多特征决策融合的音频copy-move篡改检测与定位
2022-09-20张国富肖锐苏兆品廉晨思岳峰
张国富,肖锐,苏兆品*,廉晨思,岳峰,4
1. 合肥工业大学计算机与信息学院,合肥 230601; 2. 大数据知识工程教育部重点实验室(合肥工业大学),合肥 230601;3. 智能互联系统安徽省实验室(合肥工业大学),合肥 230009; 4. 工业安全应急技术安徽省重点实验室 (合肥工业大学), 合肥 230601; 5. 安徽省公安厅物证鉴定管理处,合肥 230000
0 引 言
随着数字音频技术的发展,社交软件如微信、QQ和米聊等均提供语音和实时语聊功能。这些语音功能不仅可用于日常交流,还经常用于买卖、租赁和借贷等商业活动(杨鹏 等,2015)。当发生侵权纠纷时,语音可作为证据在法庭上使用。但是,根据2016年最高人民法院、最高人民检察院和公安部联合印发的《关于办理刑事案件收集提取和审查判断电子数据若干问题的规定》,当电子数据系篡改、伪造或者无法确定真伪,或者电子数据有增加、删除和修改等影响电子数据真实性的情形,电子数据则不得作为定案的根据。因此,音频真实性鉴别是音频能否作为法庭证据的一个基本前提,是音频取证迫切需要解决的一个现实问题。
通常,音频篡改操作包括对音频文件进行插入、删除、复制粘贴和拼接等,以破坏、扭曲或者伪造新的语义,达到断章取义、掩盖细节的目的。其中,copy-move篡改是指将部分语音片段复制并粘贴到同一音频文件中的其他位置,以改变在原始音频文件中发生的事件或对话。这些操作可以通过各种功能强大的音频编辑软件轻松实现且很难发现。与其他音频篡改类型(如拼接和合成伪造)不同,在copy-move篡改中,音频源片段和目标片段都来自同一音频文件。因此,许多基本的特性,例如振幅、频率、长度、噪声、音调甚至速度,都可以在伪造片段和音频文件之间很好地匹配,尤其当伪造片段是持续时间很短的话语,这大大增加了盲音频篡改检测的难度。因此,copy-move篡改检测是音频鉴真面临的一个极具挑战性的课题,已成为音频取证领域中的一个研究热点。
1 相关工作
针对copy-move篡改检测,当前主流的方法大都基于语音端点检测(voice activity detection, VAD)技术将音频文件划分成若干有声段和静音段,然后通过计算所有有声段或字节之间的相似性来判断是否存在copy-move篡改。VAD旨在从复杂语音信号中区分有声片段和静音片段,并确定每个有声片段的起始位置,是语音检测、语音识别和语音增强等领域的一种重要技术。VAD通常包括特征提取和判决两个方面,常用的特征参数有谱熵、短时能量和短时过零率等,判别方法有单/双门限、统计模型和机器学习等。
Xiao等人(2014)利用快速卷积算法将完整的音频文件按时间跨度划分为固定等长的片段,然后计算任意两个片段之间波形的相似程度。Wang等人(2017)计算每个有声段的离散余弦变换系数,并采用奇异值分解算法得到奇异向量特征,使用欧氏距离来衡量有声段的相似性。Imran等人(2017)通过局部二值模式编码提取每个有声段的特征,然后将均方误差(mean square error, MSE)和能量比率结合使用计算相似性。Yan等人(2015)首先使用归一化低频能量比(normalized low frequency energy ratio, NLFER)方法区分静音段和有声段,然后提取每个有声段的YAAPT(yet another algorithm for pitch tracking)特征(Kasi和Zahorian,2002),最后综合使用皮尔逊相关系数(Pearson correlation coefficients, PCC)和均方差值(average difference, AD)来衡量有声段的相似度。
