基于 “大数据+小数据” 的智慧图书馆用户精准画像模型构建
2022-09-20程光胜宁夏财经职业技术学院信息与智能工程系
程光胜(宁夏财经职业技术学院信息与智能工程系)
1 智慧图书馆及用户画像研究综述
1.1 智慧图书馆研究综述
在以 “智慧” 为主题的时代背景下,智慧图书馆的研究和建设已成为图书情报领域关注的热点,但目前关于智慧图书馆的内涵,还没有统一的界定。曾强等认为,智慧图书馆是有感知的,通过智能化技术的感知为用户提供高效、精准的服务,这种服务是建立在智慧图书馆具备分析、判断、思考和创造的服务能力基础上的[1]。石婷婷等认为,智慧图书馆是图书馆发展的高级阶段,并从感知、要素、人文、哲学等不同视角对智慧图书馆的定义进行了综述,得出智慧图书馆是以人为本的可持续发展和高品质服务的一种新模式[2]。吴建中等认为,智慧图书馆是建立在数字化图书馆基础上的,是一种高度智慧化的知识服务体系,是一个 “以人为本” 的线上与线下、虚拟和线上融合的新业态,凸显 “使用和增值”[3]。从这些研究可以看出,智慧图书馆是在物联网、大数据、人工智能等新一代智能技术的赋能下,实现图书馆的全要素智慧化建设和转型,体现 “以人为本” 的个性化、精准化和泛在化的智慧服务。同时,也有文献从逻辑方法、服务模式等角度对智慧图书馆进行了论述。总之,无论是智慧图书馆的理论研究还是业界实践,目前都处于探索阶段。
1.2 图书馆用户画像研究综述
用户画像的概念由Alan Cooper等提出[4],是指建立在真实数据基础上的用户模型,是用户信息的标签化表示,是智慧图书馆用户研究的有力工具,最近几年在电子商务、教育、公共服务等领域得到广泛应用。用户画像本质是研究用户、探求用户真实需求、对用户进行信息分析的过程,通过分析,准确定义、描述和刻画用户特征,为用户提供更加精准和个性化的服务。
赵建建在用户画像模型设计的基础上,从用户数据入手,建立用户标签体系,通过TF-IDF算法以及聚类分析全方位阐述了个体用户画像和群体用户画像的生成过程[5]。廖运平等将智慧图书馆的用户画像按照应用目的划分为面向设计的用户画像和面向营销的用户画像,并从内涵特征、需求分析、创建方法、创建步骤等方面阐述了两类用户画像的区别及生成过程[6]。杨倩为了精准分析与预测用户需求,选取用户、资源和服务三个维度,并分别创建标签内容表,运用聚类算法分组用户,构建了基于需求深度和资源广度的差别化用户群组画像[7]。肖海清等提出并构建了基于参与视角的用户画像,并将其应用到图书馆阅读推广领域[8]。于兴尚等从用户认知维度提出图书馆用户画像系统模型,旨在契合图书馆用户信息轨迹,改善用户认知需求质量,缩小认知差距[9]。李晓敏等以智慧图书馆的图书推荐为目的,从自然属性、兴趣属性、社交属性三个维度构建了用户画像,并实证了该用户画像能够提升个性化服务能力,达到精准推荐的效果。[10]
上述文献侧重从图书情报领域构建用户画像,最终目的是实现图书资源的精准推荐和个性化服务,但是在构建维度上略有差异,运用的算法、流程以及方法不尽相同,这为本文提供了很好的思路。然而,用户画像的构建需要依赖大量用户数据,如何从数据科学的角度,发挥数据的最大价值并构建用户精准画像,现有文献却很少涉及。因此,本文将用户数据分为用户 “小数据” 和用户 “大数据” ,根据小数据和大数据的特点构建精准的用户画像和群体画像,并通过精准画像为用户提供智慧服务。
2 基于小数据构建用户精准画像
