面向CFD应用的Intel持久内存性能评估*
2022-09-21文敏华胡广超韦建文王一超林新华
文敏华,陈 江,胡广超,韦建文,王一超,林新华
(1.上海交通大学网络信息中心,上海 200240;2.英特尔(中国)有限公司,北京 100013)
1 引言
随着计算机计算能力的飞速提高,处理器和存储性能的差距越来越大,数据访问能力越来越成为超级计算机应用的瓶颈。在传统的计算机架构中,DRAM负责衔接处理器和硬盘的数据流通。目前,超级计算机上单节点的DRAM容量已经能达数百GB。然而,以DRAM为主的内存配置方式存在2个问题:(1)DRAM的延时通常在几十纳秒,其下一级的固态硬盘,延时能达到上百微秒至几十毫秒,二者之间存在巨大的性能差异,一旦数据无法从内存读取,将面临极大的开销;(2)随着对计算模拟精度要求的不断提高,超级计算机上的应用在单节点产生的数据量急剧增大,DRAM由于其相对较高的价格,难以在容量上大规模扩展。
近年来,研究人员在不断探索新兴的内存技术,力求保证字节寻址能力和出色的可扩展性,其中持久内存技术PMEM(Persistent MEMory) 可提供快速的持久存储,补充 DRAM 以扩展主存储器容量。最近推出的 PMEM 技术中最有影响力的是 Intel傲腾持久内存DCPMM(Intel’s optane Data Centre Persistent Memory Module)。
相比于DRAM,持久内存可持久化、价格低、密度更高,Intel傲腾持久内存单条容量可达到128 GB/256 GB/512 GB,且支持按字节直接寻址(Binary Addressable)。在使用上,持久内存可以支持2种模式:内存模式和App Direct模式,适用不同应用场景。其缺点是带宽相对较低、延迟也更高,这对其在实际应用上的使用有一定影响。
计算流体力学CFD (Computational Fluid Dynamics)[1]是超级计算机的一个重要应用领域,是一个介于数学、流体力学和计算机之间的交叉学科,其主要研究内容是通过计算机和数值方法来求解流体力学的控制方程,对流体力学问题进行模拟和分析,在航空航天、船舶等领域应用广泛。近年来,随着计算精度需求的提高,以及对LES(Large Eddy Simulation)[2]和DNS(Direct Numerical Simulation)[3]等高精度模型的使用,前沿CFD问题的数据量越来越大,因此探索大容量内存解决方案具有实际使用价值。
本文基于Intel傲腾持久内存的内存模式评估常见CFD算法的性能,了解在完全不增加编程难度的情况下,傲腾持久内存对CFD性能的影响。本文的主要贡献点有如下2点:
(1)对两代Intel傲腾内存分别进行了基准测试,与DRAM进行了对比,测试了访存带宽;
(2)结合2个迷你应用和1个真实应用,评估了傲腾持久内存对3种常见的CFD算法的性能影响。对于CFD实际应用,测试和总结了持久内存对大数据量算例的性能影响。
2 相关工作
