Bayer阵列图像去马赛克算法综述
2022-09-20魏凌云孙帮勇
魏凌云,孙帮勇, 2*
1. 西安理工大学印刷包装与数字媒体学院,西安 710048;2. 中国科学院西安光学精密机械研究所光谱成像技术重点实验室,西安 710119
0 引 言
滤色片、棱镜和光栅是直接成像最常用的分色元件,由于滤色片可直接覆盖在传感器表面对入射光进行分色,能极大降低成像设备的体积和成本,因此彩色数字相机多采用滤色片作为分光元件。同时,为实现单次曝光成像,数字相机大多设计为单个传感器表面覆盖不同颜色滤色片的结构,通过稀疏采样和实时插值重建,实现图像的快速获取。
数字相机直接成像获取的图像为彩色滤色片阵列(color filter array,CFA)图像,每个像素位置仅存储一种特定颜色的灰度值,因此这种阵列图像也称做马赛克图像。对于RGB彩色相机来说,马赛克图像的采样率为1/3,每个位置上另外两种未采样颜色需通过重建算法获得,这个过程称为图像去马赛克。最通用的阵列图像为Bayer CFA(Bayer,1976),如图1(a)所示,其在空间分布上绿色采样量是红色或蓝色的两倍。此外,在RGB成像领域,为了达到较好的重建效果,研究者设计出其他CFA:X-Trans CFA(图1(b))和RGBW CFA(RGB-white CFA)(图1(c)),并提出相应的去马赛克方法(Rafinazari和Dubois,2014;Kang和Jung,2020;王海琳 等,2021)。

图1 RGB成像领域中的多种CFAFig.1 Various CFAs in RGB imaging((a) Bayer CFA; (b) X-Trans CFA; (c) RGBW CFA)
针对欠采样条件下的Bayer阵列图像,利用去马赛克数学模型重建未采样颜色值,实现完整图像信息的重建,是RGB相机成像中最普遍的方法。其能够显著缓解数字相机的硬件成本,并极大提高图像获取的便利性。然而,由于采样率仅为1/3,多数图像去马赛克方法存在龟纹、拉链效应和颜色失真等缺陷,因此去马赛克长期以来一直是成像和视觉领域的挑战性问题和研究热点之一。研究发现,去马赛克方法可大致分为传统方法和深度学习方法两类。传统方法主要依赖特定的先验知识或人工设计的模型,按照一定规则对各像素颜色值进行重建,泛化能力较差。深度学习方法则是根据大量的数据集训练一种图像重建网络,学习Bayer 阵列图像到原始完整图像之间的映射关系,所得模型具有更高的重建效率和泛化能力。本文主要对Bayer CFA去马赛克算法进行回顾和分析,着重对深度学习方法重建模型进行总结和分类,并按照独立去马赛克任务和联合其他视觉任务两个方向进行阐述。
1 传统方法
前期去马赛克算法是较为简单的色差插值方法,如最近邻插值(Adams,1995;Ramanath等,2002)、双线性插值(Hou和Andrews,1978)、双三次插值(Li和Randhawa,2007)和三次B样条插值(Longère等,2002)等。色差插值法简单且容易实现,但忽略了通道间的相关性和边缘结构细节,重建结果经常存在颜色伪影、拉链效应和模糊等缺陷,仅适合重建较为平滑的图像类型。后来,Pekkucuksen和Altunbasak(2010)对色差法进行改进,提出基于梯度的无阈值算法(gradient based threshold free,GBTF),利用色差梯度计算每个方向的权重,然后根据每个方向的权重,结合来自各个方向的估计对图像值进行插值。GBTF虽然在客观评价方面有一定程度的提高,但在主观评价中仍存在颜色伪影、模糊等失真现象。
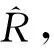
