结合轻量Openpose和注意力引导图卷积的动作识别
2022-09-21张富凯贺天成
张富凯,贺天成
河南理工大学 计算机科学与技术学院,河南 焦作454000
动作识别领域常用的数据模态主要分为原始RGB视频和人体姿态[1-2]。原始RGB视频中不仅包含人体的动作运动信息,而且也拥有造成额外计算成本的背景信息,例如光照、杂乱的场景[3]。目前一阶段2D 姿态估计Openpose算法[4]可准确提取视频中每个人的姿态信息,然而由于Openpose算法自身的兼容性差,计算开销大,姿态估计效率低等问题,很难与下游任务(动作特征提取)融合,所以本文在此基础上将骨干替换为shuffleNet轻量级网络[5],重新梳理部分计算层的必要性。
本文所设计的动作识别模型中需要把人体姿态的三维信息预处理为时空联合图卷积特征提取算法的时空图数据,之后再学习其高级语义。早期Yan 等人[6]提出基于骨架图的时空图卷积网络ST-GCN(spatial temporal graph convolutional networks)用于特征提取,在一帧图像上(空间维度)对人体关键点自然连接图做图卷积,在时间维度上做时间卷积[7]或用LSTM(long shortterm memory)网络进行时空特征融合,很好地利用了人体结构的自然连接和动作事件本身各相关关节的联动关系,考虑了空间和时间上的相邻关节,但丢失了时序上下文中一些跨时空的相关关节点的同等影响力,与此同时在时间和空间维度交错进行特征提取的方式对于捕获复杂的时空联合关系鲁棒性不够,忽略了时空内部的紧凑关联。2020 年,Liu 等人[8]提出一种G3D 时空图卷积算子,联合时空信息进行图卷积,构建了多尺度的邻接矩阵,能稳定准确提取到动作本身在立体空间的高级语义特性,对动作分类精度有很大提升,该方法扩大邻接矩阵以捕获跨时空相关关键点的特征表示,但忽略了跨时空关键点的重要性区分,在聚合时没有考虑不同的权重关系。
借鉴以上经验,本文提出一种结合轻量级Openpose和注意力引导图卷积网络的动作识别方法。动作识别的数据处理流程如图1所示,整体布局按业务类型可分为数据、特征提取及动作识别三个层面。数据层面负责将原始视频流中的行人运动信息输出为特征提取层面所需要的骨架图数据形式;特征提取层面负责使用多个时空合并图卷积模块堆叠的时空联合图卷积网络对图数据提取时空特征,最终经softmax区分特征表示,输出类别。

图1 动作识别总体流程Fig.1 Overall process of action recognition
本文的主要贡献如下:
(1)均衡融合轻量级姿态估计Openpose 算法和时空联合图卷积动作特征提取网络,在图卷积模型上下时空联合模块间引入残差连接,分别提取姿态在双流(关键点流、骨骼边流)上的时空联合特征,最终合并双流结果做出动作判断。
(2)提出在不同尺度邻接矩阵合并前加入自注意力机制计算不同尺度内邻居节点特征对中心节点的贡献程度,进一步加强不同尺度邻接矩阵的特征表示。
(3)分别在Le2i Fall Detection 数据集和自定义的UR-KTH 数据集上验证了基于轻量Openpose 和注意力引导图卷积的动作识别方法的准确性。实验结果表明,所提模型在规定的动作类别中可以获得一定的准确度提升。
1 人体姿态估计
1.1 姿态估计
基于shuffleNet 的轻量级Openpose 作为一阶段的姿态估计算法,其任务是预先检测出帧中所有可能的关键点,再将它们与人物个体联系起来,实现多人实时关键点估计[9]。轻量级Openpose的主要组成部分如表1所示,网络单元是指姿态估计模型中的组件;参数主要指各部分的主要数据样式和卷积方式;备注栏介绍部分组件的任务。