需要指出的是,上述研究虽然能够发现音频文件存在copy-move篡改,但往往很难准确定位到copy-move篡改的具体位置,难以满足实际司法取证需求。例如,在实际的音频鉴真中,经常会出现对一个有声片段内的某一个字或几个字被复制粘贴。例如,将“我没做”篡改成“我有做”。在这种情况下,不仅需要确定是否发生了篡改,还需要准确指出篡改的位置,即哪个字是伪造的。已有研究大都只能检测出整个有声片段是否发生了copy-move篡改,而很难准确指出哪个字是伪造的,即很难准确给出伪造字节所在的位置。
基于上述背景,本文在充分调研和总结分析已有工作的基础上,首先利用VAD技术划分出音频文件中的每个字节,从频域、空间域和时域角度分别提取一种特征。对于音频文件中的任意两个字节,根据每个特征计算一个相似度,然而基于多特征决策融合(multi-feature decision fusion, MFDF)准确定位copy-move篡改位置,最后基于相关数据集(Wang和Zhang,2015)对所提方法进行测试和验证。
2 基于MFDF的copy-move篡改检测与定位方法
本文所提的音频copy-move篡改检测与定位方法MFDF总体流程如图1所示。首先利用VAD技术将音频分为静音段和有声段,并进一步对有声段进行字节分割,然后提取每个字节的基音频率特征、颜色自相关图特征和短时能量特征。对于音频文件中任意两个字节,利用DTW距离计算其在基音频率特征上的相似度,利用余弦距离计算其在颜色自相关图特征上的相似度,利用短时能量和差值计算其在短时能量特征上的相似度,然后基于多特征决策融合确定copy-move篡改的具体位置。
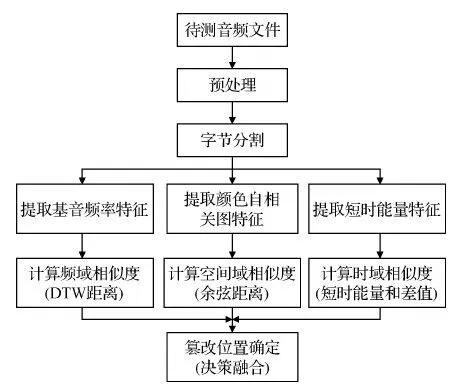
图1 本文MFDF方法整体框架Fig.1 Block diagram of the proposed MFDF
为了更加清晰地说明图1所示的copy-move篡改检测与定位MFDF方法,详细介绍框架中的一些关键步骤。
2.1 预处理
为了尽可能减少噪声和静音段的影响,需要将待测音频文件进行音量标准化、分帧和加窗,并利用基于谱熵法的VAD技术(Jin和Cheng,2010)将音频划分为若干有声段和静音段。图2为一段待检测的音频,图3是利用VAD分割的结果。可以看到,预处理后,可以把整个音频文件分割成许多的有声段和静音段,从而为下一步的字节分割打下基础。
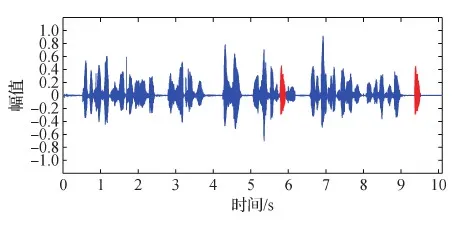
图2 一段待测音频Fig.2 Waveform of a pending audio recording

图3 基于VAD预处理后的分割结果Fig.3 Segmentation results from VAD on the audio recording
2.2 字节分割