以上基于RI的重建方法中,由于只能恢复R和B通道的像素值,而对于G通道仍是运用色差插值方法,从而不能充分挖掘G通道信息,并且G通道重建中引入的误差将会影响R和B通道的重建。针对此问题,Ye和Ma(2015)提出迭代残差方法(iterative residual interpolation,IRI),通过迭代运算对三通道应用RI,使通道间相互引导重建。之后,Monno等人(2015)提出自适应残差插值方法(adaptive residual interpolation,ARI),不同于IRI(IRI对整个图像像素使用相同的迭代次数),ARI自适应地为每个像素选择合适的迭代次数,使迭代次数更灵活、更适合每个通道像素值的重建。
2 深度学习方法
由于深度学习中的卷积神经网络(convolutional neural networks,CNN)能够有效提取图像的浅层、深层特征以及结构信息,已经在图像超分辨率(Liu等,2020a;雷鹏程 等,2020)、去噪(吴从中 等,2018;Jia等,2021)和去模糊(吴迪 等,2020;Wan等,2021)等视觉处理任务中取得令人满意的结果。近年来,基于深度学习的去马赛克方法发展较快,其利用大量数据集进行网络训练,不断学习马赛克图像与原始图像之间的映射关系,从而获得精度较高、泛化能力较强的图像重建模型。研究发现,与传统方法相比,基于深度学习的去马赛克方法重建图像质量得到进一步提升,在主观评价和客观评价指标上都更接近原始图像,在多种应用领域已逐步替代传统方法。
如图3所示,按照去马赛克任务的独立性,基于深度学习的方法可大致分为独立去马赛克任务和联合其他视觉任务的去马赛克任务。独立去马赛克方法中,有些方法首先建立参数学习的深度网络,然后利用学习到的参数在传统去马赛克模型下进行图像重建;有些方法是端到端网络,即针对给定的马赛克图像直接输出重建图像。联合去马赛克任务,主要考虑Bayer 阵列图像的采样率低、噪声明显等特征,因此已提出了大量去噪和去马赛克联合方法,以及图像超分辨率和去马赛克的联合处理方法。

图3 基于深度学习的去马赛克方法分类Fig.3 The classification of deep learning demosaicing method
2.1 独立去马赛克任务
独立去马赛克任务可大致分为两阶段去马赛克、三阶段去马赛克和端到端去马赛克3类。其中两阶段去马赛克和三阶段去马赛克方法一般遵循传统去马赛克流程,先恢复采样率较高的G通道,然后以此作为先验信息,引导R、B两通道的像素信息重建。考虑到端到端卷积神经网络重建效率高、泛化能力强的特点,近年来更多的图像去马赛克网络设计成端到端方式。
2.1.1 两阶段去马赛克
Tan等人(2017)提出CDM-CNN(color demosaicking-CNN),首先用双线性插值生成Bayer阵列图像中的缺失像素值,然后构建图像去马赛克CNN来恢复G通道,并将恢复的G通道作为引导图像来重建R和B通道。随后,余继辉等人(2020)提出插值预处理后利用网络进行重建的两阶段方法。Tan等人(2020)根据Bayer CFA阵列特点,采用不同的特征提取网络获得R、G、B三通道的浅层特征后进行特征融合,从而得到重建的R、G、B单通道图,然后进行特征增强合并成RGB全彩色图,完成图像重建。Tan等人(2018)根据不同图像的复杂程度,利用梯度校正双线性插值方法对Bayer阵列图像插值后,建立全卷积网络进行图像重建,该网络针对一般图像、平滑图像和粗糙图像训练了3类网络参数,3个网络生成的图像进一步融合后作为最终的去马赛克图像。