表1 轻量级Openpose主要组成部分Table 1 Main components of lightweight Openpose
输入原始帧,经轻量级shuffleNet 网络后得到特征映射,在初始器(主干卷积层、卷积层1,2)中通过卷积层1,2两个并行分支分别得到热图(姿态关键点置信图)、关键点之间亲和场(关键点之间关联程度),优化器(卷积块×4、卷积层3,4)作用是提取初始器输出的高级表征,提高关键点位置预测的准确性[10],它由多个优化卷积模块串行组成。
1.2 骨架图序列构建
轻量级Openpose 的输出包含帧索引、关键点二维坐标(x,y)、关键点置信度c。跨时空聚合相关关键点的特征对全局特征提取具有重要意义,例如动作中的摔倒类别,摔倒之前的动作(站立或行走)和未来动作(躺下)之间存在跨时空相关关键点的信息交流,如图2 所示。为了均等获取跨时空关键点的联系,在单空间维度构建一个多尺度的邻接矩阵A,用以描述图中各节点之间的关系,如图3 所示,箭头所指节点为聚合的中心节点(1帧编号12,节点编号在图2中给出),中心节点当前帧内的一阶关联节点(1帧箭头所连圆圈)和其他帧中指向中心节点的相关节点(2,3 帧中和1 帧一阶节点同编号的节点)构成了跨时空一阶关联节点,二阶(正方形)和三阶(三角形)的跨时空关联节点构造和一阶同样,不同阶数代表不同尺度。A的数学表达式如式(1)所示,k代表阶数(或尺度),d(vi,vj)是节点i和j之间的距离,(i=j)表示自连接。


图2 人体摔倒过程中关键点位置变化Fig.2 Changes in position of key points during fall

图3 视频中关键点空间信息Fig.3 Spatial information of key points in video
为了能同时对时间和空间维度进行联合特征提取,设定一个大小为t帧的时间窗口,在窗口内构成一个时空图G(t)=(V(t),E(t)),其中V(t)表示窗口内所有关键点的集合,E(t)则表示窗口内组合的邻接矩阵。组合后的大邻接矩阵A(t)是由窗口内每一帧的A平铺得到,如式(2)所示,V指单帧中人体姿态关键点的个数。

2 基于注意力引导图卷积的行人动作识别
2.1 使用自注意力机制加强不同尺度邻接矩阵表示
该模块任务是计算不同尺度邻接矩阵在特征提取时的贡献程度[11],假定尺度k∈[1,2,3,4],实现步骤如图4所示。