2.1 大数据时代下的小数据及其优势
这里的用户 “小数据” 是指个体数据,用其构建用户画像能够 “见微” ,用户 “大数据” 是指全量数据,反映群体特征,用其构建群体画像能够 “知著” 。在用户画像中,通过综合运用 “大数据+小数据” ,既能以小带大、小中见大,又能抓大放小、以大兼小,充分发挥大小数据的优势,让大数据体现规律、小数据蕴含智慧。大数据时代下的小数据是一类新型的数据,并不是数据量小,而是围绕个体的全方位数据,对外形成一个富有个人色彩的数据系统,具有鲜明的个体独特性、复杂多样的数据特性、高度的实时动态性和明显的人机交互性。[11]
数据多未必就是大数据。对于单个图书馆而言,现有的数据量映射到全体用户上是很稀疏的,难以反映特定的相关关系和规律,因此围绕单个用户的小数据分析可能更具优势。小数据的数据体量有限、相关性强、价值密度高,关注个体的特殊性,而非总体的普遍性,数据的获取、处理和分析成本很低,能够准确描述个体的特征和行为,体现其个性化阅读及知识需求,为图书馆个性化智能服务决策制定和模式构建提供有力支撑[12]。而大数据分析采用全样本方法,得到的结果是一般化的共性,用户的个性化需求完全被忽略,将其应用到智慧图书馆的 “智慧” 服务中,难以让个体用户满意。
2.2 用户小数据类型及其获取
获取用户小数据是实现用户精准画像的基础,一般包括用户表达和行为感知两个方面[13]。前者是用户需求的直接反映,如用户的借阅行为、文献的查阅、对特定主题的评论反馈等,这些可以视作外表特征,是用户自身可以表达的;后者需要借助特定的技术或设备去感知,如特定时空维度下的行为轨迹感知、基于用户情境的社交行为感知等。与其他数据来源相比,智慧图书馆下的用户小数据除了能够记录和反映用户的行为及喜好等特征外,还能记录用户的心理、生理、思想、情感和文化等特征,并将这些特征进行量化表示,以便绘制更加精准的用户画像。
刘庆麟认为,用户小数据由个体特征数据、读者体验数据和社会化及共享数据构成[14]。陈臣等根据画像的需要,将图书馆用户小数据划分为读者特征数据、用户生成数据和阅读相关数据,其中的阅读相关数据具体为阅读情景数据、阅读行为数据、阅读心理数据、阅读社会关系数据[15]。刘扬等将用户个人小数据分解为用户基本数据、用户行为数据、科研协同数据和情景数据[16]。综合以上分类并根据本文的研究需要,笔者将智慧图书馆环境下的用户小数据划分为用户特征数据、用户场景数据、用户行为数据以及用户情感数据。
用户特征数据反映用户的人口统计属性,包括用户在注册或个人信息维护时填写的姓名、性别、文化程度、专业方向、关注领域等,属于静态数据,一般不会发生变化;用户场景数据反映用户使用图书馆的位置空间变换,线上可以通过网络IP地址、移动终端传感设备,线下可以通过智慧图书馆内的视频采集设备等途径采集;用户行为数据反映用户使用图书馆过程中执行的各种操作,如图书借阅、文献下载、主题词查询、观看音视频资源、资源评论等,记录了用户使用图书馆时留下的操作痕迹;用户情感数据反映用户在使用图书馆过程中的情感变化,有显性和隐性之分,显性可通过智能设备采集和感知,隐性可借助智能技术深度挖掘和分析获取,是用户小数据很重要的组成部分。过去囿于技术和设备,情感数据在研究中一直被忽视,近年来随着机器学习、人工智能等技术的深度应用,情感数据已经引起不同领域研究者的极大关注。
