钻井工况智能识别与时效分析技术
2022-09-21胡志强杨进王磊侯绪田张桢翔姜萌磊
胡志强 杨进 王磊 侯绪田 张桢翔 姜萌磊
1.中国石油化工股份有限公司石油工程技术研究;2.页岩油气富集机理与有效开发国家重点试验室;3.中国石油大学(北京)安全与海洋工程学院
随着大数据分析、人工智能决策技术在石油行业的应用,数字化油气勘探开发技术显著提高了现场施工作业效率[1-3]。目前钻井施工作业平均时效仅70%,现场无法大规模利用录井数据实时监测钻井作业工况,钻井时效分析主要依赖于现场仪器的传输效率和作业人员的经验诊断,存在无法处理大量实时施工数据、决策反馈机制慢、预测精度低等问题[4-6]。许多学者针对利用综合录井数据辅助施工决策进行了大量研究,吴俊杰等[7]提出利用模糊理论构建多事故知识库,从而实现对钻井工程事故进行预警的新设计思路;徐术国等[8]总结了大量油田现场数据资料,编制了基于录井数据的钻井事故专家预测系统;孙挺等[9]建立了一种基于支持向量机的钻井工况识别方法,优化模型参数;但目前由于缺乏钻井数据的实时反馈,导致钻井工况识别、时效分析精度差,因此有必要利用钻井过程记录的大量录井数据,开展钻井作业工况自动识别和钻井时效智能分析,实现录井资料与后台服务器数据实时传输和反馈,完成现场钻井数据的自动识别与采集,协助钻井工程人员优化施工方案。
1 标准数据传输接口开发
在油气井场信息数据服务领域,各大石油服务厂商开发了大量不同标准的数据传输与转换格式。国际钻井承包商协会(简称IADC)规定了统一的井场数据传输格式来解决传输标准问题,定义为井场信息传输规范(简称WITS)[10];随着技术的发展,在WITS技术的基础上又发展出了井场信息传递标准标记语言(简称WITSML)[11]。目前,各大石油公司均开发了基于WITS和WITSML两个传输标准的井场数据传输通讯系统。
1.1 基于TCP/IP协议的Socket通信方式
基于TCP/IP协议的Socket通信方式具有性能稳定、传输功能完善等优势,能满足井场数据传输的需求。Socket通信方式采用客户端/服务端模型实现进程间的通信,建立遵循TCP/IP协议的“三次握手”双向通信模式,其建立过程包括客户端建立初始连接、监听客户连接请求并进行确认、确认报文、客户端与服务器端进入连接状态。
1.2 WITS 标准
WITS在石油行业中是应用最为广泛的传输协议。在WITS预定义数据中使用钻机动作和频率产生间距两个标准,将每种工况进行组合,共定义了24个记录,如表1所示。记录1以时间为基础,可以根据实际需求调整时间间隔;记录2以井深为基础,频率为每米产生一个数据。