图4 不同尺度邻接矩阵注意力过程Fig.4 Attention process of adjacency matrix of different scales
(1)根据式(1)获得不同尺度k对应的邻接矩阵A(k),其中A(1)代表图结构的直接表示并已初始化。其他尺度,k=[2,3,4],是基于式(1)和A(1)通过矩阵运算求出,所有A(k)∈RV×V,V代表一帧中人体姿态关键点数。
(2)节点特征X∈RV×3,3代表关键点的三维特征信息,将其分别与A(k)相乘得到不同尺度特征表示A(kk),按照A(kk)的第一个维度计算均值,得到4 组向量A(kkk)后组成列表B。嵌入层将B中的元素映射到d_model(8)个维度,嵌入的大小为k的最大值。
(3)三个并行的全连接层W_Q、W_K、W_V,输入维度均为d_model,输出维度均为64×2(2 表示2 个注意头),三个全连接层的输出分别为4维数组Q、K、V,通过自注意力公式softmax((Q⋅KT)/8)⋅V得到不同尺度中节点的重要特征,全连接层W将通过自注意力计算得到的节点特征维度还原至嵌入的维度d_model。
(4)两个并行的全连接层W_Q1、W_K1,输入维度均为d_model,输出维度为64(单头)。以k=1 为基准得到W_Q1的输出为Q1,W_K1的输出为K1,R(k)表示一阶邻居与其他k阶(包含一阶自身)的相关度,R(k)=softmax((Q1 ⋅K1T)/8),更新原始邻接矩阵R(k)⋅A(k)。
2.2 基于时空联合图卷积的特征提取
使用时空联合图卷积的方法提取图数据的时空联合特征,包含多个时空合并图卷积模块,同时对滑动窗口内的时间和空间维度进行特征提取。特征提取器的计算流程如图5所示,输入一个5维数组(N,C,T,V,M),其中N代表一个前向batch中视频的数量;C代表节点的特征信息通道数,即(x,y,c) ;T代表视频关键帧的数量;V代表关节的数量;M代表一帧中置信度最高的人数。经过批归一化层数组形状被调整为3 维(N,C×V×M,T)[12],最终输入图卷积模型的形状为(N×M,C,T,V)。
时空联合图卷积网络主要由3 个时空合并图卷积模块组成(图5 中的虚线框)。Li等人[13]和Wu 等人[14]使用图邻接矩阵的高阶多项式去聚合远距离邻居节点(即多尺度)的特征,其实验结果表明多尺度图卷积网络可以很好地捕获远距离邻居节点的特征,借鉴经验,在经过邻接矩阵自注意力机制后用多尺度图卷积提取空间特征。每个模块内包含多窗口多尺度的图卷积层和由多尺度图卷积和时间卷积组合的序列化组件层,其中多窗口多尺度的图卷积层是在不同窗口大小下做时间和空间维度联合的卷积,目的在于将动作在两个维度下的内在关系进行表达。组件中依次是多尺度图卷积,能够利用关节点间的最大距离对骨架进行建模;连续2个多尺度时间卷积,用来捕捉长期的或扩展的时间帧上下文信息。为防止层数增加造成特征损失,将时空合并图卷积模块1 的输出经卷积转换后残差连接到模块2 输出,其中每个子块括号内数字分别是计算前后的输入和输出通道数。
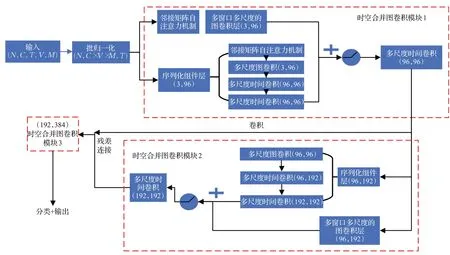
图5 时空联合图卷积网络特征提取的数据计算过程Fig.5 Data calculation process of spatio-temporal joint graph convolutional network feature extraction
经过多窗口多尺度的图卷积层和序列化组件层后,将输出特征相加,送入relu()激活函数,再进行一次多尺度时间卷积特征提取,结果被输入到具有同样逻辑处理结构的下一个时空合并图卷积模块,最终是将特征进行分类和输出。
多窗口多尺度的图卷积层:首先在时间维度上通过滑动时间窗机制(滑动步长为2)获得WIN个大小为t帧时间窗,每一帧的姿态图特征X∈RV×C,因此滑动时间窗的输出数据形状为(N,C,WIN,tV);在式(2)中构建了构建了包含时间维度和空间维度特征的大邻接矩阵A(t),在A(t)的基础上利用numpy计算不同尺度的邻接矩阵,之后运用自注意力机制计算影响力,最终将不同尺度的邻接矩阵进行合并,最终A(t)形状为tkV×tV;滑动时间窗的输出数据包含多窗口信息,最终的A(t)包含多尺度信息,利用普通图卷积方法将两者相乘得到的数据形状为(N,C,WIN,ktV),之后经过一个多层感知器,它由一个输入通道为C、输出通道C1 自定、卷积核大小为1 的二维卷积层,二维批归一化层和激活函数组成,完整多窗口多尺度的图卷积层的输出为(N,C1,WIN,tV)。
多尺度时间卷积:包含5 个并行分支,如图6 所示。前3个分支结构基本一致,均有卷积核大小为1×1的二维卷积和卷积核大小为3×1的二维空洞卷积组成,但是空洞卷积的空洞大小依次是1、2、3,是为了获得更大的时间感受野。第4 个分支只有1×1 的二维卷积,第5 个分支经过1×1的二维卷积后需要进行核大小为3×1的最大池化。输入经过1×1卷积调节通道数量,与5个分支合并后的结果进行残差连接。

图6 多尺度时间卷积Fig.6 Multi-scale time convolution


2.3 动作类别输出
时空图卷积网络输出特征通道为384,之后依次在时空维度、行人个体上对输出特征做全局平均池化,目的是把不同大小的特征图映射为相同大小,池化结果输入全连接线性层(输入通道384,输出通道为类别数),最后通过softmax分类器输出得分最高的类别。
3 实验结果与分析
3.1 数据集及预处理
在Le2i Fall Detection(LFD)[15]和自定的UR-KTH数据集上进行实验。LFD包括191个人类活动视频,分为4 个场景:办公室、家庭、咖啡室和演讲室。UR-KTH数据集是由URFD[16]和KTH[17]数据集组成:URFD 包含70个(30个跌倒+40个日常生活活动)序列,KTH包含6个动作类别,每个类别有100个动作序列。
在训练时利用opencv 和视频编辑工具预处理原始视频,分辨率为640×480,帧率为30 FPS,视频样本时长在3~9 s,LFD 中包含的动作有摔倒、行走、站立、坐下、站起来共5种,共计有26 100帧被选择。URFD中40个日常活动视频彼此间差别较大,需要把它们重新标注为行走、坐下、弯腰,其他四种动作,最终UR-KTH 数据集上共计有10 种动作(拳打、拍手、挥手、慢跑、奔跑、行走、弯腰、坐下、其他、摔倒)。实验中,通过视频翻转对两个数据集进行数据扩充。
3.2 实验设置
实验在ubuntu20.04 系统、Nvidia1080Ti 显卡上进行。基于shuffleNet 的轻量级Openpose 姿态估计算法中适配有3 个shuffleNet 单元,每个单元的深度分离卷积步长为2,分组卷积组数为3,输出通道为240,输出估计结果保存在json文件中。
时空联合图卷积特征提取模型在训练时权重衰减值为0.000 5,模型学习使用随机梯度下降(SGD)优化器,初始学习率为0.05,训练80 个epoch,batchsize 为8,LFD 数据集在第20 和40 个epoch 做0.1 倍学习率衰减,UR-KTH 数据集在第30 和40 个epoch 做相同的学习率衰减,邻接矩阵的尺度值k为4。
图卷积动作识别模型采用准确率(acc)为主要评价指标,平均损失(mean_loss)为辅助指标。acc的计算公式为acc=right/all,其中right表示正确被预测为所属类别,all表示所有参与测试的动作视频样本数;mean_loss代表一个epoch 中真实值和预测值之间的误差的平均数,此值越小越好,其计算方法为mean_loss=代表验证集中batch的数量。
3.3 轻量级姿态估计Openpose效果可视化
在LFD 和UR-KTH 数据集上运行轻量级Openpose姿态估计算法得到的效果如图7(a)所示,图7(b)表示原始Openpose 的效果,两者的输入都是同一帧。由图可看出,两者的效果在大部分情况下保持一致,在有物体或身体自身部位遮挡的情况下,都会造成人体部分关键点信息的缺失,所以在模型数据加载步骤要对缺失的信息进行变换填充,以最大限度减少对动作识别准确度产生的影响。