两阶段去马赛克方法继续保留了传统去马赛克的流程,通过构建卷积神经网络进行关键参数的学习,与传统方法相比,性能得到一定提升,峰值信噪比(peak signal to noise ratio,PSNR)等客观指标提高明显。同时,部分两阶段去马赛克方法根据Bayer阵列的点阵结构和重建图像的复杂程度,设计了不同的网络进行参数学习,使模型有针对性地进行重建图像,获得较好的主观评价结果。但是,已提出的两阶段去马赛克网络相对较浅,未充分利用图像特征,仍存在一定提升空间。此外,大部分两阶段的方法将插值作为初始化,可使后续网络稳定且易于训练。但值得注意的是,插值带来的误差也将会成为后续网络学习的对象,从而影响网络的表达能力。
2.1.2 三阶段去马赛克
Cui等人(2018)分析了R、G、B三通道之间的相关性,指出R、G、B三通道两两之间具有不同程度的相关性,且G通道与R、B通道具有更高的相关性,提出三阶段(3-stage)去马赛克方法。该方法首先构建基本卷积神经网络计算G通道,再将重建的G图像分别合并到R、B通道中进行引导,重建R、B通道,最后合成完整的RGB三通道图像。此方法遵循传统去马赛克流程,同时运用卷积神经网络有效提取图像特征。随后,Wang等人(2021b)指出3-stage的初始化和先验信息融合不够有效,为解决此问题,在遵循3-stage的去马赛克流程的同时,构建出新的三阶段深度卷积网络(new three-stage deep convolutional network,NTSDCN),将采用拉普拉斯能量损失函数约束的局部残差学习结构作为新的特征提取方式,并提出新的引导方式,在特征域应用非齐次线性模型有效融合G图像先验信息。但是该方法网络结构相对较深,参数数量大,导致计算成本高,在实际应用方面存在一定障碍。
Niu和Ouyang(2020)针对遵循传统去马赛克流程的深度学习网络的不足,如3-stage模型中时间成本高、参数多等问题,将遵循传统去马赛克流程的深度学习网络分解为三阶段轻量级网络。不同于其他方法通过构建网络计算出图像特征或残差特征之后再融合重建的思路,该方法是通过构建神经网络估计色差后再进行重建。首先通过高质量线性插值重建出Bayer图像中的未采样值,然后建立卷积神经网络恢复G通道并分别估计R-G和B-G色差,最后根据色差分别重建R和B,得到最终的RGB图。该方法充分利用了图像的跨通道相关性,并且可以独立训练和并行估计。Iriyama等人(2021)对三阶段轻量级网络进行了改进,将通道间的相关性和自相似性有效结合,在构建网络估计R-G和G-B色差的同时,应用非局部注意模块获取色差域中的长期相关性,从而可以更准确地预测纹理和边缘区域中的高频分量,提高重建质量。
此外,Kim等人(2020)考虑到Bayer CFA的点阵结构特点,为提高网络性能,使其更有针对性,提出了一种基于自适应网络感知滤波生成器和全局细化单元的去马赛克网络,首先通过密集连接网络生成自适应感知滤波器,然后在5 × 5的窗口中对局部信息进行插值,最后使用全局细化单元利用全局信息进行细化,得到最终重建的去马赛克图像。
三阶段去马赛克网络具有较高的重建精度,在遵循传统去马赛克流程的基础上,针对特征提取方式、引导方式和色差估计方法等方面进行改进,充分利用通道间的相关性,提取较为准确的图像特征,使重建图像能够保留更丰富的图像边缘和细节。然而,在性能提升的同时,网络结构也相应加深、内存和时间成本加大,导致难以投入到实际应用中。
2.1.3 端到端卷积神经网络