目前已有一些基于Intel持久内存的研究工作。Weiland等人[4]评估了Intel持久内存对一些内存受限和I/O受限的HPC(High Performance Computing)应用在性能方面的影响,发现NUMA(Non Uniform Memory Access)对性能有显著影响,必须通过进程绑定和尽可能保持数据本地存储来保持数据局部性。Yang等人[5]使用基准程序测试了Intel持久内存的延迟和带宽,并提出了一系列可实践操作的指南。Akram等人[6]分析了Java负载在持久内存上的性能可扩展性。Mason等人[7]发现持久内存在局部性上比DRAM 更敏感,使用持久内存的大页面的 Linux 策略提供了更好的 TLB 和页表局部性,可以有更好的性能。Patil等人[8]评估了DRAM和持久内存混合内存系统的功能及其对高性能计算应用程序的影响,还在持久内存的不同配置下测试了多个 HPC 迷你应用程序的性能。以上工作基本上都是基于Intel第1代持久内存来开展的,本文分别基于两代Intel持久内存和DRAM内存进行一系列实验,面向CFD领域3种常见算法进行性能评估。
3 持久内存
字节可寻址持久内存是一种非易失性存储器(即断电后数据仍然存在),并且可以同时由 CPU 通过加载和存储操作直接寻址。Intel的傲腾数据中心持久内存DCPMM产品是一种基于 3D XPoint技术[9]的字节可寻址持久内存。3D XPoint于 2015 年被提出,是一种新型内存技术,其性能与传统的主存相当,但是容量要远远高于DRAM;它的容量可与SSD相比,但是速度与耐用性要高出数个量级。
持久内存与DRAM使用相同的硬件接口,与标准 DRAM 模块一起位于 CPU 旁边的 DIMM 插槽中,与内存总线上的 DRAM 共存,既可以用作 DRAM 的替代品,也可以用作高性能和低延迟的存储设备。当前DCPMM提供了3种不同大小的容量(128 GB、256 GB和512 GB),与 DDR4 DRAM 相比,容量(每个模块)增加了约 5~10 倍。尽管 DCPMM 比 DRAM 慢,但与仅使用 DRAM 的解决方案相比,它提供的每个节点的内存容量要高得多。 DCPMM 不能完全取代 DRAM:每个内存通道(每个CPU有6个内存通道,每个内存通道有2个DIMM插槽)必须至少填充一个 DRAM DIMM。
DCPMM 可以在2种主要平台模式下运行:内存模式和App Direct 模式。
(1)内存模式:连接在同一个集成内存控制器上的DRAM会作为持久内存的缓存工作。该模式下DRAM无法直接访问,而是作为持久内存在直接映射缓存策略下的可写回缓存,持久内存作为大容量易失内存使用。DRAM作为缓存命中时,性能可以与DRAM相当;但是不命中时,开销为DRAM的访问开销加上持久内存的访问开销。其最大的优势是用户程序不需要经过任何修改可直接运行,应用没有移植成本。
(2)App Direct模式:持久内存作为可持久化的存储设备使用,该模式下持久内存和相邻的DRAM都会被识别为操作系统可见的内存设备,持久内存是与DRAM分离的持久化设备,DRAM则用作主存储器。持久内存上部署文件系统后,其访问时间比常规存储设备(如SSD)的访问时间短得多。其缺点是,用户需要使用相应的编程模型规范对持久内存进行应用程序的编程,会有代码修改的人力成本。
本文基于Intel第1代(Intel 100系列傲腾持久内存,代号Apache Pass,简称AEP)和第2代DCPMM(Intel 200系列傲腾持久内存,代号Barlow Pass,简称BPS)进行实验。AEP与第2代Intel至强可扩展处理器家族Cascade Lake同时发布于2019年4月,可与Cascade Lake及之后发布的处理器搭配使用,单路CPU最多可支持6通道、3 TB持久内存,加上DRAM,则单路CPU最高配置主存为4.5 TB。BPS发布于2021年,需与第3代Intel至强可扩展处理器搭配使用,与前一代相比,虽然单条容量不变,但是单路CPU可配置的容量和性能均大幅提升,最多可支持8通道、4 TB持久内存,主存最高容量为6 TB。
