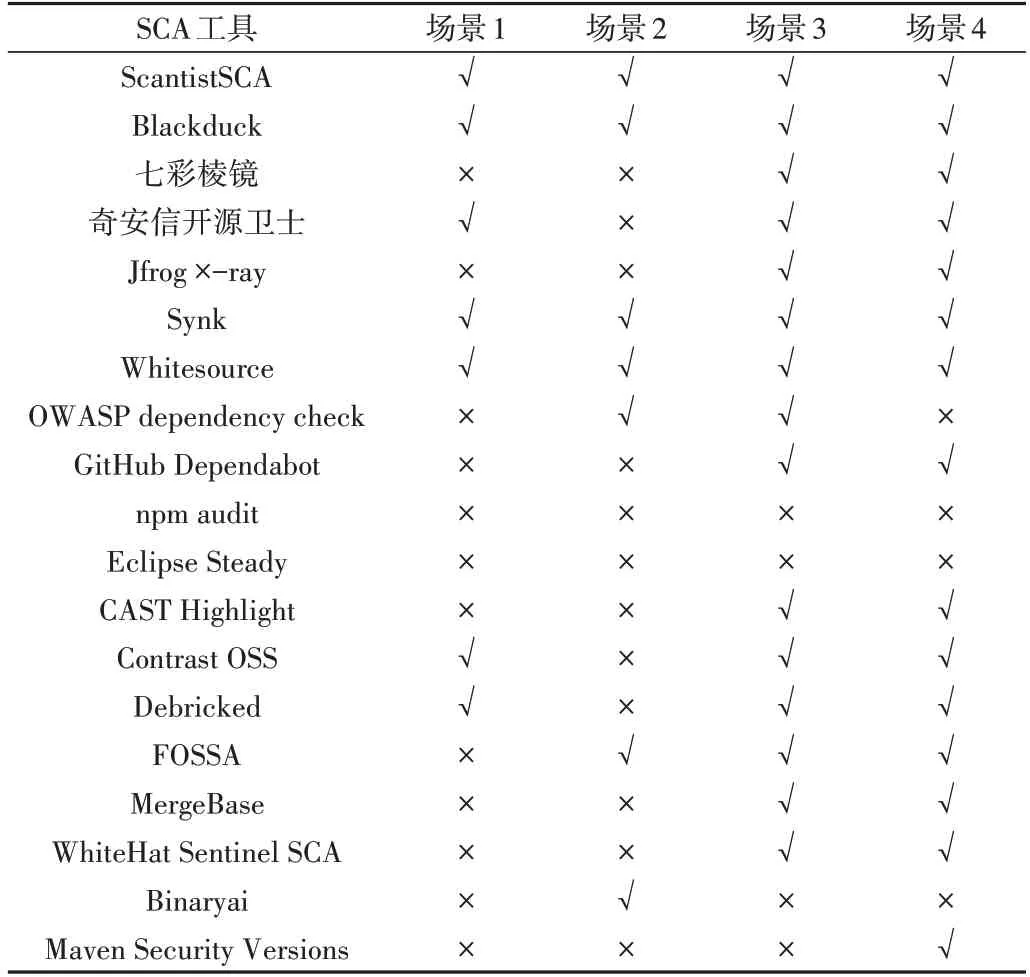
Table 1 Support for secure left shift of the SCA tool表1 SCA工具安全左移支持情况
2 验证实验
验证性实验的目的为证明安全左移会使SCA 产生偏移而导致测试结果不准确,从而诱发开源组件产生安全问题。本文实验选取软件开发过程中常见的安全场景之一,即在项目确定依赖组件时希望能够提前了解其供应链安全性[14-15]。
OWASP TOP10 是软件安全领域最知名的最危险安全漏洞类型榜单[16],2021 年该榜单的第一名为访问权限控制破坏榜单。Apache Shiro 是一款强大且易用的Java 安全框架,近期其权限绕过漏洞频发。基于此,选取几个包含不同CVE(Common Vulnerabilities&Exposures)漏洞的Shiro 组件,在其基础上进行二次开发得到新的组件,以构造间接引入的不安全项目。选取的Shiro 版本及对应的漏洞见表2。

Table 2 Shiro component version and corresponding CVE vulnerabilities表2 Shiro组件版本及对应的CVE漏洞
首先对构建的4 个项目进行漏洞利用,结果发现这4个漏洞都能够被成功利用。将4 个项目的BOM 文件以pom.xml 的格式提取出来用于模拟安全场景,使用Snyk 进行基于BOM 和源码SCA 的SCA 检测[17]。对于基于BOM的SCA,共检测出372 个漏洞,148 个组件依赖;对于基于编译的SCA,共检测出388 个漏洞,201 个组件依赖。漏洞数量比组件多的原因为许多漏洞被多个组件重复报告,这些组件之间有传递的依赖关系。此外,二者组件数有明显差距,漏洞数差距不大,且对于特意间接引入的Shiro 组件漏洞,所有安全左移场景下的SCA 均无法检测出。根据基于编译的漏洞扫描结果对项目进行漏洞修复,然后再次对程序进行验证,发现漏洞已经无法再次被利用。该结果证明编译场景下SCA 工具对于软件安全有非常重要的作用,安全左移将会导致测试结果不准确。
3 实验设计
现有SCA 工具的测试侧重点多为对于IDE、CI/CD 工具的支持情况,并没有量化数据的准确性,而本文更多关注数据准确性方面,希望将关注点从各种繁杂的IDE 和DevOps[18]工具中剥离开来。各种安全左移场景中集成的SCA 工具实际上调用的是底层服务,检测这些安全左移场景的准确度,最终将其转化为检测SCA 工具对于二进制文件、BOM 文件、源码等的扫描准确度问题。