图7 LFD和UR-KTH数据集上姿态估计情况Fig.7 Posture estimation on LFD and UR-KTH datasets
3.4 消融实验
为了验证对不同尺度邻接矩阵进行自注意力机制计算是有效的,在LFD 数据集上与多尺度G3D 算法进行比较(FLOPs 代表模型的计算量,FLOPs 和参数量数值均保留小数点后两位),在比较之前需要对原始多尺度G3D算法进行微调构成baseline模型,最终对比结果如表2所示。多尺度(k=3 或4)的baseline最优准确率acc值分别为90.48%、95.2%,将不同尺度邻接矩阵通过自注意力机制合并后,准确率acc分别上升了约3和0.3个百分点,但是在k=3 时的平均损失mean_loss相比多尺度G3D上升了约3个百分点,说明在采用自注意力机制计算每个尺度的影响力并不是对任意尺度都适应,如果要兼顾损失和准确率,就需要找到一个合适的尺度k值。

表2 LFD数据集上不同尺度自注意力对比结果Table 2 Comparison results of self-attention at different scales on LFD dataset
由表2后两列的数据可知,对不同尺度邻接矩阵使用自注意力机制所带来的模型参数量与baseline相比增加了0.01(106,k=4 或3);所带来的计算量与baseline相比增加了0.01(109,k=4),k=3 时可以忽略不计。之所以参数量和计算量有少量提升,是因为本文仅使用两层自注意力机制,其中第一层中只用两个注意力头,这样即能达到很好的识别精度。然而如今计算硬件浮点运算能力不断提高,为了追求更高的准确度和更低的损失值,本文算法带来的计算量增加也是满足需求的。
为了验证不同网络层模块对动作识别模型的影响,分别去除多窗口多尺度的图卷积模块、序列化组件模块,之后与本文所提模型进行对比,结果如表3 所示。评估指标为acc(准确度)、mean_loss(平均损失)、参数量,设定邻接矩阵的尺度数k为4(即自注意力k=4),“-”代表移除相应模块。由表3数据可以看出,多窗口多尺度的图卷积模块去除后,识别准确度下降了约6个百分点,损失上升约6 个百分点,它对整体动作识别特征抽取部分的影响程度大于序列化组件块,但是多窗口多尺度的图卷积模块参数量高于序列化组件块。综上,多窗口多尺度的图卷积模块对应的跨时空的联合特征抽取对动作识别精度有关键影响。

表3 LFD数据集上不同网络层模块效果对比Table 3 Comparison of effects of different network layer modules on LFD dataset
3.5 实验效果与分析
3.5.1 数据集训练验证
为了验证整体图卷积模型的有效性,分别在关键点流和骨骼边流上对LFD 和UR-KTH 数据集做训练和验证,最后合并双流结果。在LFD验证集上acc和mean_loss随训练迭代次数epoch变化情况如图8(a)所示,纵轴是百分比值,随着迭代次数的增多,准确率acc不断上升,平均损失逐渐下降,在第68个epoch时得到最高准确率acc为95.52%,对应的mean_loss为16.55%,模型在第55 个epoch 时开始趋于收敛,在第40 个epoch 前变化幅度较大,是因为数据集中样本的拍摄角度差异,不同视角的人体姿态结果会有一定的差异,会对模型训练造成必要的挑战。在UR-KTH 验证集上变化情况如图8(b)所示,趋于平稳时的最优准确率acc为95.07%,对应的平均损失值为16.29%,由于UR-KTH 是自定的混合数据集,在前45 个epoch 需要提取动作的共有特征,所以训练时有比较大的波动。