图书馆中的用户小数据可能分散于各个子系统和不同的数据节点。不同的子系统由于产生数据的方式和环境的不同,其数据类型和存储方式呈现多样性,如用户的基本信息、查询信息、借阅信息等结构化数据属于信息系统常规的数据和操作,而对用户行为的跟踪和记录等半结构化或非结构化数据一般由系统自动生成,主要采用文本、XML文件等存储。另外,还有一部分数据由各种传感器生成,如位置定位、心理生理指标等,属于行为感知数据,这类数据一般也属于半结构化或非结构化数据。针对结构化数据,在存储时可采用基于SQL的关系型数据库,而对半结构化或非结构化的数据,则需借助基于NoSQL的非关系型数据库实现,比较有代表性的有键值对型(如 Redis、Riak等)、文档型 (如 MongoDB、CouchDB等)、列存储型(如HBase、Cassandra等)和图形(如 Infinite Graph、Neo4J等)。因此,从这些不同的子系统和数据节点获取用户小数据时,就需面临如何来获取以及获取后如何整合等问题,获取的完整性和整合的一致性直接影响用户画像的精准性。目前,已有成熟的API和第三方工具用于获取不同存储环境下的数据,在整合时需要对数据进行清洗,如补充缺失值、剔除异常值、删除重复值等。
2.3 构建用户个体画像
为了建立用户精准画像,首先需要创建用户画像标签。有了上述用户小数据,用户画像标签可由经过数据处理和分析的用户小数据动态生成。具体生成过程见模型。
式(1)中,M表示用户画像标签,M={M1,M2,M3,M4},M1表示用户基本信息标签,M2表示用户场景信息标签,M3表示用户行为信息标签,M4表示用户情感信息标签。则

其中,i=1,2,3,4,j=1,2,……,n,n代表用户小数据的数据容量。aij为常量矩阵,表示因子载荷,Fj为相互独立且不可测的公因子,表示画像相关因子在整个用户小数据指标体系中的权重,εi为仅对该类画像标签有影响的特殊因子,在M的计算表达式中,F与εi相互独立。
用户画像就是用户信息、用户场景、用户行为和用户情感不同类别标签的集合,可以完整刻画用户在特定时间段内的综合表现。通过上述模型生成的用户标签并不是固定不变的,会随着用户行为、情感、场景等的变化而变化,这种变化可以通过模型进行刻画和描述,如果用P表示用户在某个时间点上生成的画像,那么引入时间变量t,P就是一个随时间t衰减的函数,具体见式(2)。

式(2)中,i=1,2,3,4,Ct为随时间t变化的衰减值,Ct∈(0,1],时间间隔越长,则Ct的取值越小,衰减越厉害。其计算公式见式(3)。

式(3)中,t为当前时间,t'为学习行为发生或画像模型生成的时间,α为衰减因子,其值可由专家根据经验给出或通过回归计算得到。
以时间作为X轴、以空间(位置)作为Y轴、以情感作为Z轴,生成立体化的用户个体画像(见图1)。
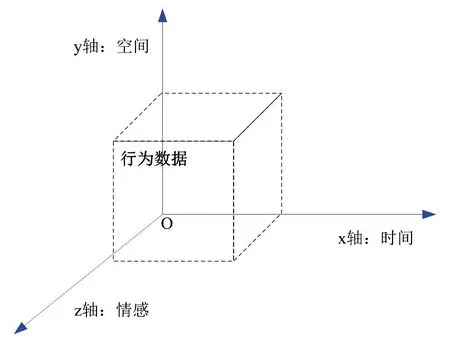
图1 立体画像描述
在时间上,可以分为(0:00,6:00]、(6:00,8:00]、(8:00,12:00]、(12:00,14:00]、(14:00,18:00]、(18:00,20:00]、(20:00,24:00] 七个时间段,用于探索用户的学习时间规律;在空间上,可以反映用户的位置变化,进一步了解用户在学习时是否经常集中于某个地点,以发现用户的特定学习模式;情感维度反映用户学习时的情感变化,与时间、空间维度不同的是,情感无法直接提取,需要借助文本分析、图像识别、视频挖掘等技术手段深层次分析获取。通过以上三个维度集中反映用户的学习行为,从而获取用户的关注领域、研究方向、资源偏好、操作习惯、网络互动等重要信息。