随着卷积神经网络结构的发展,多种新的网络结构应用到去马赛克中,如简单卷积堆叠(Syu等,2018)、残差网络(residual neural network,ResNet)(Kokkinos和Lefkimmiatis,2018;Verma等,2020;Zhang等,2019)、密集连接网络(Park和Jeong,2018,2019)、U-Net网络(Kang等,2019;Wang等,2021a)、特征金字塔网络(Mei等,2020)和生成对抗网络(generative adversarial network, GAN)(Zhao等,2019;Luo和Wang,2020)等,重建性能均有不同程度的提升。然而,近年来越来越多的端到端网络只专注于通过增加网络深度提升重建性能,忽略了参数数量与时间成本的影响,未充分权衡性能与成本,实用性不强。
1)简单卷积堆叠。Syu等人(2018)分别受图像超分辨率模型SRCNN(super-resolution CNN)(Dong等,2014)和VDSR(very deep super-resolution)(Kim等,2016)的启发,提出了DMCNN(demosaicing CNN)和DMCNN-VD (DMCNN-very deep)。如图4(a)所示,DMCNN与SRCNN类似,由3个卷积层堆叠而成,第1层为特征提取层,提取图像浅层特征;第2层为非线性映射层,学习Bayer阵列图像到完整RGB图像之间的非线性映射关系;第3层为重建层,直接重建出完整的RGB图像。3个卷积核的尺寸分别为9×9×128、1×1×64和5×5×3。尽管DMCNN实现了端到端的学习方式,但由于该网络比较浅,没有充分挖掘深度学习模型的潜力。为此,Syu等人(2018)提出了DMCNN-VD。如图4(b)所示,DMCNN-VD由20层构成,每层包含卷积层、批量归一化(Ioffe和Szegedy,2015)和缩放指数型线性单元激活函数(scaled exponential linear units,SELU)(Klambauer等,2017)。同时,为了防止梯度消失和梯度爆炸问题,还加入了残差学习策略,达到较快的收敛速度。DMCNN和DMCNN-VD是对端到端独立去马赛克任务的初步尝试,表明了端到端卷积神经网络模型在去马赛克任务中的有效性。

图4 DMCNN和DMCNN-VD的网络结构Fig.4 The network architecture of DMCNN and DMCNN-VD((a)DMCNN;(b)DMCNN-VD)
2)残差网络。尽管网络越深感受野越大,提取的上下文信息越丰富,模型的重建精度越好,但深度网络的参数量大,不易收敛,易出现梯度消失或梯度爆炸现象。为解决网络退化现象、缓解梯度消失和梯度爆炸问题,加快收敛速度,He等人(2016)提出残差网络结构,如图5(a)所示。此后,研究者将残差结构引入到去马赛克任务,Kokkinos和Lefkimmiatis(2018)提出用迭代的方式排列残差块,指出即使在较小的训练数据集上也能训练出较好的模型,网络参数较少,但是网络中残差块数量较少,效果提升不明显。Zhang等人(2019)提出残差非局部注意力网络(residual non-local attention network,RNAN),通过考虑像素间的全局相关性来获取非局部特征,进一步增强网络的表达能力。Verma等人(2020)提出将瓶颈残差(ResNet-bottleneck)网络应用到去马赛克任务中,如图5(b)所示,网络包括10个残差块,残差块的输入和输出都是256个通道,里面的特征图通道数设置为64,并在残差结构的基础上,运用瓶颈结构加深网络,由于参数量较少,更容易训练,使网络具有很好的通用性。然而,该网络未考虑图像信息分布不均匀问题。之后,余继辉和杨晓敏(2021)设计了残差注意力模块,充分利用了特征图之间的相关性和特征图内的空间相关性。

图5 残差结构和瓶颈残差网络Fig.5 The architecture of ResNet and ResNet-bottleneck network((a)ResNet;(b)ResNet-bottleneck)