为了提高copy-move篡改检测和定位的准确度,本文基于能熵比方法(Wang和Tasi,2008)进一步对划分出的有声段进行字节分割,以实现每个字节包含一个完整的汉字。假设对音频信号分割后的有声段信号为x,则字节分割步骤描述如下:
1)首先对x加窗分帧,得到若干帧信号xc(c=1,2,…),并对每一帧xc进行快速傅里叶变换(fast Fourier transform, FFT),得到系数Xc,其中含有q条谱线。计算第c帧的短时能量Ec和短时谱熵Hc
(1)
(2)
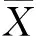
2)计算第c帧对应的能熵比EEFc,即
(3)
3)将EEFc与阈值L1进行比较。如果任意连续L2帧的能熵比均满足EEFc≥L1,则认为L2长度的音频帧为一个字节。
经过上述处理后,有声段信号x可分割为若干个字节{S1,S2,…,Sn},Si表示第i个语音字节,1≤i≤n,n为字节数。图4和图5分别为图2所示音频的能熵比示意图和字节分割结果图。可以看出,在图3的有声段基础上,基于能熵比方法可以进一步把长时有声段细分为若干短时字节。如图5所示,图2所给的音频最终被分割成37个字节。
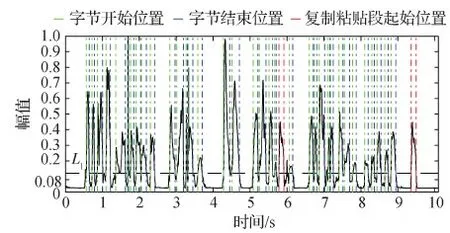
图4 待测音频的能熵比示意图Fig.4 Energy to entropy ratio of the audio recording

图5 待测音频的字节分割结果Fig.5 Syllable segmentation results of the audio recording
2.3 多特征提取与相似度计算
为了保证音频复制粘贴检测高准确率的同时,进一步降低检测误检率,本文从音频的频域、空间域和时域3个域出发分别提取基音频率、颜色自相关图特征和短时能量。在频域,说话人声带振动频率即为基音频率,作为音频频域具有代表性的特征能有效准确地体现说话人不同字节的差距。在空间域,语谱图的出现对语音分析起到了十分关键的作用,包含了丰富的语音信息。颜色自相关图不仅包含了颜色像素在同一幅图像中所占比例,还包含了空间关系信息。在时域,说话人语音都会携带能量,短时能量作为经典的时域特征,已广泛用于语音信号处理中。本文将这3种不同域的典型特征综合起来考虑,以期全面感知音频信号的细微变化。
2.3.1 基音频率特征
基音频率是音频频域常用特征之一,常用于识别发音源。对于分割得到的任一字节Si,对其包含的每一帧Sia(a=1,2,…,ni,ni为Si包含的帧数)提取基音频率特征(Zahorian和Hu,2008),具体步骤如下:
1)计算帧Sia的短时自相关函数Ria(v)和平均幅度差函数Dia(v),即
(4)
(5)
式中,Sia(l)为帧Sia中的每个采样点,l=1,…,N,N为每帧的帧长,v∈[min,max]为时间延迟量,min、max分别为基音周期的最小和最大阈值。
2)计算帧Sia短时自相关函数和平均幅度差函数的比值Qia(v),即
(6)
3)在v∈[min,max]区间内搜索Qia(v)的最大值,将最大值对应的v作为Sia语音帧的基音频率fia。
按照上述步骤,可以求得任一字节Si的基音频率向量Fi=(fi1,fi2,…,fir,…,fini)。基于此,字节之间的相似性可用DTW距离进行度量。对任一两个字节Si和Sj,其DTW距离为