对于安全左移场景1,其准确度完全依赖于SCA 工具本身使用的漏洞数据库,无法评估其检测结果的正确性[14]。另外3 种安全左移场景下的代码可以依据自身存在的蜕变关系将测试结果与传统场景下的SCA 进行比较。因此,本文对这3 种安全左移场景进行研究,尝试揭示现有SCA 工具在安全左移场景和传统使用场景下的表现差异。除开源SCA 工具外,其他工具的内部实现原理是未知的,因此本文采用黑盒测试[19]的方式进行实验。
3.1 二进制文件SCA与编译SCA的结果偏移测试(场景2)
基于二进制文件和源代码编译模式的SCA 之间存在一种蜕变关系,即二者依赖的组件和漏洞是相同的。为避免不同SCA 工具自身扫描结果存在误差的情况,本文对同种SCA 工具的二进制扫描结果与编译后的扫描结果进行比较,选择的SCA 工具为ScantistSCA 和OWASP Dependency Check。
使用编译将待测项目集打包为二进制文件。通常情况下,对于Java 项目,二进制文件有.jar 和.war 两种格式,而.war 文件是不会作为组件依赖被引入项目之中的,即不存在一种安全左移场景会使用.war 文件,因此从实验数据中去除会生成.war 文件的项目数据。多模块项目在编译过程中会产生多个.jar 文件,因此在统计多模块项目数据时对于父模块包含子模块的项目,其父模块的jar 包已经依赖了子模块,则只对父模块的jar 包进行测试;而对于不存在父子关系的多模块项目,则对每个子模块打包得到的.jar文件进行测试。
3.2 BOM 文件相较于源码方式的SCA 结果偏移测试(场景3)
该实验的目的为探究SCA 工具对BOM 文件的检测支持情况,了解安全左移场景3 下的安全初步评估与项目开发完成后实际安全情况的误差。对于maven 项目来说,其BOM 文件为pom.xml。由于目前可使用的SCA 工具并不能直接对pom.xml 文件进行处理,本实验采用源码SCA 的方式间接实现基于BOM 的SCA 检测,即在原始项目数据的基础上编写脚本提取出的pom.xml文件,以此构建空的maven 项目,然后对该项目进行源码扫描作为基于BOM 的SCA。由于源码扫描分为编译和不编译两种情况,使用不同方式对同时支持这两种方式的SCA 工具进行测试,并在实验统计阶段将前端的js 等非Java 项目的数据从结果中去除。