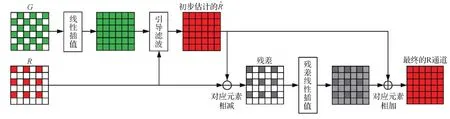
3)密集连接网络。由于之前的卷积网络结构是按顺序提取图像特征图,未充分利用到上一步以外的其他层特征信息,因此,Huang等人(2017)提出密集连接网络,如图6(a)所示,在网络中,每层卷积层的输入是前面所有层的输出合并,确保网络具有最大的信息流通,减少了参数数量,降低了过拟合问题出现的概率。随后,Park和Jeong(2018)提出密集连接去马赛克网络,如图6(b)所示,网络包括15个密集块,每个密集块均由卷积块(前6个卷积层)和过渡块(最后1×1卷积层)组成,每个卷积层紧密相连,可充分利用每一层的特征信息,有利于图像重建。在网络的最后通过亚像素插值层(Shi等,2016)生成重建图像。该网络不需要初始插值预处理,同时过渡块可以减少特征数量,计算复杂度不高,更易训练,重建精度更高。之后,Park和Jeong(2019)指出密集连接网络忽略了对浅层特征的利用,提出密集连接残差网络,将密集连接网络与残差结构有效结合,进一步提高了网络的重建能力。
图6 密集连接网络和密集连接去马赛克网络Fig.6 The architecture of densely connected network and densely connected demosaicing network((a)densely connected network;(b)densely connected demosaicing network)
4)U-Net网络。U-Net最初由Ronneberger等人(2015)提出并应用于图像分割任务,其将多尺度的特征融合在一起,能够处理任意大小的图像,具有较好的灵活性。如图7(a)所示,U-Net以编码器—解码器为基础,将原始图像的特征编码提取后,再将特征进行解码还原为需要的信息,结构简单且有效。相应地,针对去马赛克任务,Kang等人(2019)提出一种基于通道注意力的多尺度多层次特征融合的去马赛克算法,利用U-Net结构获取多尺度、多层次的特征,并引入通道注意机制,对每个场景的通道特征进行自适应调整,提高网络的表现力。后来,Zhou等人(2018b)指出U-Net结构(Ronneberger等人,2015)中位于前面的卷积层感受野较小,提取的是局部特征,而越往后感受野越大,提取到的特征更接近全局特征。如果将差异较大的局部特征与全局特征直接融合,会增大网络的难度。因此,为了减少语义差别,Zhou等人(2018b)提出了U-Net++。如图7(b)所示,在U-Net结构中直接连接的基础之上增加了类似于密集连接结构的卷积层,然后再融合下一阶段的特征,同时配合深度监督策略,使网络可任意剪枝。与U-Net相比,U-Net++ 仅增加了16%的参数量,而精度得到较大提升。Wang等人(2021a)对U-Net++进行改进,应用到边缘计算设备去马赛克任务中,其利用不改变图像大小的高斯模糊层代替下采样操作,虽然PSNR值不高,但重建图像中的伪影抑制较好,主观评价质量较高。

图7 U-Net和U-Net++的结构Fig.7 The architecture of U-Net and U-Net++((a)U-Net;(b)U-Net++)
5)特征金字塔网络。Mei等人(2020)提出金字塔注意网络,将多尺度特征提取方式与注意力机制结合进行重建,充分利用图像的自相似性来捕获远程特征对应关系。同时,该网络中的金字塔注意模块是一个通用的构建模块,可以灵活地集成到多种网络框架中。