dtw(fir,fjq)=dist(fir,fjq)+min[dtw(fir-1,fjq),
dtw(fir-1,fjq-1),dtw(fir,fjq-1)]
(7)
dist(fir,fjq)=|fir-fjq|
(8)
式中,r=1,2,…,ni,q=1,2,…,nj,nj为Sj包含的帧数。经过以上迭代计算,最终求得的dtw(fini,fjnj)即为两个字节Si和Sj之间的DTW距离DTWi,j。
2.3.2 颜色自相关图特征
以可视化形式反映语音信号频谱特性的方式,可以观察语音不同频段的信号强度随时间的变化情况,反映了音频的空间域特征。对于任一字节Si,本文从其语谱图中提取颜色自相关图特征(Huang等,1997),具体步骤如下:
1)首先生成语音字节Si的语谱图Ik。
2)将语谱图Ik量化成64种颜色,对于任意两个像素点pU1,V1和pU2,V2(U1、V1、U2、V2为空间坐标),计算两者之间的距离
t(pU1,V1,pU2,V2)=|pU1,V1-pU2,V2|=
max{|U1-U2|,|V1-V2|}
(9)
3)假设ωr表示64种颜色中的任意一个颜色,则根据式(10)计算语谱图Ik的颜色自相关系数δωr,表示颜色均为ωr的两个像素之间距离为z的概率,即
δωr=Pr[t(pU1,V1,pU2,V2)=z]
(10)
式中,Pr表示求颜色均为ωr的两个像素之间距离为z的概率运算。显然,由语谱图Ik可得到64个颜色的自相关系数,可作为字节Si的颜色自相关图特征向量Pi=[δi,1,δi,2,…,δi,64]。基于此,字节之间的相似性可采用余弦距离进行度量。对任一两个字节Si和Sj,其余弦距离cosi,j计算为
(11)
2.3.3 短时能量特征
语音短时能量指的是一帧时间内的语音能量,是语音信号典型的时域特征,通常作为辅助的特征参数用于语音识别。对于任一字节Si,首先利用提取其包含的每一帧Sia的短时能量Eia,即
(12)
式中,y(l)为语音帧Sia中第l个采样点幅值。进一步地,字节Si的短时能量和Ei为
(13)
基于此,字节之间的相似性可采用短时能量和的差值进行度量。对任一两个字节Si和Sj,其短时能量和的差值Δi,j计算为
Δi,j=Ei-Ej
(14)
2.4 决策融合
为了提高copy-move篡改检测与定位的准确性,本文基于多特征决策融合(谭等泰 等,2020)设计了一种MFDF方法,主要步骤如下:
1)对于一个待测音频文件,根据第2.3.1、2.3.2和2.3.3节的方法计算音频中任意两个字节Si和Sj之间的3种特征的相似度DTWi,j、cosi,j和Δi,j。
2)将计算出的特征相似度分别与其设定的阈值T1、T2和T3进行比较,如果同时满足DTWi,j≤T1、cosi,j≤T2和Δi,j≤T3,则判定这两个字节为copy-move字节对,并根据字节位置初步定位出篡改的大致位置;否则,这两个字节为非copy-move字节对。继续选择其他未检测的两个字节进行检查,直到所有两两字节检查完毕。
3)对于每一个copy-move字节对,分别首尾各扩展一帧构成新的两个字节,计算新的两个字节3个特征的相似度并继续与阈值进行比较。