表1 WITS 预定义数据描述Table 1 Data description pre-defined in WITS
1.3 WITSML标准
WITSML在WITS标准的基础上,融合了可扩展标记语言(简称XML)在数据通信上的优点,其核心包括数据架构和应用程序接口两个部分。现场录井数据通过WITSML标准封装成XML文档,每个数据都具备相关对象属性。开发了基于WITSML标准的井场数据传输软件,其开发流程见图1。
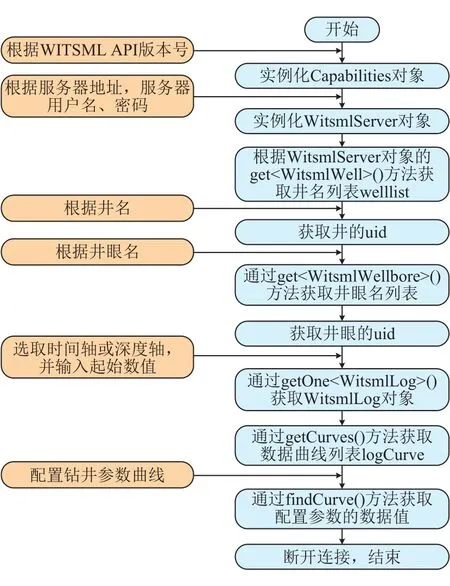
图1 基于WITSML标准的井场数据传输流程Fig.1 Wellsite data transfer flow based on WITSML
2 钻井工况智能识别算法
2.1 钻井工况选取
在开发完成满足WITS和WITSML标准数据接口后,通过软件实时获取现场井场录井资料。常规钻井施工主要包括组合钻具、下钻、钻进、循环、短起、划眼、起钻、下套管、固井、电测、下防喷器、安装井口等工序,本文主要针对录井系统能监测的11个钻井主要工况进行研究分析,其余工况归入其他,钻井工况选取如表2所示。
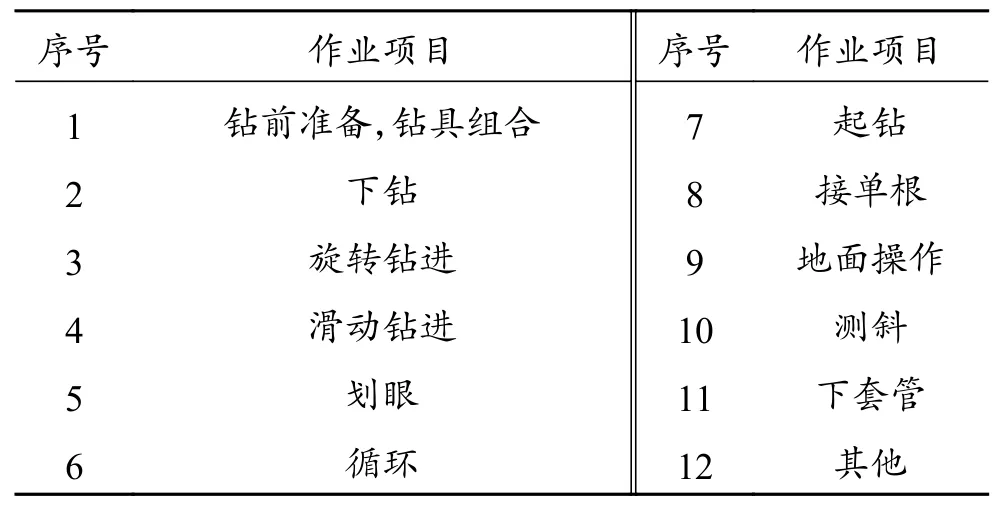
表2 钻井工况识别Table 2 Drilling operation condition identification
2.2 阈值法工况识别模型
目前钻井工况识别主要依靠人工经验结合录井数据变化趋势进行判断,识别效率不高,采用阈值法预先设定判断数值诊断录井传输的实时数据,提高工况识别精度。阈值法工况识别模型首先需要确定诊断的录井实时参数,保障工况识别的精度,排除多工况下参数冗余的情况;其次需要确定阈值范围,由于井场传输数据存在波动误差,阈值需要根据实际录井参数确定;最后根据选取的录井参数和阈值范围确定所需采用的条件判断树。本文采用霍夫曼树优化判断流程,确定各个节点的权重,构造钻井工况识别的霍夫曼树(图2)。

图2 钻井工况识别的霍夫曼树Fig.2 Huffman tree for drilling operation condition identification
2.3 神经网络法工况识别模型
目前,利用BP神经网络的非线性映射属性能较好地对钻井工况进行区分识别,其主要运算程序包括样本数据读取、样本数据标记、神经网络训练、数据样本识别、结果精度校对。图3为采用神经网络测试的一组钻进工况识别数据,可以看出该段钻头位置经历了多次上提、下放乃至停止状态,说明钻进过程不通畅,频繁划眼、循环,判断钻遇复杂地层或者出现卡钻事故。相比于阈值法“非黑即白”的逻辑树判断,神经网络通过多层次节点的工况识别,可以输出最大概率的工况特征,提高非常规录井参数的识别度。

图3 神经网络工况识别结果Fig.3 Operation condition identification results, based on the neural network method
2.4 钻井工况智能识别算法融合
为进一步提高钻井工况的识别精度,充分发挥上述两类算法模型的优势,采取算法融合的方式进行钻井工况智能识别。首先采用两种方法分别对录井数据进行工况识别,当两者识别结果1和2相同时,直接输出识别结果;而当两者结果不一致时,需要判断识别结果1是否为“其他”,如果是,则直接输出识别结果2;如果判断识别结果1不为“其他”,则需要判断识别结果2的概率是否大于0.5,如果是,则直接输出识别结果2,如果不是,直接输出识别结果1。其算法融合逻辑如图4所示。