6)生成对抗网络。生成对抗网络(Goodfellow等,2014)在图像生成领域发展较快,越来越多的研究者尝试将GAN的训练策略运用于图像去马赛克领域,以生成高质量的重建图像。Zhao等人(2019)将U-Net作为生成器,同时将生成显著图作为数据增强的一部分,提高训练集的丰富性。Luo和Wang(2020)将U-Net作为生成器,将密集残差网络作为鉴别器,进行交替训练,得到网络模型,重建图像可以更接近原始图像。罗静蕊等人(2021)利用生成对抗网络结合网络损失函数增强学习图像高频信息的能力,提升网络整体性能。
2.2 联合去马赛克任务
去噪、去马赛克和超分辨率均是彩色成像图像处理流程中的关键步骤。直接对未去噪的Bayer阵列图像进行去马赛克处理,重建网络会将噪声信息作为有用信息进行学习,导致重建效果不理想。因此,研究者经常采用去马赛克与去噪联合处理的方法,建立端到端网络对Bayer阵列图像实现一次性重建。此类方法方便快速,可一次性处理多个任务,但针对性不强,精度偏低。
2.2.1 去马赛克和去噪联合任务
1)简单卷积堆叠。Gharbi 等人(2016)采用类似SRCNN(Dong等,2014)的网络结构,建立Bayer阵列图像与完整信息图像之间的非线性映射关系,首次将卷积神经网络运用于联合去马赛克和去噪任务,相比之前方法,在重建精度上得到一定程度提高。但是,该网络在训练过程中依赖大量数据集,并且设计的网络在输出图像尺寸方面不稳定,实施比较困难。Prakash等人(2017)也采用简单堆叠卷积层进行去马赛克和去噪,但重建的图像仍存在一定的误差和伪影。
2)残差网络。Huang等人(2018)将深度残差学习和聚合残差变换(Xie等,2017)的概念应用于联合去马赛克和去噪任务,提出较少参数量的轻量级网络,但由于网络包含了36个卷积层,其内存读取写入的总时间成本不可忽略。另外,Kokkinos和Lefkimmiatis(2019)提出以迭代的方式排列残差网络,能够有效利用提取到的特征,提高网络表达能力。Guo等人(2020)针对成本问题,将Inception-ResNet结构(Szegedy等,2017)进行改进,得到轻量级的Inception结构,应用到残差网络中,获得了更好的跨通道融合特征和更大的接受域,能够有效避免棋盘效应且可以保留更多的图像细节。随后,Xing和Egiazarian(2021)在残差网络的基础上引入了通道注意力机制,也取得不错的重建效果。
3)密集连接网络。Din等人(2020)提出用密集连接网络先进行去马赛克再去噪,但忽略了去马赛克后的噪声模型破坏问题,导致去噪的结果不够准确。Qian等人(2021)提出用密集连接残差网络进行去马赛克、去噪和超分辨率的联合任务,其将网络划分为两个模块,先进行图像超分辨率,再执行去马赛克和去噪,可以减少去马赛克伪影,同时使去马赛克任务突破分辨率的限制。
4)其他网络。Dong等人(2018)提出一种端到端的基于GAN的联合去马赛克去噪网络,并且应用具有感知损失函数和对抗性损失函数的鉴别器网络来优化重建图像的感知质量,使重建图像更接近原始图像。Liu等人(2020b)指出对所有位置和所有图像不应该用同一组参数,应考虑图像的具体内容和重建难度,因此提出两种新的自引导方法——绿色通道引导和密度图引导方法,使网络可自适应处理图像不同层次的特征,重建精度更准确。Park等人(2020)提出一种可对单个图案图像进行训练,可适用于不同噪声水平的变分深度图像先验网络。Sharif等人(2021)运用深度注意力机制和空间注意力机制,引入感知颜色损失和正则化特征损失两个新的感知损失,提高重建图像的感知质量。
2.2.2 去马赛克和超分辨率联合任务
去马赛克网络的预处理操作大多是将采样得到的Bayer阵列图像下采样成半尺寸的四通道RGGB图像,导致分辨率降低或图像细节丢失。同时,RGB的相对位置信息也无法保证。因此,学者提出将去马赛克和超分辨率进行联合处理,以有效保留图像的颜色信息和位置信息。