3 基于大数据构建用户群体画像
3.1 群体画像及其构建流程
图书馆的每个用户在学习过程中会与其他个体产生某种关联,从而形成特定的网络关系。利用用户小数据可以为每一位用户建立精准画像,但是会给系统带来极大的资源和计算开销,且个人用户画像在应用中也会受限。因此,为了减轻系统计算压力,提高用户画像应用的实际性,有必要利用图书馆积累的大数据建立用户群体画像。与个体精准画像不同,群体画像本质上是对用户进行分组,按照相似性原理将具有相似特征的用户群体组织成一个虚拟整体,并用特定标签对其进行描述。群体内的用户有很多共性特征,而群体之间的用户在某种程度上存在一定的差异,因此群体画像是一个将扁平化的用户数据经过不同的数据分析方法形成高度概括化和标签化画像的过程[17]。
为了推动知识交流和创新,也为了促进学科交叉和融合,本文以阅读兴趣为主题构建群体画像,构建流程见图2。群体画像使得群内具有趋同性,群内用户通过交流深化领域学习,不同群体画像具有外部互异常性,群间用户通过交流促进融合创新[18]。
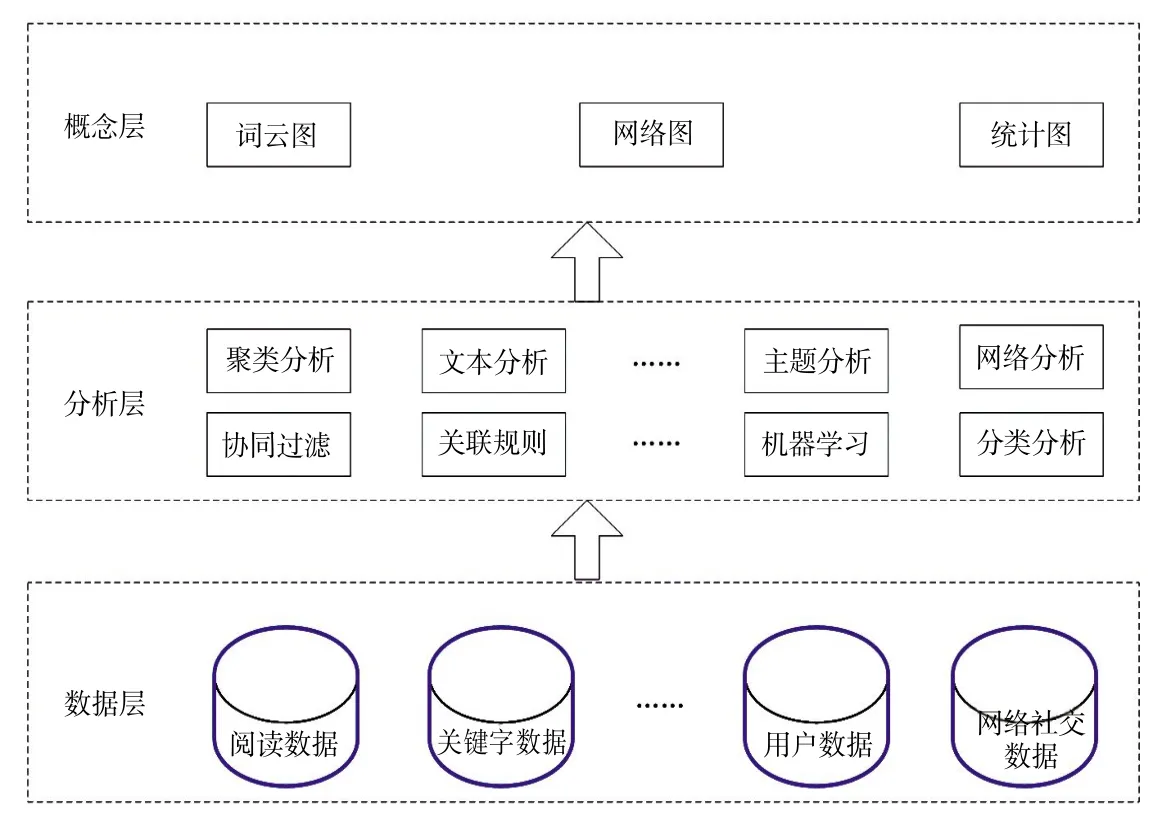
图2 群体画像构建流程
群体画像构建流程在逻辑上划分为数据层、分析层和概念层。数据层表示用户的各项数据,在群体画像中主要关注用户的各项行为数据,而这些行为数据一般是系统通过日志的方式记录下来的,默认为文本文件或XML文件格式;分析层按照特定需求对数据层的各项数据进行分析,典型的分析方法有聚类分析、文本分析、主题分析、网络分析等,通过综合运用这些方法,形成用户大数据与画像标签的关联;概念层是标签在特定用户群体上的可视化呈现,可以按照不同的时间段、不同的方式展示群体画像结果。
3.2 群体画像构建设计
根据图书馆用户的阅读和学习行为,笔者认为可从用户基本信息、学习兴趣和网络社交关系三个方面设计画像标签。用户基本信息可以显示画像群体人数、男女性别占比、学科专业分布、学历或职称结构分布等信息;学习兴趣反映画像群体关注哪些关键词,并以类似词云的方式呈现关键词热度;网络社交关系以网络图的方式显示用户和用户之间关于某一主题(话题)的讨论、评价等信息,或在某一段时间内共同学习了某个资源,或通过合作关系发表了某篇论文,或通过引证关系引用了其他用户的作品等。
在设计群体画像标签后,需要对用户数据进行整合处理。整合后将以用户ID为关键字,对应用户一段时间的所有文本信息,文本信息主要反映这一段时间用户学习的资源、搜索的关键词、发布的文本评论等。在此基础上,提取所有文本信息的关键词,通过关键词构建用户学习兴趣模型,并采用关键词共现网络的方式发现用户的共同学习兴趣,构建学习兴趣模型。
通过关键词共现网络,形成了基于关键词的词网络。关键词共现次数越多,说明用户关注的主题越相似,学习兴趣越大。在词网络的基础上,可借助社团划分算法划分用户群体。顾名思义,社团就是在网络中属性相似或角色相近的点集,而这里就是以关键词为中心形成的用户群体,群体内部连接紧密而群体之间连接松散。为了在复杂网络中有效划分社团而形成一系列有意义的社团结构,诞生了很多网络社团划分,如Girvan等提出的GN算法(分裂法)、Newman提出的FN贪婪算法(聚合法)、Blondel等提出的Louvain算法(聚合法)、Waltman等提出的SLM算法(聚合法)等。陈云伟等针对这些算法进行了比较研究,结果表明:GN算法时间效率低下,FN算法无法保证计算精度和计算效率,而Louvain算法、Louvain多级细分算法、SLM算法针对中小型数据集的划分效果较好[19]。