本实验使用的SCA 工具为Github dependabot、Eclipse Steady、ScantistSCA、Snyk、OWASP dependency check,实验最后统计漏洞数、依赖数、不安全依赖数,并根据漏洞、依赖列表之间的差异得到BOM 文件检测相对于源码编译检测的精确度(precision)、召回率(recall)、F1 分数(F1-score)等结果,计算公式分别为:

式中,TP 为真正例,FP 为假正例。
3.3 基于源码不编译和编译的SCA结果偏移测试(场景4)
不经过编译的依赖树结构是通过模拟方式生成的,与实际结果有一定偏差。在安全左移场景下,项目很有可能不被编译通过。在SCA 工具的内部实现中,经常会对不能编译的项目进行依赖树的模拟生成,以此得到其间接依赖。本实验的目的为探究各SCA 工具在不编译情况下模拟生成的依赖相较于编译得到的结果偏差,以此了解SCA工具在不能编译项目的安全左移场景下的精确度情况。采用同时支持不编译扫描和编译扫描的SCA 工具对项目进行测试,比较源码编译结果的精确度、召回率、F1分数。
4 实验结果与分析
4.1 二进制文件SCA与编译SCA比较
对最终生成jar 包的项目进行编译,得到43 个不同的jar,对这些.jar 文件进行二进制扫描,对工程文件进行编译的SCA 检测,数据统计结果见表3,其中dep、dep*、vuln 分别表示组件数、不安全的组件数、漏洞数。
对上述数据进行去重,然后统计二进制与编译方式的SCA 扫描结果分布情况,并绘制韦恩图,见图1。可以看出,二进制SCA 扫描与编译SCA 扫描结果存在较大差异,尤其是漏洞数相较于组件数方面难以分辨。分析其原因可能为大多数Java 项目都采用Spring Boot 脚手架进行构建,Spring Boot 默认使用插件进行打包,在打包过程中会将jar 包构建为fatjar,给二进制扫描带来了挑战。同时二进制文件的编译过程中存在代码混淆的情况[20-21],如将标识符重命名为无意义的信息、给字符串信息进行加密、对未知文件进行移动、将代码转化为伪代码字节流等,这些都会给二进制SCA 造成不便。对于Java 语言来说,使用不同的编译工具也会使编译结果的字节码文件不相同,这可能是导致二进制SCA 与基于编译模式的SCA 结果差异巨大的原因。
4.2 基于BOM文件的SCA检测相较于编译SCA的偏差