图4 算法逻辑图Fig.4 Algorithm logic
3 钻井时效历史数据分析
目前钻井时效分析主要依靠录井数据和钻井日报进行人工计算,效率低下,精度欠缺。通过钻井工况的智能识别,建立包含井场信息数据和单井工况识别结果的历史数据表(见表3)。

表3 钻井时效分析历史数据Table 3 Historic data for drilling time-efficiency analysis
编制软件对录井历史数据进行划分,统计钻井总工作时间和单项工况耗时,从而计算钻井时效
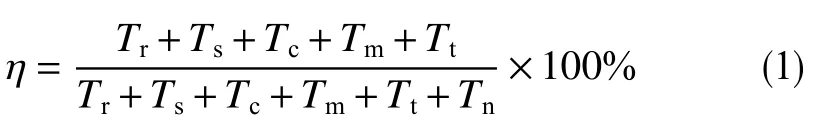
式中,η为钻井时效,无因次;Tr为旋转钻进时间,h;Ts为滑动钻进时间,h;Tc为循环时间,h;Tm为接单根时间,h;Tt为起下钻时间,h;Tn为非生产时间,h。
4 实例应用
根据上述研究成果,开发了多个模块处理的钻井工况智能识别和钻井时效分析的软件,其总体设计采用底层数据库、中间逻辑层和顶层操作层的3层结构,如图5所示。数据层是整个软件的基础,主要包括录井数据库、时效结果库、地层参数库、账号信息库和井场信息库等;逻辑层是整个软件的核心,主要包括录井数据实时传输模块、原始数据处理模块和数据结果输出模块;操作层是整个软件的可视化界面,主要包括数据传输界面、工况识别界面、时效分析界面以及系统管理界面等。

图5 软件总体设计图Fig.5 Overall software design
利用研发软件对我国渤海某一口海上油井进行测试应用。首先需要将软件中的录井数据实时传输模块与中海油研发的DiscoveryWeb系统进行调试连接,配置好相对应的数据参数,查看读取后的录井数据格式,并绘制录井钻头位置、大钩高度、扭矩、钻压等参数的图像曲线,图6为钻头位置与时间关系曲线。

图6 钻头位置随时间变化关系曲线Fig.6 Bit location vs.time
其次进行钻井工况的智能识别,其分析结果如图3所示。现场钻井工程师根据录井智能识别曲线进行工况分析与判断,再读取钻井日报中的钻井真实工况和时间占比,进而判断智能识别的预测精度,如表4所示。

表4 钻井工况识别精度结果Table 4 Identification accuracy for drilling operation conditions
分析完钻井工况后,进入软件钻井时效分析界面,统计该井当前所有工况下的时间占比。同时数据库中收录该区块其他井次相同工况下的钻井时效,便于工程人员对比分析,如图7所示,结果显示钻井单个时效统计误差在5%以内,钻井时效误差为0.27%,验证了智能算法的准确率。
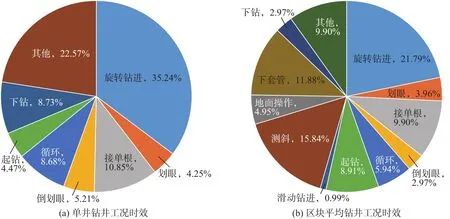
图7 钻井时效分析结果Fig.7 Drilling time-efficiency analysis results
5 结论
(1)开发了基于WITS标准和WITSML两个标准的数据传输模块,针对录井系统能监测的11个钻井主要工况进行研究,创建了将阈值法和神经网络法相结合的融合算法模型,提高了工况识别精度。
(2)研发了具有录井数据传输、钻井工况识别、钻井时效分析等功能的钻井工况识别和时效分析软件,应用结果显示钻井工况智能识别与实际工况情况基本符合,平均预测精度大于95%,钻井时效统计误差在1%以内,应用效果良好。
(3)钻井工况识别和时效分析软件实现钻井数据的实时反馈、有效地提高了工况识别的效率,能够更好地帮助施工人员优化钻井参数、合理安排进度,对实现钻井数据的自动采集、远程传输和智能决策具有重要意义。