执行具体划分是一个数据量较大的计算过程,考虑到结果生成的非实时性、吞吐量、处理速度等因素,可以选择Spark实现对数据的处理和计算。同时,不论是处理的数据对象还是生成的群体画像对象,都可以采用基于文档的MongoDB数据库实现存储管理。在搭建技术平台时,可以选择Spark+MongoDB的大数据技术管理平台实现群体画像的计算处理和存储。
4 智慧图书馆用户画像的应用
用户画像的目的是为智慧图书馆的个性化推荐系统提供智能化支持,为单个用户和群体用户提供个性化资源推荐,实现用户和资源之间精准映射。用户画像的结构关系见图3,从图3可以看出,用户画像是个性化推荐的基础,个性化推荐系统是推荐的核心,推荐系统需要与用户画像、馆藏资源同时交互,从而产生针对用户个体和用户群体的不同推荐。
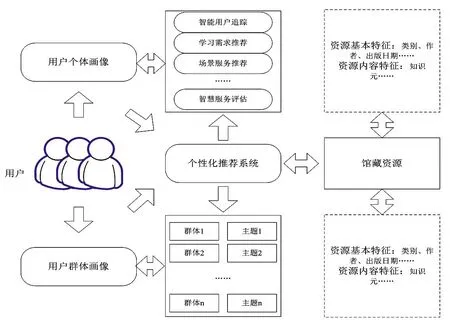
图3 用户画像应用
(1)学习需求推荐。通过精准用户画像,可以获知用户使用图书馆是基于哪一种类型的阅读需求。如果是学习型阅读需求,可以结合用户的阅读兴趣和偏好推荐与阅读主题相关的优质学习资源;如果是科研型阅读需求,可以推荐与用户最近研究主题相关的文献资料;如果是实践型阅读需求,可以推荐相关视频资源和操作手册;如果是娱乐型阅读需求,可以从用户成长发展的角度推荐业余文化生活方面的信息资源。
(2)场景服务推荐。场景个性化服务是指图书馆提供的契合用户兴趣和需求的各种服务,满足用户的实时场景(时间、空间、学习情境等)需求。融入场景标签的用户画像为图书馆个性化场景服务推荐提供了有效支撑,如用户只要打开智慧图书馆App,借助智能终端的传感器设备,用户画像模型就能够实时获取用户的场景数据,从而推荐与场景相匹配的资源列表。
(3)智能用户追踪。用户从注册图书馆到使用再到最终的注销退出,存在用户生命周期特性。用户个体画像可以捕获用户所处生命周期的阶段,运用机器学习、数据挖掘等方法判别用户的状态和类别(普通、活跃、流失),并根据这些信息制定追踪策略、优化资源供给、改进服务模式,确保为用户提供优质资源,并根据流失用户的画像信息建立流失预警分析机制,强化个性化服务措施,吸引流失用户回到图书馆。
(4)智慧服务评估。用户可以对推荐结果进行有效评估,帮助推荐系统优化推荐算法,生成更高质量、更加精准的推荐结果,提高推荐引擎的推荐质量,满足用户潜在的学习需求,体现 “以人为本” 的智慧服务。
5 结束语
本文基于智慧图书馆的用户海量行为数据,从数据科学的角度区分了小数据和大数据的内涵,明确了二者的相互关系。在此基础上,利用小数据构建用户个体画像,利用大数据构建用户群体画像,充分发挥了用户大数据和用户小数据的各自优势。生成的用户画像模型实现了图书馆各种资源与用户需求的精准对接,满足了用户的个性化需求,进而有效支撑智慧图书馆的 “智慧” 服务。然而,本文仅仅侧重于图书馆的用户画像,事实上要实现用户和知识资源的精准适配,还需要从多个维度、更细粒度刻画资源实体——知识元,形成有语义化的知识元和知识元之间的结构关系,并按需组合知识元,形成特定意义上的学习资源。这将打破以文献、图书为单位的资源体系,从而使用户需求和知识元之间能够形成更加灵活的映射关系。