4 测试应用介绍
CFD应用核心内容是对偏微分方程组进行求解,求解的方法有显式求解、隐式求解和通过粒子模拟的直接求解等,本文面向这3种基本求解方法分别进行性能测试。
为了比较持久内存对不同CFD算法性能的影响,本文选用了STREAM基准测试[10],CloverLeaf[11]和TeaLeaf[12]2个迷你应用以及基于DSMC (Direct Simulation Monte Carlo)[13]的真实应用进行测试。其中,STREAM对内存带宽进行基准测试,CloverLeaf是显式求解方法,TeaLeaf是隐式求解方法,DSMC是直接模拟的粒子方法。
4.1 STREAM
STREAM是一个简单的用于测试可持续访存带宽的综合基准测试程序,由4种不同算术操作表征,分别是Copy、Scale、Add和Triad。STREAM最多使用3个数组和1个标量进行上述基本算术,通过控制数组维度决定数据大小,可以实现不同数据量的内存带宽测试。本文使用Triad操作测出的带宽,即a[j] =b[j]+scalar×c[j],作为测试基准。
4.2 CloverLeaf
CloverLeaf 是一个基于笛卡尔网格显式求解可压欧拉方程的迷你应用程序,基于交错网格进行物理量存储,即每个单元格存储3个值:能量、密度和压力,速度向量存储在每个单元格角。求解时遍历每个单元格,使用Stencil操作更新物理量,在大部分架构下其性能受限于访存带宽。本文使用bm4(网格规模1920×1920,数据量约0.7 GB)、bm16(网格规模3840×3840,数据量约2.8 GB)和bm64(网格规模7680×7680,数据量约11 GB)3个算例。
4.3 TeaLeaf
TeaLeaf是在分解的二维和三维规则空间网格上,借助五点与七点有限差分 Stencil计算方法,使用隐式求解器来解决线性热传导方程的应用程序,TeaLeaf使用 Chebyshev求解器作为预处理器,将CG(PPCG)作为求解器的具体方法。本文使用bm2(网格规模250×250,数据量约56 MB)、bm4(网格规模1000×1000,数据量约230 MB)和bm5(网格规模4000×4000,数据量约2.8 GB)3个算例。
4.4 DSMC
DSMC算法是一种基于统计学的流场数值仿真程序,基于Boltzmann方程模拟仿真粒子。它用大量的模拟分子代替真实气体分子,并用计算机模拟分子的运动和碰撞过程,最后通过统计模拟分子的运动状态得到流体的宏观量。这种直接模拟方法极大简化了计算模型,从而使计算过程得到简化。同时,由于对分子的移动和碰撞进行了解耦,因此在碰撞计算中可以引入各种碰撞模型,极大地扩大了DSMC方法的适用范围。DSMC对访存带宽和延迟均有一定要求。由于DSMC是对粒子进行模拟,对计算量和数据量均有极大的需求,本文基于DSMC对大数据量(100 GB以上)的算例进行测试。
5 测试平台
本文分别基于AEP和BPS进行测试,AEP服务器配置双路Intel(R) Xeon(R) Gold 6248R CPU,12条32 GB 2 666 MT/s DRAM内存和12条AEP 128 GB持久内存,BPS服务器配置双路Intel(R) Xeon(R) Gold 6338 CPU,16条32 GB 2 933 MT/s DRAM内存和16条BPS 128 GB持久内存,具体硬件参数如表1所示,所有测试算例均运行于单节点。2台服务器使用相同的软件环境配置:操作系统版本为CentOS Linux 7.7,编译器使用Intel Parallel Studio 2020。