Zhang等人(2018)提出用全局残差结构学习图像特征,在网络的末端用亚像素插值实现超分辨率。Zhou等人(2018a)直接运用残差网络学习低分辨率的阵列图像到对应高分辨率图像的映射关系。Xu等人(2020)提出预去马赛克网络(pre-demosaicing network,PDNet)和残差密集压缩网络(residual-dense squeeze-and-excitation networks,RDSEN)的级联网络,首先将RI插值得到的RGB图作为替代目标,与PDNet得到的结果进行残差,得到中间的去马赛克结果,然后利用RDSEN学习中间去马赛克结果和参考图像的映射关系,并进行感知优化。
3 实 验
3.1 数据集和评价指标
在图像去马赛克任务中,常用的训练数据集有WED(Waterloo exploration database)数据库、Image-Net、DIV2K(DIVerse 2K resolution high quality images)和Flickr2K。WED数据库中包含4 744幅不同场景的高质量彩色图像。ImageNet是目前世界上图像识别最大的数据库,包含1 000种类别的对象组成的13万幅图像,涉及大量不同场景和结构。DIV2K包含1 000幅2 K分辨率的高清图。Flickr2K包含2 650幅2 K的高清图。常用的测试集主要有Kodak和McMaster(IMAX)。Kodak数据集中包含24幅765×512像素的图像,以建筑物、天空和大海为视角。McMaster包含18幅从高分辨率图像中裁剪出的大小为500×500像素的图像,内容主要以室内场景为主。
使用峰值信噪比(PSNR)和结构相似度(structural similarity index,SSIM)作为评价指标。PSNR主要是以像素的形式衡量重建图像与原始图像的差异。SSIM主要衡量重建图像与原始图像之间的相似程度。PSNR和SSIM的值越大,表示重建质量越好,方法性能越好。
3.2 实验结果与分析
实验在Kodak和McMaster两个基准数据集上进行,对具有代表性的双线性插值(Hou和Andrews,1978)、RI(Kiku等,2013)、ARI(Monno等,2015)等传统方法和CDM-CNN(Tan等,2017)、3-stage(Cui等,2018)、NTSDCN(Wang等,2021b)、U-Net++(Wang等,2021a)等典型深度学习方法进行评价。为保证公平性,测试均在同一个设备上进行,并且基于深度学习的方法均在CPU上进行。
3.2.1 客观评价实验结果
表1和表2分别是7种方法在Kodak和McMaster数据集上的性能比较。表3是测试时间的比较。可以看出:1)大部分基于深度学习方法的精度明显比传统方法高。在Kodak数据集上,深度学习中精度最高的CDM-CNN的PSNR比传统方法中精度最高的ARI高出2.72 dB,同时比ARI的时间成本低。该结果证明,CDM-CNN方法充分利用了RGB三通道间的相关性以及绿像素的高采样率。2)双线性插值方法的时间成本最小,但重建效果最差。对于U-Net++方法,虽然精度比CDM-CNN在两个基准数据集上分别低0.62 dB和1.27 dB,但在CPU上的测试时间提高了90.71%左右。实验证明,U-Net++在精确度和时间成本上能实现较好的平衡。
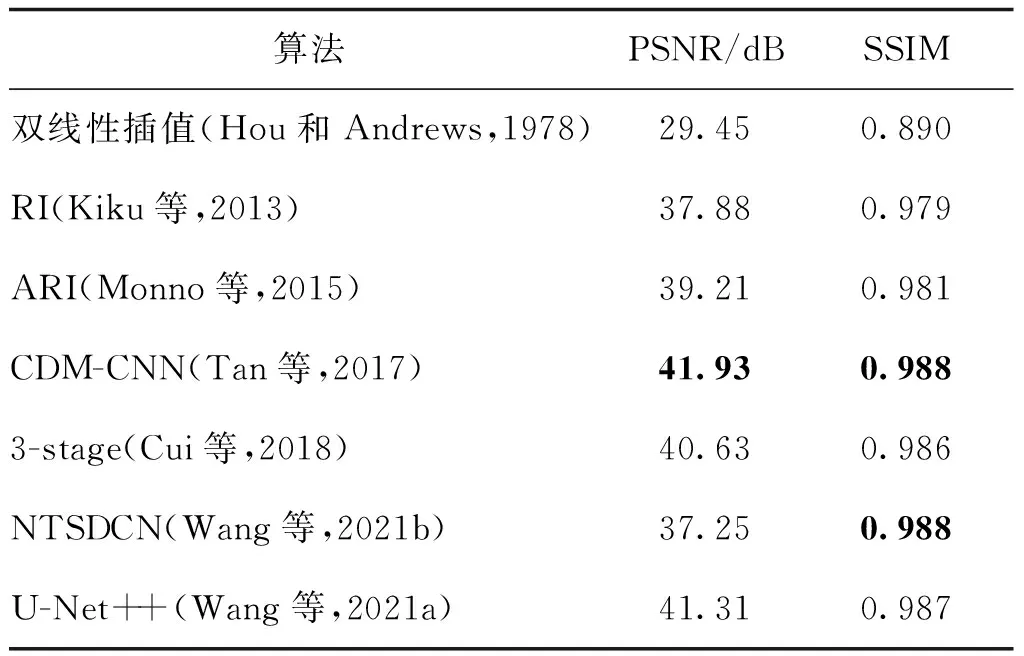
表1 不同算法在Kodak数据集上的性能对比Table 1 Comparison of performance for different algorithms on the Kodak dataset