4)如果仍然同时满足DTWi,j≤T1、cosi,j≤T2和Δi,j≤T3,则转至步骤3),直至DTWi,j≤T1、cosi,j≤T2和Δi,j≤T3这3个条件中有一个条件不满足为止,则此时的两个字节位置就是最终的篡改位置。
需要指出的是,本文基于MFDF方法进行copy-move篡改判定,所以在设置阈值时尽可能设置较低的阈值以确保低误检率。同时,非copy-move字节要想满足MFDF的判定条件十分困难,因为需要3个特征值相似度同时满足各自的阈值。因此,本文可以将阈值稍微放大一点,预留一定的判断缓冲空间,而不会影响判定结果。此时,只要两个字节其中某个特征值相似度大于所设置的阈值,则直接判定为非copy-move字节对,这样处理可以在一定程度上增加MFDF方法对常规信号处理攻击的抵抗能力。
3 实验结果与分析
3.1 数据集与参数设置
采用实验法, 即结合已有工作并基于数据集通过大量测试获得结果相对较好的阈值, 这也是目前常用的确定参数的方法。其中,MFDF方法的相似度阈值为T1=50、T2=0.015、T3=5,PF-DTW的阈值为100,DFT-PCC的阈值为0.98,LBP-MSE的阈值为60。
所有方法的代码均基于MATLAB编写,并在Intel(R) Core(TM) i7-7700 CPU @ 3.60 GHz、RAM 8.0 GB、Windows 7操作系统的个人PC上进行测试。
(15)
(16)
式中,p和r分别为精确率(precision)和召回率(recall)。TP表示正确检测出来的copy-move篡改音频数量,FP表示误检为copy-move篡改音频的原始音频数量,FN表示未检测出来的copy-move篡改音频数量。precision又称查准率,即真正正确地占所有预测为正的比例。recall又称查全率,即真正正确地占所有实际为正的比例。
采用绝对误差值来衡量不同方法在copy-move篡改定位上的精准度。
3.2 MFDF的有效性

图6—图8分别给出了两两不同字节之间的相似度指标值(即DTW距离、余弦距离、短时能量和差值)的3维Mesh平面视角图。因为同一对字节之间的相似度一致,例如字节1和7之间的相似度与字节7和1之间的相似度值相同,所以只绘制了上半区域。其中,图片下方的横线指的是设定的相似度阈值,以观察有多少字节对之间的相似度在阈值以下。从图6可以看出,有7对字节的DTW距离小于阈值50,分别为第2和第10字节、第2和第36字节、第4和第36字节、第6和第13字节、第10和第35字节、第15和第27字节、第22和第37字节。从图7可以看出,有28对字节的余弦距离小于阈值0.015,和DTW结果重叠的只有2对字节:第15和第27字节、第22和第37字节。从图8可以看出,有13对字节的短时能量和差值小于阈值5,和DTW结果、余弦距离重叠的只有1对字节:第22和第37字节。
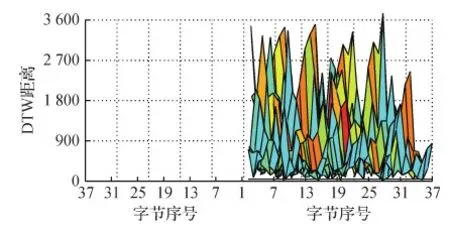
图6 所有字节对之间的DTW距离Fig.6 DTW distances between each pair of syllables
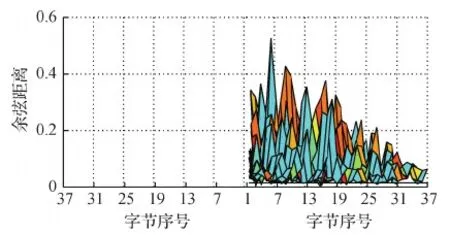
图7 所有字节对之间的余弦距离Fig.7 Cosine distances between each pair of syllables