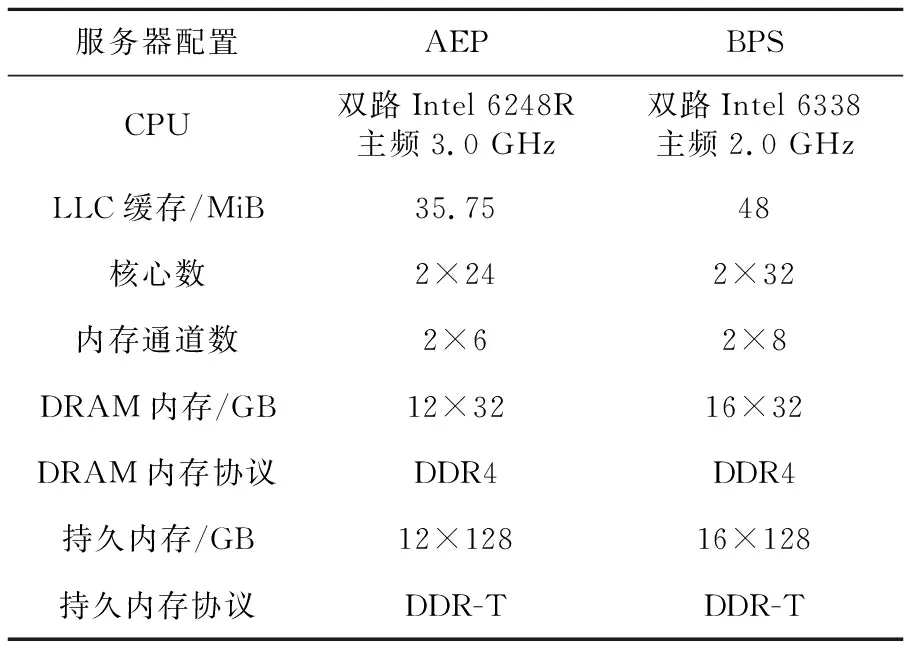
Table 1 Testing platform environment configuration
6 实验与结果分析
对于AEP服务器和BPS服务器,本文分别基于配置了持久内存的内存模式和不配置持久内存的纯DRAM模式进行一系列实验,以对比持久内存对应用性能的影响。在测试使用纯DRAM的性能时,采用拔掉相应服务器持久内存的方案,文中仍称为AEP/BPS服务器,图中以AEP_DRAM/BPS_DRAM指代。
6.1 基准测试结果
本文用STREAM基准测试测试了DRAM和两代傲腾持久内存的访问带宽,STREAM基准测试中,会对所有内存操作重复20次后取平均值。
6.1.1 NUMA访存影响
从已有研究结果[4]可知,NUMA对持久内存性能影响较大。本文通过numactl命令进行内存和CPU的绑定,分别测试单CPU访问同socket内存和跨socket内存时的带宽,结果如图1所示。可以看到,无论是AEP还是BPS,单CPU跨socket访问对带宽的影响都非常大,访存带宽降低50%左右。
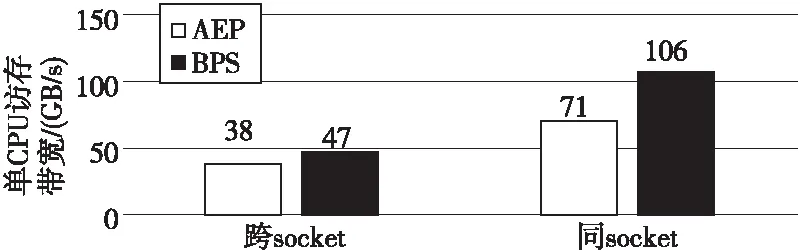
Figure 1 Performance impact of NUMA图1 NUMA访存影响
6.1.2 持久内存和DRAM的带宽比较
图2展示了节点整体访存带宽,这里设定的数据量大小约为2 GB,对于持久内存节点,该数据量远远小于作为缓存的DRAM容量,然而,持久内存节点的访存带宽均显著低于DRAM的,约为后者的70%,因此可以推断,对于有访存限制的应用,在内存模式下,数据量即使小于配置的DRAM内存,性能也会受到一定影响。由于通道数和内存频率的提升,BPS的带宽比前一代AEP的访存带宽有显著提高,纯DRAM方案和持久内存方案带宽均提升约50%。

Figure 2 DRAM bandwidth vs PMEM bandwidth图2 DRAM带宽与PMEM带宽
6.1.3 不同数据规模的访存带宽
图3和图4分别展示了DRAM和持久内存在不同数据规模下STREAM带宽的测试结果。对于DRAM,在其容量范围内,改变数据规模基本上对带宽没影响,而对于持久内存,测试出来的带宽会随着测试的数据规模的增大而减小,这意味着随着数组增大,配置持久内存的服务器实际访存性能会降低。因此可以推断,对于带宽敏感的应用,不管是AEP还是BPS,数据量增大以后,持久内存的测试性能都会受到影响。

Figure 3 Bandwidth of DRAM under different data size图3 不同数据规模DRAM的带宽
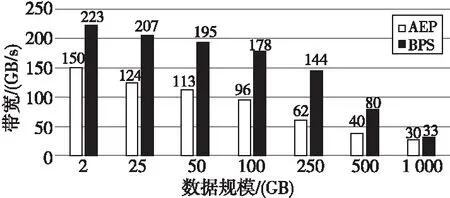
Figure 4 Bandwidth of PMEM under different data size图4 不同数据规模持久内存的带宽
6.2 CloverLeaf测试结果