采用Scantist 和Snyk 对BOM 文件进行SCA 检测时可通过基于源码编译和不编译两种方式得到数据。值得注意的是,Snyk 在采用编译SCA 方式扫描时存在报错而不能正常通过扫描的情况。命令行日志中提示的原因为不能生成依赖树的命令,源自于maven 无法在中央仓库中找到一个依赖的jar 包,而这个jar 包是子模块的jar 包,在此之前mvn install 已经安装到本地仓库,且在本地maven 仓库中能找到对应的jar 包,执行mvn dependenchy:tree 命令能够正常生成依赖树。使用其他SCA 工具并不存在这样的问题,因此对于基于编译的SCA 支持不佳的现象可能是由于Snyk 本身不够完备,这也说明了源码直接检测虽然在准确度方面可能存在一定问题,但也带来了检测成功率高的优势。
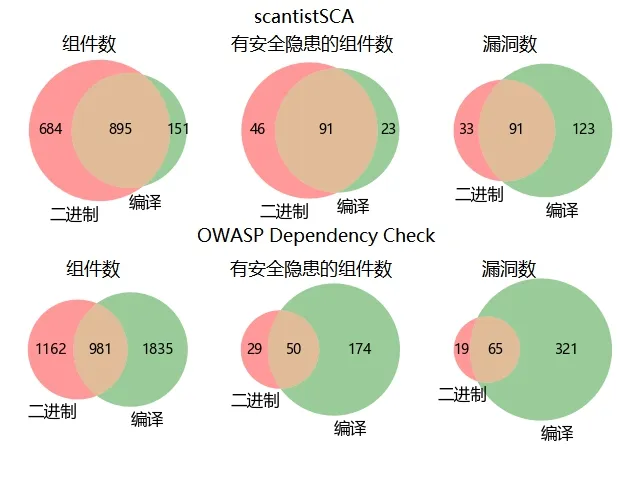
Fig.1 Wayne diagram of binary and compiled SCA result图1 二进制与编译SCA结果韦恩图
基于BOM 的SCA 检测相较于编译SCA 的偏差情况见表4。可以看出,Snyk 的source control 和Scantist 的airgap模式相较于其他模式偏差较大,原因可能为这两种模式是对源代码进行分析后对依赖树进行模拟生成,这与基于编译的SCA 扫描的实现原理有较大差异,且其源代码是不完全的,最终导致偏差较大。其他几个针对pom 文件进行的SCA 扫描均基于编译模式,因此数据比较接近。Github Dependabot 的精确度、召回率等指标全部为1,意味着其在安全左移场景下不会产生任何偏差,这个结果不在预期之中。通过查阅资料了解到其源码SCA 检测结果本身就是不准确的,Dependabot 仅对BOM 文件中的信息进行检测[22],而源码中的BOM 文件是相同的,因此导致最后检测结果相同。
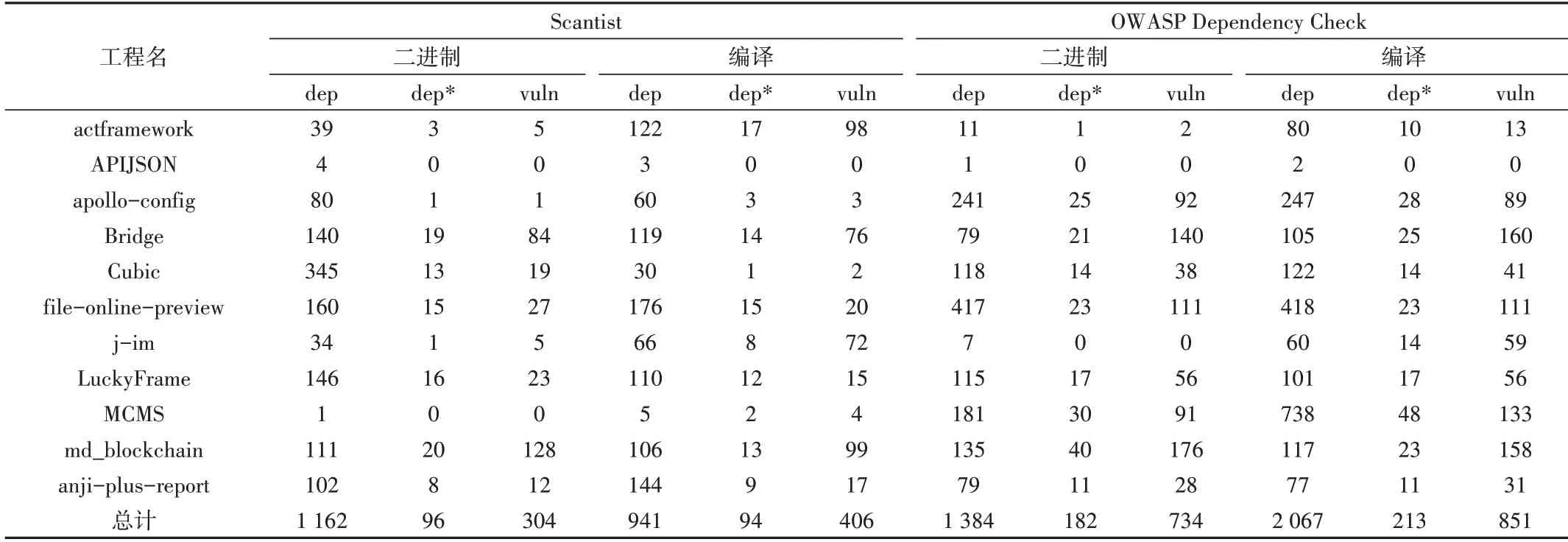
Table 3 Comparison of binary and source compiled SCA表3 二进制SCA与编译SCA比较
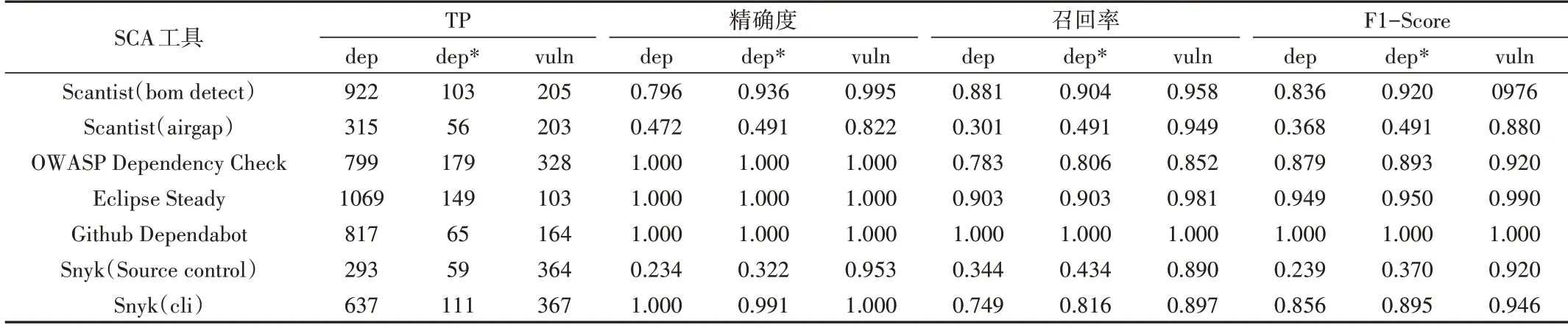
Table 4 Deviation between BOM SCA and source compiled SCA表4 基于BOM的SCA检测相较于编译SCA的偏差
所有SCA 工具测试结果中漏洞检测精确度和召回率均较高,这是由于一个漏洞可能会被多个不同组件引入或组件之间存在依赖关系,从不同地方发现了同一个漏洞,该种安全左移场景下的漏洞检出率较高。所有基于编译方式对pom 文件进行的SCA 扫描精确度均接近于1,而召回率存在一定差距,召回率较高的为Eclipse Steady 和Scantist的bom detect模式,这说明对pom.xml文件进行SCA扫描的安全左移场景误报概率较小,主要是由于出现数据不完整而造成漏报。