图8 所有字节对之间的短时能量和差值Fig.8 Difference of the short-time energy sum between each pair of syllables
表1给出了MFDF方法在全库上的消融实验。从表中可以看出,当只利用单个特征进行篡改检测,虽然未被检测出来的样本数很少,但是检测的精确率很低,误检率太高。当利用两个特征进行篡改检测,精确率有所提升,但误检率依然很高。当利用MFDF方法(利用3个特征)进行篡改检测,不仅保持了较高的召回率,而且获得了较高的精确率,大大降低了误检率。

表1 MFDF方法的全库消融实验结果Table 1 Ablation experimental results of MFDF /%
3.3 与已有方法的对比
表2给出了4种方法的检测结果。可以看出,本文MFDF方法在精确率和召回率上均优于其他方法,均达到了97%以上,而其他3种方法均在90%以下。具体来说,相比于PF-DTW、DFT-PCC和LBP-MSE,精确率分别提升了约12%、11%和26%,平均提升约16%;召回率分别提升了约26%、28%和33%,平均提升约29%。上述实验结果表明,本文MFDF方法对copy-move篡改具有更好的检测效果。

表2 不同方法的copy-move篡改检测结果Table 2 Experimental results of different methods to copy-move forgery detection /%
为了进一步对比4种方法定位的精准度,从4种方法均检测正确的篡改音频中随机挑取了100条进行分析。首先根据MFDF的定位绝对误差值将这100条篡改音频按照升序进行排列,并统计排序后对应音频序号在PF-DTW、DFT-PCC和LBP-MSE上的定位绝对误差值。其中,由于PF-DTW和LBP-MSE采用相同的分段方法,因此其定位绝对误差值相同。图9给出了4种方法在100条篡改音频上的定位绝对误差值。从图中可以看出,在100条音频中,MFDF在89条音频上的定位绝对误差值均小于等于其他方法。
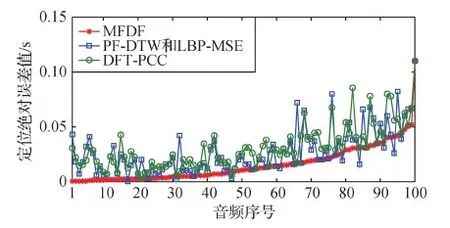
图9 不同方法的定位绝对误差值Fig.9 Absolute error of different methods to copy-move forgery localization
表3给出了4种方法在100条篡改音频上的定位平均绝对误差值。从表中可以看出,相比于PF-DTW、LBP-MSE和DFT-PCC,MFDF的定位精准度分别提升约43%、43%和49%,平均提升约45%。上述实验结果表明,本文MFDF方法在copy-move篡改定位的精准度上要显著优于已有方法,能够定位到更加精准的copy-move篡改区域。

表3 不同方法的定位平均绝对误差值Table 3 Average absolute error of different methods to copy-move forgery localization
3.4 鲁棒性分析
在实际的音频鉴真活动中,音频篡改操作常常附加一些常规信号处理攻击(Su等,2018),以掩盖篡改的痕迹,例如,1)加噪:对音频添加30 dB的高斯白噪声;2)滤波:对音频进行中值滤波;3)上采样:对音频分别进行频率18 kHz的上采样;4)下采样:对音频分别进行14 kHz的下采样;5)MP3压缩:对音频进行MP3压缩,比特率160 kbps,采样率保持不变。