CloverLeaf采用显式求解算法,其核心部分是Stencil算法,该算法对带宽的依赖比较大。本文基于OpenMP并行版本测试了不同算例的结果,其扩展性如图5和图6所示,纵坐标为同线程数下CloverLeaf在持久内存和DRAM上的相对性能。线程数较小时,DRAM和持久内存的性能差异不大,随着线程数的增加,二者性能差异有稍微增加的趋势,对于AEP,性能差异最大时,持久内存性能约为DRAM的85%,对于BPS,其与DRAM的性能差异则更小,大部分在90%以上,最大差异为87%。
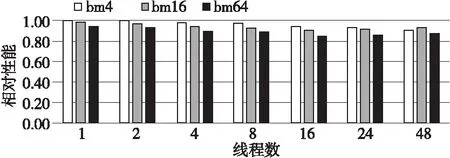
Figure 5 Performance comparison of AEP PMEM and DRAM based on CloverLeaf图5 基于CloverLeaf的AEP持久内存与DRAM性能比较

Figure 6 Performance comparison of BPS PMEM and DRAM based on CloverLeaf图6 基于CloverLeaf的BPS持久内存与DRAM性能比较
对于同样的算例,在都采用服务器所有核心运行的情况下,本文对比了不同配置下的相对性能,如图7所示,这里以AEP服务器的纯DRAM性能为基准进行比较。相比AEP,BPS的性能有了显著的提升,对于纯DRAM方案,性能提升了30%~40%,对于持久内存方案,性能提升了40%以上。

Figure 7 Performance comparison of BPS and AEP图7 BPS与AEP性能比较
6.3 TeaLeaf测试结果
TeaLeaf采用隐式求解算法,对延迟和带宽有一定要求。本文选用3个小数据量(最大2.8 GB)的算例进行测试,不同算例的扩展性结果如图8和图9所示,持久内存和DRAM的性能差异较小,对AEP来说,差异最大的算例,性能为DRAM的92%,对BPS来说,几乎所有算例的性能均与DRAM的差不多。

Figure 8 Performance comparison of AEP PMEM and DRAM based on TeaLeaf图8 基于TeaLeaf的AEP持久内存与DRAM性能比较

Figure 9 Performance comparison of BPS PMEM and DRAM based on TeaLeaf图9 基于TeaLeaf的BPS持久内存与DRAM性能比较
对于TeaLeaf,在都采用服务器所有核心运行的情况下,不同配置下的性能对比如图10所示,对于规模较小的bm2算例,相比AEP,BPS的性能有所下降,本文认为这是因为规模较小时,可扩展性较差,BPS服务器具有64核心,而AEP服务器是48核心,对于规模相对较大的bm4算例和bm5算例,BPS服务器性能提升约20%~30%。

Figure 10 Performance comparison of BPS and AEP based on TeaLeaf图10 基于TeaLeaf的BPS与AEP性能比较
6.4 DSMC测试结果
DSMC是基于粒子网格方法的CFD算法,可以获得高精度的模拟结果,对计算量和存储的需求均十分庞大,本文基于真实的DSMC应用进行测试,单节点数据量在100 GB以上,线程数较少时难以进行测试,因而使用节点内的所有CPU核心计算,并通过调节每个网格的粒子数,来调整每个节点的数据量,最大规模数据量达到了1 TB。
不同配置下的性能对比如图11所示,该算例占用内存的数据量约为130 GB,对于该算例AEP和BPS性能差距不大,在5%以内。本文认为,这是因为相对于CloverLeaf和TeaLeaf这种对访存性能敏感的程序,DSMC在算法上具有更高的计算/访存比,对访存的性能相对没有那么敏感。