4.3 基于源码的不编译与编译模式SCA结果偏差
不同SCA 工具对于是否处理编译和不编译模式存在差异。例如Scantist 的命令行工具提供了airgap 模式,在该种模式下,Scantist 将不会对源码进行编译处理,而是通过对源码进行检测模拟生成依赖树来进行扫描。而Snyk 的命令行工具在执行测试命令前要求项目能够使用mvn install 命令进行编译,如果项目无法编译通过,Snyk 的测试命令将因无法正常执行而抛出异常。在实测过程中发现,执行Snyk 命令行时实际上是调用maven 命令生成依赖树,因此Snyk 使用命令行工具是以编译的方式进行检测的,对于那些Snyk 不能正常导入的项目则通过Git仓库集成的方式得到扫描结果,而这种方式显然是不编译的。
基于源码的不编译与编译模式SCA 结果比较见表5。可以看出,Scantist 和OWASP Dependency Check 两个工具在组件数和有漏洞的组件数方面存在较大偏差,在漏洞数检测方面均表现较好。分析原因可能为多个组件会引入同一个漏洞,最终同时被检测出。导致组件数结果不准确的原因在于不编译方法的依赖树信息是基于代码信息模拟生成的,组件及其依赖关系是通过推测得到的,由于模拟生成依赖树的每一层都有偏差,最终导致其与编译SCA方法生成的依赖树相差较大。

Table 5 Comparison of results between uncompiled and compiled modes based on source code表5 基于源码的不编译和编译模式结果比较
5 结语
本文提出在安全左移场景下开源组件安全可能面临的挑战,并设计了多组实验对不同安全左移场景下的开源组件安全检测准确率进行研究。结果显示,现有SCA 检测工具在安全左移场景下的检测结果均产生了较大偏差,进而对偏差产生的原因进行分析,为SCA 检测的优化方向提供了参考。然而,本次实验仅针对Java 语言和maven 构建工具展开,对于其他编程语言和构建工具不一定具有适用性。后续将针对基于其他编程语言和构建工具的软件开发在安全左移场景下的开源组件安全进行研究,同时将通过融合SCA 构建出漏洞检测和自修复的二进制制品仓库,为安全左移场景下的软件开发提供更多网络安全保障。