图8 两个数据集上指标变化情况统计图Fig.8 Statistical graphs of indicator changes on two datasets
3.5.2 与其他算法对比
本文所提算法与其他算法在UR-KTH 数据集上进行准确率和平均损失值对比,对比结果如表4所示。2s-AGCN[18](two-stream adaptive graph convolutional networks)方法是对早期ST-GCN方法的扩展,引入了自适应二维图卷积方法,重点考虑多尺度节点对动作识别准确率的影响,但是在计算高阶邻接矩阵时忽略了远方节点的影响力,本文算法在逐层信息聚合中先均衡化不同阶邻居节点的权重,之后通过自注意力机制加权不同的尺度组,由表4数据可知本文算法准确率比2s-AGCN方法高2.11 个百分点,损失值也下降了3 个百分点。MSG3D[8]是本文采用的基准算法,由表4数据可知,加入邻接矩阵自注意力后可加强不同尺度的特征表示,使模型识别准确率得到提升。pose-C3D[19]的输入是人体关键点的热图体,采用三维卷积提取时空特征,与之相比,本文所提算法更具有优势,准确率提高了2.46 个百分点,因为人体姿态作为一个自然拓扑图,用图卷积算法更能挖掘深层的时空信息。

表4 各模型在UR-KTH上准确率比较Table 4 Comparison of accuracy of each model on UR-KTH %
图9 表示所提模型在UR-KTH 测试集上的混淆矩阵,标签0~9 依次表示拳打、拍手、挥手、慢跑、奔跑、行走、弯腰、坐下、其他、摔倒;横轴表示预测值,纵轴表示真实值。由图9 数据可看出,识别错误主要集中在慢跑、奔跑,行走动作之间,有6个慢跑样本被错误辨别为奔跑或行走,有2 个弯腰样本被错误辨别为坐下,因此需要加强对类似动作的鉴别特征抽取。

图9 UR-KTH数据集上的混淆矩阵Fig.9 Confusion matrix on UR-KTH dataset
3.5.3 总体动作识别模型效果可视化
图10展示了本文模型在所用数据集和网络搜集视频中的表现,总共分为A、B、C、D 四组。A 组展示所用数据集上的常规效果,左边3个是在UR-KTH数据集上的效果,前几帧初始为其他(other),之后间隔采样得到动作类别行走(walking),摔倒(fall),右边3个表示LFD数据集上某一样本,依次检测到行走、坐下(sit down)、站起来(stand up);B 组展示所用数据集LFD 中某一视频动作样本在物体遮挡情况下的识别效果,因受物体遮挡,部分人体姿态关键点无法精确识别,但是可以对关键点进行缺失填充或得到所执行动作中部分鉴别关键点的特征,这样也可成功辨别动作,因此在特征提取时需要关注不同尺度邻接矩阵所对应的部分重要鉴别特征;C 组展示一段网络搜集的体育运动视频,在多目标场景下也可以准确识别出三个人正在慢跑(jogging);D组展示网络搜集视频,第一幅图像存在模糊,严重遮挡,仅识别到奔跑和行走,第二幅图像存在视野模糊,较少关键点信息,一人动作(奔跑,running)错误识别为行走(walking),第三幅正确识别(2个running,1个walking)。

图10 动作识别效果展示Fig.10 Demonstration of action recognition effects
在严重遮挡和密集目标群体中,所提模型的实时性和准确率需要加强。
4 结束语
本文利用人体的姿态信息构造图数据来进行动作识别,不仅大大减少了背景对识别效果的影响,而且也减少了计算量。较早使用图卷积模型(ST-GCN)获取骨架动作特征未能将时空表征联合考虑,对于对时空结合信息依赖大的动作并不能做到很好的识别。本文在G3D卷积算子的基础上提取姿态时空联合特征,并融合了不同尺度邻接矩阵自注意力机制加强相关关键点的依赖性,通过融合多种模型算法来解决现实生活中的动作识别问题。该识别系统序列化组织姿态估计、特征提取和分类模块,规范数据流逻辑处理,在未来的研究中,将更专注于动作的发生时间段获取和识别实时性、准确性,这样可以提高识别系统的泛化能力,更好的投入应用。