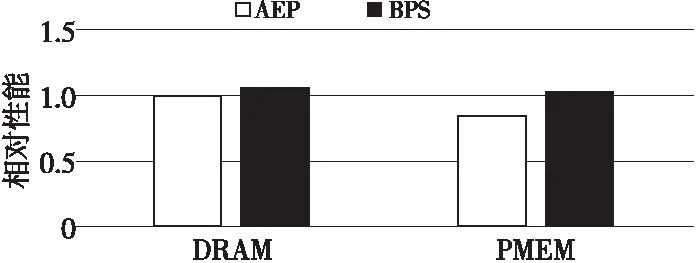
Figure 11 Performance comparison of BPS and AEP based on DSMC图11 基于DSMC的BPS与AEP性能比较
为测试大规模数据对性能的影响,本文在BPS节点上进行了不同数据量的测试,并以纯DRAM运行的时间为基准进行对比,结果如图12所示。对于DSMC,数据规模较小时,持久内存和DRAM性能相差不大,但随着数据规模的增大,运行时间显著增加,且增加比例大于数据量增加的比例,与DRAM的性能差异也显著增加,访存性能对程序整体性能的影响加大,与前面的STREAM测试结果类似。数据量为260 GB时,持久内存性能为DRAM的67%。另外,持久内存可以支撑1 TB以上数据量的算例运行,而该算例的DRAM方案则因内存不足而无法测试。

Figure 12 Comparison of running time of BPS PMEM and DRAM under different data sizes图12 不同数据量下 BPS PMEM与DRAM的运行时间对比
7 结束语
本文面向常见CFD算法对Intel傲腾持久内存进行了性能测试,评估持久内存2种使用模式中最易于使用的内存模式对CFD应用的性能影响,并对比了两代傲腾持久内存的性能差异。通过STREAM基准程序,测试了持久内存在不同数据规模下的带宽,并发现配置持久内存后访存带宽随数据规模的增大而降低,而纯DRAM的测试带宽则几乎不受影响。
在此基础上,本文还测试了3种常见的CFD算法。对于CloverLeaf和TeaLeaf 2个迷你应用,本文基于小规模数据量的算例进行了不同计算配置的性能对比,结果显示,在该数据量下,对于这2种迷你应用所代表的CFD计算模式,持久内存的引入会带来性能少量下降,性能损失在20%以内,而数据量越小,带来的性能损失也越小。对于计算/访存比相对较大的DSMC算法,在数据量达到100 GB时持久内存的引入也不会带来显著性能损失,但是当数据量进一步增大,对访存性能要求增加时,持久内存的性能会显著低于纯DRAM的性能,在260 GB的数据量时二者性能差距在30%以上。另一方面,当数据量再增加时,DRAM由于容量不足而无法支撑计算,持久内存则可以支撑TB级数据量的数值模拟。
因此,对于CFD应用,基于内存模式的持久内存方案,最大的优势是在不增加移植成本的情况下,提供大容量的访存方案。但是,该模式难以适用于所有算法和数据规模。在算法选择上,持久内存适合于计算/访存比较高的计算模式,而对于访存带宽受限的求解模式,随着数据量的增加,持久内存方案性能会有较大损失,其大内存容量的意义则大打折扣。
对比第1代Intel傲腾持久内存,基于第2代持久内存的配置方案由于访存性能有了显著增加,不管对于STREAM基准测试还是实际的CFD应用,性能大部分都有约20%~50%的显著提高。
本文对内存模式下的CFD常见算法进行了性能测评,在后续的工作中,将主要进行以下3方面的工作:(1)对App Direct模式下的性能进行评测;(2)在本文的实验结果中,内存模式下即使数据量远远小于作为缓存的DRAM容量,访存带宽也会显著低于纯DRAM配置,将通过一些性能分析工具,深入分析其中机理;(3)结合DSMC算法和持久内存模式性能特征,对DSMC真实算例进行性能优化。