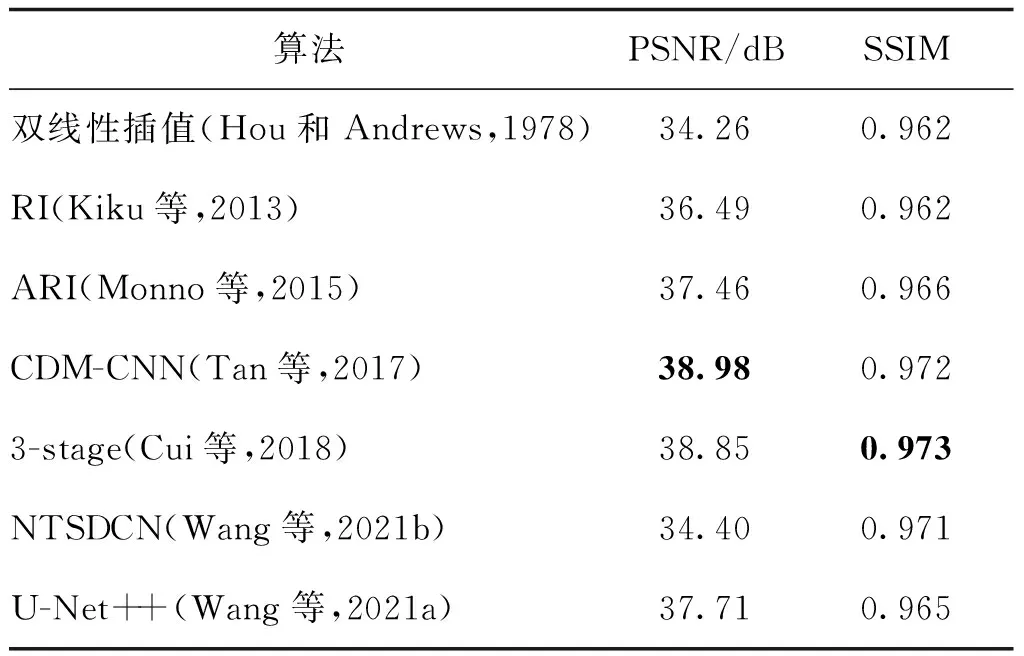
表2 不同算法在McMaster数据集上的性能对比Table 2 Comparison of performance for different algorithms on the McMaster dataset

表3 不同算法在Kodak和McMaster数据集上测试时间的比较Table 3 Comparison of test time for different algorithms on Kodak and McMaster datasets /s
3.2.2 主观评价实验结果
对于图像去马赛克任务来说,最大的挑战是在纹理丰富和色彩过渡区域的重建。图8和图9分别是在Kodak第1幅和McMaster第8幅上不同方法重建效果的局部放大图。可以看出,传统方法极易产生边缘伪影和拉链效应,而深度学习无明显的边缘伪影,即使是PSNR较低的NTSDCN(Wang等,2021b)算法也极少出现伪影,实现了较好的视觉效果。

图8 Kodak上不同方法重建图像的局部放大图Fig.8 The partial enlarged view of the reconstructed image with different methods on Kodak((a) original image; (b) bilinear; (c) RI; (d) ARI; (e) CDM-CNN; (f) 3-stage; (g) NTSDCN; (h) U-Net++)

图9 McMaster上不同方法重建图像的局部放大图Fig.9 The partial enlarged view of the reconstructed image with different methods on McMaster((a) original image; (b) bilinear; (c) RI; (d) ARI; (e) CDM-CNN; (f) 3-stage; (g) NTSDCN; (h) U-Net++)
4 结 语
图像去马赛克是计算机视觉领域中基本的图像处理任务之一,也是图像分类、目标检测等任务的基础。传统图像去马赛克方法中,重建图像多存在颜色伪影、拉链效应和棋盘效应等缺陷。随着深度学习在去马赛克任务中的应用,提出了多种重建模型,重建精度得到提升。本文主要对Bayer阵列图像的去马赛克方法进行分类总结,阐述了不同方法的基本原理和网络结构,比较了不同方法的重建性能。实验和分析证明,深度学习方法在重建精度方面已超越大部分传统方法,但仍存在时间成本高和应用性不强等问题。
根据已有的研究方法和研究思路,本文对基于深度学习的Bayer阵列图像去马赛克技术的待解决问题和研究方向进行展望。1)部分深度学习方法过度注重网络结构设计,易造成网络过深、不收敛等问题。虽然该思路能够改善图像重建质量,但需存储大量模型参数,计算时间较长。因此,在设计网络结构的同时,应当将计算成本考虑在内,如何平衡计算成本和算法的准确性是图像去马赛克任务的一大挑战;2)在测试集的图像特征与训练集差异较大时,容易造成网络训练结果不理想,导致模型泛化能力弱,所以进行模型训练时,应选择图像特征丰富的数据集,提高模型的泛化能力;3)部分研究工作只有系统的客观评价指标,没有系统的主观评价机制,例如NTSDCN(Wang等,2021)能够获得很好的视觉质量,但是PSNR不高。在模型评价时,应结合主客观指标综合评价;4)多数去马赛克方法仅关注软件层面的改进和提高,针对图像获取硬件的研究较少。围绕软硬件结合的图像去马赛克方法是后续的研究方向之一。