为了测试4种方法对上述常规信号处理攻击的鲁棒性,对于1 000条音频,依次采用一种信号处理进行攻击,共产生5 000条攻击音频。表4和表5分别给出了4种方法在攻击音频数据集上的检测精确率和召回率。可以看出,经过5种常规信号处理攻击后,4种方法的精确率和召回率均有所下降,但本文MFDF方法在精确率和召回率上依然优于对比方法,且平均值达到了94%以上,而其他3种方法均在85%以下。具体来说,相比于PF-DTW、DFT-PCC和LBP-MSE,平均精确率提升了约16%,平均召回率提升了约31%。这是因为,本文MFDF方法分别从频域、空间域和时域3个不同域提取最典型的特征,可以在一定程度上保证单特征的检测准确率,然后基于多特征决策融合可进一步提高检测和定位的精准度,并有效降低误检率。上述实验结果表明,本文MFDF方法具有很好的鲁棒性,可以更好地适应一些常规信号处理攻击。
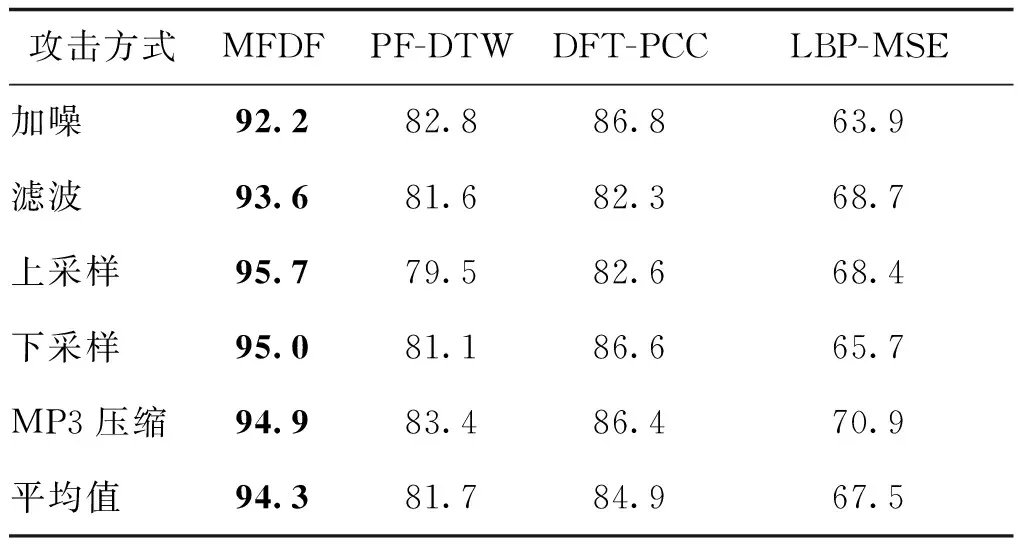
表4 本文MFDF方法在信号处理攻击音频数据集上的检测精确率Table 4 Detection precision of MFDF on the dataset attacked by common signal processing /%
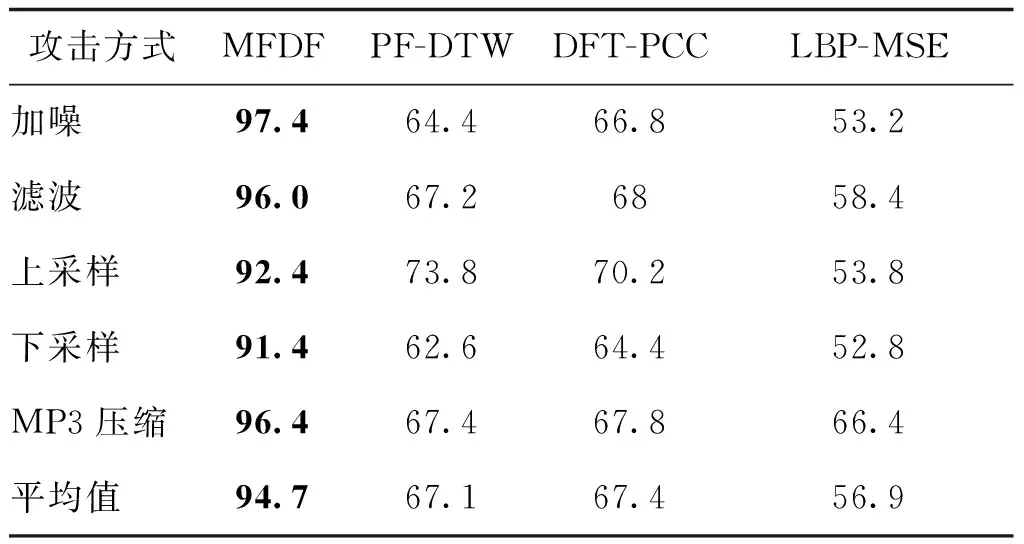
表5 本文MFDF方法在信号处理攻击音频数据集上的检测召回率Table 5 Detection recall of MFDF on the dataset attacked by common signal processing /%
4 结 论
音频真实性鉴别是音频能否作为法庭证据的一个重要前提,是目前音频取证领域一个亟待解决的问题。其中,copy-move篡改将部分语音片段复制并粘贴到同一音频文件中的其他位置,由于音频源片段和目标片段均来自同一音频文件,给盲音频篡改检测带来了极大挑战。传统方法擅长检测周期较长的有声分段,而在面向短复制片段时,检测和定位精度均不够理想,难以满足音频鉴真的实际需求。为此,本文综合考虑音频信号的频域、空间域和时域特性,提取音频信号的基音频率特征、颜色自相关图特征和短时能量特征,并通过全库消融实验验证了多特征相较单特征有着更高的精准率和召回率,误检率得到显著降低。提出一种多特征决策融合(MFDF)的copy-move篡改检测和定位方法。在清华大学开源中文语料库上的测试结果表明,本文MFDF方法在检测的精确率和召回率上,以及定位的精准度上均显著优于已有方法,且对常规信号处理攻击具有很好的鲁棒性。不过,本文只是针对音频copy-move篡改检测和定位研究的一个初步尝试,在未来仍有许多工作需要深入研究。首先,需要考虑引入更多的特征,以期进一步提升MFDF的检测性能。其次,还需要考虑一种更加通用的MFDF方法,以便能够检测和定位各种音频篡改操作,拓展MFDF检测方法的普适性。
致 谢本文对比方法DFT-PCC(Liu和Lu,2017)和PF-DTW(Yan等,2019)的源代码由中山大学计算机学院卢伟教授和深圳大学信息工程学院黄继武教授提供,在此表示感谢。
